 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
RASR: Risk-Averse Soft-Robust MDPs with EVaR and Entropic Risk
Sep 14, 2022
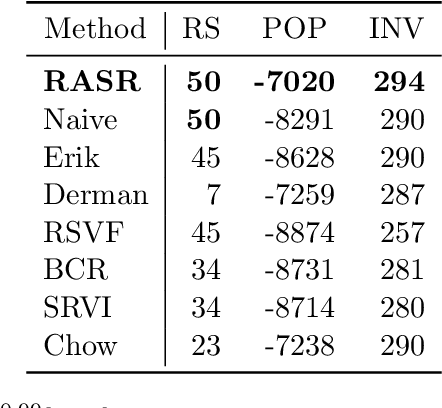

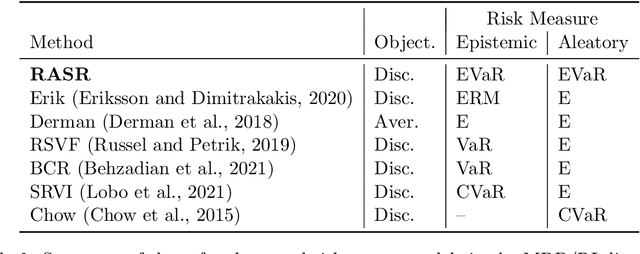
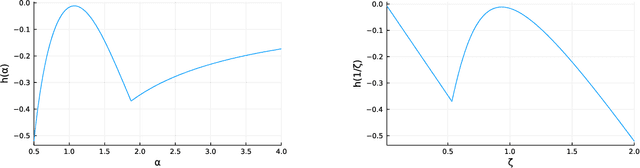
Prior work on safe Reinforcement Learning (RL) has studied risk-aversion to randomness in dynamics (aleatory) and to model uncertainty (epistemic) in isolation. We propose and analyze a new framework to jointly model the risk associated with epistemic and aleatory uncertainties in finite-horizon and discounted infinite-horizon MDPs. We call this framework that combines Risk-Averse and Soft-Robust methods RASR. We show that when the risk-aversion is defined using either EVaR or the entropic risk, the optimal policy in RASR can be computed efficiently using a new dynamic program formulation with a time-dependent risk level. As a result, the optimal risk-averse policies are deterministic but time-dependent, even in the infinite-horizon discounted setting. We also show that particular RASR objectives reduce to risk-averse RL with mean posterior transition probabilities. Our empirical results show that our new algorithms consistently mitigate uncertainty as measured by EVaR and other standard risk measures.
Learning Large-Time-Step Molecular Dynamics with Graph Neural Networks
Dec 21, 2021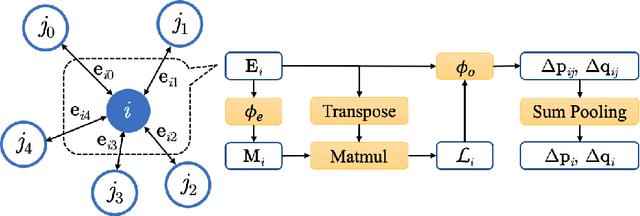

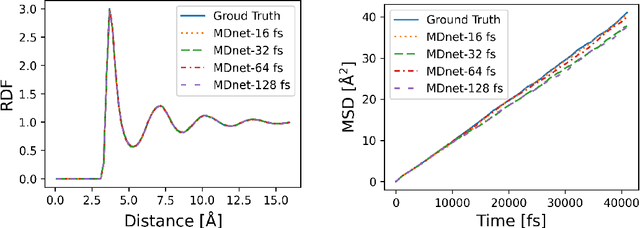
Molecular dynamics (MD) simulation predicts the trajectory of atoms by solving Newton's equation of motion with a numeric integrator. Due to physical constraints, the time step of the integrator need to be small to maintain sufficient precision. This limits the efficiency of simulation. To this end, we introduce a graph neural network (GNN) based model, MDNet, to predict the evolution of coordinates and momentum with large time steps. In addition, MDNet can easily scale to a larger system, due to its linear complexity with respect to the system size. We demonstrate the performance of MDNet on a 4000-atom system with large time steps, and show that MDNet can predict good equilibrium and transport properties, well aligned with standard MD simulations.
Deep Idempotent Network for Efficient Single Image Blind Deblurring
Oct 18, 2022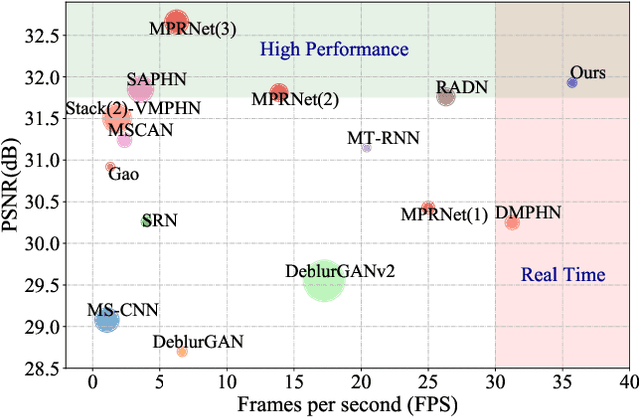


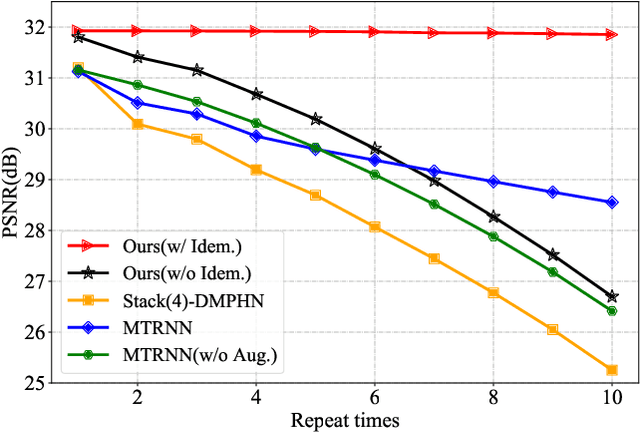
Single image blind deblurring is highly ill-posed as neither the latent sharp image nor the blur kernel is known. Even though considerable progress has been made, several major difficulties remain for blind deblurring, including the trade-off between high-performance deblurring and real-time processing. Besides, we observe that current single image blind deblurring networks cannot further improve or stabilize the performance but significantly degrades the performance when re-deblurring is repeatedly applied. This implies the limitation of these networks in modeling an ideal deblurring process. In this work, we make two contributions to tackle the above difficulties: (1) We introduce the idempotent constraint into the deblurring framework and present a deep idempotent network to achieve improved blind non-uniform deblurring performance with stable re-deblurring. (2) We propose a simple yet efficient deblurring network with lightweight encoder-decoder units and a recurrent structure that can deblur images in a progressive residual fashion. Extensive experiments on synthetic and realistic datasets prove the superiority of our proposed framework. Remarkably, our proposed network is nearly 6.5X smaller and 6.4X faster than the state-of-the-art while achieving comparable high performance.
No Pairs Left Behind: Improving Metric Learning with Regularized Triplet Objective
Oct 18, 2022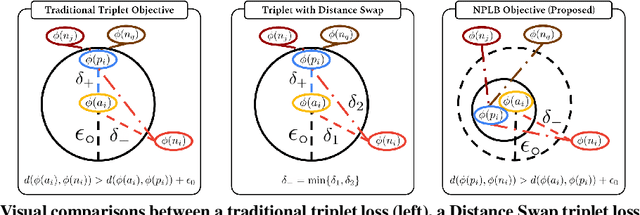

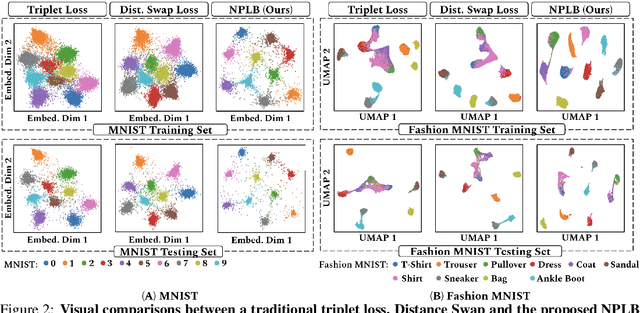
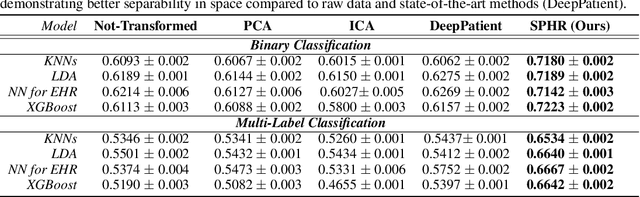
We propose a novel formulation of the triplet objective function that improves metric learning without additional sample mining or overhead costs. Our approach aims to explicitly regularize the distance between the positive and negative samples in a triplet with respect to the anchor-negative distance. As an initial validation, we show that our method (called No Pairs Left Behind [NPLB]) improves upon the traditional and current state-of-the-art triplet objective formulations on standard benchmark datasets. To show the effectiveness and potentials of NPLB on real-world complex data, we evaluate our approach on a large-scale healthcare dataset (UK Biobank), demonstrating that the embeddings learned by our model significantly outperform all other current representations on tested downstream tasks. Additionally, we provide a new model-agnostic single-time health risk definition that, when used in tandem with the learned representations, achieves the most accurate prediction of subjects' future health complications. Our results indicate that NPLB is a simple, yet effective framework for improving existing deep metric learning models, showcasing the potential implications of metric learning in more complex applications, especially in the biological and healthcare domains.
Deep Spatial and Tonal Data Optimisation for Homogeneous Diffusion Inpainting
Aug 30, 2022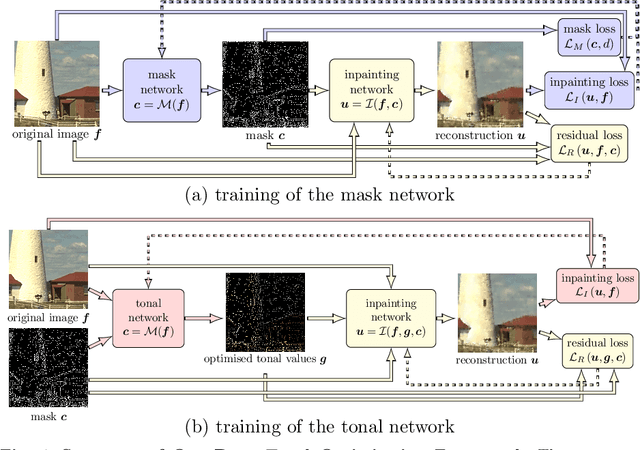
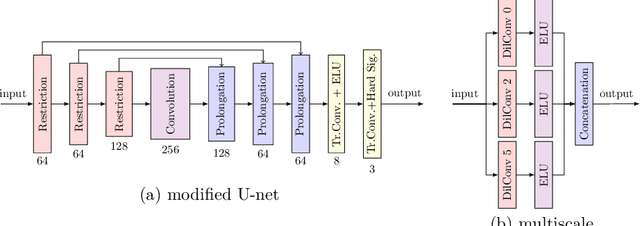
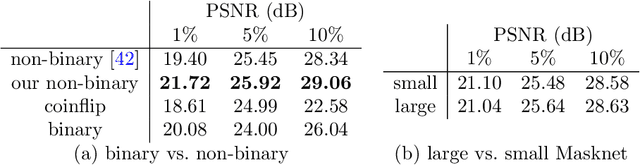
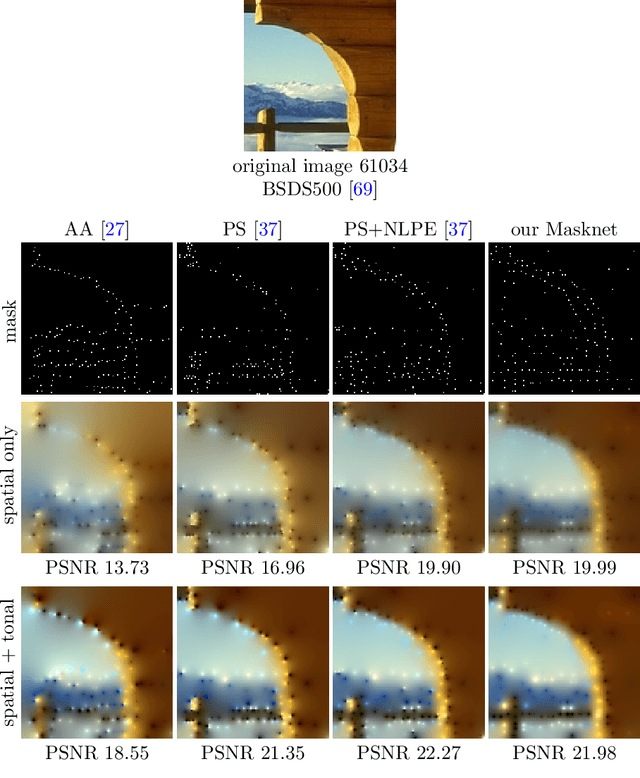
Diffusion-based inpainting can reconstruct missing image areas with high quality from sparse data, provided that their location and their values are well optimised. This is particularly useful for applications such as image compression, where the original image is known. Selecting the known data constitutes a challenging optimisation problem, that has so far been only investigated with model-based approaches. So far, these methods require a choice between either high quality or high speed since qualitatively convincing algorithms rely on many time-consuming inpaintings. We propose the first neural network architecture that allows fast optimisation of pixel positions and pixel values for homogeneous diffusion inpainting. During training, we combine two optimisation networks with a neural network-based surrogate solver for diffusion inpainting. This novel concept allows us to perform backpropagation based on inpainting results that approximate the solution of the inpainting equation. Without the need for a single inpainting during test time, our deep optimisation combines the high quality of model-based approaches with real-time performance.
Breaking the Convergence Barrier: Optimization via Fixed-Time Convergent Flows
Dec 02, 2021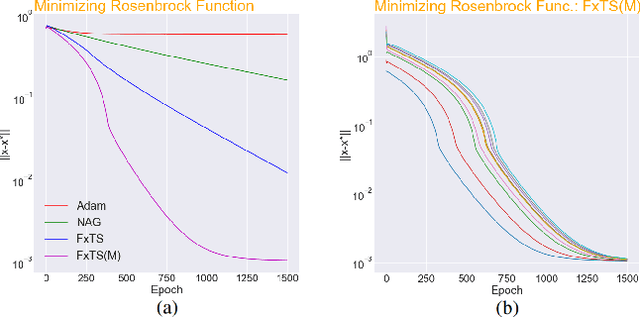
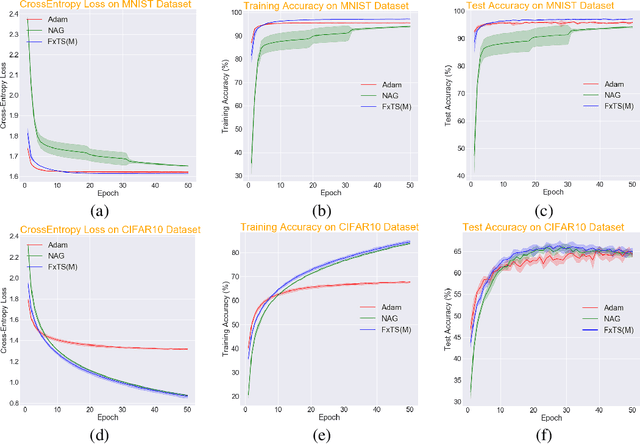
Accelerated gradient methods are the cornerstones of large-scale, data-driven optimization problems that arise naturally in machine learning and other fields concerning data analysis. We introduce a gradient-based optimization framework for achieving acceleration, based on the recently introduced notion of fixed-time stability of dynamical systems. The method presents itself as a generalization of simple gradient-based methods suitably scaled to achieve convergence to the optimizer in a fixed-time, independent of the initialization. We achieve this by first leveraging a continuous-time framework for designing fixed-time stable dynamical systems, and later providing a consistent discretization strategy, such that the equivalent discrete-time algorithm tracks the optimizer in a practically fixed number of iterations. We also provide a theoretical analysis of the convergence behavior of the proposed gradient flows, and their robustness to additive disturbances for a range of functions obeying strong convexity, strict convexity, and possibly nonconvexity but satisfying the Polyak-{\L}ojasiewicz inequality. We also show that the regret bound on the convergence rate is constant by virtue of the fixed-time convergence. The hyperparameters have intuitive interpretations and can be tuned to fit the requirements on the desired convergence rates. We validate the accelerated convergence properties of the proposed schemes on a range of numerical examples against the state-of-the-art optimization algorithms. Our work provides insights on developing novel optimization algorithms via discretization of continuous-time flows.
Finite Sample Guarantees for Distributed Online Parameter Estimation with Communication Costs
Sep 12, 2022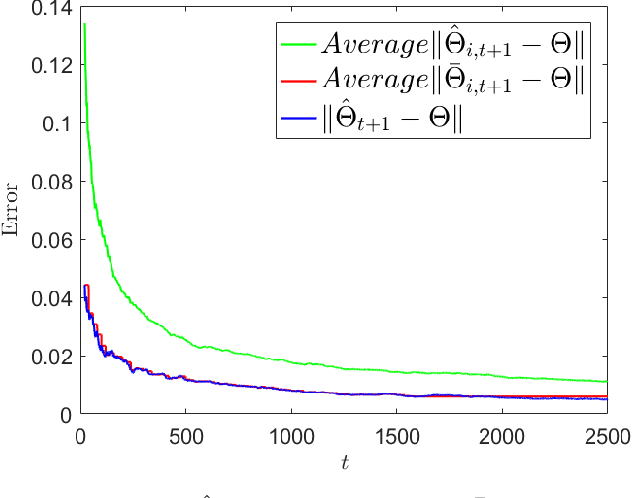
We study the problem of estimating an unknown parameter in a distributed and online manner. Existing work on distributed online learning typically either focuses on asymptotic analysis, or provides bounds on regret. However, these results may not directly translate into bounds on the error of the learned model after a finite number of time-steps. In this paper, we propose a distributed online estimation algorithm which enables each agent in a network to improve its estimation accuracy by communicating with neighbors. We provide non-asymptotic bounds on the estimation error, leveraging the statistical properties of the underlying model. Our analysis demonstrates a trade-off between estimation error and communication costs. Further, our analysis allows us to determine a time at which the communication can be stopped (due to the costs associated with communications), while meeting a desired estimation accuracy. We also provide a numerical example to validate our results.
Test time Adaptation through Perturbation Robustness
Oct 19, 2021
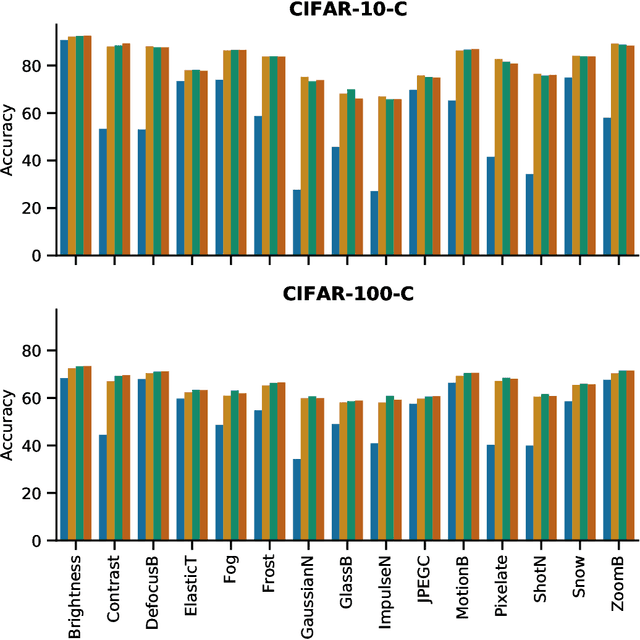

Data samples generated by several real world processes are dynamic in nature \textit{i.e.}, their characteristics vary with time. Thus it is not possible to train and tackle all possible distributional shifts between training and inference, using the host of transfer learning methods in literature. In this paper, we tackle this problem of adapting to domain shift at inference time \textit{i.e.}, we do not change the training process, but quickly adapt the model at test-time to handle any domain shift. For this, we propose to enforce consistency of predictions of data sampled in the vicinity of test sample on the image manifold. On a host of test scenarios like dealing with corruptions (CIFAR-10-C and CIFAR-100-C), and domain adaptation (VisDA-C), our method is at par or significantly outperforms previous methods.
Runtime-Assured, Real-Time Neural Control of Microgrids
Feb 20, 2022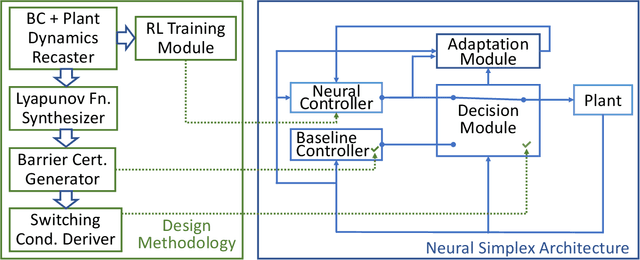
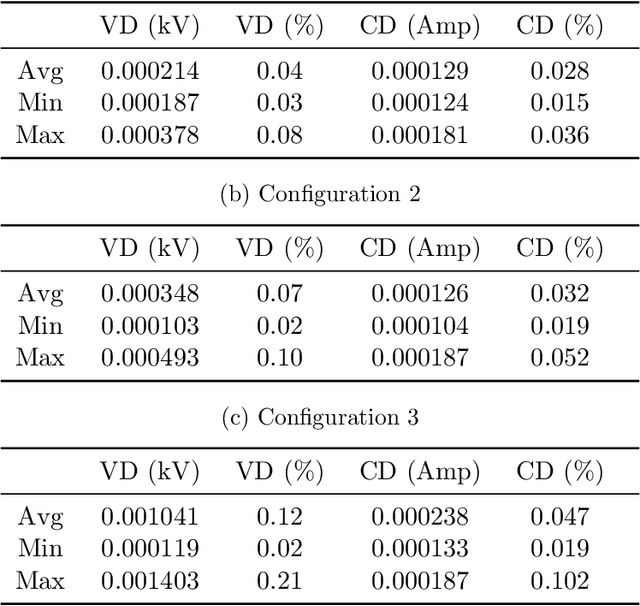
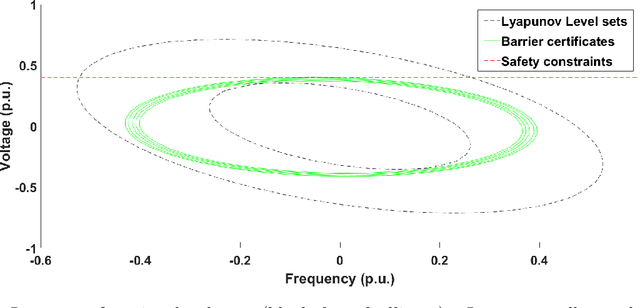
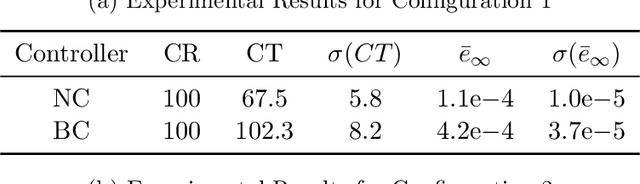
We present SimpleMG, a new, provably correct design methodology for runtime assurance of microgrids (MGs) with neural controllers. Our approach is centered around the Neural Simplex Architecture, which in turn is based on Sha et al.'s Simplex Control Architecture. Reinforcement Learning is used to synthesize high-performance neural controllers for MGs. Barrier Certificates are used to establish SimpleMG's runtime-assurance guarantees. We present a novel method to derive the condition for switching from the unverified neural controller to the verified-safe baseline controller, and we prove that the method is correct. We conduct an extensive experimental evaluation of SimpleMG using RTDS, a high-fidelity, real-time simulation environment for power systems, on a realistic model of a microgrid comprising three distributed energy resources (battery, photovoltaic, and diesel generator). Our experiments confirm that SimpleMG can be used to develop high-performance neural controllers for complex microgrids while assuring runtime safety, even in the presence of adversarial input attacks on the neural controller. Our experiments also demonstrate the benefits of online retraining of the neural controller while the baseline controller is in control
Bayesian Regression Approach for Building and Stacking Predictive Models in Time Series Analytics
Jan 06, 2022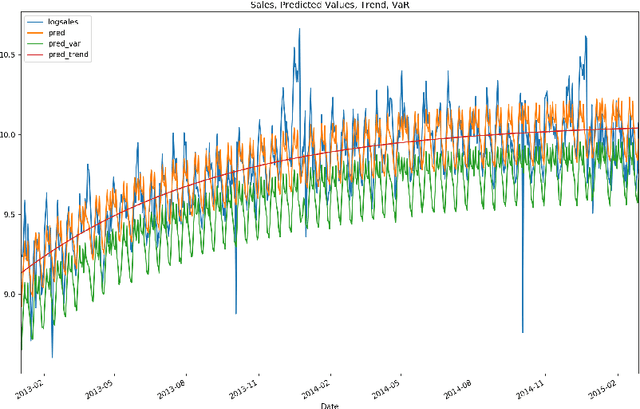
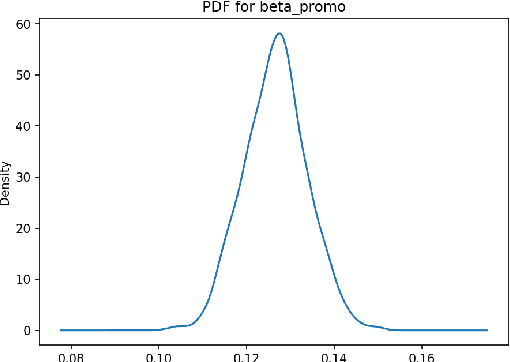
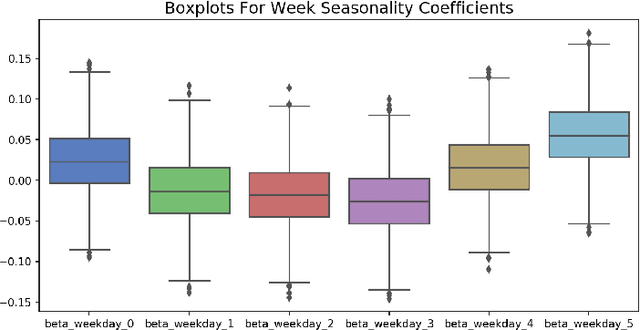
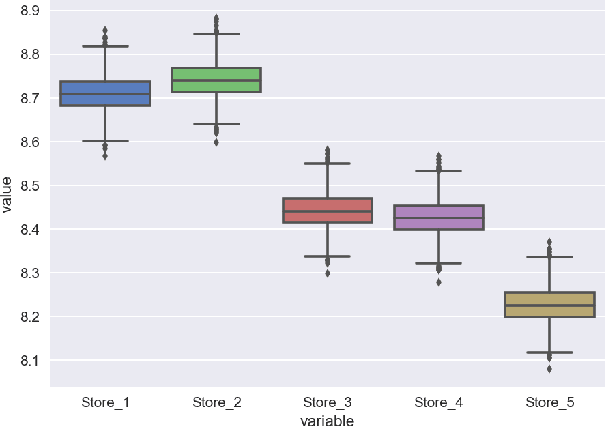
The paper describes the use of Bayesian regression for building time series models and stacking different predictive models for time series. Using Bayesian regression for time series modeling with nonlinear trend was analyzed. This approach makes it possible to estimate an uncertainty of time series prediction and calculate value at risk characteristics. A hierarchical model for time series using Bayesian regression has been considered. In this approach, one set of parameters is the same for all data samples, other parameters can be different for different groups of data samples. Such an approach allows using this model in the case of short historical data for specified time series, e.g. in the case of new stores or new products in the sales prediction problem. In the study of predictive models stacking, the models ARIMA, Neural Network, Random Forest, Extra Tree were used for the prediction on the first level of model ensemble. On the second level, time series predictions of these models on the validation set were used for stacking by Bayesian regression. This approach gives distributions for regression coefficients of these models. It makes it possible to estimate the uncertainty contributed by each model to stacking result. The information about these distributions allows us to select an optimal set of stacking models, taking into account the domain knowledge. The probabilistic approach for stacking predictive models allows us to make risk assessment for the predictions that are important in a decision-making process.