 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashSAC: Fast and Stable Off-Policy Reinforcement Learning for High-Dimensional Robot Control
Apr 06, 2026Reinforcement learning (RL) is a core approach for robot control when expert demonstrations are unavailable. On-policy methods such as Proximal Policy Optimization (PPO) are widely used for their stability, but their reliance on narrowly distributed on-policy data limits accurate policy evaluation in high-dimensional state and action spaces. Off-policy methods can overcome this limitation by learning from a broader state-action distribution, yet suffer from slow convergence and instability, as fitting a value function over diverse data requires many gradient updates, causing critic errors to accumulate through bootstrapping. We present FlashSAC, a fast and stable off-policy RL algorithm built on Soft Actor-Critic. Motivated by scaling laws observed in supervised learning, FlashSAC sharply reduces gradient updates while compensating with larger models and higher data throughput. To maintain stability at increased scale, FlashSAC explicitly bounds weight, feature, and gradient norms, curbing critic error accumulation. Across over 60 tasks in 10 simulators, FlashSAC consistently outperforms PPO and strong off-policy baselines in both final performance and training efficiency, with the largest gains on high-dimensional tasks such as dexterous manipulation. In sim-to-real humanoid locomotion, FlashSAC reduces training time from hours to minutes, demonstrating the promise of off-policy RL for sim-to-real transfer.
Belief in Authority: Impact of Authority in Multi-Agent Evaluation Framework
Jan 08, 2026Multi-agent systems utilizing large language models often assign authoritative roles to improve performance, yet the impact of authority bias on agent interactions remains underexplored. We present the first systematic analysis of role-based authority bias in free-form multi-agent evaluation using ChatEval. Applying French and Raven's power-based theory, we classify authoritative roles into legitimate, referent, and expert types and analyze their influence across 12-turn conversations. Experiments with GPT-4o and DeepSeek R1 reveal that Expert and Referent power roles exert stronger influence than Legitimate power roles. Crucially, authority bias emerges not through active conformity by general agents, but through authoritative roles consistently maintaining their positions while general agents demonstrate flexibility. Furthermore, authority influence requires clear position statements, as neutral responses fail to generate bias. These findings provide key insights for designing multi-agent frameworks with asymmetric interaction patterns.
Generative GaitNet
Jan 28, 2022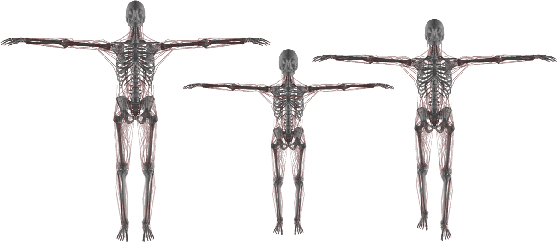
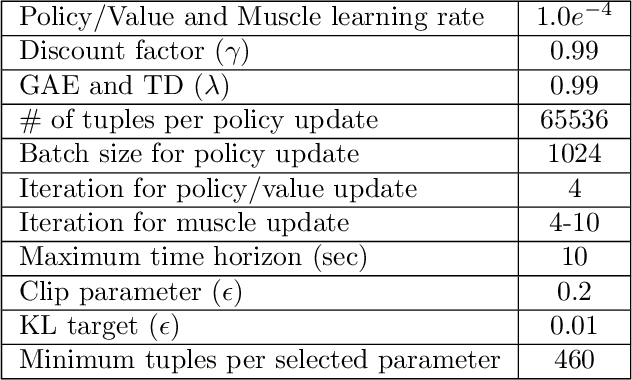
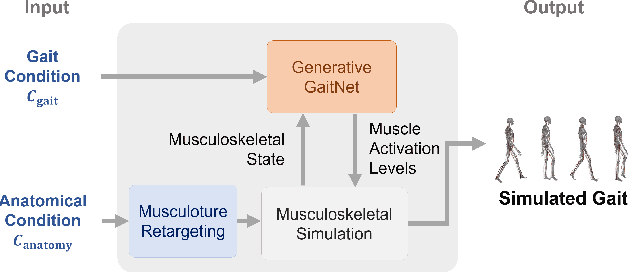
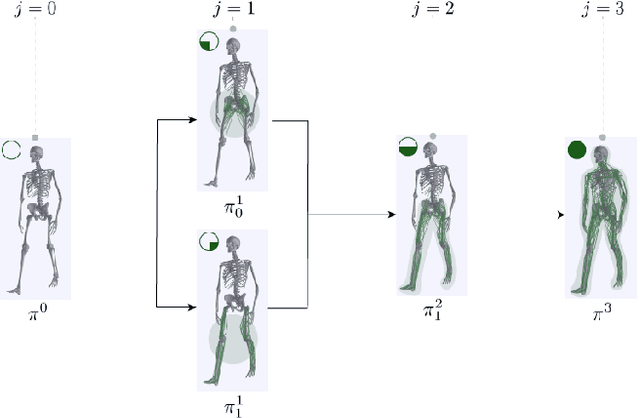
Understanding the relation between anatomy andgait is key to successful predictive gait simulation. Inthis paper, we present Generative GaitNet, which isa novel network architecture based on deep reinforce-ment learning for controlling a comprehensive, full-body, musculoskeletal model with 304 Hill-type mus-culotendons. The Generative Gait is a pre-trained, in-tegrated system of artificial neural networks learnedin a 618-dimensional continuous domain of anatomyconditions (e.g., mass distribution, body proportion,bone deformity, and muscle deficits) and gait condi-tions (e.g., stride and cadence). The pre-trained Gait-Net takes anatomy and gait conditions as input andgenerates a series of gait cycles appropriate to theconditions through physics-based simulation. We willdemonstrate the efficacy and expressive power of Gen-erative GaitNet to generate a variety of healthy andpathologic human gaits in real-time physics-based sim-ulation.