 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Polyphonic audio event detection: multi-label or multi-class multi-task classification problem?
Jan 29, 2022
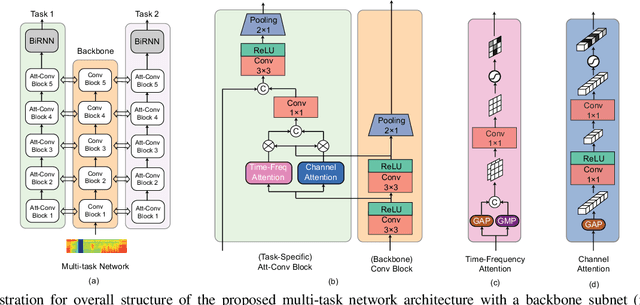
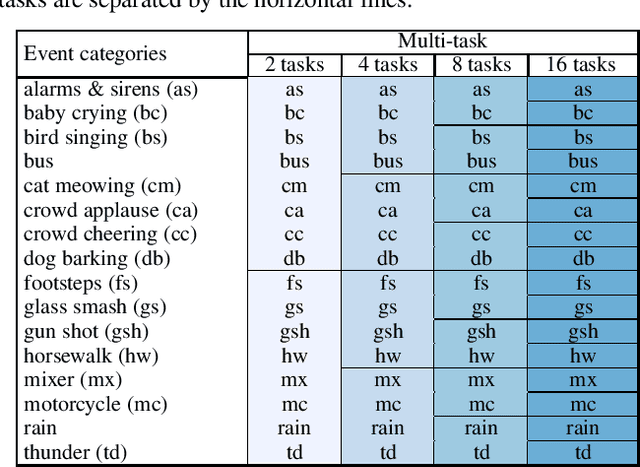
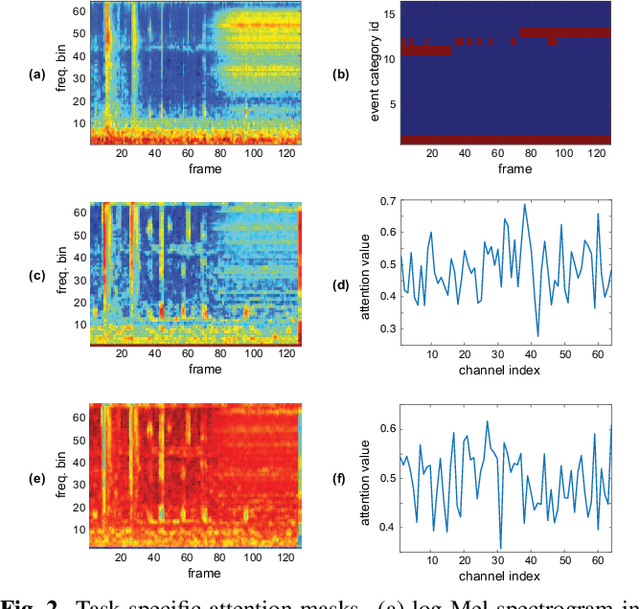
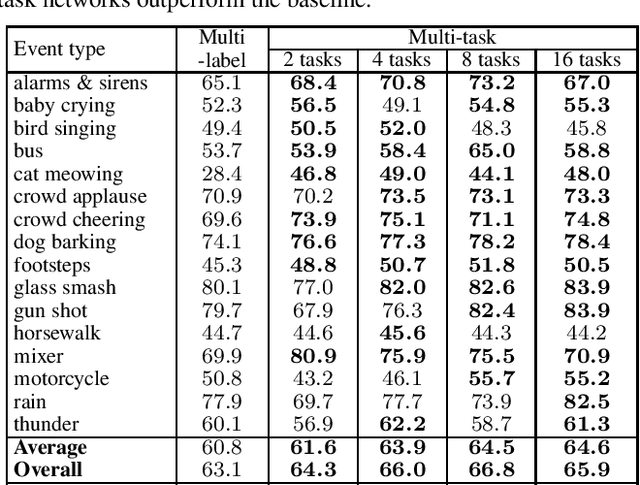
Polyphonic events are the main error source of audio event detection (AED) systems. In deep-learning context, the most common approach to deal with event overlaps is to treat the AED task as a multi-label classification problem. By doing this, we inherently consider multiple one-vs.-rest classification problems, which are jointly solved by a single (i.e. shared) network. In this work, to better handle polyphonic mixtures, we propose to frame the task as a multi-class classification problem by considering each possible label combination as one class. To circumvent the large number of arising classes due to combinatorial explosion, we divide the event categories into multiple groups and construct a multi-task problem in a divide-and-conquer fashion, where each of the tasks is a multi-class classification problem. A network architecture is then devised for multi-class multi-task modelling. The network is composed of a backbone subnet and multiple task-specific subnets. The task-specific subnets are designed to learn time-frequency and channel attention masks to extract features for the task at hand from the common feature maps learned by the backbone. Experiments on the TUT-SED-Synthetic-2016 with high degree of event overlap show that the proposed approach results in more favorable performance than the common multi-label approach.
A Time Attention based Fraud Transaction Detection Framework
Dec 26, 2019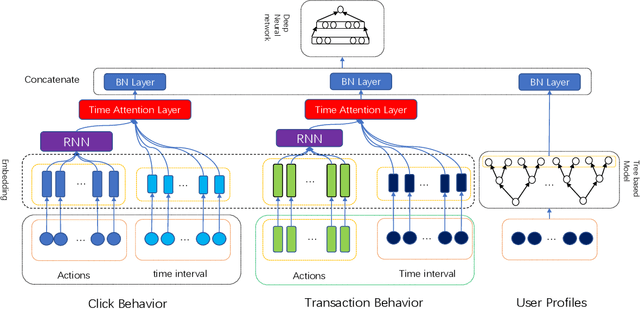
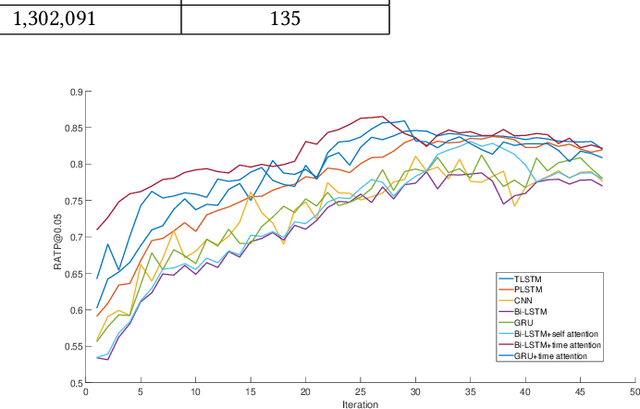
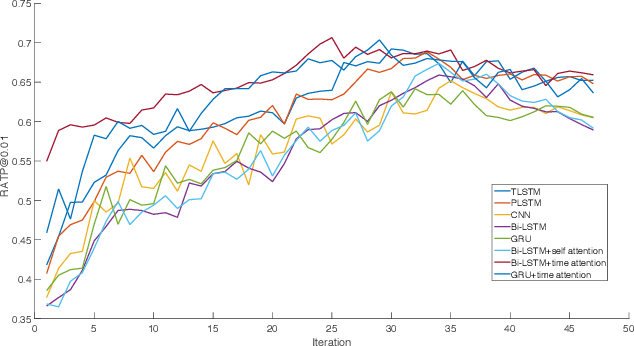
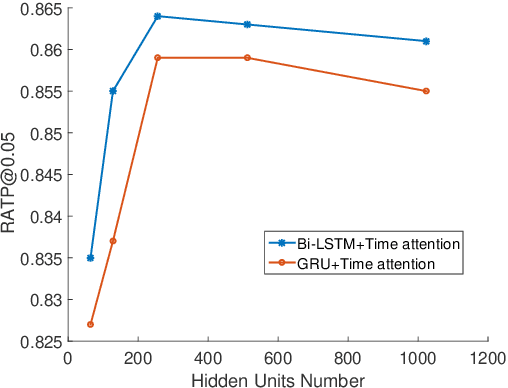
With online payment platforms being ubiquitous and important, fraud transaction detection has become the key for such platforms, to ensure user account safety and platform security. In this work, we present a novel method for detecting fraud transactions by leveraging patterns from both users' static profiles and users' dynamic behaviors in a unified framework. To address and explore the information of users' behaviors in continuous time spaces, we propose to use \emph{time attention based recurrent layers} to embed the detailed information of the time interval, such as the durations of specific actions, time differences between different actions and sequential behavior patterns,etc., in the same latent space. We further combine the learned embeddings and users' static profiles altogether in a unified framework. Extensive experiments validate the effectiveness of our proposed methods over state-of-the-art methods on various evaluation metrics, especially on \emph{recall at top percent} which is an important metric for measuring the balance between service experiences and risk of potential losses.
A Simulation Platform for Multi-tenant Machine Learning Services on Thousands of GPUs
Jan 10, 2022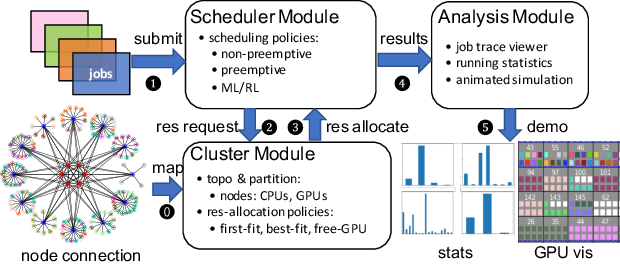
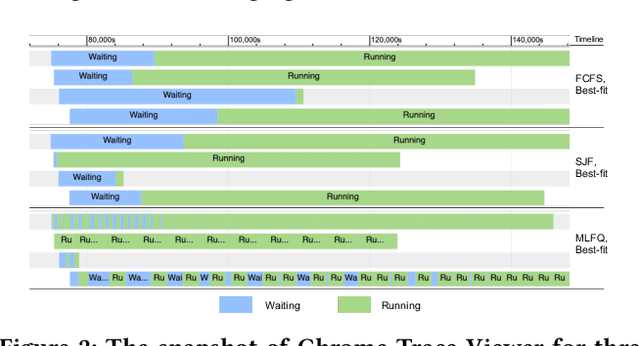
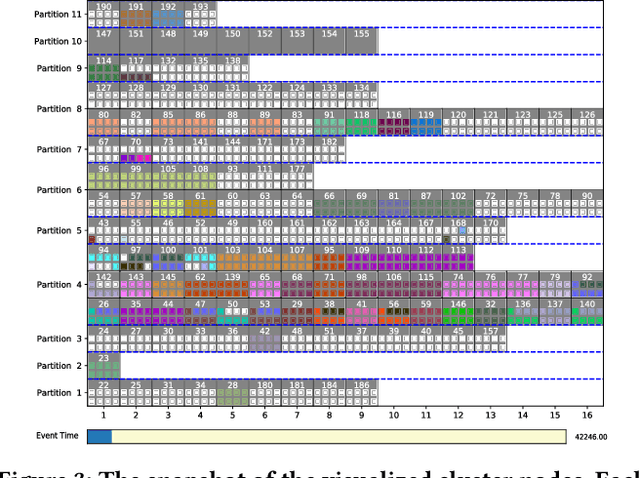
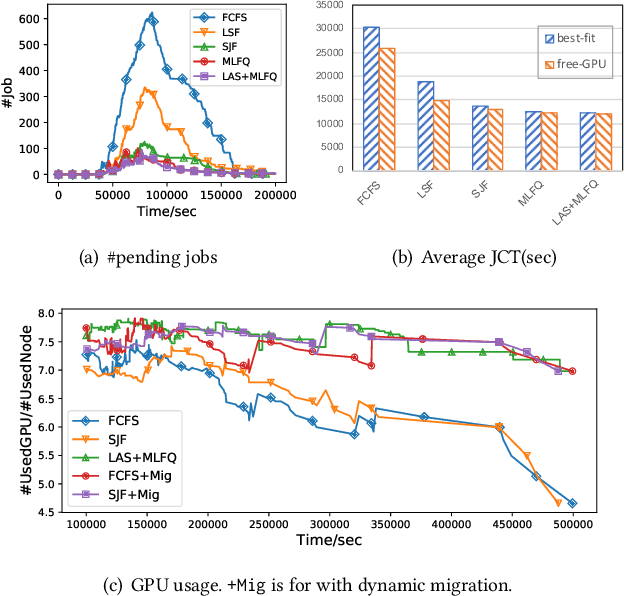
Multi-tenant machine learning services have become emerging data-intensive workloads in data centers with heavy usage of GPU resources. Due to the large scale, many tuning parameters and heavy resource usage, it is usually impractical to evaluate and benchmark those machine learning services on real clusters. In this demonstration, we present AnalySIM, a cluster simulator that allows efficient design explorations for multi-tenant machine learning services. Specifically, by trace-driven cluster workload simulation, AnalySIM can easily test and analyze various scheduling policies in a number of performance metrics such as GPU resource utilization. AnalySIM simulates the cluster computational resource based on both physical topology and logical partition. The tool has been used in SenseTime to understand the impact of different scheduling policies with the trace from a real production cluster of over 1000 GPUs. We find that preemption and migration are able to significantly reduce average job completion time and mitigate the resource fragmentation problem.
Landscape of Neural Architecture Search across sensors: how much do they differ ?
Jan 20, 2022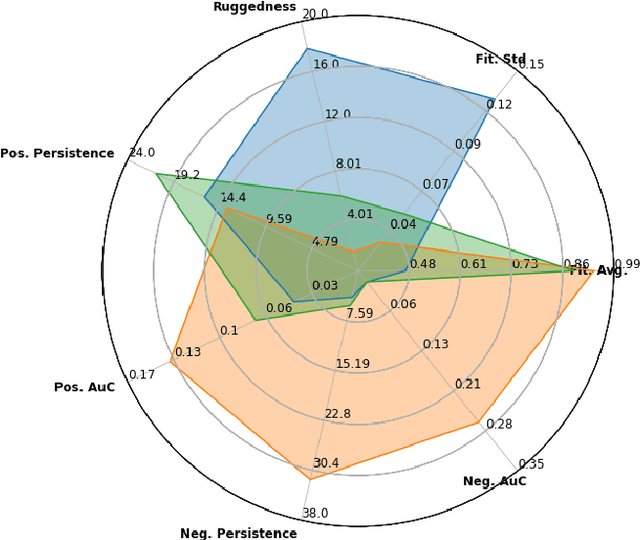
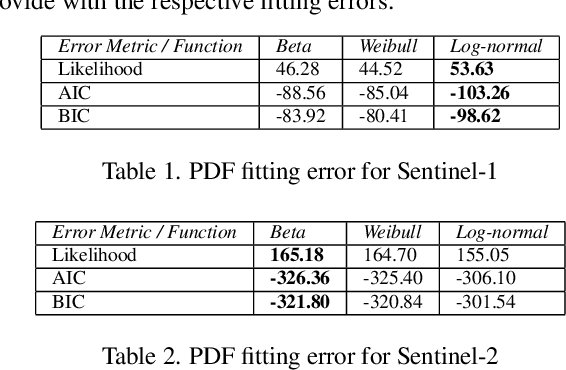

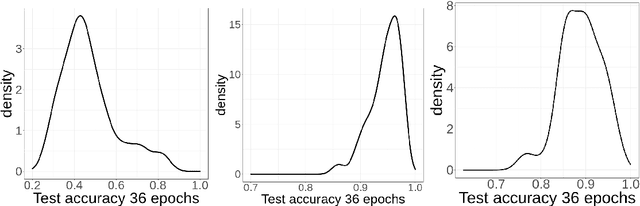
With the rapid rise of neural architecture search, the ability to understand its complexity from the perspective of a search algorithm is desirable. Recently, Traor\'e et al. have proposed the framework of Fitness Landscape Footprint to help describe and compare neural architecture search problems. It attempts at describing why a search strategy might be successful, struggle or fail on a target task. Our study leverages this methodology in the context of searching across sensors, including sensor data fusion. In particular, we apply the Fitness Landscape Footprint to the real-world image classification problem of So2Sat LCZ42, in order to identify the most beneficial sensor to our neural network hyper-parameter optimization problem. From the perspective of distributions of fitness, our findings indicate a similar behaviour of the search space for all sensors: the longer the training time, the larger the overall fitness, and more flatness in the landscapes (less ruggedness and deviation). Regarding sensors, the better the fitness they enable (Sentinel-2), the better the search trajectories (smoother, higher persistence). Results also indicate very similar search behaviour for sensors that can be decently fitted by the search space (Sentinel-2 and fusion).
Fast Differentiable Matrix Square Root and Inverse Square Root
Jan 29, 2022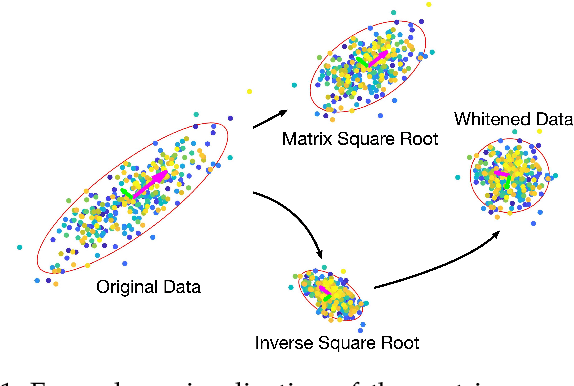

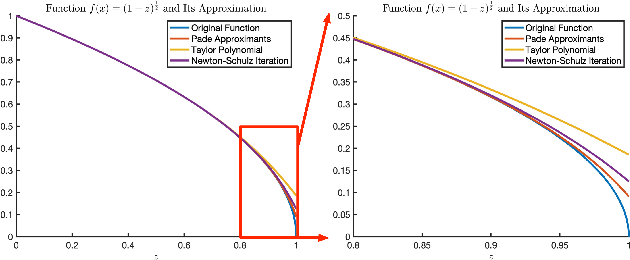

Computing the matrix square root and its inverse in a differentiable manner is important in a variety of computer vision tasks. Previous methods either adopt the Singular Value Decomposition (SVD) to explicitly factorize the matrix or use the Newton-Schulz iteration (NS iteration) to derive the approximate solution. However, both methods are not computationally efficient enough in either the forward pass or the backward pass. In this paper, we propose two more efficient variants to compute the differentiable matrix square root and the inverse square root. For the forward propagation, one method is to use Matrix Taylor Polynomial (MTP), and the other method is to use Matrix Pad\'e Approximants (MPA). The backward gradient is computed by iteratively solving the continuous-time Lyapunov equation using the matrix sign function. A series of numerical tests show that both methods yield considerable speed-up compared with the SVD or the NS iteration. Moreover, we validate the effectiveness of our methods in several real-world applications, including de-correlated batch normalization, second-order vision transformer, global covariance pooling for large-scale and fine-grained recognition, attentive covariance pooling for video recognition, and neural style transfer. The experimental results demonstrate that our methods can also achieve competitive and even slightly better performances. The Pytorch implementation is available at \href{https://github.com/KingJamesSong/FastDifferentiableMatSqrt}{https://github.com/KingJamesSong/FastDifferentiableMatSqrt}.
Enhancement or Super-Resolution: Learning-based Adaptive Video Streaming with Client-Side Video Processing
Jan 20, 2022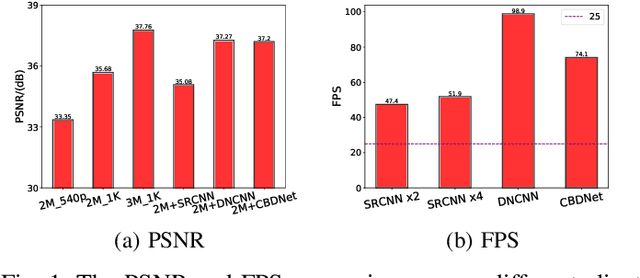
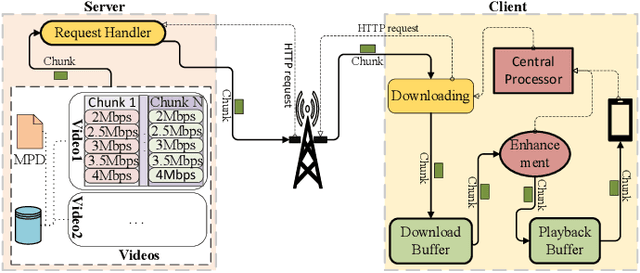
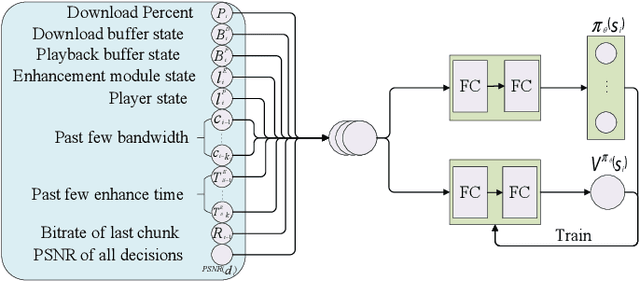
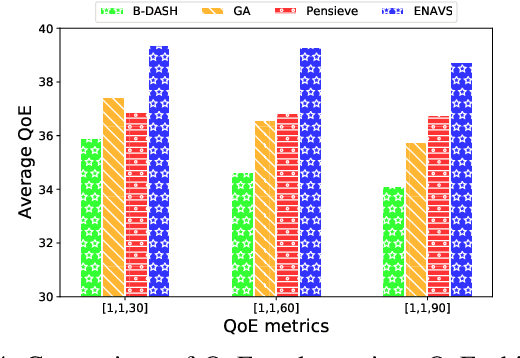
The rapid development of multimedia and communication technology has resulted in an urgent need for high-quality video streaming. However, robust video streaming under fluctuating network conditions and heterogeneous client computing capabilities remains a challenge. In this paper, we consider an enhancement-enabled video streaming network under a time-varying wireless network and limited computation capacity. "Enhancement" means that the client can improve the quality of the downloaded video segments via image processing modules. We aim to design a joint bitrate adaptation and client-side enhancement algorithm toward maximizing the quality of experience (QoE). We formulate the problem as a Markov decision process (MDP) and propose a deep reinforcement learning (DRL)-based framework, named ENAVS. As video streaming quality is mainly affected by video compression, we demonstrate that the video enhancement algorithm outperforms the super-resolution algorithm in terms of signal-to-noise ratio and frames per second, suggesting a better solution for client processing in video streaming. Ultimately, we implement ENAVS and demonstrate extensive testbed results under real-world bandwidth traces and videos. The simulation shows that ENAVS is capable of delivering 5%-14% more QoE under the same bandwidth and computing power conditions as conventional ABR streaming.
Watermarking Images in Self-Supervised Latent Spaces
Dec 17, 2021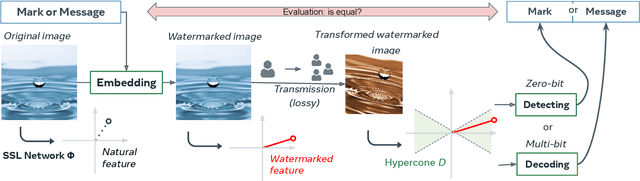
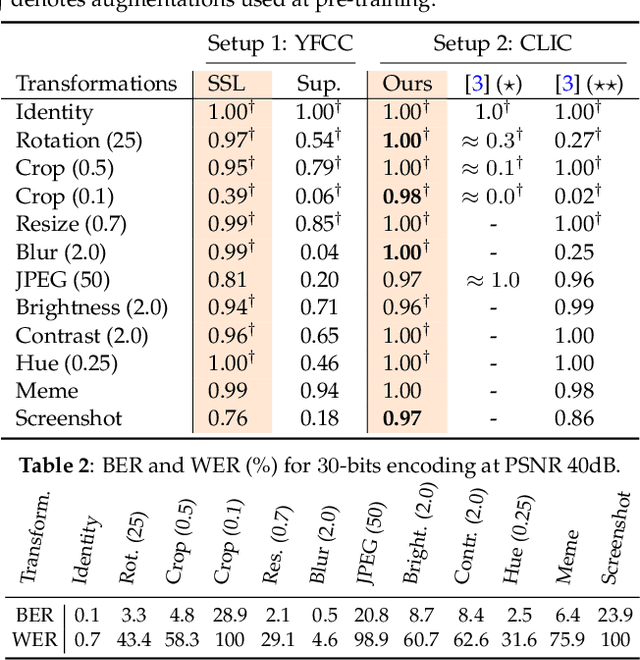
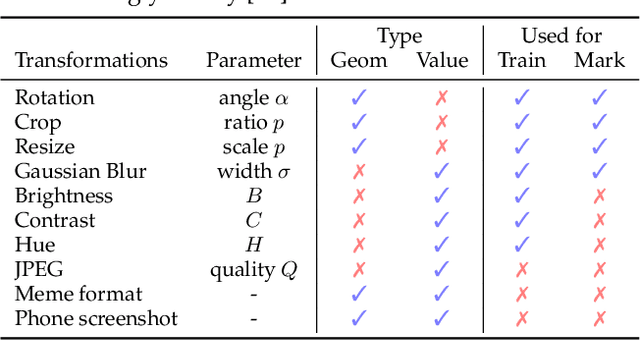
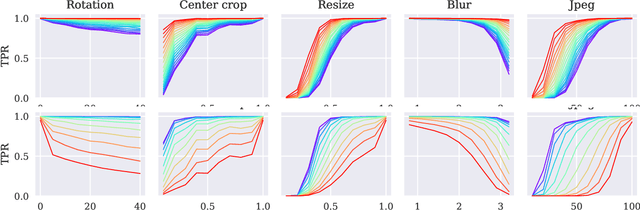
We revisit watermarking techniques based on pre-trained deep networks, in the light of self-supervised approaches. We present a way to embed both marks and binary messages into their latent spaces, leveraging data augmentation at marking time. Our method can operate at any resolution and creates watermarks robust to a broad range of transformations (rotations, crops, JPEG, contrast, etc). It significantly outperforms the previous zero-bit methods, and its performance on multi-bit watermarking is on par with state-of-the-art encoder-decoder architectures trained end-to-end for watermarking. Our implementation and models will be made publicly available.
Bayesian Learning via Neural Schrödinger-Föllmer Flows
Nov 29, 2021
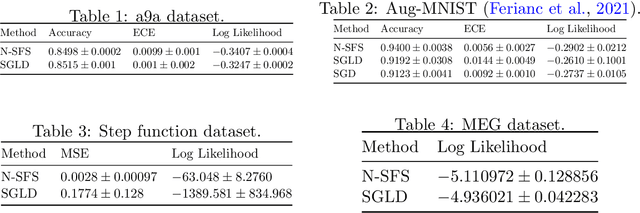
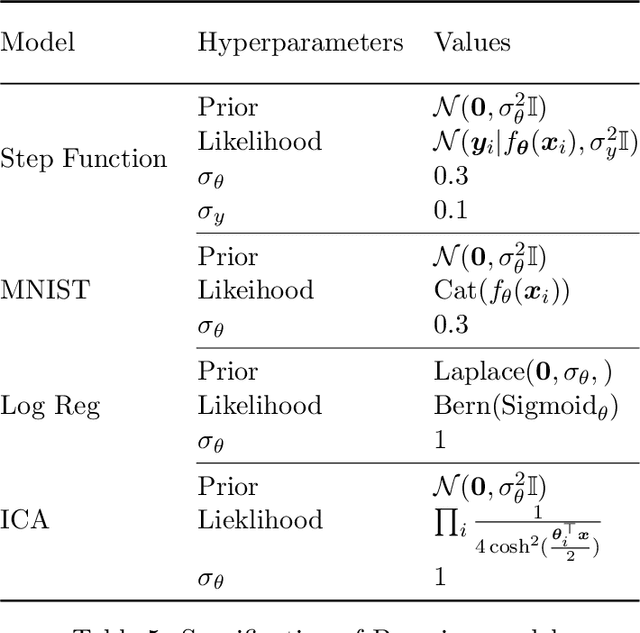
In this work we explore a new framework for approximate Bayesian inference in large datasets based on stochastic control. We advocate stochastic control as a finite time alternative to popular steady-state methods such as stochastic gradient Langevin dynamics (SGLD). Furthermore, we discuss and adapt the existing theoretical guarantees of this framework and establish connections to already existing VI routines in SDE-based models.
Interactive Attention AI to translate low light photos to captions for night scene understanding in women safety
Jan 04, 2022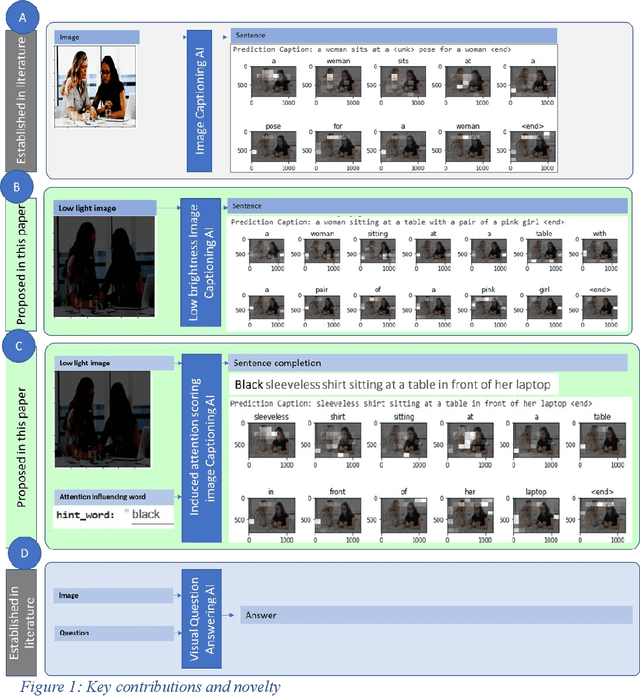
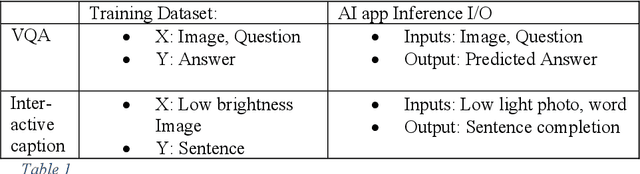
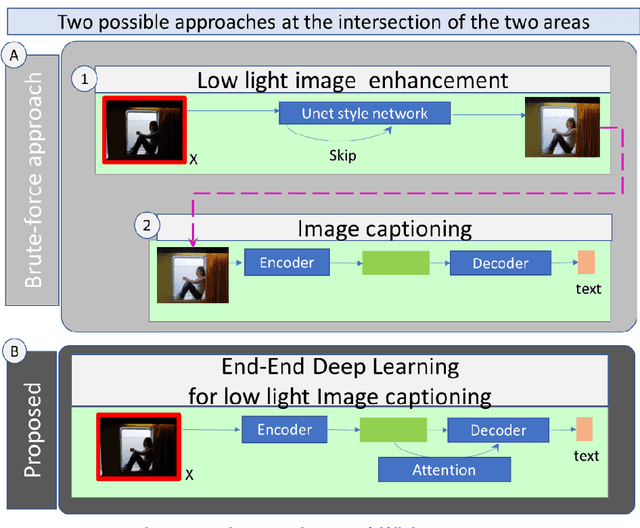
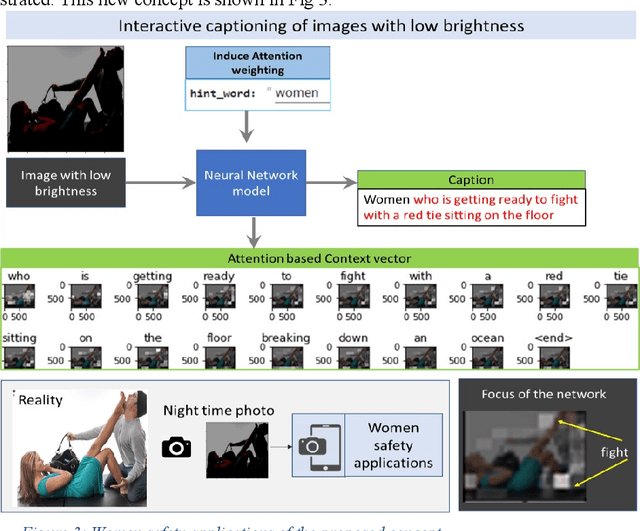
There is amazing progress in Deep Learning based models for Image captioning and Low Light image enhancement. For the first time in literature, this paper develops a Deep Learning model that translates night scenes to sentences, opening new possibilities for AI applications in the safety of visually impaired women. Inspired by Image Captioning and Visual Question Answering, a novel Interactive Image Captioning is developed. A user can make the AI focus on any chosen person of interest by influencing the attention scoring. Attention context vectors are computed from CNN feature vectors and user-provided start word. The Encoder-Attention-Decoder neural network learns to produce captions from low brightness images. This paper demonstrates how women safety can be enabled by researching a novel AI capability in the Interactive Vision-Language model for perception of the environment in the night.
SPIRAL: Self-supervised Perturbation-Invariant Representation Learning for Speech Pre-Training
Jan 29, 2022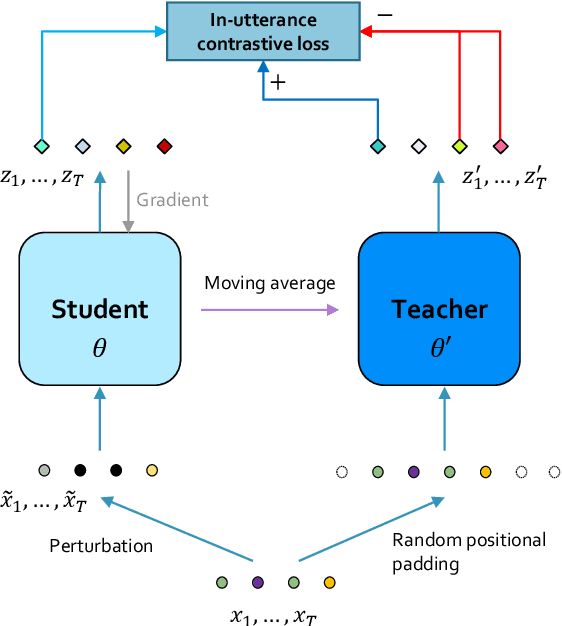
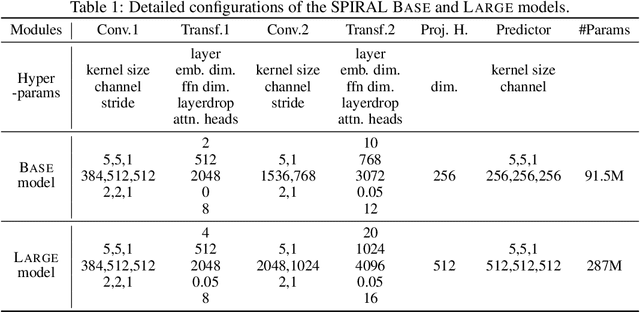


We introduce a new approach for speech pre-training named SPIRAL which works by learning denoising representation of perturbed data in a teacher-student framework. Specifically, given a speech utterance, we first feed the utterance to a teacher network to obtain corresponding representation. Then the same utterance is perturbed and fed to a student network. The student network is trained to output representation resembling that of the teacher. At the same time, the teacher network is updated as moving average of student's weights over training steps. In order to prevent representation collapse, we apply an in-utterance contrastive loss as pre-training objective and impose position randomization on the input to the teacher. SPIRAL achieves competitive or better results compared to state-of-the-art speech pre-training method wav2vec 2.0, with significant reduction of training cost (80% for Base model, 65% for Large model). Furthermore, we address the problem of noise-robustness that is critical to real-world speech applications. We propose multi-condition pre-training by perturbing the student's input with various types of additive noise. We demonstrate that multi-condition pre-trained SPIRAL models are more robust to noisy speech (9.0% - 13.3% relative word error rate reduction on real noisy test data), compared to applying multi-condition training solely in the fine-tuning stage. The code will be released after publication.