 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessment of cognitive characteristics in intelligent systems and predictive ability
Sep 16, 2022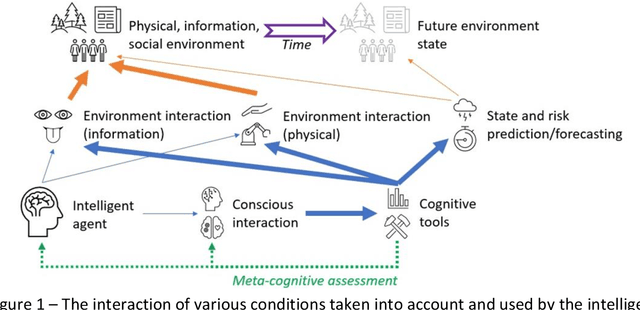
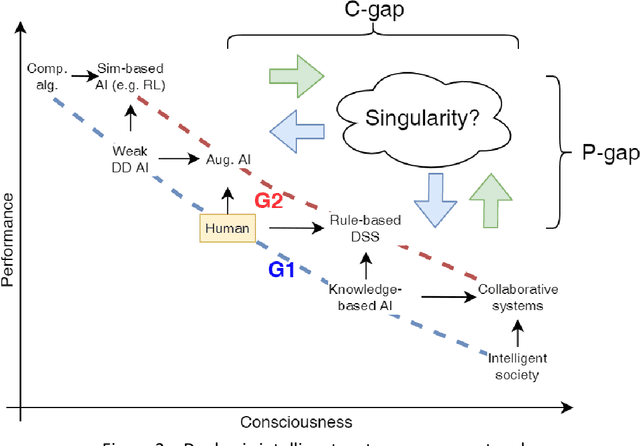
The article proposes a universal dual-axis intelligent systems assessment scale. The scale considers the properties of intelligent systems within the environmental context, which develops over time. In contrast to the frequent consideration of the 'mind' of artificial intelligent systems on a scale from 'weak' to 'strong', we highlight the modulating influences of anticipatory ability on their 'brute force'. In addition, the complexity, the 'weight' of the cognitive task and the ability to critically assess it beforehand determine the actual set of cognitive tools, the use of which provides the best result in these conditions. In fact, the presence of 'common sense' options is what connects the ability to solve a problem with the correct use of such an ability itself. The degree of 'correctness' and 'adequacy' is determined by the combination of a suitable solution with the temporal characteristics of the event, phenomenon, object or subject under study.
Extending Process Discovery with Model Complexity Optimization and Cyclic States Identification: Application to Healthcare Processes
Jun 10, 2022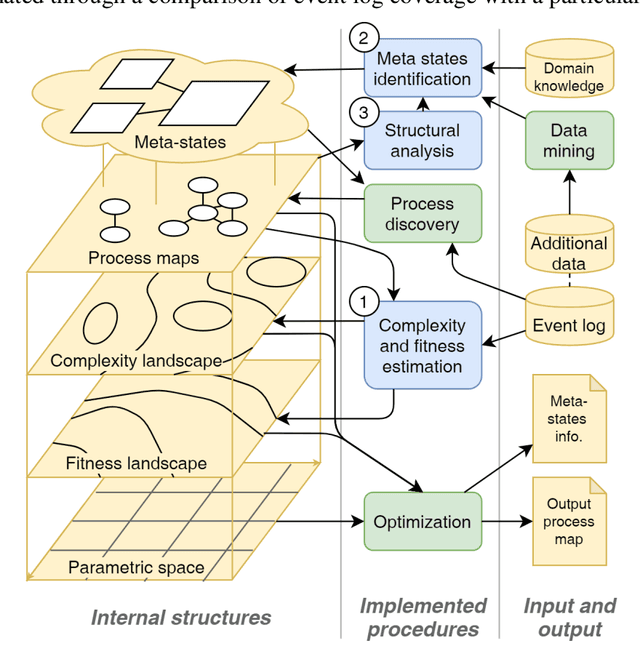
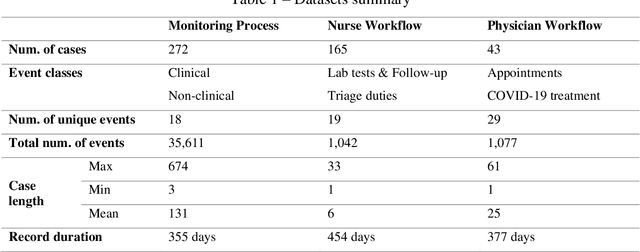
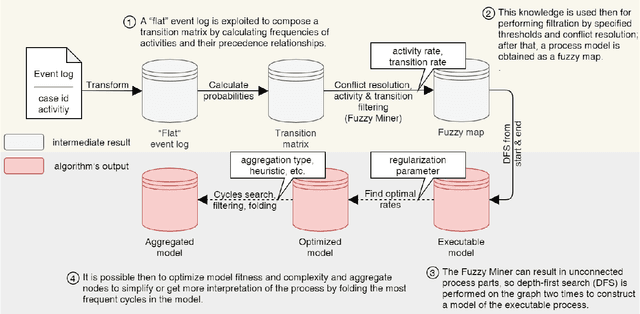
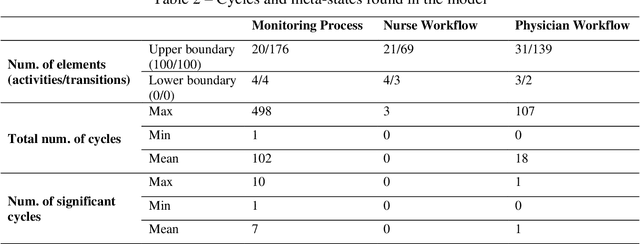
Within Process mining, discovery techniques had made it possible to construct business process models automatically from event logs. However, results often do not achieve the balance between model complexity and its fitting accuracy, so there is a need for manual model adjusting. The paper presents an approach to process mining providing semi-automatic support to model optimization based on the combined assessment of the model complexity and fitness. To balance between the two ingredients, a model simplification approach is proposed, which essentially abstracts the raw model at the desired granularity. Additionally, we introduce a concept of meta-states, a cycle collapsing in the model, which can potentially simplify the model and interpret it. We aim to demonstrate the capabilities of the technological solution using three datasets from different applications in the healthcare domain. They are remote monitoring process for patients with arterial hypertension and workflows of healthcare workers during the COVID-19 pandemic. A case study also investigates the use of various complexity measures and different ways of solution application providing insights on better practices in improving interpretability and complexity/fitness balance in process models.
Why Machine Learning Integrated Patient Flow Simulation?
Apr 16, 2021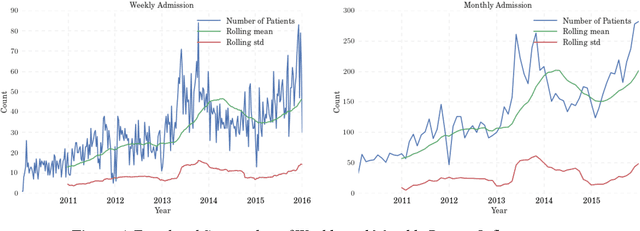
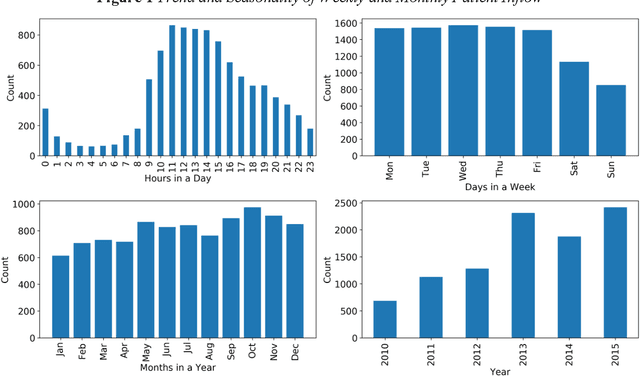
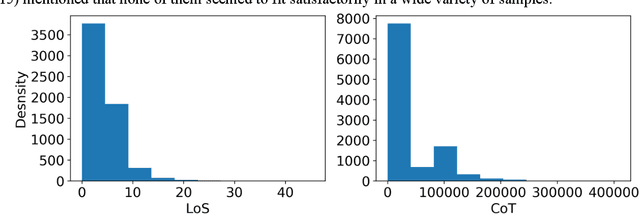
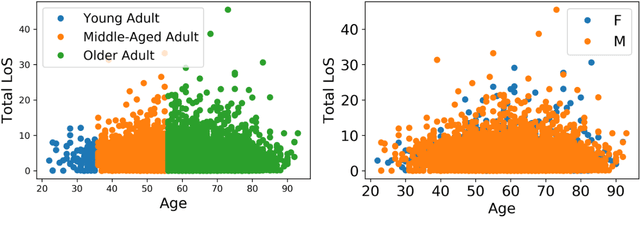
Patient flow analysis can be studied from a clinical and or operational perspective using simulation. Traditional statistical methods such as stochastic distribution methods have been used to construct patient flow simulation submodels such as patient inflow, Length of Stay (LoS), Cost of Treatment (CoT) and Clinical Pathway (CP) models. However, patient inflow demonstrates seasonality, trend and variation over time. LoS, CoT and CP are significantly determined by attributes of patients and clinical and laboratory test results. For this reason, patient flow simulation models constructed using traditional statistical methods are criticized for ignoring heterogeneity and their contribution to personalized and value based healthcare. On the other hand, machine learning methods have proven to be efficient to study and predict admission rate, LoS, CoT, and CP. This paper, hence, describes why coupling machine learning with patient flow simulation is important and proposes a conceptual architecture that shows how to integrate machine learning with patient flow simulation.
* Proceedings of the Operational Research Society Simulation Workshop 2021 (SW21)
Three-stage intelligent support of clinical decision making for higher trust, validity, and explainability
Jul 25, 2020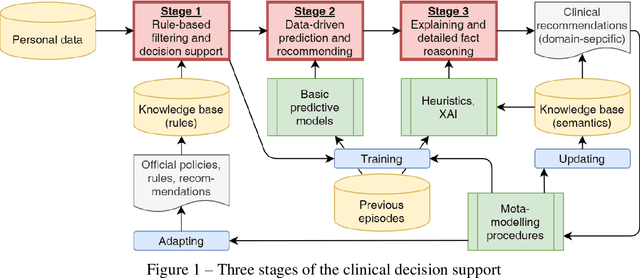
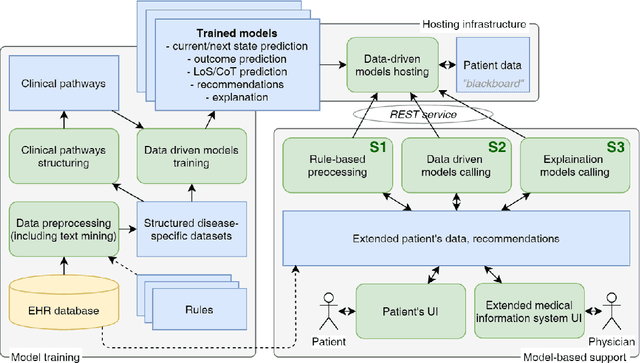
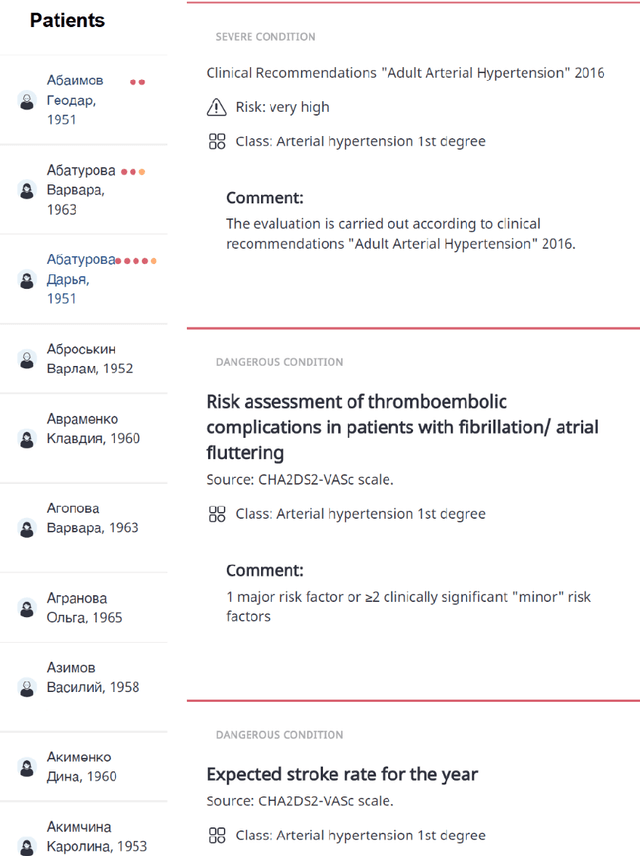

The paper presents the approach for the building of consistent and applicable clinical decision support systems (CDSS) using a data-driven predictive model aimed to resolve a problem of low applicability and scalability of CDSS in real-world applications. The approach is based on the three-stage application of domain-specific and data-driven supportive procedures to integrate into clinical business-processes with higher trust and explainability of the prediction results and recommendations. Within the considered three stages, the regulatory policy, data-driven modes, and interpretation procedures are integrated to enable natural domain-specific interaction with decision-makers with sequential narrowing of the intelligent decision support focus. The proposed methodology enables a higher level of automation, scalability, and semantic interpretability of CDSS. The approach was implemented in software solutions and tested within a case study in T2DM prediction, enabling to improve known clinical scales (such as FINDRISK), keeping the problem-specific reasoning interface similar to existing applications. Such inheritance, together with the three-stages approach, provide higher compatibility of the solution and leads to trust, valid, and explainable application of data-driven solution in real-world cases.
Surrogate-assisted performance tuning of knowledge discovery algorithms: application to clinical pathway evolutionary modeling
Apr 02, 2020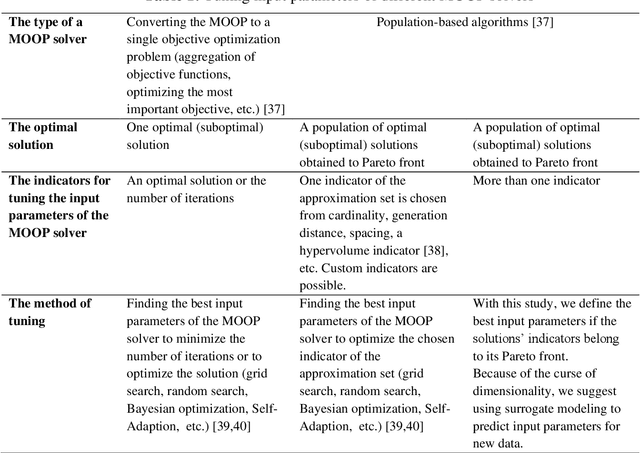
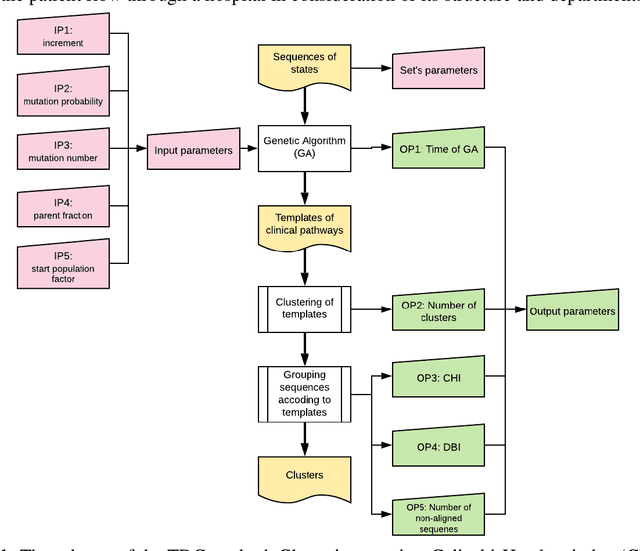
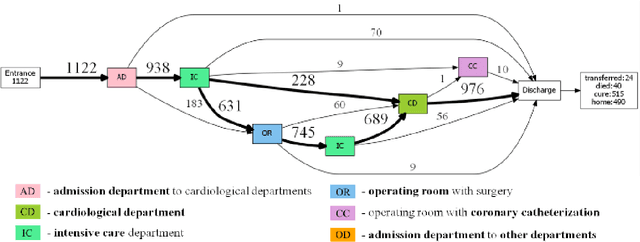
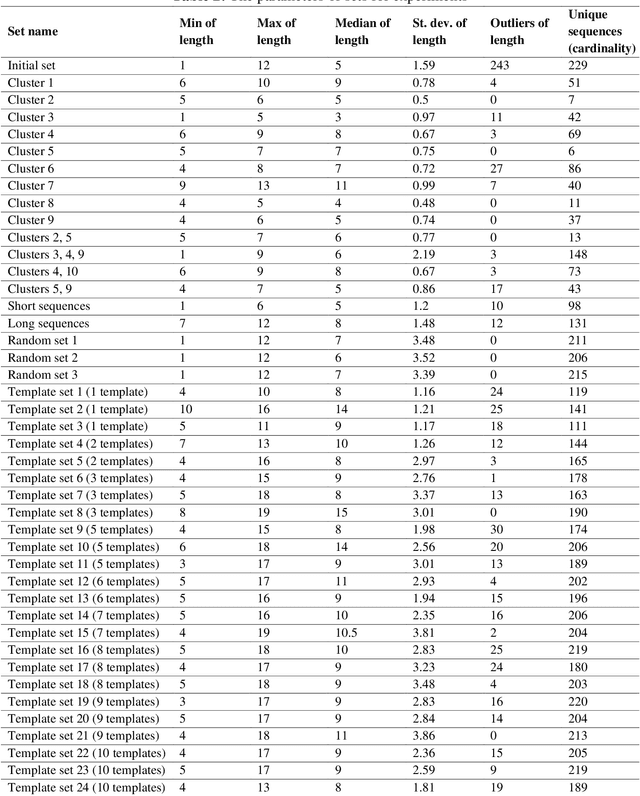
The paper proposes an approach for surrogate-assisted tuning of knowledge discovery algorithms. The approach is based on the prediction of both the quality and performance of the target algorithm. The prediction is furtherly used as objectives for the optimization and tuning of the algorithm. The approach is investigated using clinical pathways (CP) discovery problem resolved using the evolutionary-based clustering of electronic health records (EHR). Target algorithm and the proposed approach were applied to the discovery of CPs for Acute Coronary Syndrome patients in 3434 EHRs of patients treated in Almazov National Medical Research Center (Saint Petersburg, Russia). The study investigates the possible acquisition of interpretable clusters of typical CPs within a single disease. It shows how the approach could be used to improve complex data-driven analytical knowledge discovery algorithms. The study of the results includes the feature importance of the best surrogate model and discover how the parameters of input data influence the predictions.
Analysis of Computational Science Papers from ICCS 2001-2016 using Topic Modeling and Graph Theory
Apr 18, 2017
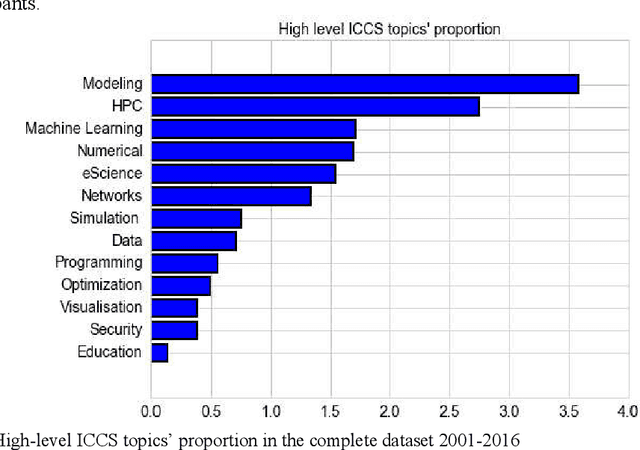

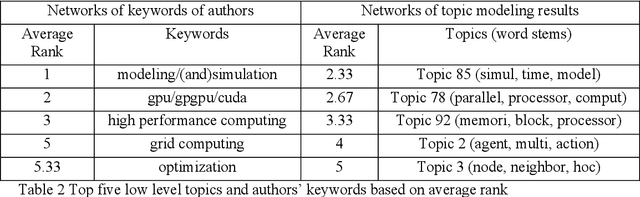
This paper presents results of topic modeling and network models of topics using the International Conference on Computational Science corpus, which contains domain-specific (computational science) papers over sixteen years (a total of 5695 papers). We discuss topical structures of International Conference on Computational Science, how these topics evolve over time in response to the topicality of various problems, technologies and methods, and how all these topics relate to one another. This analysis illustrates multidisciplinary research and collaborations among scientific communities, by constructing static and dynamic networks from the topic modeling results and the keywords of authors. The results of this study give insights about the past and future trends of core discussion topics in computational science. We used the Non-negative Matrix Factorization topic modeling algorithm to discover topics and labeled and grouped results hierarchically.