 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Designing Robust Biotechnological Processes Regarding Variabilities using Multi-Objective Optimization Applied to a Biopharmaceutical Seed Train Design
May 06, 2022


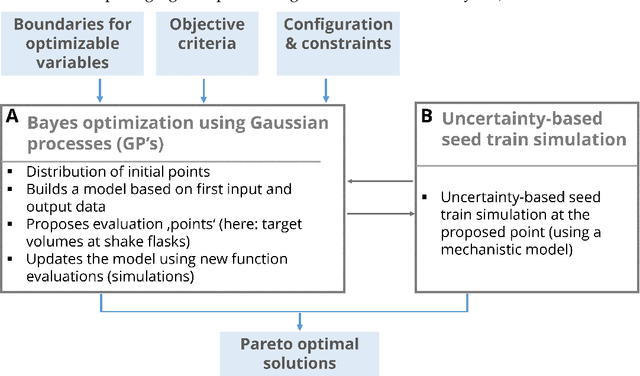

Development and optimization of biopharmaceutical production processes with cell cultures is cost- and time-consuming and often performed rather empirically. Efficient optimization of multiple-objectives like process time, viable cell density, number of operating steps & cultivation scales, required medium, amount of product as well as product quality depicts a promising approach. This contribution presents a workflow which couples uncertainty-based upstream simulation and Bayes optimization using Gaussian processes. Its application is demonstrated in a simulation case study for a relevant industrial task in process development, the design of a robust cell culture expansion process (seed train), meaning that despite uncertainties and variabilities concerning cell growth, low variations of viable cell density during the seed train are obtained. Compared to a non-optimized reference seed train, the optimized process showed much lower deviation rates regarding viable cell densities (<~10% instead of 41.7%) using 5 or 4 shake flask scales and seed train duration could be reduced by 56 h from 576 h to 520 h. Overall, it is shown that applying Bayes optimization allows for optimization of a multi-objective optimization function with several optimizable input variables and under a considerable amount of constraints with a low computational effort. This approach provides the potential to be used in form of a decision tool, e.g. for the choice of an optimal and robust seed train design or for further optimization tasks within process development.
Control Barrier Functions and Input-to-State Safety with Application to Automated Vehicles
Jun 07, 2022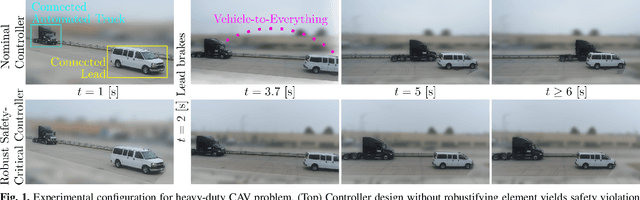
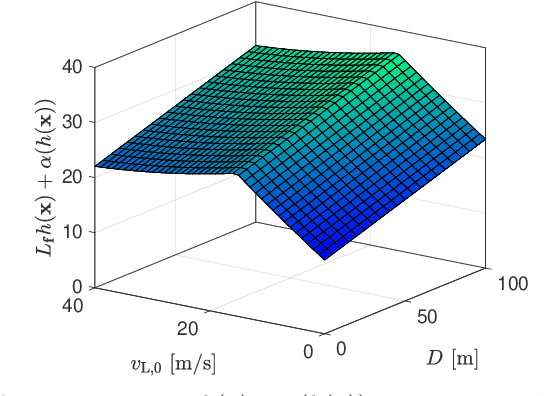
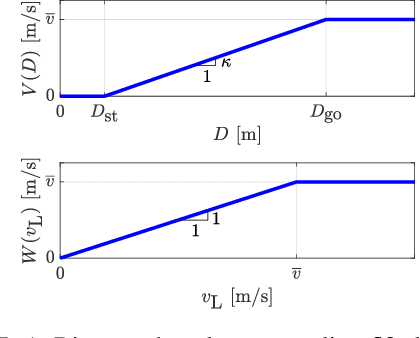
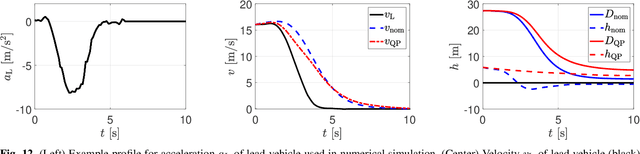
Balancing safety and performance is one of the predominant challenges in modern control system design. Moreover, it is crucial to robustly ensure safety without inducing unnecessary conservativeness that degrades performance. In this work we present a constructive approach for safety-critical control synthesis via Control Barrier Functions (CBF). By filtering a hand-designed controller via a CBF, we are able to attain performant behavior while providing rigorous guarantees of safety. In the face of disturbances, robust safety and performance are simultaneously achieved through the notion of Input-to-State Safety (ISSf). We take a tutorial approach by developing the CBF-design methodology in parallel with an inverted pendulum example, making the challenges and sensitivities in the design process concrete. To establish the capability of the proposed approach, we consider the practical setting of safety-critical design via CBFs for a connected automated vehicle (CAV) in the form of a class-8 truck without a trailer. Through experimentation we see the impact of unmodeled disturbances in the truck's actuation system on the safety guarantees provided by CBFs. We characterize these disturbances and using ISSf, produce a robust controller that achieves safety without conceding performance. We evaluate our design both in simulation, and for the first time on an automotive system, experimentally.
NeuralTree: A 256-Channel 0.227μJ/class Versatile Neural Activity Classification and Closed-Loop Neuromodulation SoC
May 12, 2022



Closed-loop neural interfaces with on-chip machine learning can detect and suppress disease symptoms in neurological disorders or restore lost functions in paralyzed patients. While high-density neural recording can provide rich neural activity information for accurate disease-state detection, existing systems have low channel count and poor scalability, which could limit their therapeutic efficacy. This work presents a highly scalable and versatile closed-loop neural interface SoC that can overcome these limitations. A 256-channel time-division multiplexed (TDM) front-end with a two-step fast-settling mixed-signal DC servo loop (DSL) is proposed to record high-spatial-resolution neural activity and perform channel-selective brain-state inference. A tree-structured neural network (NeuralTree) classification processor extracts a rich set of neural biomarkers in a patient- and disease-specific manner. Trained with an energy-aware learning algorithm, the NeuralTree classifier detects the symptoms of underlying disorders at an optimal energy-accuracy trade-off. A 16-channel high-voltage (HV) compliant neurostimulator closes the therapeutic loop by delivering charge-balanced biphasic current pulses to the brain. The proposed SoC was fabricated in 65nm CMOS and achieved a 0.227{\mu}J/class energy efficiency in a compact area of 0.014mm\textsuperscript{2}/channel. The SoC was extensively verified on human electroencephalography (EEG) and intracranial EEG (iEEG) epilepsy datasets, obtaining 95.6\%/94\% sensitivity and 96.8\%/96.9\% specificity, respectively. \emph{In-vivo} neural recordings using soft {\mu}ECoG arrays and multi-domain biomarker extraction were further performed on a rat model of epilepsy. In addition, for the first time in literature, on-chip classification of rest-state tremor in Parkinson's disease from human local field potentials (LFPs) was demonstrated.
Parameter Adaptation for Joint Distribution Shifts
May 15, 2022
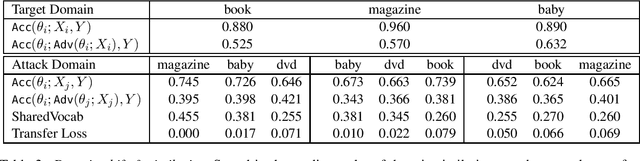
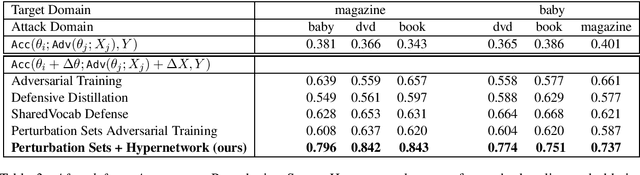
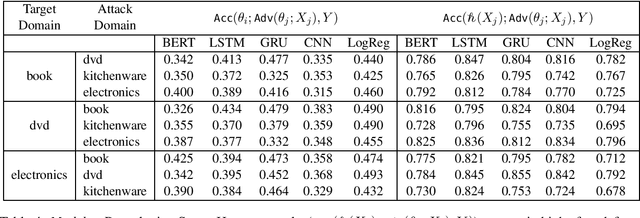
While different methods exist to tackle distinct types of distribution shift, such as label shift (in the form of adversarial attacks) or domain shift, tackling the joint shift setting is still an open problem. Through the study of a joint distribution shift manifesting both adversarial and domain-specific perturbations, we not only show that a joint shift worsens model performance compared to their individual shifts, but that the use of a similar domain worsens performance than a dissimilar domain. To curb the performance drop, we study the use of perturbation sets motivated by input and parameter space bounds, and adopt a meta learning strategy (hypernetworks) to model parameters w.r.t. test-time inputs to recover performance.
Delving into the Scale Variance Problem in Object Detection
Jun 16, 2022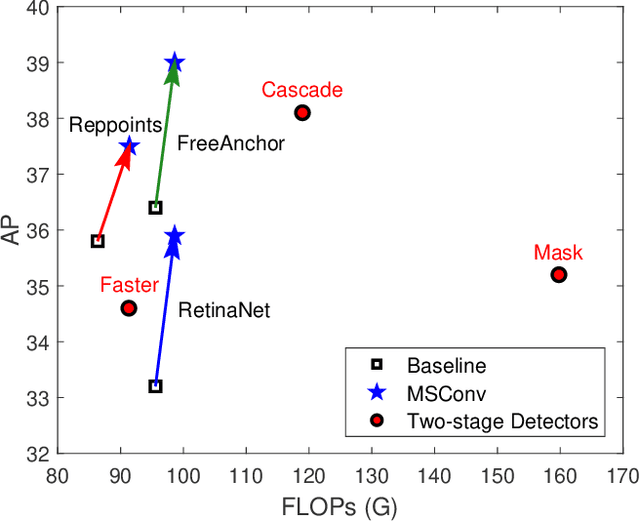
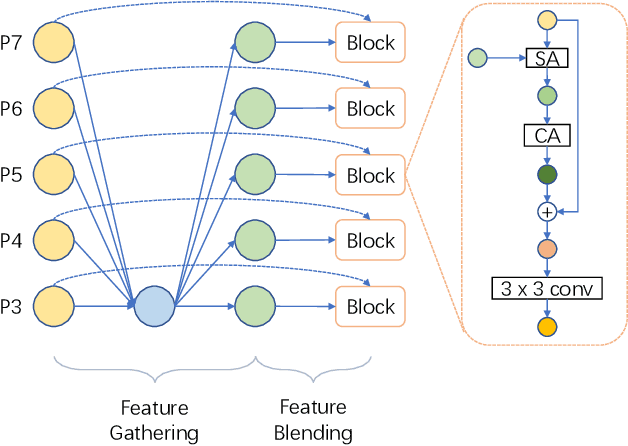
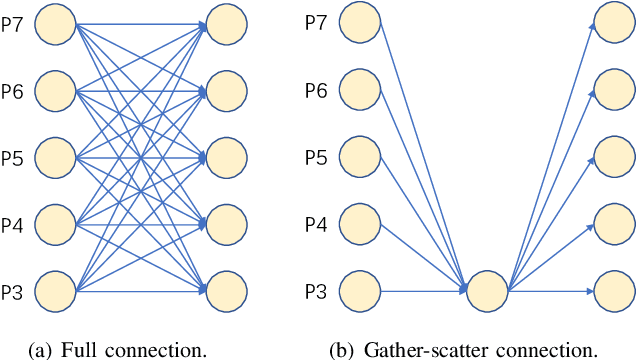
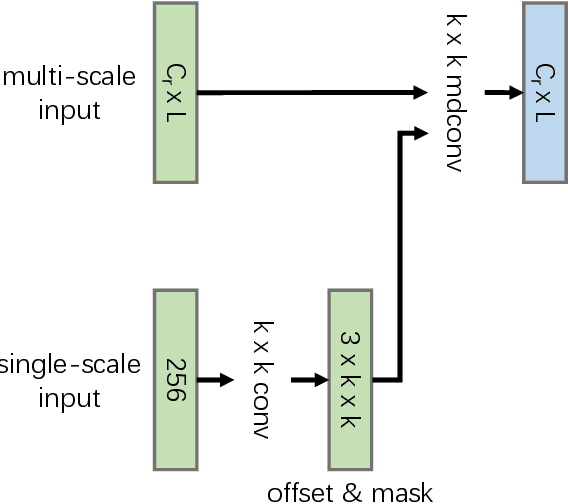
Object detection has made substantial progress in the last decade, due to the capability of convolution in extracting local context of objects. However, the scales of objects are diverse and current convolution can only process single-scale input. The capability of traditional convolution with a fixed receptive field in dealing with such a scale variance problem, is thus limited. Multi-scale feature representation has been proven to be an effective way to mitigate the scale variance problem. Recent researches mainly adopt partial connection with certain scales, or aggregate features from all scales and focus on the global information across the scales. However, the information across spatial and depth dimensions is ignored. Inspired by this, we propose the multi-scale convolution (MSConv) to handle this problem. Taking into consideration scale, spatial and depth information at the same time, MSConv is able to process multi-scale input more comprehensively. MSConv is effective and computationally efficient, with only a small increase of computational cost. For most of the single-stage object detectors, replacing the traditional convolutions with MSConvs in the detection head can bring more than 2.5\% improvement in AP (on COCO 2017 dataset), with only 3\% increase of FLOPs. MSConv is also flexible and effective for two-stage object detectors. When extended to the mainstream two-stage object detectors, MSConv can bring up to 3.0\% improvement in AP. Our best model under single-scale testing achieves 48.9\% AP on COCO 2017 \textit{test-dev} split, which surpasses many state-of-the-art methods.
Three-dimensional microstructure generation using generative adversarial neural networks in the context of continuum micromechanics
May 31, 2022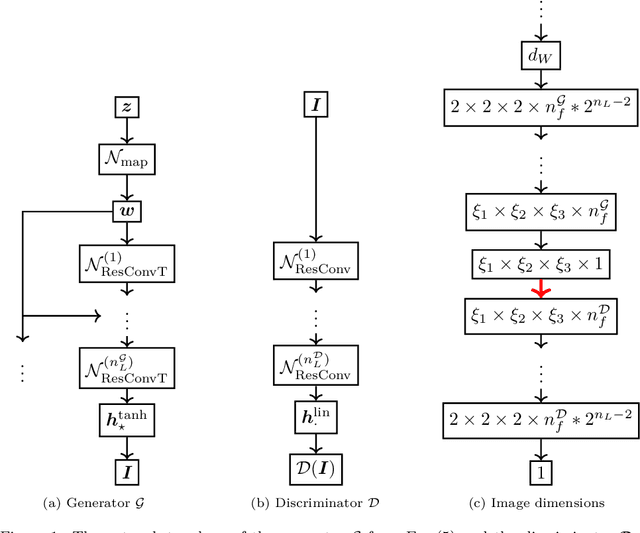
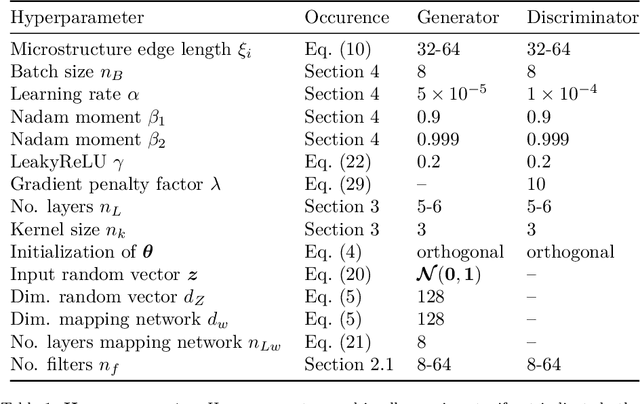
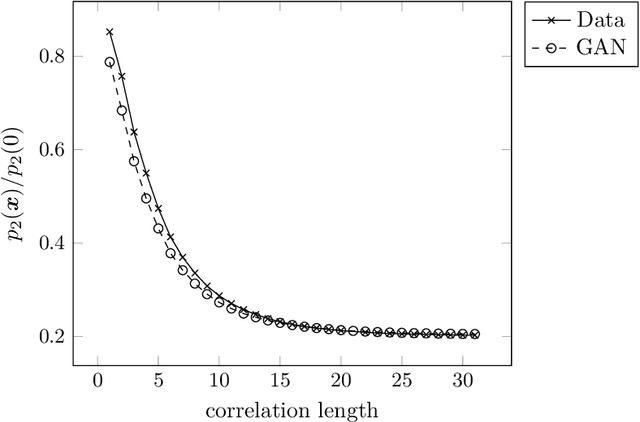

Multiscale simulations are demanding in terms of computational resources. In the context of continuum micromechanics, the multiscale problem arises from the need of inferring macroscopic material parameters from the microscale. If the underlying microstructure is explicitly given by means of microCT-scans, convolutional neural networks can be used to learn the microstructure-property mapping, which is usually obtained from computational homogenization. The CNN approach provides a significant speedup, especially in the context of heterogeneous or functionally graded materials. Another application is uncertainty quantification, where many expansive evaluations are required. However, one bottleneck of this approach is the large number of training microstructures needed. This work closes this gap by proposing a generative adversarial network tailored towards three-dimensional microstructure generation. The lightweight algorithm is able to learn the underlying properties of the material from a single microCT-scan without the need of explicit descriptors. During prediction time, the network can produce unique three-dimensional microstructures with the same properties of the original data in a fraction of seconds and at consistently high quality.
Ensemble Augmentation for Deep Neural Networks Using 1-D Time Series Vibration Data
Aug 06, 2021
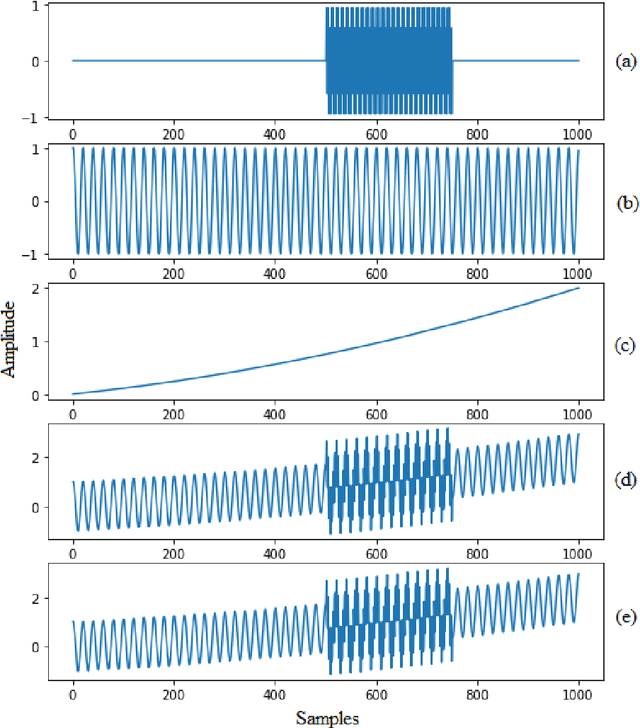
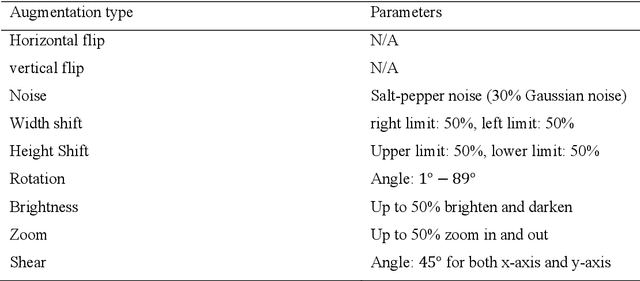
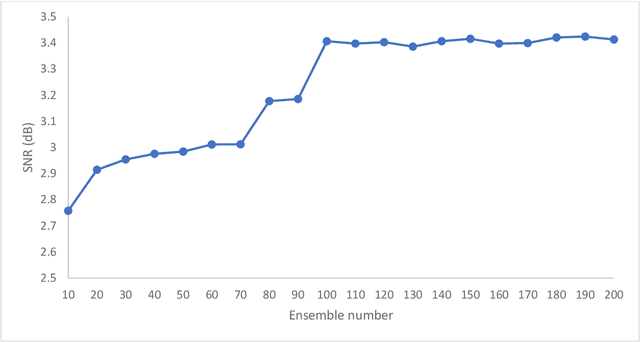
Time-series data are one of the fundamental types of raw data representation used in data-driven techniques. In machine condition monitoring, time-series vibration data are overly used in data mining for deep neural networks. Typically, vibration data is converted into images for classification using Deep Neural Networks (DNNs), and scalograms are the most effective form of image representation. However, the DNN classifiers require huge labeled training samples to reach their optimum performance. So, many forms of data augmentation techniques are applied to the classifiers to compensate for the lack of training samples. However, the scalograms are graphical representations where the existing augmentation techniques suffer because they either change the graphical meaning or have too much noise in the samples that change the physical meaning. In this study, a data augmentation technique named ensemble augmentation is proposed to overcome this limitation. This augmentation method uses the power of white noise added in ensembles to the original samples to generate real-like samples. After averaging the signal with ensembles, a new signal is obtained that contains the characteristics of the original signal. The parameters for the ensemble augmentation are validated using a simulated signal. The proposed method is evaluated using 10 class bearing vibration data using three state-of-the-art Transfer Learning (TL) models, namely, Inception-V3, MobileNet-V2, and ResNet50. Augmented samples are generated in two increments: the first increment generates the same number of fake samples as the training samples, and in the second increment, the number of samples is increased gradually. The outputs from the proposed method are compared with no augmentation, augmentations using deep convolution generative adversarial network (DCGAN), and several geometric transformation-based augmentations...
SADAM: Stochastic Adam, A Stochastic Operator for First-Order Gradient-based Optimizer
May 20, 2022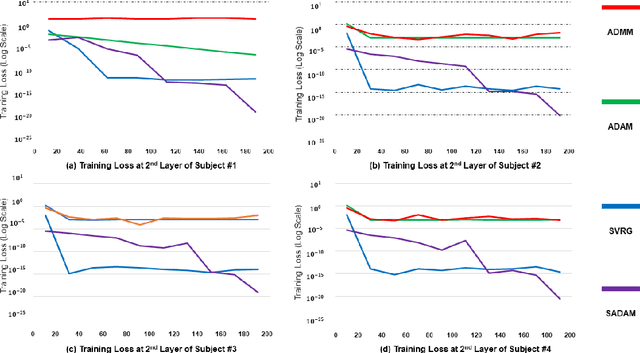
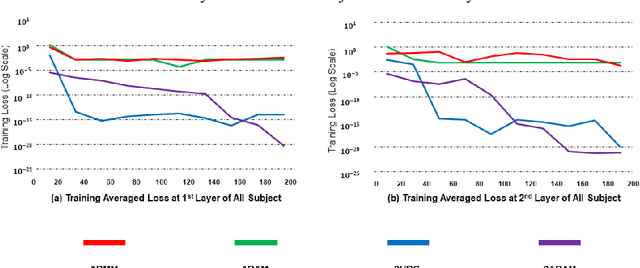
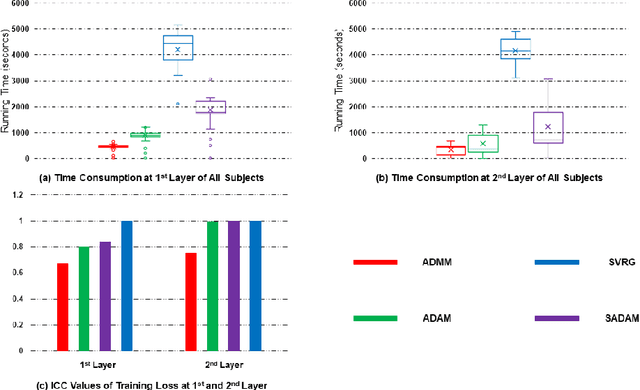
In this work, to efficiently help escape the stationary and saddle points, we propose, analyze, and generalize a stochastic strategy performed as an operator for a first-order gradient descent algorithm in order to increase the target accuracy and reduce time consumption. Unlike existing algorithms, the proposed stochastic the strategy does not require any batches and sampling techniques, enabling efficient implementation and maintaining the initial first-order optimizer's convergence rate, but provides an incomparable improvement of target accuracy when optimizing the target functions. In short, the proposed strategy is generalized, applied to Adam, and validated via the decomposition of biomedical signals using Deep Matrix Fitting and another four peer optimizers. The validation results show that the proposed random strategy can be easily generalized for first-order optimizers and efficiently improve the target accuracy.
Time and Frequency Network for Human Action Detection in Videos
Mar 08, 2021
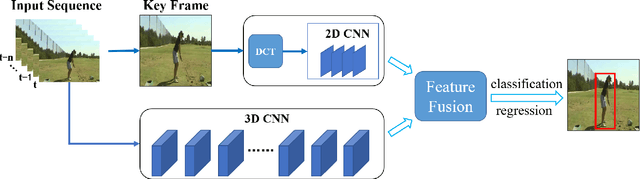
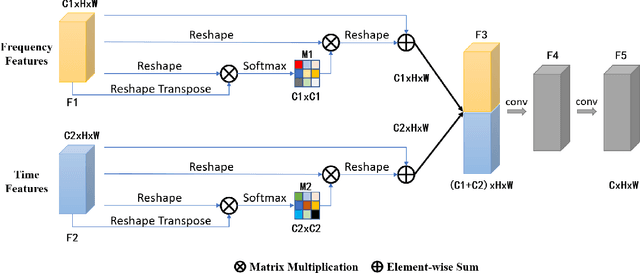

Currently, spatiotemporal features are embraced by most deep learning approaches for human action detection in videos, however, they neglect the important features in frequency domain. In this work, we propose an end-to-end network that considers the time and frequency features simultaneously, named TFNet. TFNet holds two branches, one is time branch formed of three-dimensional convolutional neural network(3D-CNN), which takes the image sequence as input to extract time features; and the other is frequency branch, extracting frequency features through two-dimensional convolutional neural network(2D-CNN) from DCT coefficients. Finally, to obtain the action patterns, these two features are deeply fused under the attention mechanism. Experimental results on the JHMDB51-21 and UCF101-24 datasets demonstrate that our approach achieves remarkable performance for frame-mAP.
Lite Pose: Efficient Architecture Design for 2D Human Pose Estimation
May 03, 2022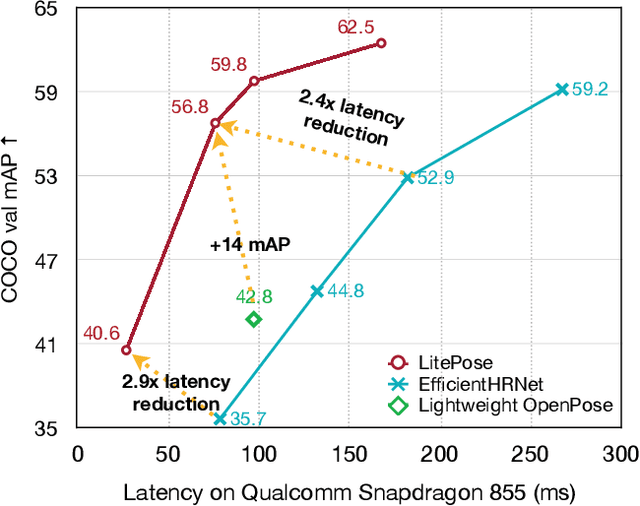
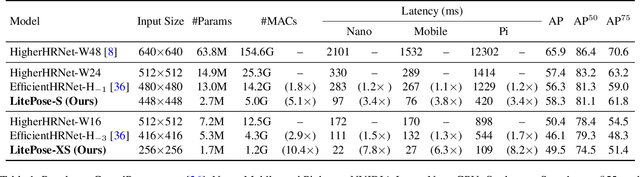
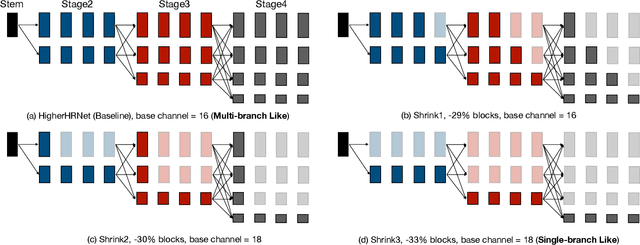
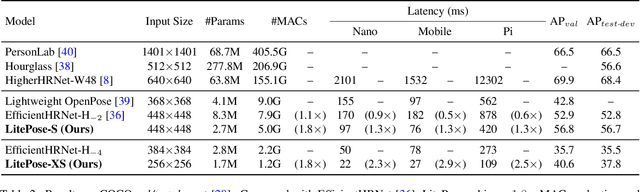
Pose estimation plays a critical role in human-centered vision applications. However, it is difficult to deploy state-of-the-art HRNet-based pose estimation models on resource-constrained edge devices due to the high computational cost (more than 150 GMACs per frame). In this paper, we study efficient architecture design for real-time multi-person pose estimation on edge. We reveal that HRNet's high-resolution branches are redundant for models at the low-computation region via our gradual shrinking experiments. Removing them improves both efficiency and performance. Inspired by this finding, we design LitePose, an efficient single-branch architecture for pose estimation, and introduce two simple approaches to enhance the capacity of LitePose, including Fusion Deconv Head and Large Kernel Convs. Fusion Deconv Head removes the redundancy in high-resolution branches, allowing scale-aware feature fusion with low overhead. Large Kernel Convs significantly improve the model's capacity and receptive field while maintaining a low computational cost. With only 25% computation increment, 7x7 kernels achieve +14.0 mAP better than 3x3 kernels on the CrowdPose dataset. On mobile platforms, LitePose reduces the latency by up to 5.0x without sacrificing performance, compared with prior state-of-the-art efficient pose estimation models, pushing the frontier of real-time multi-person pose estimation on edge. Our code and pre-trained models are released at https://github.com/mit-han-lab/litepose.
* 11 pages