 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
LeNSE: Learning To Navigate Subgraph Embeddings for Large-Scale Combinatorial Optimisation
May 20, 2022
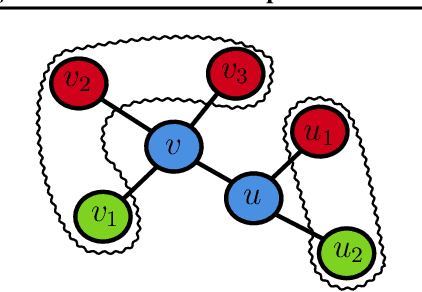
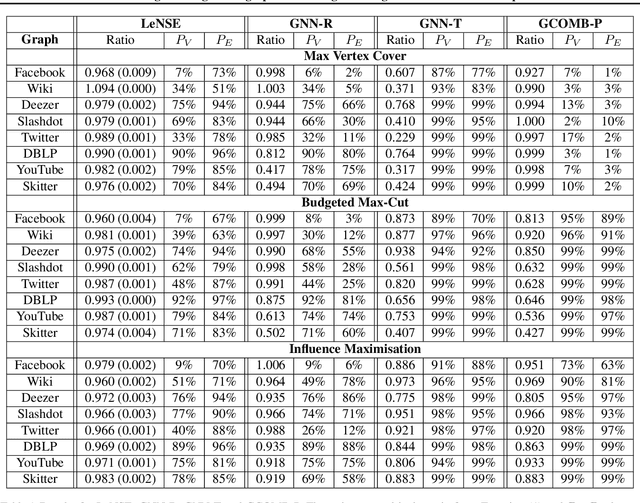
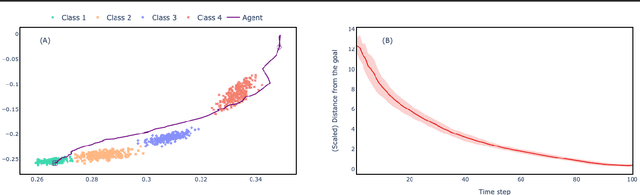
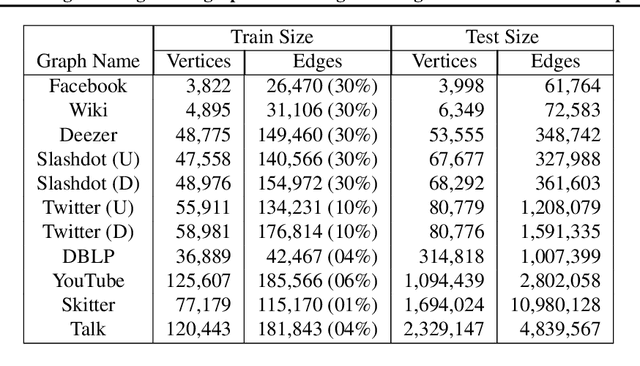
Combinatorial Optimisation problems arise in several application domains and are often formulated in terms of graphs. Many of these problems are NP-hard, but exact solutions are not always needed. Several heuristics have been developed to provide near-optimal solutions; however, they do not typically scale well with the size of the graph. We propose a low-complexity approach for identifying a (possibly much smaller) subgraph of the original graph where the heuristics can be run in reasonable time and with a high likelihood of finding a global near-optimal solution. The core component of our approach is LeNSE, a reinforcement learning algorithm that learns how to navigate the space of possible subgraphs using an Euclidean subgraph embedding as its map. To solve CO problems, LeNSE is provided with a discriminative embedding trained using any existing heuristics using only on a small portion of the original graph. When tested on three problems (vertex cover, max-cut and influence maximisation) using real graphs with up to $10$ million edges, LeNSE identifies small subgraphs yielding solutions comparable to those found by running the heuristics on the entire graph, but at a fraction of the total run time.
Improving trajectory calculations using deep learning inspired single image superresolution
Jun 07, 2022

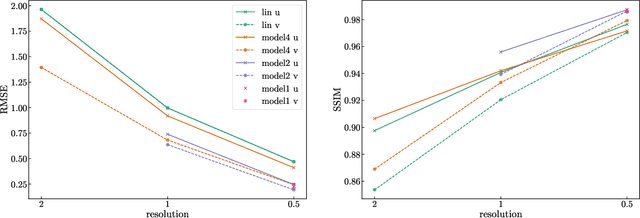

Lagrangian trajectory or particle dispersion models as well as semi-Lagrangian advection schemes require meteorological data such as wind, temperature and geopotential at the exact spatio-temporal locations of the particles that move independently from a regular grid. Traditionally, this high-resolution data has been obtained by interpolating the meteorological parameters from the gridded data of a meteorological model or reanalysis, e.g. using linear interpolation in space and time. However, interpolation errors are a large source of error for these models. Reducing them requires meteorological input fields with high space and time resolution, which may not always be available and can cause severe data storage and transfer problems. Here, we interpret this problem as a single image superresolution task. We interpret meteorological fields available at their native resolution as low-resolution images and train deep neural networks to up-scale them to higher resolution, thereby providing more accurate data for Lagrangian models. We train various versions of the state-of-the-art Enhanced Deep Residual Networks for Superresolution on low-resolution ERA5 reanalysis data with the goal to up-scale these data to arbitrary spatial resolution. We show that the resulting up-scaled wind fields have root-mean-squared errors half the size of the winds obtained with linear spatial interpolation at acceptable computational inference costs. In a test setup using the Lagrangian particle dispersion model FLEXPART and reduced-resolution wind fields, we demonstrate that absolute horizontal transport deviations of calculated trajectories from "ground-truth" trajectories calculated with undegraded 0.5{\deg} winds are reduced by at least 49.5% (21.8%) after 48 hours relative to trajectories using linear interpolation of the wind data when training on 2{\deg} to 1{\deg} (4{\deg} to 2{\deg}) resolution data.
SentimentArcs: A Novel Method for Self-Supervised Sentiment Analysis of Time Series Shows SOTA Transformers Can Struggle Finding Narrative Arcs
Oct 18, 2021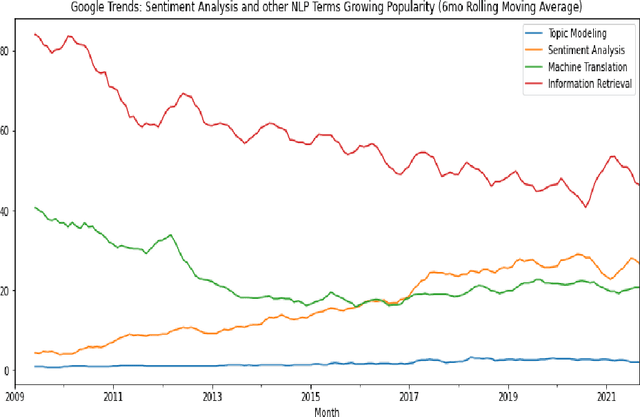
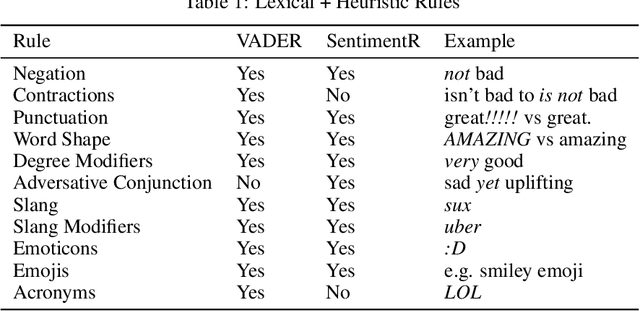
SOTA Transformer and DNN short text sentiment classifiers report over 97% accuracy on narrow domains like IMDB movie reviews. Real-world performance is significantly lower because traditional models overfit benchmarks and generalize poorly to different or more open domain texts. This paper introduces SentimentArcs, a new self-supervised time series sentiment analysis methodology that addresses the two main limitations of traditional supervised sentiment analysis: limited labeled training datasets and poor generalization. A large ensemble of diverse models provides a synthetic ground truth for self-supervised learning. Novel metrics jointly optimize an exhaustive search across every possible corpus:model combination. The joint optimization over both the corpus and model solves the generalization problem. Simple visualizations exploit the temporal structure in narratives so domain experts can quickly spot trends, identify key features, and note anomalies over hundreds of arcs and millions of data points. To our knowledge, this is the first self-supervised method for time series sentiment analysis and the largest survey directly comparing real-world model performance on long-form narratives.
Adversarial attacks on an optical neural network
Apr 29, 2022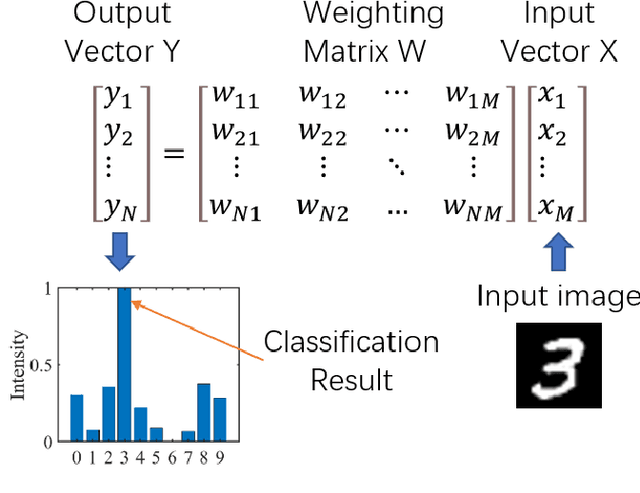
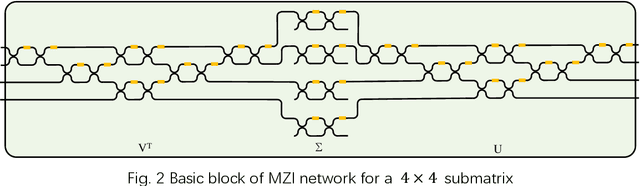
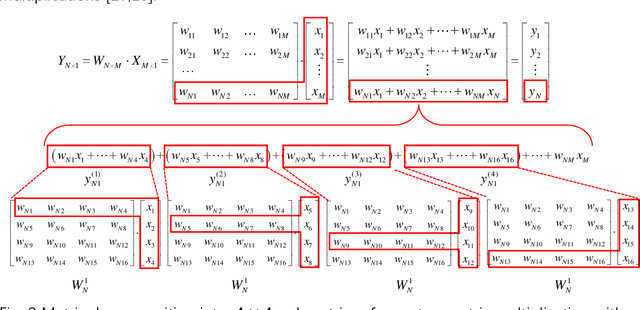
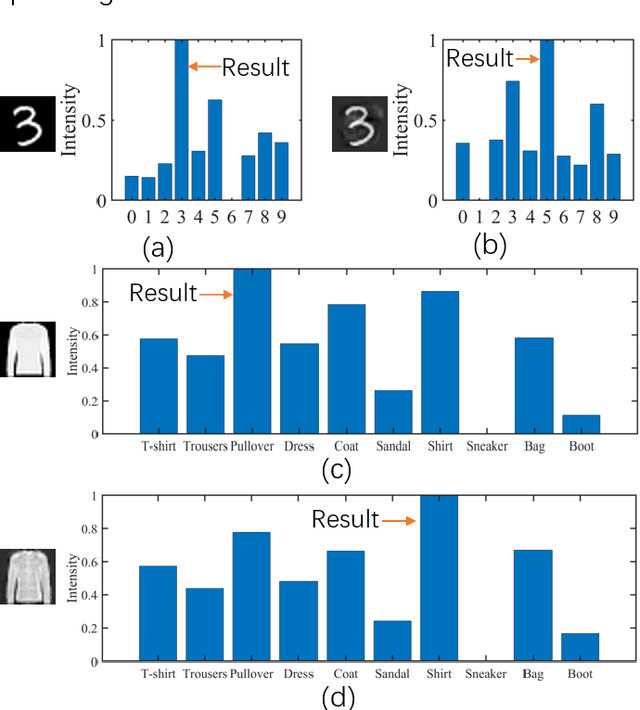
Adversarial attacks have been extensively investigated for machine learning systems including deep learning in the digital domain. However, the adversarial attacks on optical neural networks (ONN) have been seldom considered previously. In this work, we first construct an accurate image classifier with an ONN using a mesh of interconnected Mach-Zehnder interferometers (MZI). Then a corresponding adversarial attack scheme is proposed for the first time. The attacked images are visually very similar to the original ones but the ONN system becomes malfunctioned and generates wrong classification results in most time. The results indicate that adversarial attack is also a significant issue for optical machine learning systems.
Real-time Spatio-temporal Event Detection on Geotagged Social Media
Jun 23, 2021
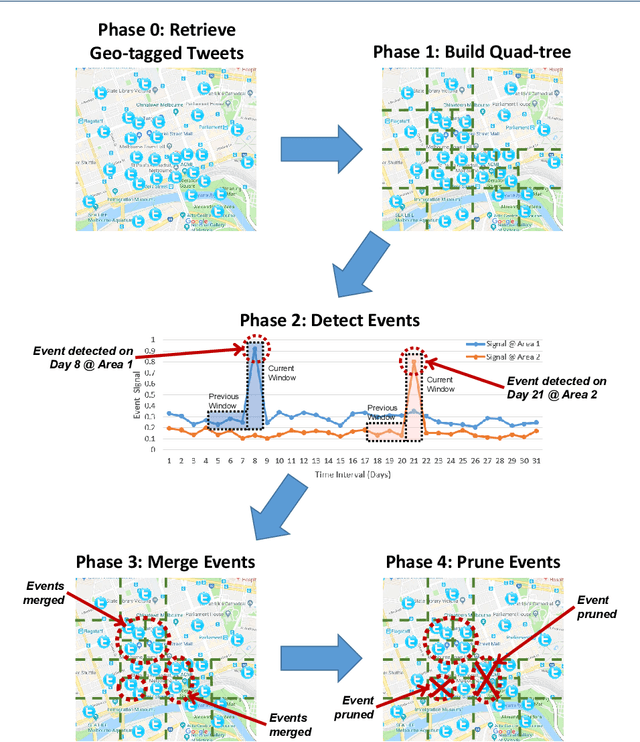


A key challenge in mining social media data streams is to identify events which are actively discussed by a group of people in a specific local or global area. Such events are useful for early warning for accident, protest, election or breaking news. However, neither the list of events nor the resolution of both event time and space is fixed or known beforehand. In this work, we propose an online spatio-temporal event detection system using social media that is able to detect events at different time and space resolutions. First, to address the challenge related to the unknown spatial resolution of events, a quad-tree method is exploited in order to split the geographical space into multiscale regions based on the density of social media data. Then, a statistical unsupervised approach is performed that involves Poisson distribution and a smoothing method for highlighting regions with unexpected density of social posts. Further, event duration is precisely estimated by merging events happening in the same region at consecutive time intervals. A post processing stage is introduced to filter out events that are spam, fake or wrong. Finally, we incorporate simple semantics by using social media entities to assess the integrity, and accuracy of detected events. The proposed method is evaluated using different social media datasets: Twitter and Flickr for different cities: Melbourne, London, Paris and New York. To verify the effectiveness of the proposed method, we compare our results with two baseline algorithms based on fixed split of geographical space and clustering method. For performance evaluation, we manually compute recall and precision. We also propose a new quality measure named strength index, which automatically measures how accurate the reported event is.
Adaptive Test-Time Augmentation for Low-Power CPU
May 13, 2021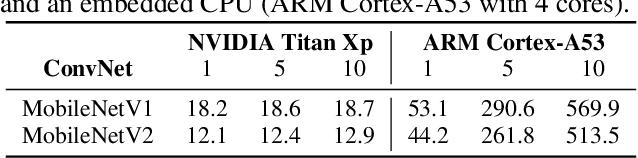
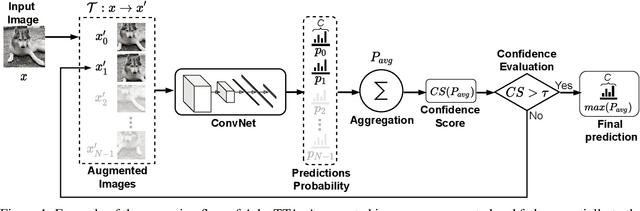
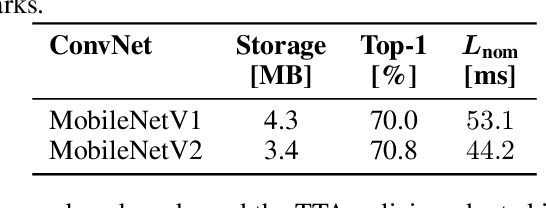
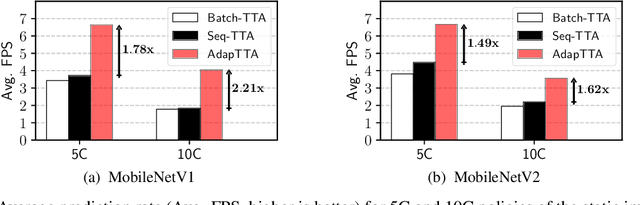
Convolutional Neural Networks (ConvNets) are trained offline using the few available data and may therefore suffer from substantial accuracy loss when ported on the field, where unseen input patterns received under unpredictable external conditions can mislead the model. Test-Time Augmentation (TTA) techniques aim to alleviate such common side effect at inference-time, first running multiple feed-forward passes on a set of altered versions of the same input sample, and then computing the main outcome through a consensus of the aggregated predictions. Unfortunately, the implementation of TTA on embedded CPUs introduces latency penalties that limit its adoption on edge applications. To tackle this issue, we propose AdapTTA, an adaptive implementation of TTA that controls the number of feed-forward passes dynamically, depending on the complexity of the input. Experimental results on state-of-the-art ConvNets for image classification deployed on a commercial ARM Cortex-A CPU demonstrate AdapTTA reaches remarkable latency savings, from 1.49X to 2.21X, and hence a higher frame rate compared to static TTA, still preserving the same accuracy gain.
Adaptive Task Planning for Large-Scale Robotized Warehouses
Apr 24, 2022
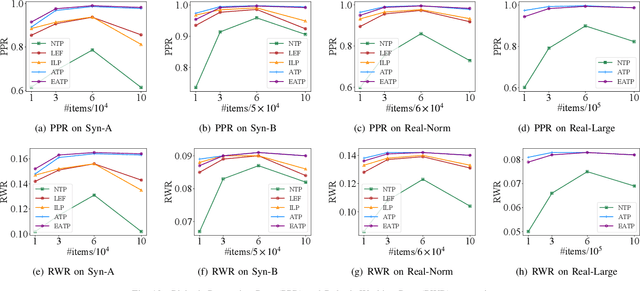
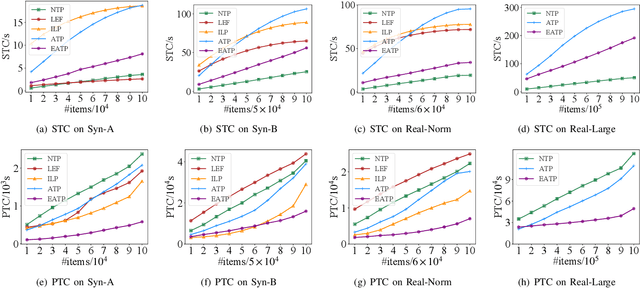
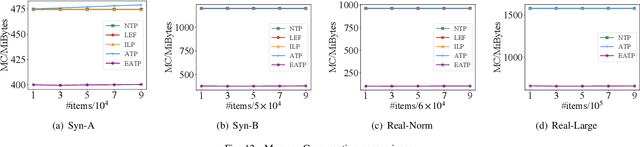
Robotized warehouses are deployed to automatically distribute millions of items brought by the massive logistic orders from e-commerce. A key to automated item distribution is to plan paths for robots, also known as task planning, where each task is to deliver racks with items to pickers for processing and then return the rack back. Prior solutions are unfit for large-scale robotized warehouses due to the inflexibility to time-varying item arrivals and the low efficiency for high throughput. In this paper, we propose a new task planning problem called TPRW, which aims to minimize the end-to-end makespan that incorporates the entire item distribution pipeline, known as a fulfilment cycle. Direct extensions from state-of-the-art path finding methods are ineffective to solve the TPRW problem because they fail to adapt to the bottleneck variations of fulfillment cycles. In response, we propose Efficient Adaptive Task Planning, a framework for large-scale robotized warehouses with time-varying item arrivals. It adaptively selects racks to fulfill at each timestamp via reinforcement learning, accounting for the time-varying bottleneck of the fulfillment cycles. Then it finds paths for robots to transport the selected racks. The framework adopts a series of efficient optimizations on both time and memory to handle large-scale item throughput. Evaluations on both synthesized and real data show an improvement of $37.1\%$ in effectiveness and $75.5\%$ in efficiency over the state-of-the-arts.
Fast Continuous and Integer L-shaped Heuristics Through Supervised Learning
May 02, 2022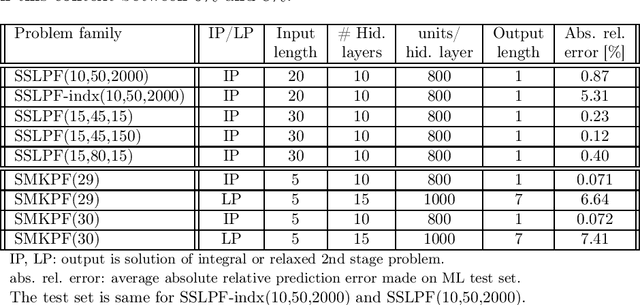
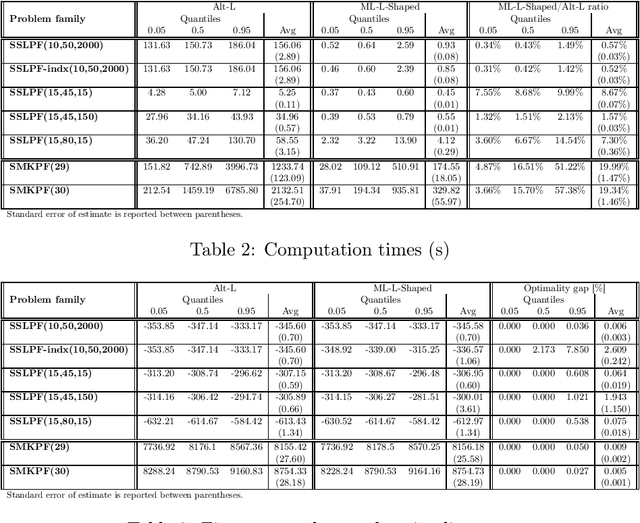
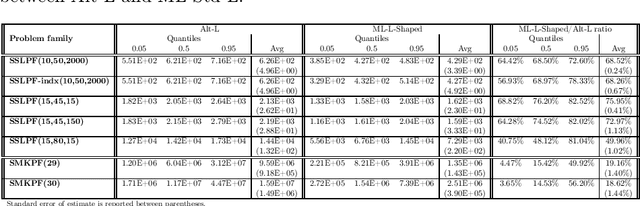
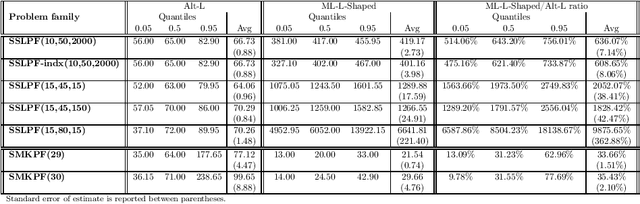
We propose a methodology at the nexus of operations research and machine learning (ML) leveraging generic approximators available from ML to accelerate the solution of mixed-integer linear two-stage stochastic programs. We aim at solving problems where the second stage is highly demanding. Our core idea is to gain large reductions in online solution time while incurring small reductions in first-stage solution accuracy by substituting the exact second-stage solutions with fast, yet accurate supervised ML predictions. This upfront investment in ML would be justified when similar problems are solved repeatedly over time, for example, in transport planning related to fleet management, routing and container yard management. Our numerical results focus on the problem class seminally addressed with the integer and continuous L-shaped cuts. Our extensive empirical analysis is grounded in standardized families of problems derived from stochastic server location (SSLP) and stochastic multi knapsack (SMKP) problems available in the literature. The proposed method can solve the hardest instances of SSLP in less than 9% of the time it takes the state-of-the-art exact method, and in the case of SMKP the same figure is 20%. Average optimality gaps are in most cases less than 0.1%.
Missing Value Imputation on Multidimensional Time Series
Mar 02, 2021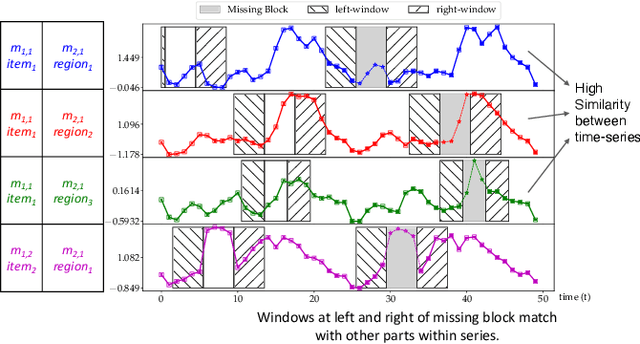
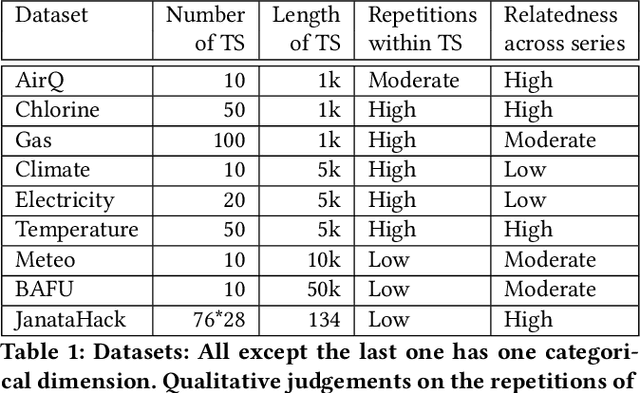
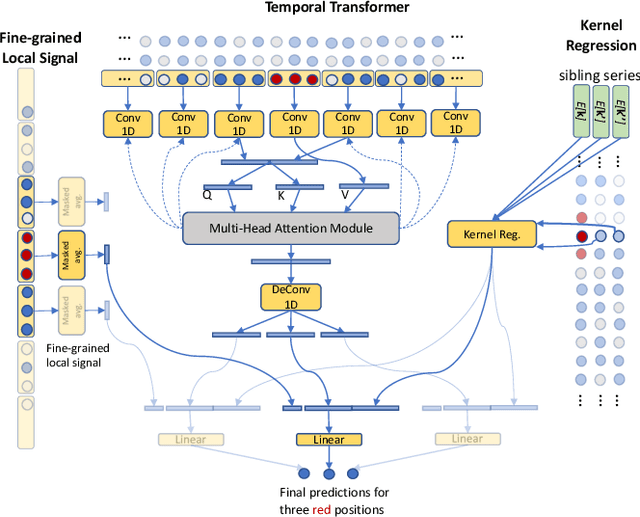

We present DeepMVI, a deep learning method for missing value imputation in multidimensional time-series datasets. Missing values are commonplace in decision support platforms that aggregate data over long time stretches from disparate sources, and reliable data analytics calls for careful handling of missing data. One strategy is imputing the missing values, and a wide variety of algorithms exist spanning simple interpolation, matrix factorization methods like SVD, statistical models like Kalman filters, and recent deep learning methods. We show that often these provide worse results on aggregate analytics compared to just excluding the missing data. DeepMVI uses a neural network to combine fine-grained and coarse-grained patterns along a time series, and trends from related series across categorical dimensions. After failing with off-the-shelf neural architectures, we design our own network that includes a temporal transformer with a novel convolutional window feature, and kernel regression with learned embeddings. The parameters and their training are designed carefully to generalize across different placements of missing blocks and data characteristics. Experiments across nine real datasets, four different missing scenarios, comparing seven existing methods show that DeepMVI is significantly more accurate, reducing error by more than 50% in more than half the cases, compared to the best existing method. Although slower than simpler matrix factorization methods, we justify the increased time overheads by showing that DeepMVI is the only option that provided overall more accurate analytics than dropping missing values.
Enforcing Continuous Physical Symmetries in Deep Learning Network for Solving Partial Differential Equations
Jun 19, 2022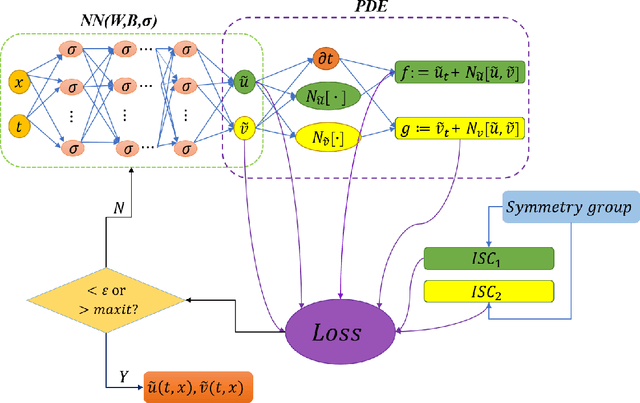

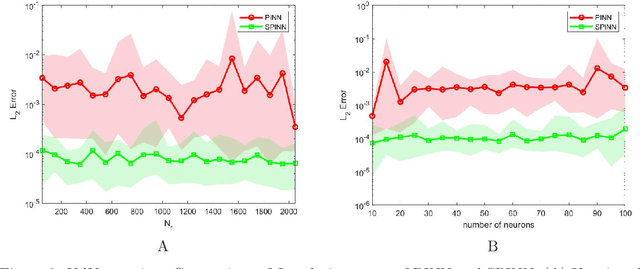

As a typical {application} of deep learning, physics-informed neural network (PINN) {has been} successfully used to find numerical solutions of partial differential equations (PDEs), but how to improve the limited accuracy is still a great challenge for PINN. In this work, we introduce a new method, symmetry-enhanced physics informed neural network (SPINN) where the invariant surface conditions induced by the Lie symmetries of PDEs are embedded into the loss function of PINN, for improving the accuracy of PINN. We test the effectiveness of SPINN via two groups of ten independent numerical experiments for the heat equation, Korteweg-de Vries (KdV) equation and potential Burgers {equations} respectively, which shows that SPINN performs better than PINN with fewer training points and simpler architecture of neural network. Furthermore, we discuss the computational overhead of SPINN in terms of the relative computational cost to PINN and show that the training time of SPINN has no obvious increases, even less than PINN for some cases.