 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Label-Smoothed Backdoor Attack
Feb 19, 2022


By injecting a small number of poisoned samples into the training set, backdoor attacks aim to make the victim model produce designed outputs on any input injected with pre-designed backdoors. In order to achieve a high attack success rate using as few poisoned training samples as possible, most existing attack methods change the labels of the poisoned samples to the target class. This practice often results in severe over-fitting of the victim model over the backdoors, making the attack quite effective in output control but easier to be identified by human inspection or automatic defense algorithms. In this work, we proposed a label-smoothing strategy to overcome the over-fitting problem of these attack methods, obtaining a \textit{Label-Smoothed Backdoor Attack} (LSBA). In the LSBA, the label of the poisoned sample $\bm{x}$ will be changed to the target class with a probability of $p_n(\bm{x})$ instead of 100\%, and the value of $p_n(\bm{x})$ is specifically designed to make the prediction probability the target class be only slightly greater than those of the other classes. Empirical studies on several existing backdoor attacks show that our strategy can considerably improve the stealthiness of these attacks and, at the same time, achieve a high attack success rate. In addition, our strategy makes it able to manually control the prediction probability of the design output through manipulating the applied and activated number of LSBAs\footnote{Source code will be published at \url{https://github.com/v-mipeng/LabelSmoothedAttack.git}}.
Learning to Liquidate Forex: Optimal Stopping via Adaptive Top-K Regression
Feb 25, 2022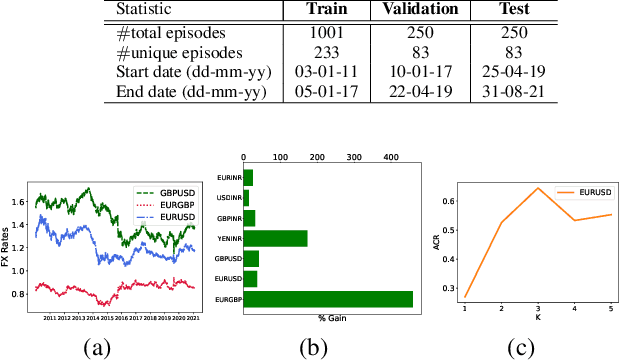
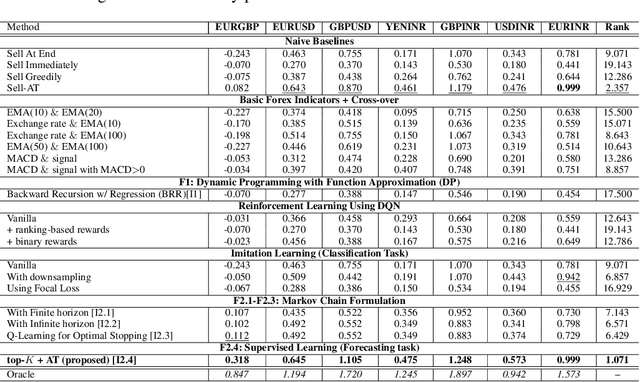
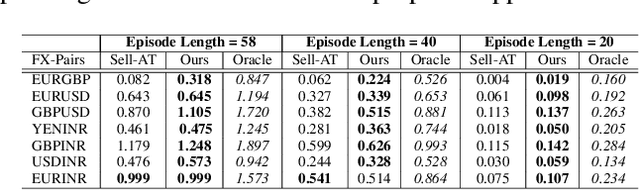
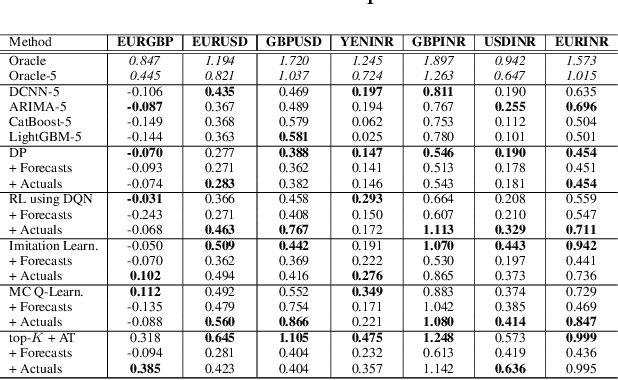
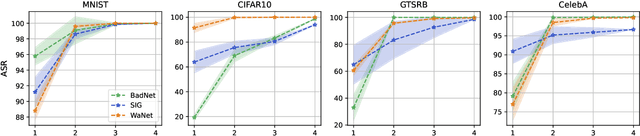
We consider learning a trading agent acting on behalf of the treasury of a firm earning revenue in a foreign currency (FC) and incurring expenses in the home currency (HC). The goal of the agent is to maximize the expected HC at the end of the trading episode by deciding to hold or sell the FC at each time step in the trading episode. We pose this as an optimization problem, and consider a broad spectrum of approaches with the learning component ranging from supervised to imitation to reinforcement learning. We observe that most of the approaches considered struggle to improve upon simple heuristic baselines. We identify two key aspects of the problem that render standard solutions ineffective - i) while good forecasts of future FX rates can be highly effective in guiding good decisions, forecasting FX rates is difficult, and erroneous estimates tend to degrade the performance of trading agents instead of improving it, ii) the inherent non-stationary nature of FX rates renders a fixed decision-threshold highly ineffective. To address these problems, we propose a novel supervised learning approach that learns to forecast the top-K future FX rates instead of forecasting all the future FX rates, and bases the hold-versus-sell decision on the forecasts (e.g. hold if future FX rate is higher than current FX rate, sell otherwise). Furthermore, to handle the non-stationarity in the FX rates data which poses challenges to the i.i.d. assumption in supervised learning methods, we propose to adaptively learn decision-thresholds based on recent historical episodes. Through extensive empirical evaluation, we show that our approach is the only approach which is able to consistently improve upon a simple heuristic baseline. Further experiments show the inefficacy of state-of-the-art statistical and deep-learning-based forecasting methods as they degrade the performance of the trading agent.
Bayesian Linear Bandits for Large-Scale Recommender Systems
Feb 07, 2022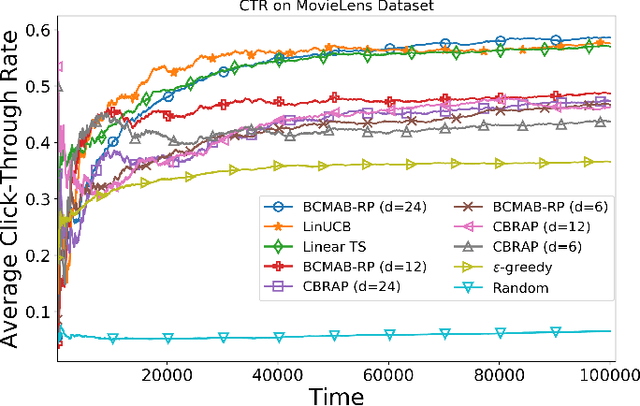
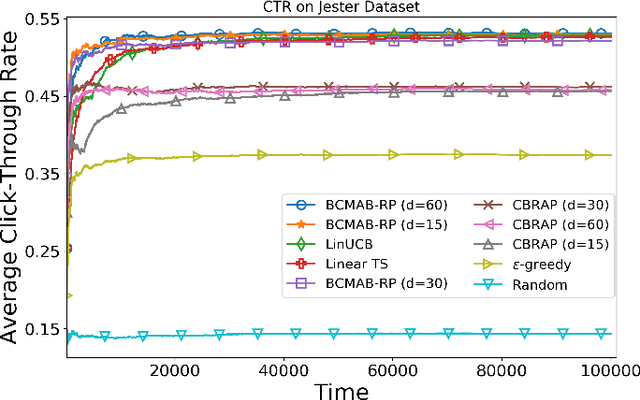
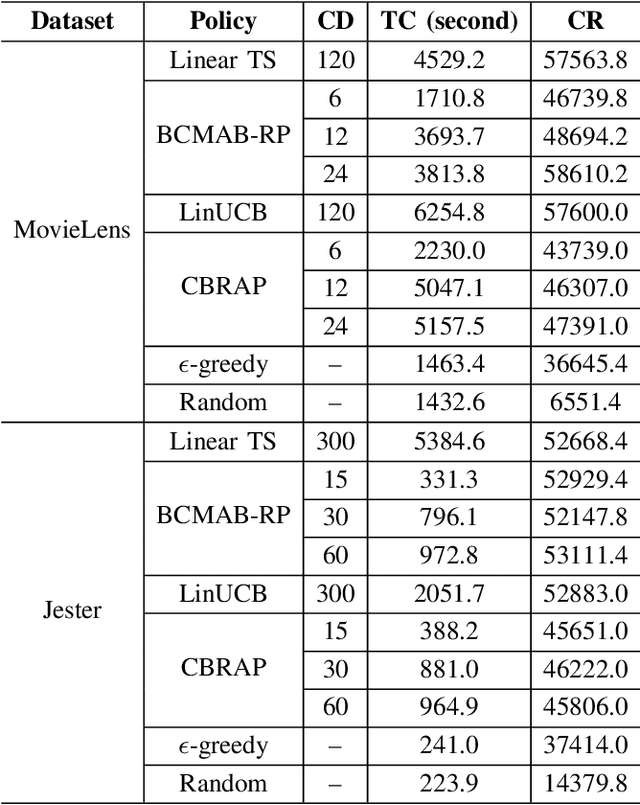
Potentially, taking advantage of available side information boosts the performance of recommender systems; nevertheless, with the rise of big data, the side information has often several dimensions. Hence, it is imperative to develop decision-making algorithms that can cope with such a high-dimensional context in real-time. That is especially challenging when the decision-maker has a variety of items to recommend. In this paper, we build upon the linear contextual multi-armed bandit framework to address this problem. We develop a decision-making policy for a linear bandit problem with high-dimensional context vectors and several arms. Our policy employs Thompson sampling and feeds it with reduced context vectors, where the dimensionality reduction follows by random projection. Our proposed recommender system follows this policy to learn online the item preferences of users while keeping its runtime as low as possible. We prove a regret bound that scales as a factor of the reduced dimension instead of the original one. For numerical evaluation, we use our algorithm to build a recommender system and apply it to real-world datasets. The theoretical and numerical results demonstrate the effectiveness of our proposed algorithm compared to the state-of-the-art in terms of computational complexity and regret performance.
Transformers in Self-Supervised Monocular Depth Estimation with Unknown Camera Intrinsics
Feb 07, 2022The advent of autonomous driving and advanced driver assistance systems necessitates continuous developments in computer vision for 3D scene understanding. Self-supervised monocular depth estimation, a method for pixel-wise distance estimation of objects from a single camera without the use of ground truth labels, is an important task in 3D scene understanding. However, existing methods for this task are limited to convolutional neural network (CNN) architectures. In contrast with CNNs that use localized linear operations and lose feature resolution across the layers, vision transformers process at constant resolution with a global receptive field at every stage. While recent works have compared transformers against their CNN counterparts for tasks such as image classification, no study exists that investigates the impact of using transformers for self-supervised monocular depth estimation. Here, we first demonstrate how to adapt vision transformers for self-supervised monocular depth estimation. Thereafter, we compare the transformer and CNN-based architectures for their performance on KITTI depth prediction benchmarks, as well as their robustness to natural corruptions and adversarial attacks, including when the camera intrinsics are unknown. Our study demonstrates how transformer-based architecture, though lower in run-time efficiency, achieves comparable performance while being more robust and generalizable.
GenderedNews: Une approche computationnelle des écarts de représentation des genres dans la presse française
Feb 11, 2022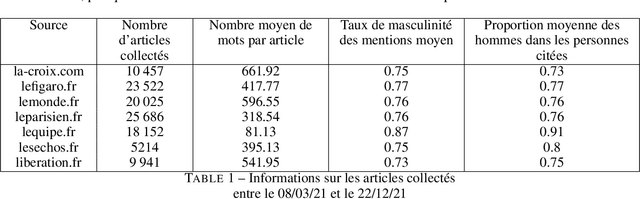
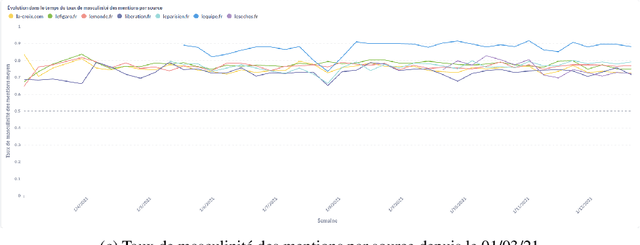
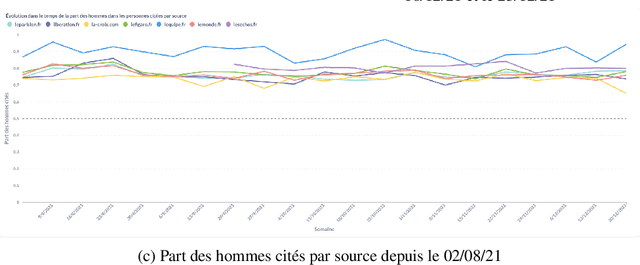
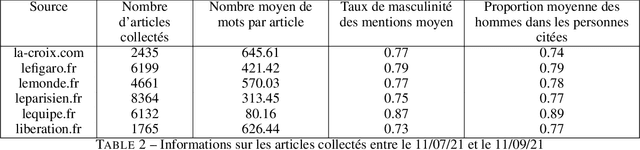
In this article, we present GenderedNews (https://gendered-news.imag.fr), an online dashboard which gives weekly measures of gender imbalance in French online press. We use Natural Language Processing (NLP) methods to quantify gender inequalities in the media, in the wake of global projects like the Global Media Monitoring Project. Such projects are instrumental in highlighting gender imbalance in the media and its very slow evolution. However, their generalisation is limited by their sampling and cost in terms of time, data and staff. Automation allows us to offer complementary measures to quantify inequalities in gender representation. We understand representation as the presence and distribution of men and women mentioned and quoted in the news -- as opposed to representation as stereotypification. In this paper, we first review different means adopted by previous studies on gender inequality in the media : qualitative content analysis, quantitative content analysis and computational methods. We then detail the methods adopted by {\it GenderedNews} and the two metrics implemented: the masculinity rate of mentions and the proportion of men quoted in online news. We describe the data collected daily (seven main titles of French online news media) and the methodology behind our metrics, as well as a few visualisations. We finally propose to illustrate possible analysis of our data by conducting an in-depth observation of a sample of two months of our database.
Optimal Localization with Sequential Pseudorange Measurements for Moving Users in a Time Division Broadcast Positioning System
Feb 01, 2021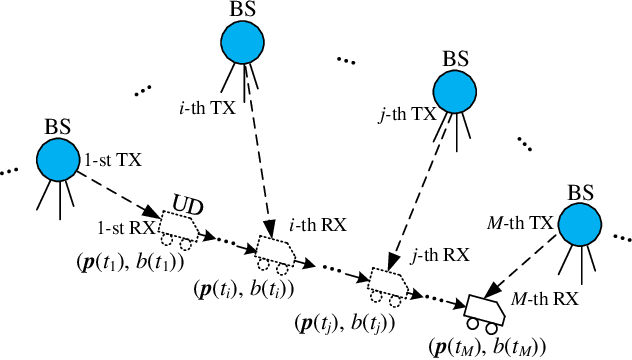
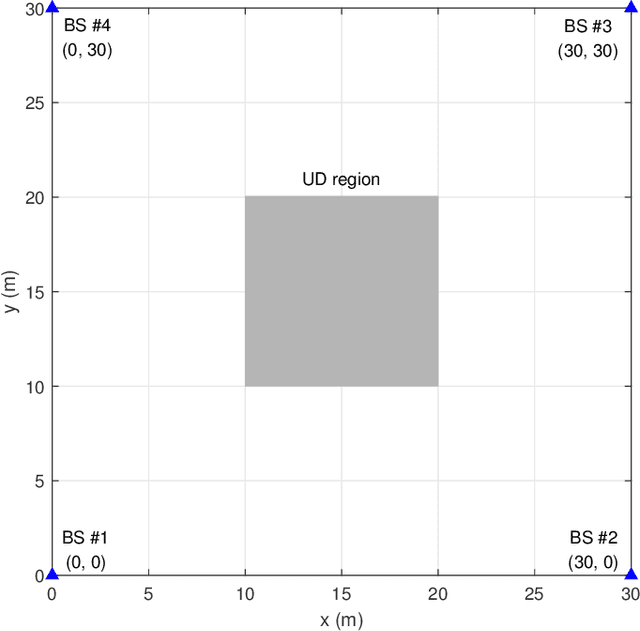
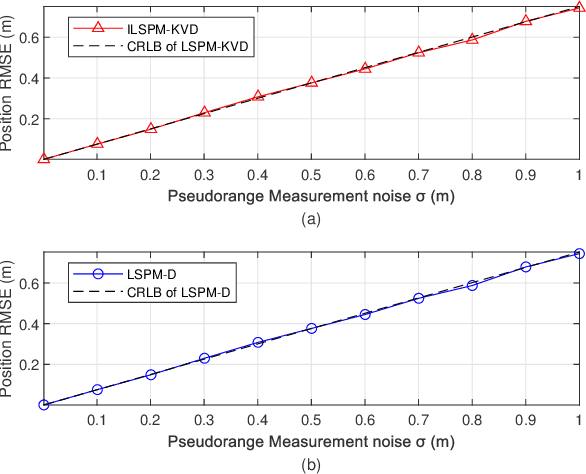
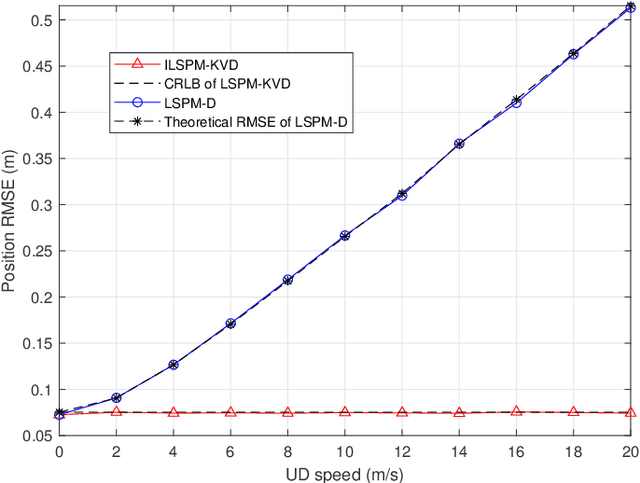
In a time division broadcast positioning system (TDBPS), a user device (UD) determines its position by obtaining sequential time-of-arrival (TOA) or pseudorange measurements from signals broadcast by multiple synchronized base stations (BSs). The existing localization method using sequential pseudorange measurements and a linear clock drift model for the TDPBS, namely LSPM-D, does not compensate the position displacement caused by the UD movement and will result in position error. In this paper, depending on the knowledge of the UD velocity, we develop a set of optimal localization methods for different cases. First, for known UD velocity, we develop the optimal localization method, namely LSPM-KVD, to compensate the movement-caused position error. We show that the LSPM-D is a special case of the LSPM-KVD when the UD is stationary with zero velocity. Second, for the case with unknown UD velocity, we develop a maximum likelihood (ML) method to jointly estimate the UD position and velocity, namely LSPM-UVD. Third, in the case that we have prior distribution information of the UD velocity, we present a maximum a posteriori (MAP) estimator for localization, namely LSPM-PVD. We derive the Cramer-Rao lower bound (CRLB) for all three estimators and analyze their localization error performance. We show that the position error of the LSPM-KVD increases as the assumed known velocity deviates from the true value. As expected, the LSPM-KVD has the smallest position error while the LSPM-PVD and the LSPM-UVD are more robust when the prior knowledge of the UD velocity is limited. Numerical results verify the theoretical analysis on the optimality and the positioning accuracy of the proposed methods.
VGAER: graph neural network reconstruction based community detection
Jan 29, 2022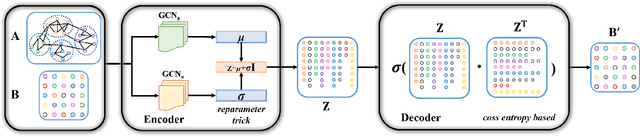
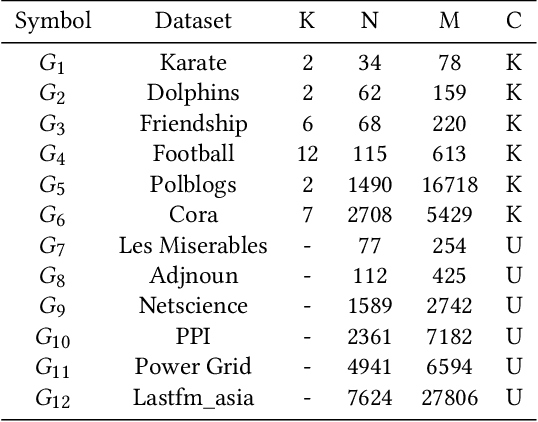
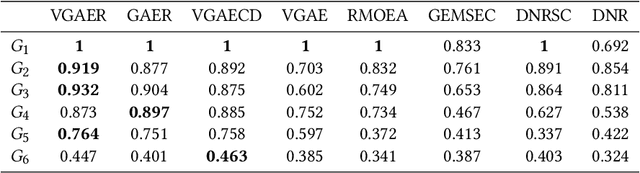
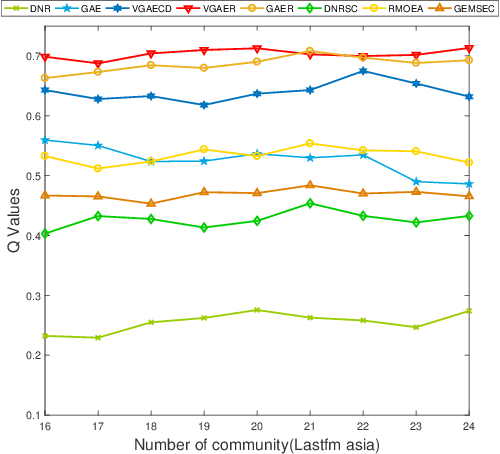
Community detection is a fundamental and important issue in network science, but there are only a few community detection algorithms based on graph neural networks, among which unsupervised algorithms are almost blank. By fusing the high-order modularity information with network features, this paper proposes a Variational Graph AutoEncoder Reconstruction based community detection VGAER for the first time, and gives its non-probabilistic version. They do not need any prior information. We have carefully designed corresponding input features, decoder, and downstream tasks based on the community detection task and these designs are concise, natural, and perform well (NMI values under our design are improved by 59.1% - 565.9%). Based on a series of experiments with wide range of datasets and advanced methods, VGAER has achieved superior performance and shows strong competitiveness and potential with a simpler design. Finally, we report the results of algorithm convergence analysis and t-SNE visualization, which clearly depicted the stable performance and powerful network modularity ability of VGAER. Our codes are available at https://github.com/qcydm/VGAER.
Safe Online Convex Optimization with Unknown Linear Safety Constraints
Nov 14, 2021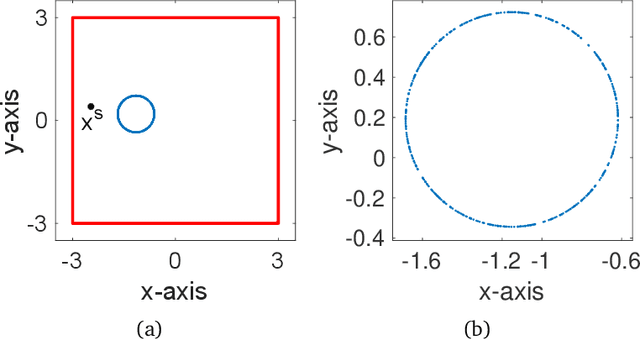
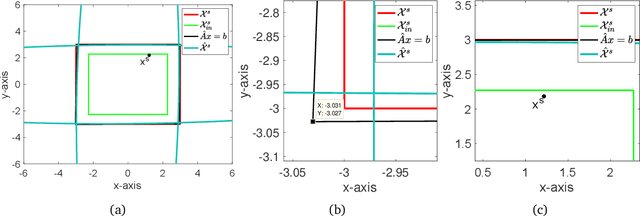
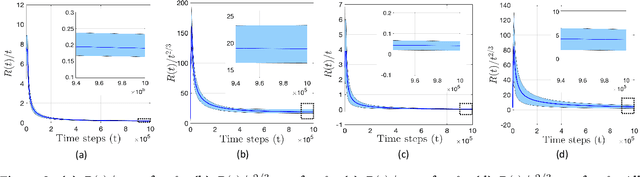
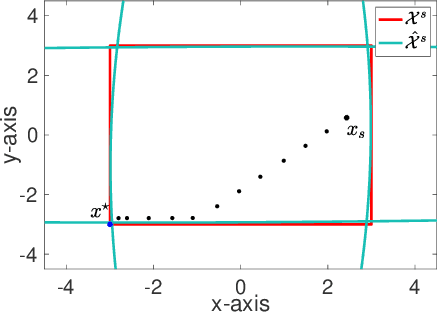
We study the problem of safe online convex optimization, where the action at each time step must satisfy a set of linear safety constraints. The goal is to select a sequence of actions to minimize the regret without violating the safety constraints at any time step (with high probability). The parameters that specify the linear safety constraints are unknown to the algorithm. The algorithm has access to only the noisy observations of constraints for the chosen actions. We propose an algorithm, called the {Safe Online Projected Gradient Descent} (SO-PGD) algorithm, to address this problem. We show that, under the assumption of the availability of a safe baseline action, the SO-PGD algorithm achieves a regret $O(T^{2/3})$. While there are many algorithms for online convex optimization (OCO) problems with safety constraints available in the literature, they allow constraint violations during learning/optimization, and the focus has been on characterizing the cumulative constraint violations. To the best of our knowledge, ours is the first work that provides an algorithm with provable guarantees on the regret, without violating the linear safety constraints (with high probability) at any time step.
An efficient label-free analyte detection algorithm for time-resolved spectroscopy
Nov 15, 2020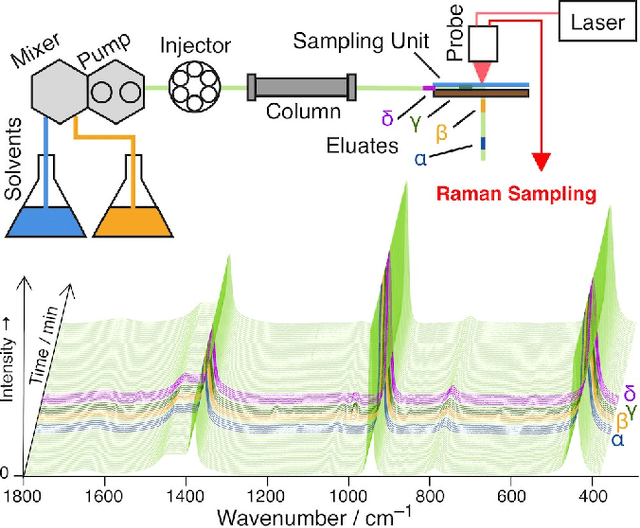
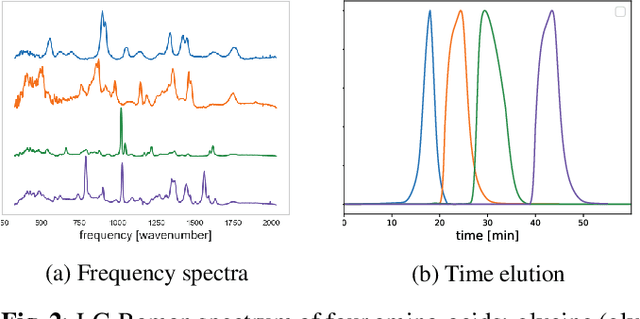
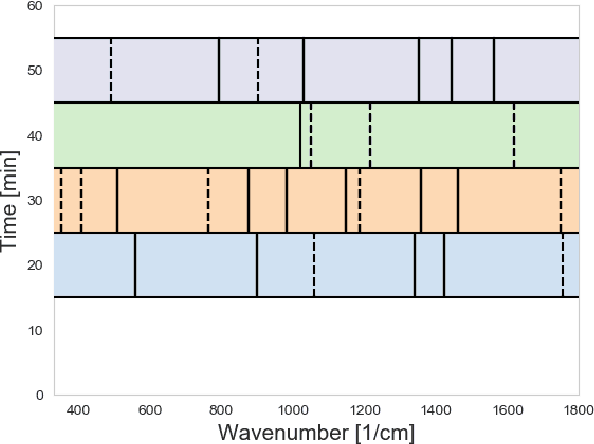
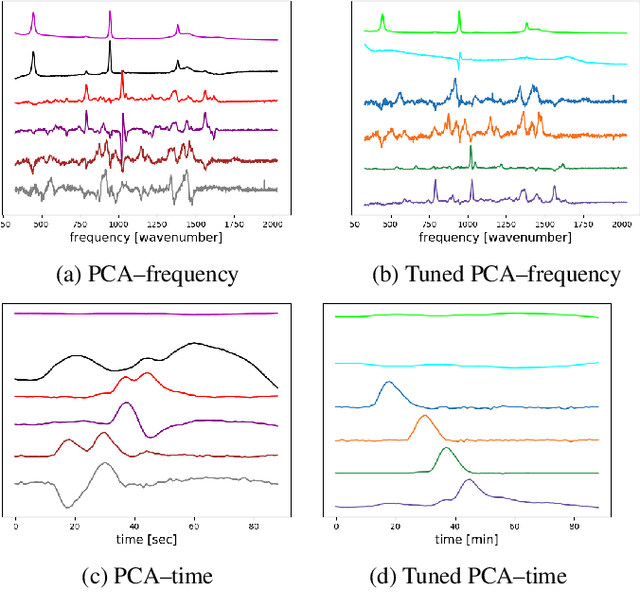
Time-resolved spectral techniques play an important analysis tool in many contexts, from physical chemistry to biomedicine. Customarily, the label-free detection of analytes is manually performed by experts through the aid of classic dimensionality-reduction methods, such as Principal Component Analysis (PCA) and Non-negative Matrix Factorization (NMF). This fundamental reliance on expert analysis for unknown analyte detection severely hinders the applicability and the throughput of these such techniques. For this reason, in this paper, we formulate this detection problem as an unsupervised learning problem and propose a novel machine learning algorithm for label-free analyte detection. To show the effectiveness of the proposed solution, we consider the problem of detecting the amino-acids in Liquid Chromatography coupled with Raman spectroscopy (LC-Raman).
An Improved Mathematical Model of Sepsis: Modeling, Bifurcation Analysis, and Optimal Control Study for Complex Nonlinear Infectious Disease System
Jan 07, 2022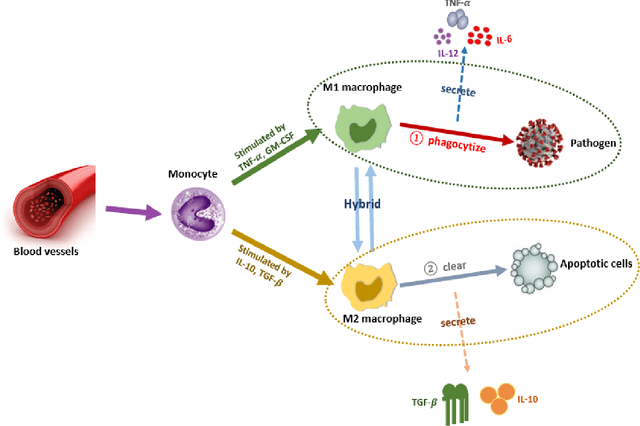

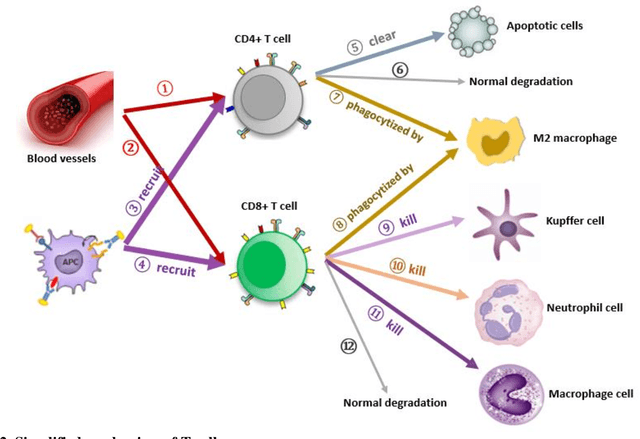
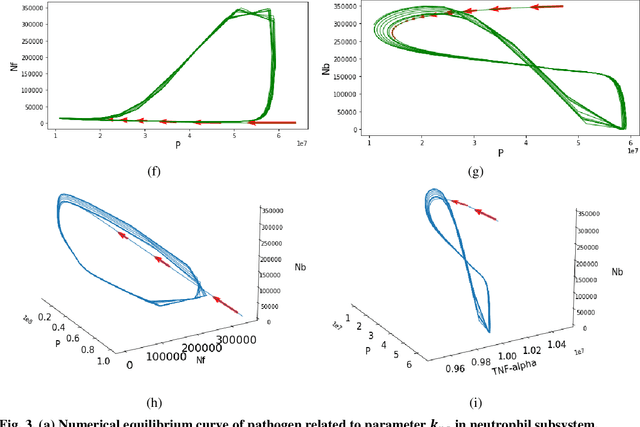
Sepsis is a life-threatening medical emergency, which is a major cause of death worldwide and the second highest cause of mortality in the United States. Researching the optimal control treatment or intervention strategy on the comprehensive sepsis system is key in reducing mortality. For this purpose, first, this paper improves a complex nonlinear sepsis model proposed in our previous work. Then, bifurcation analyses are conducted for each sepsis subsystem to study the model behaviors under some system parameters. The bifurcation analysis results also further indicate the necessity of control treatment and intervention therapy. If the sepsis system is without adding any control under some parameter and initial system value settings, the system will perform persistent inflammation outcomes as time goes by. Therefore, we develop our complex improved nonlinear sepsis model into a sepsis optimal control model, and then use some effective biomarkers recommended in existing clinic practices as optimization objective function to measure the development of sepsis. Besides that, a Bayesian optimization algorithm by combining Recurrent neural network (RNN-BO algorithm) is introduced to predict the optimal control strategy for the studied sepsis optimal control system. The difference between the RNN-BO algorithm from other optimization algorithms is that once given any new initial system value setting (initial value is associated with the initial conditions of patients), the RNN-BO algorithm is capable of quickly predicting a corresponding time-series optimal control based on the historical optimal control data for any new sepsis patient. To demonstrate the effectiveness and efficiency of the RNN-BO algorithm on solving the optimal control solution on the complex nonlinear sepsis system, some numerical simulations are implemented by comparing with other optimization algorithms in this paper.