 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Adaptive Test-Time Augmentation for Low-Power CPU
May 13, 2021
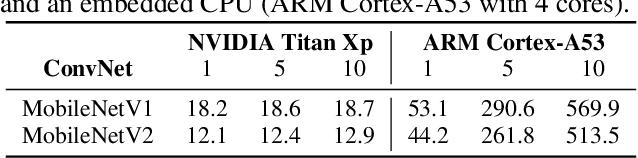
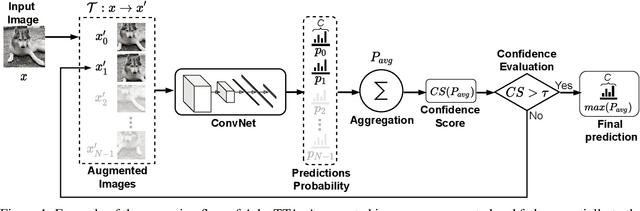
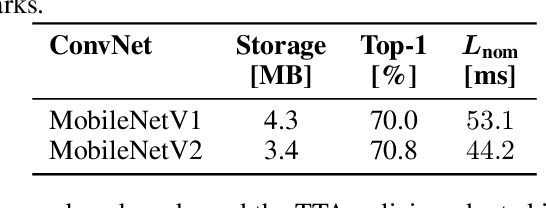
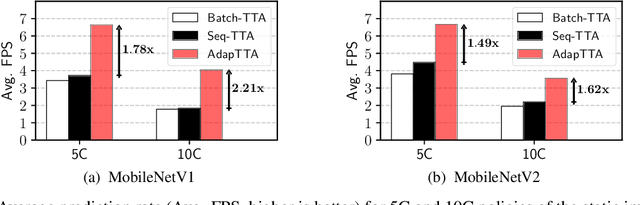
Convolutional Neural Networks (ConvNets) are trained offline using the few available data and may therefore suffer from substantial accuracy loss when ported on the field, where unseen input patterns received under unpredictable external conditions can mislead the model. Test-Time Augmentation (TTA) techniques aim to alleviate such common side effect at inference-time, first running multiple feed-forward passes on a set of altered versions of the same input sample, and then computing the main outcome through a consensus of the aggregated predictions. Unfortunately, the implementation of TTA on embedded CPUs introduces latency penalties that limit its adoption on edge applications. To tackle this issue, we propose AdapTTA, an adaptive implementation of TTA that controls the number of feed-forward passes dynamically, depending on the complexity of the input. Experimental results on state-of-the-art ConvNets for image classification deployed on a commercial ARM Cortex-A CPU demonstrate AdapTTA reaches remarkable latency savings, from 1.49X to 2.21X, and hence a higher frame rate compared to static TTA, still preserving the same accuracy gain.
Predictive Compliance Monitoring in Process-Aware Information Systems: State of the Art, Functionalities, Research Directions
May 10, 2022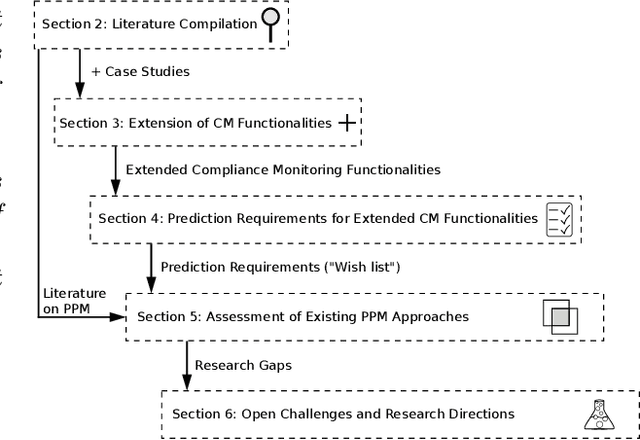
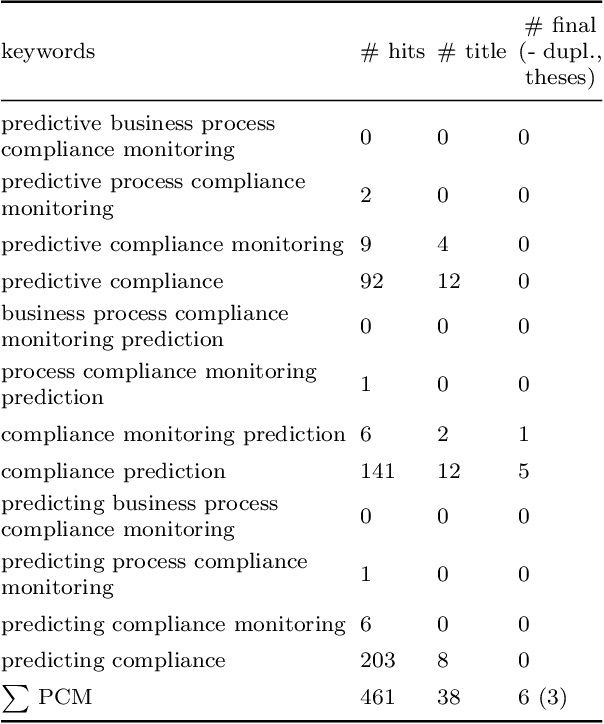
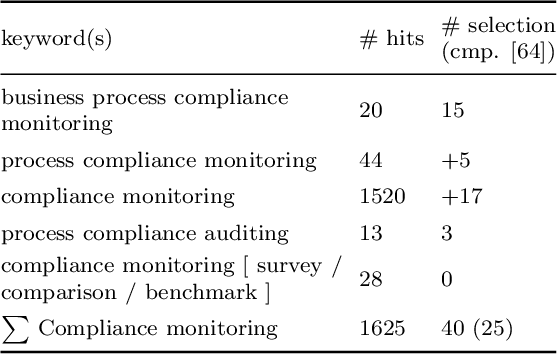
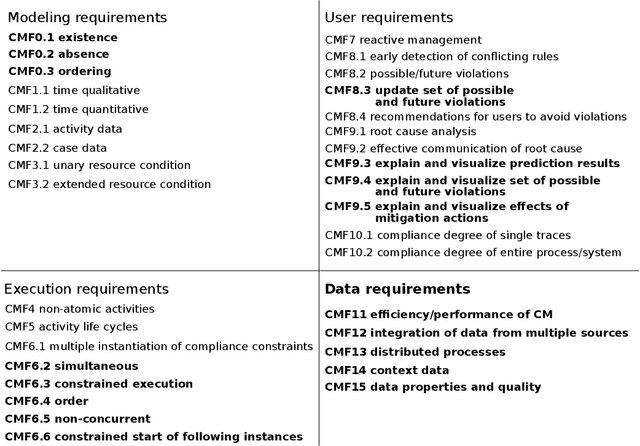
Business process compliance is a key area of business process management and aims at ensuring that processes obey to compliance constraints such as regulatory constraints or business rules imposed on them. Process compliance can be checked during process design time based on verification of process models and at runtime based on monitoring the compliance states of running process instances. For existing compliance monitoring approaches it remains unclear whether and how compliance violations can be predicted, although predictions are crucial in order to prepare and take countermeasures in time. This work, hence, analyzes existing literature from compliance and SLA monitoring as well as predictive process monitoring and provides an updated framework of compliance monitoring functionalities. For each compliance monitoring functionality we elicit prediction requirements and analyze their coverage by existing approaches. Based on this analysis, open challenges and research directions for predictive compliance and process monitoring are elaborated.
Missing Value Imputation on Multidimensional Time Series
Mar 02, 2021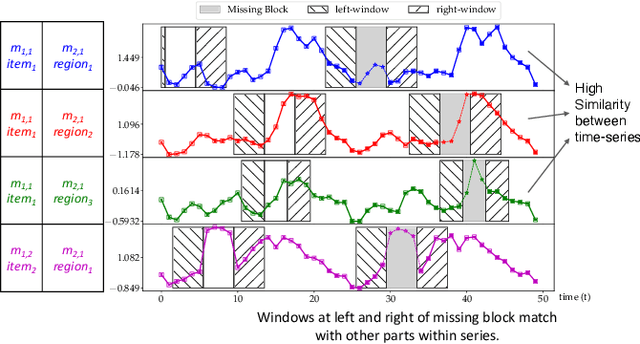
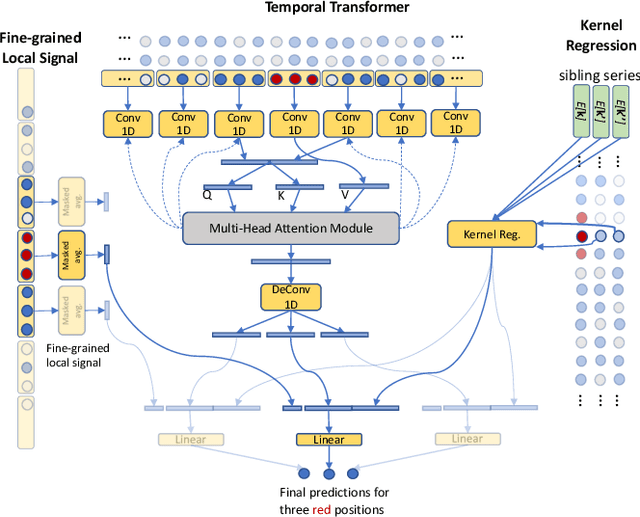

We present DeepMVI, a deep learning method for missing value imputation in multidimensional time-series datasets. Missing values are commonplace in decision support platforms that aggregate data over long time stretches from disparate sources, and reliable data analytics calls for careful handling of missing data. One strategy is imputing the missing values, and a wide variety of algorithms exist spanning simple interpolation, matrix factorization methods like SVD, statistical models like Kalman filters, and recent deep learning methods. We show that often these provide worse results on aggregate analytics compared to just excluding the missing data. DeepMVI uses a neural network to combine fine-grained and coarse-grained patterns along a time series, and trends from related series across categorical dimensions. After failing with off-the-shelf neural architectures, we design our own network that includes a temporal transformer with a novel convolutional window feature, and kernel regression with learned embeddings. The parameters and their training are designed carefully to generalize across different placements of missing blocks and data characteristics. Experiments across nine real datasets, four different missing scenarios, comparing seven existing methods show that DeepMVI is significantly more accurate, reducing error by more than 50% in more than half the cases, compared to the best existing method. Although slower than simpler matrix factorization methods, we justify the increased time overheads by showing that DeepMVI is the only option that provided overall more accurate analytics than dropping missing values.
Adversarial Attention for Human Motion Synthesis
Apr 25, 2022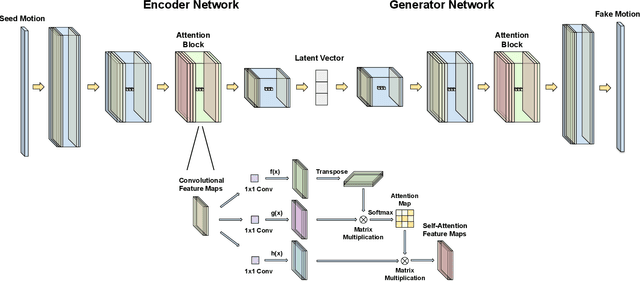
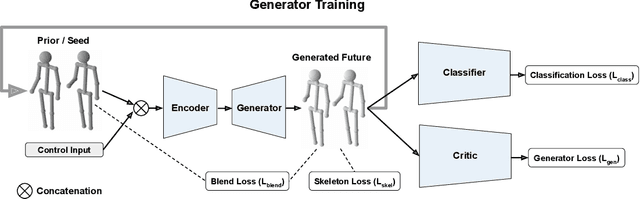
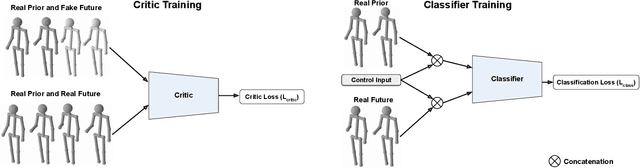
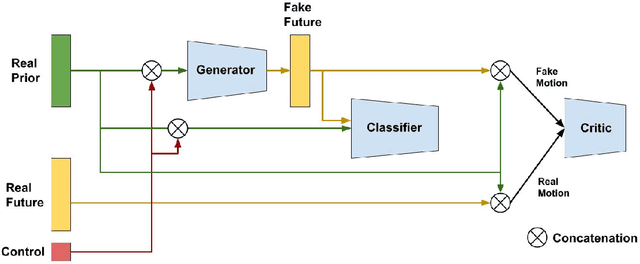
Analysing human motions is a core topic of interest for many disciplines, from Human-Computer Interaction, to entertainment, Virtual Reality and healthcare. Deep learning has achieved impressive results in capturing human pose in real-time. On the other hand, due to high inter-subject variability, human motion analysis models often suffer from not being able to generalise to data from unseen subjects due to very limited specialised datasets available in fields such as healthcare. However, acquiring human motion datasets is highly time-consuming, challenging, and expensive. Hence, human motion synthesis is a crucial research problem within deep learning and computer vision. We present a novel method for controllable human motion synthesis by applying attention-based probabilistic deep adversarial models with end-to-end training. We show that we can generate synthetic human motion over both short- and long-time horizons through the use of adversarial attention. Furthermore, we show that we can improve the classification performance of deep learning models in cases where there is inadequate real data, by supplementing existing datasets with synthetic motions.
Then and Now: Quantifying the Longitudinal Validity of Self-Disclosed Depression Diagnoses
Jun 22, 2022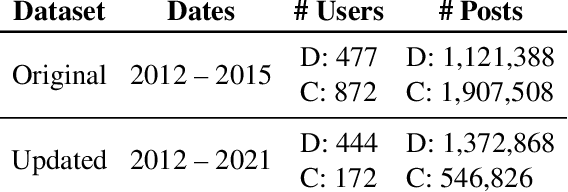
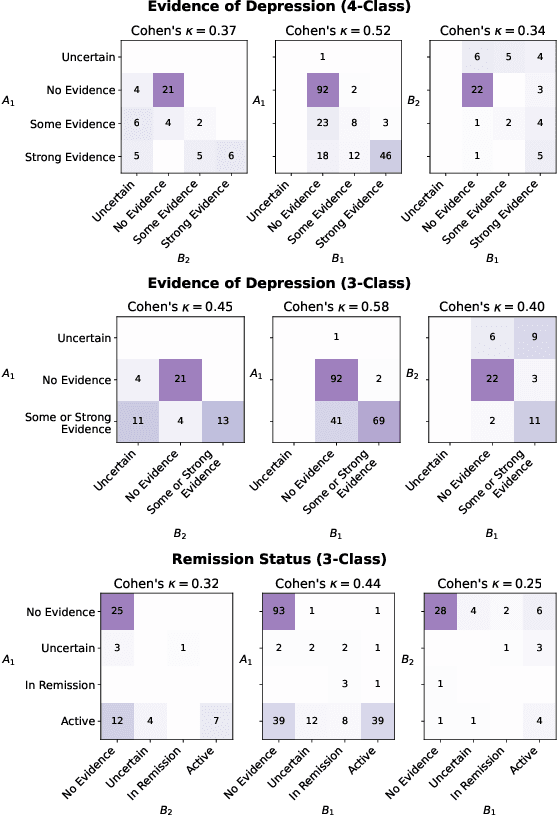
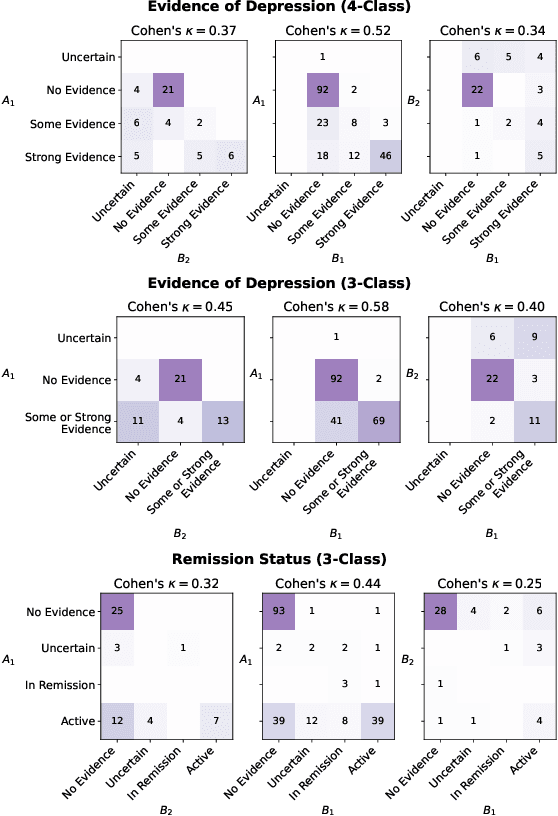
Self-disclosed mental health diagnoses, which serve as ground truth annotations of mental health status in the absence of clinical measures, underpin the conclusions behind most computational studies of mental health language from the last decade. However, psychiatric conditions are dynamic; a prior depression diagnosis may no longer be indicative of an individual's mental health, either due to treatment or other mitigating factors. We ask: to what extent are self-disclosures of mental health diagnoses actually relevant over time? We analyze recent activity from individuals who disclosed a depression diagnosis on social media over five years ago and, in turn, acquire a new understanding of how presentations of mental health status on social media manifest longitudinally. We also provide expanded evidence for the presence of personality-related biases in datasets curated using self-disclosed diagnoses. Our findings motivate three practical recommendations for improving mental health datasets curated using self-disclosed diagnoses: 1) Annotate diagnosis dates and psychiatric comorbidities; 2) Sample control groups using propensity score matching; 3) Identify and remove spurious correlations introduced by selection bias.
ICC++: Explainable Image Retrieval for Art Historical Corpora using Image Composition Canvas
Jun 22, 2022
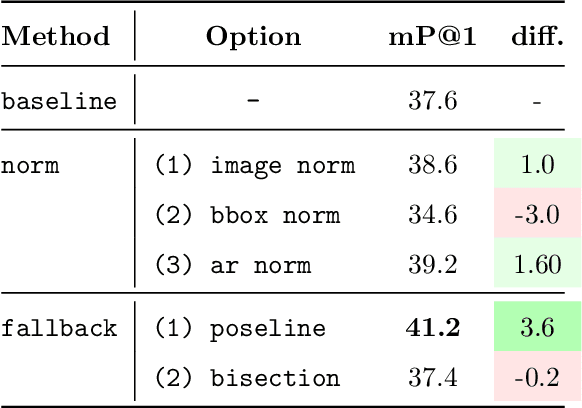
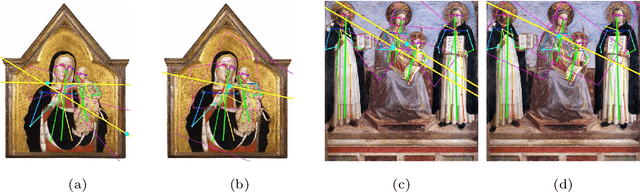
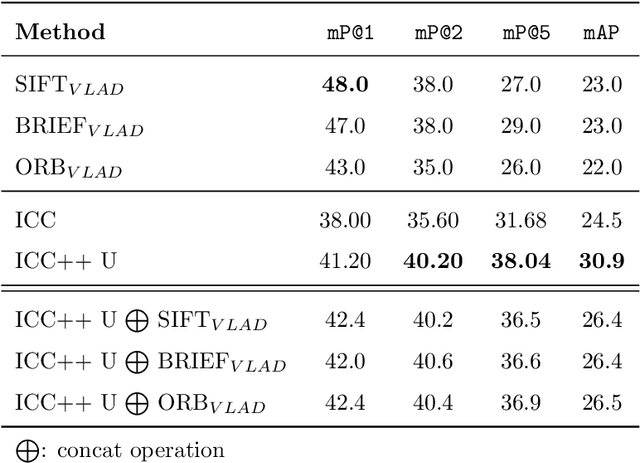
Image compositions are helpful in the study of image structures and assist in discovering the semantics of the underlying scene portrayed across art forms and styles. With the digitization of artworks in recent years, thousands of images of a particular scene or narrative could potentially be linked together. However, manually linking this data with consistent objectiveness can be a highly challenging and time-consuming task. In this work, we present a novel approach called Image Composition Canvas (ICC++) to compare and retrieve images having similar compositional elements. ICC++ is an improvement over ICC specializing in generating low and high-level features (compositional elements) motivated by Max Imdahl's work. To this end, we present a rigorous quantitative and qualitative comparison of our approach with traditional and state-of-the-art (SOTA) methods showing that our proposed method outperforms all of them. In combination with deep features, our method outperforms the best deep learning-based method, opening the research direction for explainable machine learning for digital humanities. We will release the code and the data post-publication.
Back2Future: Leveraging Backfill Dynamics for Improving Real-time Predictions in Future
Jun 08, 2021

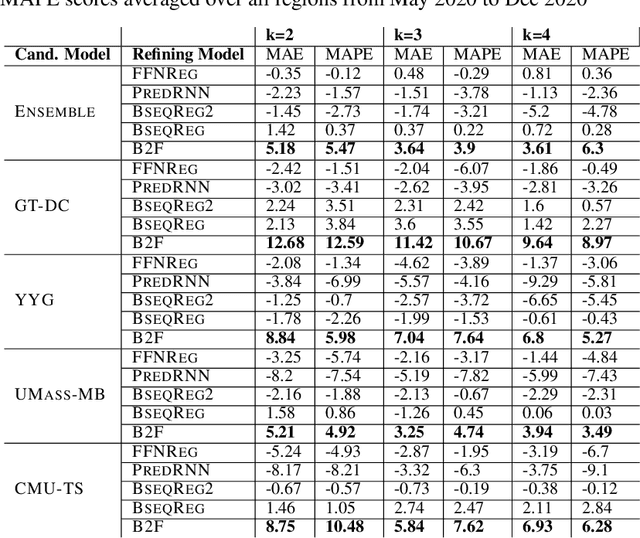
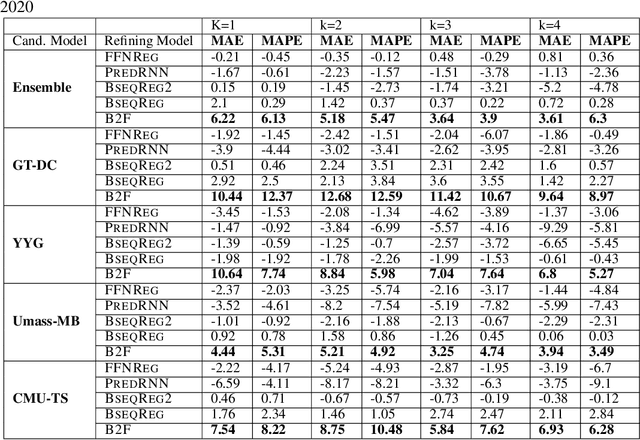
In real-time forecasting in public health, data collection is a non-trivial and demanding task. Often after initially released, it undergoes several revisions later (maybe due to human or technical constraints) - as a result, it may take weeks until the data reaches to a stable value. This so-called 'backfill' phenomenon and its effect on model performance has been barely studied in the prior literature. In this paper, we introduce the multi-variate backfill problem using COVID-19 as the motivating example. We construct a detailed dataset composed of relevant signals over the past year of the pandemic. We then systematically characterize several patterns in backfill dynamics and leverage our observations for formulating a novel problem and neural framework Back2Future that aims to refines a given model's predictions in real-time. Our extensive experiments demonstrate that our method refines the performance of top models for COVID-19 forecasting, in contrast to non-trivial baselines, yielding 18% improvement over baselines, enabling us obtain a new SOTA performance. In addition, we show that our model improves model evaluation too; hence policy-makers can better understand the true accuracy of forecasting models in real-time.
Variance-Aware Sparse Linear Bandits
May 26, 2022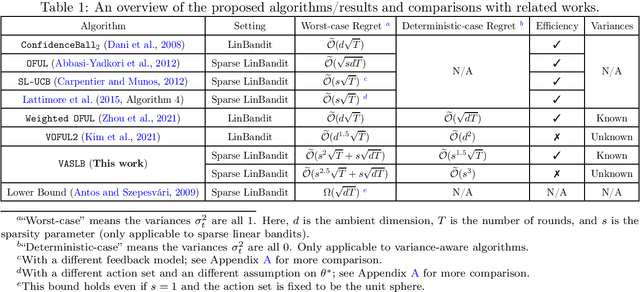
It is well-known that the worst-case minimax regret for sparse linear bandits is $\widetilde{\Theta}\left(\sqrt{dT}\right)$ where $d$ is the ambient dimension and $T$ is the number of time steps (ignoring the dependency on sparsity). On the other hand, in the benign setting where there is no noise and the action set is the unit sphere, one can use divide-and-conquer to achieve an $\widetilde{\mathcal O}(1)$ regret, which is (nearly) independent of $d$ and $T$. In this paper, we present the first variance-aware regret guarantee for sparse linear bandits: $\widetilde{\mathcal O}\left(\sqrt{d\sum_{t=1}^T \sigma_t^2} + 1\right)$, where $\sigma_t^2$ is the variance of the noise at the $t$-th time step. This bound naturally interpolates the regret bounds for the worst-case constant-variance regime ($\sigma_t = \Omega(1)$) and the benign deterministic regimes ($\sigma_t = 0$). To achieve this variance-aware regret guarantee, we develop a general framework that converts any variance-aware linear bandit algorithm to a variance-aware algorithm for sparse linear bandits in a ``black-box'' manner. Specifically, we take two recent algorithms as black boxes to illustrate that the claimed bounds indeed hold, where the first algorithm can handle unknown-variance cases and the second one is more efficient.
On automatic calibration of the SIRD epidemiological model for COVID-19 data in Poland
Apr 26, 2022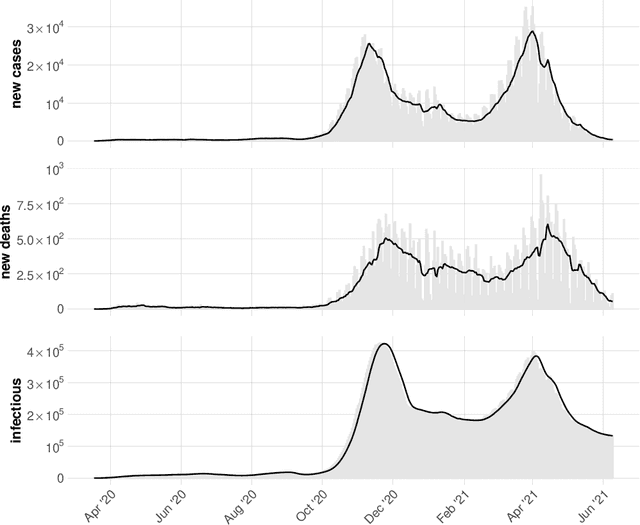

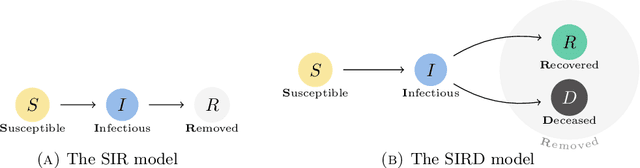
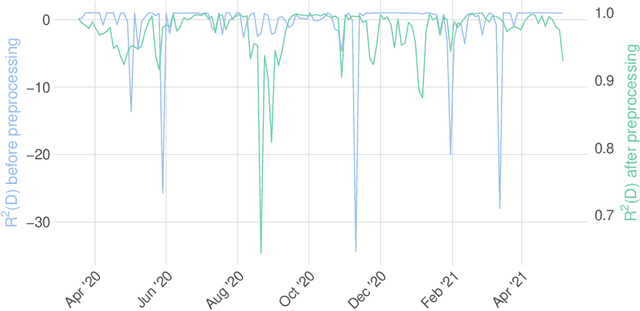
We propose a novel methodology for estimating the epidemiological parameters of a modified SIRD model (acronym of Susceptible, Infected, Recovered and Deceased individuals) and perform a short-term forecast of SARS-CoV-2 virus spread. We mainly focus on forecasting number of deceased. The procedure was tested on reported data for Poland. For some short-time intervals we performed numerical test investigating stability of parameter estimates in the proposed approach. Numerical experiments confirm the effectiveness of short-term forecasts (up to 2 weeks) and stability of the method. To improve their performance (i.e. computation time) GPU architecture was used in computations.
LT-OCF: Learnable-Time ODE-based Collaborative Filtering
Aug 18, 2021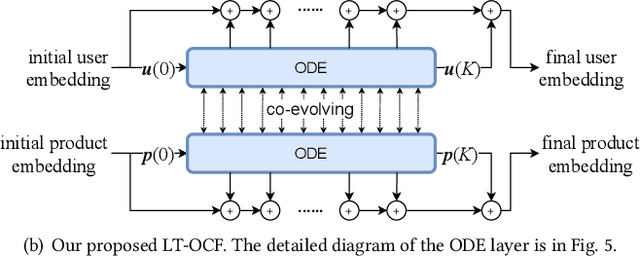
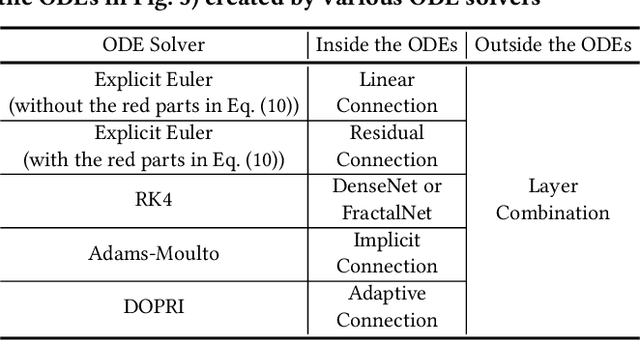
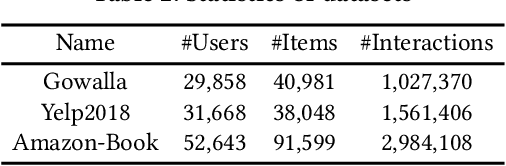
Collaborative filtering (CF) is a long-standing problem of recommender systems. Many novel methods have been proposed, ranging from classical matrix factorization to recent graph convolutional network-based approaches. After recent fierce debates, researchers started to focus on linear graph convolutional networks (GCNs) with a layer combination, which show state-of-the-art accuracy in many datasets. In this work, we extend them based on neural ordinary differential equations (NODEs), because the linear GCN concept can be interpreted as a differential equation, and present the method of Learnable-Time ODE-based Collaborative Filtering (LT-OCF). The main novelty in our method is that after redesigning linear GCNs on top of the NODE regime, i) we learn the optimal architecture rather than relying on manually designed ones, ii) we learn smooth ODE solutions that are considered suitable for CF, and iii) we test with various ODE solvers that internally build a diverse set of neural network connections. We also present a novel training method specialized to our method. In our experiments with three benchmark datasets, Gowalla, Yelp2018, and Amazon-Book, our method consistently shows better accuracy than existing methods, e.g., a recall of 0.0411 by LightGCN vs. 0.0442 by LT-OCF and an NDCG of 0.0315 by LightGCN vs. 0.0341 by LT-OCF in Amazon-Book. One more important discovery in our experiments that is worth mentioning is that our best accuracy was achieved by dense connections rather than linear connections.