 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
VocGAN: A High-Fidelity Real-time Vocoder with a Hierarchically-nested Adversarial Network
Jul 30, 2020
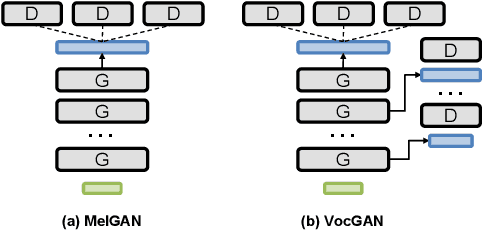
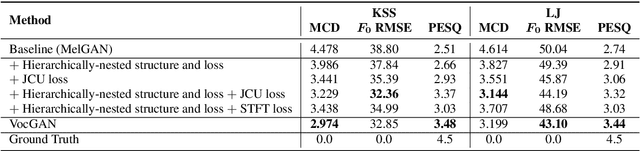
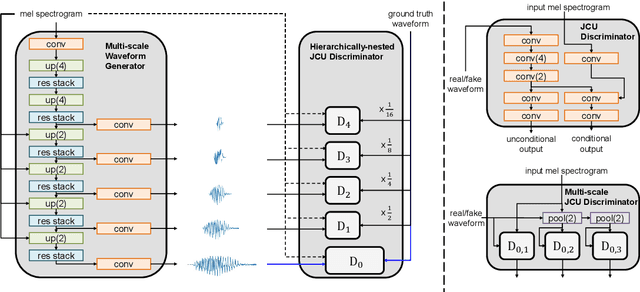
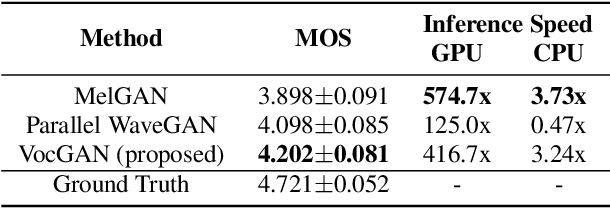
We present a novel high-fidelity real-time neural vocoder called VocGAN. A recently developed GAN-based vocoder, MelGAN, produces speech waveforms in real-time. However, it often produces a waveform that is insufficient in quality or inconsistent with acoustic characteristics of the input mel spectrogram. VocGAN is nearly as fast as MelGAN, but it significantly improves the quality and consistency of the output waveform. VocGAN applies a multi-scale waveform generator and a hierarchically-nested discriminator to learn multiple levels of acoustic properties in a balanced way. It also applies the joint conditional and unconditional objective, which has shown successful results in high-resolution image synthesis. In experiments, VocGAN synthesizes speech waveforms 416.7x faster on a GTX 1080Ti GPU and 3.24x faster on a CPU than real-time. Compared with MelGAN, it also exhibits significantly improved quality in multiple evaluation metrics including mean opinion score (MOS) with minimal additional overhead. Additionally, compared with Parallel WaveGAN, another recently developed high-fidelity vocoder, VocGAN is 6.98x faster on a CPU and exhibits higher MOS.
Fast and Data-Efficient Training of Rainbow: an Experimental Study on Atari
Nov 19, 2021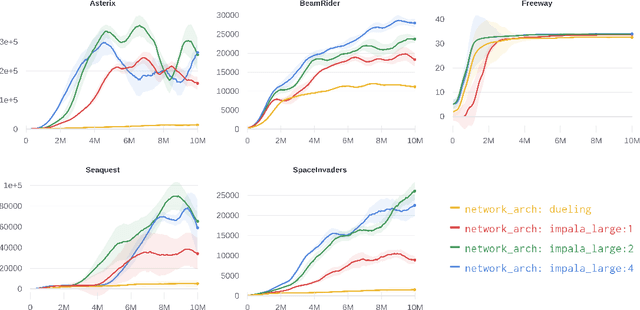

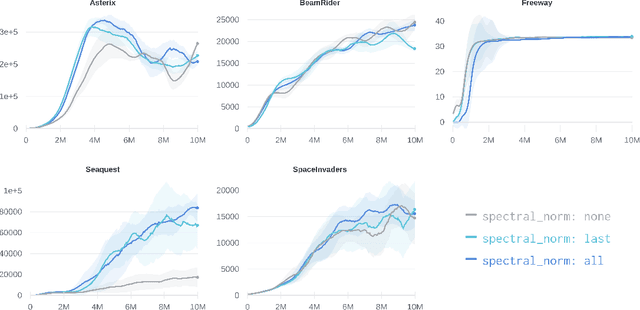
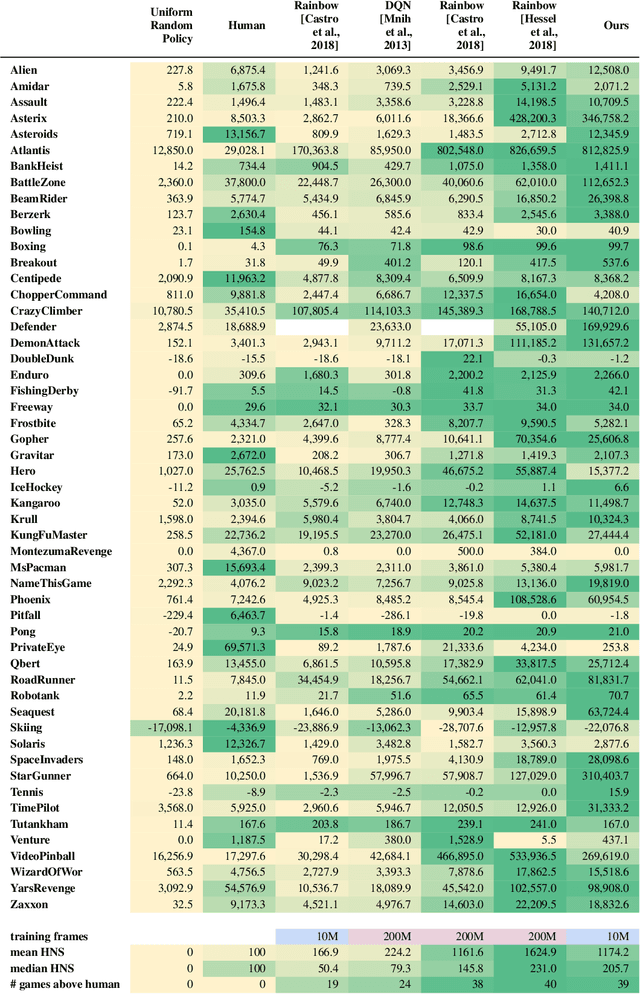
Across the Arcade Learning Environment, Rainbow achieves a level of performance competitive with humans and modern RL algorithms. However, attaining this level of performance requires large amounts of data and hardware resources, making research in this area computationally expensive and use in practical applications often infeasible. This paper's contribution is threefold: We (1) propose an improved version of Rainbow, seeking to drastically reduce Rainbow's data, training time, and compute requirements while maintaining its competitive performance; (2) we empirically demonstrate the effectiveness of our approach through experiments on the Arcade Learning Environment, and (3) we conduct a number of ablation studies to investigate the effect of the individual proposed modifications. Our improved version of Rainbow reaches a median human normalized score close to classic Rainbow's, while using 20 times less data and requiring only 7.5 hours of training time on a single GPU. We also provide our full implementation including pre-trained models.
Multi-Airport Delay Prediction with Transformers
Nov 04, 2021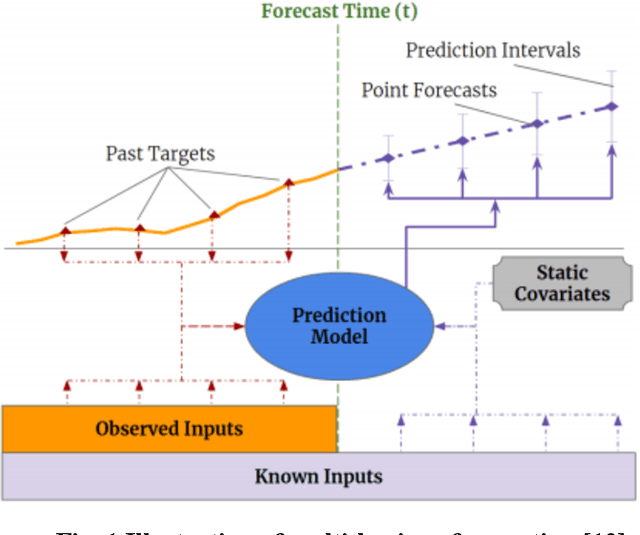
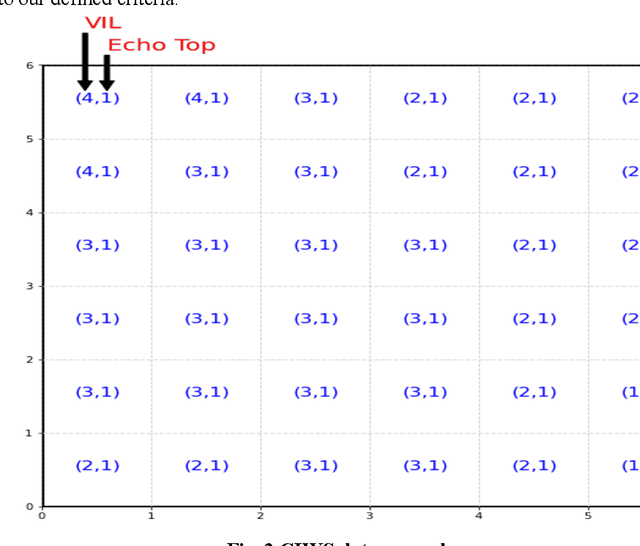
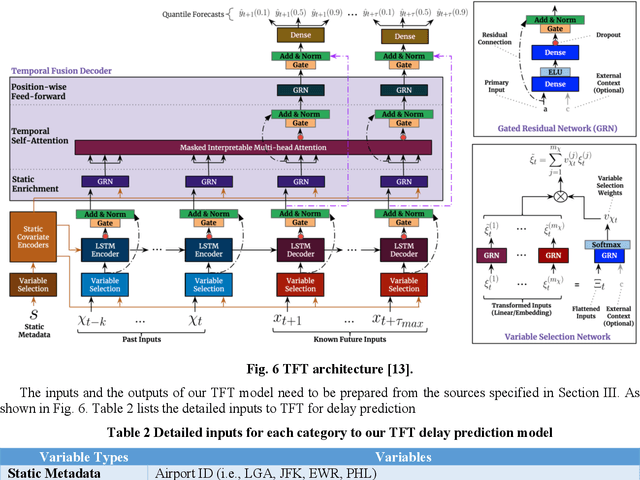
Airport performance prediction with a reasonable look-ahead time is a challenging task and has been attempted by various prior research. Traffic, demand, weather, and traffic management actions are all critical inputs to any prediction model. In this paper, a novel approach based on Temporal Fusion Transformer (TFT) was proposed to predict departure and arrival delays simultaneously for multiple airports at once. This approach can capture complex temporal dynamics of the inputs known at the time of prediction and then forecast selected delay metrics up to four hours into the future. When dealing with weather inputs, a self-supervised learning (SSL) model was developed to encode high-dimensional weather data into a much lower-dimensional representation to make the training of TFT more efficiently and effectively. The initial results show that the TFT-based delay prediction model achieves satisfactory performance measured by smaller prediction errors on a testing dataset. In addition, the interpretability analysis of the model outputs identifies the important input factors for delay prediction. The proposed approach is expected to help air traffic managers or decision makers gain insights about traffic management actions on delay mitigation and once operationalized, provide enough lead time to plan for predicted performance degradation.
TME-BNA: Temporal Motif-Preserving Network Embedding with Bicomponent Neighbor Aggregation
Oct 26, 2021
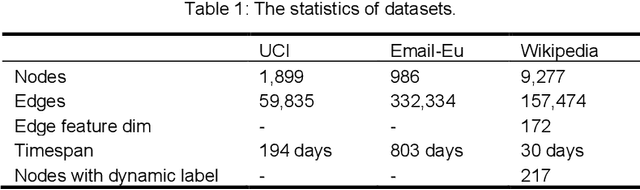
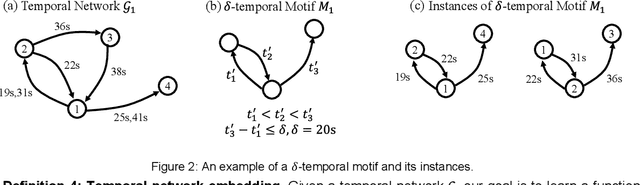
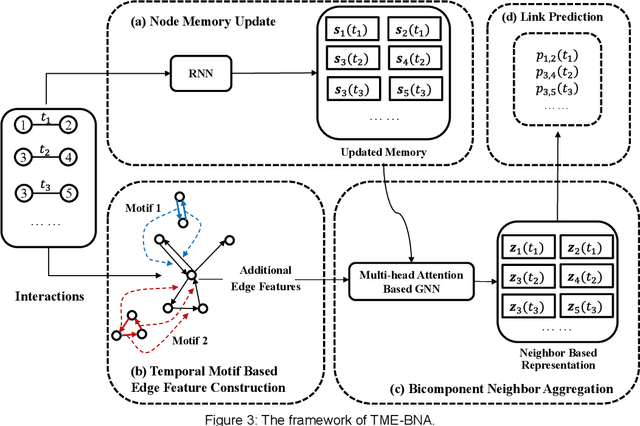
Evolving temporal networks serve as the abstractions of many real-life dynamic systems, e.g., social network and e-commerce. The purpose of temporal network embedding is to map each node to a time-evolving low-dimension vector for downstream tasks, e.g., link prediction and node classification. The difficulty of temporal network embedding lies in how to utilize the topology and time information jointly to capture the evolution of a temporal network. In response to this challenge, we propose a temporal motif-preserving network embedding method with bicomponent neighbor aggregation, named TME-BNA. Considering that temporal motifs are essential to the understanding of topology laws and functional properties of a temporal network, TME-BNA constructs additional edge features based on temporal motifs to explicitly utilize complex topology with time information. In order to capture the topology dynamics of nodes, TME-BNA utilizes Graph Neural Networks (GNNs) to aggregate the historical and current neighbors respectively according to the timestamps of connected edges. Experiments are conducted on three public temporal network datasets, and the results show the effectiveness of TME-BNA.
Music2Video: Automatic Generation of Music Video with fusion of audio and text
Jan 11, 2022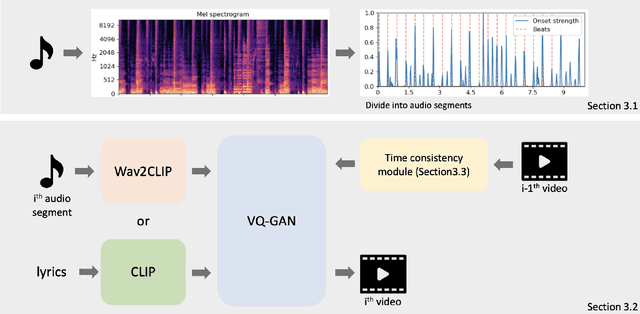


Creation of images using generative adversarial networks has been widely adapted into multi-modal regime with the advent of multi-modal representation models pre-trained on large corpus. Various modalities sharing a common representation space could be utilized to guide the generative models to create images from text or even from audio source. Departing from the previous methods that solely rely on either text or audio, we exploit the expressiveness of both modality. Based on the fusion of text and audio, we create video whose content is consistent with the distinct modalities that are provided. A simple approach to automatically segment the video into variable length intervals and maintain time consistency in generated video is part of our method. Our proposed framework for generating music video shows promising results in application level where users can interactively feed in music source and text source to create artistic music videos. Our code is available at https://github.com/joeljang/music2video.
Language bias in Visual Question Answering: A Survey and Taxonomy
Nov 16, 2021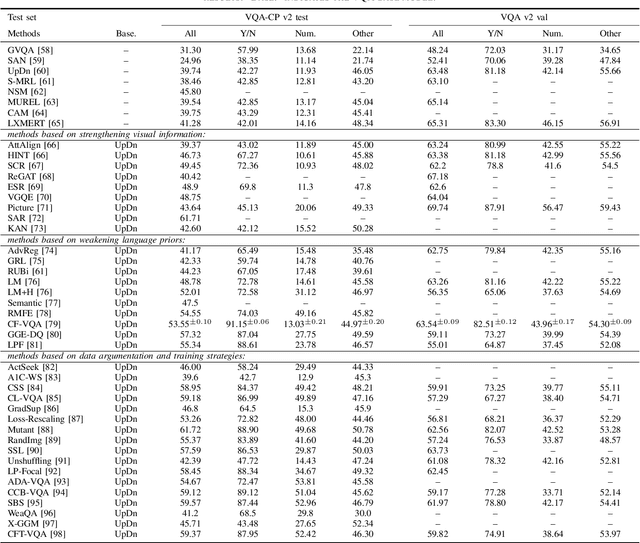
Visual question answering (VQA) is a challenging task, which has attracted more and more attention in the field of computer vision and natural language processing. However, the current visual question answering has the problem of language bias, which reduces the robustness of the model and has an adverse impact on the practical application of visual question answering. In this paper, we conduct a comprehensive review and analysis of this field for the first time, and classify the existing methods according to three categories, including enhancing visual information, weakening language priors, data enhancement and training strategies. At the same time, the relevant representative methods are introduced, summarized and analyzed in turn. The causes of language bias are revealed and classified. Secondly, this paper introduces the datasets mainly used for testing, and reports the experimental results of various existing methods. Finally, we discuss the possible future research directions in this field.
Auditory Model based Phase-Aware Bayesian Spectral Amplitude Estimator for Single-Channel Speech Enhancement
Feb 10, 2022
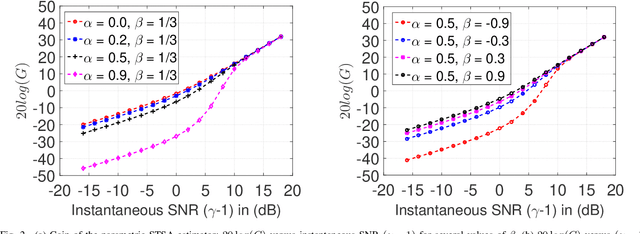
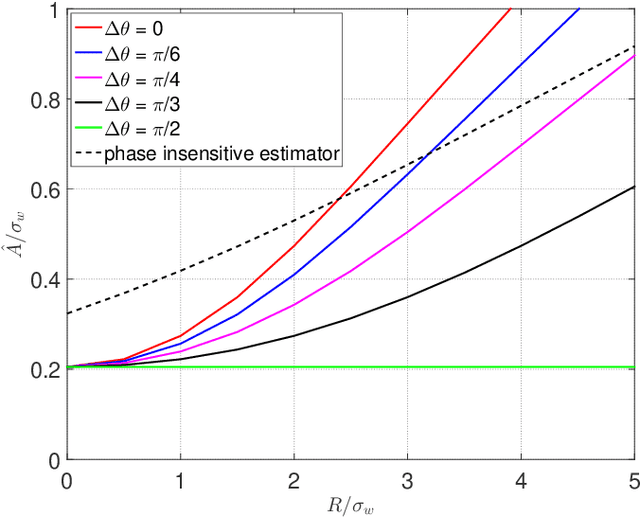
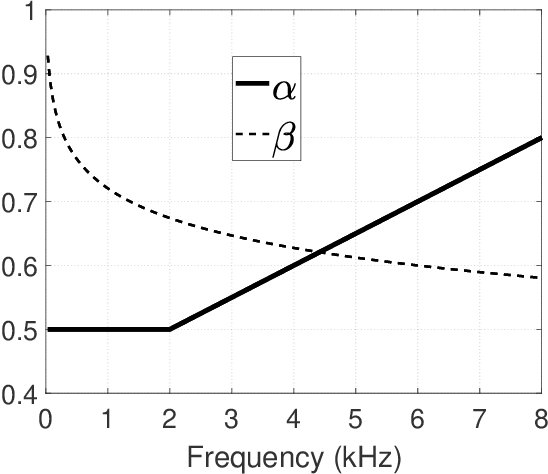
Bayesian estimation of short-time spectral amplitude is one of the most predominant approaches for the enhancement of the noise corrupted speech. The performance of these estimators are usually significantly improved when any perceptually relevant cost function is considered. On the other hand, the recent progress in the phase-based speech signal processing have shown that the phase-only enhancement based on spectral phase estimation methods can also provide joint improvement in the perceived speech quality and intelligibility, even in low SNR conditions. In this paper, to take advantage of both the perceptually motivated cost function involving STSAs of estimated and true clean speech and utilizing the prior spectral phase information, we have derived a phase-aware Bayesian STSA estimator. The parameters of the cost function are chosen based on the characteristics of the human auditory system, namely, the dynamic compressive nonlinearity of the cochlea, the perceived loudness theory and the simultaneous masking properties of the ear. This type of parameter selection scheme results in more noise reduction while limiting the speech distortion. The derived STSA estimator is optimal in the MMSE sense if the prior phase information is available. In practice, however, typically only an estimate of the clean speech phase can be obtained via employing different types of spectral phase estimation techniques which have been developed throughout the last few years. In a blind setup, we have evaluated the proposed Bayesian STSA estimator with different types of standard phase estimation methods available in the literature. Experimental results have shown that the proposed estimator can achieve substantial improvement in performance than the traditional phase-blind approaches.
Competitive Simplicity for Multi-Task Learning for Real-Time Foggy Scene Understanding via Domain Adaptation
Dec 09, 2020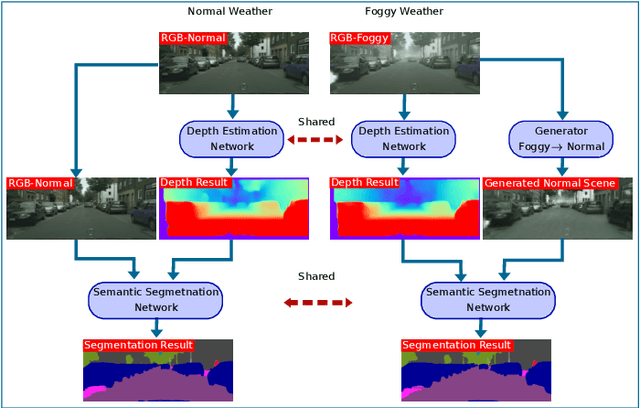
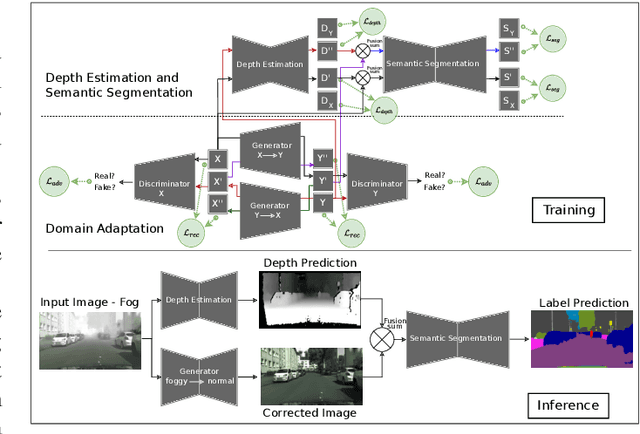
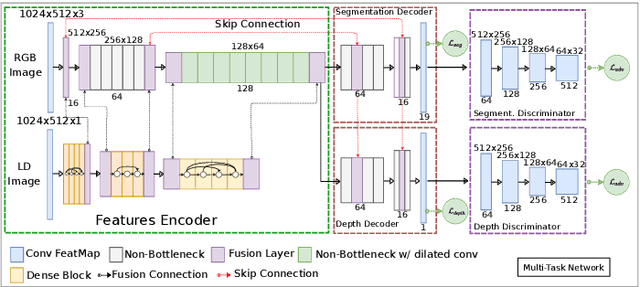
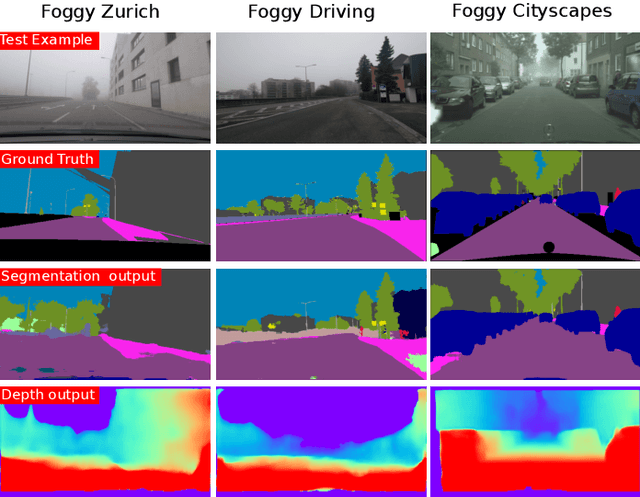
Automotive scene understanding under adverse weather conditions raises a realistic and challenging problem attributable to poor outdoor scene visibility (e.g. foggy weather). However, because most contemporary scene understanding approaches are applied under ideal-weather conditions, such approaches may not provide genuinely optimal performance when compared to established a priori insights on extreme-weather understanding. In this paper, we propose a complex but competitive multi-task learning approach capable of performing in real-time semantic scene understanding and monocular depth estimation under foggy weather conditions by leveraging both recent advances in adversarial training and domain adaptation. As an end-to-end pipeline, our model provides a novel solution to surpass degraded visibility in foggy weather conditions by transferring scenes from foggy to normal using a GAN-based model. For optimal performance in semantic segmentation, our model generates depth to be used as complementary source information with RGB in the segmentation network. We provide a robust method for foggy scene understanding by training two models (normal and foggy) simultaneously with shared weights (each model is trained on each weather condition independently). Our model incorporates RGB colour, depth, and luminance images via distinct encoders with dense connectivity and features fusing, and leverages skip connections to produce consistent depth and segmentation predictions. Using this architectural formulation with light computational complexity at inference time, we are able to achieve comparable performance to contemporary approaches at a fraction of the overall model complexity.
Deep Reinforcement Learning Assisted Federated Learning Algorithm for Data Management of IIoT
Feb 03, 2022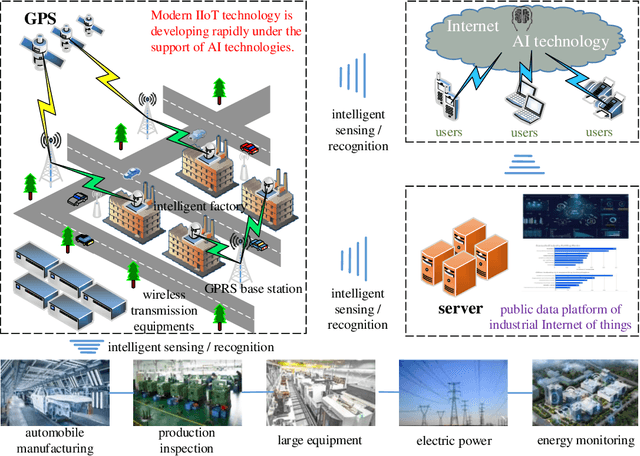
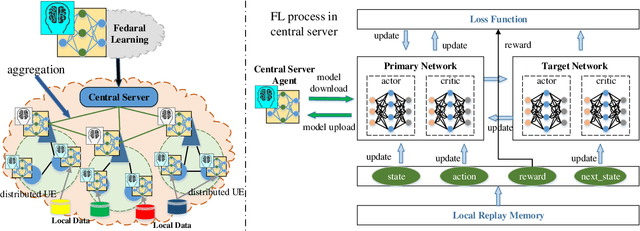
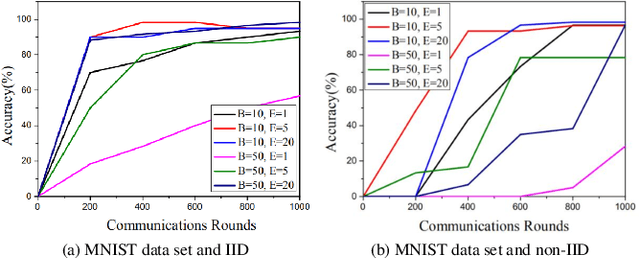
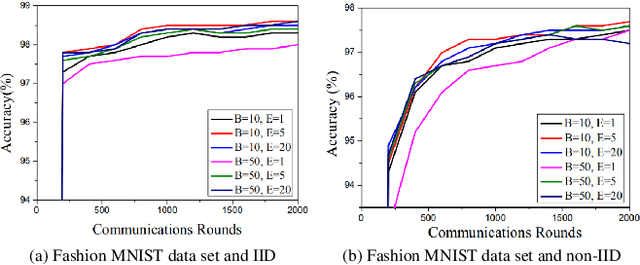
The continuous expanded scale of the industrial Internet of Things (IIoT) leads to IIoT equipments generating massive amounts of user data every moment. According to the different requirement of end users, these data usually have high heterogeneity and privacy, while most of users are reluctant to expose them to the public view. How to manage these time series data in an efficient and safe way in the field of IIoT is still an open issue, such that it has attracted extensive attention from academia and industry. As a new machine learning (ML) paradigm, federated learning (FL) has great advantages in training heterogeneous and private data. This paper studies the FL technology applications to manage IIoT equipment data in wireless network environments. In order to increase the model aggregation rate and reduce communication costs, we apply deep reinforcement learning (DRL) to IIoT equipment selection process, specifically to select those IIoT equipment nodes with accurate models. Therefore, we propose a FL algorithm assisted by DRL, which can take into account the privacy and efficiency of data training of IIoT equipment. By analyzing the data characteristics of IIoT equipments, we use MNIST, fashion MNIST and CIFAR-10 data sets to represent the data generated by IIoT. During the experiment, we employ the deep neural network (DNN) model to train the data, and experimental results show that the accuracy can reach more than 97\%, which corroborates the effectiveness of the proposed algorithm.
Drone Object Detection Using RGB/IR Fusion
Jan 11, 2022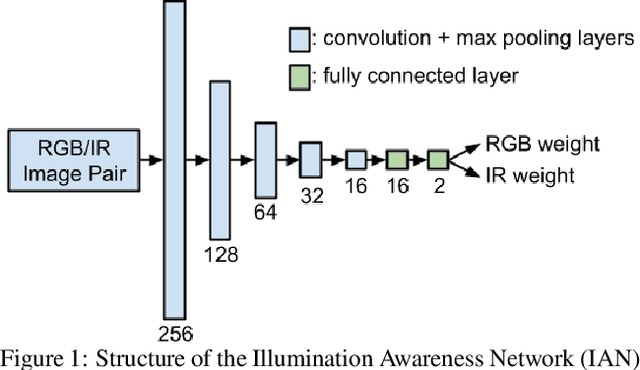
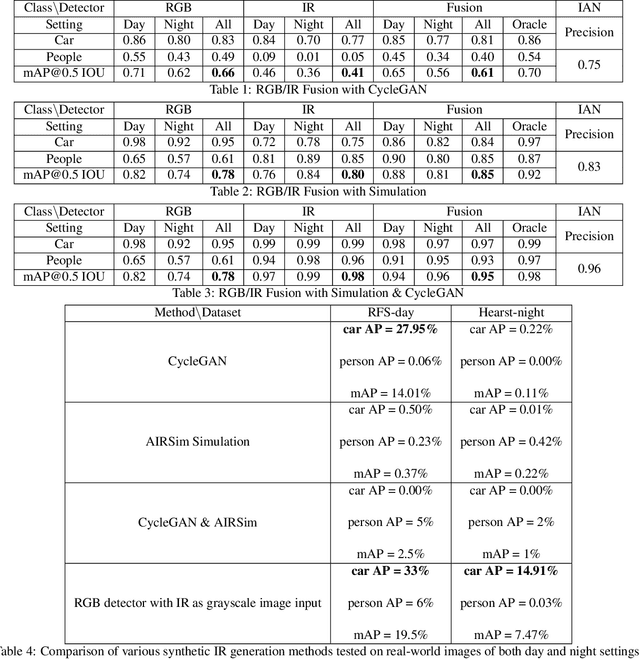
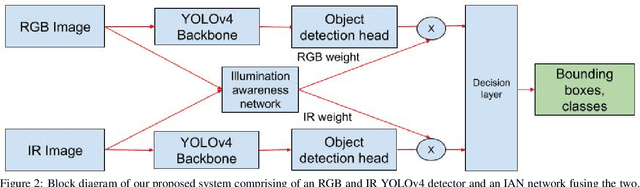

Object detection using aerial drone imagery has received a great deal of attention in recent years. While visible light images are adequate for detecting objects in most scenarios, thermal cameras can extend the capabilities of object detection to night-time or occluded objects. As such, RGB and Infrared (IR) fusion methods for object detection are useful and important. One of the biggest challenges in applying deep learning methods to RGB/IR object detection is the lack of available training data for drone IR imagery, especially at night. In this paper, we develop several strategies for creating synthetic IR images using the AIRSim simulation engine and CycleGAN. Furthermore, we utilize an illumination-aware fusion framework to fuse RGB and IR images for object detection on the ground. We characterize and test our methods for both simulated and actual data. Our solution is implemented on an NVIDIA Jetson Xavier running on an actual drone, requiring about 28 milliseconds of processing per RGB/IR image pair.