 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Cell nuclei classification in histopathological images using hybrid OLConvNet
Feb 21, 2022
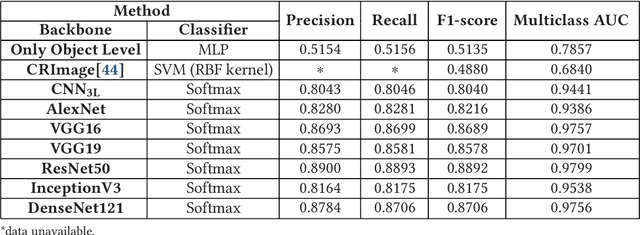
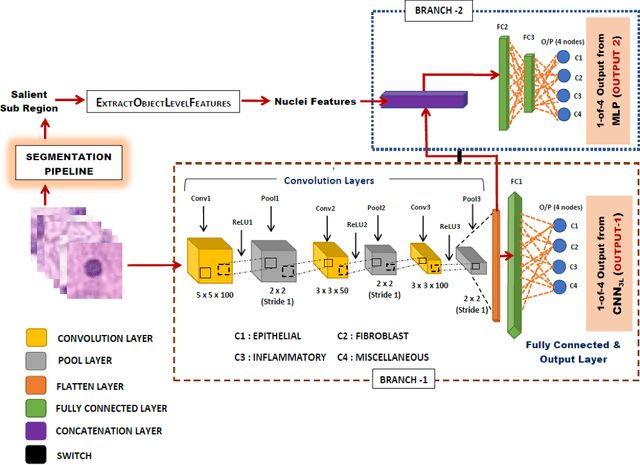
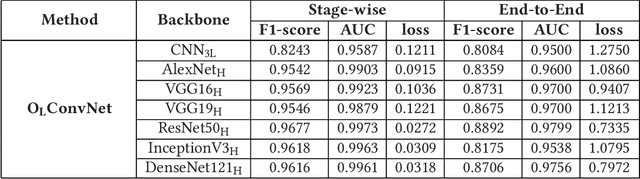
Computer-aided histopathological image analysis for cancer detection is a major research challenge in the medical domain. Automatic detection and classification of nuclei for cancer diagnosis impose a lot of challenges in developing state of the art algorithms due to the heterogeneity of cell nuclei and data set variability. Recently, a multitude of classification algorithms has used complex deep learning models for their dataset. However, most of these methods are rigid and their architectural arrangement suffers from inflexibility and non-interpretability. In this research article, we have proposed a hybrid and flexible deep learning architecture OLConvNet that integrates the interpretability of traditional object-level features and generalization of deep learning features by using a shallower Convolutional Neural Network (CNN) named as $CNN_{3L}$. $CNN_{3L}$ reduces the training time by training fewer parameters and hence eliminating space constraints imposed by deeper algorithms. We used F1-score and multiclass Area Under the Curve (AUC) performance parameters to compare the results. To further strengthen the viability of our architectural approach, we tested our proposed methodology with state of the art deep learning architectures AlexNet, VGG16, VGG19, ResNet50, InceptionV3, and DenseNet121 as backbone networks. After a comprehensive analysis of classification results from all four architectures, we observed that our proposed model works well and perform better than contemporary complex algorithms.
Binary Neural Networks as a general-propose compute paradigm for on-device computer vision
Feb 08, 2022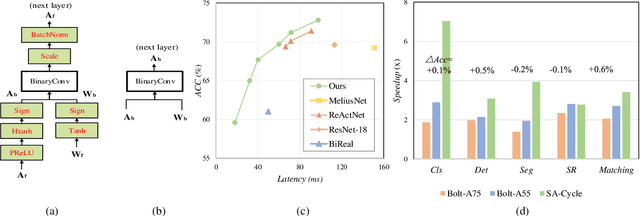

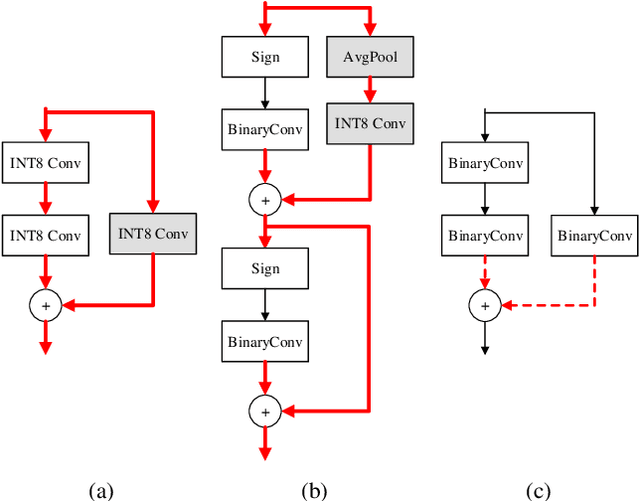
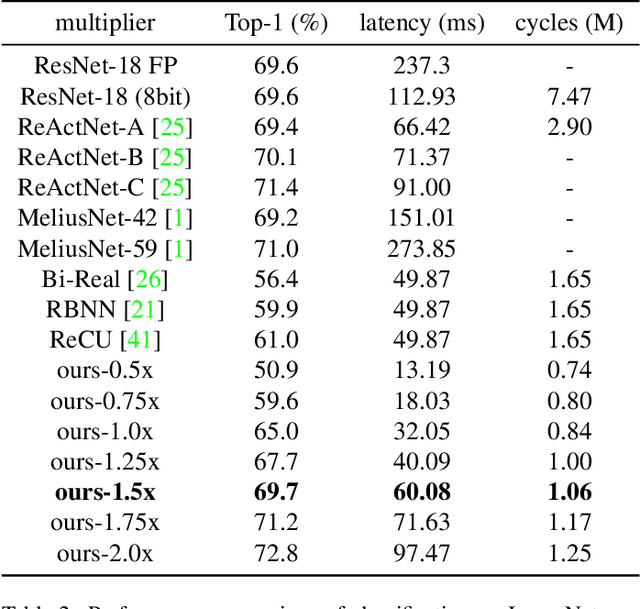
For binary neural networks (BNNs) to become the mainstream on-device computer vision algorithm, they must achieve a superior speed-vs-accuracy tradeoff than 8-bit quantization and establish a similar degree of general applicability in vision tasks. To this end, we propose a BNN framework comprising 1) a minimalistic inference scheme for hardware-friendliness, 2) an over-parameterized training scheme for high accuracy, and 3) a simple procedure to adapt to different vision tasks. The resultant framework overtakes 8-bit quantization in the speed-vs-accuracy tradeoff for classification, detection, segmentation, super-resolution and matching: our BNNs not only retain the accuracy levels of their 8-bit baselines but also showcase 1.3-2.4$\times$ faster FPS on mobile CPUs. Similar conclusions can be drawn for prototypical systolic-array-based AI accelerators, where our BNNs promise 2.8-7$\times$ fewer execution cycles than 8-bit and 2.1-2.7$\times$ fewer cycles than alternative BNN designs. These results suggest that the time for large-scale BNN adoption could be upon us.
What's Cracking? A Review and Analysis of Deep Learning Methods for Structural Crack Segmentation, Detection and Quantification
Feb 08, 2022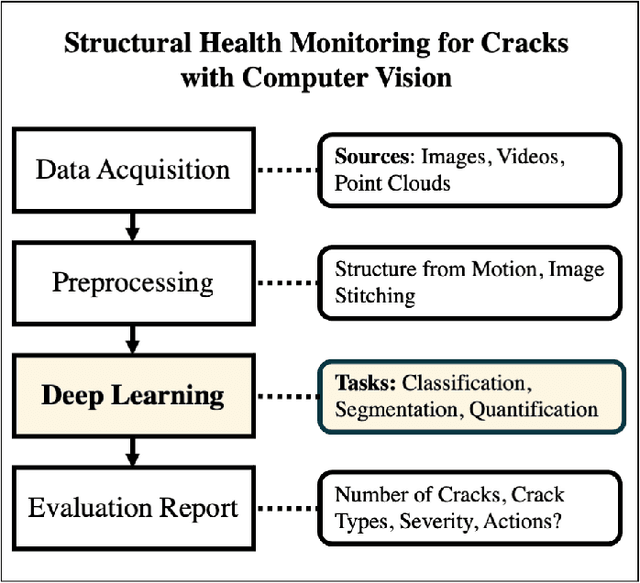
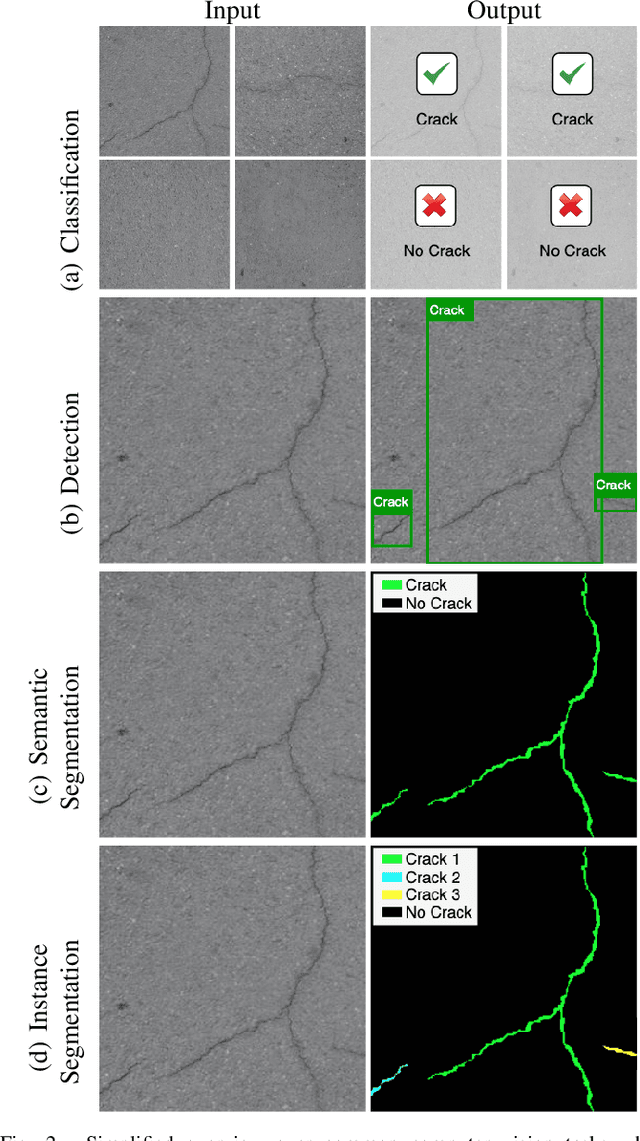


Surface cracks are a very common indicator of potential structural faults. Their early detection and monitoring is an important factor in structural health monitoring. Left untreated, they can grow in size over time and require expensive repairs or maintenance. With recent advances in computer vision and deep learning algorithms, the automatic detection and segmentation of cracks for this monitoring process have become a major topic of interest. This review aims to give researchers an overview of the published work within the field of crack analysis algorithms that make use of deep learning. It outlines the various tasks that are solved through applying computer vision algorithms to surface cracks in a structural health monitoring setting and also provides in-depth reviews of recent fully, semi and unsupervised approaches that perform crack classification, detection, segmentation and quantification. Additionally, this review also highlights popular datasets used for cracks and the metrics that are used to evaluate the performance of those algorithms. Finally, potential research gaps are outlined and further research directions are provided.
ReCasNet: Improving consistency within the two-stage mitosis detection framework
Feb 28, 2022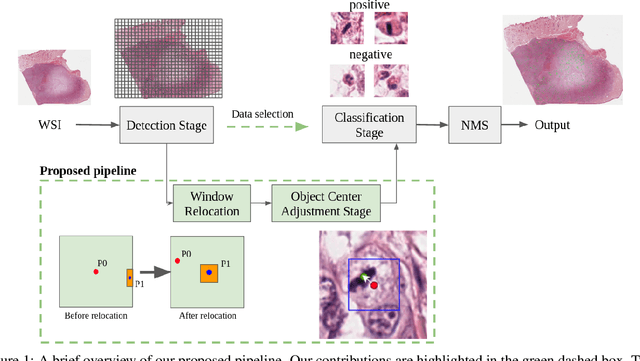
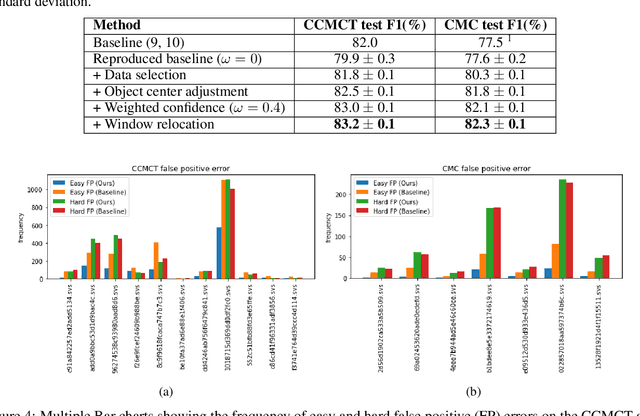
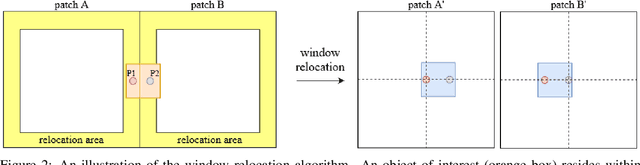

Mitotic count (MC) is an important histological parameter for cancer diagnosis and grading, but the manual process for obtaining MC from whole-slide histopathological images is very time-consuming and prone to error. Therefore, deep learning models have been proposed to facilitate this process. Existing approaches utilize a two-stage pipeline: the detection stage for identifying the locations of potential mitotic cells and the classification stage for refining prediction confidences. However, this pipeline formulation can lead to inconsistencies in the classification stage due to the poor prediction quality of the detection stage and the mismatches in training data distributions between the two stages. In this study, we propose a Refine Cascade Network (ReCasNet), an enhanced deep learning pipeline that mitigates the aforementioned problems with three improvements. First, window relocation was used to reduce the number of poor quality false positives generated during the detection stage. Second, object re-cropping was performed with another deep learning model to adjust poorly centered objects. Third, improved data selection strategies were introduced during the classification stage to reduce the mismatches in training data distributions. ReCasNet was evaluated on two large-scale mitotic figure recognition datasets, canine cutaneous mast cell tumor (CCMCT) and canine mammary carcinoma (CMC), which resulted in up to 4.8% percentage point improvements in the F1 scores for mitotic cell detection and 44.1% reductions in mean absolute percentage error (MAPE) for MC prediction. Techniques that underlie ReCasNet can be generalized to other two-stage object detection networks and should contribute to improving the performances of deep learning models in broad digital pathology applications.
On the Suitability of Neural Networks as Building Blocks for The Design of Efficient Learned Indexes
Feb 21, 2022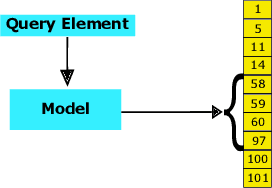
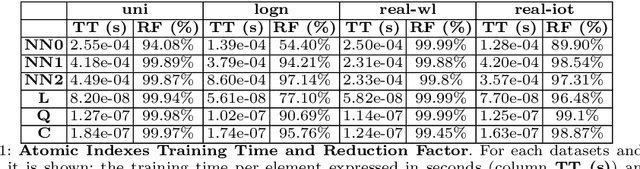


With the aim of obtaining time/space improvements in classic Data Structures, an emerging trend is to combine Machine Learning techniques with the ones proper of Data Structures. This new area goes under the name of Learned Data Structures. The motivation for its study is a perceived change of paradigm in Computer Architectures that would favour the use of Graphics Processing Units and Tensor Processing Units over conventional Central Processing Units. In turn, that would favour the use of Neural Networks as building blocks of Classic Data Structures. Indeed, Learned Bloom Filters, which are one of the main pillars of Learned Data Structures, make extensive use of Neural Networks to improve the performance of classic Filters. However, no use of Neural Networks is reported in the realm of Learned Indexes, which is another main pillar of that new area. In this contribution, we provide the first, and much needed, comparative experimental analysis regarding the use of Neural Networks as building blocks of Learned Indexes. The results reported here highlight the need for the design of very specialized Neural Networks tailored to Learned Indexes and it establishes a solid ground for those developments. Our findings, methodologically important, are of interest to both Scientists and Engineers working in Neural Networks Design and Implementation, in view also of the importance of the application areas involved, e.g., Computer Networks and Data Bases.
Temporal Walk Centrality: Ranking Nodes in Evolving Networks
Feb 08, 2022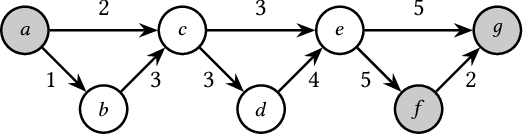



We propose the Temporal Walk Centrality, which quantifies the importance of a node by measuring its ability to obtain and distribute information in a temporal network. In contrast to the widely-used betweenness centrality, we assume that information does not necessarily spread on shortest paths but on temporal random walks that satisfy the time constraints of the network. We show that temporal walk centrality can identify nodes playing central roles in dissemination processes that might not be detected by related betweenness concepts and other common static and temporal centrality measures. We propose exact and approximation algorithms with different running times depending on the properties of the temporal network and parameters of our new centrality measure. A technical contribution is a general approach to lift existing algebraic methods for counting walks in static networks to temporal networks. Our experiments on real-world temporal networks show the efficiency and accuracy of our algorithms. Finally, we demonstrate that the rankings by temporal walk centrality often differ significantly from those of other state-of-the-art temporal centralities.
Enabling On-Device Smartphone GPU based Training: Lessons Learned
Feb 21, 2022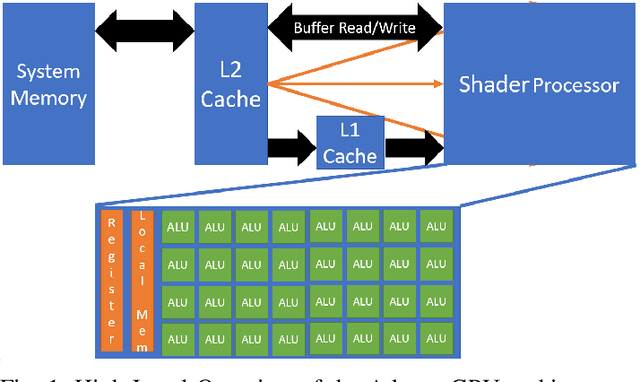
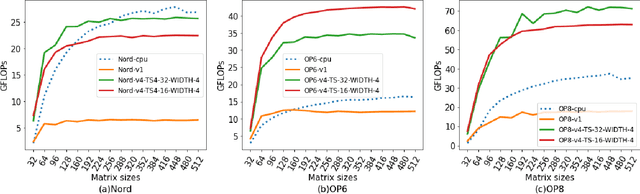
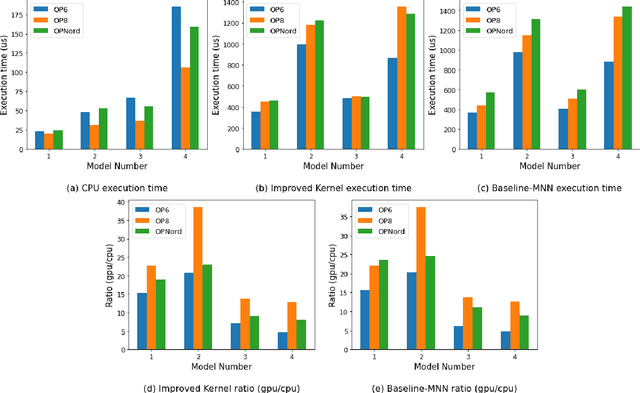
Deep Learning (DL) has shown impressive performance in many mobile applications. Most existing works have focused on reducing the computational and resource overheads of running Deep Neural Networks (DNN) inference on resource-constrained mobile devices. However, the other aspect of DNN operations, i.e. training (forward and backward passes) on smartphone GPUs, has received little attention thus far. To this end, we conduct an initial analysis to examine the feasibility of on-device training on smartphones using mobile GPUs. We first employ the open-source mobile DL framework (MNN) and its OpenCL backend for running compute kernels on GPUs. Next, we observed that training on CPUs is much faster than on GPUs and identified two possible bottlenecks related to this observation: (i) computation and (ii) memory bottlenecks. To solve the computation bottleneck, we optimize the OpenCL backend's kernels, showing 2x improvements (40-70 GFLOPs) over CPUs (15-30 GFLOPs) on the Snapdragon 8 series processors. However, we find that the full DNN training is still much slower on GPUs than on CPUs, indicating that memory bottleneck plays a significant role in the lower performance of GPU over CPU. The data movement takes almost 91% of training time due to the low bandwidth. Lastly, based on the findings and failures during our investigation, we present limitations and practical guidelines for future directions.
Generative GaitNet
Jan 28, 2022
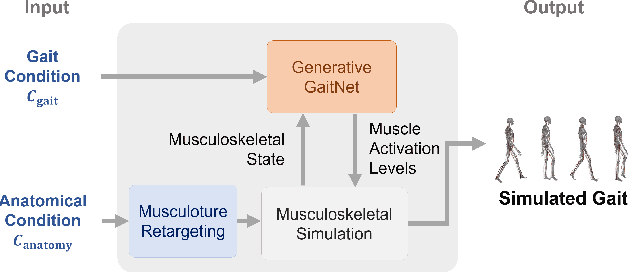
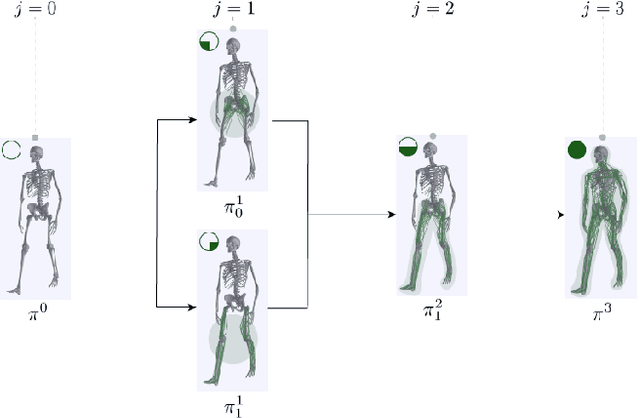
Understanding the relation between anatomy andgait is key to successful predictive gait simulation. Inthis paper, we present Generative GaitNet, which isa novel network architecture based on deep reinforce-ment learning for controlling a comprehensive, full-body, musculoskeletal model with 304 Hill-type mus-culotendons. The Generative Gait is a pre-trained, in-tegrated system of artificial neural networks learnedin a 618-dimensional continuous domain of anatomyconditions (e.g., mass distribution, body proportion,bone deformity, and muscle deficits) and gait condi-tions (e.g., stride and cadence). The pre-trained Gait-Net takes anatomy and gait conditions as input andgenerates a series of gait cycles appropriate to theconditions through physics-based simulation. We willdemonstrate the efficacy and expressive power of Gen-erative GaitNet to generate a variety of healthy andpathologic human gaits in real-time physics-based sim-ulation.
A Pilot Study on Visually-Stimulated Cognitive Tasks for EEG-Based Dementia Recognition Using Frequency and Time Features
Mar 05, 2021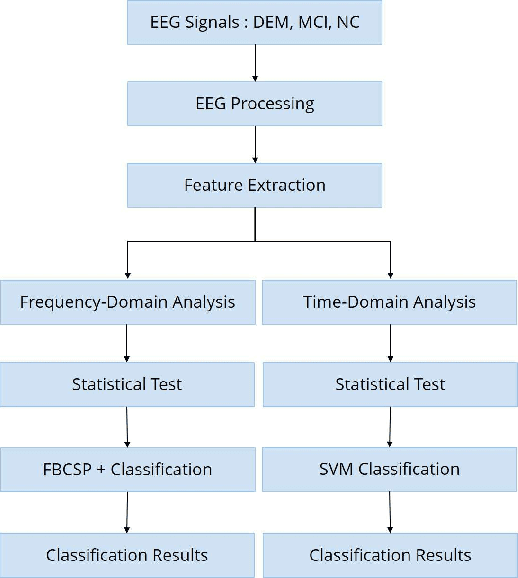
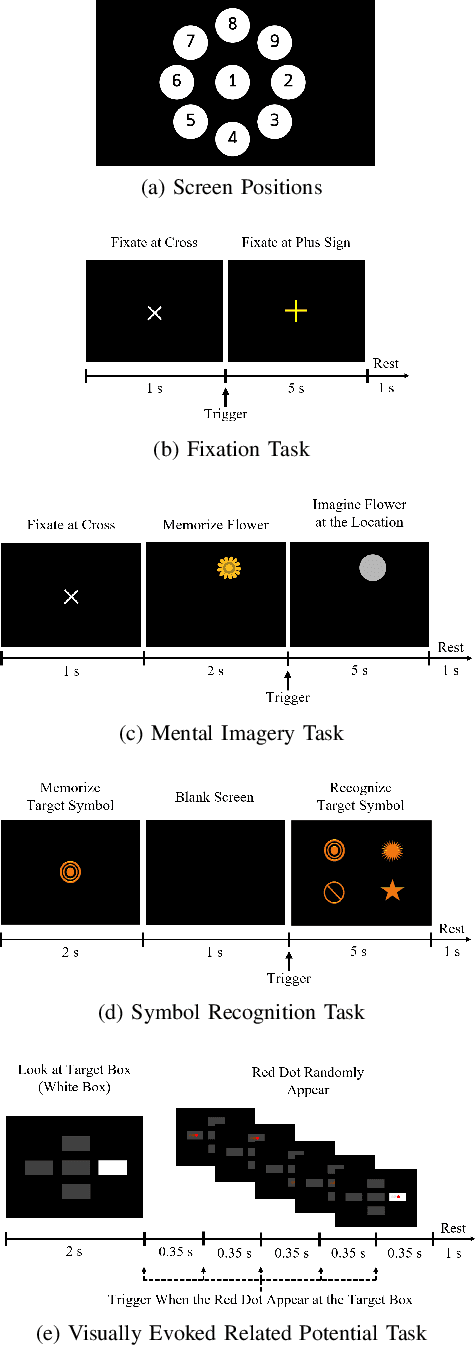
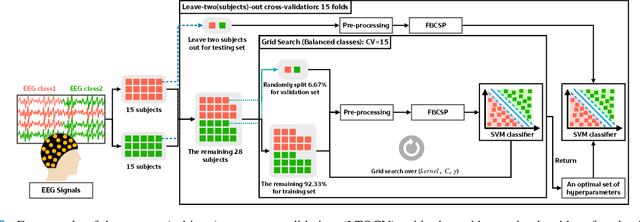
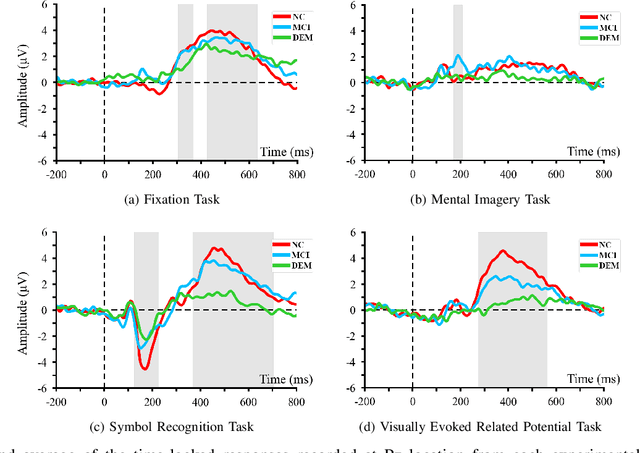
Dementia is one of the main causes of cognitive decline. Since the majority of dementia patients cannot be cured, being able to diagnose them before the onset of the symptoms can prevent the rapid progression of the cognitive impairment. This study aims to investigate the difference in the Electroencephalograph (EEG) signals of three groups of subjects: Normal Control (NC), Mild Cognitive Impairment (MCI), and Dementia (DEM). Unlike previous works that focus on the diagnosis of Alzheimer's disease (AD) from EEG signals, we study the detection of dementia to generalize the classification models to other types of dementia. We have developed a pilot study on machine learning-based dementia diagnosis using EEG signals from four visual stimulation tasks (Fixation, Mental Imagery, Symbol Recognition, and Visually Evoked Related Potential) to identify the most suitable task and method to detect dementia using EEG signals. We extracted both frequency and time domain features from the EEG signals and applied a Support Vector Machine (SVM) for each domain to classify the patients using those extracted features. Additionally, we study the feasibility of the Filter Bank Common Spatial Pattern (FBCSP) algorithm to extract features from the frequency domain to detect dementia. The evaluation of the model shows that the tasks that test the working memory are the most appropriate to detect dementia using EEG signals in both time and frequency domain analysis. However, the best results in both domains are obtained by combining features of all four cognitive tasks.
Making the most of your day: online learning for optimal allocation of time
Feb 16, 2021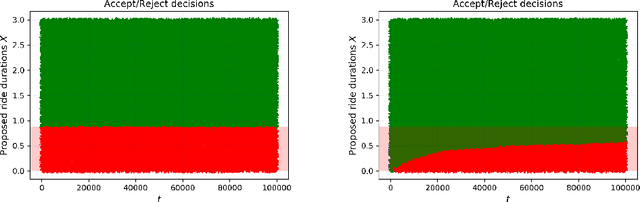
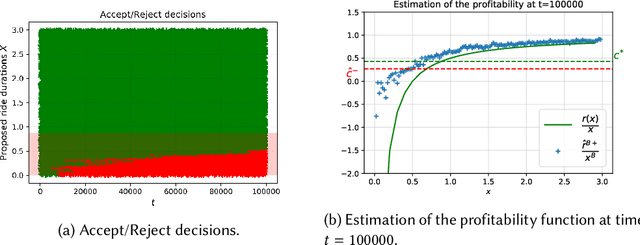
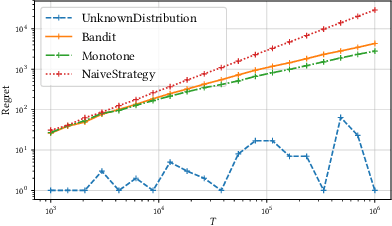
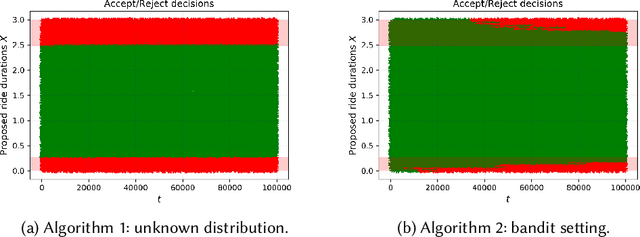
We study online learning for optimal allocation when the resource to be allocated is time. Examples of possible applications include a driver filling a day with rides, a landlord renting an estate, etc. Following our initial motivation, a driver receives ride proposals sequentially according to a Poisson process and can either accept or reject a proposed ride. If she accepts the proposal, she is busy for the duration of the ride and obtains a reward that depends on the ride duration. If she rejects it, she remains on hold until a new ride proposal arrives. We study the regret incurred by the driver first when she knows her reward function but does not know the distribution of the ride duration, and then when she does not know her reward function, either. Faster rates are finally obtained by adding structural assumptions on the distribution of rides or on the reward function. This natural setting bears similarities with contextual (one-armed) bandits, but with the crucial difference that the normalized reward associated to a context depends on the whole distribution of contexts.