 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Modeling unknown dynamical systems with hidden parameters
Feb 03, 2022
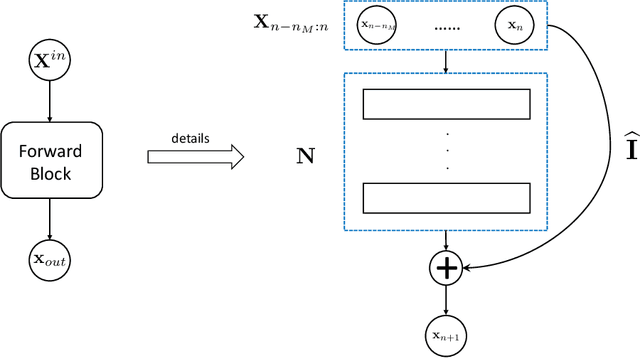
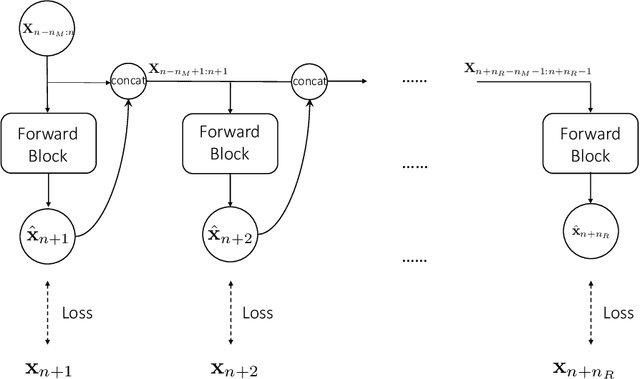
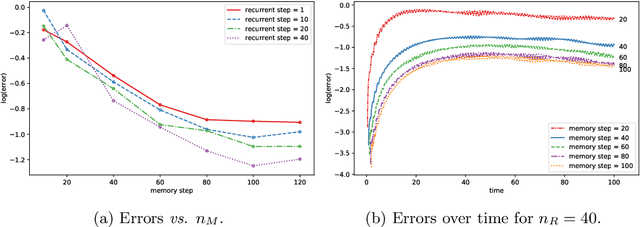
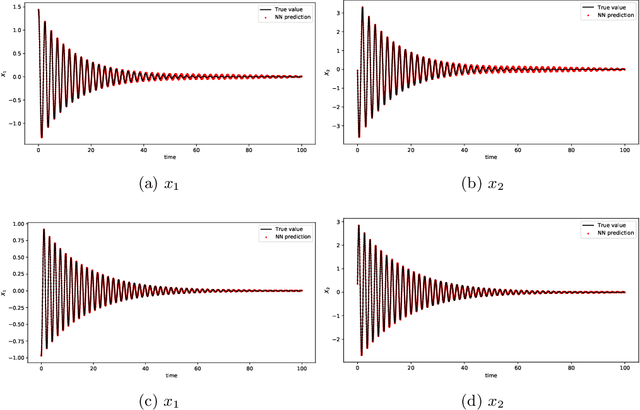
We present a data-driven numerical approach for modeling unknown dynamical systems with missing/hidden parameters. The method is based on training a deep neural network (DNN) model for the unknown system using its trajectory data. A key feature is that the unknown dynamical system contains system parameters that are completely hidden, in the sense that no information about the parameters is available through either the measurement trajectory data or our prior knowledge of the system. We demonstrate that by training a DNN using the trajectory data with sufficient time history, the resulting DNN model can accurately model the unknown dynamical system. For new initial conditions associated with new, and unknown, system parameters, the DNN model can produce accurate system predictions over longer time.
A Hierarchical Block Distance Model for Ultra Low-Dimensional Graph Representations
Apr 12, 2022

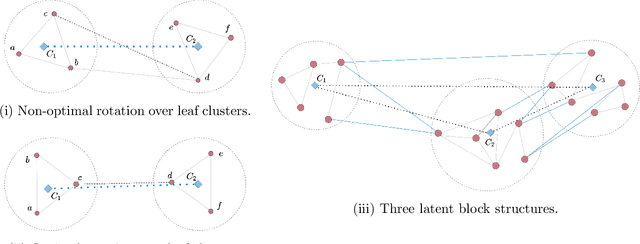
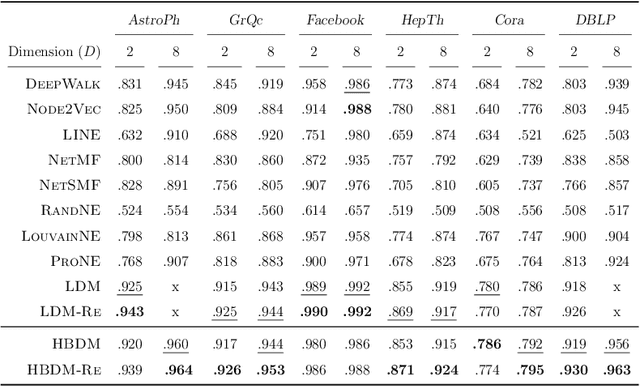
Graph Representation Learning (GRL) has become central for characterizing structures of complex networks and performing tasks such as link prediction, node classification, network reconstruction, and community detection. Whereas numerous generative GRL models have been proposed, many approaches have prohibitive computational requirements hampering large-scale network analysis, fewer are able to explicitly account for structure emerging at multiple scales, and only a few explicitly respect important network properties such as homophily and transitivity. This paper proposes a novel scalable graph representation learning method named the Hierarchical Block Distance Model (HBDM). The HBDM imposes a multiscale block structure akin to stochastic block modeling (SBM) and accounts for homophily and transitivity by accurately approximating the latent distance model (LDM) throughout the inferred hierarchy. The HBDM naturally accommodates unipartite, directed, and bipartite networks whereas the hierarchy is designed to ensure linearithmic time and space complexity enabling the analysis of very large-scale networks. We evaluate the performance of the HBDM on massive networks consisting of millions of nodes. Importantly, we find that the proposed HBDM framework significantly outperforms recent scalable approaches in all considered downstream tasks. Surprisingly, we observe superior performance even imposing ultra-low two-dimensional embeddings facilitating accurate direct and hierarchical-aware network visualization and interpretation.
Constructing dynamic residential energy lifestyles using Latent Dirichlet Allocation
Apr 22, 2022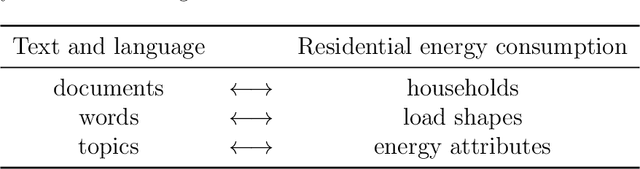
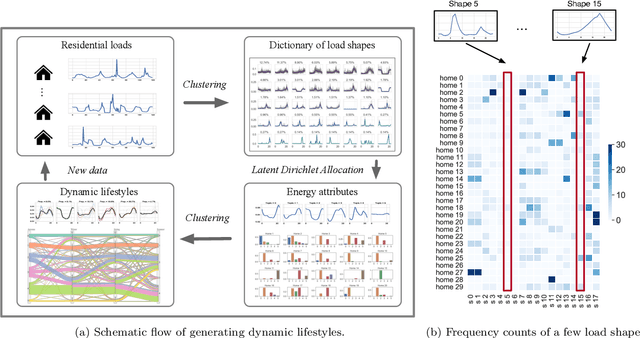
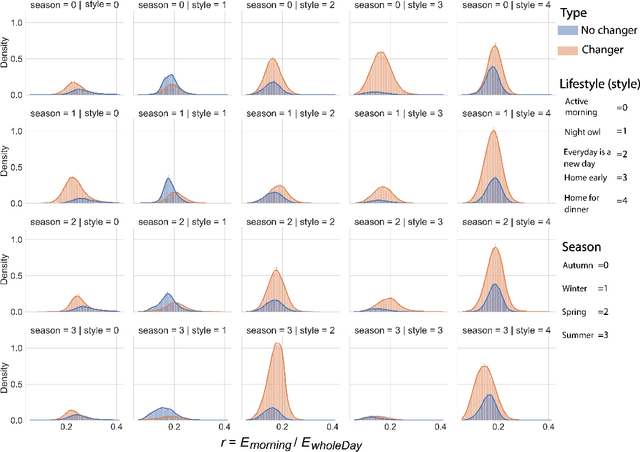
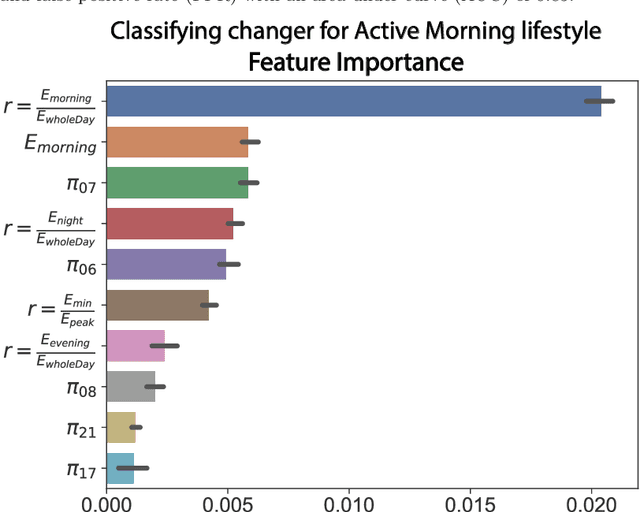
The rapid expansion of Advanced Meter Infrastructure (AMI) has dramatically altered the energy information landscape. However, our ability to use this information to generate actionable insights about residential electricity demand remains limited. In this research, we propose and test a new framework for understanding residential electricity demand by using a dynamic energy lifestyles approach that is iterative and highly extensible. To obtain energy lifestyles, we develop a novel approach that applies Latent Dirichlet Allocation (LDA), a method commonly used for inferring the latent topical structure of text data, to extract a series of latent household energy attributes. By doing so, we provide a new perspective on household electricity consumption where each household is characterized by a mixture of energy attributes that form the building blocks for identifying a sparse collection of energy lifestyles. We examine this approach by running experiments on one year of hourly smart meter data from 60,000 households and we extract six energy attributes that describe general daily use patterns. We then use clustering techniques to derive six distinct energy lifestyle profiles from energy attribute proportions. Our lifestyle approach is also flexible to varying time interval lengths, and we test our lifestyle approach seasonally (Autumn, Winter, Spring, and Summer) to track energy lifestyle dynamics within and across households and find that around 73% of households manifest multiple lifestyles across a year. These energy lifestyles are then compared to different energy use characteristics, and we discuss their practical applications for demand response program design and lifestyle change analysis.
Model Mediated Teleoperation with a Hand-Arm Exoskeleton in Long Time Delays Using Reinforcement Learning
Jul 01, 2021
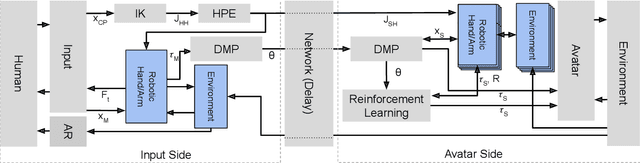
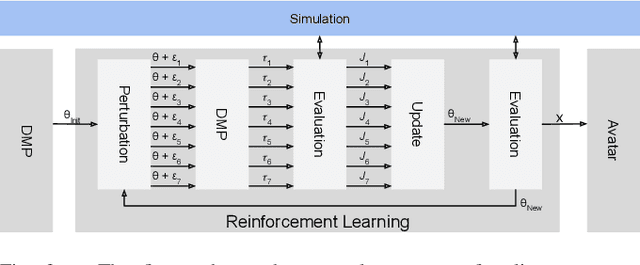
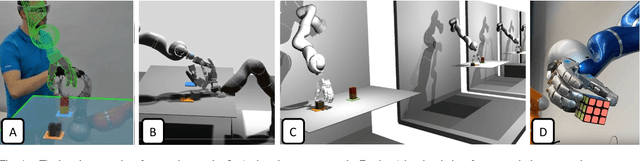
Telerobotic systems must adapt to new environmental conditions and deal with high uncertainty caused by long-time delays. As one of the best alternatives to human-level intelligence, Reinforcement Learning (RL) may offer a solution to cope with these issues. This paper proposes to integrate RL with the Model Mediated Teleoperation (MMT) concept. The teleoperator interacts with a simulated virtual environment, which provides instant feedback. Whereas feedback from the real environment is delayed, feedback from the model is instantaneous, leading to high transparency. The MMT is realized in combination with an intelligent system with two layers. The first layer utilizes Dynamic Movement Primitives (DMP) which accounts for certain changes in the avatar environment. And, the second layer addresses the problems caused by uncertainty in the model using RL methods. Augmented reality was also provided to fuse the avatar device and virtual environment models for the teleoperator. Implemented on DLR's Exodex Adam hand-arm haptic exoskeleton, the results show RL methods are able to find different solutions when changes are applied to the object position after the demonstration. The results also show DMPs to be effective at adapting to new conditions where there is no uncertainty involved.
Physics-constrained Unsupervised Learning of Partial Differential Equations using Meshes
Mar 30, 2022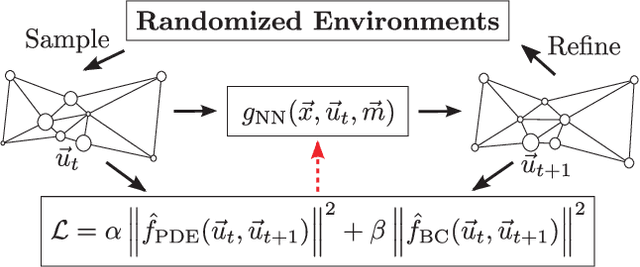

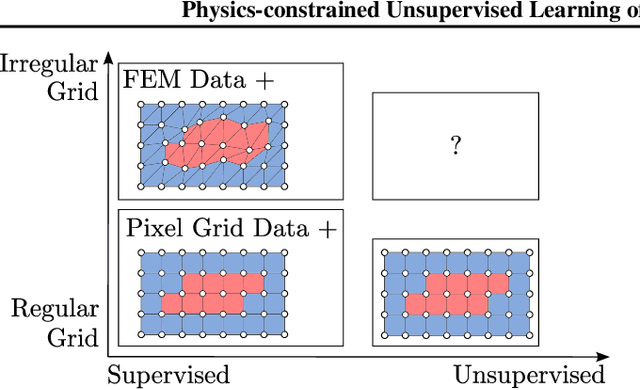
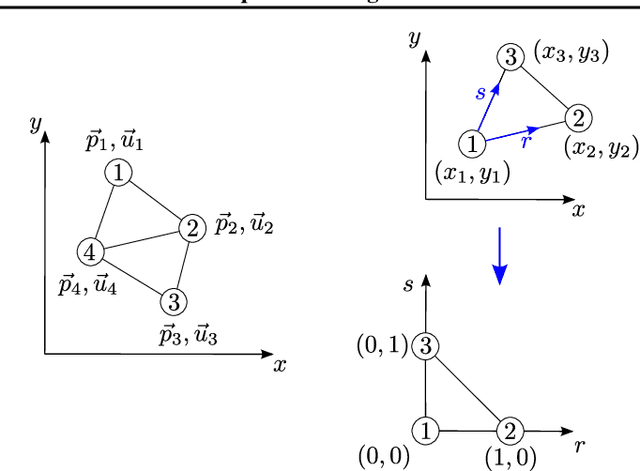
Enhancing neural networks with knowledge of physical equations has become an efficient way of solving various physics problems, from fluid flow to electromagnetism. Graph neural networks show promise in accurately representing irregularly meshed objects and learning their dynamics, but have so far required supervision through large datasets. In this work, we represent meshes naturally as graphs, process these using Graph Networks, and formulate our physics-based loss to provide an unsupervised learning framework for partial differential equations (PDE). We quantitatively compare our results to a classical numerical PDE solver, and show that our computationally efficient approach can be used as an interactive PDE solver that is adjusting boundary conditions in real-time and remains sufficiently close to the baseline solution. Our inherently differentiable framework will enable the application of PDE solvers in interactive settings, such as model-based control of soft-body deformations, or in gradient-based optimization methods that require a fully differentiable pipeline.
Detection of Dangerous Events on Social Media: A Perspective Review
Apr 04, 2022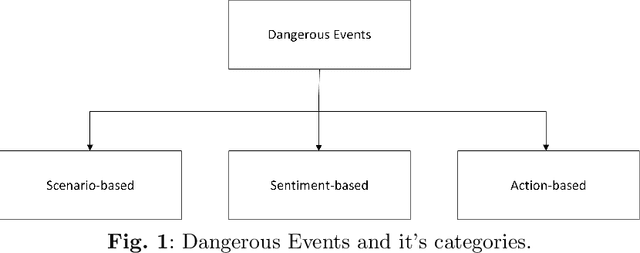

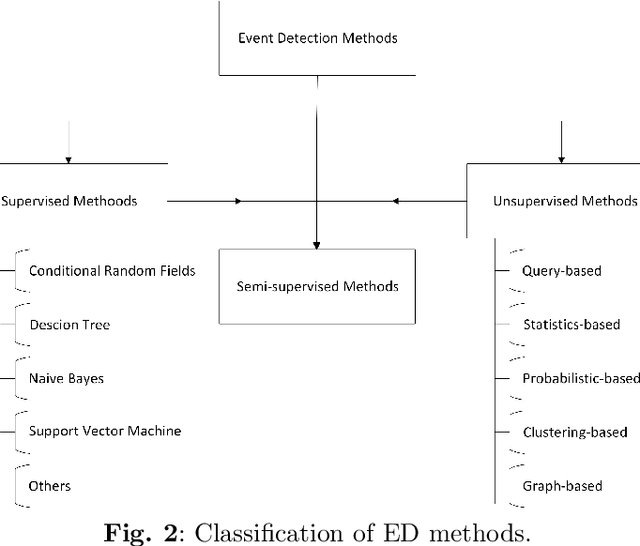
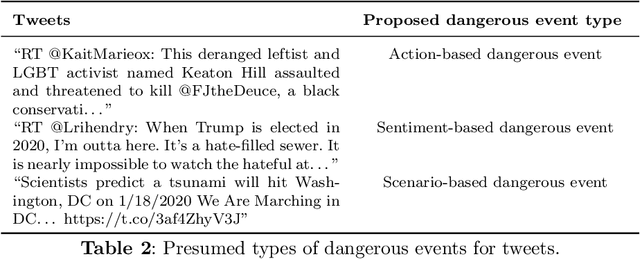
Social media is an essential gateway of information and communication for people worldwide. The amount of time spent and reliance of people on social media makes it a vital resource for detecting events happening in real life. Thousands of significant events are posted by users every hour in the form of multimedia. Some individuals and groups target the audience to promote their agenda among these users. Their cause can threaten other groups and individuals who do not share the same views or have specific differences. Any group with a definitive cause cannot survive without the support which acts as a catalyst for their agenda. A phenomenon occurs where people are fed information that motivates them to act on their behalf and carry out their agenda. One is benefit results in the loss of the others by putting their lives, assets, physical and emotional health in danger. This paper introduces a concept of dangerous events to approach this problem and their three main types based on their characteristics: action, scenarios, and sentiment-based dangerous events.
Two-Dimensional Drift Analysis: Optimizing Two Functions Simultaneously Can Be Hard
Mar 28, 2022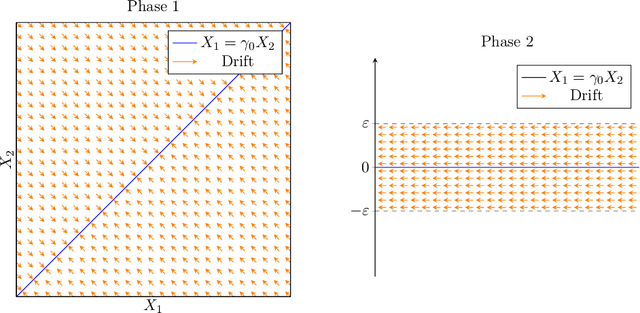
In this paper we show how to use drift analysis in the case of two random variables $X_1, X_2$, when the drift is approximatively given by $A\cdot (X_1,X_2)^T$ for a matrix $A$. The non-trivial case is that $X_1$ and $X_2$ impede each other's progress, and we give a full characterization of this case. As application, we develop and analyze a minimal example TwoLinear of a dynamic environment that can be hard. The environment consists of two linear function $f_1$ and $f_2$ with positive weights $1$ and $n$, and in each generation selection is based on one of them at random. They only differ in the set of positions that have weight $1$ and $n$. We show that the $(1+1)$-EA with mutation rate $\chi/n$ is efficient for small $\chi$ on TwoLinear, but does not find the shared optimum in polynomial time for large $\chi$.
A Conformer Based Acoustic Model for Robust Automatic Speech Recognition
Mar 20, 2022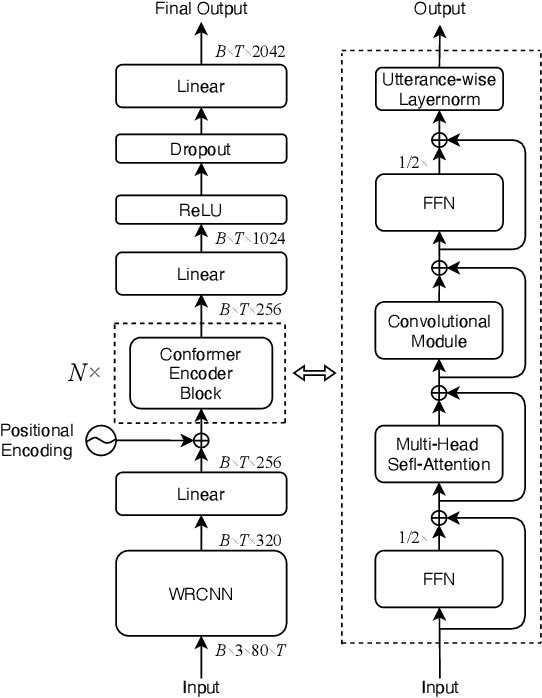
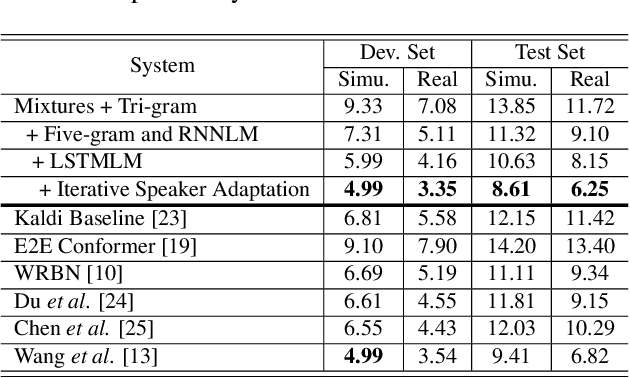
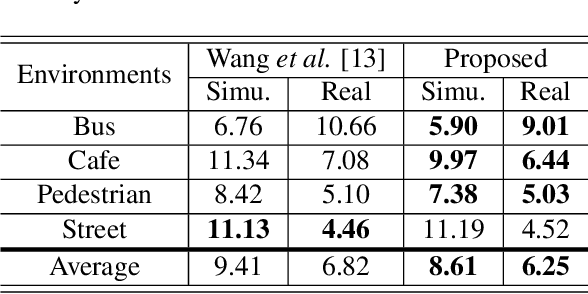
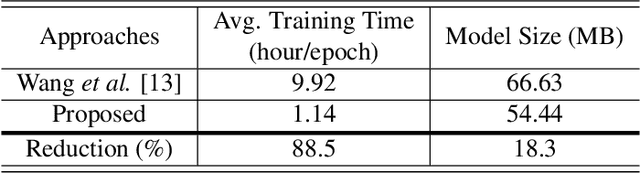
This study addresses robust automatic speech recognition (ASR) by introducing a Conformer-based acoustic model. The proposed model builds on a state-of-the-art recognition system using a bi-directional long short-term memory (BLSTM) model with utterance-wise dropout and iterative speaker adaptation, but employs a Conformer encoder instead of the BLSTM network. The Conformer encoder uses a convolution-augmented attention mechanism for acoustic modeling. The proposed system is evaluated on the monaural ASR task of the CHiME-4 corpus. Coupled with utterance-wise normalization and speaker adaptation, our model achieves $6.25\%$ word error rate, which outperforms the previous best system by $8.4\%$ relatively. In addition, the proposed Conformer-based model is $18.3\%$ smaller in model size and reduces total training time by $79.6\%$.
Capturing Delayed Feedback in Conversion Rate Prediction via Elapsed-Time Sampling
Dec 06, 2020

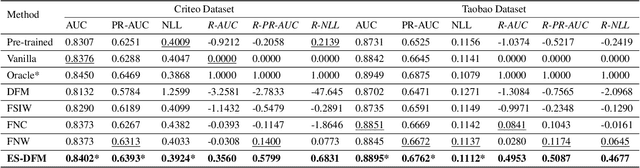

Capturing Delayed Feedback in Conversion Rate Prediction via Elapsed-Time Sampling Hide abstract Conversion rate (CVR) prediction is one of the most critical tasks for digital display advertising. Commercial systems often require to update models in an online learning manner to catch up with the evolving data distribution. However, conversions usually do not happen immediately after a user click. This may result in inaccurate labeling, which is called delayed feedback problem. In previous studies, delayed feedback problem is handled either by waiting positive label for a long period of time, or by consuming the negative sample on its arrival and then insert a positive duplicate when a conversion happens later. Indeed, there is a trade-off between waiting for more accurate labels and utilizing fresh data, which is not considered in existing works. To strike a balance in this trade-off, we propose Elapsed-Time Sampling Delayed Feedback Model (ES-DFM), which models the relationship between the observed conversion distribution and the true conversion distribution. Then we optimize the expectation of true conversion distribution via importance sampling under the elapsed-time sampling distribution. We further estimate the importance weight for each instance, which is used as the weight of loss function in CVR prediction. To demonstrate the effectiveness of ES-DFM, we conduct extensive experiments on a public data and a private industrial dataset. Experimental results confirm that our method consistently outperforms the previous state-of-the-art results.
The Companion Model -- a Canonical Model in Graph Signal Processing
Mar 25, 2022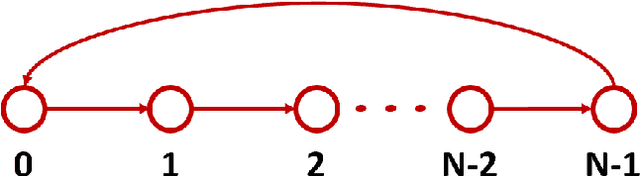
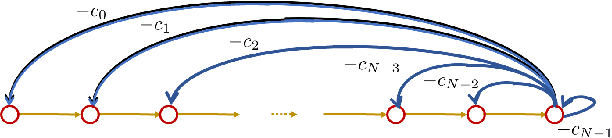
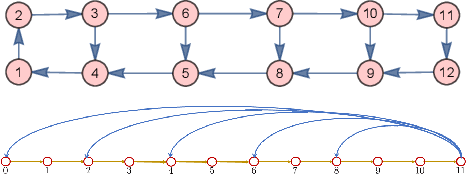
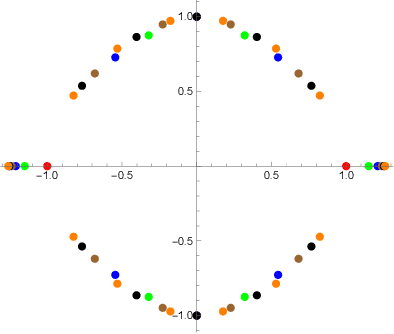
This paper introduces a $\textit{canonical}$ graph signal model defined by a $\textit{canonical}$ graph and a $\textit{canonical}$ shift, the $\textit{companion}$ graph and the $\textit{companion}$ shift. These are canonical because, under standard conditions, we show that any graph signal processing (GSP) model can be transformed into the canonical model. The transform that obtains this is the graph $z$-transform ($\textrm{G$z$T}$) that we introduce. The GSP canonical model comes closest to the discrete signal processing (DSP) time signal models: the structure of the companion shift decomposes into a line shift and a signal continuation just like the DSP shift and the GSP canonical graph is a directed line graph with a terminal condition reflecting the signal continuation condition. We further show that, surprisingly, in the canonical model, convolution of graph signals is fast convolution by the DSP FFT.