 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Two-step Planning of Dynamic UAV Trajectories using Iterative $δ$-Spaces
May 04, 2022
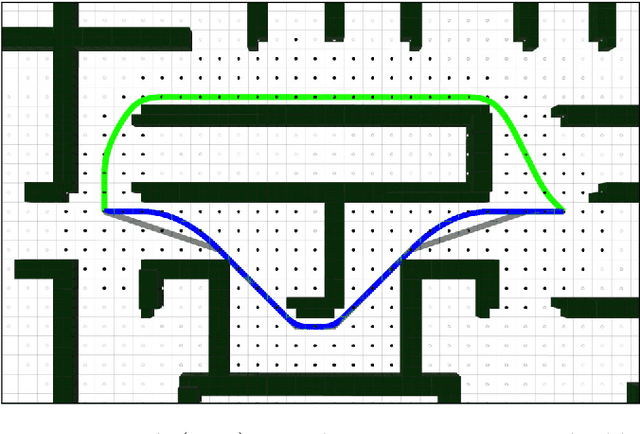

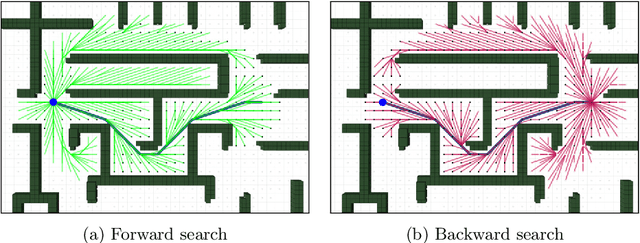
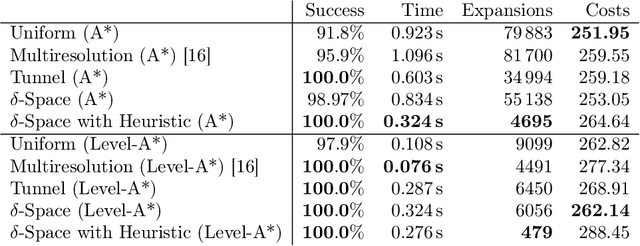
UAV trajectory planning is often done in a two-step approach, where a low-dimensional path is refined to a dynamic trajectory. The resulting trajectories are only locally optimal, however. On the other hand, direct planning in higher-dimensional state spaces generates globally optimal solutions but is time-consuming and thus infeasible for time-constrained applications. To address this issue, we propose $\delta$-Spaces, a pruned high-dimensional state space representation for trajectory refinement. It does not only contain the area around a single lower-dimensional path but consists of the union of multiple near-optimal paths. Thus, it is less prone to local minima. Furthermore, we propose an anytime algorithm using $\delta$-Spaces of increasing sizes. We compare our method against state-of-the-art search-based trajectory planning methods and evaluate it in 2D and 3D environments to generate second-order and third-order UAV trajectories.
Real-time Speaker counting in a cocktail party scenario using Attention-guided Convolutional Neural Network
Oct 30, 2021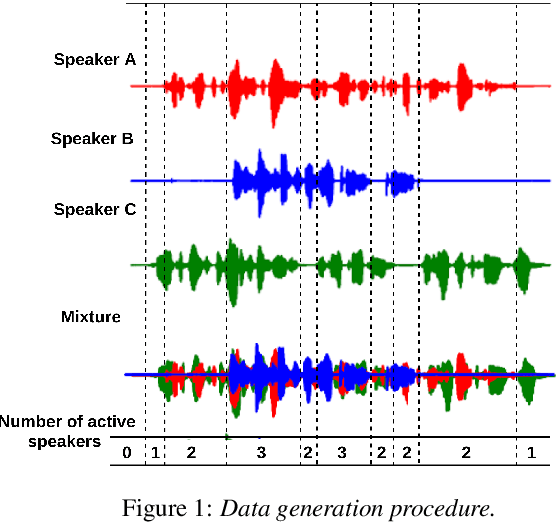
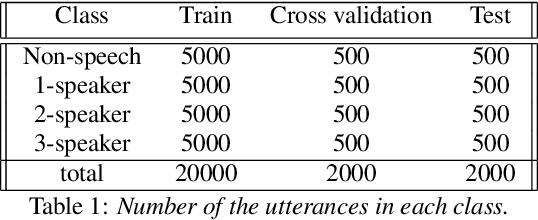
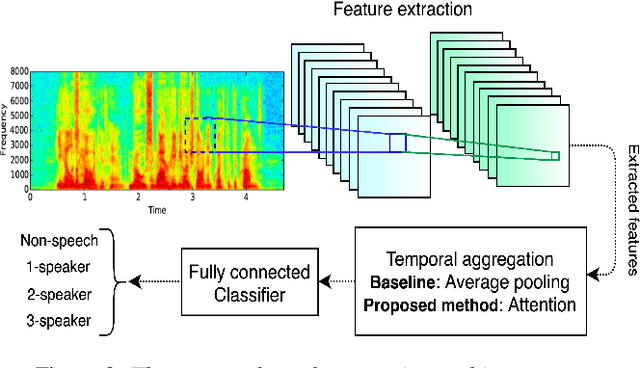
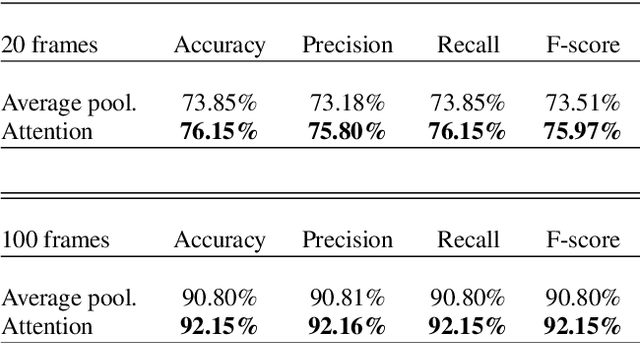
Most current speech technology systems are designed to operate well even in the presence of multiple active speakers. However, most solutions assume that the number of co-current speakers is known. Unfortunately, this information might not always be available in real-world applications. In this study, we propose a real-time, single-channel attention-guided Convolutional Neural Network (CNN) to estimate the number of active speakers in overlapping speech. The proposed system extracts higher-level information from the speech spectral content using a CNN model. Next, the attention mechanism summarizes the extracted information into a compact feature vector without losing critical information. Finally, the active speakers are classified using a fully connected network. Experiments on simulated overlapping speech using WSJ corpus show that the attention solution is shown to improve the performance by almost 3% absolute over conventional temporal average pooling. The proposed Attention-guided CNN achieves 76.15% for both Weighted Accuracy and average Recall, and 75.80% Precision on speech segments as short as 20 frames (i.e., 200 ms). All the classification metrics exceed 92% for the attention-guided model in offline scenarios where the input signal is more than 100 frames long (i.e., 1s).
Approximating 1-Wasserstein Distance with Trees
Jun 24, 2022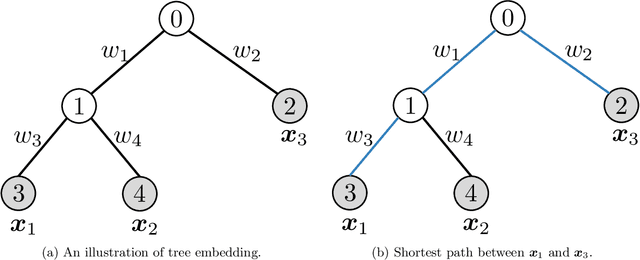
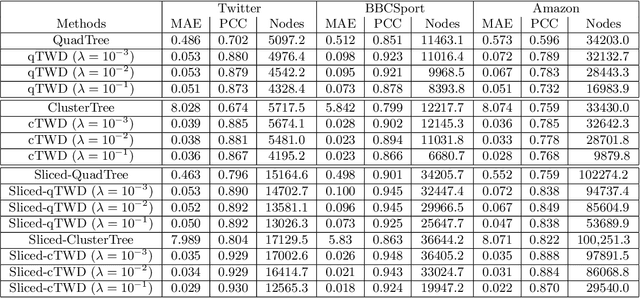
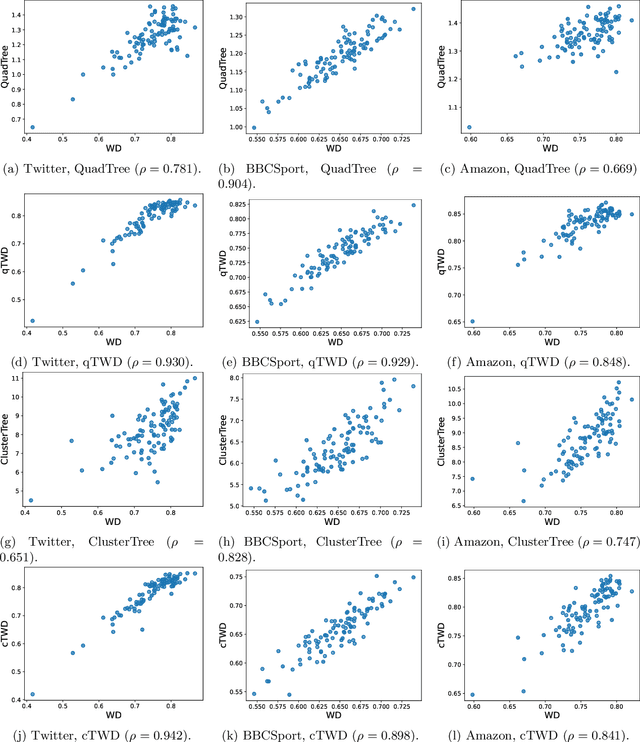
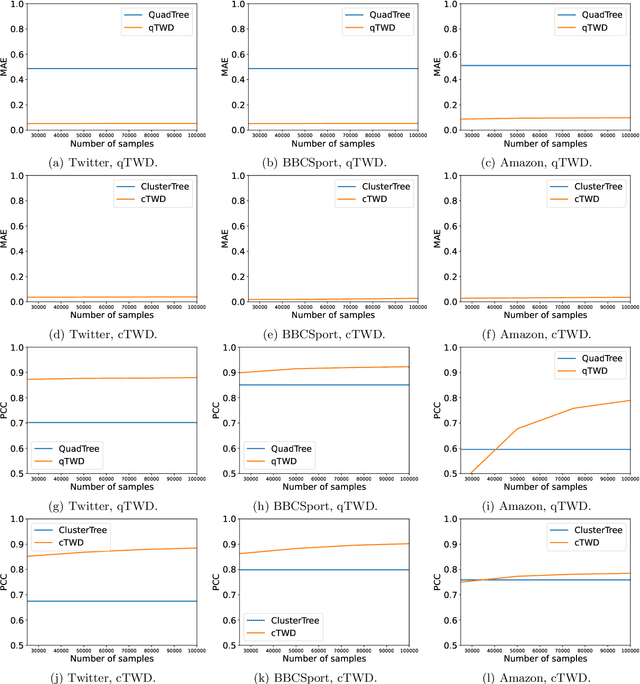
Wasserstein distance, which measures the discrepancy between distributions, shows efficacy in various types of natural language processing (NLP) and computer vision (CV) applications. One of the challenges in estimating Wasserstein distance is that it is computationally expensive and does not scale well for many distribution comparison tasks. In this paper, we aim to approximate the 1-Wasserstein distance by the tree-Wasserstein distance (TWD), where TWD is a 1-Wasserstein distance with tree-based embedding and can be computed in linear time with respect to the number of nodes on a tree. More specifically, we propose a simple yet efficient L1-regularized approach to learning the weights of the edges in a tree. To this end, we first show that the 1-Wasserstein approximation problem can be formulated as a distance approximation problem using the shortest path distance on a tree. We then show that the shortest path distance can be represented by a linear model and can be formulated as a Lasso-based regression problem. Owing to the convex formulation, we can obtain a globally optimal solution efficiently. Moreover, we propose a tree-sliced variant of these methods. Through experiments, we demonstrated that the weighted TWD can accurately approximate the original 1-Wasserstein distance.
Summary Markov Models for Event Sequences
May 06, 2022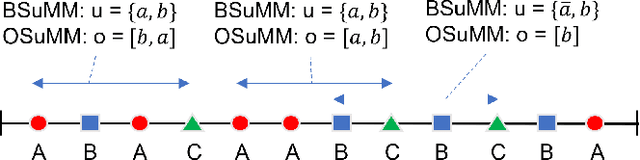

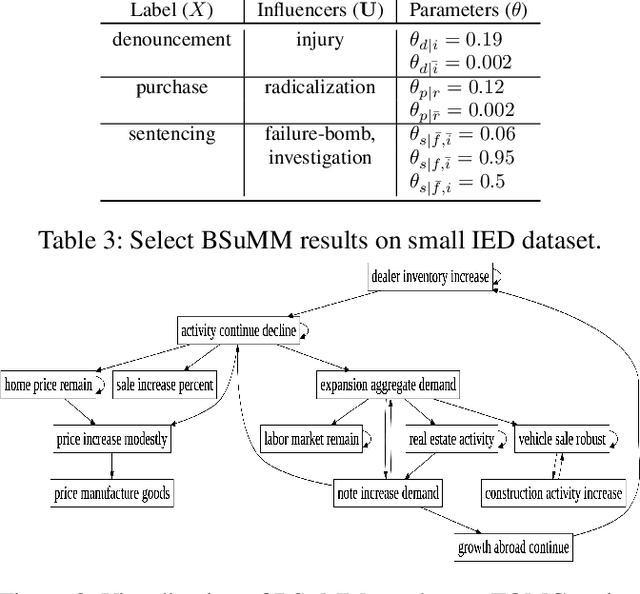
Datasets involving sequences of different types of events without meaningful time stamps are prevalent in many applications, for instance when extracted from textual corpora. We propose a family of models for such event sequences -- summary Markov models -- where the probability of observing an event type depends only on a summary of historical occurrences of its influencing set of event types. This Markov model family is motivated by Granger causal models for time series, with the important distinction that only one event can occur in a position in an event sequence. We show that a unique minimal influencing set exists for any set of event types of interest and choice of summary function, formulate two novel models from the general family that represent specific sequence dynamics, and propose a greedy search algorithm for learning them from event sequence data. We conduct an experimental investigation comparing the proposed models with relevant baselines, and illustrate their knowledge acquisition and discovery capabilities through case studies involving sequences from text.
Exploring Temporally Dynamic Data Augmentation for Video Recognition
Jun 30, 2022
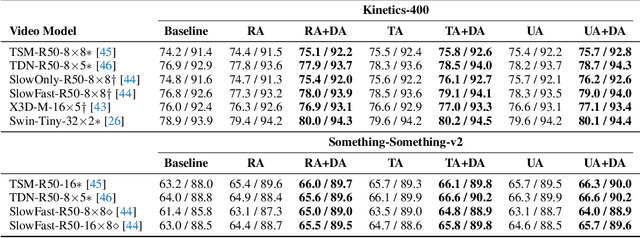
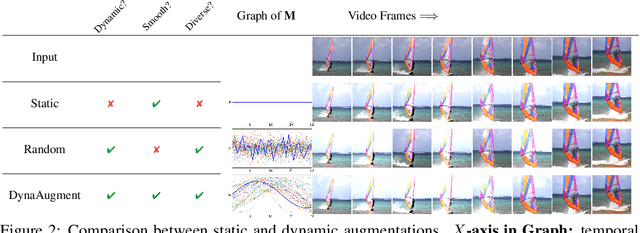

Data augmentation has recently emerged as an essential component of modern training recipes for visual recognition tasks. However, data augmentation for video recognition has been rarely explored despite its effectiveness. Few existing augmentation recipes for video recognition naively extend the image augmentation methods by applying the same operations to the whole video frames. Our main idea is that the magnitude of augmentation operations for each frame needs to be changed over time to capture the real-world video's temporal variations. These variations should be generated as diverse as possible using fewer additional hyper-parameters during training. Through this motivation, we propose a simple yet effective video data augmentation framework, DynaAugment. The magnitude of augmentation operations on each frame is changed by an effective mechanism, Fourier Sampling that parameterizes diverse, smooth, and realistic temporal variations. DynaAugment also includes an extended search space suitable for video for automatic data augmentation methods. DynaAugment experimentally demonstrates that there are additional performance rooms to be improved from static augmentations on diverse video models. Specifically, we show the effectiveness of DynaAugment on various video datasets and tasks: large-scale video recognition (Kinetics-400 and Something-Something-v2), small-scale video recognition (UCF- 101 and HMDB-51), fine-grained video recognition (Diving-48 and FineGym), video action segmentation on Breakfast, video action localization on THUMOS'14, and video object detection on MOT17Det. DynaAugment also enables video models to learn more generalized representation to improve the model robustness on the corrupted videos.
Amortised Likelihood-free Inference for Expensive Time-series Simulators with Signatured Ratio Estimation
Feb 23, 2022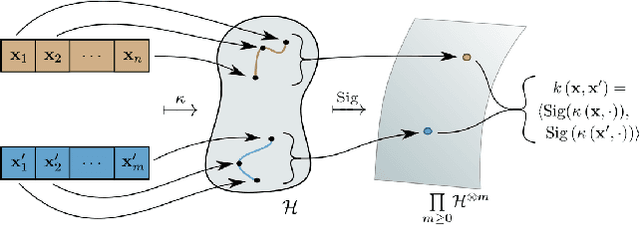

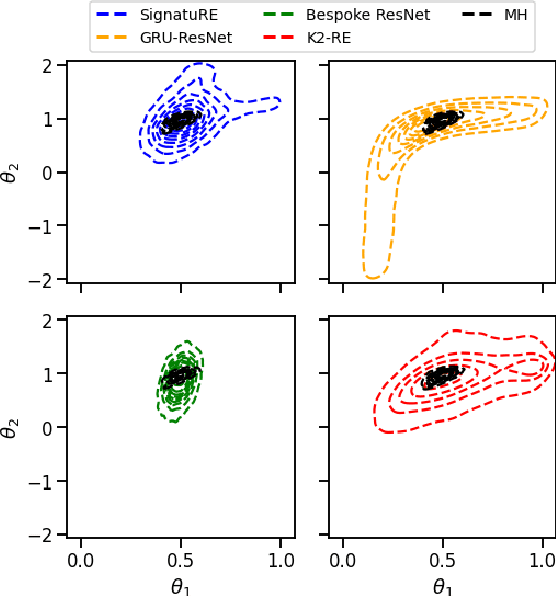
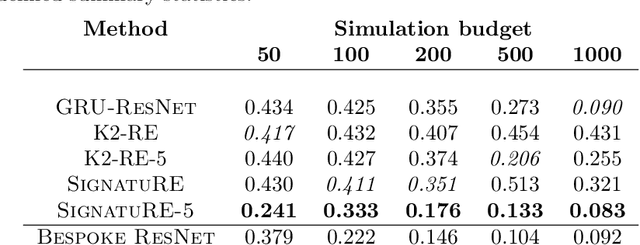
Simulation models of complex dynamics in the natural and social sciences commonly lack a tractable likelihood function, rendering traditional likelihood-based statistical inference impossible. Recent advances in machine learning have introduced novel algorithms for estimating otherwise intractable likelihood functions using a likelihood ratio trick based on binary classifiers. Consequently, efficient likelihood approximations can be obtained whenever good probabilistic classifiers can be constructed. We propose a kernel classifier for sequential data using path signatures based on the recently introduced signature kernel. We demonstrate that the representative power of signatures yields a highly performant classifier, even in the crucially important case where sample numbers are low. In such scenarios, our approach can outperform sophisticated neural networks for common posterior inference tasks.
Dynaformer: A Deep Learning Model for Ageing-aware Battery Discharge Prediction
Jun 01, 2022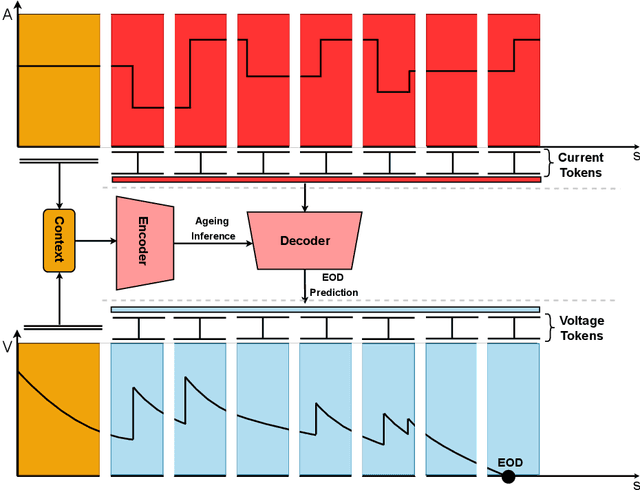
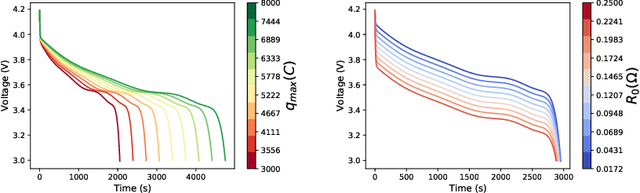
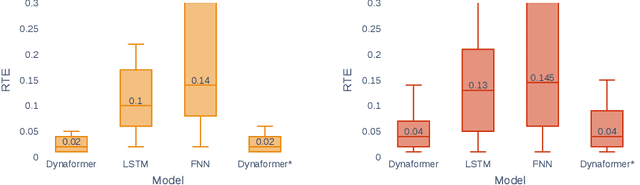
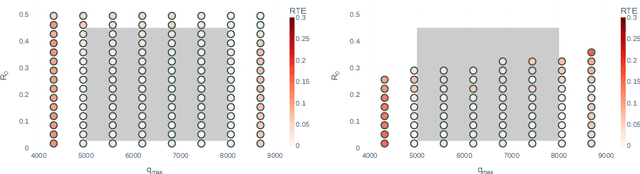
Electrochemical batteries are ubiquitous devices in our society. When they are employed in mission-critical applications, the ability to precisely predict the end of discharge under highly variable environmental and operating conditions is of paramount importance in order to support operational decision-making. While there are accurate predictive models of the processes underlying the charge and discharge phases of batteries, the modelling of ageing and its effect on performance remains poorly understood. Such a lack of understanding often leads to inaccurate models or the need for time-consuming calibration procedures whenever the battery ages or its conditions change significantly. This represents a major obstacle to the real-world deployment of efficient and robust battery management systems. In this paper, we propose for the first time an approach that can predict the voltage discharge curve for batteries of any degradation level without the need for calibration. In particular, we introduce Dynaformer, a novel Transformer-based deep learning architecture which is able to simultaneously infer the ageing state from a limited number of voltage/current samples and predict the full voltage discharge curve for real batteries with high precision. Our experiments show that the trained model is effective for input current profiles of different complexities and is robust to a wide range of degradation levels. In addition to evaluating the performance of the proposed framework on simulated data, we demonstrate that a minimal amount of fine-tuning allows the model to bridge the simulation-to-real gap between simulations and real data collected from a set of batteries. The proposed methodology enables the utilization of battery-powered systems until the end of discharge in a controlled and predictable way, thereby significantly prolonging the operating cycles and reducing costs.
Linear-Time Probabilistic Solutions of Boundary Value Problems
Jun 14, 2021

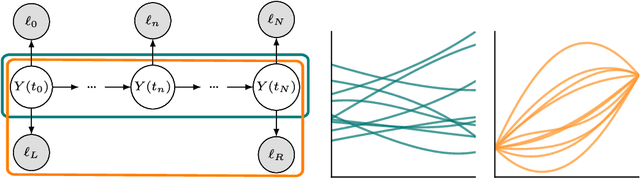

We propose a fast algorithm for the probabilistic solution of boundary value problems (BVPs), which are ordinary differential equations subject to boundary conditions. In contrast to previous work, we introduce a Gauss--Markov prior and tailor it specifically to BVPs, which allows computing a posterior distribution over the solution in linear time, at a quality and cost comparable to that of well-established, non-probabilistic methods. Our model further delivers uncertainty quantification, mesh refinement, and hyperparameter adaptation. We demonstrate how these practical considerations positively impact the efficiency of the scheme. Altogether, this results in a practically usable probabilistic BVP solver that is (in contrast to non-probabilistic algorithms) natively compatible with other parts of the statistical modelling tool-chain.
OROS: Orchestrating ROS-driven Collaborative Connected Robots in Mission-Critical Operations
May 06, 2022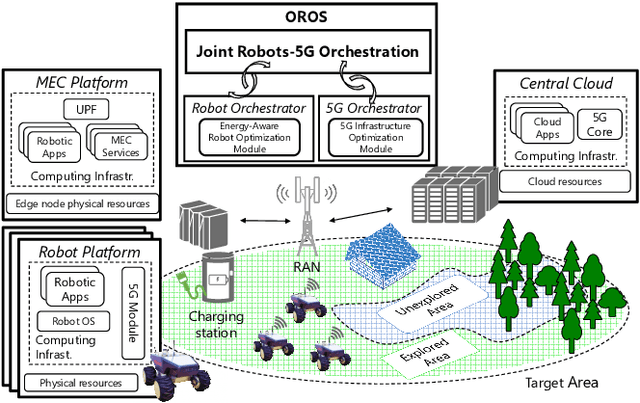
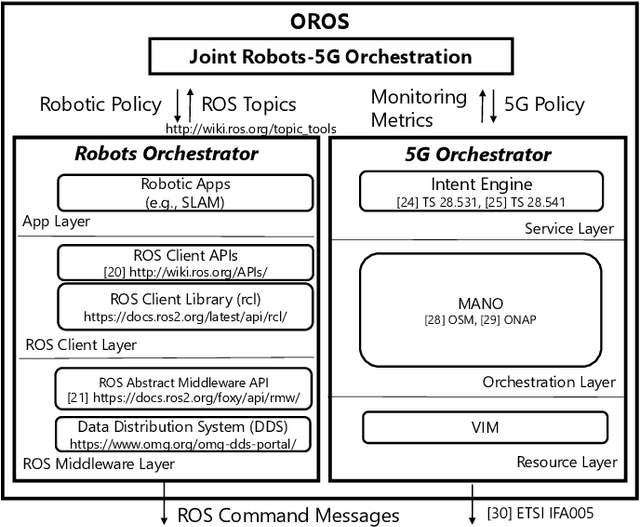
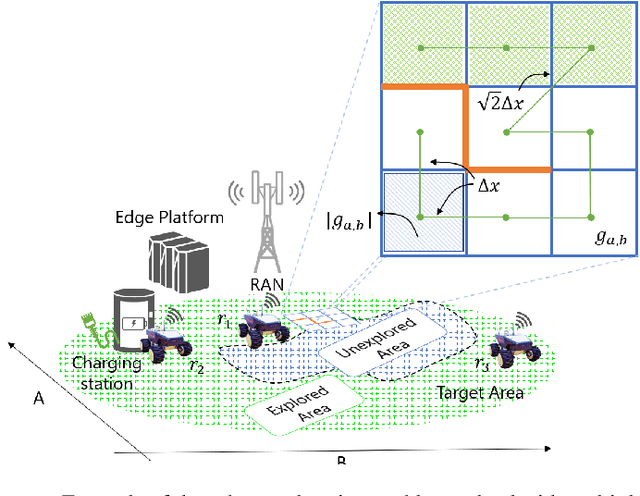
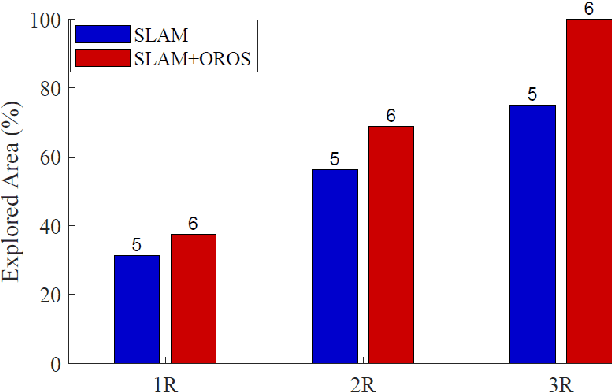
Battery life for collaborative robotics scenarios is a key challenge limiting operational uses and deployment in real life. Mission-Critical tasks are among the most relevant and challenging scenarios. As multiple and heterogeneous on-board sensors are required to explore unknown environments in simultaneous localization and mapping (SLAM) tasks, battery life problems are further exacerbated. Given the time-sensitivity of mission-critical operations, the successful completion of specific tasks in the minimum amount of time is of paramount importance. In this paper, we analyze the benefits of 5G-enabled collaborative robots by enhancing the Robot Operating System (ROS) capabilities with network orchestration features for energy-saving purposes. We propose OROS, a novel orchestration approach that minimizes mission-critical task completion times of 5G-connected robots by jointly optimizing robotic navigation and sensing together with infrastructure resources. Our results show that OROS significantly outperforms state-of-the-art solutions in exploration tasks completion times by exploiting 5G orchestration features for battery life extension.
Deep Matching Prior: Test-Time Optimization for Dense Correspondence
Jun 06, 2021
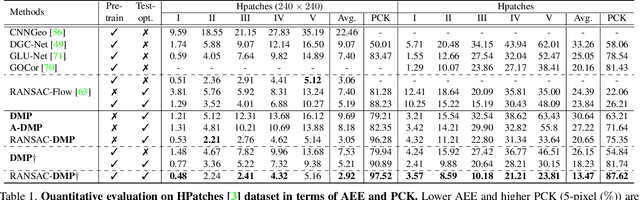
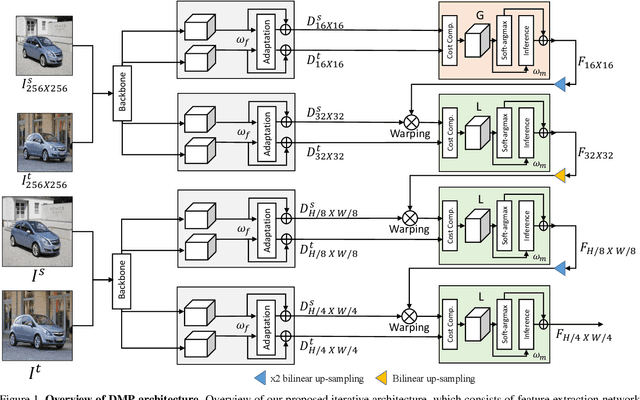
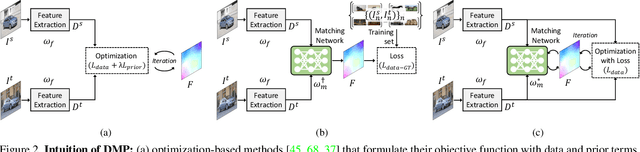
Conventional techniques to establish dense correspondences across visually or semantically similar images focused on designing a task-specific matching prior, which is difficult to model. To overcome this, recent learning-based methods have attempted to learn a good matching prior within a model itself on large training data. The performance improvement was apparent, but the need for sufficient training data and intensive learning hinders their applicability. Moreover, using the fixed model at test time does not account for the fact that a pair of images may require their own prior, thus providing limited performance and poor generalization to unseen images. In this paper, we show that an image pair-specific prior can be captured by solely optimizing the untrained matching networks on an input pair of images. Tailored for such test-time optimization for dense correspondence, we present a residual matching network and a confidence-aware contrastive loss to guarantee a meaningful convergence. Experiments demonstrate that our framework, dubbed Deep Matching Prior (DMP), is competitive, or even outperforms, against the latest learning-based methods on several benchmarks for geometric matching and semantic matching, even though it requires neither large training data nor intensive learning. With the networks pre-trained, DMP attains state-of-the-art performance on all benchmarks.