 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
On Background Bias in Deep Metric Learning
Oct 04, 2022

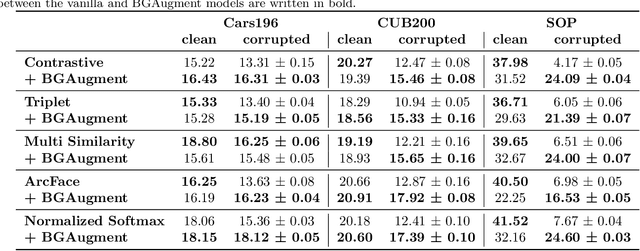

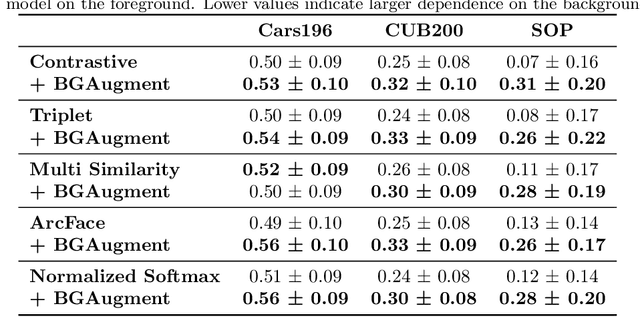
Deep Metric Learning trains a neural network to map input images to a lower-dimensional embedding space such that similar images are closer together than dissimilar images. When used for item retrieval, a query image is embedded using the trained model and the closest items from a database storing their respective embeddings are returned as the most similar items for the query. Especially in product retrieval, where a user searches for a certain product by taking a photo of it, the image background is usually not important and thus should not influence the embedding process. Ideally, the retrieval process always returns fitting items for the photographed object, regardless of the environment the photo was taken in. In this paper, we analyze the influence of the image background on Deep Metric Learning models by utilizing five common loss functions and three common datasets. We find that Deep Metric Learning networks are prone to so-called background bias, which can lead to a severe decrease in retrieval performance when changing the image background during inference. We also show that replacing the background of images during training with random background images alleviates this issue. Since we use an automatic background removal method to do this background replacement, no additional manual labeling work and model changes are required while inference time stays the same. Qualitative and quantitative analyses, for which we introduce a new evaluation metric, confirm that models trained with replaced backgrounds attend more to the main object in the image, benefitting item retrieval systems.
Time Encoding of Finite-Rate-of-Innovation Signals
Aug 12, 2021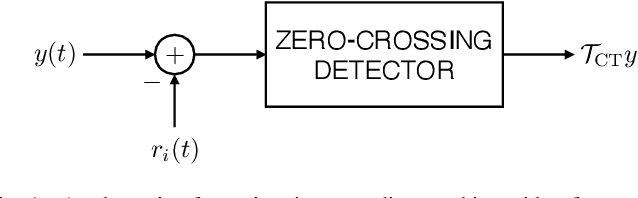
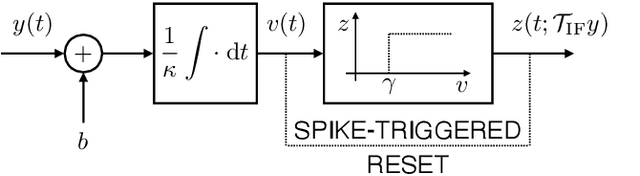
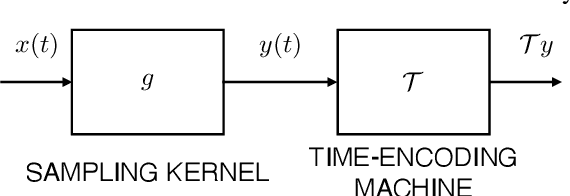
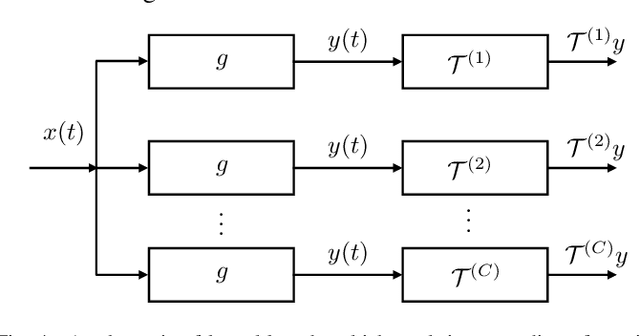
Time-encoding of continuous-time signals is an alternative sampling paradigm to conventional methods such as Shannon's sampling. In time-encoding, the signal is encoded using a sequence of time instants where an event occurs, and hence fall under event-driven sampling methods. Time-encoding can be designed agnostic to the global clock of the sampling hardware, which makes sampling asynchronous. Moreover, the encoding is sparse. This makes time-encoding energy efficient. However, the signal representation is nonstandard and in general, nonuniform. In this paper, we consider time-encoding of finite-rate-of-innovation signals, and in particular, periodic signals composed of weighted and time-shifted versions of a known pulse. We consider encoding using both crossing-time-encoding machine (C-TEM) and integrate-and-fire time-encoding machine (IF-TEM). We analyze how time-encoding manifests in the Fourier domain and arrive at the familiar sum-of-sinusoids structure of the Fourier coefficients that can be obtained starting from the time-encoded measurements via a suitable linear transformation. Thereafter, standard FRI techniques become applicable. Further, we extend the theory to multichannel time-encoding such that each channel operates with a lower sampling requirement. We also study the effect of measurement noise, where the temporal measurements are perturbed by additive noise. To combat the effect of noise, we propose a robust optimization framework to simultaneously denoise the Fourier coefficients and estimate the annihilating filter accurately. We provide sufficient conditions for time-encoding and perfect reconstruction using C-TEM and IF-TEM, and furnish extensive simulations to substantiate our findings.
Joint Channel Estimation and Data Detection for Hybrid RIS aided Millimeter Wave OTFS Systems
Aug 14, 2022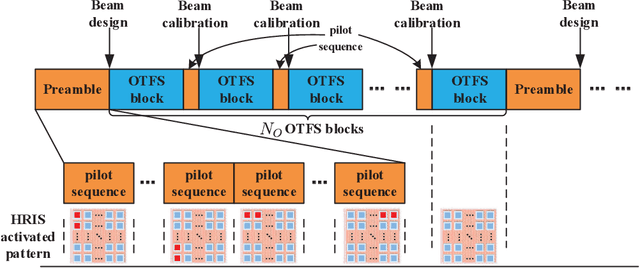
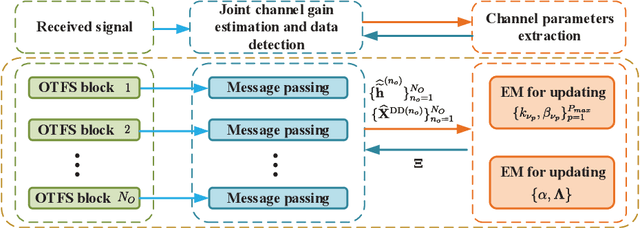
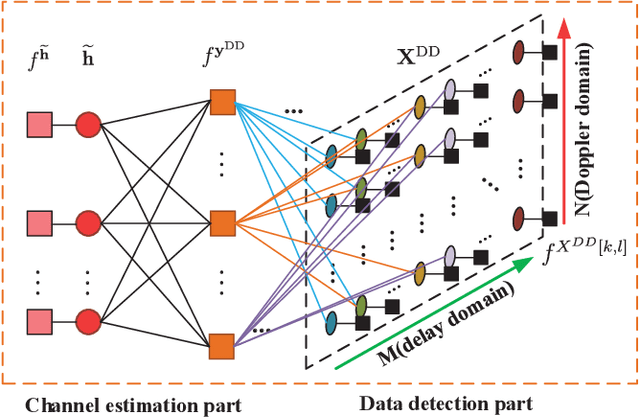
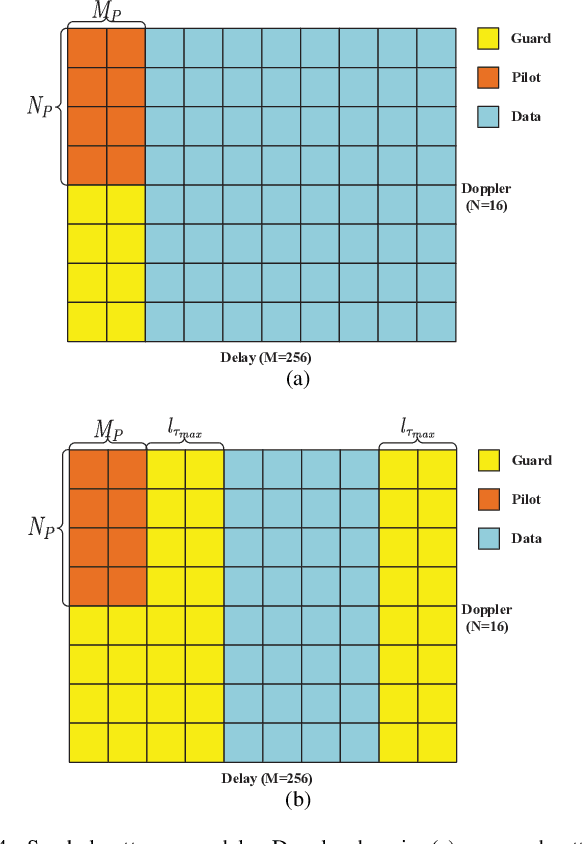
For high mobility communication scenario, the recently emerged orthogonal time frequency space (OTFS) modulation introduces a new delay-Doppler domain signal space, and can provide better communication performance than traditional orthogonal frequency division multiplexing system. This article focuses on the joint channel estimation and data detection (JCEDD) for hybrid reconfigurable intelligent surface (HRIS) aided millimeter wave (mmWave) OTFS systems. Firstly, a new transmission structure is designed. Within the pilot durations of the designed structure, partial HRIS elements are alternatively activated. The time domain channel model is then exhibited. Secondly, the received signal model for both the HRIS over time domain and the base station over delay-Doppler domain are studied. Thirdly, by utilizing channel parameters acquired at the HRIS, an HRIS beamforming design strategy is proposed. For the OTFS transmission, we propose a JCEDD scheme over delay-Doppler domain. In this scheme, message passing (MP) algorithm is designed to simultaneously obtain the equivalent channel gain and the data symbols. On the other hand, the channel parameters, i.e., the Doppler shift, the channel sparsity, and the channel variance, are updated through expectation-maximization (EM) algorithm. By iteratively executing the MP and EM algorithm, both the channel and the unknown data symbols can be accurately acquired. Finally, simulation results are provided to validate the effectiveness of our proposed JCEDD scheme.
Social-Inverse: Inverse Decision-making of Social Contagion Management with Task Migrations
Sep 21, 2022
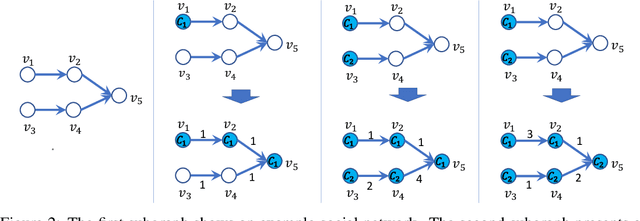
Considering two decision-making tasks $A$ and $B$, each of which wishes to compute an effective \textit{decision} $Y$ for a given \textit{query} $X$, {can we solve task $B$ by using query-decision pairs $(X, Y)$ of $A$ without knowing the latent decision-making model?} Such problems, called \textit{inverse decision-making with task migrations}, are of interest in that the complex and stochastic nature of real-world applications often prevents the agent from completely knowing the underlying system. In this paper, we introduce such a new problem with formal formulations and present a generic framework for addressing decision-making tasks in social contagion management. On the theory side, we present a generalization analysis for justifying the learning performance of our framework. In empirical studies, we perform a sanity check and compare the presented method with other possible learning-based and graph-based methods. We have acquired promising experimental results, confirming for the first time that it is possible to solve one decision-making task by using the solutions associated with another one.
Assessment of cognitive characteristics in intelligent systems and predictive ability
Sep 16, 2022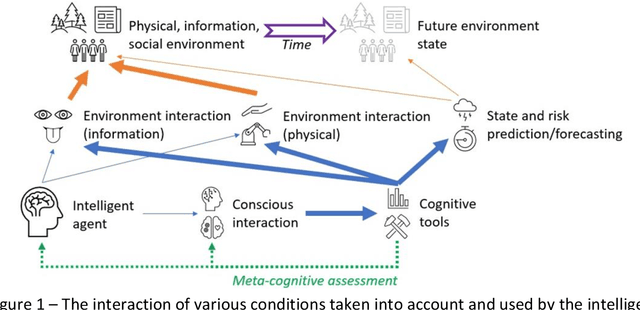
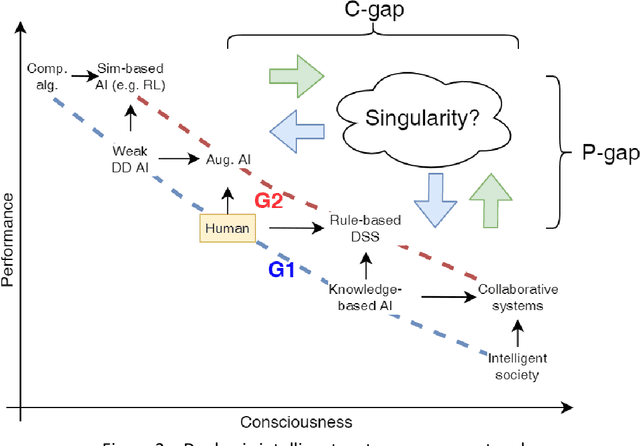
The article proposes a universal dual-axis intelligent systems assessment scale. The scale considers the properties of intelligent systems within the environmental context, which develops over time. In contrast to the frequent consideration of the 'mind' of artificial intelligent systems on a scale from 'weak' to 'strong', we highlight the modulating influences of anticipatory ability on their 'brute force'. In addition, the complexity, the 'weight' of the cognitive task and the ability to critically assess it beforehand determine the actual set of cognitive tools, the use of which provides the best result in these conditions. In fact, the presence of 'common sense' options is what connects the ability to solve a problem with the correct use of such an ability itself. The degree of 'correctness' and 'adequacy' is determined by the combination of a suitable solution with the temporal characteristics of the event, phenomenon, object or subject under study.
Graph-Based Active Machine Learning Method for Diverse and Novel Antimicrobial Peptides Generation and Selection
Sep 18, 2022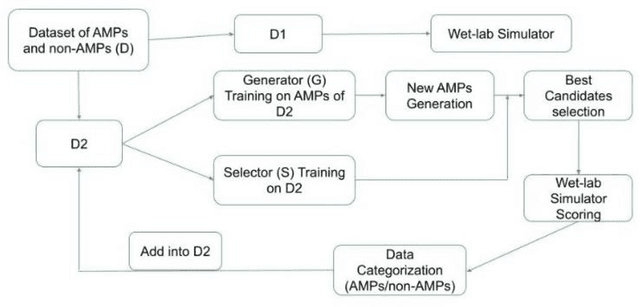

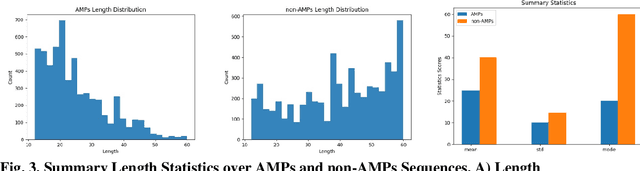
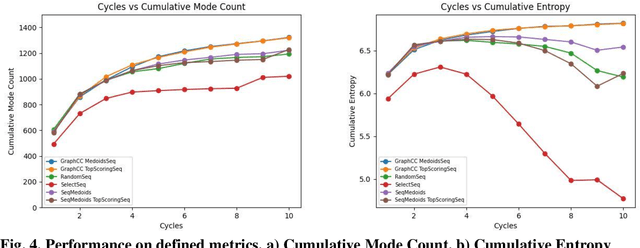
As antibiotic-resistant bacterial strains are rapidly spreading worldwide, infections caused by these strains are emerging as a global crisis causing the death of millions of people every year. Antimicrobial Peptides (AMPs) are one of the candidates to tackle this problem because of their potential diversity, and ability to favorably modulate the host immune response. However, large-scale screening of new AMP candidates is expensive, time-consuming, and now affordable in developing countries, which need the treatments the most. In this work, we propose a novel active machine learning-based framework that statistically minimizes the number of wet-lab experiments needed to design new AMPs, while ensuring a high diversity and novelty of generated AMPs sequences, in multi-rounds of wet-lab AMP screening settings. Combining recurrent neural network models and a graph-based filter (GraphCC), our proposed approach delivers novel and diverse candidates and demonstrates better performances according to our defined metrics.
Predicting Performances of Mutual Funds using Deep Learning and Ensemble Techniques
Sep 18, 2022
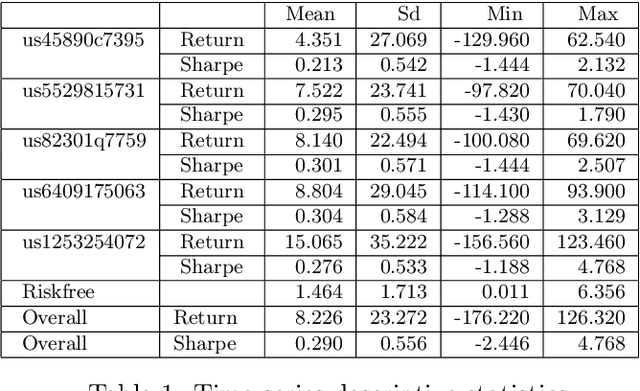
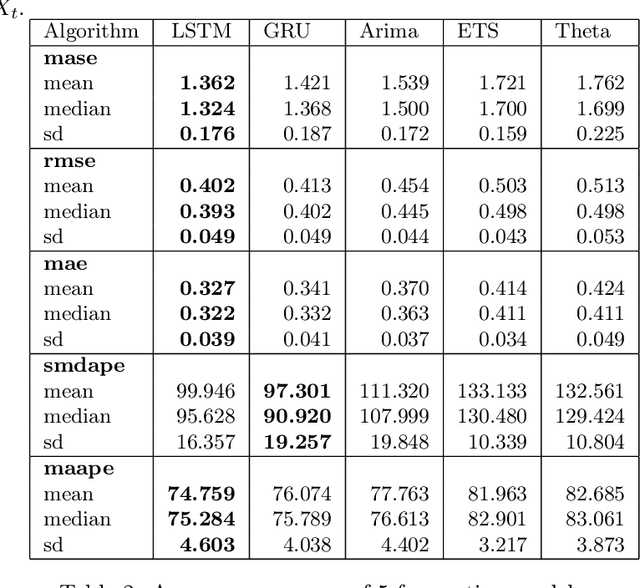
Predicting fund performance is beneficial to both investors and fund managers, and yet is a challenging task. In this paper, we have tested whether deep learning models can predict fund performance more accurately than traditional statistical techniques. Fund performance is typically evaluated by the Sharpe ratio, which represents the risk-adjusted performance to ensure meaningful comparability across funds. We calculated the annualised Sharpe ratios based on the monthly returns time series data for more than 600 open-end mutual funds investing in listed large-cap equities in the United States. We find that long short-term memory (LSTM) and gated recurrent units (GRUs) deep learning methods, both trained with modern Bayesian optimization, provide higher accuracy in forecasting funds' Sharpe ratios than traditional statistical ones. An ensemble method, which combines forecasts from LSTM and GRUs, achieves the best performance of all models. There is evidence to say that deep learning and ensembling offer promising solutions in addressing the challenge of fund performance forecasting.
TranAD: Deep Transformer Networks for Anomaly Detection in Multivariate Time Series Data
Jan 18, 2022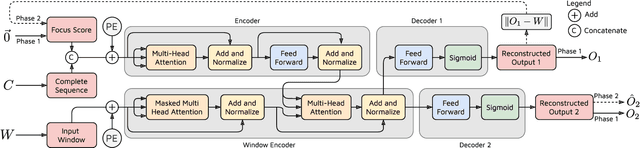
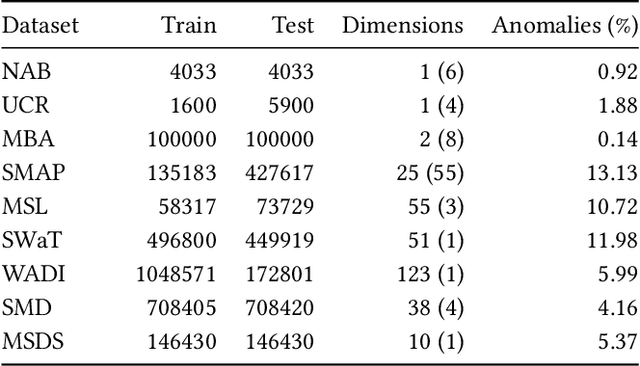
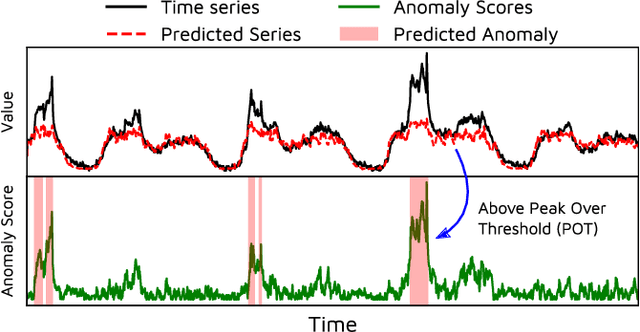
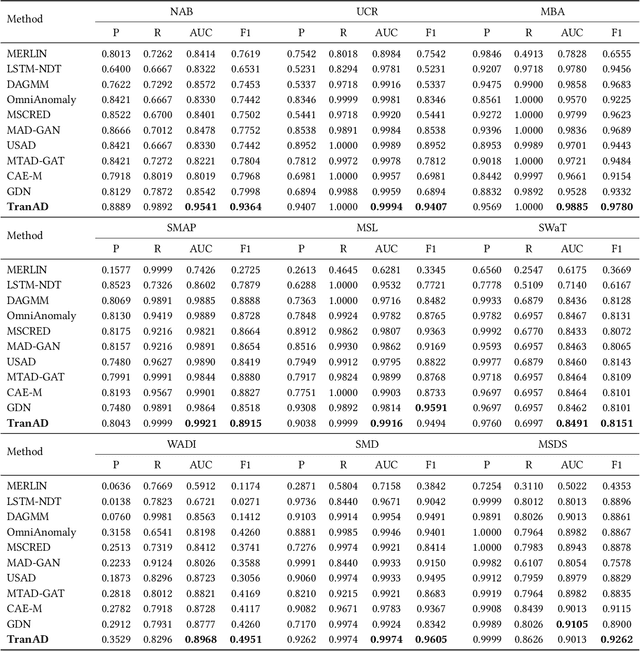
Efficient anomaly detection and diagnosis in multivariate time-series data is of great importance for modern industrial applications. However, building a system that is able to quickly and accurately pinpoint anomalous observations is a challenging problem. This is due to the lack of anomaly labels, high data volatility and the demands of ultra-low inference times in modern applications. Despite the recent developments of deep learning approaches for anomaly detection, only a few of them can address all of these challenges. In this paper, we propose TranAD, a deep transformer network based anomaly detection and diagnosis model which uses attention-based sequence encoders to swiftly perform inference with the knowledge of the broader temporal trends in the data. TranAD uses focus score-based self-conditioning to enable robust multi-modal feature extraction and adversarial training to gain stability. Additionally, model-agnostic meta learning (MAML) allows us to train the model using limited data. Extensive empirical studies on six publicly available datasets demonstrate that TranAD can outperform state-of-the-art baseline methods in detection and diagnosis performance with data and time-efficient training. Specifically, TranAD increases F1 scores by up to 17%, reducing training times by up to 99% compared to the baselines.
On the Transferability of Adversarial Examples between Encrypted Models
Sep 07, 2022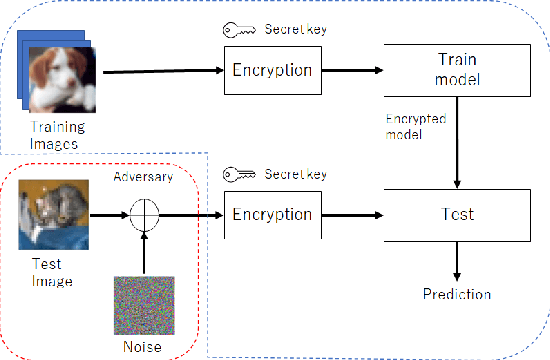


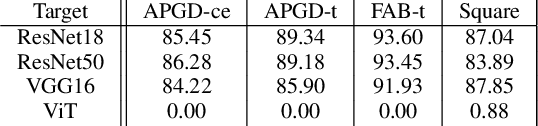
Deep neural networks (DNNs) are well known to be vulnerable to adversarial examples (AEs). In addition, AEs have adversarial transferability, namely, AEs generated for a source model fool other (target) models. In this paper, we investigate the transferability of models encrypted for adversarially robust defense for the first time. To objectively verify the property of transferability, the robustness of models is evaluated by using a benchmark attack method, called AutoAttack. In an image-classification experiment, the use of encrypted models is confirmed not only to be robust against AEs but to also reduce the influence of AEs in terms of the transferability of models.
A Two-stream Convolutional Network for Musculoskeletal and Neurological Disorders Prediction
Aug 18, 2022
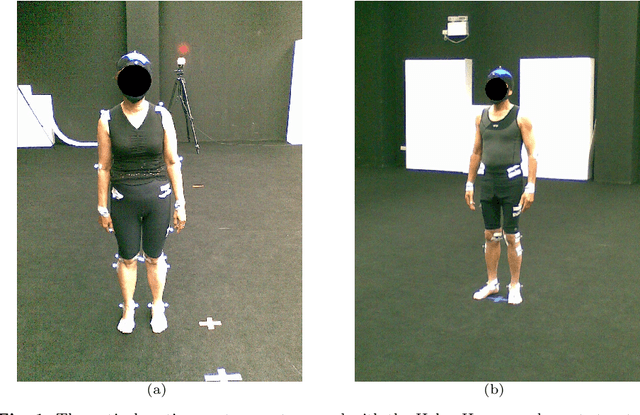
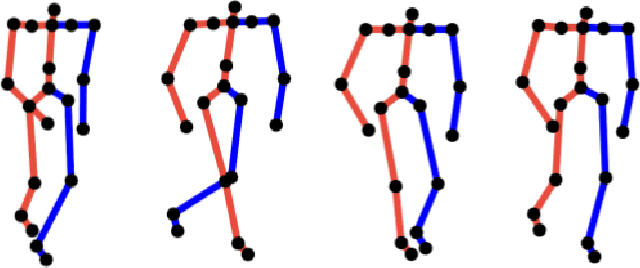

Musculoskeletal and neurological disorders are the most common causes of walking problems among older people, and they often lead to diminished quality of life. Analyzing walking motion data manually requires trained professionals and the evaluations may not always be objective. To facilitate early diagnosis, recent deep learning-based methods have shown promising results for automated analysis, which can discover patterns that have not been found in traditional machine learning methods. We observe that existing work mostly applies deep learning on individual joint features such as the time series of joint positions. Due to the challenge of discovering inter-joint features such as the distance between feet (i.e. the stride width) from generally smaller-scale medical datasets, these methods usually perform sub-optimally. As a result, we propose a solution that explicitly takes both individual joint features and inter-joint features as input, relieving the system from the need of discovering more complicated features from small data. Due to the distinctive nature of the two types of features, we introduce a two-stream framework, with one stream learning from the time series of joint position and the other from the time series of relative joint displacement. We further develop a mid-layer fusion module to combine the discovered patterns in these two streams for diagnosis, which results in a complementary representation of the data for better prediction performance. We validate our system with a benchmark dataset of 3D skeleton motion that involves 45 patients with musculoskeletal and neurological disorders, and achieve a prediction accuracy of 95.56%, outperforming state-of-the-art methods.