 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time Uncertainty-Aware Motion Planning for Magnetic-based Navigation
Jul 26, 2024



Localization in GPS-denied environments is critical for autonomous systems, and traditional methods like SLAM have limitations in generalizability across diverse environments. Magnetic-based navigation (MagNav) offers a robust solution by leveraging the ubiquity and unique anomalies of external magnetic fields. This paper proposes a real-time uncertainty-aware motion planning algorithm for MagNav, using onboard magnetometers and information-driven methodologies to adjust trajectories based on real-time localization confidence. This approach balances the trade-off between finding the shortest or most energy-efficient routes and reducing localization uncertainty, enhancing navigational accuracy and reliability. The novel algorithm integrates an uncertainty-driven framework with magnetic-based localization, creating a real-time adaptive system capable of minimizing localization errors in complex environments. Extensive simulations and real-world experiments validate the method, demonstrating significant reductions in localization uncertainty and the feasibility of real-time implementation. The paper also details the mathematical modeling of uncertainty, the algorithmic foundation of the planning approach, and the practical implications of using magnetic fields for localization. Future work includes incorporating a global path planner to address the local nature of the current guidance law, further enhancing the method's suitability for long-duration operations.
GPU-Accelerated 3D Polygon Visibility Volumes for Synergistic Perception and Navigation
Feb 05, 2024



UAV missions often require specific geometric constraints to be satisfied between ground locations and the vehicle location. Such requirements are typical for contexts where line-of-sight must be maintained between the vehicle location and the ground control location and are also important in surveillance applications where the UAV wishes to be able to sense, e.g., with a camera sensor, a specific region within a complex geometric environment. This problem is further complicated when the ground location is generalized to a convex 2D polygonal region. This article describes the theory and implementation of a system which can quickly calculate the 3D volume that encloses all 3D coordinates from which a 2D convex planar region can be entirely viewed; referred to as a visibility volume. The proposed approach computes visibility volumes using a combination of depth map computation using GPU-acceleration and geometric boolean operations. Solutions to this problem require complex 3D geometric analysis techniques that must execute using arbitrary precision arithmetic on a collection of discontinuous and non-analytic surfaces. Post-processing steps incorporate navigational constraints to further restrict the enclosed coordinates to include both visibility and navigation constraints. Integration of sensing visibility constraints with navigational constraints yields a range of navigable space where a vehicle will satisfy both perceptual sensing and navigational needs of the mission. This algorithm then provides a synergistic perception and navigation sensitive solution yielding a volume of coordinates in 3D that satisfy both the mission path and sensing needs.
DOMINO++: Domain-aware Loss Regularization for Deep Learning Generalizability
Aug 21, 2023



Out-of-distribution (OOD) generalization poses a serious challenge for modern deep learning (DL). OOD data consists of test data that is significantly different from the model's training data. DL models that perform well on in-domain test data could struggle on OOD data. Overcoming this discrepancy is essential to the reliable deployment of DL. Proper model calibration decreases the number of spurious connections that are made between model features and class outputs. Hence, calibrated DL can improve OOD generalization by only learning features that are truly indicative of the respective classes. Previous work proposed domain-aware model calibration (DOMINO) to improve DL calibration, but it lacks designs for model generalizability to OOD data. In this work, we propose DOMINO++, a dual-guidance and dynamic domain-aware loss regularization focused on OOD generalizability. DOMINO++ integrates expert-guided and data-guided knowledge in its regularization. Unlike DOMINO which imposed a fixed scaling and regularization rate, DOMINO++ designs a dynamic scaling factor and an adaptive regularization rate. Comprehensive evaluations compare DOMINO++ with DOMINO and the baseline model for head tissue segmentation from magnetic resonance images (MRIs) on OOD data. The OOD data consists of synthetic noisy and rotated datasets, as well as real data using a different MRI scanner from a separate site. DOMINO++'s superior performance demonstrates its potential to improve the trustworthy deployment of DL on real clinical data.
Learning Flight Control Systems from Human Demonstrations and Real-Time Uncertainty-Informed Interventions
May 01, 2023



This paper describes a methodology for learning flight control systems from human demonstrations and interventions while considering the estimated uncertainty in the learned models. The proposed approach uses human demonstrations to train an initial model via imitation learning and then iteratively, improve its performance by using real-time human interventions. The aim of the interventions is to correct undesired behaviors and adapt the model to changes in the task dynamics. The learned model uncertainty is estimated in real-time via Monte Carlo Dropout and the human supervisor is cued for intervention via an audiovisual signal when this uncertainty exceeds a predefined threshold. This proposed approach is validated in an autonomous quadrotor landing task on both fixed and moving platforms. It is shown that with this algorithm, a human can rapidly teach a flight task to an unmanned aerial vehicle via demonstrating expert trajectories and then adapt the learned model by intervening when the learned controller performs any undesired maneuver, the task changes, and/or the model uncertainty exceeds a threshold
Photometric Correction for Infrared Sensors
Apr 08, 2023



Infrared thermography has been widely used in several domains to capture and measure temperature distributions across surfaces and objects. This methodology can be further expanded to 3D applications if the spatial distribution of the temperature distribution is available. Structure from Motion (SfM) is a photometric range imaging technique that makes it possible to obtain 3D renderings from a cloud of 2D images. To explore the possibility of 3D reconstruction via SfM from infrared images, this article proposes a photometric correction model for infrared sensors based on temperature constancy. Photometric correction is accomplished by estimating the scene irradiance as the values from the solution to a differential equation for microbolometer pixel excitation with unknown coefficients and initial conditions. The model was integrated into an SfM framework and experimental evaluations demonstrate the contribution of the photometric correction for improving the estimates of both the camera motion and the scene structure. Further, experiments show that the reconstruction quality from the corrected infrared imagery achieves performance on par with state-of-the-art reconstruction using RGB sensors.
DOMINO: Domain-aware Loss for Deep Learning Calibration
Feb 10, 2023

Deep learning has achieved the state-of-the-art performance across medical imaging tasks; however, model calibration is often not considered. Uncalibrated models are potentially dangerous in high-risk applications since the user does not know when they will fail. Therefore, this paper proposes a novel domain-aware loss function to calibrate deep learning models. The proposed loss function applies a class-wise penalty based on the similarity between classes within a given target domain. Thus, the approach improves the calibration while also ensuring that the model makes less risky errors even when incorrect. The code for this software is available at https://github.com/lab-smile/DOMINO.
Incremental cycle bases for cycle-based pose graph optimization
Sep 15, 2022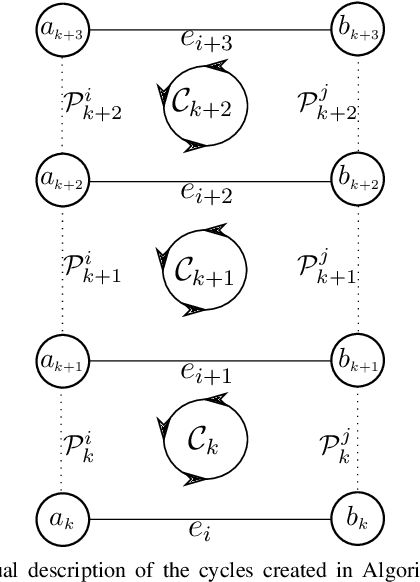
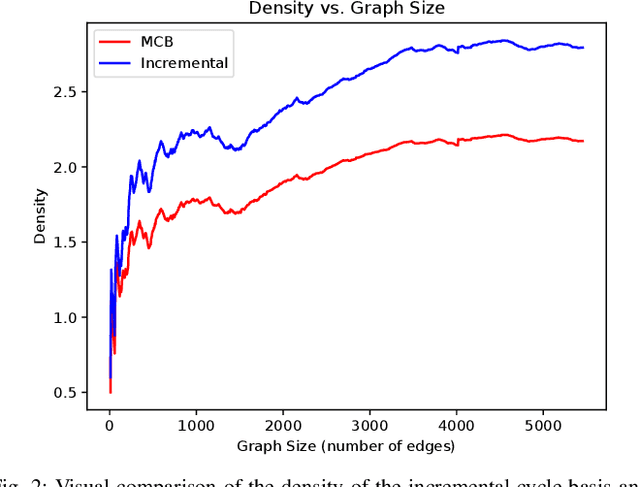
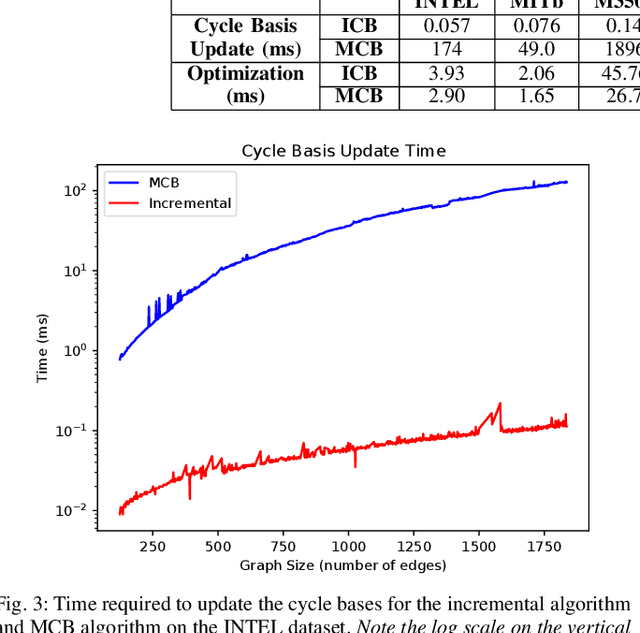
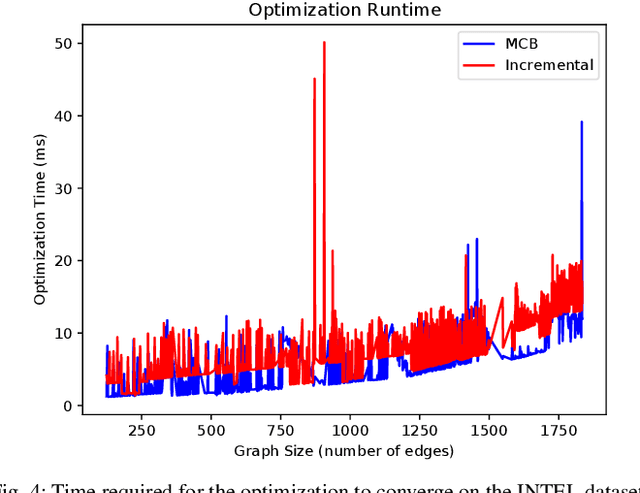
Pose graph optimization is a special case of the simultaneous localization and mapping problem where the only variables to be estimated are pose variables and the only measurements are inter-pose constraints. The vast majority of PGO techniques are vertex based (variables are robot poses), but recent work has parameterized the pose graph optimization problem in a relative fashion (variables are the transformations between poses) that utilizes a minimum cycle basis to maximize the sparsity of the problem. We explore the construction of a cycle basis in an incremental manner while maximizing the sparsity. We validate an algorithm that constructs a sparse cycle basis incrementally and compare its performance with a minimum cycle basis. Additionally, we present an algorithm to approximate the minimum cycle basis of two graphs that are sparsely connected as is common in multi-agent scenarios. Lastly, the relative parameterization of pose graph optimization has been limited to using rigid body transforms on SE(2) or SE(3) as the constraints between poses. We introduce a methodology to allow for the use of lower-degree-of-freedom measurements in the relative pose graph optimization problem. We provide extensive validation of our algorithms on standard benchmarks, simulated datasets, and custom hardware.
DOMINO: Domain-aware Model Calibration in Medical Image Segmentation
Sep 13, 2022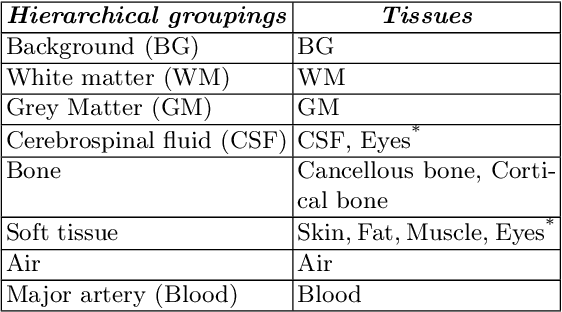
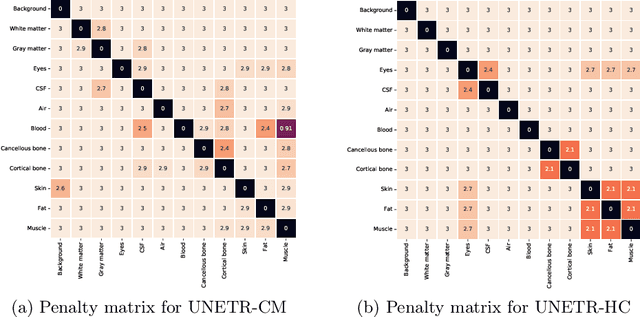
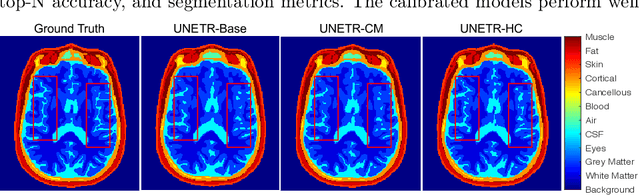
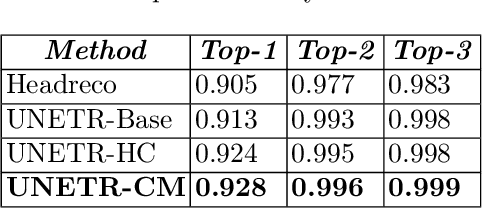
Model calibration measures the agreement between the predicted probability estimates and the true correctness likelihood. Proper model calibration is vital for high-risk applications. Unfortunately, modern deep neural networks are poorly calibrated, compromising trustworthiness and reliability. Medical image segmentation particularly suffers from this due to the natural uncertainty of tissue boundaries. This is exasperated by their loss functions, which favor overconfidence in the majority classes. We address these challenges with DOMINO, a domain-aware model calibration method that leverages the semantic confusability and hierarchical similarity between class labels. Our experiments demonstrate that our DOMINO-calibrated deep neural networks outperform non-calibrated models and state-of-the-art morphometric methods in head image segmentation. Our results show that our method can consistently achieve better calibration, higher accuracy, and faster inference times than these methods, especially on rarer classes. This performance is attributed to our domain-aware regularization to inform semantic model calibration. These findings show the importance of semantic ties between class labels in building confidence in deep learning models. The framework has the potential to improve the trustworthiness and reliability of generic medical image segmentation models. The code for this article is available at: https://github.com/lab-smile/DOMINO.
ROS georegistration: Aerial Multi-spectral Image Simulator for the Robot Operating System
Jan 19, 2022



This article describes a software package called ROS georegistration intended for use with the Robot Operating System (ROS) and the Gazebo 3D simulation environment. ROSgeoregistration provides tools for the simulation, test and deployment of aerial georegistration algorithms and is made available with a link provided in the paper. A model creation package is provided which downloads multi-spectral images from the Google Earth Engine database and, if necessary, incorporates these images into a single, possibly very large, reference image. Additionally a Gazebo plugin which uses the real-time sensor pose and image formation model to generate simulated imagery using the specified reference image is provided along with related plugins for UAV relevant data. The novelty of this work is threefold: (1) this is the first system to link the massive multi-spectral imaging database of Google's Earth Engine to the Gazebo simulator, (2) this is the first example of a system that can simulate geospatially and radiometrically accurate imagery from multiple sensor views of the same terrain region, and (3) integration with other UAS tools creates a new holistic UAS simulation environment to support UAS system and subsystem development where real-world testing would generally be prohibitive. Sensed imagery and ground truth registration information is published to client applications which can receive imagery synchronously with telemetry from other payload sensors, e.g., IMU, GPS/GNSS, barometer, and windspeed sensor data. To highlight functionality, we demonstrate ROSgeoregistration for simulating Electro-Optical (EO) and Synthetic Aperture Radar (SAR) image sensors and an example use case for developing and evaluating image-based UAS position feedback, i.e., pose for image-based Guidance Navigation and Control (GNC) applications.
Deployable, Data-Driven Unmanned Vehicle Navigation System in GPS-Denied, Feature-Deficient Environments
Jan 24, 2021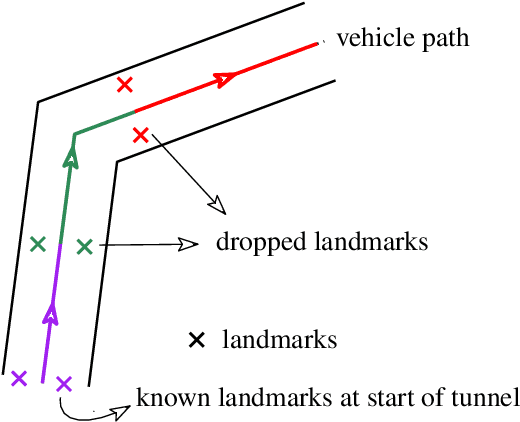
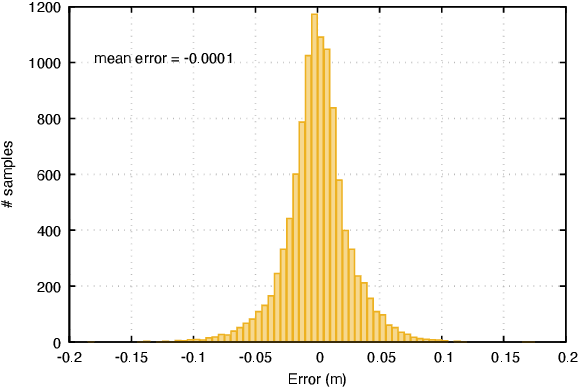
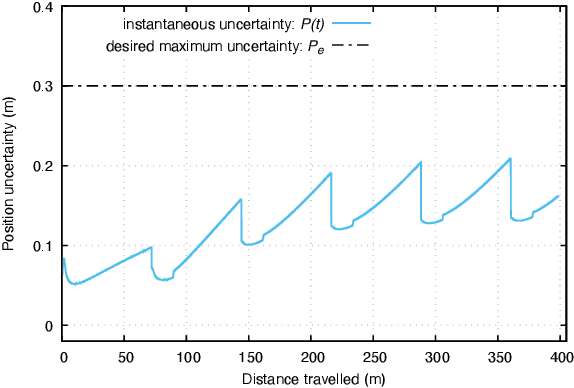
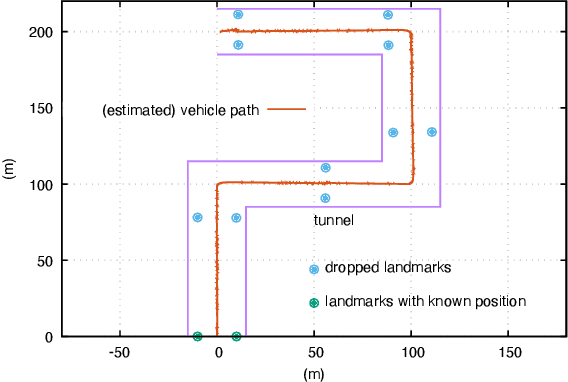
This paper presents a novel data-driven navigation system to navigate an Unmanned Vehicle (UV) in GPS-denied, feature-deficient environments such as tunnels, or mines. The method utilizes Radio Frequency Identification (RFID) tags, also referred to as landmarks, as range sensors that are carried by the vehicle and are deployed in the environment to enable localization as the vehicle traverses its pre-defined path through the tunnel. A key question that arises in such scenario is to estimate and reduce the number of landmarks required for localization before the start of the mission, given some information about the environment. The main constraint of the problem is to keep the maximum uncertainty in the position estimate near a desired value. In this article, we combine techniques from estimation, machine learning, and mixed-integer convex optimization to develop a systematic method to perform localization and navigate the UV through the environment while ensuring minimum number of landmarks are used and all the mission constraints are satisfied.