 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Timing is Everything: Learning to Act Selectively with Costly Actions and Budgetary Constraints
Jun 06, 2022
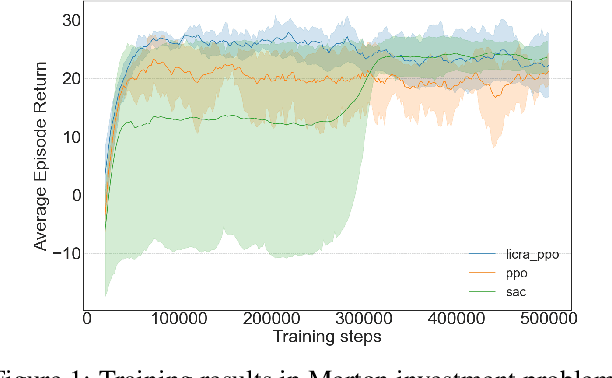
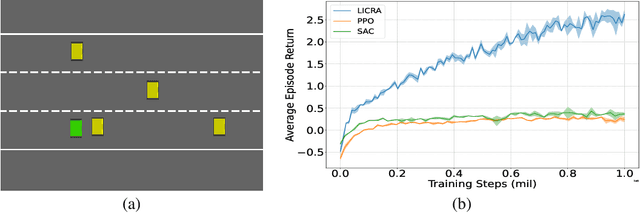
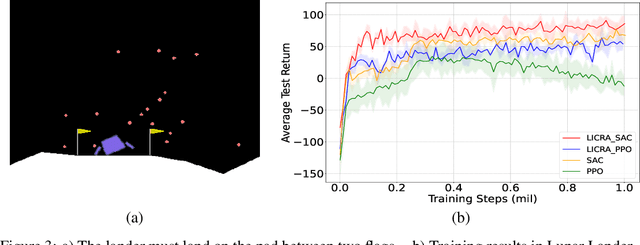
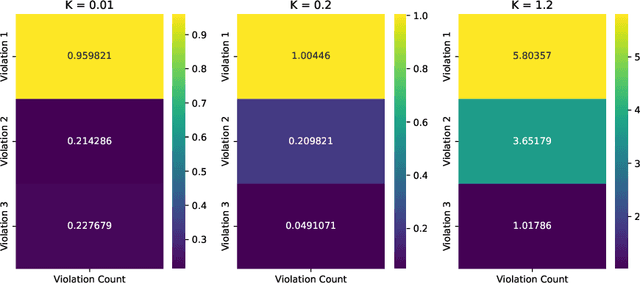
Many real-world settings involve costs for performing actions; transaction costs in financial systems and fuel costs being common examples. In these settings, performing actions at each time step quickly accumulates costs leading to vastly suboptimal outcomes. Additionally, repeatedly acting produces wear and tear and ultimately, damage. Determining when to act is crucial for achieving successful outcomes and yet, the challenge of efficiently learning to behave optimally when actions incur minimally bounded costs remains unresolved. In this paper, we introduce a reinforcement learning (RL) framework named Learnable Impulse Control Reinforcement Algorithm (LICRA), for learning to optimally select both when to act and which actions to take when actions incur costs. At the core of LICRA is a nested structure that combines RL and a form of policy known as impulse control which learns to maximise objectives when actions incur costs. We prove that LICRA, which seamlessly adopts any RL method, converges to policies that optimally select when to perform actions and their optimal magnitudes. We then augment LICRA to handle problems in which the agent can perform at most $k<\infty$ actions and more generally, faces a budget constraint. We show LICRA learns the optimal value function and ensures budget constraints are satisfied almost surely. We demonstrate empirically LICRA's superior performance against benchmark RL methods in OpenAI gym's Lunar Lander and in Highway environments and a variant of the Merton portfolio problem within finance.
Why GANs are overkill for NLP
May 19, 2022This work offers a novel theoretical perspective on why, despite numerous attempts, adversarial approaches to generative modeling (e.g., GANs) have not been as popular for certain generation tasks, particularly sequential tasks such as Natural Language Generation, as they have in others, such as Computer Vision. In particular, on sequential data such as text, maximum-likelihood approaches are significantly more utilized than GANs. We show that, while it may seem that maximizing likelihood is inherently different than minimizing distinguishability, this distinction is largely artificial and only holds for limited models. We argue that minimizing KL-divergence (i.e., maximizing likelihood) is a more efficient approach to effectively minimizing the same distinguishability criteria that adversarial models seek to optimize. Reductions show that minimizing distinguishability can be seen as simply boosting likelihood for certain families of models including n-gram models and neural networks with a softmax output layer. To achieve a full polynomial-time reduction, a novel next-token distinguishability model is considered.
Adaptive Modulation for Wobbling UAV Air-to-Ground Links in Millimeter-wave Bands
Apr 13, 2022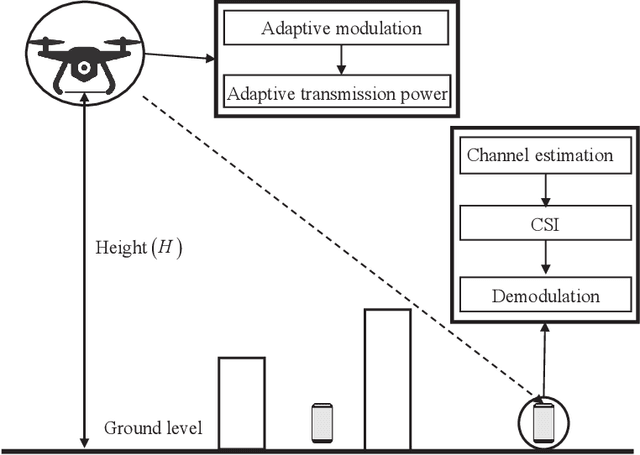
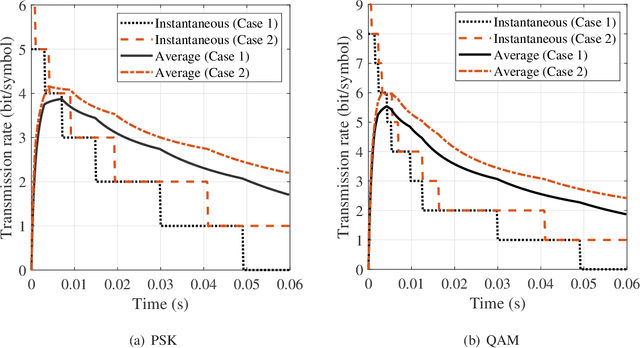
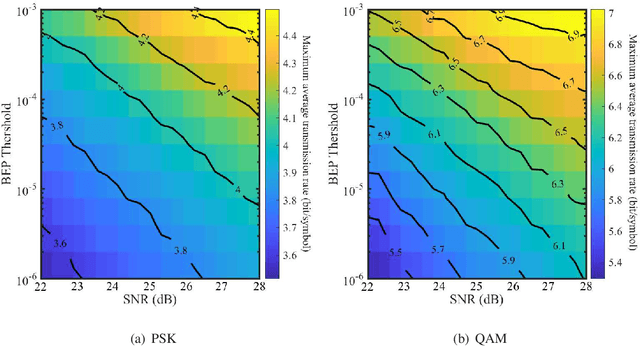
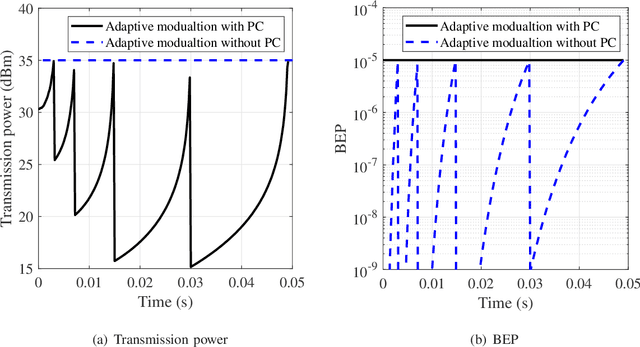
The emerging millimeter-wave (mm-wave) unmanned aerial vehicle (UAV) air-to-ground (A2G) communications are facing the Doppler effect problem that arises from the inevitable wobbling of the UAV. The fast time-varying channel for UAV A2G communications may lead to the outdated channel state information (CSI) from the channel estimation. In this paper, we introduce two detectors to demodulate the received signal and get the instantaneous bit error probability (BEP) of a mm-wave UAV A2G link under imperfect CSI. Based on the designed detectors, we propose an adaptive modulation scheme to maximize the average transmission rate under imperfect CSI by optimizing the data transmission time subject to the maximum tolerable BEP. A power control policy is in conjunction with adaptive modulation to minimize the transmission power while maintaining both the BEP under the threshold and the maximized average transmission rate. Numerical results show that the proposed adaptive modulation scheme in conjunction with the power control policy could maximize the temporally averaged transmission rate, while saves as much as 50\% energy.
Constraining Gaussian processes for physics-informed acoustic emission mapping
Jun 03, 2022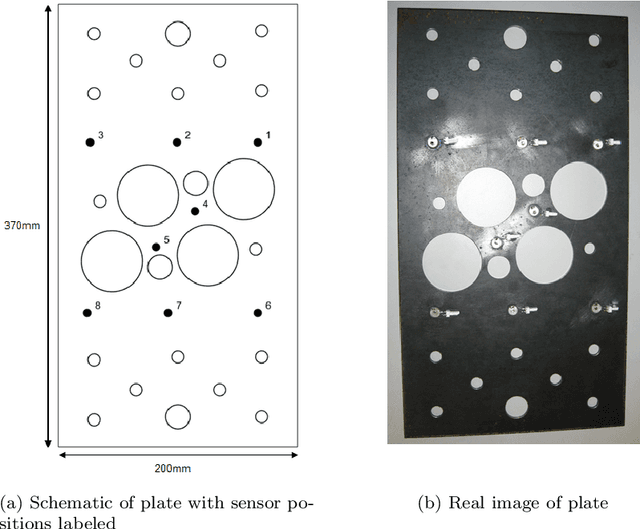
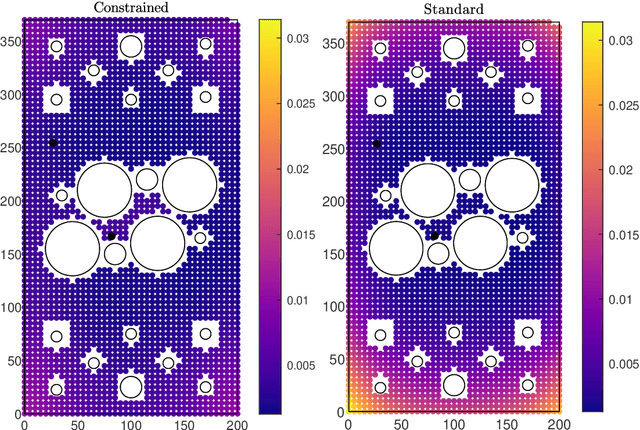
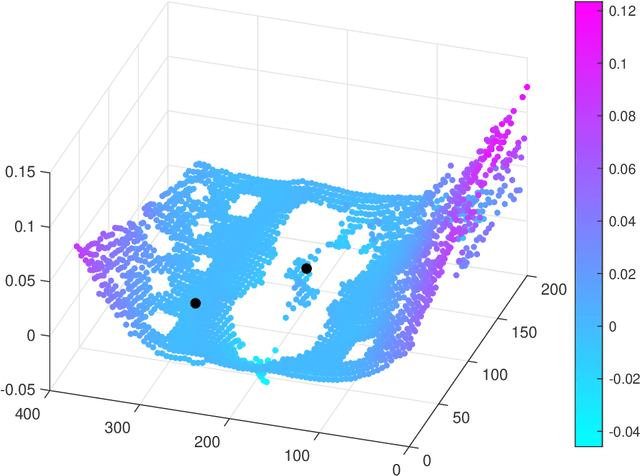
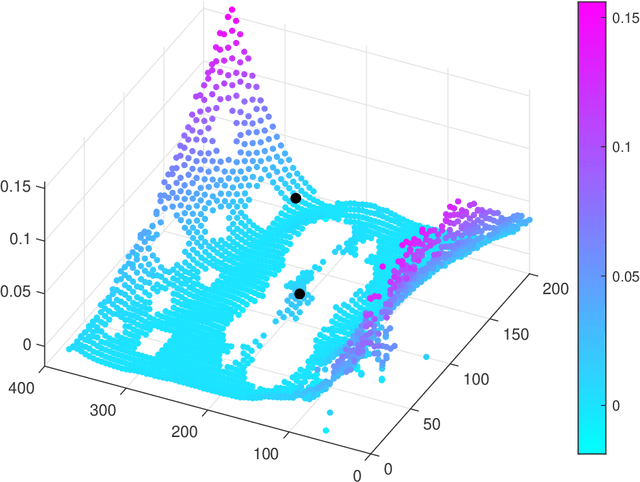
The automated localisation of damage in structures is a challenging but critical ingredient in the path towards predictive or condition-based maintenance of high value structures. The use of acoustic emission time of arrival mapping is a promising approach to this challenge, but is severely hindered by the need to collect a dense set of artificial acoustic emission measurements across the structure, resulting in a lengthy and often impractical data acquisition process. In this paper, we consider the use of physics-informed Gaussian processes for learning these maps to alleviate this problem. In the approach, the Gaussian process is constrained to the physical domain such that information relating to the geometry and boundary conditions of the structure are embedded directly into the learning process, returning a model that guarantees that any predictions made satisfy physically-consistent behaviour at the boundary. A number of scenarios that arise when training measurement acquisition is limited, including where training data are sparse, and also of limited coverage over the structure of interest. Using a complex plate-like structure as an experimental case study, we show that our approach significantly reduces the burden of data collection, where it is seen that incorporation of boundary condition knowledge significantly improves predictive accuracy as training observations are reduced, particularly when training measurements are not available across all parts of the structure.
Functional Connectivity Methods for EEG-based Biometrics on a Large, Heterogeneous Dataset
Jun 03, 2022
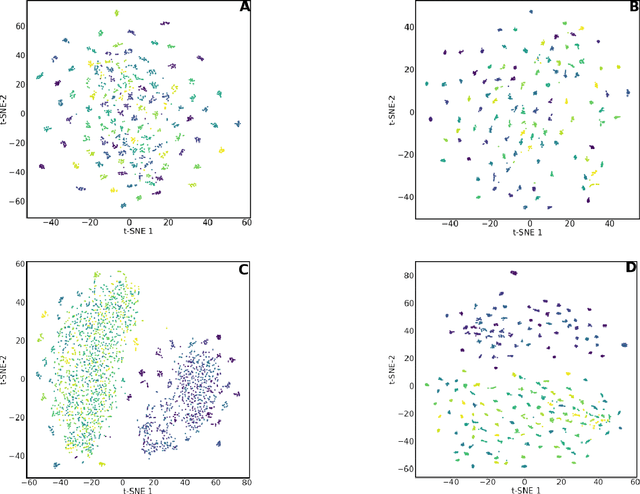
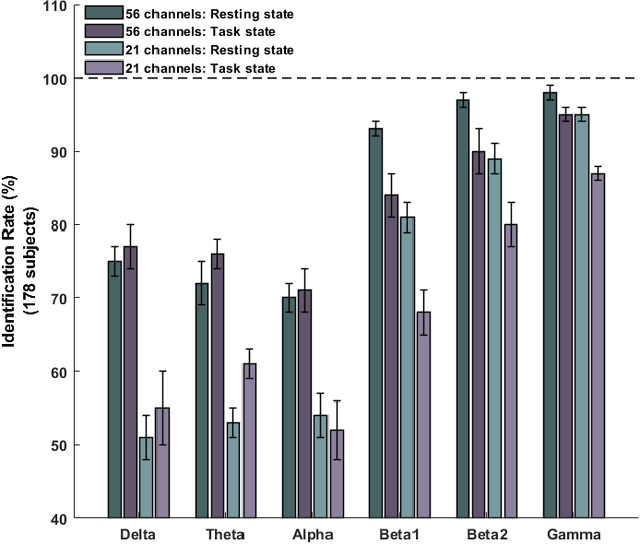
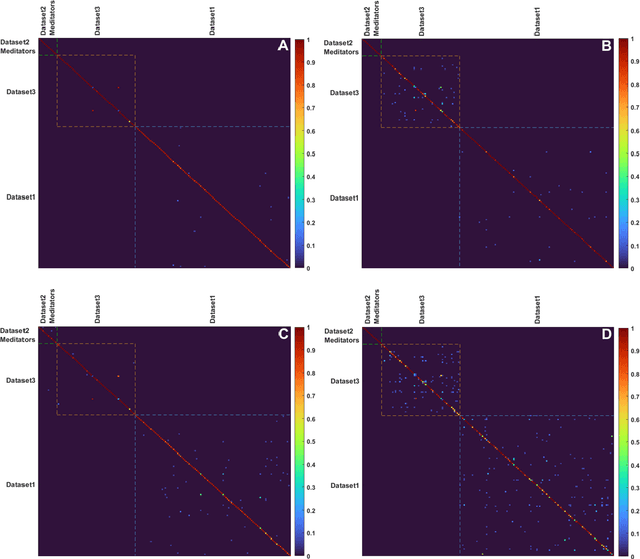
This study examines the utility of functional connectivity (FC) and graph-based (GB) measures with a support vector machine classifier for use in electroencephalogram (EEG) based biometrics. Although FC-based features have been used in biometric applications, studies assessing the identification algorithms on heterogeneous and large datasets are scarce. This work investigates the performance of FC and GB metrics on a dataset of 184 subjects formed by pooling three datasets recorded under different protocols and acquisition systems. The results demonstrate the higher discriminatory power of FC than GB metrics. The identification accuracy increases with higher frequency EEG bands, indicating the enhanced uniqueness of the neural signatures in beta and gamma bands. Using all the 56 EEG channels common to the three databases, the best identification accuracy of 97.4% is obtained using phase-locking value (PLV) based measures extracted from the gamma frequency band. Further, we investigate the effect of the length of the analysis epoch to determine the data acquisition time required to obtain satisfactory identification accuracy. When the number of channels is reduced to 21 from 56, there is a marginal reduction of 2.4% only in the identification accuracy using PLV features in the gamma band. Additional experiments have been conducted to study the effect of the cognitive state of the subject and mismatched train/test conditions on the performance of the system.
Automatic Expert Selection for Multi-Scenario and Multi-Task Search
Jun 06, 2022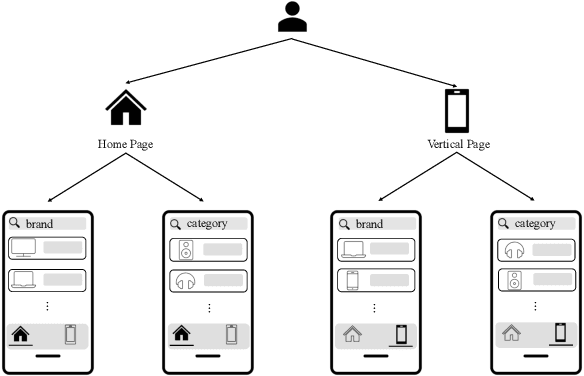
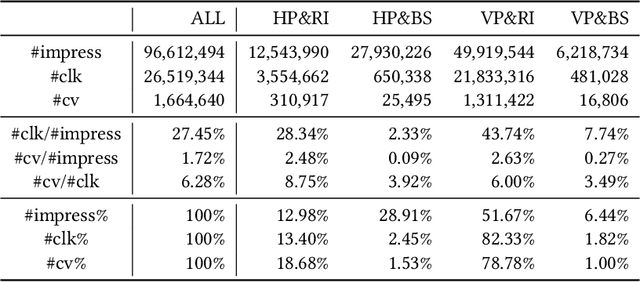
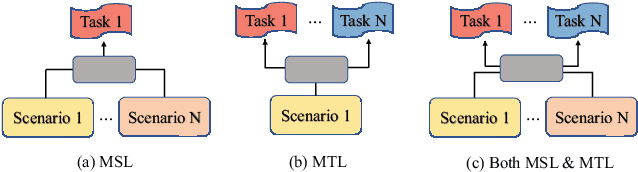
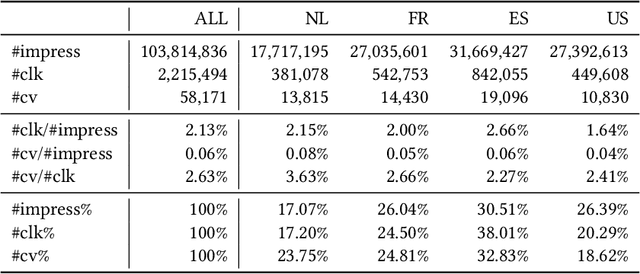
Multi-scenario learning (MSL) enables a service provider to cater for users' fine-grained demands by separating services for different user sectors, e.g., by user's geographical region. Under each scenario there is a need to optimize multiple task-specific targets e.g., click through rate and conversion rate, known as multi-task learning (MTL). Recent solutions for MSL and MTL are mostly based on the multi-gate mixture-of-experts (MMoE) architecture. MMoE structure is typically static and its design requires domain-specific knowledge, making it less effective in handling both MSL and MTL. In this paper, we propose a novel Automatic Expert Selection framework for Multi-scenario and Multi-task search, named AESM^{2}. AESM^{2} integrates both MSL and MTL into a unified framework with an automatic structure learning. Specifically, AESM^{2} stacks multi-task layers over multi-scenario layers. This hierarchical design enables us to flexibly establish intrinsic connections between different scenarios, and at the same time also supports high-level feature extraction for different tasks. At each multi-scenario/multi-task layer, a novel expert selection algorithm is proposed to automatically identify scenario-/task-specific and shared experts for each input. Experiments over two real-world large-scale datasets demonstrate the effectiveness of AESM^{2} over a battery of strong baselines. Online A/B test also shows substantial performance gain on multiple metrics. Currently, AESM^{2} has been deployed online for serving major traffic.
Real-time Virtual Intraoperative CT for Image Guided Surgery
Dec 05, 2021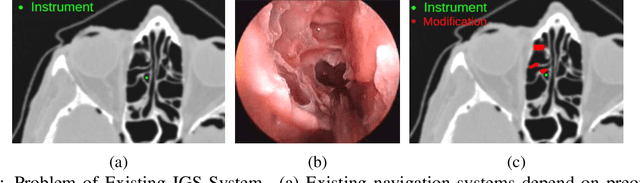
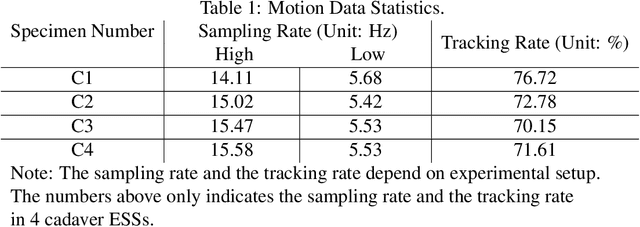
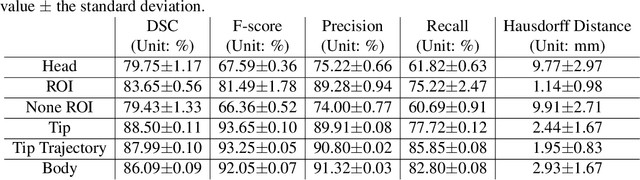
Abstract. Purpose: This paper presents a scheme for generating virtual intraoperative CT scans in order to improve surgical completeness in Endoscopic Sinus Surgeries (ESS). Approach: The work presents three methods, the tip motion-based, the tip trajectory-based, and the instrument based, along with non-parametric smoothing and Gaussian Process Regression, for virtual intraoperative CT generation. Results: The proposed methods studied and compared on ESS performed on cadavers. Surgical results show all three methods improve the Dice Similarity Coefficients > 86%, with F-score > 92% and precision > 89.91%. The tip trajectory-based method was found to have best performance and reached 96.87% precision in surgical completeness evaluation. Conclusions: This work demonstrated that virtual intraoperative CT scans improves the consistency between the actual surgical scene and the reference model, and improves surgical completeness in ESS. Comparing with actual intraoperative CT scans, the proposed scheme has no impact on existing surgical protocols, does not require extra hardware other than the one is already available in most ESS overcome the high costs, the repeated radiation, and the elongated anesthesia caused by actual intraoperative CTs, and is practical in ESS.
Fluctuation-based Outlier Detection
Apr 21, 2022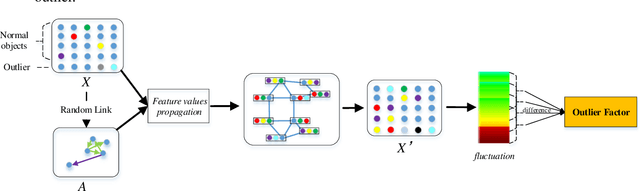
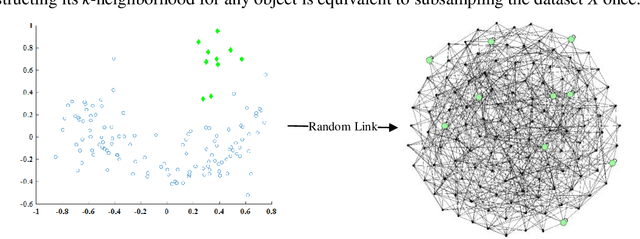
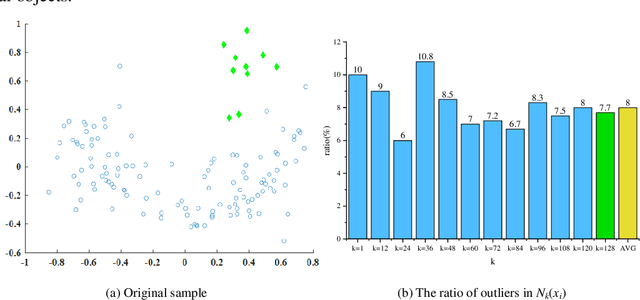
Outlier detection is an important topic in machine learning and has been used in a wide range of applications. Outliers are objects that are few in number and deviate from the majority of objects. As a result of these two properties, we show that outliers are susceptible to a mechanism called fluctuation. This article proposes a method called fluctuation-based outlier detection (FBOD) that achieves a low linear time complexity and detects outliers purely based on the concept of fluctuation without employing any distance, density or isolation measure. Fundamentally different from all existing methods. FBOD first converts the Euclidean structure datasets into graphs by using random links, then propagates the feature value according to the connection of the graph. Finally, by comparing the difference between the fluctuation of an object and its neighbors, FBOD determines the object with a larger difference as an outlier. The results of experiments comparing FBOD with seven state-of-the-art algorithms on eight real-world tabular datasets and three video datasets show that FBOD outperforms its competitors in the majority of cases and that FBOD has only 5% of the execution time of the fastest algorithm. The experiment codes are available at: https://github.com/FluctuationOD/Fluctuation-based-Outlier-Detection.
Inference of stochastic time series with missing data
Jan 28, 2021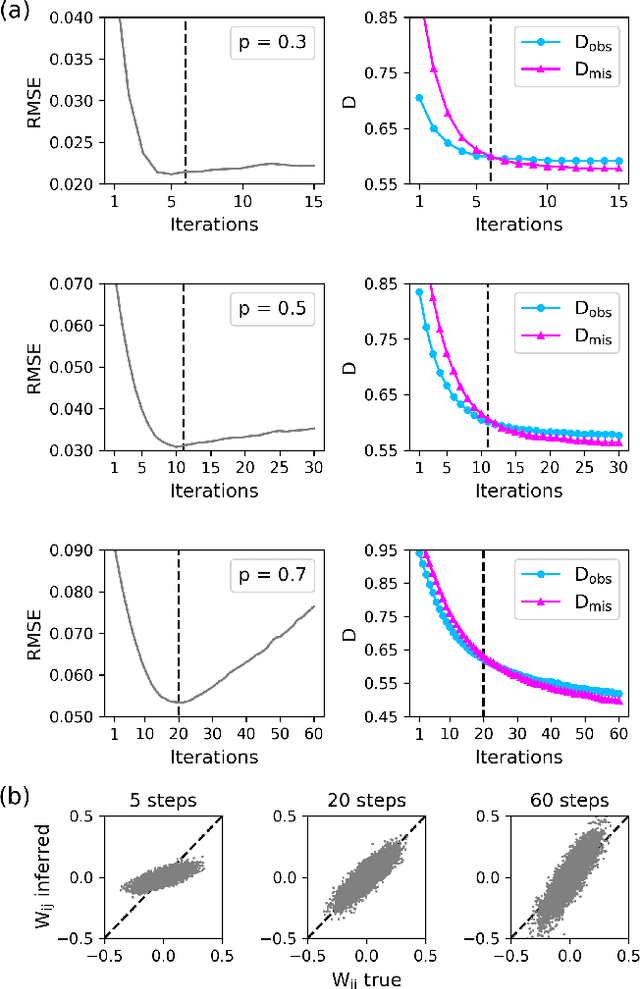
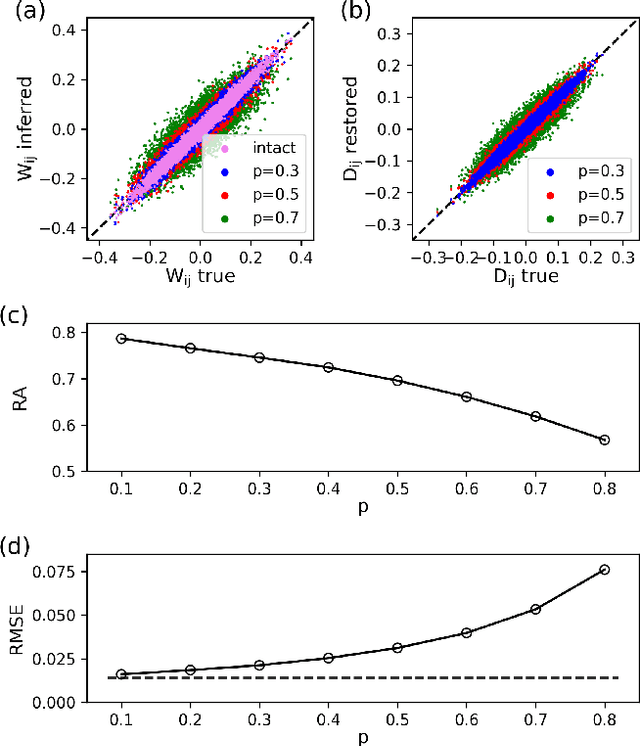
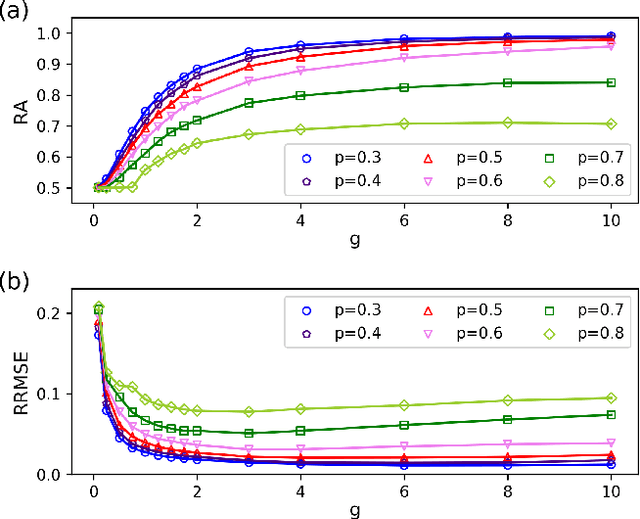
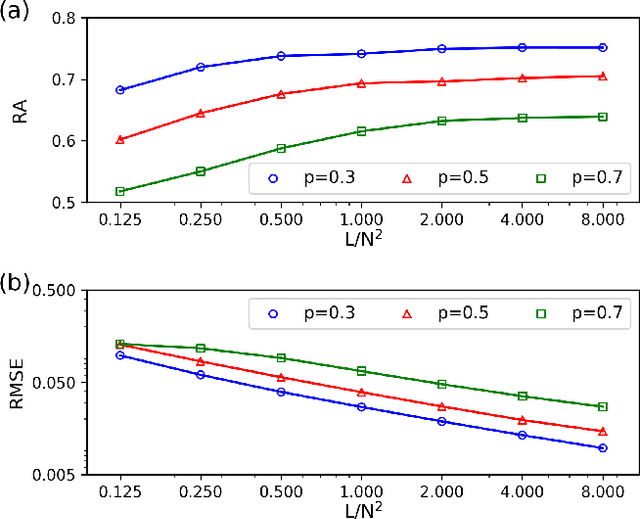
Inferring dynamics from time series is an important objective in data analysis. In particular, it is challenging to infer stochastic dynamics given incomplete data. We propose an expectation maximization (EM) algorithm that iterates between alternating two steps: E-step restores missing data points, while M-step infers an underlying network model of restored data. Using synthetic data generated by a kinetic Ising model, we confirm that the algorithm works for restoring missing data points as well as inferring the underlying model. At the initial iteration of the EM algorithm, the model inference shows better model-data consistency with observed data points than with missing data points. As we keep iterating, however, missing data points show better model-data consistency. We find that demanding equal consistency of observed and missing data points provides an effective stopping criterion for the iteration to prevent overshooting the most accurate model inference. Armed with this EM algorithm with this stopping criterion, we infer missing data points and an underlying network from a time-series data of real neuronal activities. Our method recovers collective properties of neuronal activities, such as time correlations and firing statistics, which have previously never been optimized to fit.
The Wavefunction of Continuous-Time Recurrent Neural Networks
Feb 13, 2021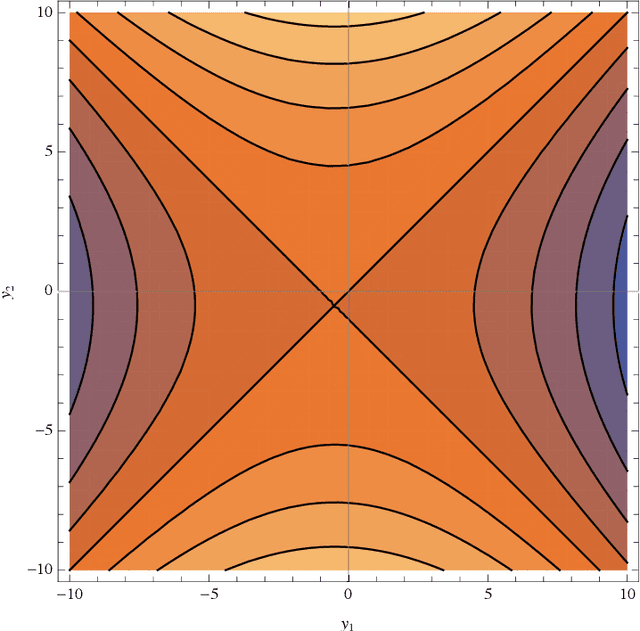
In this paper, we explore the possibility of deriving a quantum wavefunction for continuous-time recurrent neural network (CTRNN). We did this by first starting with a two-dimensional dynamical system that describes the classical dynamics of a continuous-time recurrent neural network, and then deriving a Hamiltonian. After this, we quantized this Hamiltonian on a Hilbert space $\mathbb{H} = L^2(\mathbb{R})$ using Weyl quantization. We then solved the Schrodinger equation which gave us the wavefunction in terms of Kummer's confluent hypergeometric function corresponding to the neural network structure. Upon applying spatial boundary conditions at infinity, we were able to derive conditions/restrictions on the weights and hyperparameters of the neural network, which could potentially give insights on the the nature of finding optimal weights of said neural networks.