 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing TinyML: The Impact of Reduced Data Acquisition Rates for Time Series Classification on Microcontrollers
Sep 17, 2024



Tiny Machine Learning (TinyML) enables efficient, lowcost, and privacy preserving machine learning inference directly on microcontroller units (MCUs) connected to sensors. Optimizing models for these constrained environments is crucial. This paper investigates how reducing data acquisition rates affects TinyML models for time series classification, focusing on resource-constrained, battery operated IoT devices. By lowering data sampling frequency, we aim to reduce computational demands RAM usage, energy consumption, latency, and MAC operations by approximately fourfold while maintaining similar classification accuracies. Our experiments with six benchmark datasets (UCIHAR, WISDM, PAMAP2, MHEALTH, MITBIH, and PTB) showed that reducing data acquisition rates significantly cut energy consumption and computational load, with minimal accuracy loss. For example, a 75\% reduction in acquisition rate for MITBIH and PTB datasets led to a 60\% decrease in RAM usage, 75\% reduction in MAC operations, 74\% decrease in latency, and 70\% reduction in energy consumption, without accuracy loss. These results offer valuable insights for deploying efficient TinyML models in constrained environments.
CTG-KrEW: Generating Synthetic Structured Contextually Correlated Content by Conditional Tabular GAN with K-Means Clustering and Efficient Word Embedding
Sep 03, 2024Conditional Tabular Generative Adversarial Networks (CTGAN) and their various derivatives are attractive for their ability to efficiently and flexibly create synthetic tabular data, showcasing strong performance and adaptability. However, there are certain critical limitations to such models. The first is their inability to preserve the semantic integrity of contextually correlated words or phrases. For instance, skillset in freelancer profiles is one such attribute where individual skills are semantically interconnected and indicative of specific domain interests or qualifications. The second challenge of traditional approaches is that, when applied to generate contextually correlated tabular content, besides generating semantically shallow content, they consume huge memory resources and CPU time during the training stage. To address these problems, we introduce a novel framework, CTGKrEW (Conditional Tabular GAN with KMeans Clustering and Word Embedding), which is adept at generating realistic synthetic tabular data where attributes are collections of semantically and contextually coherent words. CTGKrEW is trained and evaluated using a dataset from Upwork, a realworld freelancing platform. Comprehensive experiments were conducted to analyze the variability, contextual similarity, frequency distribution, and associativity of the generated data, along with testing the framework's system feasibility. CTGKrEW also takes around 99\% less CPU time and 33\% less memory footprints than the conventional approach. Furthermore, we developed KrEW, a web application to facilitate the generation of realistic data containing skill-related information. This application, available at https://riyasamanta.github.io/krew.html, is freely accessible to both the general public and the research community.
TinyTNAS: GPU-Free, Time-Bound, Hardware-Aware Neural Architecture Search for TinyML Time Series Classification
Aug 29, 2024



In this work, we present TinyTNAS, a novel hardware-aware multi-objective Neural Architecture Search (NAS) tool specifically designed for TinyML time series classification. Unlike traditional NAS methods that rely on GPU capabilities, TinyTNAS operates efficiently on CPUs, making it accessible for a broader range of applications. Users can define constraints on RAM, FLASH, and MAC operations to discover optimal neural network architectures within these parameters. Additionally, the tool allows for time-bound searches, ensuring the best possible model is found within a user-specified duration. By experimenting with benchmark dataset UCI HAR, PAMAP2, WISDM, MIT BIH, and PTB Diagnostic ECG Databas TinyTNAS demonstrates state-of-the-art accuracy with significant reductions in RAM, FLASH, MAC usage, and latency. For example, on the UCI HAR dataset, TinyTNAS achieves a 12x reduction in RAM usage, a 144x reduction in MAC operations, and a 78x reduction in FLASH memory while maintaining superior accuracy and reducing latency by 149x. Similarly, on the PAMAP2 and WISDM datasets, it achieves a 6x reduction in RAM usage, a 40x reduction in MAC operations, an 83x reduction in FLASH, and a 67x reduction in latency, all while maintaining superior accuracy. Notably, the search process completes within 10 minutes in a CPU environment. These results highlight TinyTNAS's capability to optimize neural network architectures effectively for resource-constrained TinyML applications, ensuring both efficiency and high performance. The code for TinyTNAS is available at the GitHub repository and can be accessed at https://github.com/BidyutSaha/TinyTNAS.git.
What You Like: Generating Explainable Topical Recommendations for Twitter Using Social Annotations
Dec 23, 2022



With over 500 million tweets posted per day, in Twitter, it is difficult for Twitter users to discover interesting content from the deluge of uninteresting posts. In this work, we present a novel, explainable, topical recommendation system, that utilizes social annotations, to help Twitter users discover tweets, on topics of their interest. A major challenge in using traditional rating dependent recommendation systems, like collaborative filtering and content based systems, in high volume social networks is that, due to attention scarcity most items do not get any ratings. Additionally, the fact that most Twitter users are passive consumers, with 44% users never tweeting, makes it very difficult to use user ratings for generating recommendations. Further, a key challenge in developing recommendation systems is that in many cases users reject relevant recommendations if they are totally unfamiliar with the recommended item. Providing a suitable explanation, for why the item is recommended, significantly improves the acceptability of recommendation. By virtue of being a topical recommendation system our method is able to present simple topical explanations for the generated recommendations. Comparisons with state-of-the-art matrix factorization based collaborative filtering, content based and social recommendations demonstrate the efficacy of the proposed approach.
Auditory Model based Phase-Aware Bayesian Spectral Amplitude Estimator for Single-Channel Speech Enhancement
Feb 10, 2022



Bayesian estimation of short-time spectral amplitude is one of the most predominant approaches for the enhancement of the noise corrupted speech. The performance of these estimators are usually significantly improved when any perceptually relevant cost function is considered. On the other hand, the recent progress in the phase-based speech signal processing have shown that the phase-only enhancement based on spectral phase estimation methods can also provide joint improvement in the perceived speech quality and intelligibility, even in low SNR conditions. In this paper, to take advantage of both the perceptually motivated cost function involving STSAs of estimated and true clean speech and utilizing the prior spectral phase information, we have derived a phase-aware Bayesian STSA estimator. The parameters of the cost function are chosen based on the characteristics of the human auditory system, namely, the dynamic compressive nonlinearity of the cochlea, the perceived loudness theory and the simultaneous masking properties of the ear. This type of parameter selection scheme results in more noise reduction while limiting the speech distortion. The derived STSA estimator is optimal in the MMSE sense if the prior phase information is available. In practice, however, typically only an estimate of the clean speech phase can be obtained via employing different types of spectral phase estimation techniques which have been developed throughout the last few years. In a blind setup, we have evaluated the proposed Bayesian STSA estimator with different types of standard phase estimation methods available in the literature. Experimental results have shown that the proposed estimator can achieve substantial improvement in performance than the traditional phase-blind approaches.
Machine Assistance for Credit Card Approval? Random Wheel can Recommend and Explain
May 11, 2021

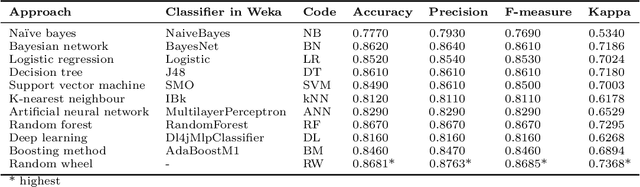
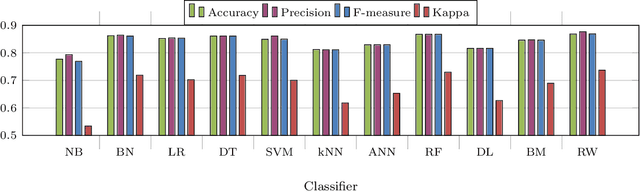
Approval of credit card application is one of the censorious business decision the bankers are usually taking regularly. The growing number of new card applications and the enormous outstanding amount of credit card bills during the recent pandemic make this even more challenging nowadays. Some of the previous studies suggest the usage of machine intelligence for automating the approval process to mitigate this challenge. However, the effectiveness of such automation may depend on the richness of the training dataset and model efficiency. We have recently developed a novel classifier named random wheel which provides a more interpretable output. In this work, we have used an enhanced version of random wheel to facilitate a trustworthy recommendation for credit card approval process. It not only produces more accurate and precise recommendation but also provides an interpretable confidence measure. Besides, it explains the machine recommendation for each credit card application as well. The availability of recommendation confidence and explanation could bring more trust in the machine provided intelligence which in turn can enhance the efficiency of the credit card approval process.
Tensor-Train Long Short-Term Memory for Monaural Speech Enhancement
Dec 25, 2018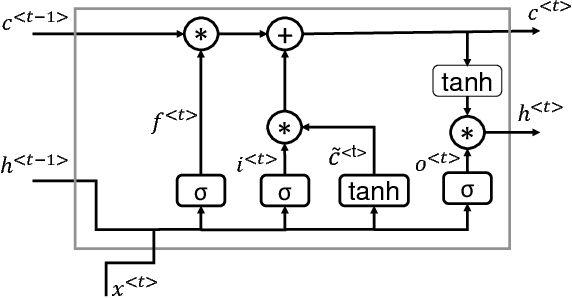
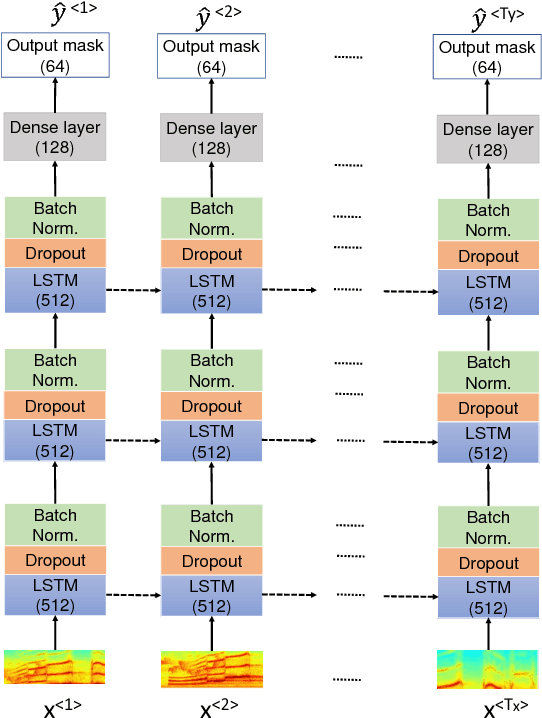
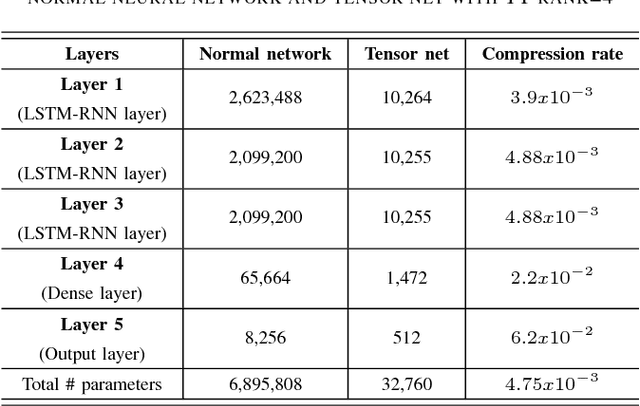
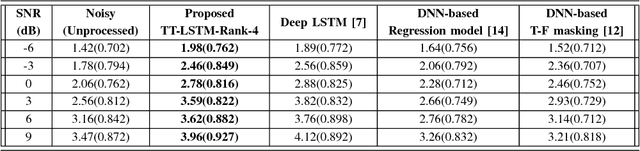
In recent years, Long Short-Term Memory (LSTM) has become a popular choice for speech separation and speech enhancement task. The capability of LSTM network can be enhanced by widening and adding more layers. However, this would introduce millions of parameters in the network and also increase the requirement of computational resources. These limitations hinders the efficient implementation of RNN models in low-end devices such as mobile phones and embedded systems with limited memory. To overcome these issues, we proposed to use an efficient alternative approach of reducing parameters by representing the weight matrix parameters of LSTM based on Tensor-Train (TT) format. We called this Tensor-Train factorized LSTM as TT-LSTM model. Based on this TT-LSTM units, we proposed a deep TensorNet model for single-channel speech enhancement task. Experimental results in various test conditions and in terms of standard speech quality and intelligibility metrics, demonstrated that the proposed deep TT-LSTM based speech enhancement framework can achieve competitive performances with the state-of-the-art uncompressed RNN model, even though the proposed model architecture is orders of magnitude less complex.