 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-time Monocular Depth Estimation with Sparse Supervision on Mobile
May 25, 2021
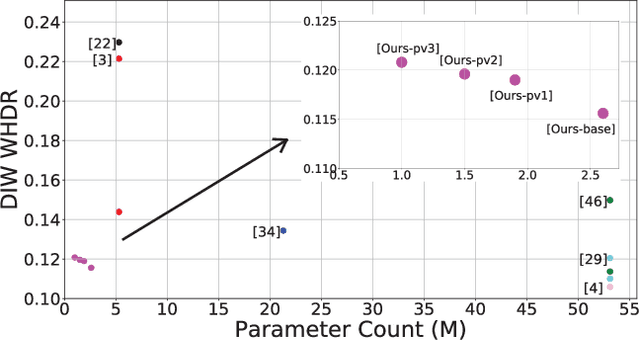
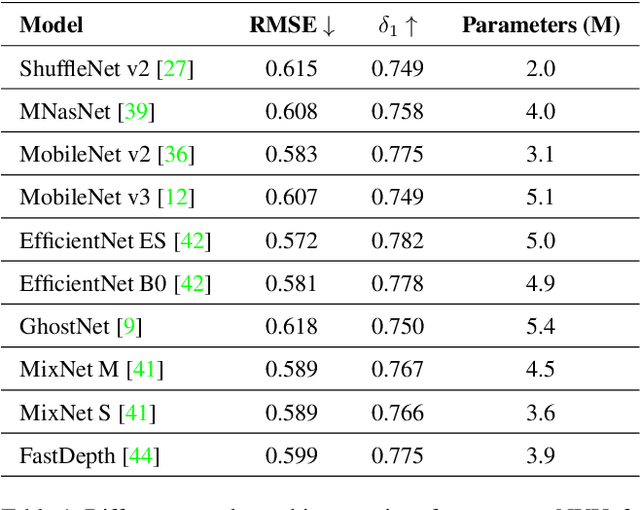
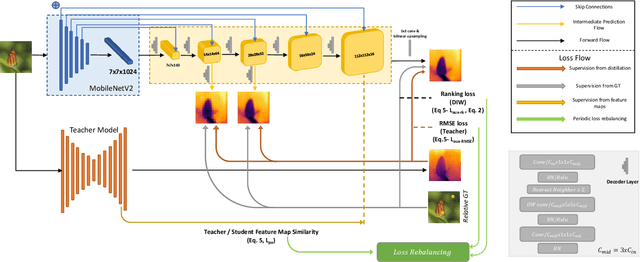
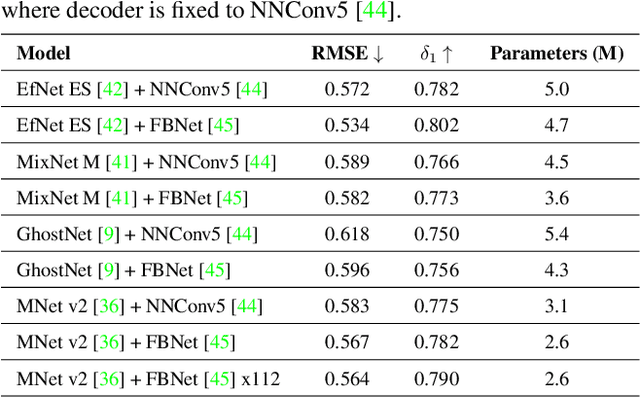
Monocular (relative or metric) depth estimation is a critical task for various applications, such as autonomous vehicles, augmented reality and image editing. In recent years, with the increasing availability of mobile devices, accurate and mobile-friendly depth models have gained importance. Increasingly accurate models typically require more computational resources, which inhibits the use of such models on mobile devices. The mobile use case is arguably the most unrestricted one, which requires highly accurate yet mobile-friendly architectures. Therefore, we try to answer the following question: How can we improve a model without adding further complexity (i.e. parameters)? Towards this end, we systematically explore the design space of a relative depth estimation model from various dimensions and we show, with key design choices and ablation studies, even an existing architecture can reach highly competitive performance to the state of the art, with a fraction of the complexity. Our study spans an in-depth backbone model selection process, knowledge distillation, intermediate predictions, model pruning and loss rebalancing. We show that our model, using only DIW as the supervisory dataset, achieves 0.1156 WHDR on DIW with 2.6M parameters and reaches 37 FPS on a mobile GPU, without pruning or hardware-specific optimization. A pruned version of our model achieves 0.1208 WHDR on DIW with 1M parameters and reaches 44 FPS on a mobile GPU.
Unsupervised Domain Adaptation for Constraining Star Formation Histories
Dec 28, 2021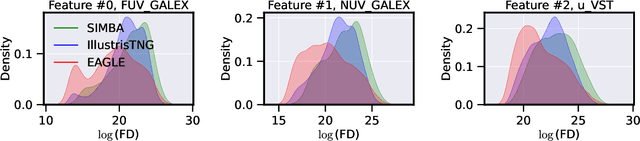
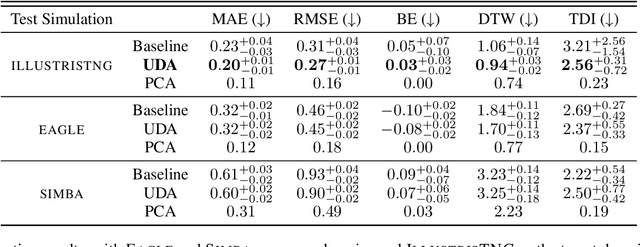
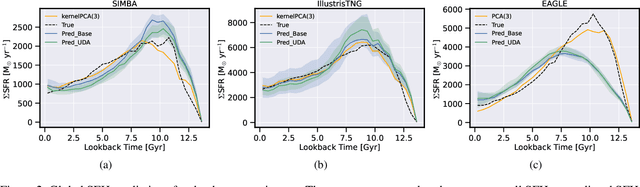
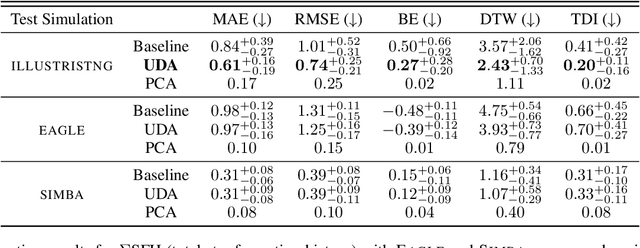
The prevalent paradigm of machine learning today is to use past observations to predict future ones. What if, however, we are interested in knowing the past given the present? This situation is indeed one that astronomers must contend with often. To understand the formation of our universe, we must derive the time evolution of the visible mass content of galaxies. However, to observe a complete star life, one would need to wait for one billion years! To overcome this difficulty, astrophysicists leverage supercomputers and evolve simulated models of galaxies till the current age of the universe, thus establishing a mapping between observed radiation and star formation histories (SFHs). Such ground-truth SFHs are lacking for actual galaxy observations, where they are usually inferred -- with often poor confidence -- from spectral energy distributions (SEDs) using Bayesian fitting methods. In this investigation, we discuss the ability of unsupervised domain adaptation to derive accurate SFHs for galaxies with simulated data as a necessary first step in developing a technique that can ultimately be applied to observational data.
LSTM Architecture for Oil Stocks Prices Prediction
Jan 02, 2022
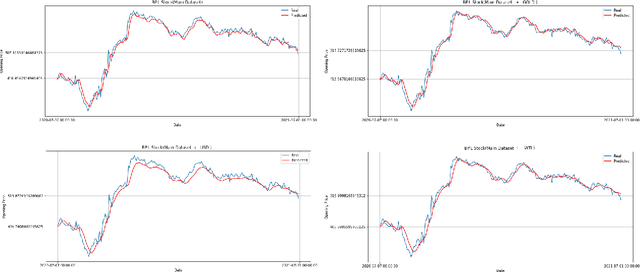
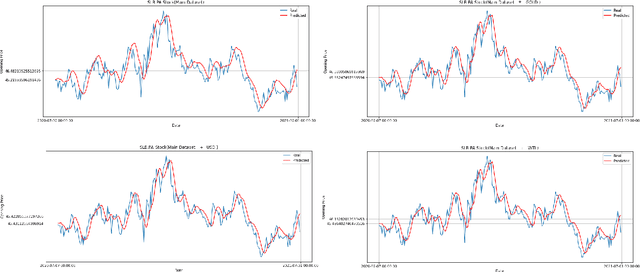
Oil companies are among the largest companies in the world whose economic indicators in the global stock market have a great impact on the world economy and market due to their relation to gold, crude oil, and the dollar. To quantify these relations we use the correlation feature and the relationships between stocks with the dollar, crude oil, gold, and major oil company stock indices, we create datasets and compare the results of forecasts with real data. To predict the stocks of different companies, we use Recurrent Neural Networks (RNNs) and LSTM, because these stocks change in time series. We carry on empirical experiments and perform on the stock indices dataset to evaluate the prediction performance in terms of several common error metrics such as Mean Square Error (MSE), Mean Absolute Error (MAE), Root Mean Square Error (RMSE), and Mean Absolute Percentage Error (MAPE). The received results are promising and present a reasonably accurate prediction for the price of oil companies' stocks in the near future. The results show that RNNs do not have the interpretability, and we cannot improve the model by adding any correlated data.
Memetic Search for Vehicle Routing with Simultaneous Pickup-Delivery and Time Windows
Nov 19, 2020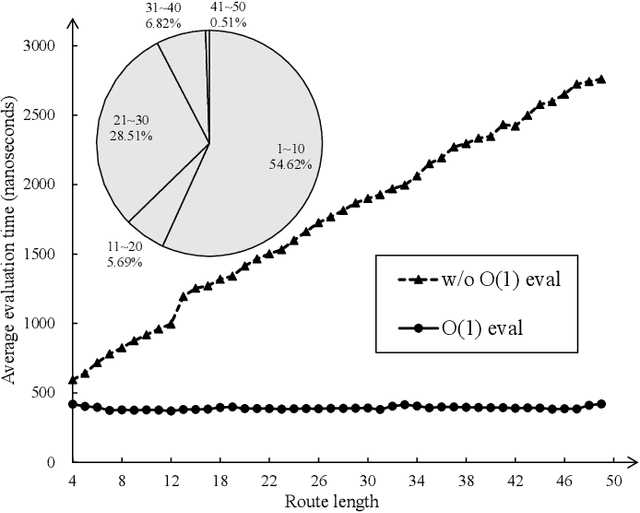
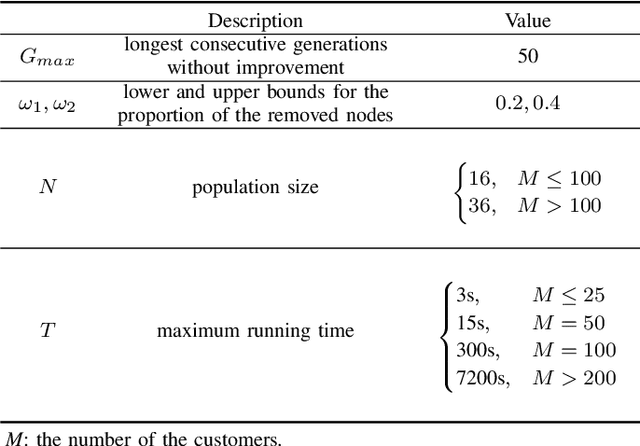
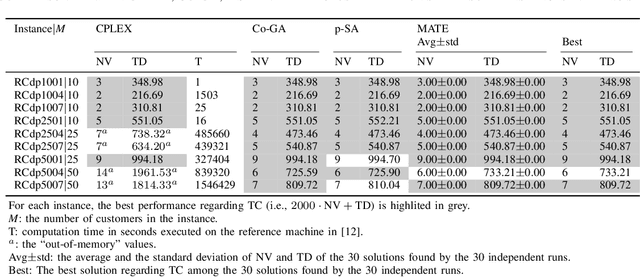
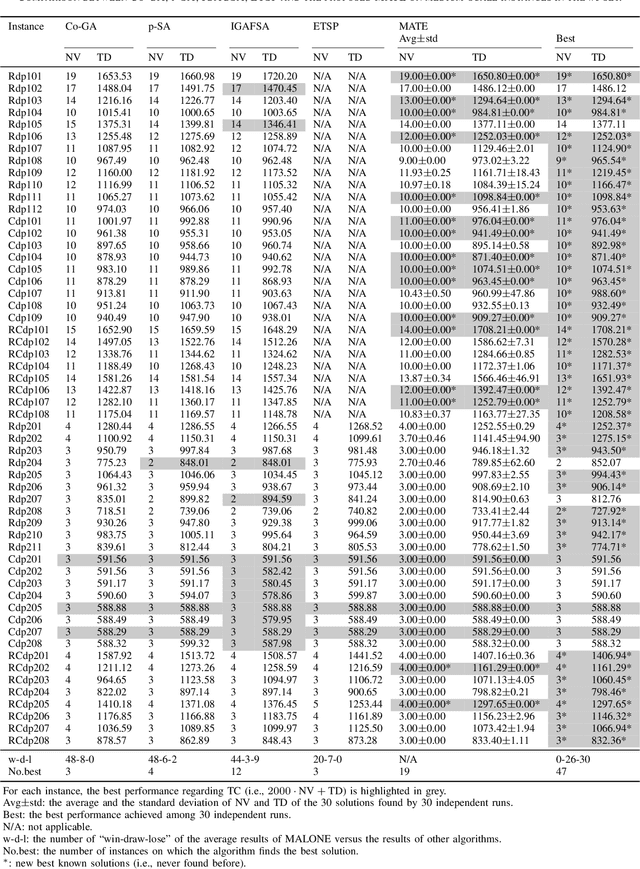
The vehicle routing problem with simultaneous pickup-delivery and time windows (VRPSPDTW) has attracted much attention in the last decade, due to its wide application in modern logistics involving bi-directional flow of goods. In this paper, we propose a memetic algorithm with efficient local search and extended neighborhood, dubbed MATE, for solving this problem. The novelty of MATE lies in three aspects: 1) an initialization procedure which integrates an existing heuristic into the population-based search framework, in an intelligent way; 2) a new crossover involving route inheritance and regret-based node reinsertion; 3) a highly-effective local search procedure which could flexibly search in a large neighborhood by switching between move operators with different step sizes, while keeping low computational complexity. Experimental results on public benchmark show that MATE consistently outperforms all the state-of-the-art algorithms, and notably, finds new best-known solutions on 44 instances (65 instances in total). A new benchmark of large-scale instances, derived from a real-world application of the JD logistics, is also introduced, which could serve as a new and more practical test set for future research.
IterMVS: Iterative Probability Estimation for Efficient Multi-View Stereo
Dec 09, 2021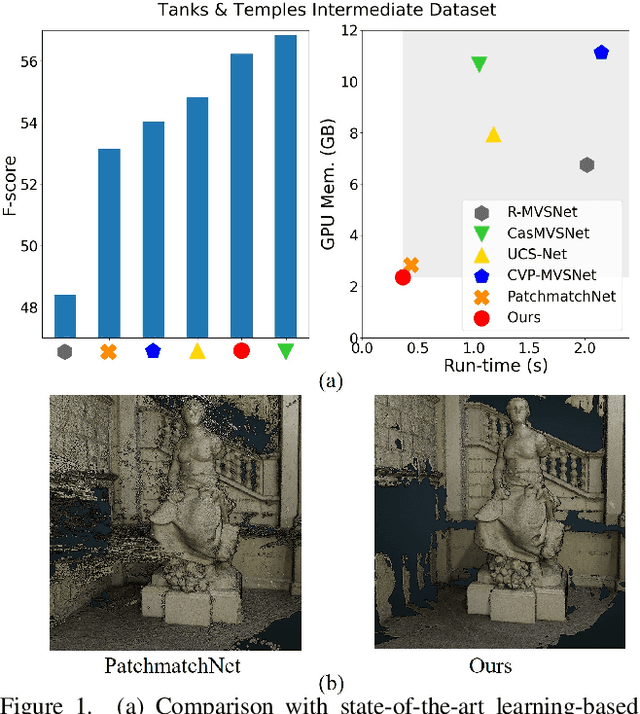
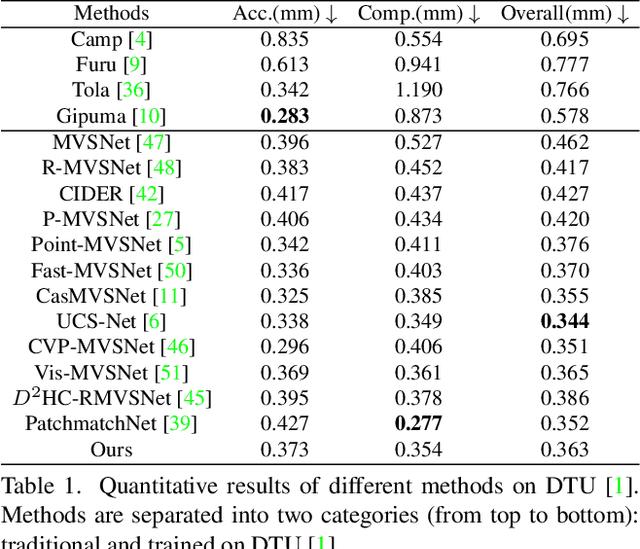

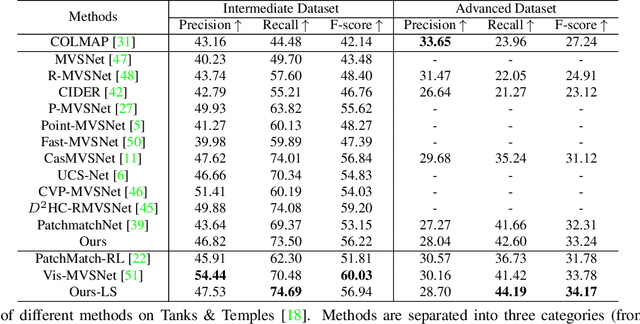
We present IterMVS, a new data-driven method for high-resolution multi-view stereo. We propose a novel GRU-based estimator that encodes pixel-wise probability distributions of depth in its hidden state. Ingesting multi-scale matching information, our model refines these distributions over multiple iterations and infers depth and confidence. To extract the depth maps, we combine traditional classification and regression in a novel manner. We verify the efficiency and effectiveness of our method on DTU, Tanks&Temples and ETH3D. While being the most efficient method in both memory and run-time, our model achieves competitive performance on DTU and better generalization ability on Tanks&Temples as well as ETH3D than most state-of-the-art methods. Code is available at https://github.com/FangjinhuaWang/IterMVS.
A Survey on Principles, Models and Methods for Learning from Irregularly Sampled Time Series: From Discretization to Attention and Invariance
Nov 30, 2020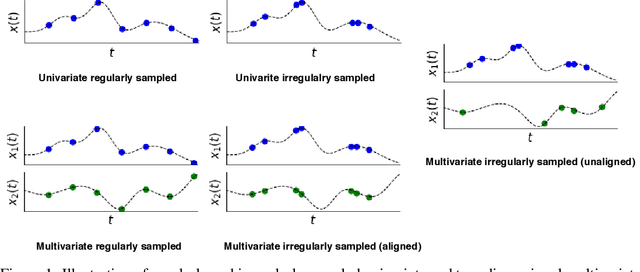
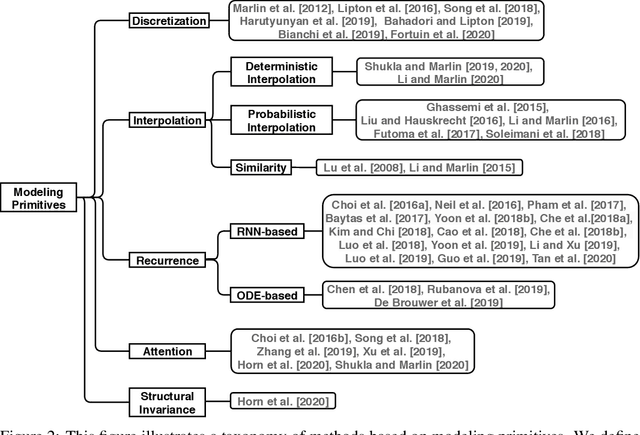
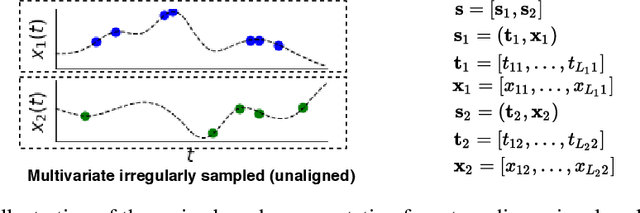
Irregularly sampled time series data arise naturally in many application domains including biology, ecology, climate science, astronomy, and health. Such data represent fundamental challenges to many classical models from machine learning and statistics due to the presence of non-uniform intervals between observations. However, there has been significant progress within the machine learning community over the last decade on developing specialized models and architectures for learning from irregularly sampled univariate and multivariate time series data. In this survey, we first describe several axes along which approaches differ including what data representations they are based on, what modeling primitives they leverage to deal with the fundamental problem of irregular sampling, and what inference tasks they are designed to perform. We then survey the recent literature organized primarily along the axis of modeling primitives. We describe approaches based on temporal discretization, interpolation, recurrence, attention, and structural invariance. We discuss similarities and differences between approaches and highlight primary strengths and weaknesses.
Self-checking Logical Agents
Nov 09, 2021
This paper presents a comprehensive framework for run-time self-checking of logical agents, by means of temporal axioms to be dynamically checked. These axioms are specified by using an agent-oriented interval temporal logic defined to this purpose. We define syntax, semantics and pragmatics for this new logic, specifically tailored for application to agents. In the resulting framework, we encompass and extend our past work.
* Proceedings currently not available on the web
Continual learning of longitudinal health records
Dec 22, 2021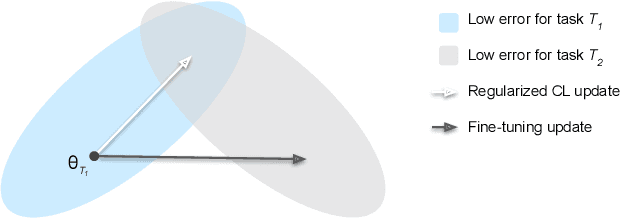
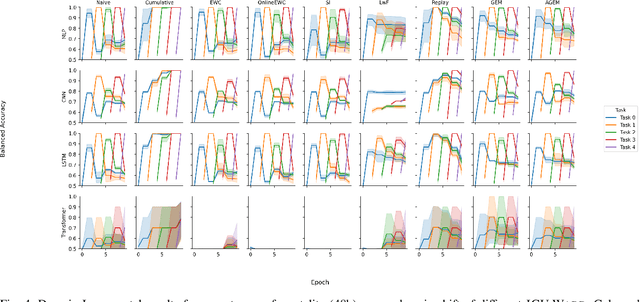
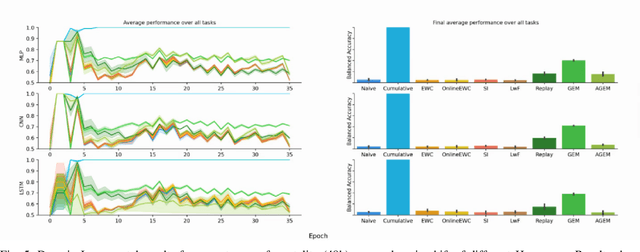
Continual learning denotes machine learning methods which can adapt to new environments while retaining and reusing knowledge gained from past experiences. Such methods address two issues encountered by models in non-stationary environments: ungeneralisability to new data, and the catastrophic forgetting of previous knowledge when retrained. This is a pervasive problem in clinical settings where patient data exhibits covariate shift not only between populations, but also continuously over time. However, while continual learning methods have seen nascent success in the imaging domain, they have been little applied to the multi-variate sequential data characteristic of critical care patient recordings. Here we evaluate a variety of continual learning methods on longitudinal ICU data in a series of representative healthcare scenarios. We find that while several methods mitigate short-term forgetting, domain shift remains a challenging problem over large series of tasks, with only replay based methods achieving stable long-term performance. Code for reproducing all experiments can be found at https://github.com/iacobo/continual
Testing network correlation efficiently via counting trees
Oct 22, 2021

We propose a new procedure for testing whether two networks are edge-correlated through some latent vertex correspondence. The test statistic is based on counting the co-occurrences of signed trees for a family of non-isomorphic trees. When the two networks are Erd\H{o}s-R\'enyi random graphs $\mathcal{G}(n,q)$ that are either independent or correlated with correlation coefficient $\rho$, our test runs in $n^{2+o(1)}$ time and succeeds with high probability as $n\to\infty$, provided that $n\min\{q,1-q\} \ge n^{-o(1)}$ and $\rho^2>\alpha \approx 0.338$, where $\alpha$ is Otter's constant so that the number of unlabeled trees with $K$ edges grows as $(1/\alpha)^K$. This significantly improves the prior work in terms of statistical accuracy, running time, and graph sparsity.
Agricultural Plant Cataloging and Establishment of a Data Framework from UAV-based Crop Images by Computer Vision
Jan 11, 2022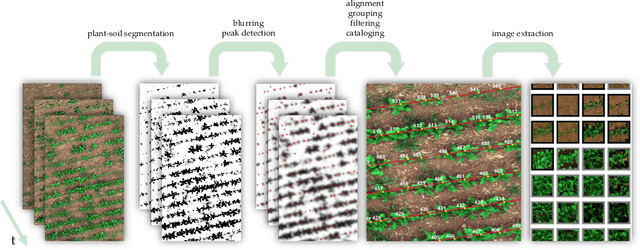


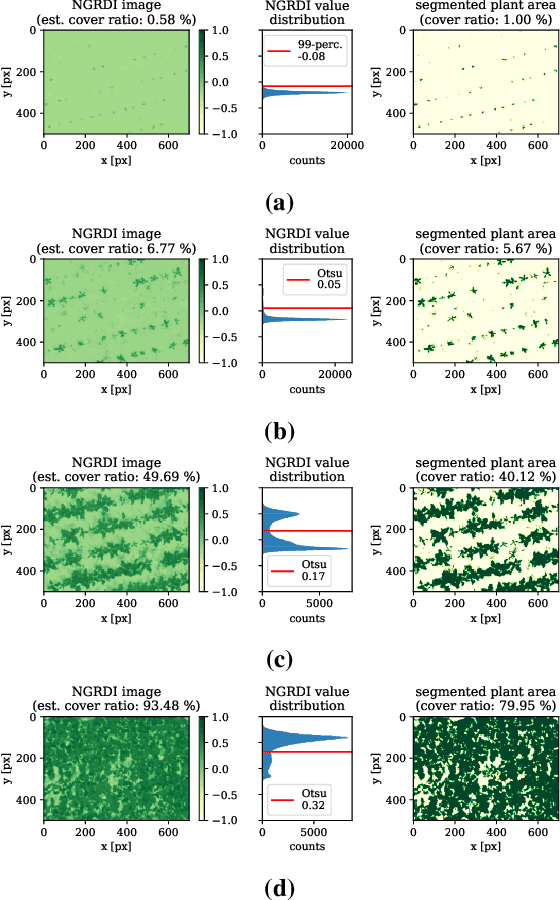
UAV-based image retrieval in modern agriculture enables gathering large amounts of spatially referenced crop image data. In large-scale experiments, however, UAV images suffer from containing a multitudinous amount of crops in a complex canopy architecture. Especially for the observation of temporal effects, this complicates the recognition of individual plants over several images and the extraction of relevant information tremendously. In this work, we present a hands-on workflow for the automatized temporal and spatial identification and individualization of crop images from UAVs abbreviated as "cataloging" based on comprehensible computer vision methods. We evaluate the workflow on two real-world datasets. One dataset is recorded for observation of Cercospora leaf spot - a fungal disease - in sugar beet over an entire growing cycle. The other one deals with harvest prediction of cauliflower plants. The plant catalog is utilized for the extraction of single plant images seen over multiple time points. This gathers large-scale spatio-temporal image dataset that in turn can be applied to train further machine learning models including various data layers. The presented approach improves analysis and interpretation of UAV data in agriculture significantly. By validation with some reference data, our method shows an accuracy that is similar to more complex deep learning-based recognition techniques. Our workflow is able to automatize plant cataloging and training image extraction, especially for large datasets.