 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Live Speech Portraits: Real-Time Photorealistic Talking-Head Animation
Sep 24, 2021

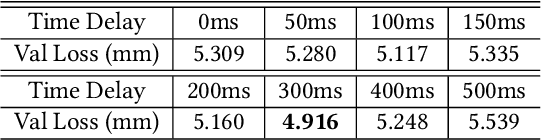
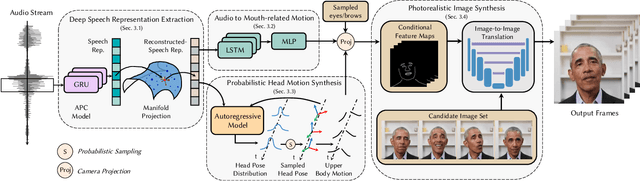
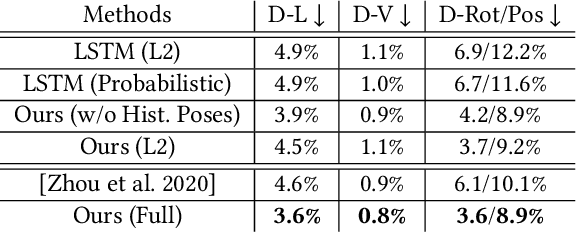
To the best of our knowledge, we first present a live system that generates personalized photorealistic talking-head animation only driven by audio signals at over 30 fps. Our system contains three stages. The first stage is a deep neural network that extracts deep audio features along with a manifold projection to project the features to the target person's speech space. In the second stage, we learn facial dynamics and motions from the projected audio features. The predicted motions include head poses and upper body motions, where the former is generated by an autoregressive probabilistic model which models the head pose distribution of the target person. Upper body motions are deduced from head poses. In the final stage, we generate conditional feature maps from previous predictions and send them with a candidate image set to an image-to-image translation network to synthesize photorealistic renderings. Our method generalizes well to wild audio and successfully synthesizes high-fidelity personalized facial details, e.g., wrinkles, teeth. Our method also allows explicit control of head poses. Extensive qualitative and quantitative evaluations, along with user studies, demonstrate the superiority of our method over state-of-the-art techniques.
Probing for Labeled Dependency Trees
Mar 24, 2022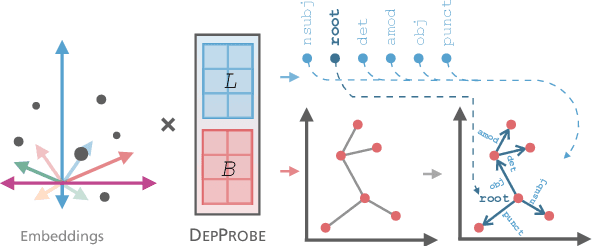

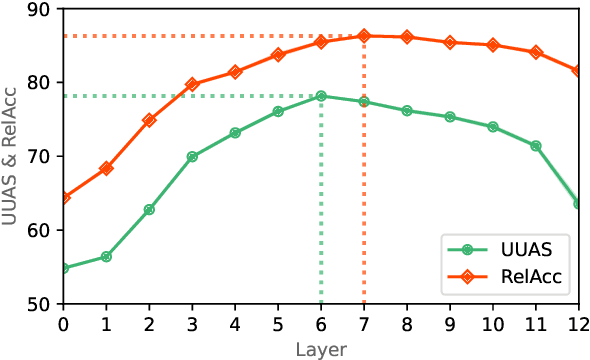
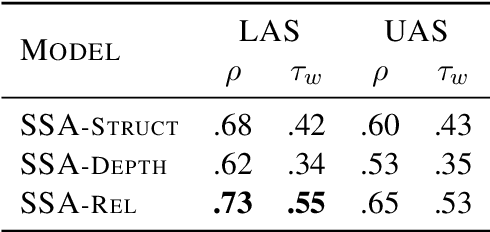
Probing has become an important tool for analyzing representations in Natural Language Processing (NLP). For graphical NLP tasks such as dependency parsing, linear probes are currently limited to extracting undirected or unlabeled parse trees which do not capture the full task. This work introduces DepProbe, a linear probe which can extract labeled and directed dependency parse trees from embeddings while using fewer parameters and compute than prior methods. Leveraging its full task coverage and lightweight parametrization, we investigate its predictive power for selecting the best transfer language for training a full biaffine attention parser. Across 13 languages, our proposed method identifies the best source treebank 94% of the time, outperforming competitive baselines and prior work. Finally, we analyze the informativeness of task-specific subspaces in contextual embeddings as well as which benefits a full parser's non-linear parametrization provides.
Toeplitz Least Squares Problems, Fast Algorithms and Big Data
Dec 24, 2021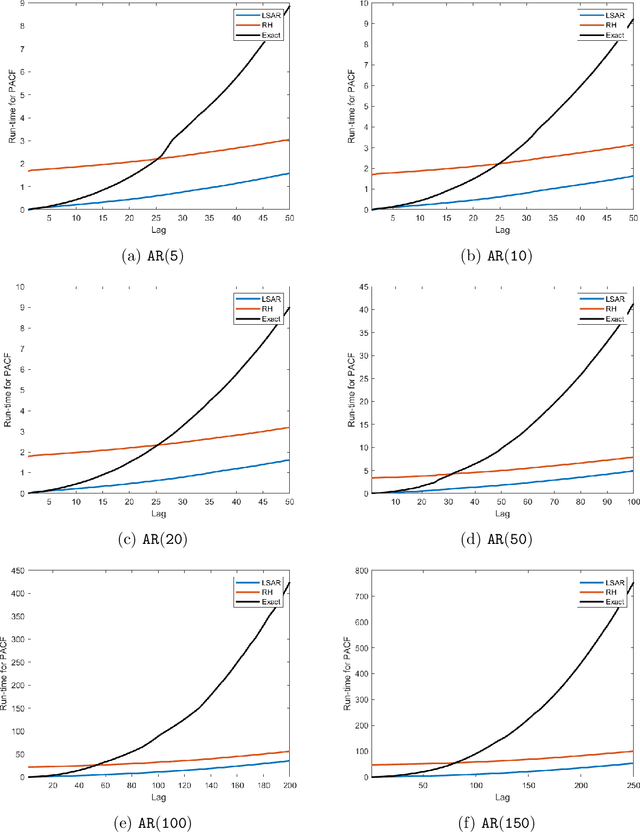
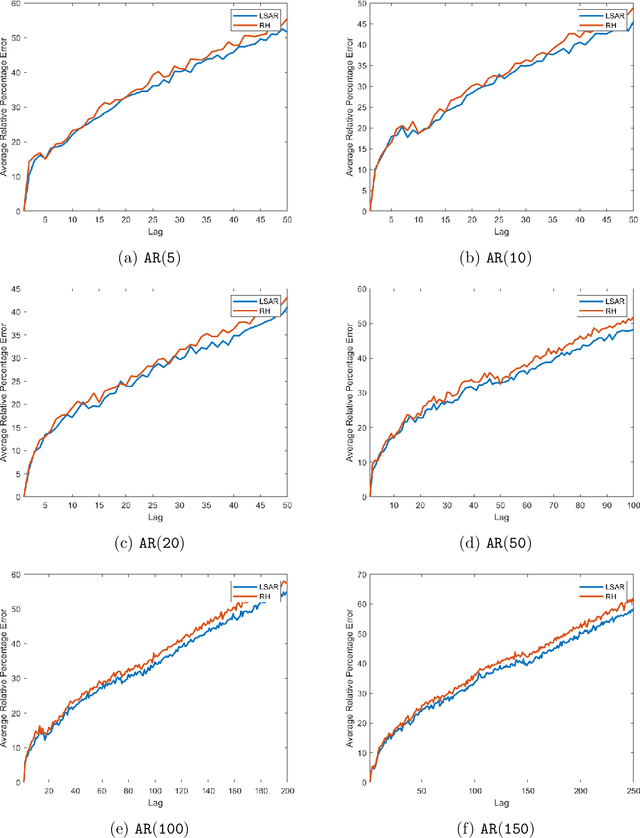
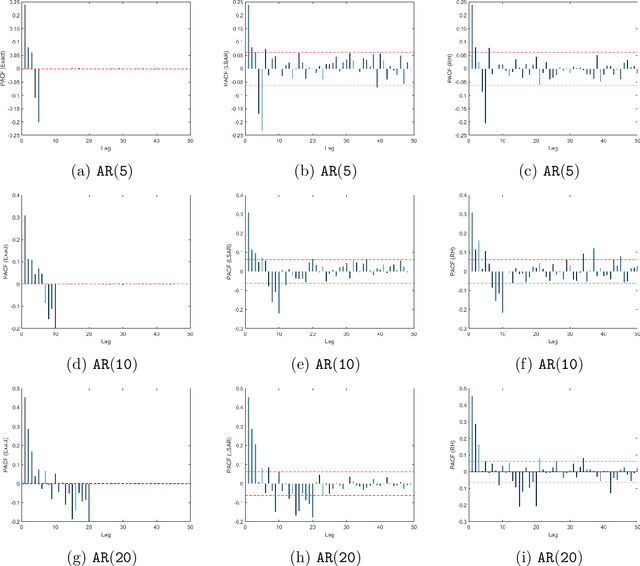
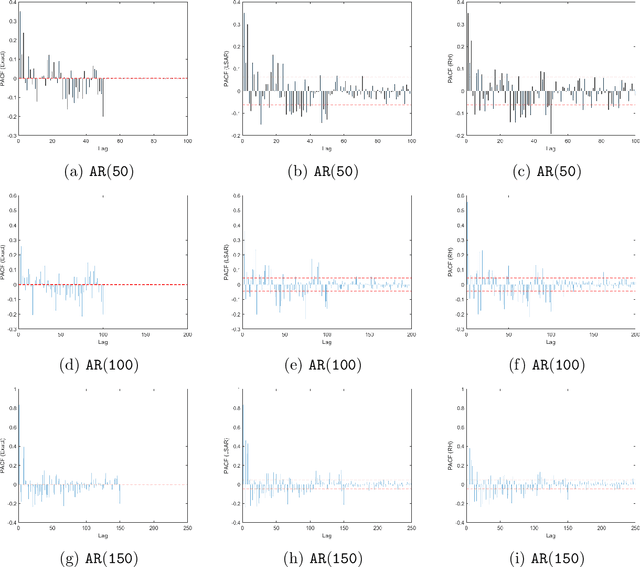
In time series analysis, when fitting an autoregressive model, one must solve a Toeplitz ordinary least squares problem numerous times to find an appropriate model, which can severely affect computational times with large data sets. Two recent algorithms (LSAR and Repeated Halving) have applied randomized numerical linear algebra (RandNLA) techniques to fitting an autoregressive model to big time-series data. We investigate and compare the quality of these two approximation algorithms on large-scale synthetic and real-world data. While both algorithms display comparable results for synthetic datasets, the LSAR algorithm appears to be more robust when applied to real-world time series data. We conclude that RandNLA is effective in the context of big-data time series.
Tweet Emotion Dynamics: Emotion Word Usage in Tweets from US and Canada
Apr 11, 2022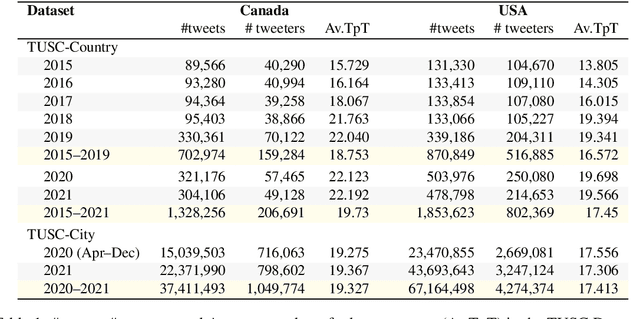
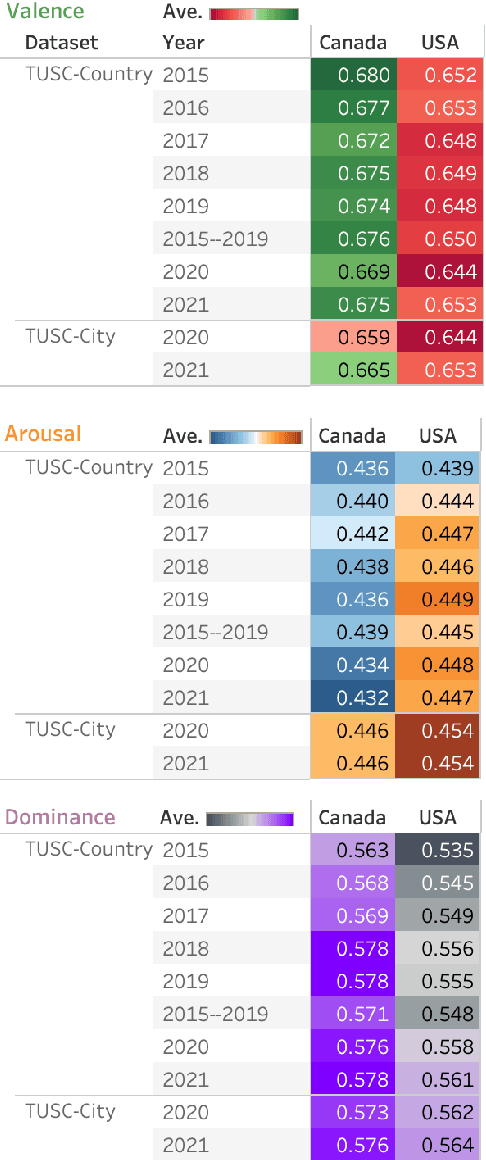
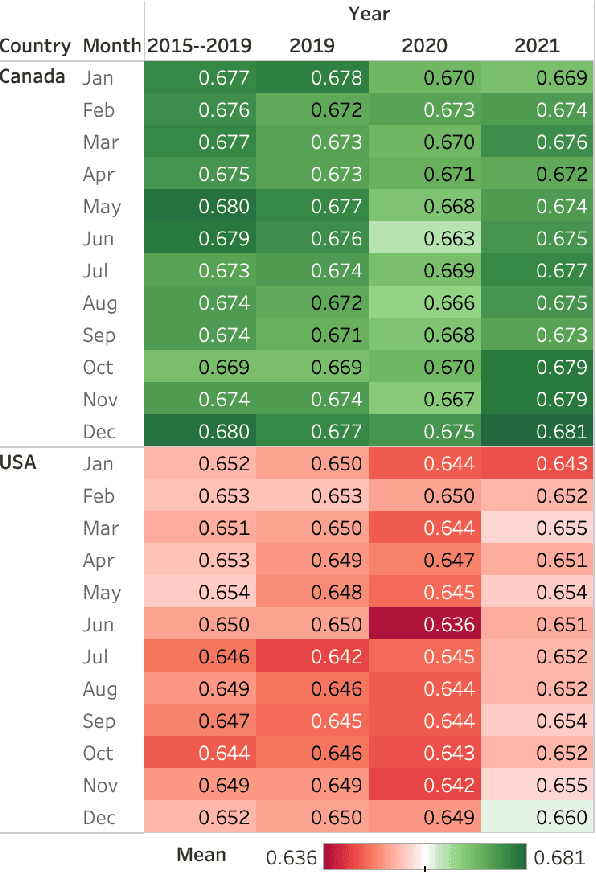
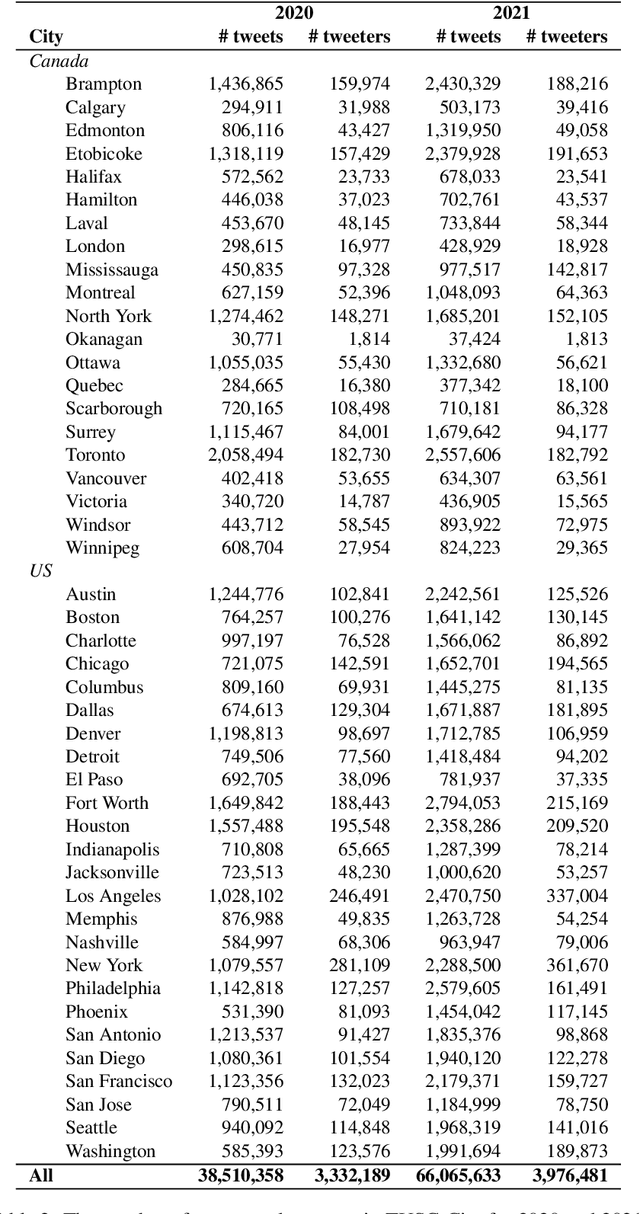
Over the last decade, Twitter has emerged as one of the most influential forums for social, political, and health discourse. In this paper, we introduce a massive dataset of more than 45 million geo-located tweets posted between 2015 and 2021 from US and Canada (TUSC), especially curated for natural language analysis. We also introduce Tweet Emotion Dynamics (TED) -- metrics to capture patterns of emotions associated with tweets over time. We use TED and TUSC to explore the use of emotion-associated words across US and Canada; across 2019 (pre-pandemic), 2020 (the year the pandemic hit), and 2021 (the second year of the pandemic); and across individual tweeters. We show that Canadian tweets tend to have higher valence, lower arousal, and higher dominance than the US tweets. Further, we show that the COVID-19 pandemic had a marked impact on the emotional signature of tweets posted in 2020, when compared to the adjoining years. Finally, we determine metrics of TED for 170,000 tweeters to benchmark characteristics of TED metrics at an aggregate level. TUSC and the metrics for TED will enable a wide variety of research on studying how we use language to express ourselves, persuade, communicate, and influence, with particularly promising applications in public health, affective science, social science, and psychology.
Prediction of financial time series using LSTM and data denoising methods
Mar 05, 2021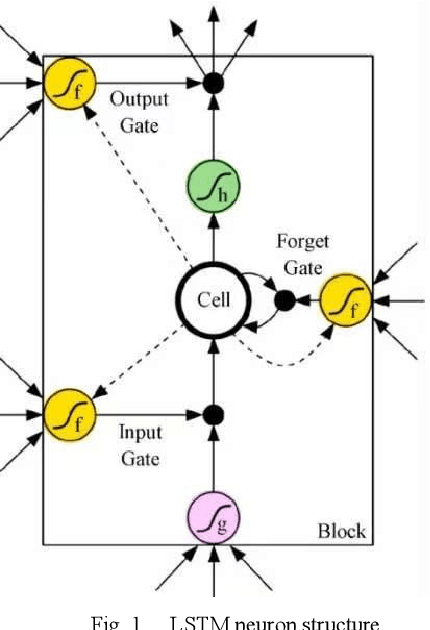

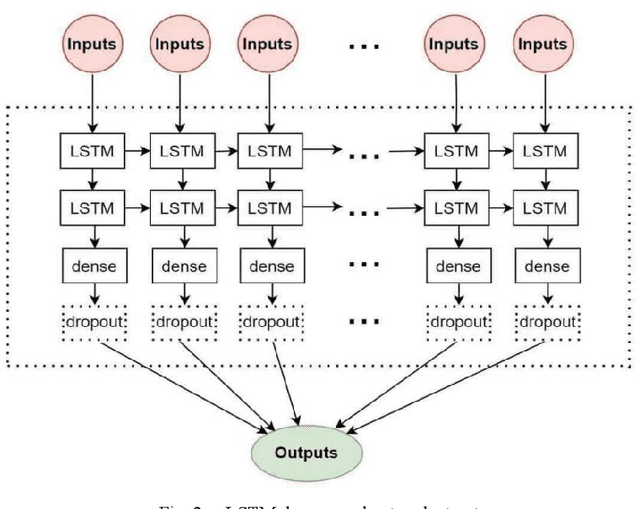

In order to further overcome the difficulties of the existing models in dealing with the non-stationary and nonlinear characteristics of high-frequency financial time series data, especially its weak generalization ability, this paper proposes an ensemble method based on data denoising methods, including the wavelet transform (WT) and singular spectrum analysis (SSA), and long-term short-term memory neural network (LSTM) to build a data prediction model, The financial time series is decomposed and reconstructed by WT and SSA to denoise. Under the condition of denoising, the smooth sequence with effective information is reconstructed. The smoothing sequence is introduced into LSTM and the predicted value is obtained. With the Dow Jones industrial average index (DJIA) as the research object, the closing price of the DJIA every five minutes is divided into short-term (1 hour), medium-term (3 hours) and long-term (6 hours) respectively. . Based on root mean square error (RMSE), mean absolute error (MAE), mean absolute percentage error (MAPE) and absolute percentage error standard deviation (SDAPE), the experimental results show that in the short-term, medium-term and long-term, data denoising can greatly improve the accuracy and stability of the prediction, and can effectively improve the generalization ability of LSTM prediction model. As WT and SSA can extract useful information from the original sequence and avoid overfitting, the hybrid model can better grasp the sequence pattern of the closing price of the DJIA. And the WT-LSTM model is better than the benchmark LSTM model and SSA-LSTM model.
Bayesian Online Change Point Detection for Baseline Shifts
Jan 07, 2022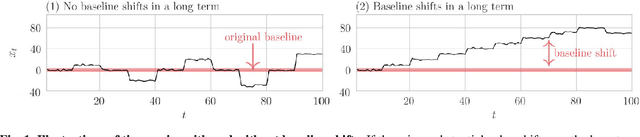
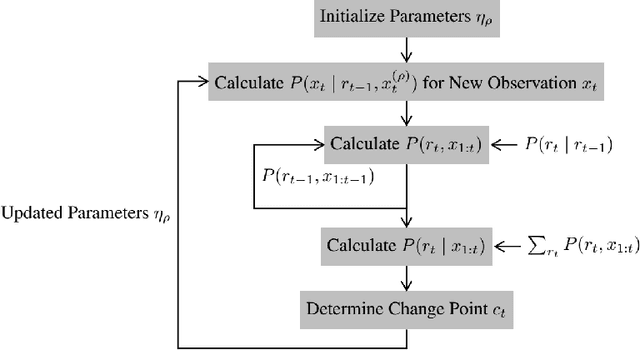
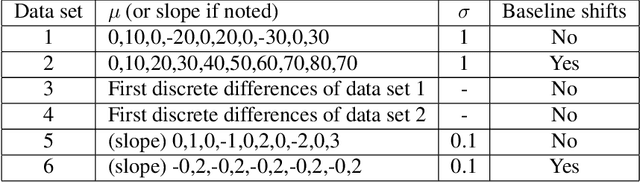

In time series data analysis, detecting change points on a real-time basis (online) is of great interest in many areas, such as finance, environmental monitoring, and medicine. One promising means to achieve this is the Bayesian online change point detection (BOCPD) algorithm, which has been successfully adopted in particular cases in which the time series of interest has a fixed baseline. However, we have found that the algorithm struggles when the baseline irreversibly shifts from its initial state. This is because with the original BOCPD algorithm, the sensitivity with which a change point can be detected is degraded if the data points are fluctuating at locations relatively far from the original baseline. In this paper, we not only extend the original BOCPD algorithm to be applicable to a time series whose baseline is constantly shifting toward unknown values but also visualize why the proposed extension works. To demonstrate the efficacy of the proposed algorithm compared to the original one, we examine these algorithms on two real-world data sets and six synthetic data sets.
* Published in Statistics, Optimization & Information Computing
Cross-Modality High-Frequency Transformer for MR Image Super-Resolution
Mar 29, 2022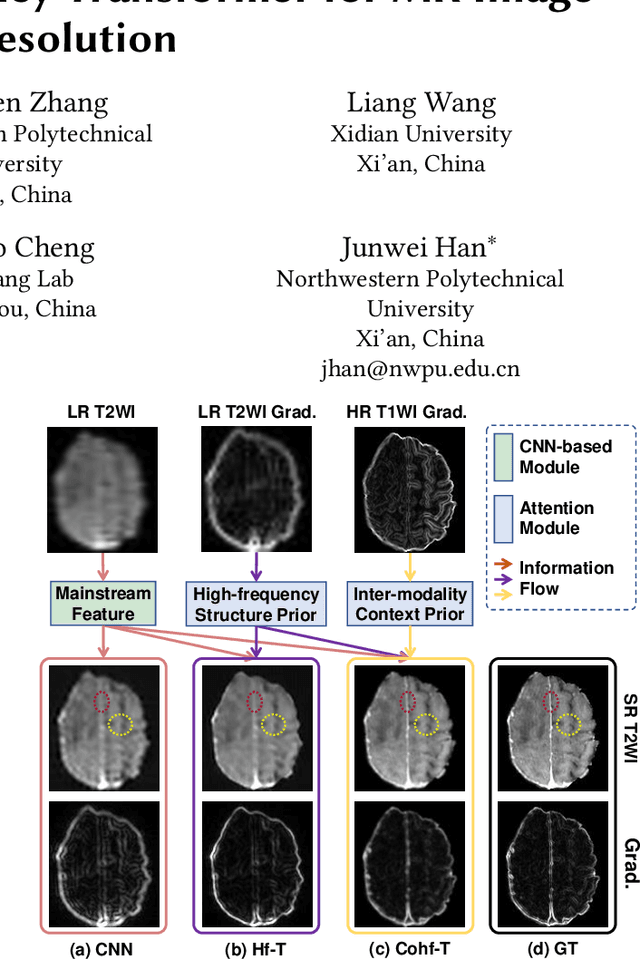
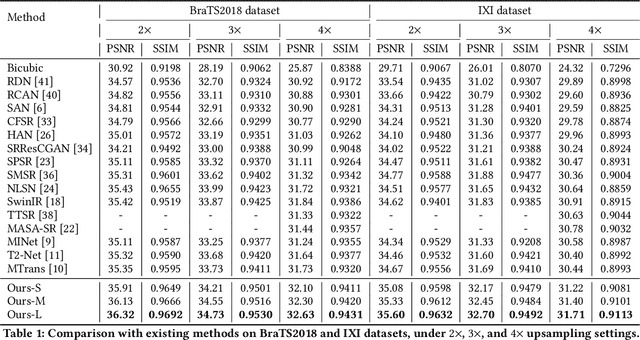
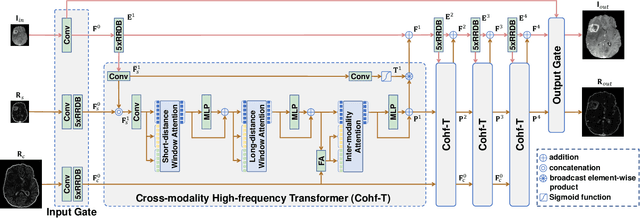
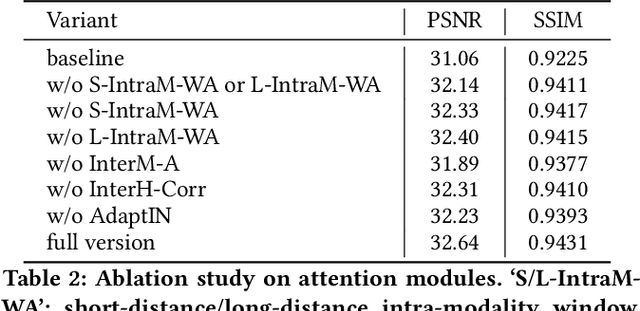
Improving the resolution of magnetic resonance (MR) image data is critical to computer-aided diagnosis and brain function analysis. Higher resolution helps to capture more detailed content, but typically induces to lower signal-to-noise ratio and longer scanning time. To this end, MR image super-resolution has become a widely-interested topic in recent times. Existing works establish extensive deep models with the conventional architectures based on convolutional neural networks (CNN). In this work, to further advance this research field, we make an early effort to build a Transformer-based MR image super-resolution framework, with careful designs on exploring valuable domain prior knowledge. Specifically, we consider two-fold domain priors including the high-frequency structure prior and the inter-modality context prior, and establish a novel Transformer architecture, called Cross-modality high-frequency Transformer (Cohf-T), to introduce such priors into super-resolving the low-resolution (LR) MR images. Comprehensive experiments on two datasets indicate that Cohf-T achieves new state-of-the-art performance.
Implementation and Evaluation of a Multivariate Abstraction-Based, Interval-Based Dynamic Time-Warping Method as a Similarity Measure for Longitudinal Medical Records
May 18, 2021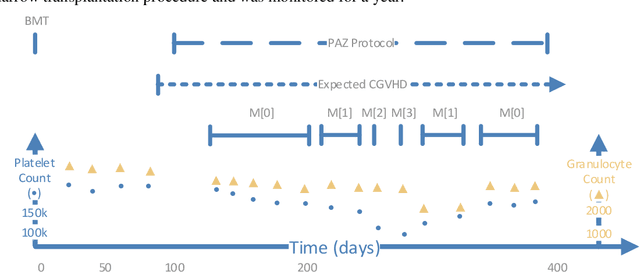
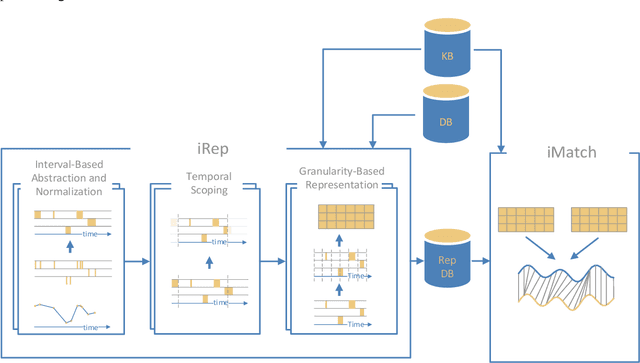

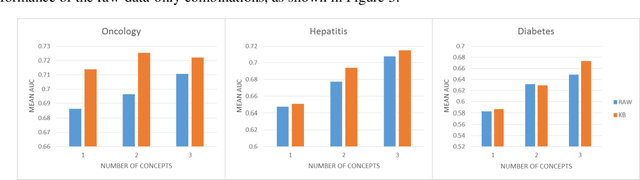
We extended dynamic time warping (DTW) into interval-based dynamic time warping (iDTW), including (A) interval-based representation (iRep): [1] abstracting raw, time-stamped data into interval-based abstractions, [2] comparison-period scoping, [3] partitioning abstract intervals into a given temporal granularity; (B) interval-based matching (iMatch): matching partitioned, abstract-concepts records, using a modified DTW. Using domain knowledge, we abstracted the raw data of medical records, for up to three concepts out of four or five relevant concepts, into two interval types: State abstractions (e.g. LOW, HIGH) and Gradient abstractions (e.g. INCREASING, DECREASING). We created all uni-dimensional (State or Gradient) or multi-dimensional (State and Gradient) abstraction combinations. Tasks: Classifying 161 oncology patients records as autologous or allogenic bone-marrow transplantation; classifying 125 hepatitis patients records as B or C hepatitis; predicting micro- or macro-albuminuria in the next year for 151 Type 2 diabetes patients. We used a k-Nearest-Neighbors majority, k=1 to SQRT(N), N = set size. 50,328 10-fold cross-validation experiments were performed: 23,400 (Oncology), 19,800 (Hepatitis), 7,128 (Diabetes). Measures: Area Under the Curve (AUC), optimal Youden's Index. Paired t-tests compared result vectors for equivalent configurations other than a tested variable, to determine a significant mean accuracy difference (P<0.05). Mean classification and prediction using abstractions was significantly better than using only raw time-stamped data. In each domain, at least one abstraction combination led to a significantly better performance than using raw data. Increasing feature number, and using multi-dimensional abstractions, enhanced performance. Unlike when using raw data, optimal performance was often reached with k=5, using abstractions.
ACuTE: Automatic Curriculum Transfer from Simple to Complex Environments
Apr 11, 2022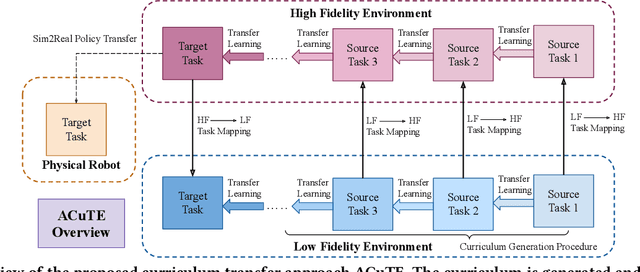
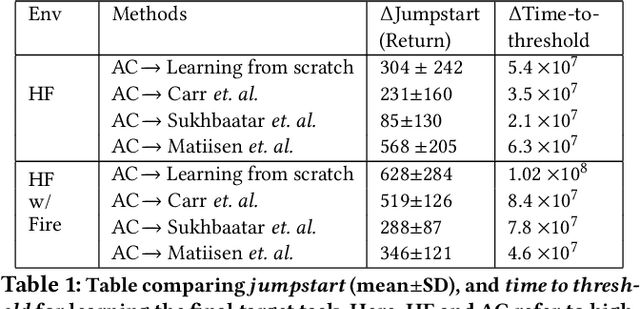
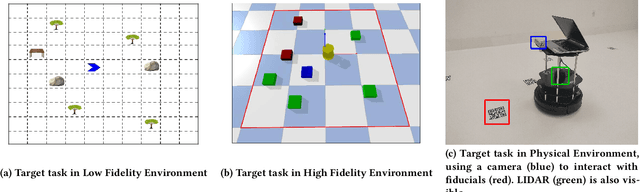
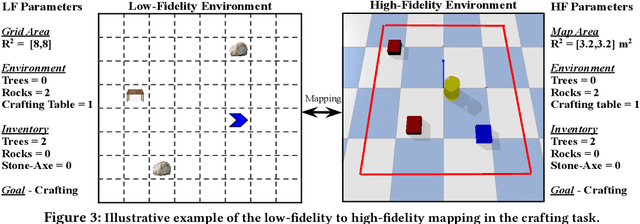
Despite recent advances in Reinforcement Learning (RL), many problems, especially real-world tasks, remain prohibitively expensive to learn. To address this issue, several lines of research have explored how tasks, or data samples themselves, can be sequenced into a curriculum to learn a problem that may otherwise be too difficult to learn from scratch. However, generating and optimizing a curriculum in a realistic scenario still requires extensive interactions with the environment. To address this challenge, we formulate the curriculum transfer problem, in which the schema of a curriculum optimized in a simpler, easy-to-solve environment (e.g., a grid world) is transferred to a complex, realistic scenario (e.g., a physics-based robotics simulation or the real world). We present "ACuTE", Automatic Curriculum Transfer from Simple to Complex Environments, a novel framework to solve this problem, and evaluate our proposed method by comparing it to other baseline approaches (e.g., domain adaptation) designed to speed up learning. We observe that our approach produces improved jumpstart and time-to-threshold performance even when adding task elements that further increase the difficulty of the realistic scenario. Finally, we demonstrate that our approach is independent of the learning algorithm used for curriculum generation, and is Sim2Real transferable to a real world scenario using a physical robot.
Minimizing Maintenance Cost Involving Flow-time and Tardiness Penalty with Unequal Release Dates
Dec 15, 2020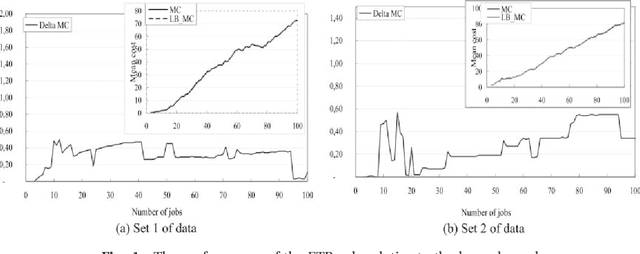
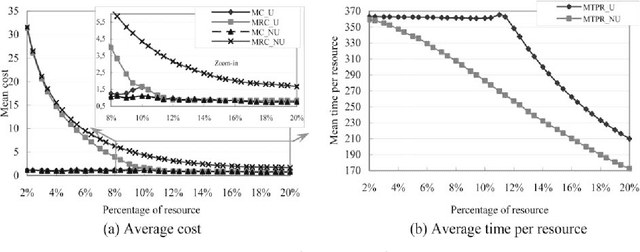
This paper proposes important and useful results relating to the minimization of the sum of the flow-time and the tardiness of tasks or jobs with unequal release dates (occurrence date), with application to maintenance planning and scheduling. Firstly, the policy of real-time maintenance is defined for minimizing the cost of tardiness and critical states. The required local optimality rule (FTR) is proved, in order to minimize the sum or the linear combination of the tasks' flow-time and tardiness costs. This rule has served to design a scheduling algorithm, with O(n 3) complexity when it is applied to schedule a set of n tasks on one processor. To evaluate its performance, the results are compared to a lower bound that is provided, in a numerical case study. Using this algorithm in combination with the tasks urgency criterion, a real-time algorithm is developed to schedule the tasks on q parallel processors. This latter algorithm is finally applied to schedule and assign preventive maintenance tasks to processors in the case of a distributed system. Its efficiency enables, as shown in the numerical example, to minimize the cost of preventive maintenance tasks, expressed as the sum of the tasks tardiness and flow-time. This corresponds to costs of critical states and of tardiness of preventive maintenance.