 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Spatiotemporal Analysis Using Riemannian Composition of Diffusion Operators
Jan 21, 2022
Multivariate time-series have become abundant in recent years, as many data-acquisition systems record information through multiple sensors simultaneously. In this paper, we assume the variables pertain to some geometry and present an operator-based approach for spatiotemporal analysis. Our approach combines three components that are often considered separately: (i) manifold learning for building operators representing the geometry of the variables, (ii) Riemannian geometry of symmetric positive-definite matrices for multiscale composition of operators corresponding to different time samples, and (iii) spectral analysis of the composite operators for extracting different dynamic modes. We propose a method that is analogous to the classical wavelet analysis, which we term Riemannian multi-resolution analysis (RMRA). We provide some theoretical results on the spectral analysis of the composite operators, and we demonstrate the proposed method on simulations and on real data.
A Robust Optimization Method for Label Noisy Datasets Based on Adaptive Threshold: Adaptive-k
Mar 26, 2022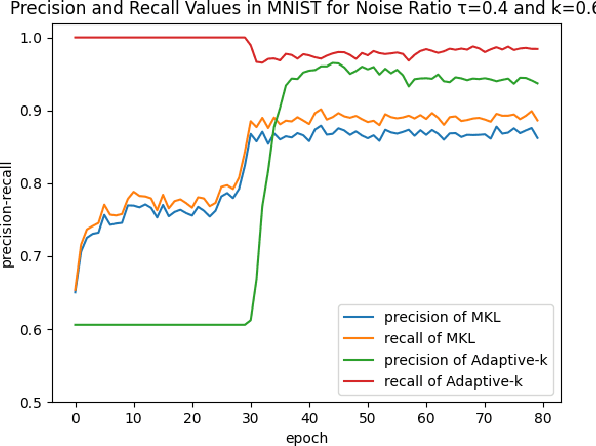
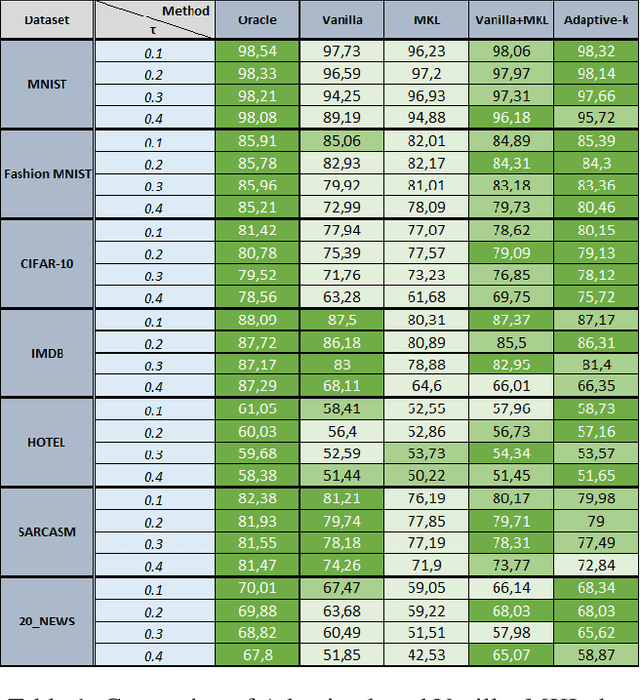
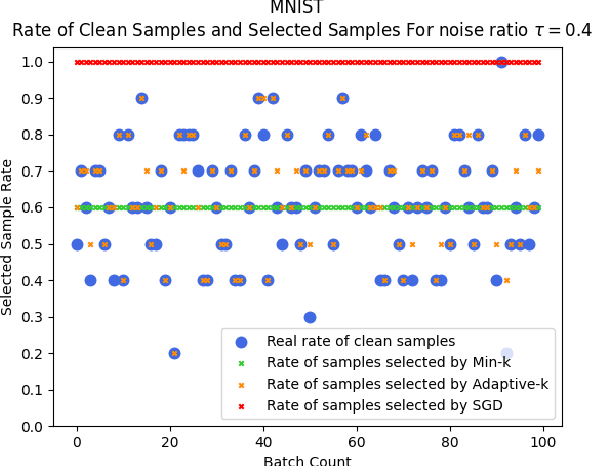
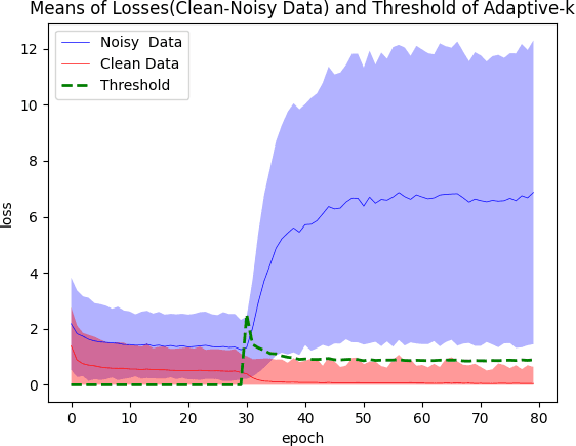
SGD does not produce robust results on datasets with label noise. Because the gradients calculated according to the losses of the noisy samples cause the optimization process to go in the wrong direction. In this paper, as an alternative to SGD, we recommend using samples with loss less than a threshold value determined during the optimization process, instead of using all samples in the mini-batch. Our proposed method, Adaptive-k, aims to exclude label noise samples from the optimization process and make the process robust. On noisy datasets, we found that using a threshold-based approach, such as Adaptive-k, produces better results than using all samples or a fixed number of low-loss samples in the mini-batch. Based on our theoretical analysis and experimental results, we show that the Adaptive-k method is closest to the performance of the oracle, in which noisy samples are entirely removed from the dataset. Adaptive-k is a simple but effective method. It does not require prior knowledge of the noise ratio of the dataset, does not require additional model training, and does not increase training time significantly. The code for Adaptive-k is available at https://github.com/enesdedeoglu-TR/Adaptive-k
A Weakly Supervised Propagation Model for Rumor Verification and Stance Detection with Multiple Instance Learning
Apr 06, 2022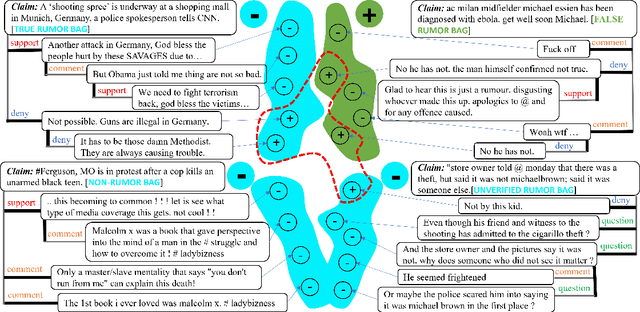
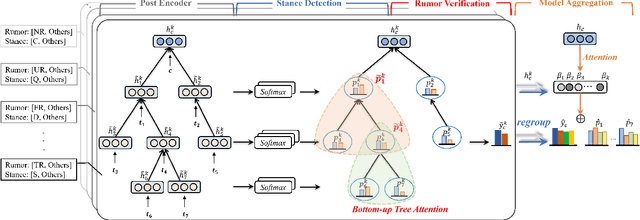
The diffusion of rumors on microblogs generally follows a propagation tree structure, that provides valuable clues on how an original message is transmitted and responded by users over time. Recent studies reveal that rumor detection and stance detection are two different but relevant tasks which can jointly enhance each other, e.g., rumors can be debunked by cross-checking the stances conveyed by their relevant microblog posts, and stances are also conditioned on the nature of the rumor. However, most stance detection methods require enormous post-level stance labels for training, which are labor-intensive given a large number of posts. Enlightened by Multiple Instance Learning (MIL) scheme, we first represent the diffusion of claims with bottom-up and top-down trees, then propose two tree-structured weakly supervised frameworks to jointly classify rumors and stances, where only the bag-level labels concerning claim's veracity are needed. Specifically, we convert the multi-class problem into a multiple MIL-based binary classification problem where each binary model focuses on differentiating a target stance or rumor type and other types. Finally, we propose a hierarchical attention mechanism to aggregate the binary predictions, including (1) a bottom-up or top-down tree attention layer to aggregate binary stances into binary veracity; and (2) a discriminative attention layer to aggregate the binary class into finer-grained classes. Extensive experiments conducted on three Twitter-based datasets demonstrate promising performance of our model on both claim-level rumor detection and post-level stance classification compared with state-of-the-art methods.
Machine Learning Testing in an ADAS Case Study Using Simulation-Integrated Bio-Inspired Search-Based Testing
Mar 22, 2022
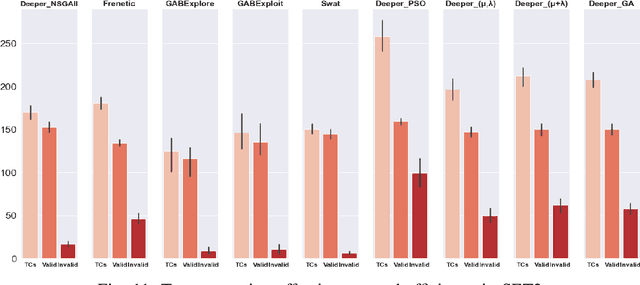
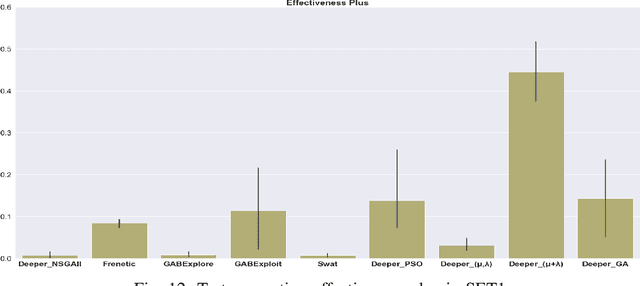
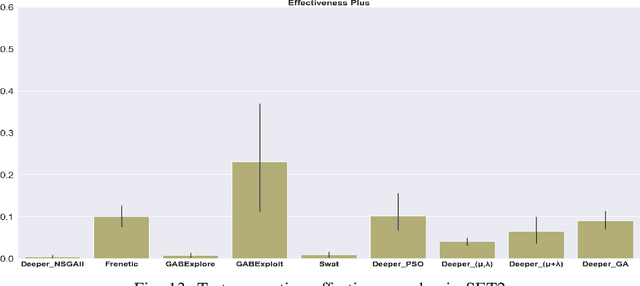
This paper presents an extended version of Deeper, a search-based simulation-integrated test solution that generates failure-revealing test scenarios for testing a deep neural network-based lane-keeping system. In the newly proposed version, we utilize a new set of bio-inspired search algorithms, genetic algorithm (GA), $({\mu}+{\lambda})$ and $({\mu},{\lambda})$ evolution strategies (ES), and particle swarm optimization (PSO), that leverage a quality population seed and domain-specific cross-over and mutation operations tailored for the presentation model used for modeling the test scenarios. In order to demonstrate the capabilities of the new test generators within Deeper, we carry out an empirical evaluation and comparison with regard to the results of five participating tools in the cyber-physical systems testing competition at SBST 2021. Our evaluation shows the newly proposed test generators in Deeper not only represent a considerable improvement on the previous version but also prove to be effective and efficient in provoking a considerable number of diverse failure-revealing test scenarios for testing an ML-driven lane-keeping system. They can trigger several failures while promoting test scenario diversity, under a limited test time budget, high target failure severity, and strict speed limit constraints.
Real-Time Wave Mitigation for Water-Air OWC Systems Via Beam Tracking
Oct 16, 2021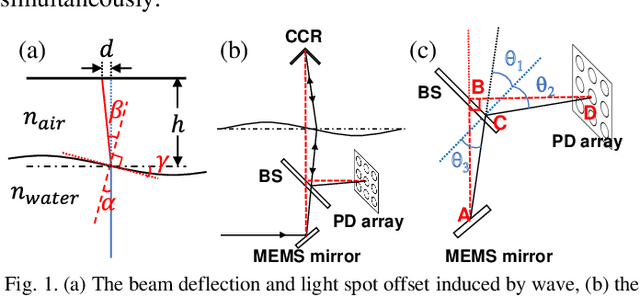
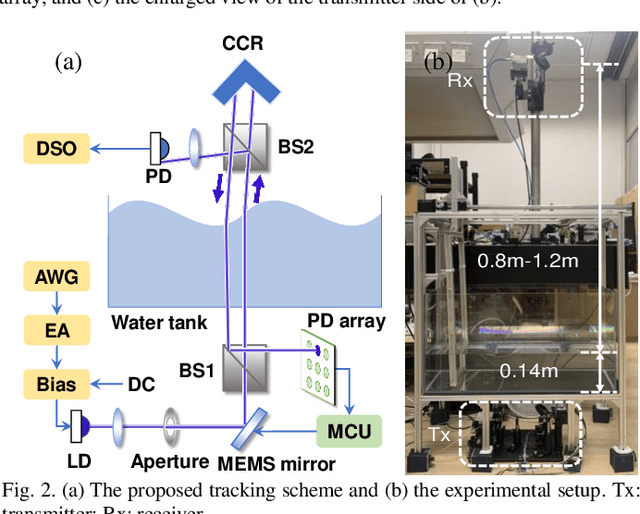
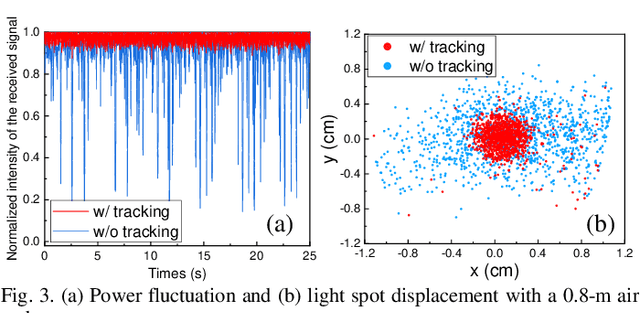
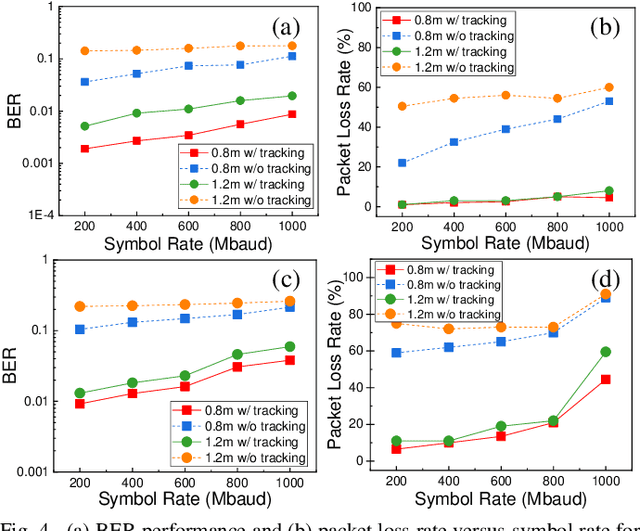
In a water-air optical wireless communication (OWC) channel, dynamic ocean waves may significantly deflect the light beam from its original direction, thus deteriorating the communication performance. In this letter, a beam tracking system to mitigate wave-induced communication degradation is experimentally demonstrated. By employing the beam tracking on the PAM6 system, a maximum of 486% improvement (from 140 Mb/s to 820 Mb/s) in throughput is realized at a 1.2-m air distance for an average wave slope changing rate of 0.34 rad/s. For PAM4 signals, the packet loss rate reduces significantly from 75% to 11%, and a maximum throughput of 1.25 Gb/s is achieved.
Time-Correlated Sparsification for Communication-Efficient Federated Learning
Jan 21, 2021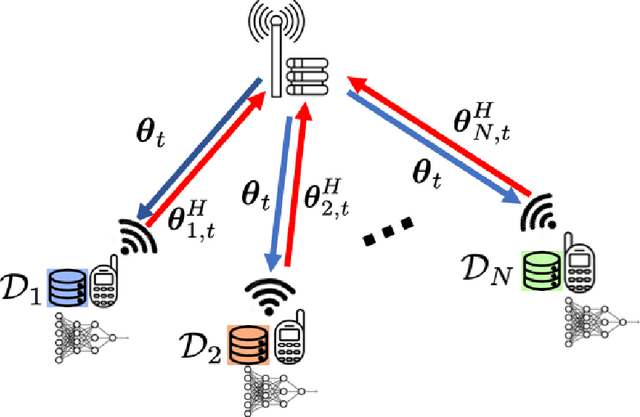
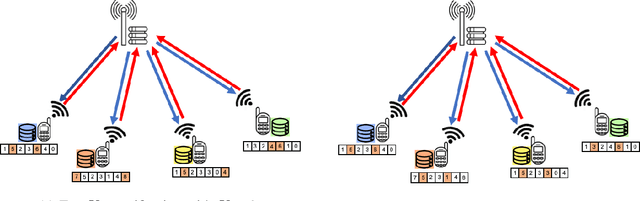
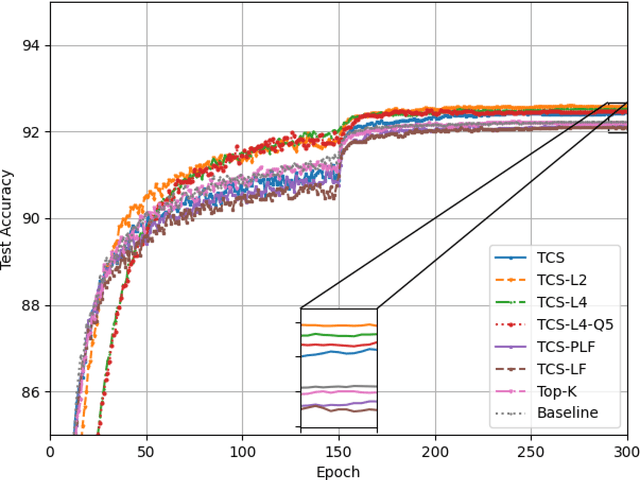
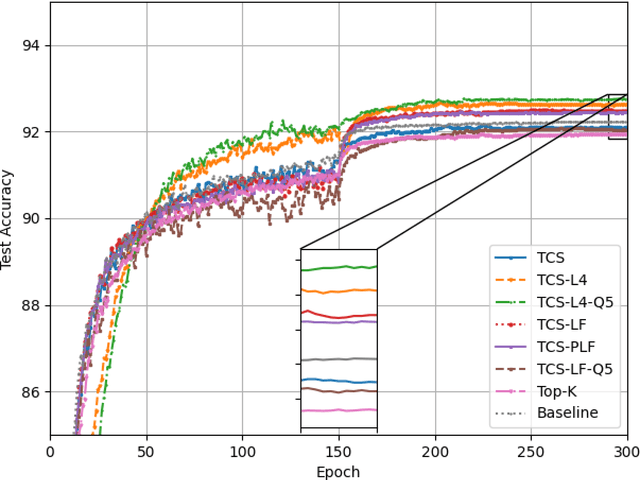
Federated learning (FL) enables multiple clients to collaboratively train a shared model without disclosing their local datasets. This is achieved by exchanging local model updates with the help of a parameter server (PS). However, due to the increasing size of the trained models, the communication load due to the iterative exchanges between the clients and the PS often becomes a bottleneck in the performance. Sparse communication is often employed to reduce the communication load, where only a small subset of the model updates are communicated from the clients to the PS. In this paper, we introduce a novel time-correlated sparsification (TCS) scheme, which builds upon the notion that sparse communication framework can be considered as identifying the most significant elements of the underlying model. Hence, TCS seeks a certain correlation between the sparse representations used at consecutive iterations in FL, so that the overhead due to encoding and transmission of the sparse representation can be significantly reduced without compromising the test accuracy. Through extensive simulations on the CIFAR-10 dataset, we show that TCS can achieve centralized training accuracy with 100 times sparsification, and up to 2000 times reduction in the communication load when employed together with quantization.
Reinforcement Learning Approach to Clear Paths of Robots in Elevator Environment
Mar 18, 2022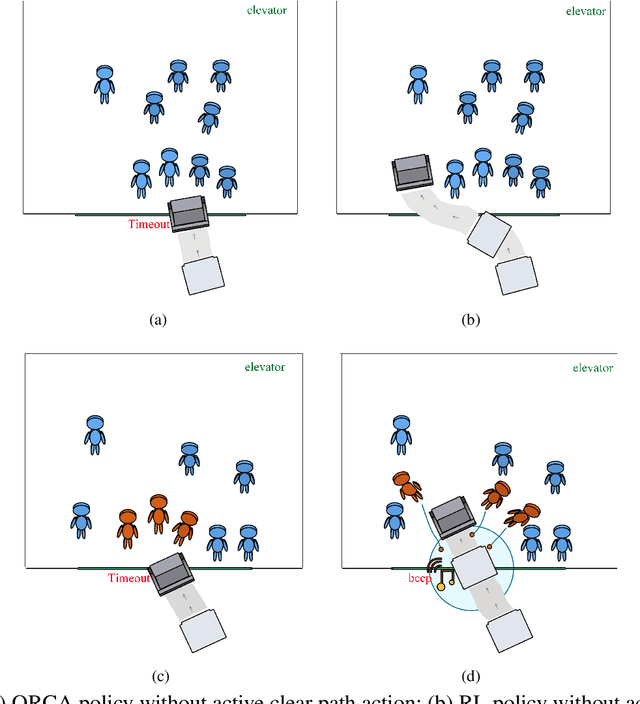
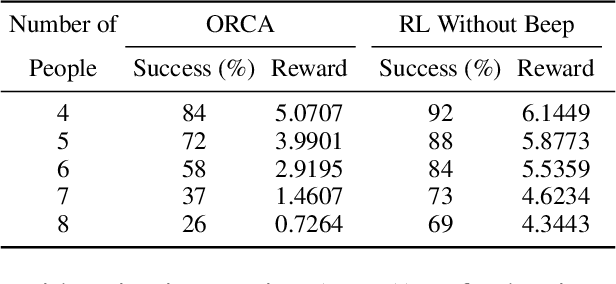
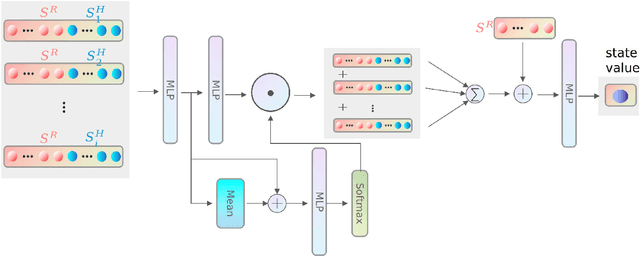
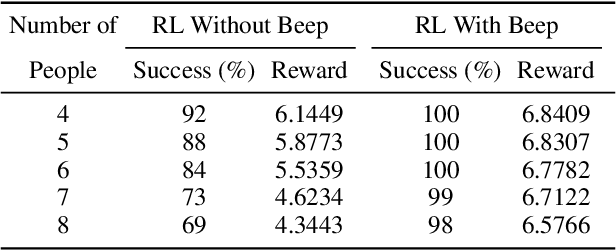
Efficiently using the space of an elevator for a service robot is very necessary, due to the need for reducing the amount of time caused by waiting for the next elevator. To solve this, we propose a hybrid approach that combines reinforcement learning (RL) with voice interaction for robot navigation in the scene of entering the elevator. RL provides robots with a high exploration ability to find a new clear path to enter the elevator compared to the traditional navigation methods such as Optimal Reciprocal Collision Avoidance (ORCA). The proposed method allows the robot to take an active clear path action towards the elevator whilst a crowd of people stands at the entrance of the elevator wherein there are still lots of space. This is done by embedding a clear path action (beep) into the RL framework, and the proposed navigation policy leads the robot to finish tasks efficiently and safely. Our model approach provides a great improvement in the success rate and reward of entering the elevator compared to state-of-the-art ORCA and RL navigation policy without beep.
Information-Theoretic Odometry Learning
Mar 11, 2022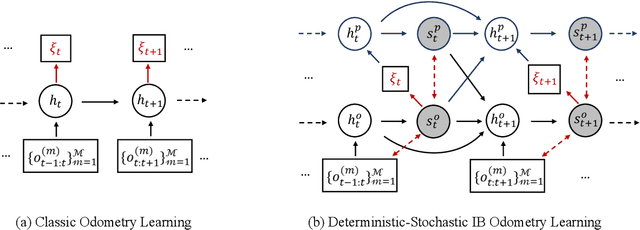
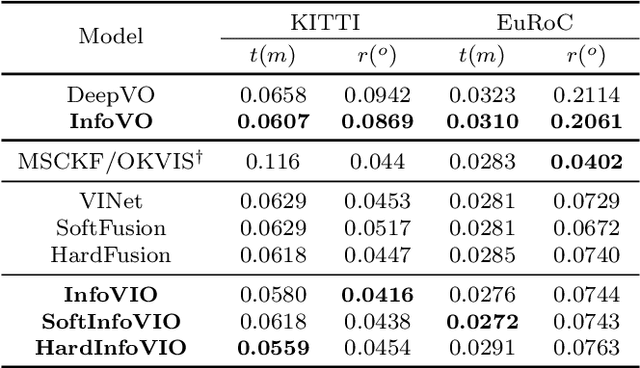
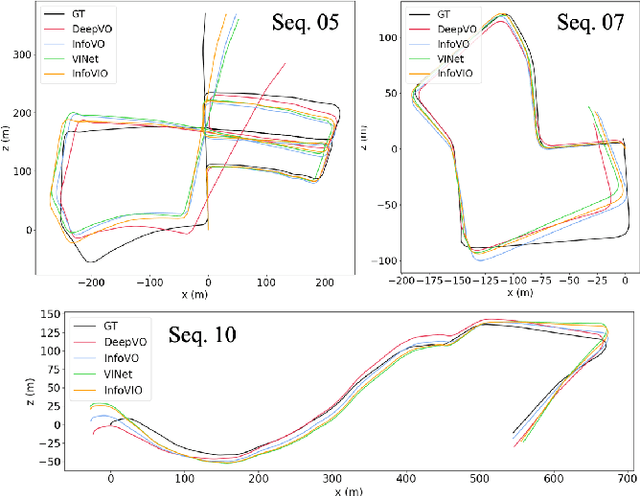
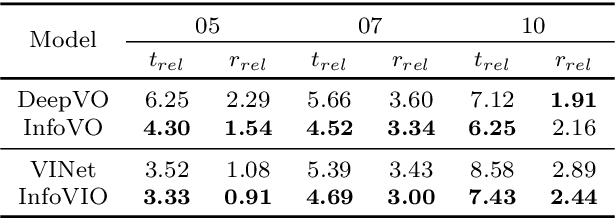
In this paper, we propose a unified information theoretic framework for learning-motivated methods aimed at odometry estimation, a crucial component of many robotics and vision tasks such as navigation and virtual reality where relative camera poses are required in real time. We formulate this problem as optimizing a variational information bottleneck objective function, which eliminates pose-irrelevant information from the latent representation. The proposed framework provides an elegant tool for performance evaluation and understanding in information-theoretic language. Specifically, we bound the generalization errors of the deep information bottleneck framework and the predictability of the latent representation. These provide not only a performance guarantee but also practical guidance for model design, sample collection, and sensor selection. Furthermore, the stochastic latent representation provides a natural uncertainty measure without the needs for extra structures or computations. Experiments on two well-known odometry datasets demonstrate the effectiveness of our method.
Iterative Refinement for Real-Time Multi-Robot Path Planning
Feb 24, 2021
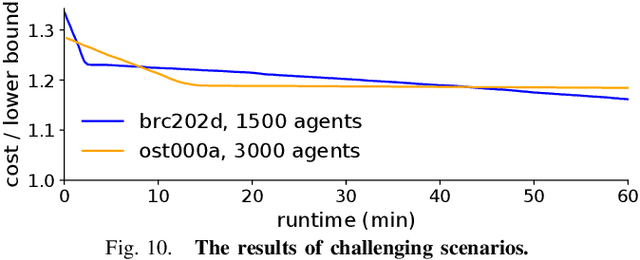
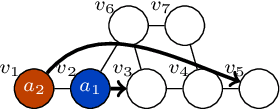
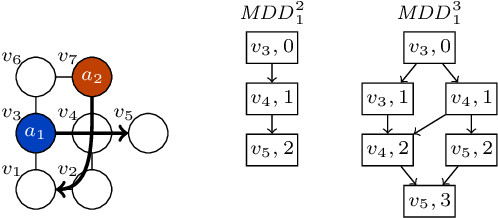
We study the iterative refinement of path planning for multiple robots, known as multi-agent pathfinding (MAPF). Given a graph, agents, their initial locations, and destinations, a solution of MAPF is a set of paths without collisions. Iterative refinement for MAPF is desirable for three reasons: 1) optimization is intractable, 2) sub-optimal solutions can be obtained instantly, and 3) it is anytime planning, desired in online scenarios where time for deliberation is limited. Despite the high demand, this is under-explored in MAPF because finding good neighborhoods has been unclear so far. Our proposal uses a sub-optimal MAPF solver to obtain an initial solution quickly, then iterates the two procedures: 1) select a subset of agents, 2) use an optimal MAPF solver to refine paths of selected agents while keeping other paths unchanged. Since the optimal solvers are used on small instances of the problem, this scheme yields efficient-enough solutions rapidly while providing high scalability. We also present reasonable candidates on how to select a subset of agents. Evaluations in various scenarios show that the proposal is promising; the convergence is fast, scalable, with reasonable quality, and practical because it can be interrupted whenever the solution is needed.
Reinforcement-learning calibration of coherent-state receivers on variable-loss optical channels
Mar 18, 2022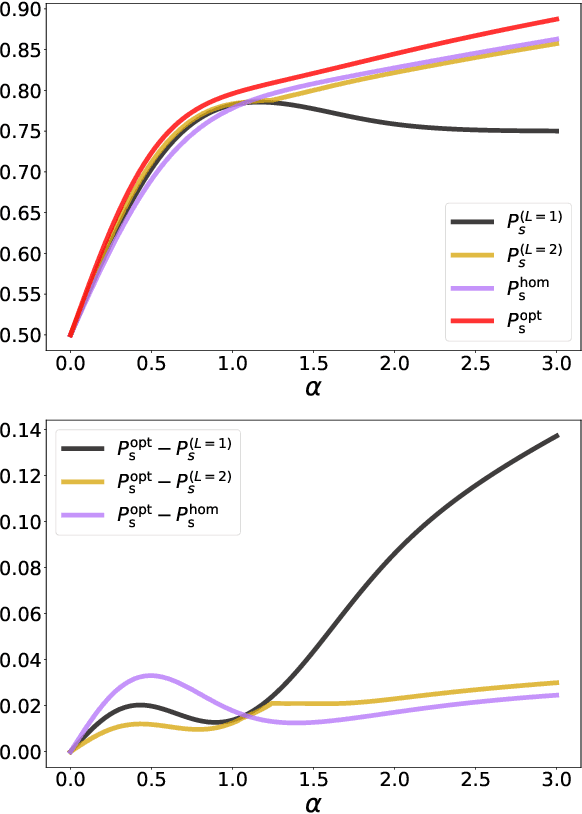

We study the problem of calibrating a quantum receiver for optical coherent states when transmitted on a quantum optical channel with variable transmissivity, a common model for long-distance optical-fiber and free/deep-space optical communication. We optimize the error probability of legacy adaptive receivers, such as Kennedy's and Dolinar's, on average with respect to the channel transmissivity distribution. We then compare our results with the ultimate error probability attainable by a general quantum device, computing the Helstrom bound for mixtures of coherent-state hypotheses, for the first time to our knowledge, and with homodyne measurements. With these tools, we first analyze the simplest case of two different transmissivity values; we find that the strategies adopted by adaptive receivers exhibit strikingly new features as the difference between the two transmissivities increases. Finally, we employ a recently introduced library of shallow reinforcement learning methods, demonstrating that an intelligent agent can learn the optimal receiver setup from scratch by training on repeated communication episodes on the channel with variable transmissivity and receiving rewards if the coherent-state message is correctly identified.