 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Data-Driven System Identification of 6-DoF Ship Motion in Waves with Neural Networks
Nov 02, 2021
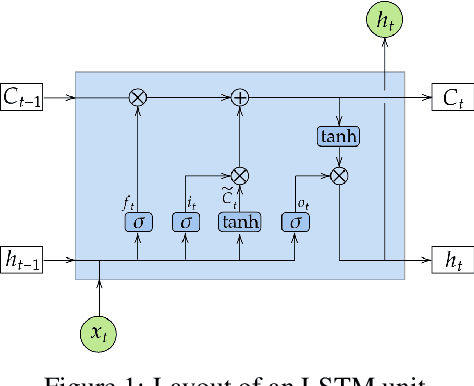

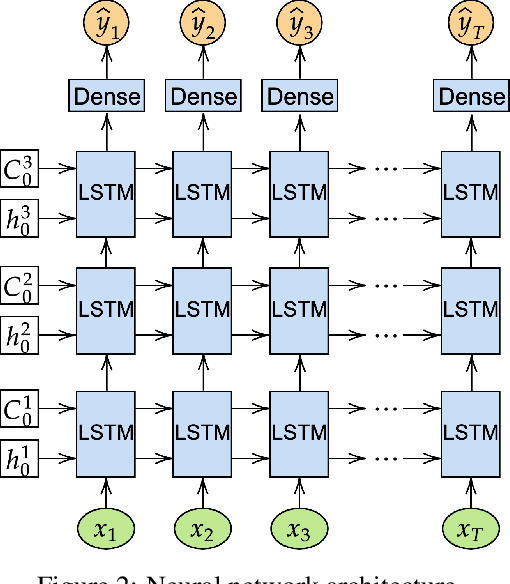

Critical evaluation and understanding of ship responses in the ocean is important for not only the design and engineering of future platforms but also the operation and safety of those that are currently deployed. Simulations or experiments are typically performed in nominal sea conditions during ship design or prior to deployment and the results may not be reflective of the instantaneous state of the vessel and the ocean environment while deployed. Short-term temporal predictions of ship responses given the current wave environment and ship state would enable enhanced decision-making onboard for both manned and unmanned vessels. However, the current state-of-the-art in numerical hydrodynamic simulation tools are too computationally expensive to be employed for real-time ship motion forecasting and the computationally efficient tools are too low fidelity to provide accurate responses. A methodology is developed with long short-term memory (LSTM) neural networks to represent the motions of a free running David Taylor Model Basin (DTMB) 5415 destroyer operating at 20 knots in Sea State 7 stern-quartering irregular seas. Case studies are performed for both course-keeping and turning circle scenarios. An estimate of the vessel's encounter frame is made with the trajectories observed in the training dataset. Wave elevation time histories are given by artificial wave probes that travel with the estimated encounter frame and serve as input into the neural network, while the output is the 6-DOF temporal ship motion response. Overall, the neural network is able to predict the temporal response of the ship due to unseen waves accurately, which makes this methodology suitable for system identification and real-time ship motion forecasting. The methodology, the dependence of model accuracy on wave probe and training data quantity and the estimated encounter frame are all detailed.
Intelligent Traffic Light via Policy-based Deep Reinforcement Learning
Dec 27, 2021
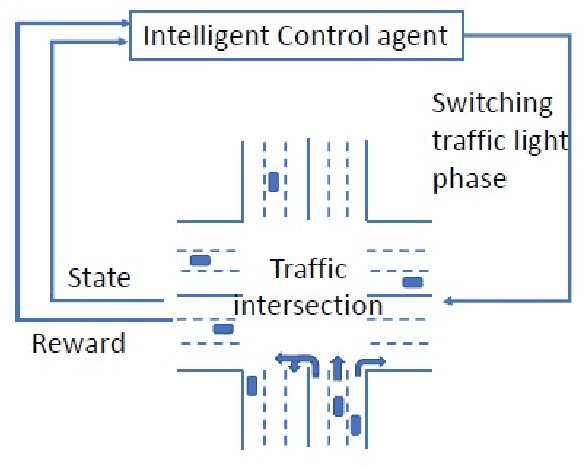

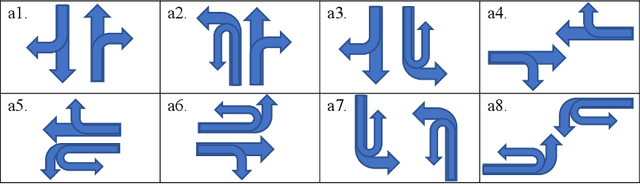
Intelligent traffic lights in smart cities can optimally reduce traffic congestion. In this study, we employ reinforcement learning to train the control agent of a traffic light on a simulator of urban mobility. As a difference from existing works, a policy-based deep reinforcement learning method, Proximal Policy Optimization (PPO), is utilized other than value-based methods such as Deep Q Network (DQN) and Double DQN (DDQN). At first, the obtained optimal policy from PPO is compared to those from DQN and DDQN. It is found that the policy from PPO performs better than the others. Next, instead of the fixed-interval traffic light phases, we adopt the light phases with variable time intervals, which result in a better policy to pass the traffic flow. Then, the effects of environment and action disturbances are studied to demonstrate the learning-based controller is robust. At last, we consider unbalanced traffic flows and find that an intelligent traffic light can perform moderately well for the unbalanced traffic scenarios, although it learns the optimal policy from the balanced traffic scenarios only.
Real-time CNN-based Segmentation Architecture for Ball Detection in a Single View Setup
Jul 23, 2020
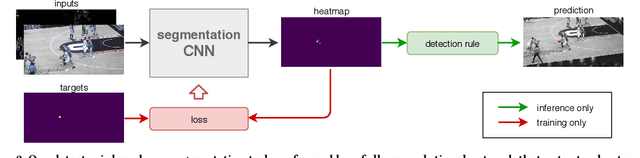
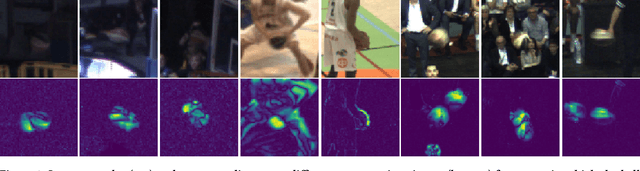
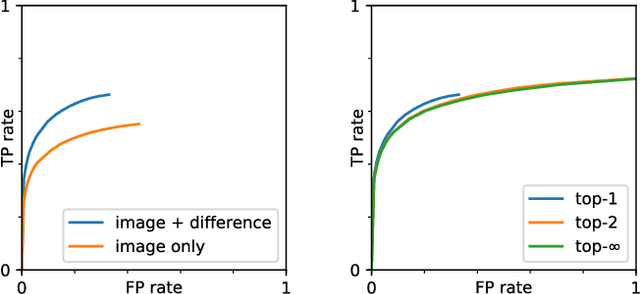
This paper considers the task of detecting the ball from a single viewpoint in the challenging but common case where the ball interacts frequently with players while being poorly contrasted with respect to the background. We propose a novel approach by formulating the problem as a segmentation task solved by an efficient CNN architecture. To take advantage of the ball dynamics, the network is fed with a pair of consecutive images. Our inference model can run in real time without the delay induced by a temporal analysis. We also show that test-time data augmentation allows for a significant increase the detection accuracy. As an additional contribution, we publicly release the dataset on which this work is based.
* 8 pages, 10 figures
Arm order recognition in multi-armed bandit problem with laser chaos time series
May 26, 2020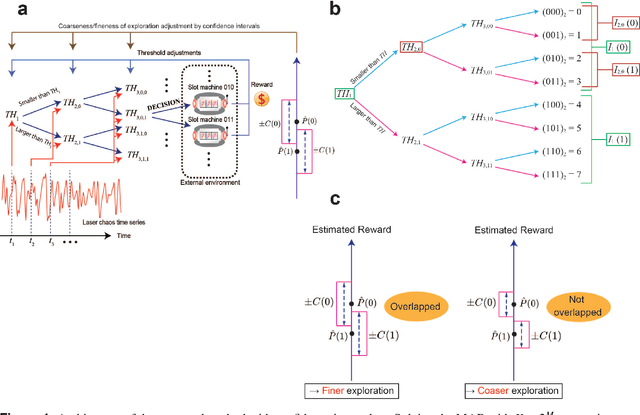
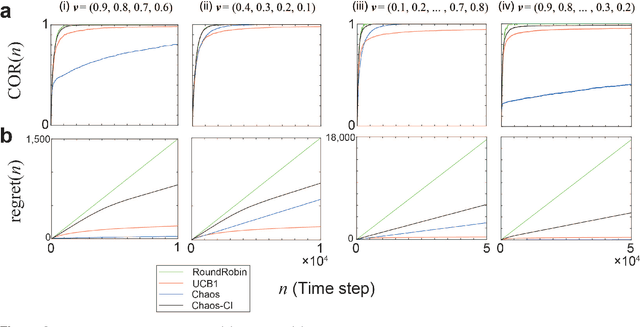
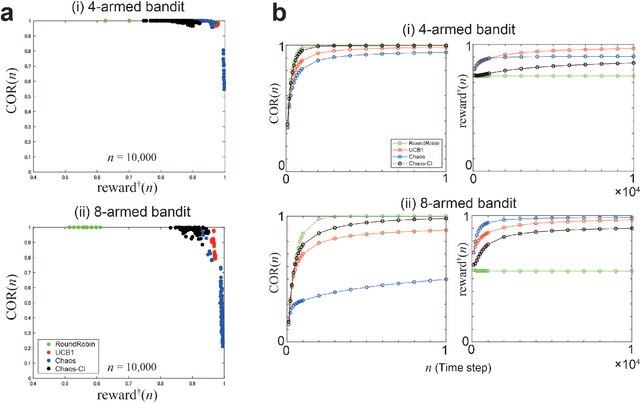
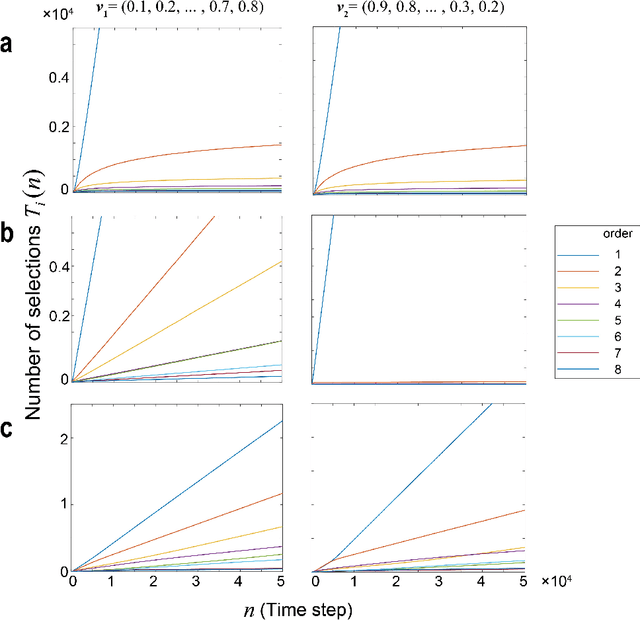
By exploiting ultrafast and irregular time series generated by lasers with delayed feedback, we have previously demonstrated a scalable algorithm to solve multi-armed bandit (MAB) problems utilizing the time-division multiplexing of laser chaos time series. Although the algorithm detects the arm with the highest reward expectation, the correct recognition of the order of arms in terms of reward expectations is not achievable. Here, we present an algorithm where the degree of exploration is adaptively controlled based on confidence intervals that represent the estimation accuracy of reward expectations. We have demonstrated numerically that our approach did improve arm order recognition accuracy significantly, along with reduced dependence on reward environments, and the total reward is almost maintained compared with conventional MAB methods. This study applies to sectors where the order information is critical, such as efficient allocation of resources in information and communications technology.
Robust Ambient Backscatter Communications with Polarization Reconfigurable Tags
Nov 02, 2021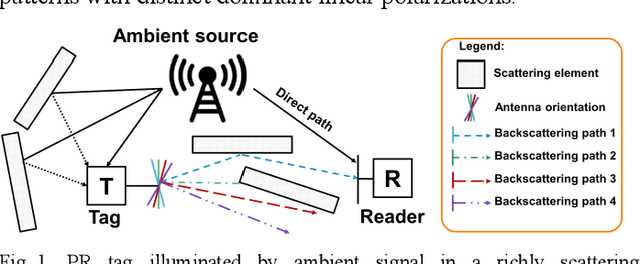
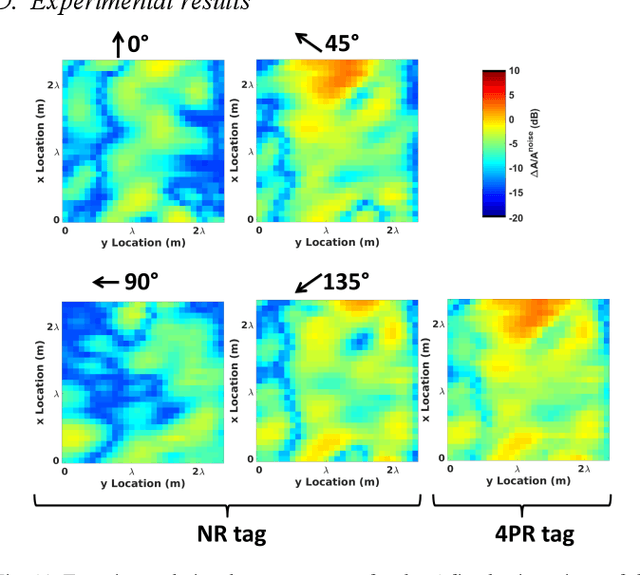
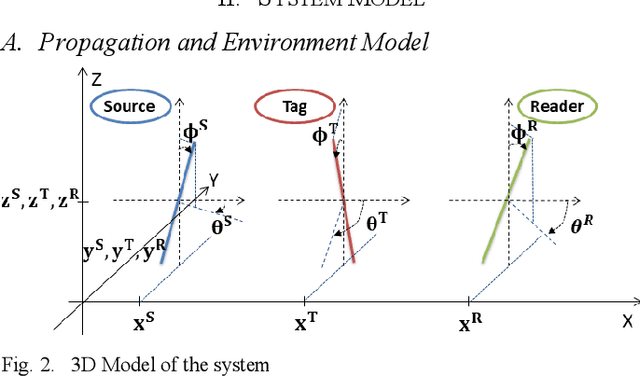
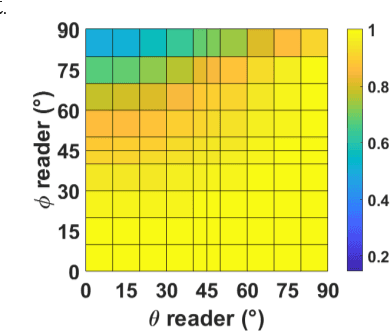
Ambient backscatter communication system is an emerging and promising low-energy technology for Internet of Things. In such system, a device named tag, sends a binary message to a reader by backscattering a radio frequency signal generated by an ambient source. Such tag can operate without battery and without generating additional wave. However, the tag-to-reader link suffers from the source-to-reader direct interference. In this paper, for the first time, we propose to exploit a "polarization reconfigurable" antenna to improve robustness of the tag-to-reader link against the source-to-reader direct interference. Our proposed new tag sends its message by backscattering as an usual tag. However, it repeats its message several times, with a different radiation pattern and polarization, each time. We expect one polarization pattern to be better detected by the reader. We show by simulations and experiments, in line-of-sight and in richly scattering environment, that a polarization reconfigurable tag limited to 4 polarization directions outperforms a nonreconfigurable tag and nearly equals an ideally reconfigurable tag in performance.
Training BatchNorm Only in Neural Architecture Search and Beyond
Dec 01, 2021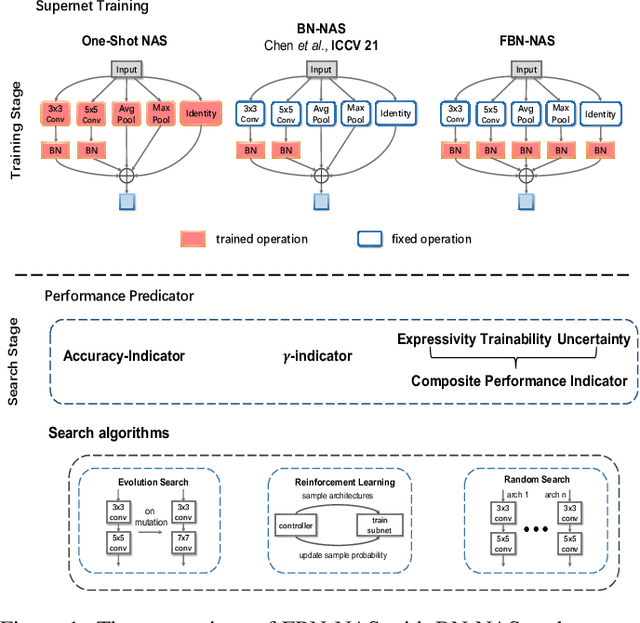

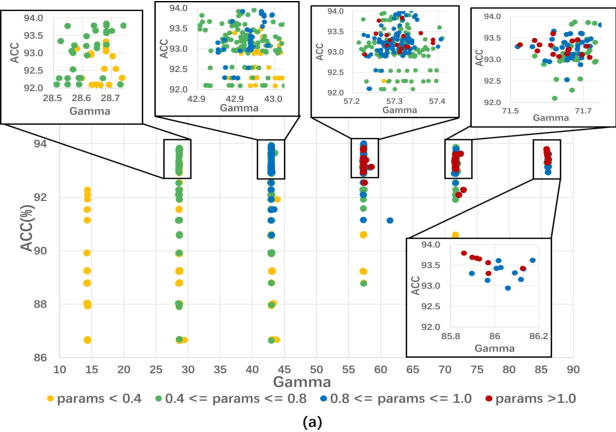
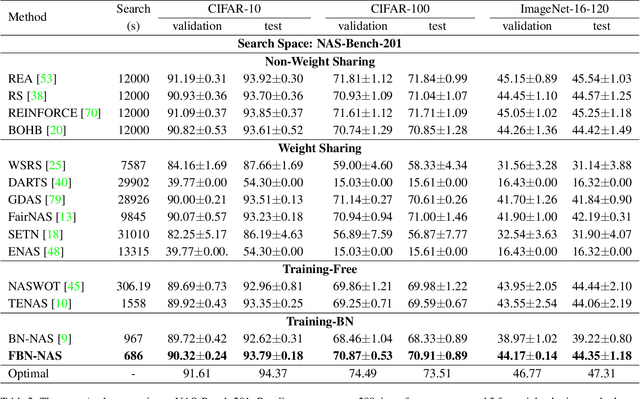
This work investigates the usage of batch normalization in neural architecture search (NAS). Specifically, Frankle et al. find that training BatchNorm only can achieve nontrivial performance. Furthermore, Chen et al. claim that training BatchNorm only can speed up the training of the one-shot NAS supernet over ten times. Critically, there is no effort to understand 1) why training BatchNorm only can find the perform-well architectures with the reduced supernet-training time, and 2) what is the difference between the train-BN-only supernet and the standard-train supernet. We begin by showing that the train-BN-only networks converge to the neural tangent kernel regime, obtain the same training dynamics as train all parameters theoretically. Our proof supports the claim to train BatchNorm only on supernet with less training time. Then, we empirically disclose that train-BN-only supernet provides an advantage on convolutions over other operators, cause unfair competition between architectures. This is due to only the convolution operator being attached with BatchNorm. Through experiments, we show that such unfairness makes the search algorithm prone to select models with convolutions. To solve this issue, we introduce fairness in the search space by placing a BatchNorm layer on every operator. However, we observe that the performance predictor in Chen et al. is inapplicable on the new search space. To this end, we propose a novel composite performance indicator to evaluate networks from three perspectives: expressivity, trainability, and uncertainty, derived from the theoretical property of BatchNorm. We demonstrate the effectiveness of our approach on multiple NAS-benchmarks (NAS-Bench101, NAS-Bench-201) and search spaces (DARTS search space and MobileNet search space).
Inference, Prediction, and Entropy-Rate Estimation of Continuous-time, Discrete-event Processes
May 07, 2020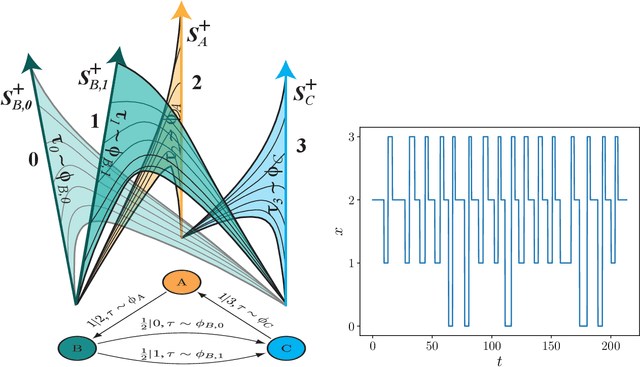
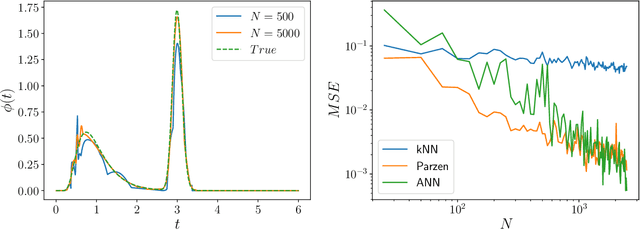
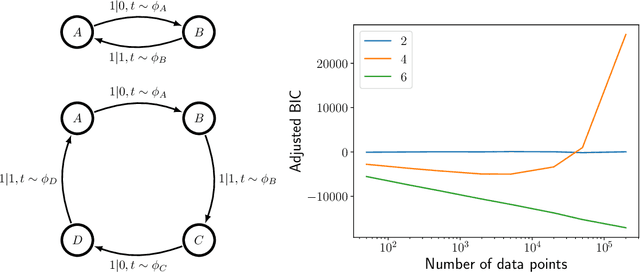
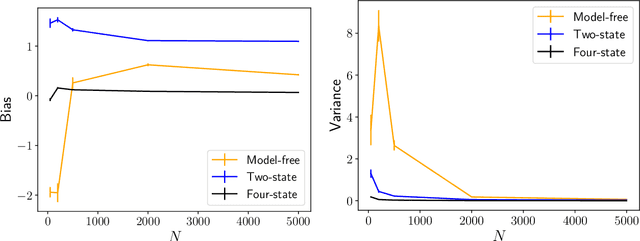
Inferring models, predicting the future, and estimating the entropy rate of discrete-time, discrete-event processes is well-worn ground. However, a much broader class of discrete-event processes operates in continuous-time. Here, we provide new methods for inferring, predicting, and estimating them. The methods rely on an extension of Bayesian structural inference that takes advantage of neural network's universal approximation power. Based on experiments with complex synthetic data, the methods are competitive with the state-of-the-art for prediction and entropy-rate estimation.
PAMMELA: Policy Administration Methodology using Machine Learning
Nov 13, 2021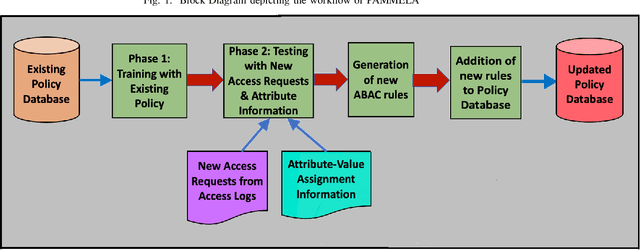
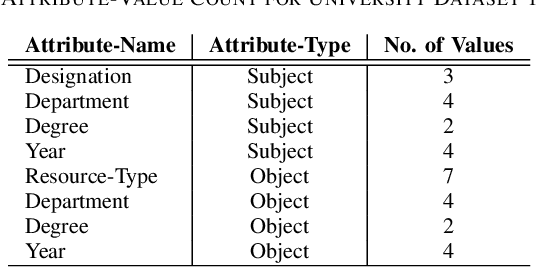
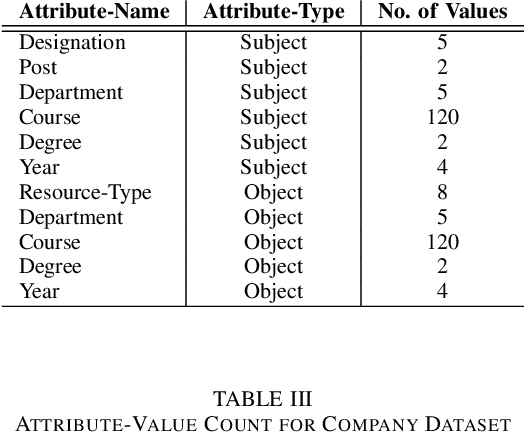
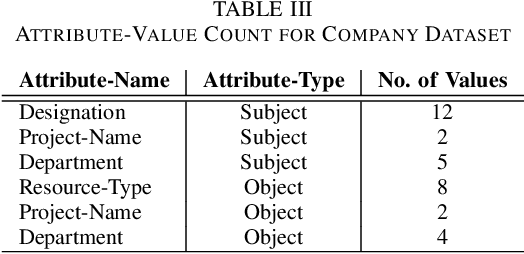
In recent years, Attribute-Based Access Control (ABAC) has become quite popular and effective for enforcing access control in dynamic and collaborative environments. Implementation of ABAC requires the creation of a set of attribute-based rules which cumulatively form a policy. Designing an ABAC policy ab initio demands a substantial amount of effort from the system administrator. Moreover, organizational changes may necessitate the inclusion of new rules in an already deployed policy. In such a case, re-mining the entire ABAC policy will require a considerable amount of time and administrative effort. Instead, it is better to incrementally augment the policy. Keeping these aspects of reducing administrative overhead in mind, in this paper, we propose PAMMELA, a Policy Administration Methodology using Machine Learning to help system administrators in creating new ABAC policies as well as augmenting existing ones. PAMMELA can generate a new policy for an organization by learning the rules of a policy currently enforced in a similar organization. For policy augmentation, PAMMELA can infer new rules based on the knowledge gathered from the existing rules. Experimental results show that our proposed approach provides a reasonably good performance in terms of the various machine learning evaluation metrics as well as execution time.
NFTGAN: Non-Fungible Token Art Generation Using Generative Adversarial Networks
Dec 27, 2021


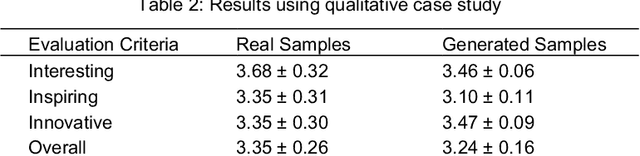
Digital arts have gained an unprecedented level of popularity with the emergence of non-fungible tokens (NFTs). NFTs are cryptographic assets that are stored on blockchain networks and represent a digital certificate of ownership that cannot be forged. NFTs can be incorporated into a smart contract which allows the owner to benefit from a future sale percentage. While digital art producers can benefit immensely with NFTs, their production is time consuming. Therefore, this paper explores the possibility of using generative adversarial networks (GANs) for automatic generation of digital arts. GANs are deep learning architectures that are widely and effectively used for synthesis of audio, images, and video contents. However, their application to NFT arts have been limited. In this paper, a GAN-based architecture is implemented and evaluated for novel NFT-style digital arts generation. Results from the qualitative case study indicate that the generated artworks are comparable to the real samples in terms of being interesting and inspiring and they were judged to be more innovative than real samples.
SiamPolar: Semi-supervised Realtime Video Object Segmentation with Polar Representation
Oct 27, 2021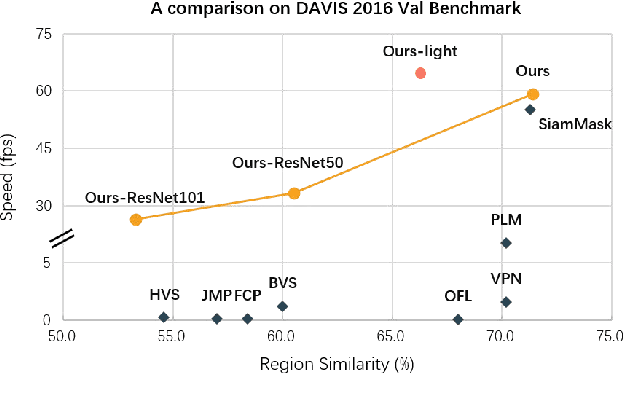
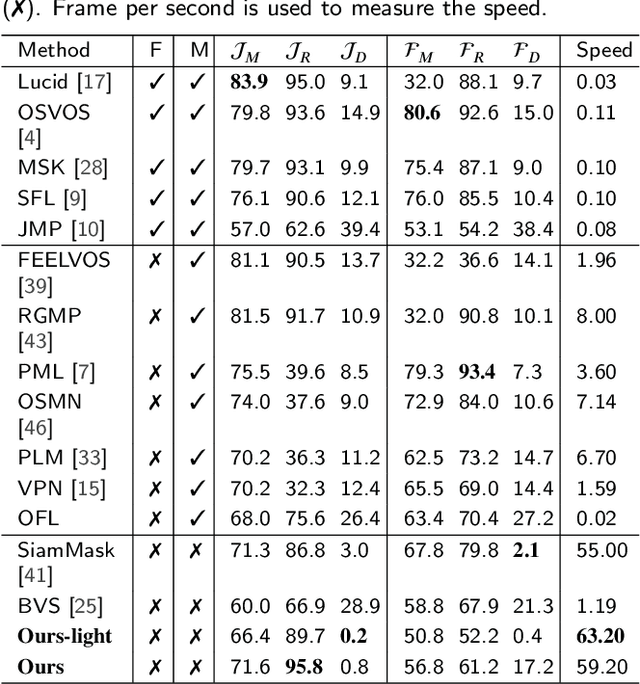
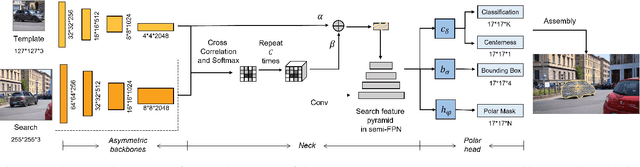
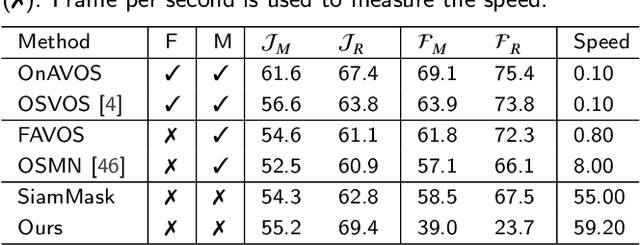
Video object segmentation (VOS) is an essential part of autonomous vehicle navigation. The real-time speed is very important for the autonomous vehicle algorithms along with the accuracy metric. In this paper, we propose a semi-supervised real-time method based on the Siamese network using a new polar representation. The input of bounding boxes is initialized rather than the object masks, which are applied to the video object detection tasks. The polar representation could reduce the parameters for encoding masks with subtle accuracy loss so that the algorithm speed can be improved significantly. An asymmetric siamese network is also developed to extract the features from different spatial scales. Moreover, the peeling convolution is proposed to reduce the antagonism among the branches of the polar head. The repeated cross-correlation and semi-FPN are designed based on this idea. The experimental results on the DAVIS-2016 dataset and other public datasets demonstrate the effectiveness of the proposed method.
* 11 pages, 11 figures, journal