 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
End-To-End Audiovisual Feature Fusion for Active Speaker Detection
Jul 27, 2022
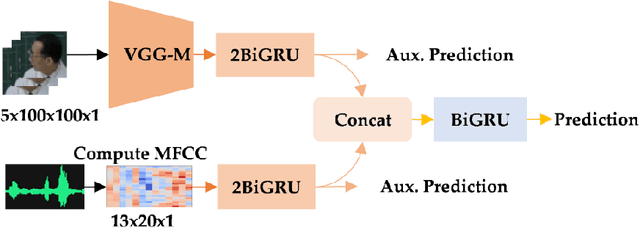
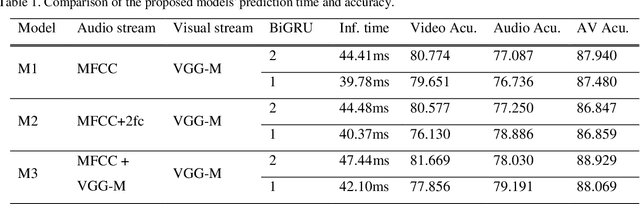
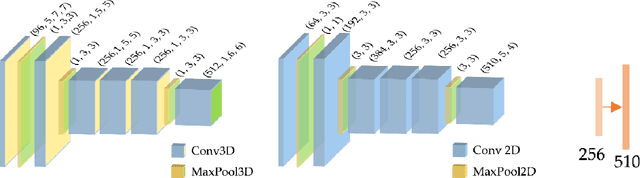

Active speaker detection plays a vital role in human-machine interaction. Recently, a few end-to-end audiovisual frameworks emerged. However, these models' inference time was not explored and are not applicable for real-time applications due to their complexity and large input size. In addition, they explored a similar feature extraction strategy that employs the ConvNet on audio and visual inputs. This work presents a novel two-stream end-to-end framework fusing features extracted from images via VGG-M with raw Mel Frequency Cepstrum Coefficients features extracted from the audio waveform. The network has two BiGRU layers attached to each stream to handle each stream's temporal dynamic before fusion. After fusion, one BiGRU layer is attached to model the joint temporal dynamics. The experiment result on the AVA-ActiveSpeaker dataset indicates that our new feature extraction strategy shows more robustness to noisy signals and better inference time than models that employed ConvNet on both modalities. The proposed model predicts within 44.41 ms, which is fast enough for real-time applications. Our best-performing model attained 88.929% accuracy, nearly the same detection result as state-of-the-art -work.
Neural-Rendezvous: Learning-based Robust Guidance and Control to Encounter Interstellar Objects
Aug 09, 2022


Interstellar objects (ISOs), astronomical objects not gravitationally bound to the Sun, are likely representatives of primitive materials invaluable in understanding exoplanetary star systems. Due to their poorly constrained orbits with generally high inclinations and relative velocities, however, exploring ISOs with conventional human-in-the-loop approaches is significantly challenging. This paper presents Neural-Rendezvous -- a deep learning-based guidance and control framework for encountering any fast-moving objects, including ISOs, robustly, accurately, and autonomously in real-time. It uses pointwise minimum norm tracking control on top of a guidance policy modeled by a spectrally-normalized deep neural network, where its hyperparameters are tuned with a newly introduced loss function directly penalizing the state trajectory tracking error. We rigorously show that, even in the challenging case of ISO exploration, Neural-Rendezvous provides 1) a high probability exponential bound on the expected spacecraft delivery error; and 2) a finite optimality gap with respect to the solution of model predictive control, both of which are indispensable especially for such a critical space mission. In numerical simulations, Neural-Rendezvous is demonstrated to achieve a terminal-time delivery error of less than 0.2 km for 99% of the ISO candidates with realistic state uncertainty, whilst retaining computational efficiency sufficient for real-time implementation.
CrossDTR: Cross-view and Depth-guided Transformers for 3D Object Detection
Sep 27, 2022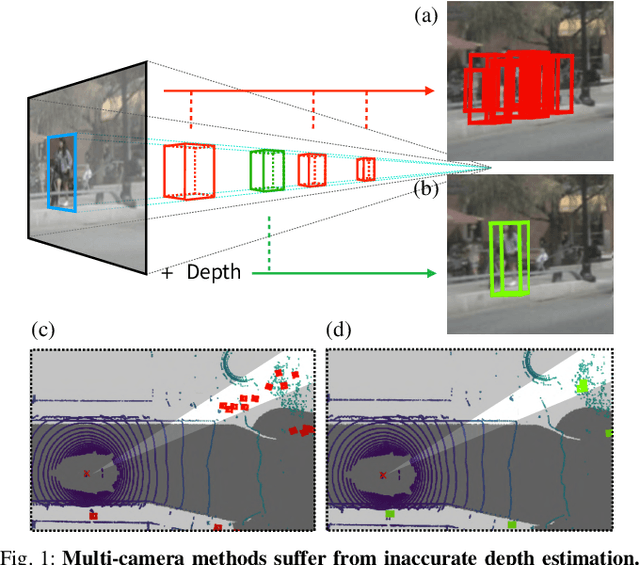
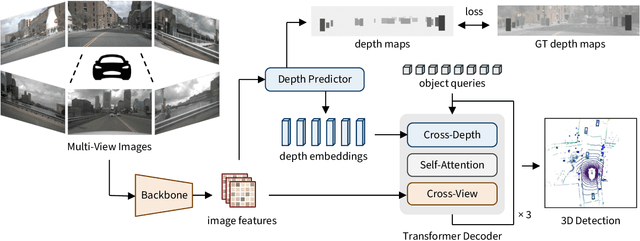
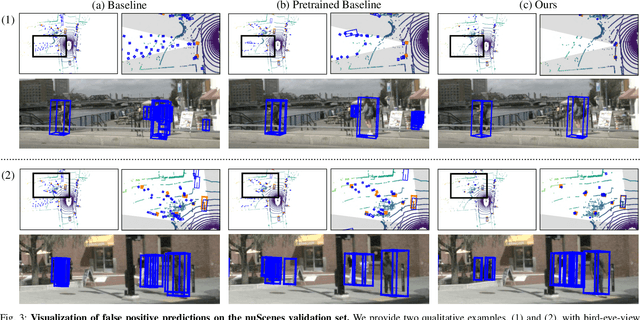
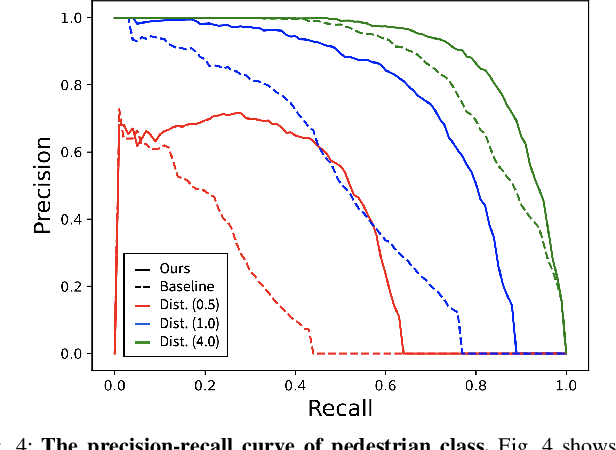
To achieve accurate 3D object detection at a low cost for autonomous driving, many multi-camera methods have been proposed and solved the occlusion problem of monocular approaches. However, due to the lack of accurate estimated depth, existing multi-camera methods often generate multiple bounding boxes along a ray of depth direction for difficult small objects such as pedestrians, resulting in an extremely low recall. Furthermore, directly applying depth prediction modules to existing multi-camera methods, generally composed of large network architectures, cannot meet the real-time requirements of self-driving applications. To address these issues, we propose Cross-view and Depth-guided Transformers for 3D Object Detection, CrossDTR. First, our lightweight depth predictor is designed to produce precise object-wise sparse depth maps and low-dimensional depth embeddings without extra depth datasets during supervision. Second, a cross-view depth-guided transformer is developed to fuse the depth embeddings as well as image features from cameras of different views and generate 3D bounding boxes. Extensive experiments demonstrated that our method hugely surpassed existing multi-camera methods by 10 percent in pedestrian detection and about 3 percent in overall mAP and NDS metrics. Also, computational analyses showed that our method is 5 times faster than prior approaches. Our codes will be made publicly available at https://github.com/sty61010/CrossDTR.
Predictive Event Segmentation and Representation with Neural Networks: A Self-Supervised Model Assessed by Psychological Experiments
Oct 04, 2022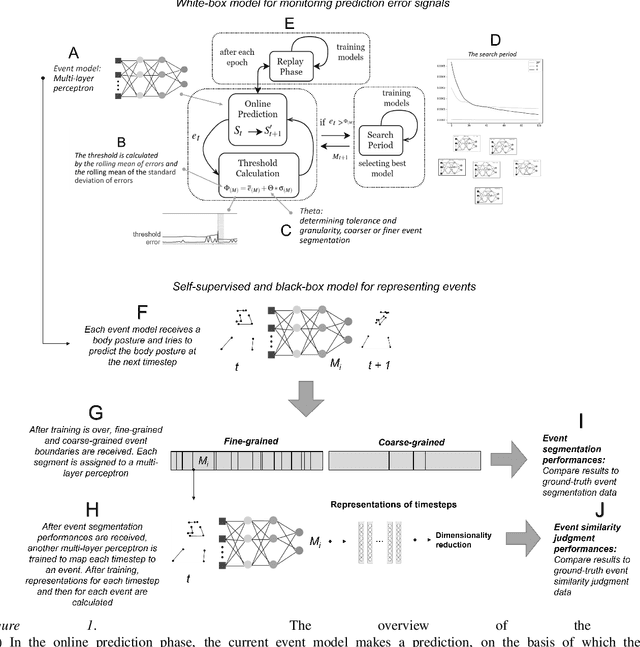
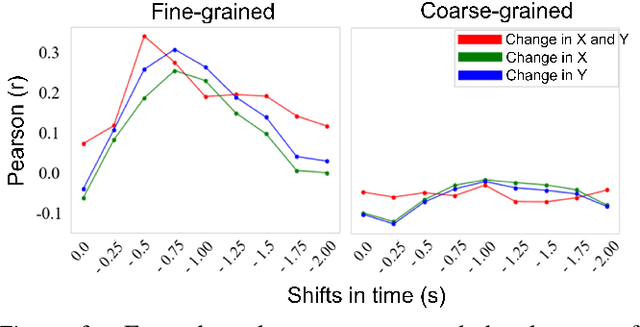
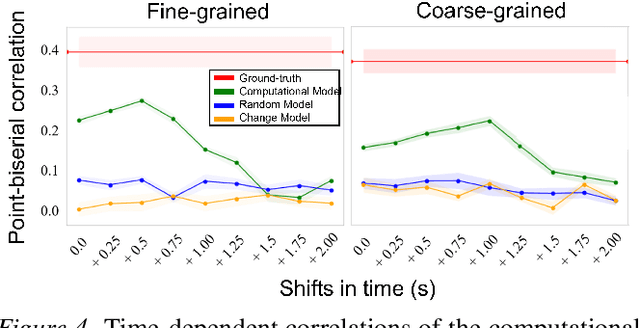
People segment complex, ever-changing and continuous experience into basic, stable and discrete spatio-temporal experience units, called events. Event segmentation literature investigates the mechanisms that allow people to extract events. Event segmentation theory points out that people predict ongoing activities and observe prediction error signals to find event boundaries that keep events apart. In this study, we investigated the mechanism giving rise to this ability by a computational model and accompanying psychological experiments. Inspired from event segmentation theory and predictive processing, we introduced a self-supervised model of event segmentation. This model consists of neural networks that predict the sensory signal in the next time-step to represent different events, and a cognitive model that regulates these networks on the basis of their prediction errors. In order to verify the ability of our model in segmenting events, learning them during passive observation, and representing them in its internal representational space, we prepared a video that depicts human behaviors represented by point-light displays. We compared event segmentation behaviors of participants and our model with this video in two hierarchical event segmentation levels. By using point-biserial correlation technique, we demonstrated that event segmentation decisions of our model correlated with the responses of participants. Moreover, by approximating representation space of participants by a similarity-based technique, we showed that our model formed a similar representation space with those of participants. The result suggests that our model that tracks the prediction error signals can produce human-like event boundaries and event representations. Finally, we discussed our contribution to the literature of event cognition and our understanding of how event segmentation is implemented in the brain.
Lifelong Learning for Neural powered Mixed Integer Programming
Aug 26, 2022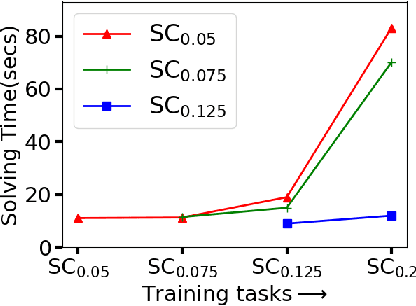
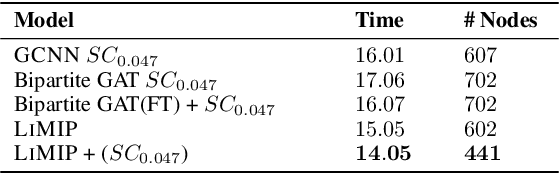
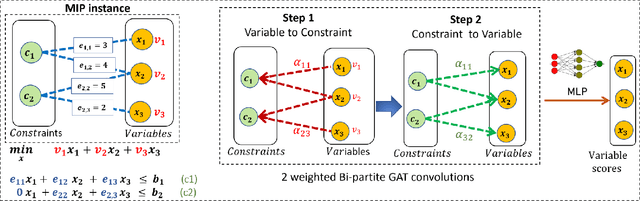

Mixed Integer programs (MIPs) are typically solved by the Branch-and-Bound algorithm. Recently, Learning to imitate fast approximations of the expert strong branching heuristic has gained attention due to its success in reducing the running time for solving MIPs. However, existing learning-to-branch methods assume that the entire training data is available in a single session of training. This assumption is often not true, and if the training data is supplied in continual fashion over time, existing techniques suffer from catastrophic forgetting. In this work, we study the hitherto unexplored paradigm of Lifelong Learning to Branch on Mixed Integer Programs. To mitigate catastrophic forgetting, we propose LIMIP, which is powered by the idea of modeling an MIP instance in the form of a bipartite graph, which we map to an embedding space using a bipartite Graph Attention Network. This rich embedding space avoids catastrophic forgetting through the application of knowledge distillation and elastic weight consolidation, wherein we learn the parameters key towards retaining efficacy and are therefore protected from significant drift. We evaluate LIMIP on a series of NP-hard problems and establish that in comparison to existing baselines, LIMIP is up to 50% better when confronted with lifelong learning.
Quantifying How Hateful Communities Radicalize Online Users
Oct 02, 2022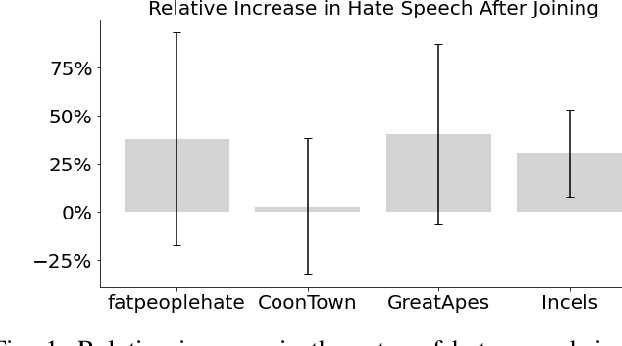
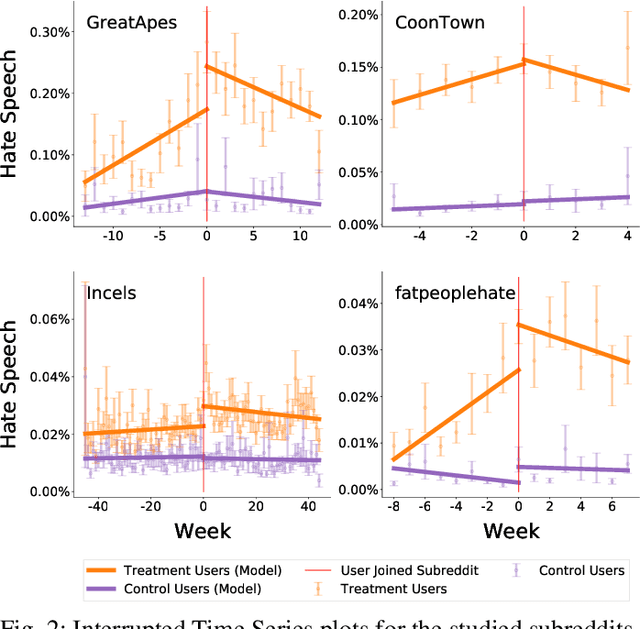
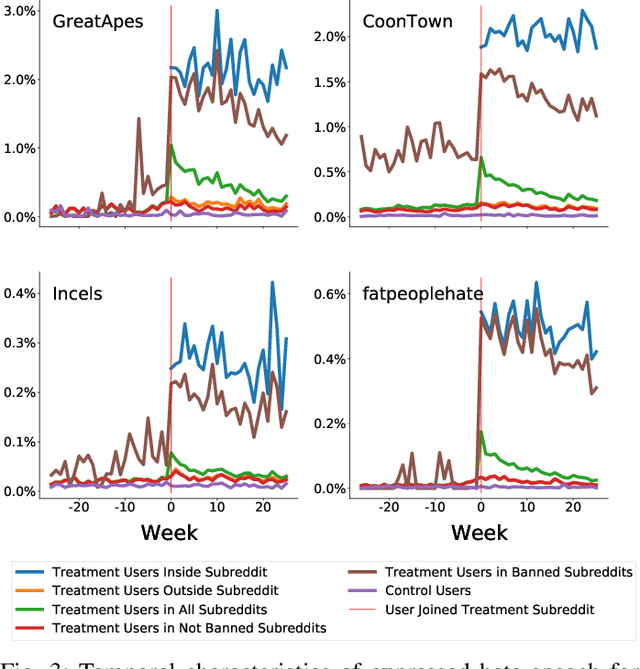
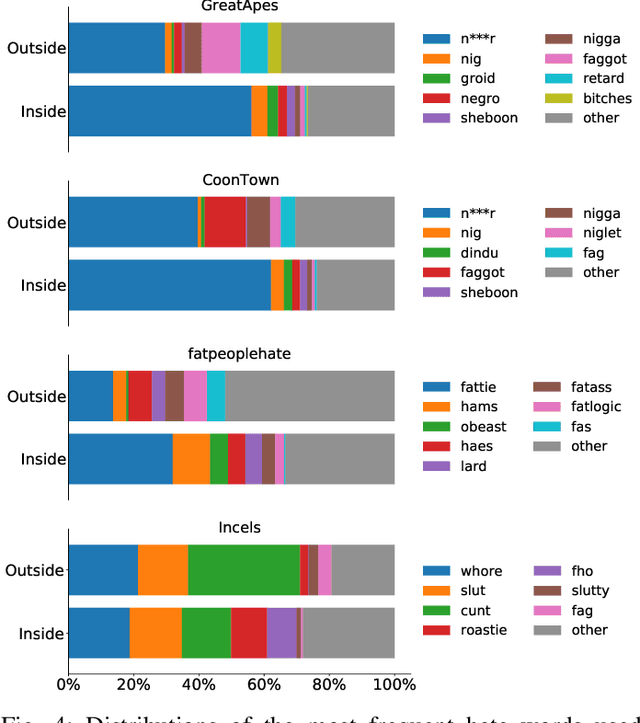
While online social media offers a way for ignored or stifled voices to be heard, it also allows users a platform to spread hateful speech. Such speech usually originates in fringe communities, yet it can spill over into mainstream channels. In this paper, we measure the impact of joining fringe hateful communities in terms of hate speech propagated to the rest of the social network. We leverage data from Reddit to assess the effect of joining one type of echo chamber: a digital community of like-minded users exhibiting hateful behavior. We measure members' usage of hate speech outside the studied community before and after they become active participants. Using Interrupted Time Series (ITS) analysis as a causal inference method, we gauge the spillover effect, in which hateful language from within a certain community can spread outside that community by using the level of out-of-community hate word usage as a proxy for learned hate. We investigate four different Reddit sub-communities (subreddits) covering three areas of hate speech: racism, misogyny and fat-shaming. In all three cases we find an increase in hate speech outside the originating community, implying that joining such community leads to a spread of hate speech throughout the platform. Moreover, users are found to pick up this new hateful speech for months after initially joining the community. We show that the harmful speech does not remain contained within the community. Our results provide new evidence of the harmful effects of echo chambers and the potential benefit of moderating them to reduce adoption of hateful speech.
EventNet: Detecting Events in EEG
Sep 22, 2022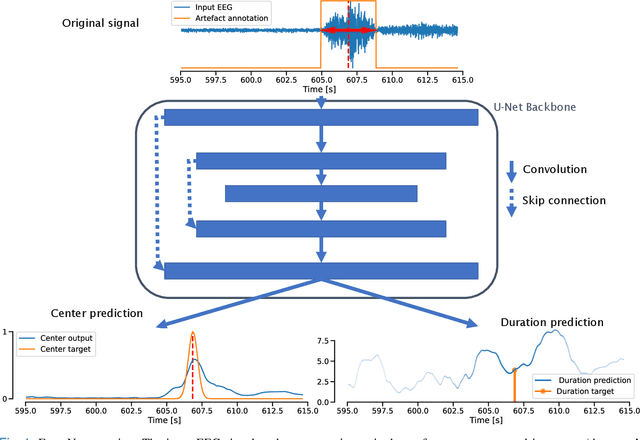
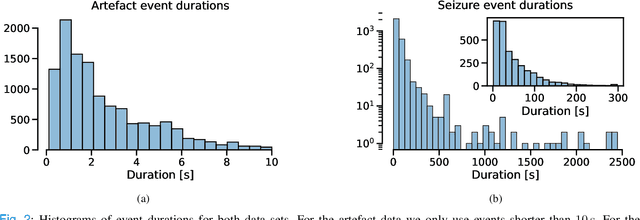
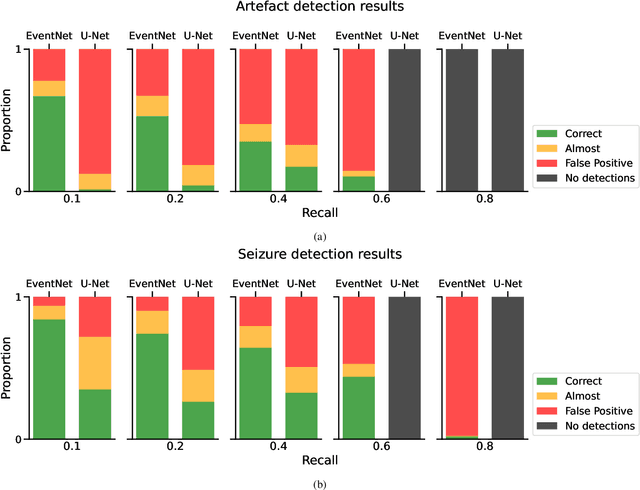
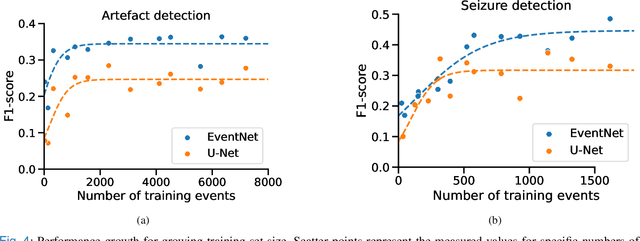
Neurologists are often looking for various "events of interest" when analyzing EEG. To support them in this task various machine-learning-based algorithms have been developed. Most of these algorithms treat the problem as classification, thereby independently processing signal segments and ignoring temporal dependencies inherent to events of varying duration. At inference time, the predicted labels for each segment then have to be post processed to detect the actual events. We propose an end-to-end event detection approach (EventNet), based on deep learning, that directly works with events as learning targets, stepping away from ad-hoc postprocessing schemes to turn model outputs into events. We compare EventNet with a state-of-the-art approach for artefact and and epileptic seizure detection, two event types with highly variable durations. EventNet shows improved performance in detecting both event types. These results show the power of treating events as direct learning targets, instead of using ad-hoc postprocessing to obtain them. Our event detection framework can easily be extended to other event detection problems in signal processing, since the deep learning backbone does not depend on any task-specific features.
DYP-SLAM: A Real-time Visual SLAM Based on YOLO and Probability in Dynamic Environments
Feb 04, 2022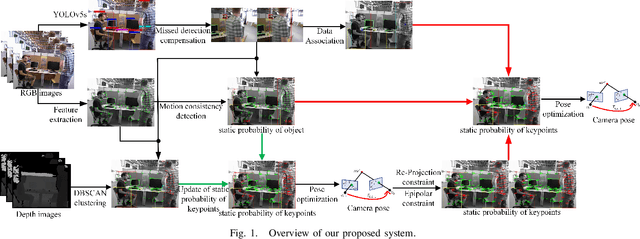

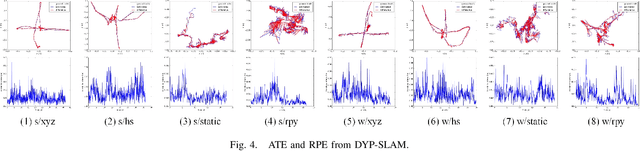
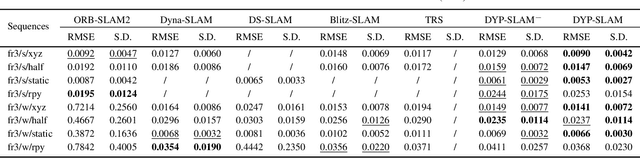
SLAM algorithm is based on the static assumption of environment. Therefore, the dynamic factors in the environment will have a great impact on the matching points due to violating this assumption, and then directly affect the accuracy of subsequent camera pose estimation. Recently, some related works generally use the combination of semantic constraints and geometric constraints to deal with dynamic objects, but there are some problems, such as poor real-time performance, easy to treat people as rigid bodies, and poor performance in low dynamic scenes. In this paper, a dynamic scene oriented visual SLAM algorithm based on target detection and static probability named DYP-SLAM is proposed. The algorithm combines semantic constraints and geometric constraints to calculate the static probability of objects, keypoints and map points, and takes them as weights to participate in camera pose estimation. The proposed algorithm is evaluated on the public dataset and compared with a variety of advanced algorithms. It has achieved the best results in almost all low dynamics and high dynamic scenarios, and showing quite high real-time.
On Developing Facial Stress Analysis and Expression Recognition Platform
Sep 16, 2022

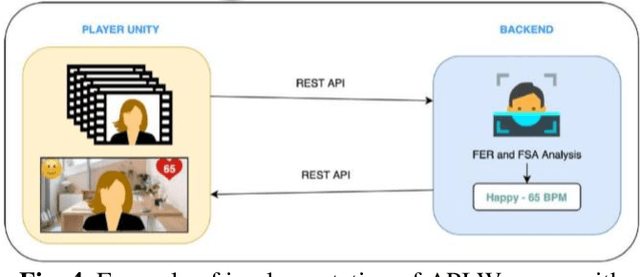
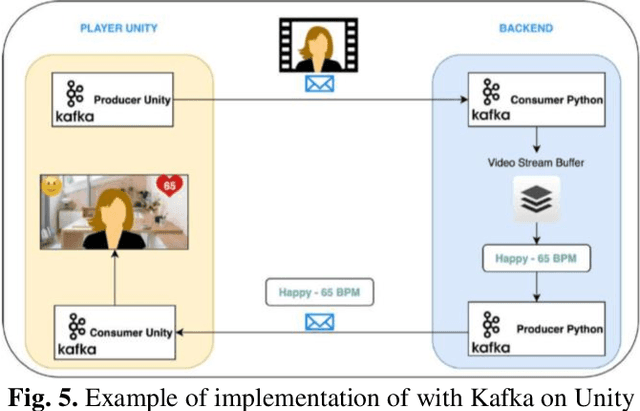
This work represents the experimental and development process of system facial expression recognition and facial stress analysis algorithms for an immersive digital learning platform. The system retrieves from users web camera and evaluates it using artificial neural network (ANN) algorithms. The ANN output signals can be used to score and improve the learning process. Adapting an ANN to a new system can require a significant implementation effort or the need to repeat the ANN training. There are also limitations related to the minimum hardware required to run an ANN. To overpass these constraints, some possible implementations of facial expression recognition and facial stress analysis algorithms in real-time systems are presented. The implementation of the new solution has made it possible to improve the accuracy in the recognition of facial expressions and also to increase their response speed. Experimental results showed that using the developed algorithms allow to detect the heart rate with better rate in comparison with social equipment.
Shape-aware Safe Corridors Generation using Voxel Grids
Aug 16, 2022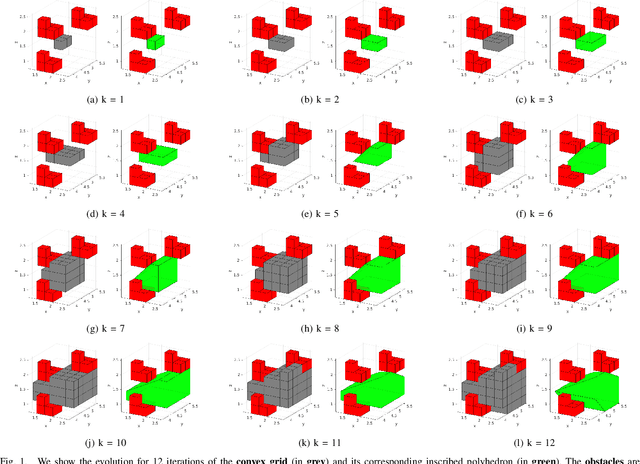
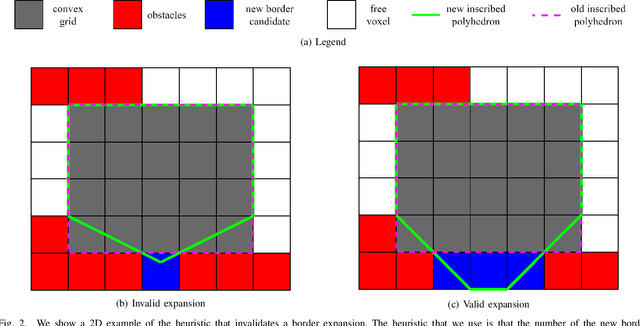
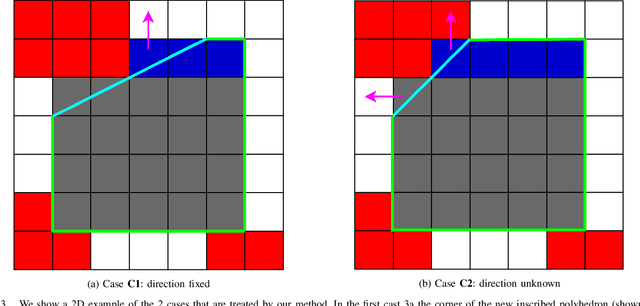
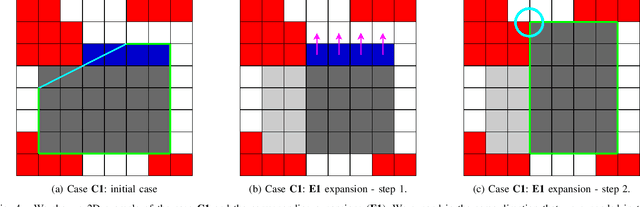
Safe Corridors (a series of overlapping convex shapes) have been used recently in multiple state-of-the-art motion planning methods. They allow to represent the free space in the environment in an efficient way for collision avoidance. In this paper, we propose a new framework for generating Safe Corridors. We assume that we have a voxel grid representation of the environment. The proposed framework improves on a previous state-of-the-art voxel grid based Safe Corridor generation method. It also creates a connectivity graph between polyhedra of a given Safe Corridor that allows to know which polyhedra intersect with each other. The connectivity graph can be used in planning methods to reduce computation time. The method is compared to other state-of-the-art methods in simulations in terms of computation time, volume covered, safety, number of polyhedron per Safe Corridor and number of constraints per polyhedron.