 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Colon Nuclei Instance Segmentation using a Probabilistic Two-Stage Detector
Mar 01, 2022

Cancer is one of the leading causes of death in the developed world. Cancer diagnosis is performed through the microscopic analysis of a sample of suspicious tissue. This process is time consuming and error prone, but Deep Learning models could be helpful for pathologists during cancer diagnosis. We propose to change the CenterNet2 object detection model to also perform instance segmentation, which we call SegCenterNet2. We train SegCenterNet2 in the CoNIC challenge dataset and show that it performs better than Mask R-CNN in the competition metrics.
A single Long Short-Term Memory network for enhancing the prediction of path-dependent plasticity with material heterogeneity and anisotropy
Apr 05, 2022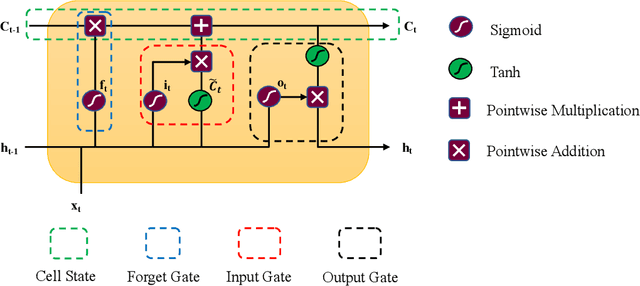

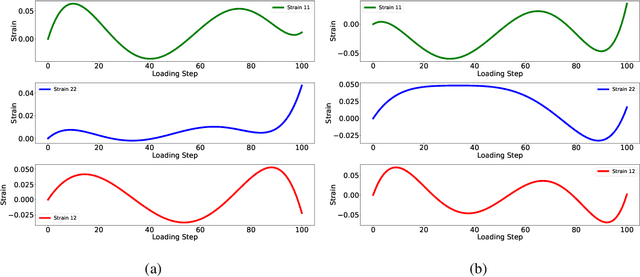

This study presents the applicability of conventional deep recurrent neural networks (RNN) to predict path-dependent plasticity associated with material heterogeneity and anisotropy. Although the architecture of RNN possesses inductive biases toward information over time, it is still challenging to learn the path-dependent material behavior as a function of the loading path considering the change from elastic to elastoplastic regimes. Our attempt is to develop a simple machine-learning-based model that can replicate elastoplastic behaviors considering material heterogeneity and anisotropy. The basic Long-Short Term Memory Unit (LSTM) is adopted for the modeling of plasticity in the two-dimensional space by enhancing the inductive bias toward the past information through manipulating input variables. Our results find that a single LSTM based model can capture the J2 plasticity responses under both monotonic and arbitrary loading paths provided the material heterogeneity. The proposed neural network architecture is then used to model elastoplastic responses of a two-dimensional transversely anisotropic material associated with computational homogenization (FE2). It is also found that a single LSTM model can be used to accurately and effectively capture the path-dependent responses of heterogeneous and anisotropic microstructures under arbitrary mechanical loading conditions.
Scalable Whitebox Attacks on Tree-based Models
Mar 31, 2022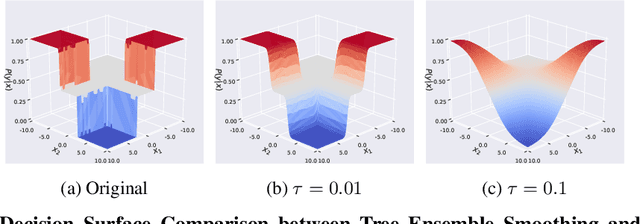
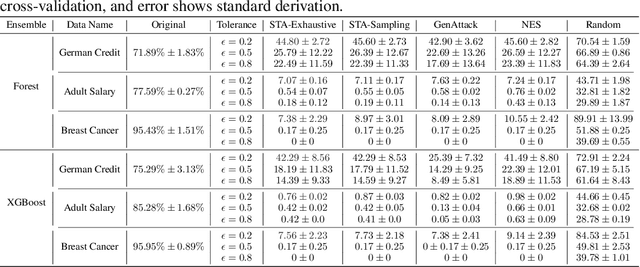
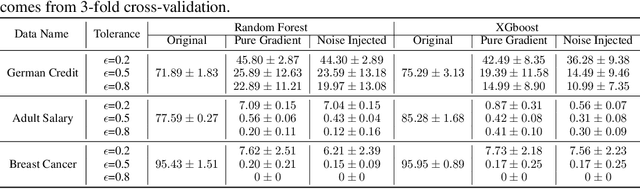
Adversarial robustness is one of the essential safety criteria for guaranteeing the reliability of machine learning models. While various adversarial robustness testing approaches were introduced in the last decade, we note that most of them are incompatible with non-differentiable models such as tree ensembles. Since tree ensembles are widely used in industry, this reveals a crucial gap between adversarial robustness research and practical applications. This paper proposes a novel whitebox adversarial robustness testing approach for tree ensemble models. Concretely, the proposed approach smooths the tree ensembles through temperature controlled sigmoid functions, which enables gradient descent-based adversarial attacks. By leveraging sampling and the log-derivative trick, the proposed approach can scale up to testing tasks that were previously unmanageable. We compare the approach against both random perturbations and blackbox approaches on multiple public datasets (and corresponding models). Our results show that the proposed method can 1) successfully reveal the adversarial vulnerability of tree ensemble models without causing computational pressure for testing and 2) flexibly balance the search performance and time complexity to meet various testing criteria.
A Reinforcement Learning Approach to Sensing Design in Resource-Constrained Wireless Networked Control Systems
Apr 05, 2022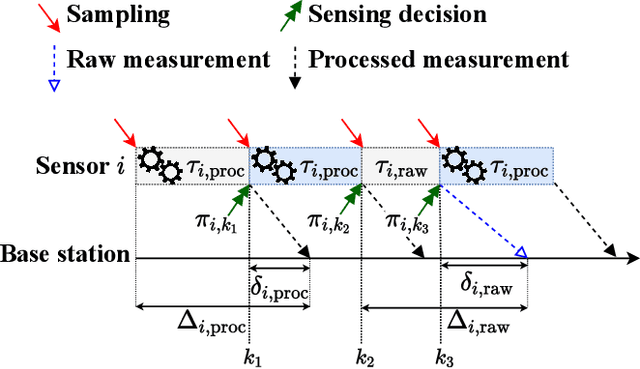
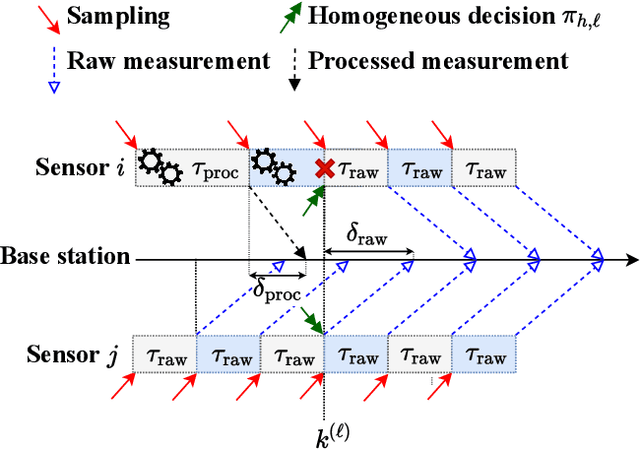
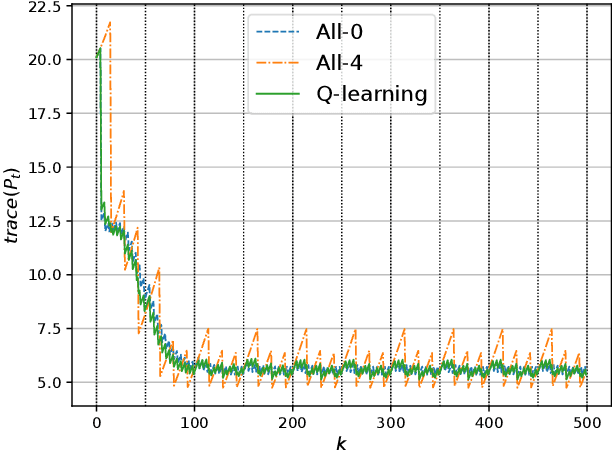
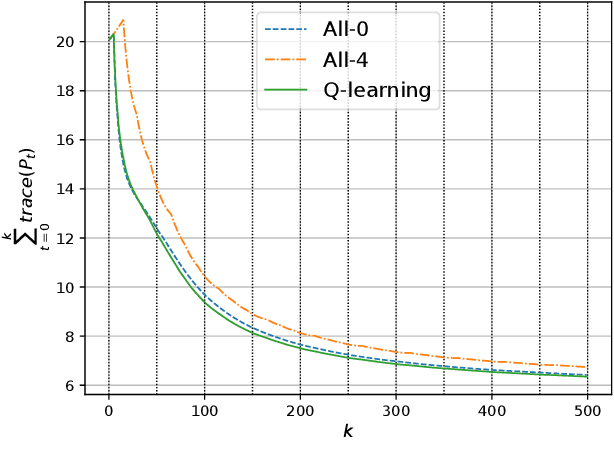
In this paper, we consider a wireless network of smart sensors (agents) that monitor a dynamical process and send measurements to a base station that performs global monitoring and decision-making. Smart sensors are equipped with both sensing and computation, and can either send raw measurements or process them prior to transmission. Constrained agent resources raise a fundamental latency-accuracy trade-off. On the one hand, raw measurements are inaccurate but fast to produce. On the other hand, data processing on resource-constrained platforms generates accurate measurements at the cost of non-negligible computation latency. Further, if processed data are also compressed, latency caused by wireless communication might be higher for raw measurements. Hence, it is challenging to decide when and where sensors in the network should transmit raw measurements or leverage time-consuming local processing. To tackle this design problem, we propose a Reinforcement Learning approach to learn an efficient policy that dynamically decides when measurements are to be processed at each sensor. Effectiveness of our proposed approach is validated through a numerical simulation with case study on smart sensing motivated by the Internet of Drones.
Active-learning-based non-intrusive Model Order Reduction
Apr 08, 2022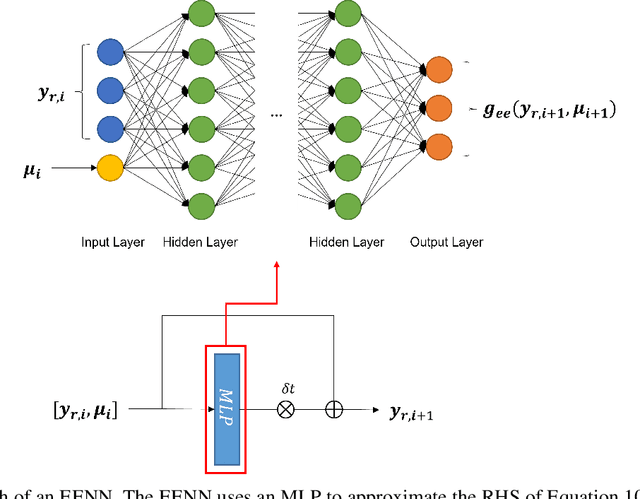
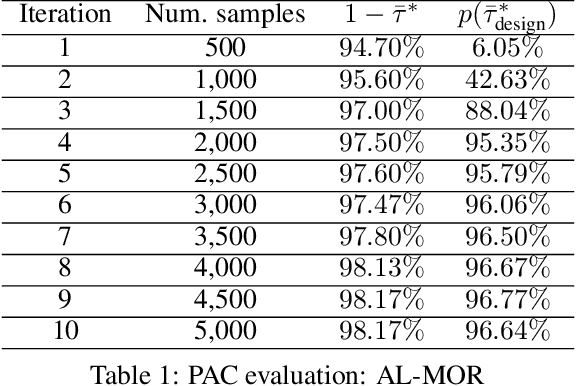
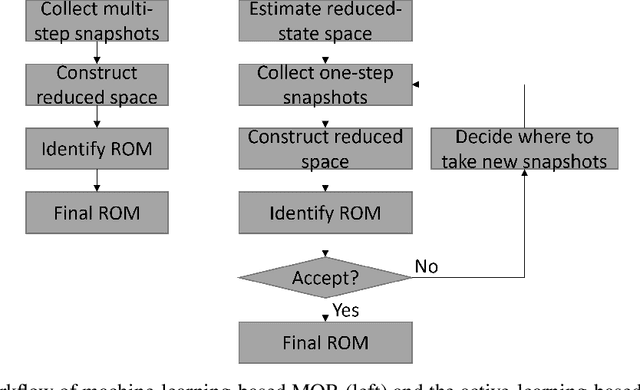

The Model Order Reduction (MOR) technique can provide compact numerical models for fast simulation. Different from the intrusive MOR methods, the non-intrusive MOR does not require access to the Full Order Models (FOMs), especially system matrices. Since the non-intrusive MOR methods strongly rely on the snapshots of the FOMs, constructing good snapshot sets becomes crucial. In this work, we propose a new active learning approach with two novelties. A novel idea with our approach is the use of single-time step snapshots from the system states taken from an estimation of the reduced-state space. These states are selected using a greedy strategy supported by an error estimator based Gaussian Process Regression (GPR). Additionally, we introduce a use case-independent validation strategy based on Probably Approximately Correct (PAC) learning. In this work, we use Artificial Neural Networks (ANNs) to identify the Reduced Order Model (ROM), however the method could be similarly applied to other ROM identification methods. The performance of the whole workflow is tested by a 2-D thermal conduction and a 3-D vacuum furnace model. With little required user interaction and a training strategy independent to a specific use case, the proposed method offers a huge potential for industrial usage to create so-called executable Digital Twins (DTs).
Unsupervised Anomaly Detection in 3D Brain MRI using Deep Learning with impured training data
Apr 12, 2022
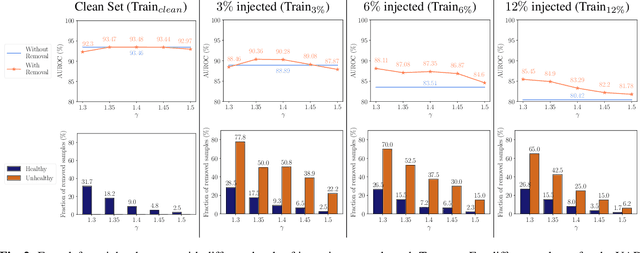
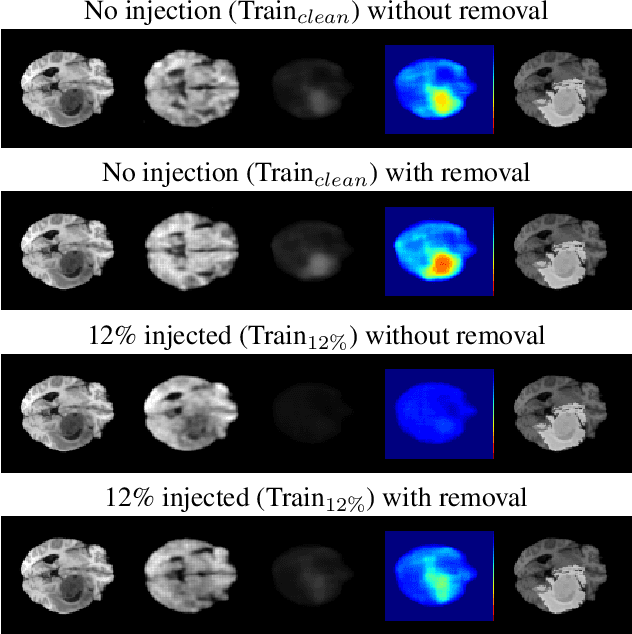
The detection of lesions in magnetic resonance imaging (MRI)-scans of human brains remains challenging, time-consuming and error-prone. Recently, unsupervised anomaly detection (UAD) methods have shown promising results for this task. These methods rely on training data sets that solely contain healthy samples. Compared to supervised approaches, this significantly reduces the need for an extensive amount of labeled training data. However, data labelling remains error-prone. We study how unhealthy samples within the training data affect anomaly detection performance for brain MRI-scans. For our evaluations, we consider three publicly available data sets and use autoencoders (AE) as a well-established baseline method for UAD. We systematically evaluate the effect of impured training data by injecting different quantities of unhealthy samples to our training set of healthy samples from T1-weighted MRI-scans. We evaluate a method to identify falsely labeled samples directly during training based on the reconstruction error of the AE. Our results show that training with impured data decreases the UAD performance notably even with few falsely labeled samples. By performing outlier removal directly during training based on the reconstruction-loss, we demonstrate that falsely labeled data can be detected and removed to mitigate the effect of falsely labeled data. Overall, we highlight the importance of clean data sets for UAD in brain MRI and demonstrate an approach for detecting falsely labeled data directly during training.
Conditional Approximate Normalizing Flows for Joint Multi-Step Probabilistic Electricity Demand Forecasting
Jan 08, 2022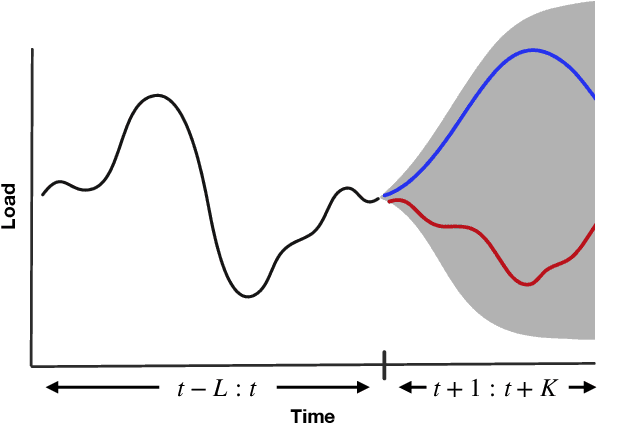
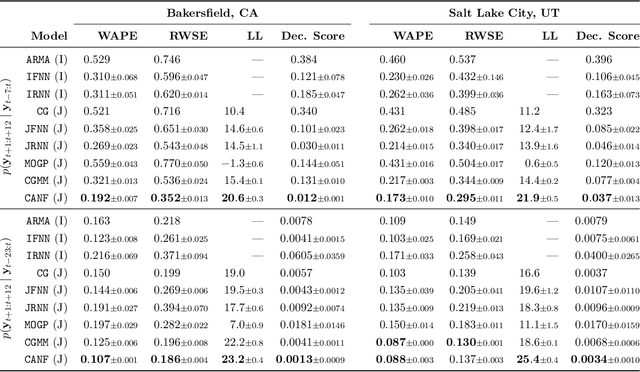
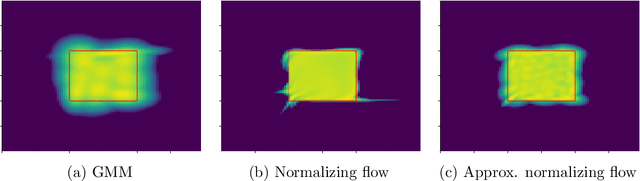
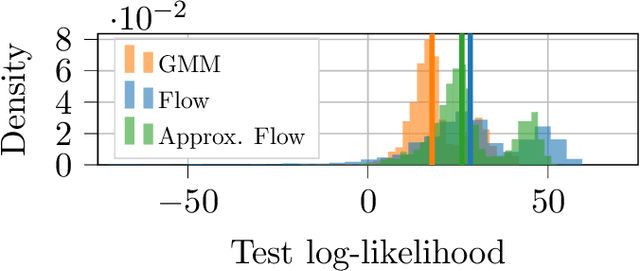
Some real-world decision-making problems require making probabilistic forecasts over multiple steps at once. However, methods for probabilistic forecasting may fail to capture correlations in the underlying time-series that exist over long time horizons as errors accumulate. One such application is with resource scheduling under uncertainty in a grid environment, which requires forecasting electricity demand that is inherently noisy, but often cyclic. In this paper, we introduce the conditional approximate normalizing flow (CANF) to make probabilistic multi-step time-series forecasts when correlations are present over long time horizons. We first demonstrate our method's efficacy on estimating the density of a toy distribution, finding that CANF improves the KL divergence by one-third compared to that of a Gaussian mixture model while still being amenable to explicit conditioning. We then use a publicly available household electricity consumption dataset to showcase the effectiveness of CANF on joint probabilistic multi-step forecasting. Empirical results show that conditional approximate normalizing flows outperform other methods in terms of multi-step forecast accuracy and lead to up to 10x better scheduling decisions. Our implementation is available at https://github.com/sisl/JointDemandForecasting.
Learning to modulate random weights can induce task-specific contexts for economical meta and continual learning
Apr 08, 2022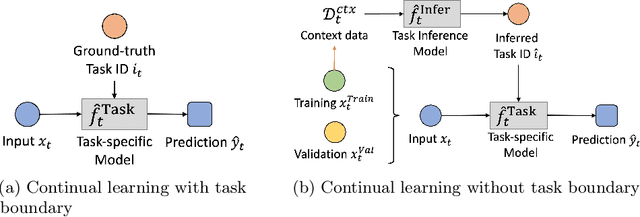
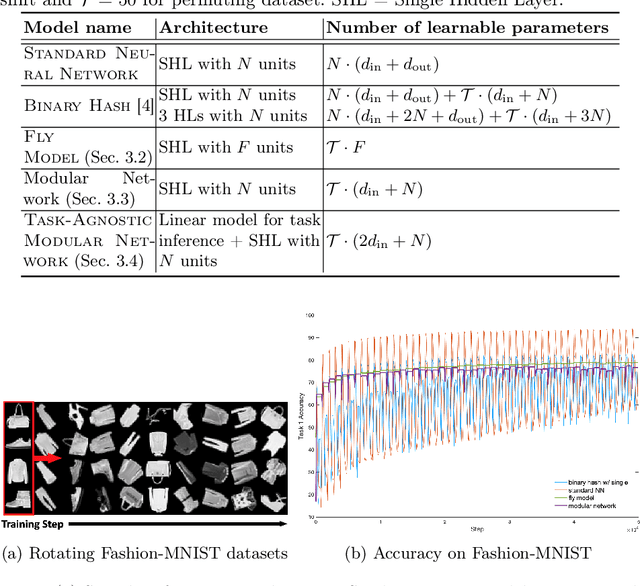
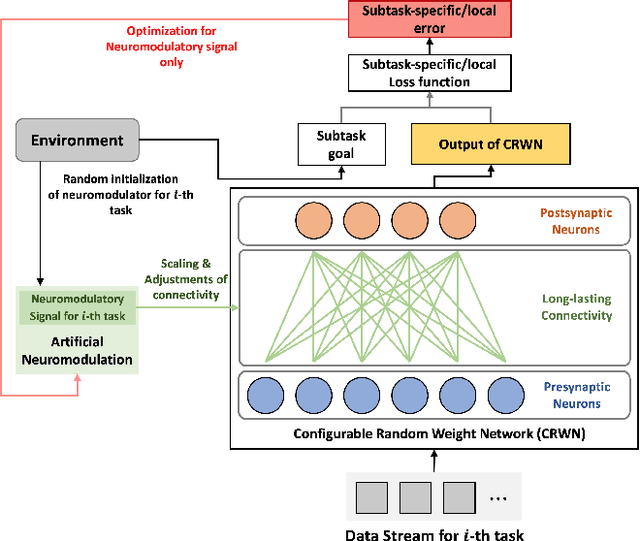
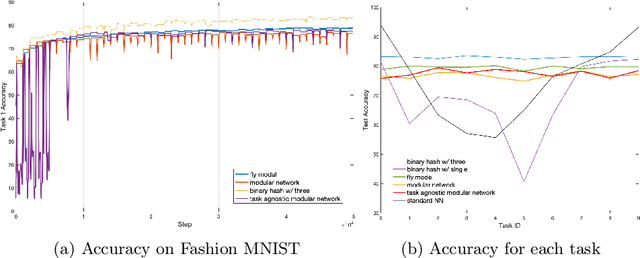
Neural networks are vulnerable to catastrophic forgetting when data distributions are non-stationary during continual online learning; learning of a later task often leads to forgetting of an earlier task. One solution approach is model-agnostic continual meta-learning, whereby both task-specific and meta parameters are trained. Here, we depart from this view and introduce a novel neural-network architecture inspired by neuromodulation in biological nervous systems. Neuromodulation is the biological mechanism that dynamically controls and fine-tunes synaptic dynamics to complement the behavioral context in real-time, which has received limited attention in machine learning. We introduce a single-hidden-layer network that learns only a relatively small context vector per task (task-specific parameters) that neuromodulates unchanging, randomized weights (meta parameters) that transform the input. We show that when task boundaries are available, this approach can eliminate catastrophic forgetting entirely while also drastically reducing the number of learnable parameters relative to other context-vector-based approaches. Furthermore, by combining this model with a simple meta-learning approach for inferring task identity, we demonstrate that the model can be generalized into a framework to perform continual learning without knowledge of task boundaries. Finally, we showcase the framework in a supervised continual online learning scenario and discuss the implications of the proposed formalism.
Learning Commonsense-aware Moment-Text Alignment for Fast Video Temporal Grounding
Apr 12, 2022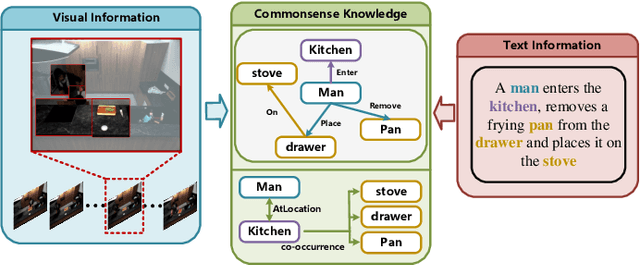
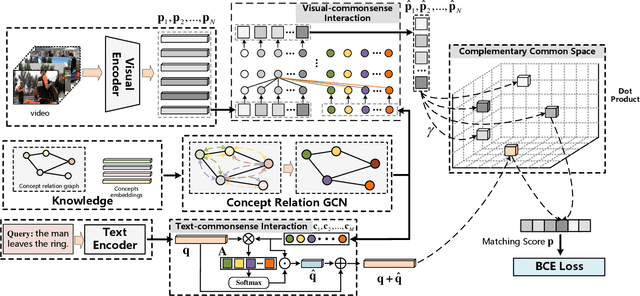
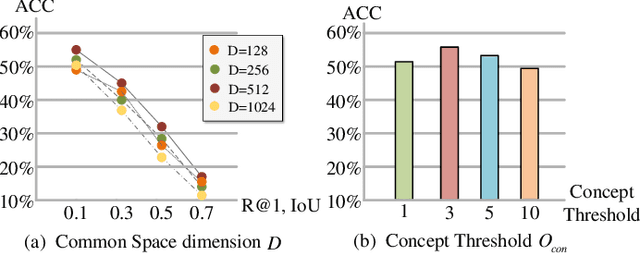
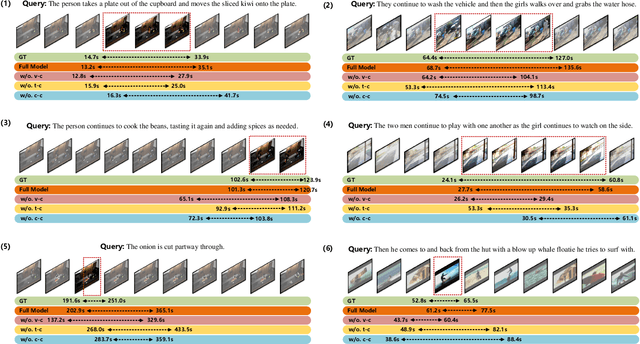
Grounding temporal video segments described in natural language queries effectively and efficiently is a crucial capability needed in vision-and-language fields. In this paper, we deal with the fast video temporal grounding (FVTG) task, aiming at localizing the target segment with high speed and favorable accuracy. Most existing approaches adopt elaborately designed cross-modal interaction modules to improve the grounding performance, which suffer from the test-time bottleneck. Although several common space-based methods enjoy the high-speed merit during inference, they can hardly capture the comprehensive and explicit relations between visual and textual modalities. In this paper, to tackle the dilemma of speed-accuracy tradeoff, we propose a commonsense-aware cross-modal alignment (CCA) framework, which incorporates commonsense-guided visual and text representations into a complementary common space for fast video temporal grounding. Specifically, the commonsense concepts are explored and exploited by extracting the structural semantic information from a language corpus. Then, a commonsense-aware interaction module is designed to obtain bridged visual and text features by utilizing the learned commonsense concepts. Finally, to maintain the original semantic information of textual queries, a cross-modal complementary common space is optimized to obtain matching scores for performing FVTG. Extensive results on two challenging benchmarks show that our CCA method performs favorably against state-of-the-arts while running at high speed. Our code is available at https://github.com/ZiyueWu59/CCA.
Sequential Doppler Shift based Optimal Localization and Synchronization with TOA
Feb 14, 2022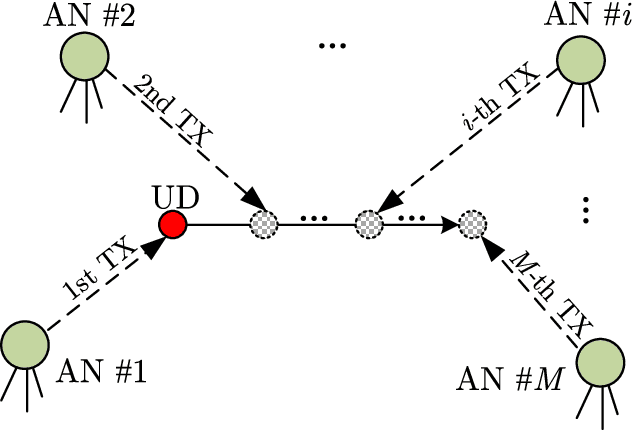
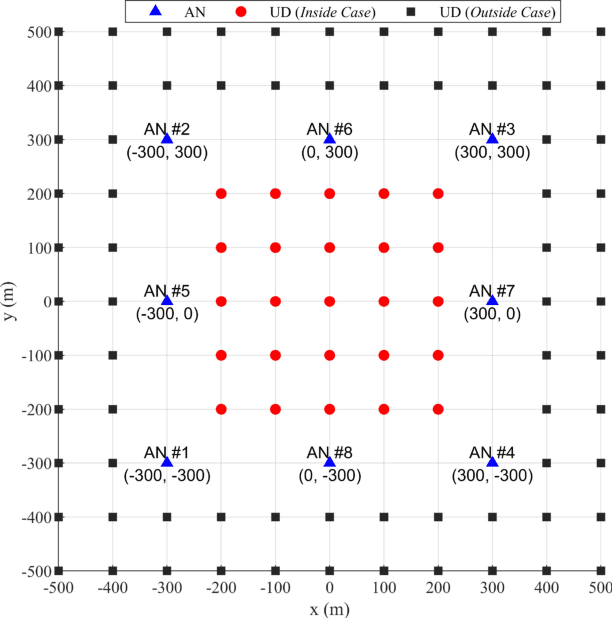
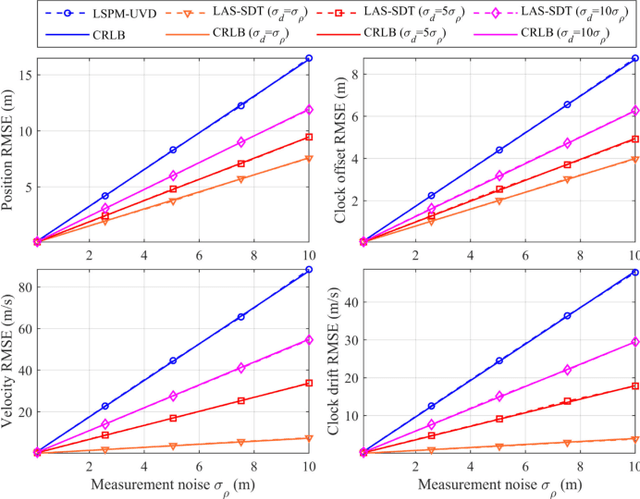
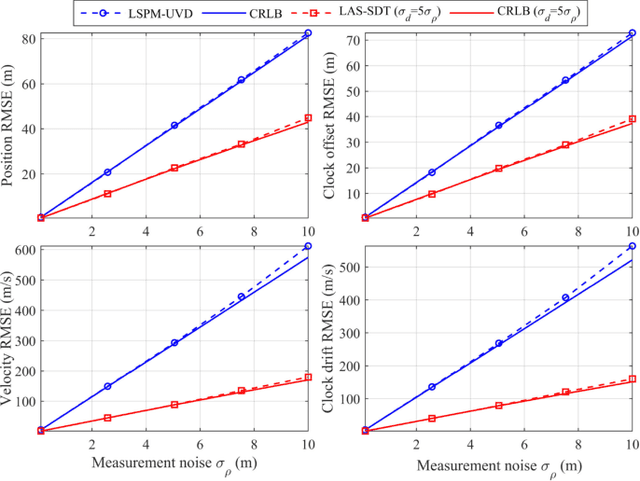
Doppler shift is an important measurement for localization and synchronization (LAS), and is available in various practical systems. Existing studies on LAS techniques in a time division broadcast LAS system (TDBS) only use sequential time-of-arrival (TOA) measurements from the broadcast signals. In this paper, we develop a new optimal LAS method in the TDBS, namely LAS-SDT, by taking advantage of the sequential Doppler shift and TOA measurements. It achieves higher accuracy compared with the conventional TOA-only method for user devices (UDs) with motion and clock drift. Another two variant methods, LAS-SDT-v for the case with UD velocity aiding, and LAS-SDT-k for the case with UD clock drift aiding, are developed. We derive the Cramer-Rao lower bound (CRLB) for these different cases. We show analytically that the accuracies of the estimated UD position, clock offset, velocity and clock drift are all significantly higher than those of the conventional LAS method using TOAs only. Numerical results corroborate the theoretical analysis and show the optimal estimation performance of the LAS-SDT.