 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Ordinal-ResLogit: Interpretable Deep Residual Neural Networks for Ordered Choices
Apr 20, 2022
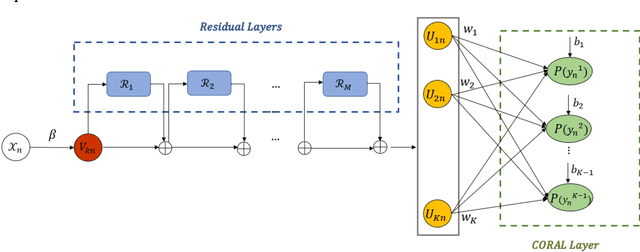
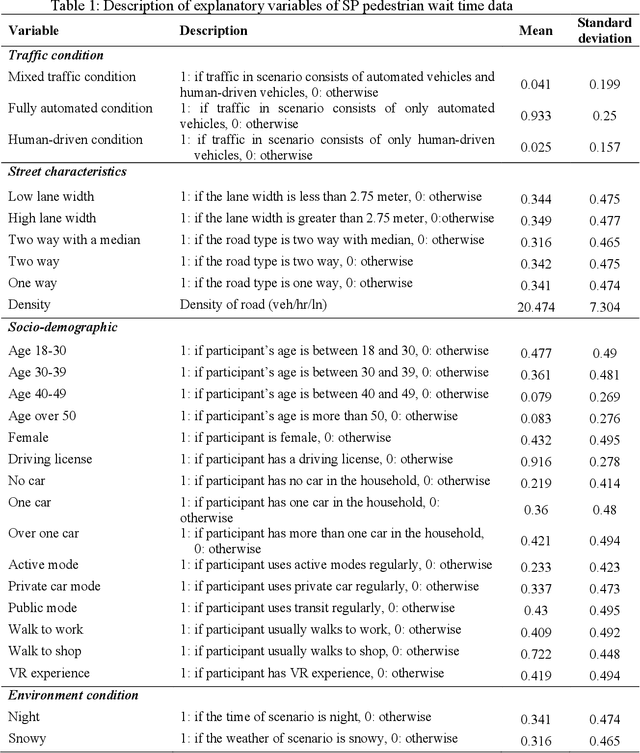
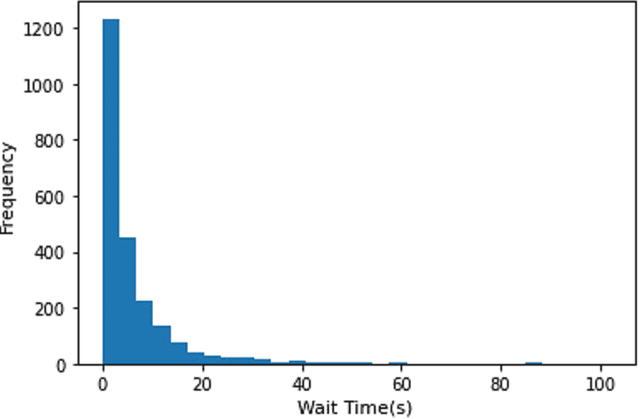
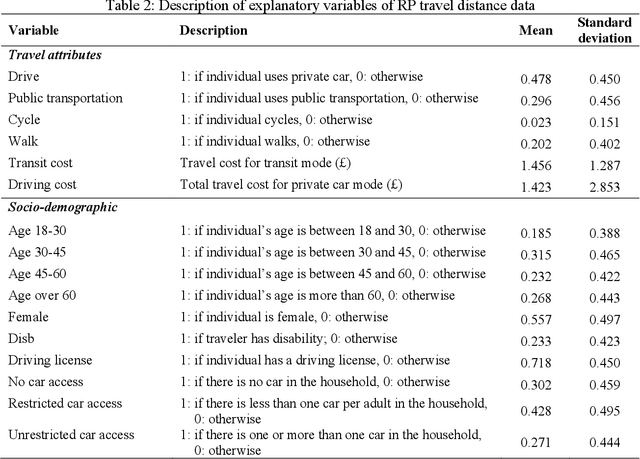
This study presents an Ordinal version of Residual Logit (Ordinal-ResLogit) model to investigate the ordinal responses. We integrate the standard ResLogit model into COnsistent RAnk Logits (CORAL) framework, classified as a binary classification algorithm, to develop a fully interpretable deep learning-based ordinal regression model. As the formulation of the Ordinal-ResLogit model enjoys the Residual Neural Networks concept, our proposed model addresses the main constraint of machine learning algorithms, known as black-box. Moreover, the Ordinal-ResLogit model, as a binary classification framework for ordinal data, guarantees consistency among binary classifiers. We showed that the resulting formulation is able to capture underlying unobserved heterogeneity from the data as well as being an interpretable deep learning-based model. Formulations for market share, substitution patterns, and elasticities are derived. We compare the performance of the Ordinal-ResLogit model with an Ordered Logit Model using a stated preference (SP) dataset on pedestrian wait time and a revealed preference (RP) dataset on travel distance. Our results show that Ordinal-ResLogit outperforms the traditional ordinal regression model for both datasets. Furthermore, the results obtained from the Ordinal-ResLogit RP model show that travel attributes such as driving and transit cost have significant effects on choosing the location of non-mandatory trips. In terms of the Ordinal-ResLogit SP model, our results highlight that the road-related variables and traffic condition are contributing factors in the prediction of pedestrian waiting time such that the mixed traffic condition significantly increases the probability of choosing longer waiting times.
Autoregressive Denoising Diffusion Models for Multivariate Probabilistic Time Series Forecasting
Jan 28, 2021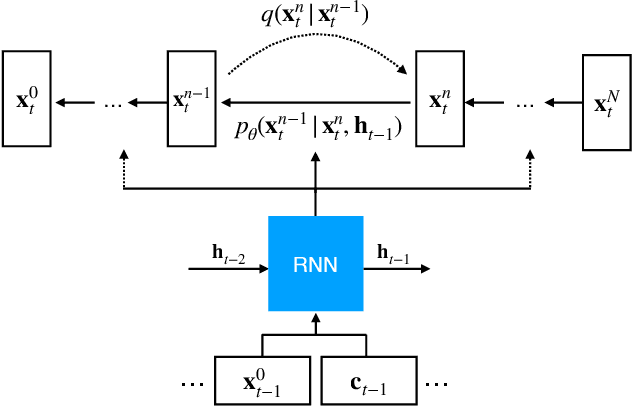
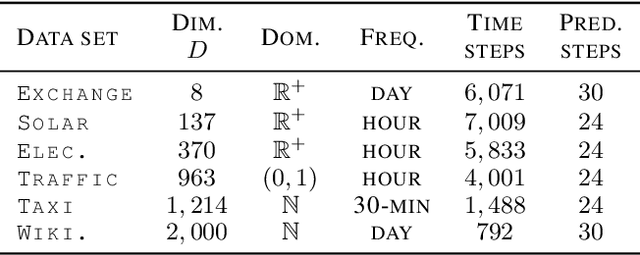
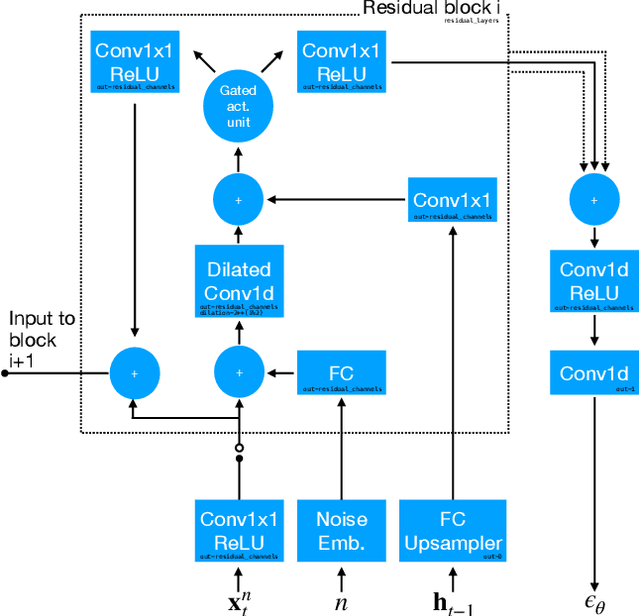
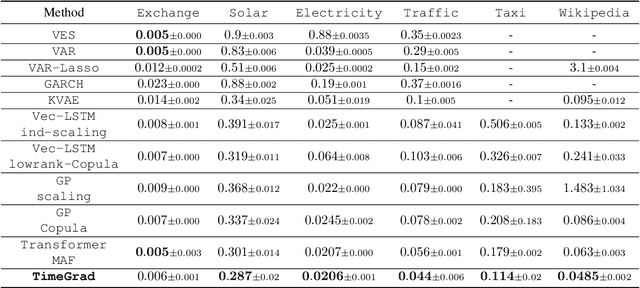
In this work, we propose \texttt{TimeGrad}, an autoregressive model for multivariate probabilistic time series forecasting which samples from the data distribution at each time step by estimating its gradient. To this end, we use diffusion probabilistic models, a class of latent variable models closely connected to score matching and energy-based methods. Our model learns gradients by optimizing a variational bound on the data likelihood and at inference time converts white noise into a sample of the distribution of interest through a Markov chain using Langevin sampling. We demonstrate experimentally that the proposed autoregressive denoising diffusion model is the new state-of-the-art multivariate probabilistic forecasting method on real-world data sets with thousands of correlated dimensions. We hope that this method is a useful tool for practitioners and lays the foundation for future research in this area.
AWAPart: Adaptive Workload-Aware Partitioning of Knowledge Graphs
Mar 28, 2022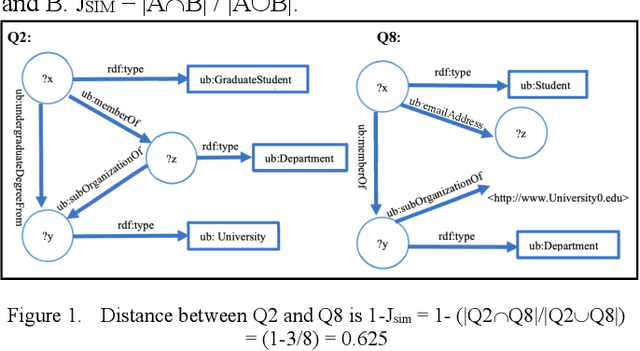
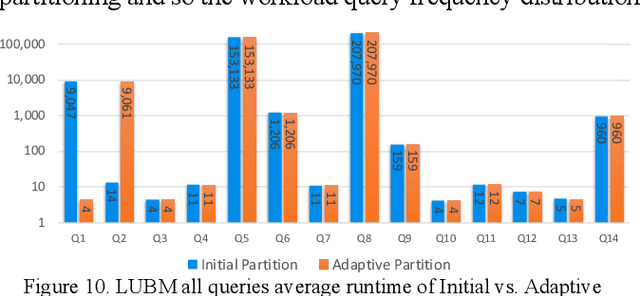
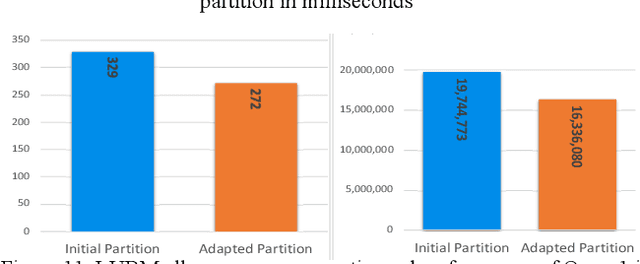
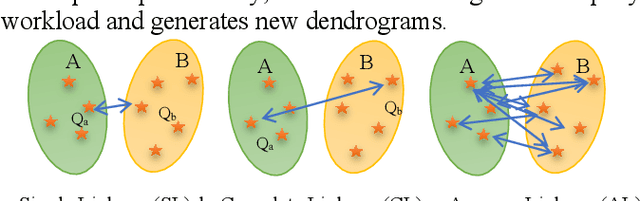
Large-scale knowledge graphs are increasingly common in many domains. Their large sizes often exceed the limits of systems storing the graphs in a centralized data store, especially if placed in main memory. To overcome this, large knowledge graphs need to be partitioned into multiple sub-graphs and placed in nodes in a distributed system. But querying these fragmented sub-graphs poses new challenges, such as increased communication costs, due to distributed joins involving cut edges. To combat these problems, a good partitioning should reduce the edge cuts while considering a given query workload. However, a partitioned graph needs to be continually re-partitioned to accommodate changes in the query workload and maintain a good average processing time. In this paper, an adaptive partitioning method for large-scale knowledge graphs is introduced, which adapts the partitioning in response to changes in the query workload. Our evaluation demonstrates that the performance of processing time for queries is improved after dynamically adapting the partitioning of knowledge graph triples.
Unsupervised Discovery and Composition of Object Light Fields
May 08, 2022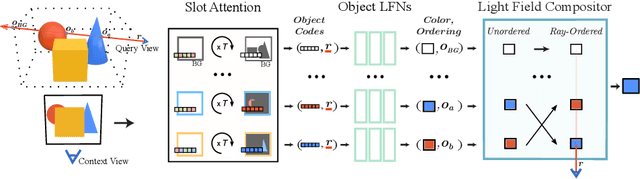

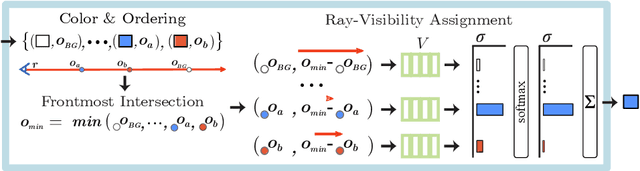

Neural scene representations, both continuous and discrete, have recently emerged as a powerful new paradigm for 3D scene understanding. Recent efforts have tackled unsupervised discovery of object-centric neural scene representations. However, the high cost of ray-marching, exacerbated by the fact that each object representation has to be ray-marched separately, leads to insufficiently sampled radiance fields and thus, noisy renderings, poor framerates, and high memory and time complexity during training and rendering. Here, we propose to represent objects in an object-centric, compositional scene representation as light fields. We propose a novel light field compositor module that enables reconstructing the global light field from a set of object-centric light fields. Dubbed Compositional Object Light Fields (COLF), our method enables unsupervised learning of object-centric neural scene representations, state-of-the-art reconstruction and novel view synthesis performance on standard datasets, and rendering and training speeds at orders of magnitude faster than existing 3D approaches.
Statistical inference of travelers' route choice preferences with system-level data
Apr 23, 2022
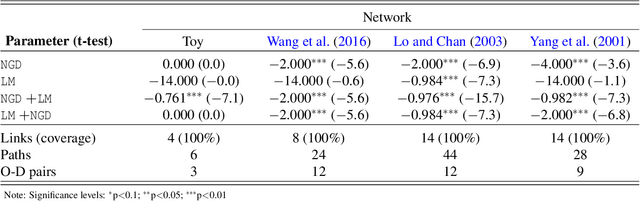
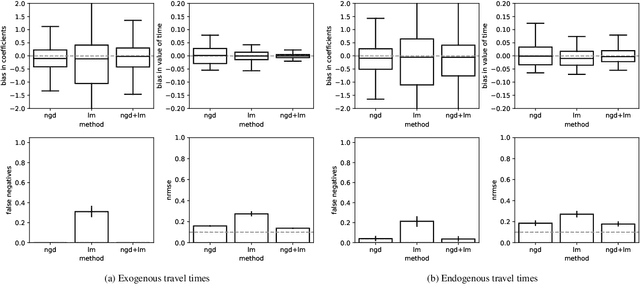
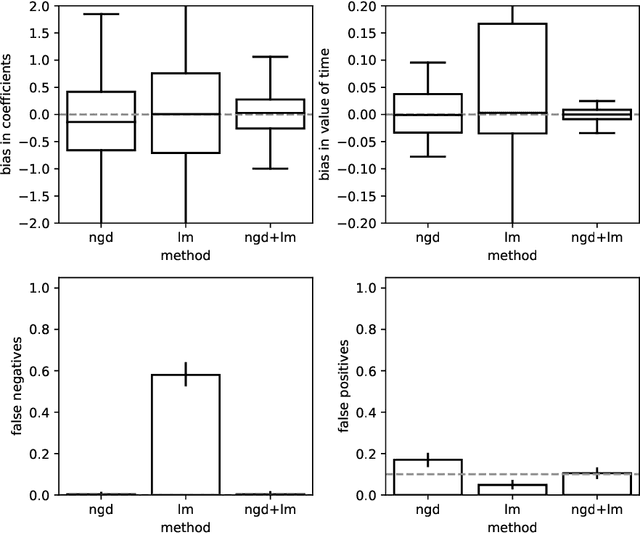
Traditional network models encapsulate travel behavior among all origin-destination pairs based on a simplified and generic utility function. Typically, the utility function consists of travel time solely and its coefficients are equated to estimates obtained from stated preference data. While this modeling strategy is reasonable, the inherent sampling bias in individual-level data may be further amplified over network flow aggregation, leading to inaccurate flow estimates. This data must be collected from surveys or travel diaries, which may be labor intensive, costly and limited to a small time period. To address these limitations, this study extends classical bi-level formulations to estimate travelers' utility functions with multiple attributes using system-level data. We formulate a methodology grounded on non-linear least squares to statistically infer travelers' utility function in the network context using traffic counts, traffic speeds, traffic incidents and sociodemographic information, among other attributes. The analysis of the mathematical properties of the optimization problem and of its pseudo-convexity motivate the use of normalized gradient descent. We also develop a hypothesis test framework to examine statistical properties of the utility function coefficients and to perform attributes selection. Experiments on synthetic data show that the coefficients are consistently recovered and that hypothesis tests are a reliable statistic to identify which attributes are determinants of travelers' route choices. Besides, a series of Monte-Carlo experiments suggest that statistical inference is robust to noise in the Origin-Destination matrix and in the traffic counts, and to various levels of sensor coverage. The methodology is also deployed at a large scale using real-world multi-source data in Fresno, CA collected before and during the COVID-19 outbreak.
Time Series Anomaly Detection with label-free Model Selection
Jun 11, 2021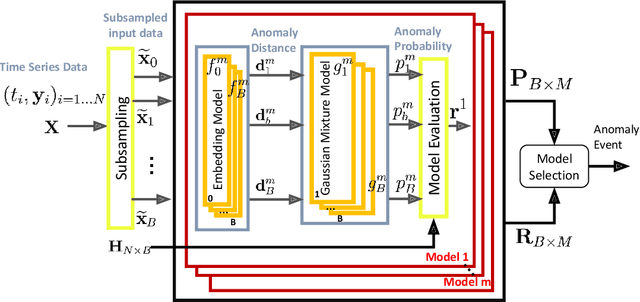

Anomaly detection for time-series data becomes an essential task for many data-driven applications fueled with an abundance of data and out-of-the-box machine-learning algorithms. In many real-world settings, developing a reliable anomaly model is highly challenging due to insufficient anomaly labels and the prohibitively expensive cost of obtaining anomaly examples. It imposes a significant bottleneck to evaluate model quality for model selection and parameter tuning reliably. As a result, many existing anomaly detection algorithms fail to show their promised performance after deployment. In this paper, we propose LaF-AD, a novel anomaly detection algorithm with label-free model selection for unlabeled times-series data. Our proposed algorithm performs a fully unsupervised ensemble learning across a large number of candidate parametric models. We develop a model variance metric that quantifies the sensitivity of anomaly probability with a bootstrapping method. Then it makes a collective decision for anomaly events by model learners using the model variance. Our algorithm is easily parallelizable, more robust for ill-conditioned and seasonal data, and highly scalable for a large number of anomaly models. We evaluate our algorithm against other state-of-the-art methods on a synthetic domain and a benchmark public data set.
Segmentation and Classification of EMG Time-Series During Reach-to-Grasp Motion
Apr 19, 2021
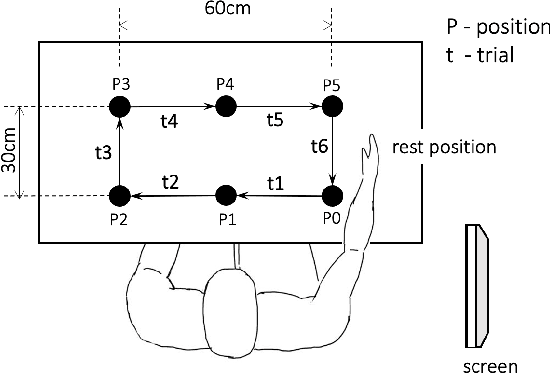
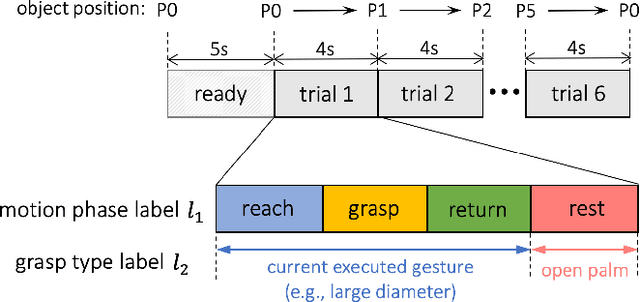
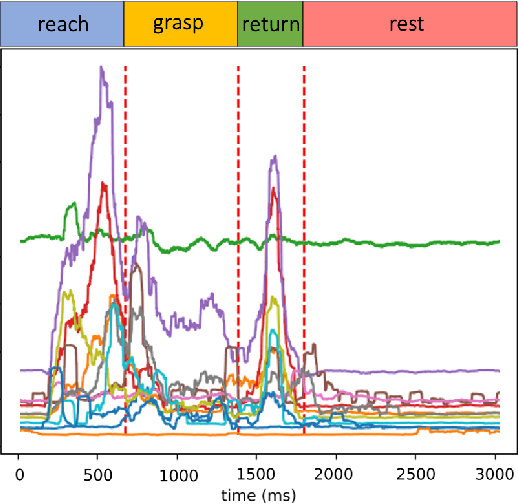
The electromyography (EMG) signals have been widely utilized in human robot interaction for extracting user hand and arm motion instructions. A major challenge of the online interaction with robots is the reliable EMG recognition from real-time data. However, previous studies mainly focused on using steady-state EMG signals with a small number of grasp patterns to implement classification algorithms, which is insufficient to generate robust control regarding the dynamic muscular activity variation in practice. Introducing more EMG variability during training and validation could implement a better dynamic-motion detection, but only limited research focused on such grasp-movement identification, and all of those assessments on the non-static EMG classification require supervised ground-truth label of the movement status. In this study, we propose a framework for classifying EMG signals generated from continuous grasp movements with variations on dynamic arm/hand postures, using an unsupervised motion status segmentation method. We collected data from large gesture vocabularies with multiple dynamic motion phases to encode the transitions from one intent to another based on common sequences of the grasp movements. Two classifiers were constructed for identifying the motion-phase label and grasp-type label, where the dynamic motion phases were segmented and labeled in an unsupervised manner. The proposed framework was evaluated in real-time with the accuracy variation over time presented, which was shown to be efficient due to the high degree of freedom of the EMG data.
Conditional Simulation Using Diffusion Schrödinger Bridges
Feb 27, 2022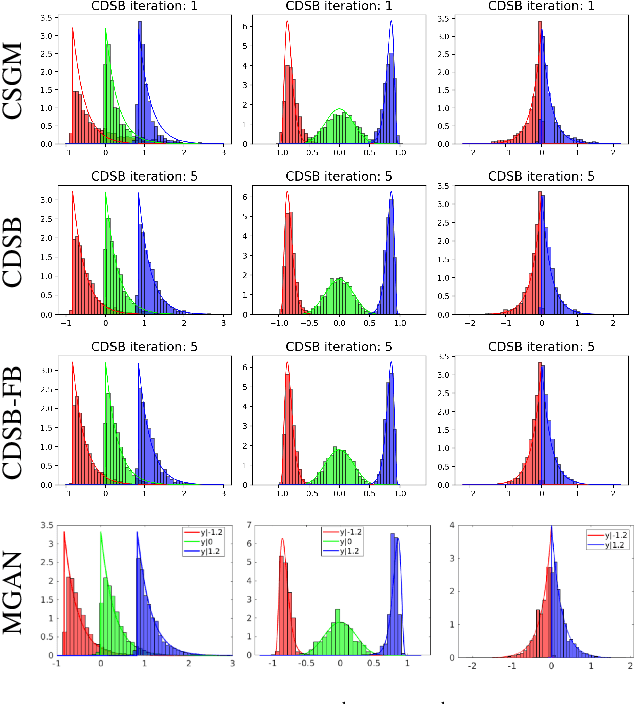
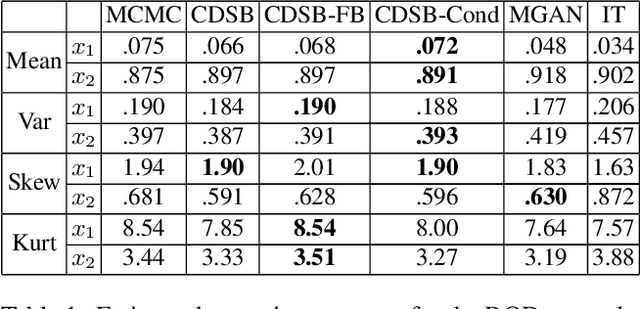


Denoising diffusion models have recently emerged as a powerful class of generative models. They provide state-of-the-art results, not only for unconditional simulation, but also when used to solve conditional simulation problems arising in a wide range of inverse problems such as image inpainting or deblurring. A limitation of these models is that they are computationally intensive at generation time as they require simulating a diffusion process over a long time horizon. When performing unconditional simulation, a Schr\"odinger bridge formulation of generative modeling leads to a theoretically grounded algorithm shortening generation time which is complementary to other proposed acceleration techniques. We extend here the Schr\"odinger bridge framework to conditional simulation. We demonstrate this novel methodology on various applications including image super-resolution and optimal filtering for state-space models.
Graphical Models for Financial Time Series and Portfolio Selection
Jan 22, 2021
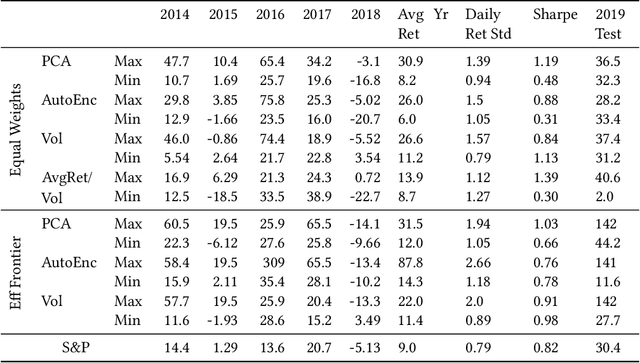
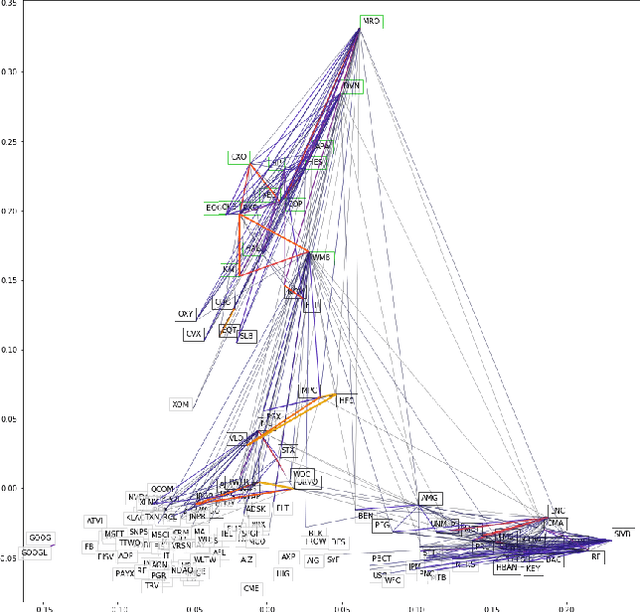
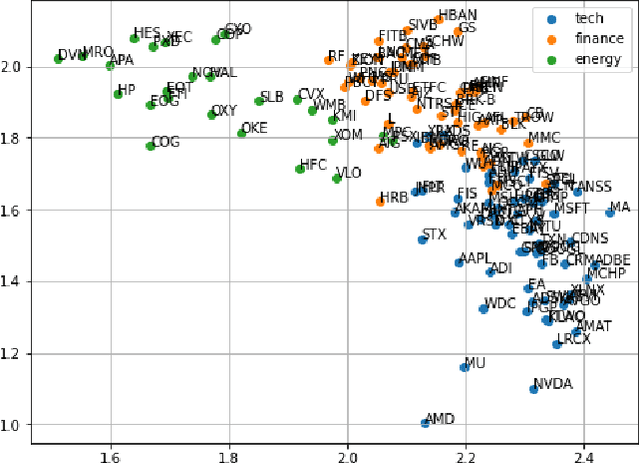
We examine a variety of graphical models to construct optimal portfolios. Graphical models such as PCA-KMeans, autoencoders, dynamic clustering, and structural learning can capture the time varying patterns in the covariance matrix and allow the creation of an optimal and robust portfolio. We compared the resulting portfolios from the different models with baseline methods. In many cases our graphical strategies generated steadily increasing returns with low risk and outgrew the S&P 500 index. This work suggests that graphical models can effectively learn the temporal dependencies in time series data and are proved useful in asset management.
Exploration, Exploitation, and Engagement in Multi-Armed Bandits with Abandonment
May 26, 2022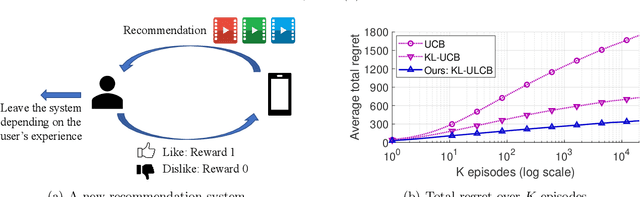

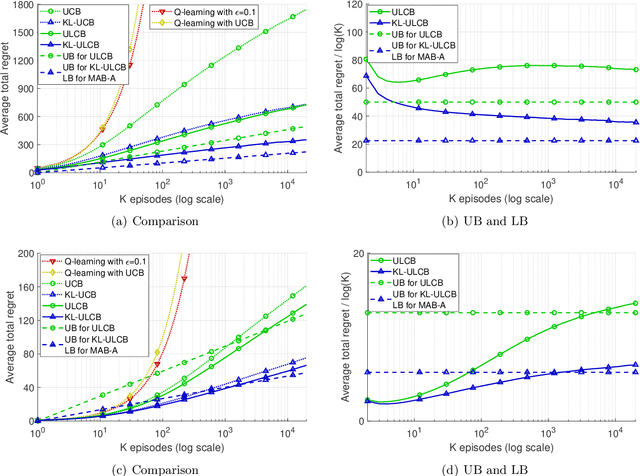

Multi-armed bandit (MAB) is a classic model for understanding the exploration-exploitation trade-off. The traditional MAB model for recommendation systems assumes the user stays in the system for the entire learning horizon. In new online education platforms such as ALEKS or new video recommendation systems such as TikTok and YouTube Shorts, the amount of time a user spends on the app depends on how engaging the recommended contents are. Users may temporarily leave the system if the recommended items cannot engage the users. To understand the exploration, exploitation, and engagement in these systems, we propose a new model, called MAB-A where "A" stands for abandonment and the abandonment probability depends on the current recommended item and the user's past experience (called state). We propose two algorithms, ULCB and KL-ULCB, both of which do more exploration (being optimistic) when the user likes the previous recommended item and less exploration (being pessimistic) when the user does not like the previous item. We prove that both ULCB and KL-ULCB achieve logarithmic regret, $O(\log K)$, where $K$ is the number of visits (or episodes). Furthermore, the regret bound under KL-ULCB is asymptotically sharp. We also extend the proposed algorithms to the general-state setting. Simulation results confirm our theoretical analysis and show that the proposed algorithms have significantly lower regrets than the traditional UCB and KL-UCB, and Q-learning-based algorithms.