 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat's Cracking? A Review and Analysis of Deep Learning Methods for Structural Crack Segmentation, Detection and Quantification
Feb 08, 2022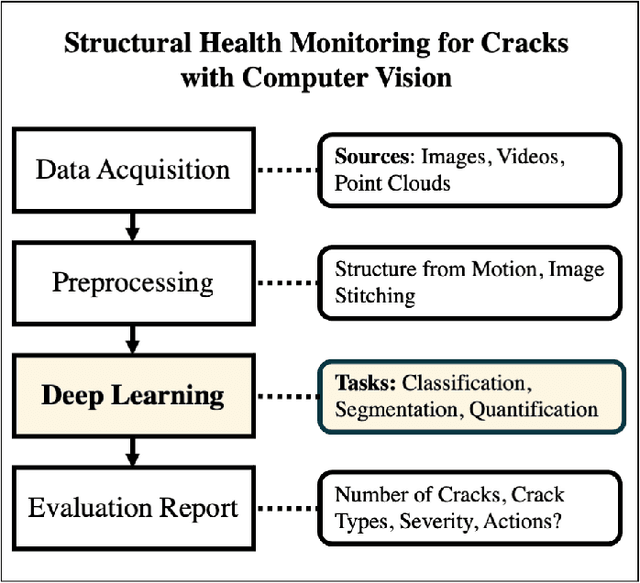
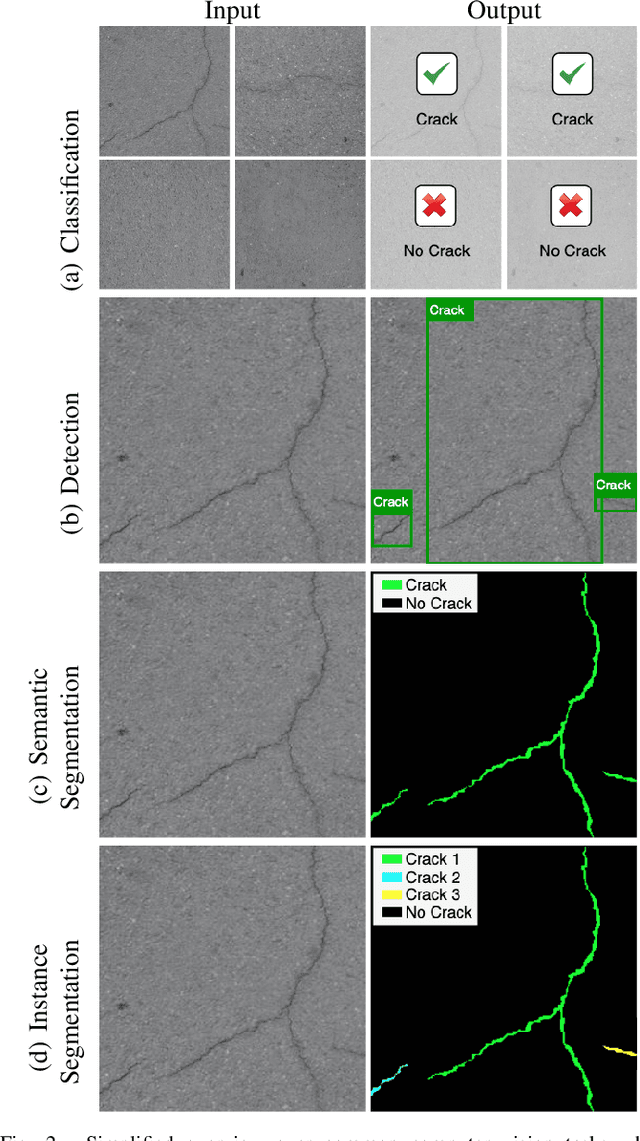


Surface cracks are a very common indicator of potential structural faults. Their early detection and monitoring is an important factor in structural health monitoring. Left untreated, they can grow in size over time and require expensive repairs or maintenance. With recent advances in computer vision and deep learning algorithms, the automatic detection and segmentation of cracks for this monitoring process have become a major topic of interest. This review aims to give researchers an overview of the published work within the field of crack analysis algorithms that make use of deep learning. It outlines the various tasks that are solved through applying computer vision algorithms to surface cracks in a structural health monitoring setting and also provides in-depth reviews of recent fully, semi and unsupervised approaches that perform crack classification, detection, segmentation and quantification. Additionally, this review also highlights popular datasets used for cracks and the metrics that are used to evaluate the performance of those algorithms. Finally, potential research gaps are outlined and further research directions are provided.
A Weakly-Supervised Surface Crack Segmentation Method using Localisation with a Classifier and Thresholding
Sep 03, 2021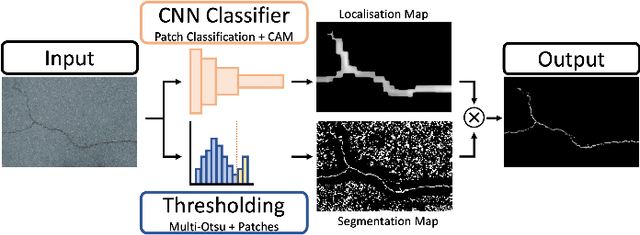



Surface cracks are a common sight on public infrastructure nowadays. Recent work has been addressing this problem by supporting structural maintenance measures using machine learning methods which segment surface cracks from their background so that they are easy to localize. However, a common issue with those methods is that to create a well functioning algorithm, the training data needs to have detailed annotations of pixels that belong to cracks. Our work proposes a weakly supervised approach which leverages a CNN classifier to create surface crack segmentation maps. We use this classifier to create a rough crack localisation map by using its class activation maps and a patch based classification approach and fuse this with a thresholding based approach to segment the mostly darker crack pixels. The classifier assists in suppressing noise from the background regions, which commonly are incorrectly highlighted as cracks by standard thresholding methods. We focus on the ease of implementation of our method and it is shown to perform well on several surface crack datasets, segmenting cracks efficiently even though the only data that was used for training were simple classification labels.
Optimized Deep Encoder-Decoder Methods for Crack Segmentation
Aug 14, 2020

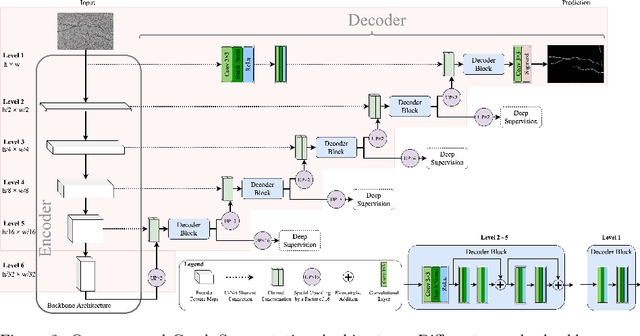

Continuous maintenance of concrete infrastructure is an important task which is needed to continue safe operations of these structures. One kind of defect that occurs on surfaces in these structures are cracks. Automatic detection of those cracks poses a challenging computer vision task as background, shape, colour and size of cracks vary. In this work we propose optimized deep encoder-decoder methods consisting of a combination of techniques which yield an increase in crack segmentation performance. Specifically, we propose a new design for the decoder-part in encoder-decoder based deep learning architectures for semantic segmentation. We study its composition and how to achieve increased performance by exploring components such as deep supervision and upsampling strategies. Then we examine the optimal encoder to go in conjunction with this decoder and determine that pretrained encoders lead to an increase in performance. We propose a data augmentation strategy to increase the amount of available training data and carry out the performance evaluation of the designed architecture on four publicly available crack segmentation datasets. Additionally, we introduce two techniques into the field of surface crack segmentation, previously not used there: Generating results using test-time-augmentation and performing a statistical result analysis over multiple training runs. The former approach generally yields increased performance results, whereas the latter allows for more reproducible and better representability of a methods results. Using those aforementioned strategies with our proposed encoder-decoder architecture we are able to achieve new state of the art results in all datasets.