 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Approaches to Qualitative and Quantitative News Analytics on NATO Unity
May 08, 2025



The paper considers the use of GPT models with retrieval-augmented generation (RAG) for qualitative and quantitative analytics on NATO sentiments, NATO unity and NATO Article 5 trust opinion scores in different web sources: news sites found via Google Search API, Youtube videos with comments, and Reddit discussions. A RAG approach using GPT-4.1 model was applied to analyse news where NATO related topics were discussed. Two levels of RAG analytics were used: on the first level, the GPT model generates qualitative news summaries and quantitative opinion scores using zero-shot prompts; on the second level, the GPT model generates the summary of news summaries. Quantitative news opinion scores generated by the GPT model were analysed using Bayesian regression to get trend lines. The distributions found for the regression parameters make it possible to analyse an uncertainty in specified news opinion score trends. Obtained results show a downward trend for analysed scores of opinion related to NATO unity. This approach does not aim to conduct real political analysis; rather, it consider AI based approaches which can be used for further analytics as a part of a complex analytical approach. The obtained results demonstrate that the use of GPT models for news analysis can give informative qualitative and quantitative analytics, providing important insights. The dynamic model based on neural ordinary differential equations was considered for modelling public opinions. This approach makes it possible to analyse different scenarios for evolving public opinions.
Using GPT Models for Qualitative and Quantitative News Analytics in the 2024 US Presidental Election Process
Oct 21, 2024



The paper considers an approach of using Google Search API and GPT-4o model for qualitative and quantitative analyses of news through retrieval-augmented generation (RAG). This approach was applied to analyze news about the 2024 US presidential election process. Different news sources for different time periods have been analyzed. Quantitative scores generated by GPT model have been analyzed using Bayesian regression to derive trend lines. The distributions found for the regression parameters allow for the analysis of uncertainty in the election process. The obtained results demonstrate that using the GPT models for news analysis, one can get informative analytics and provide key insights that can be applied in further analyses of election processes.
Financial News Analytics Using Fine-Tuned Llama 2 GPT Model
Sep 11, 2023

The paper considers the possibility to fine-tune Llama 2 GPT large language model (LLM) for the multitask analysis of financial news. For fine-tuning, the PEFT/LoRA based approach was used. In the study, the model was fine-tuned for the following tasks: analysing a text from financial market perspectives, highlighting main points of a text, summarizing a text and extracting named entities with appropriate sentiments. The obtained results show that the fine-tuned Llama 2 model can perform a multitask financial news analysis with a specified structure of response, part of response can be a structured text and another part of data can have JSON format for further processing. Extracted sentiments for named entities can be considered as predictive features in supervised machine learning models with quantitative target variables.
Analysis of Disinformation and Fake News Detection Using Fine-Tuned Large Language Model
Sep 09, 2023The paper considers the possibility of fine-tuning Llama 2 large language model (LLM) for the disinformation analysis and fake news detection. For fine-tuning, the PEFT/LoRA based approach was used. In the study, the model was fine-tuned for the following tasks: analysing a text on revealing disinformation and propaganda narratives, fact checking, fake news detection, manipulation analytics, extracting named entities with their sentiments. The obtained results show that the fine-tuned Llama 2 model can perform a deep analysis of texts and reveal complex styles and narratives. Extracted sentiments for named entities can be considered as predictive features in supervised machine learning models.
Analytics of Business Time Series Using Machine Learning and Bayesian Inference
Jun 02, 2022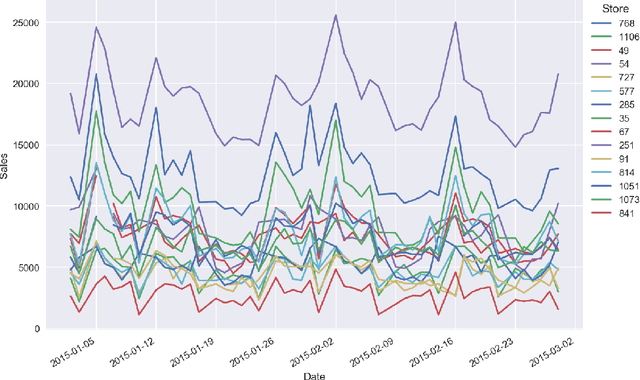
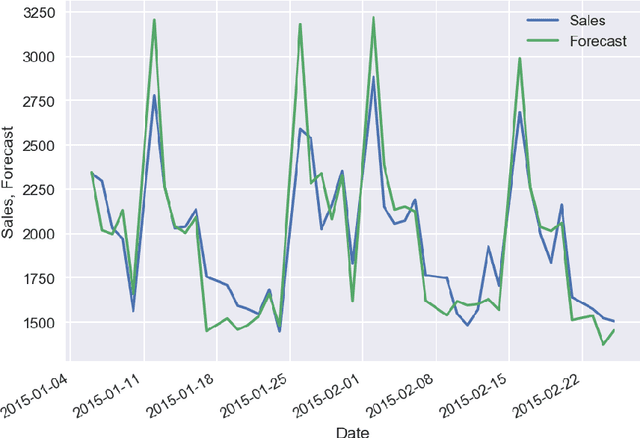
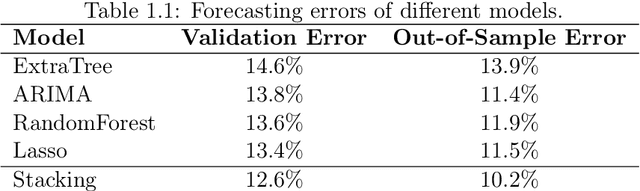
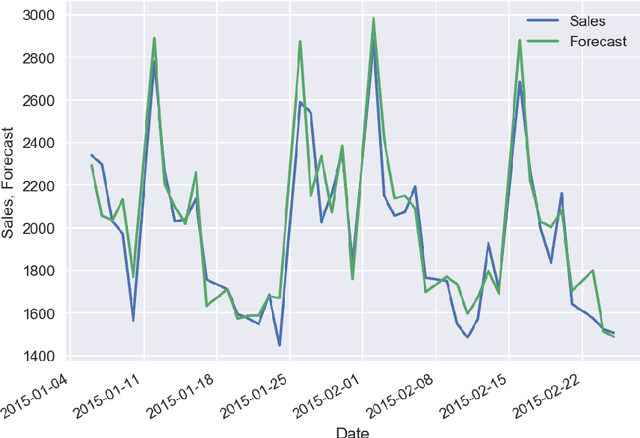
In the survey we consider the case studies on sales time series forecasting, the deep learning approach for forecasting non-stationary time series using time trend correction, dynamic price and supply optimization using Q-learning, Bitcoin price modeling, COVID-19 spread impact on stock market, using social networks signals in analytics. The use of machine learning and Bayesian inference in predictive analytics has been analyzed.
Forecasting of Non-Stationary Sales Time Series Using Deep Learning
May 23, 2022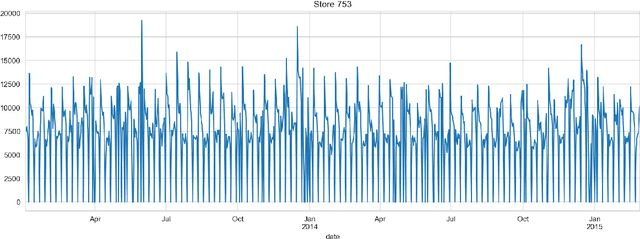
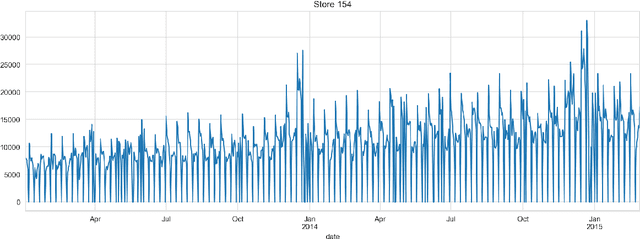
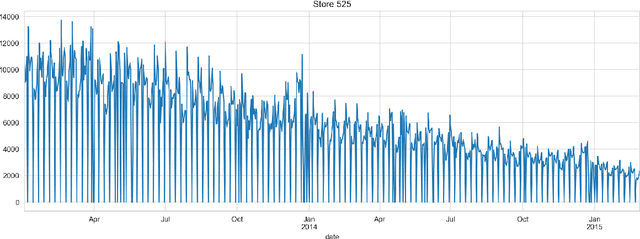
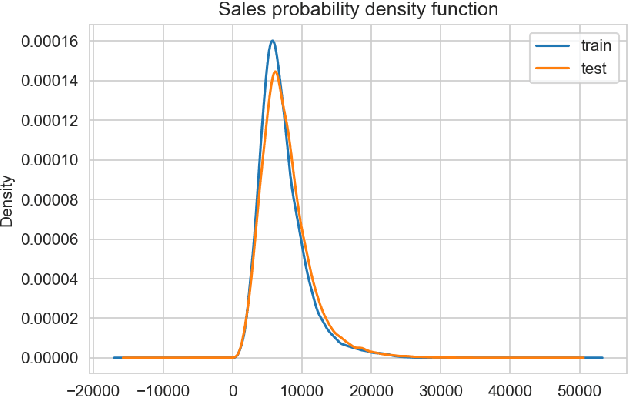
The paper describes the deep learning approach for forecasting non-stationary time series with using time trend correction in a neural network model. Along with the layers for predicting sales values, the neural network model includes a subnetwork block for the prediction weight for a time trend term which is added to a predicted sales value. The time trend term is considered as a product of the predicted weight value and normalized time value. The results show that the forecasting accuracy can be essentially improved for non-stationary sales with time trends using the trend correction block in the deep learning model.
Methods of Informational Trends Analytics and Fake News Detection on Twitter
Apr 11, 2022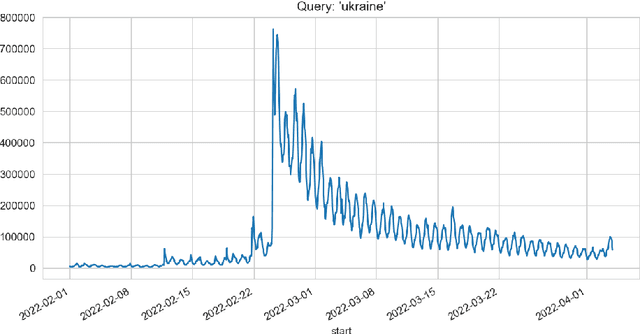
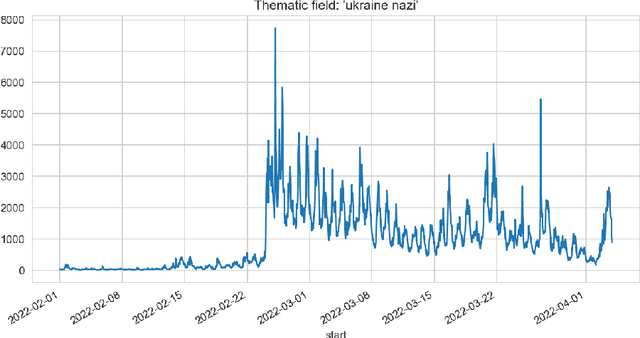
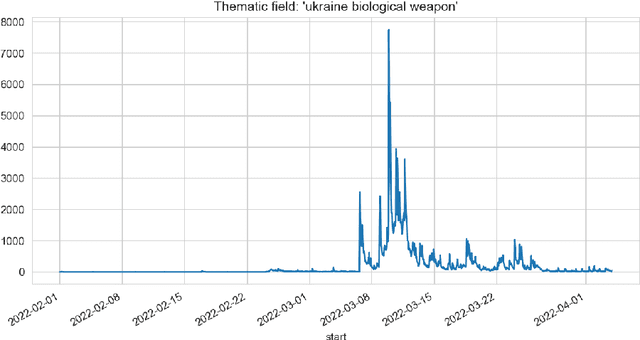
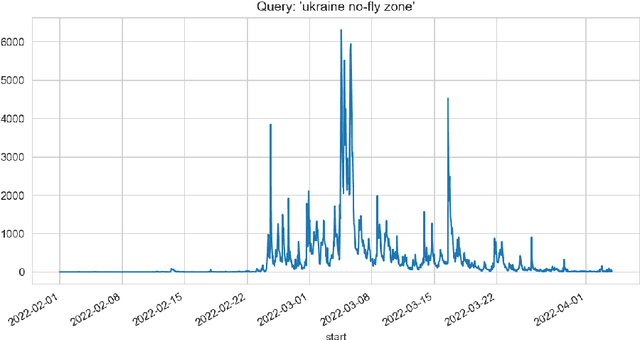
In the paper, different approaches for the analysis of news trends on Twitter has been considered. For the analysis and case study, informational trends on Twitter caused by Russian invasion of Ukraine in 2022 year have been studied. A deep learning approach for fake news detection has been analyzed. The use of the theory of frequent itemsets and association rules, graph theory for news trends analytics have been considered.
Bitcoin Price Predictive Modeling Using Expert Correction
Jan 06, 2022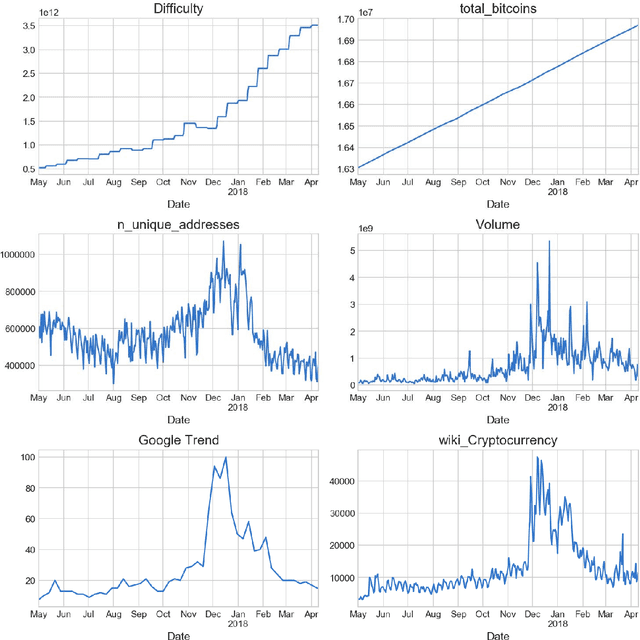
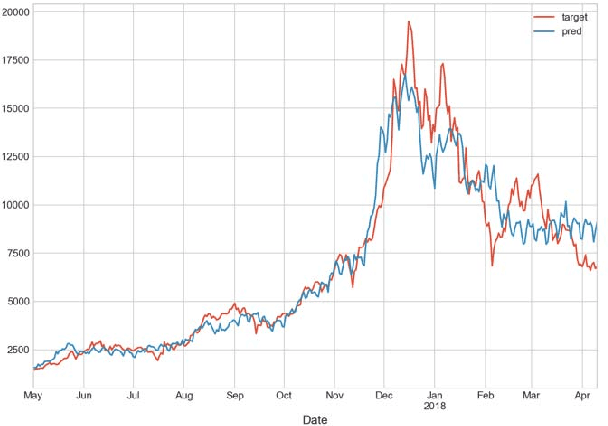
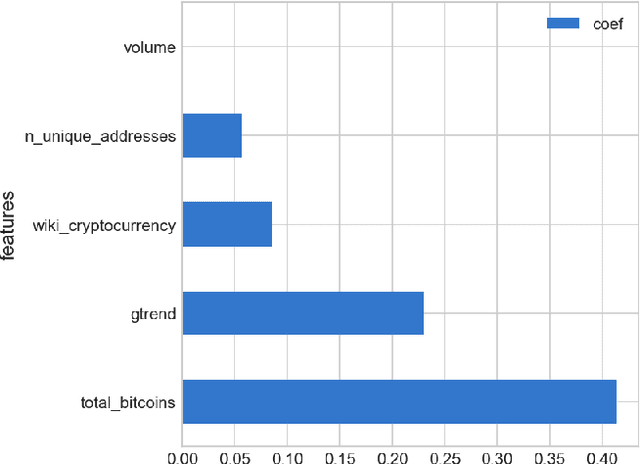
The paper studies the linear model for Bitcoin price which includes regression features based on Bitcoin currency statistics, mining processes, Google search trends, Wikipedia pages visits. The pattern of deviation of regression model prediction from real prices is simpler comparing to price time series. It is assumed that this pattern can be predicted by an experienced expert. In such a way, using the combination of the regression model and expert correction, one can receive better results than with either regression model or expert opinion only. It is shown that Bayesian approach makes it possible to utilize the probabilistic approach using distributions with fat tails and take into account the outliers in Bitcoin price time series.
Sales Time Series Analytics Using Deep Q-Learning
Jan 06, 2022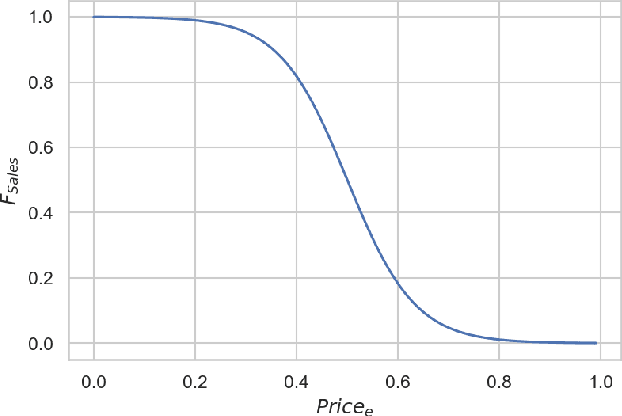
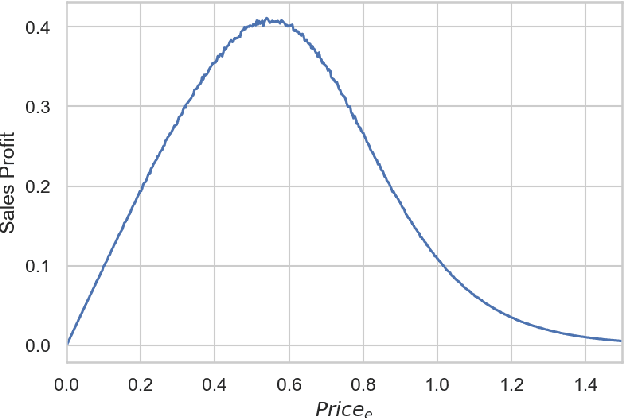
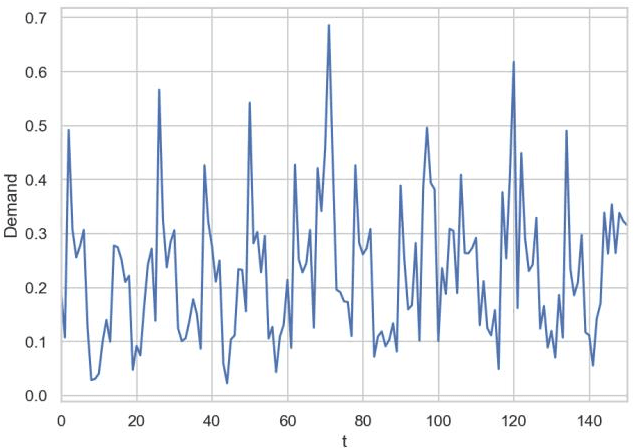
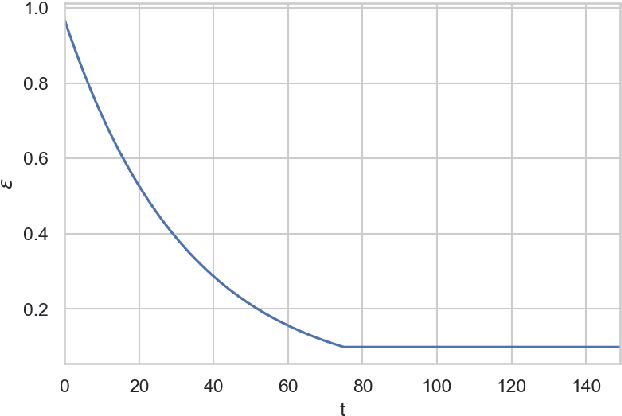
The article describes the use of deep Q-learning models in the problems of sales time series analytics. In contrast to supervised machine learning which is a kind of passive learning using historical data, Q-learning is a kind of active learning with goal to maximize a reward by optimal sequence of actions. Model free Q-learning approach for optimal pricing strategies and supply-demand problems was considered in the work. The main idea of the study is to show that using deep Q-learning approach in time series analytics, the sequence of actions can be optimized by maximizing the reward function when the environment for learning agent interaction can be modeled using the parametric model and in the case of using the model which is based on the historical data. In the pricing optimizing case study environment was modeled using sales dependence on extras price and randomly simulated demand. In the pricing optimizing case study, the environment was modeled using sales dependence on extra price and randomly simulated demand. In the supply-demand case study, it was proposed to use historical demand time series for environment modeling, agent states were represented by promo actions, previous demand values and weekly seasonality features. Obtained results show that using deep Q-learning, we can optimize the decision making process for price optimization and supply-demand problems. Environment modeling using parametric models and historical data can be used for the cold start of learning agent. On the next steps, after the cold start, the trained agent can be used in real business environment.
Forming Predictive Features of Tweets for Decision-Making Support
Jan 06, 2022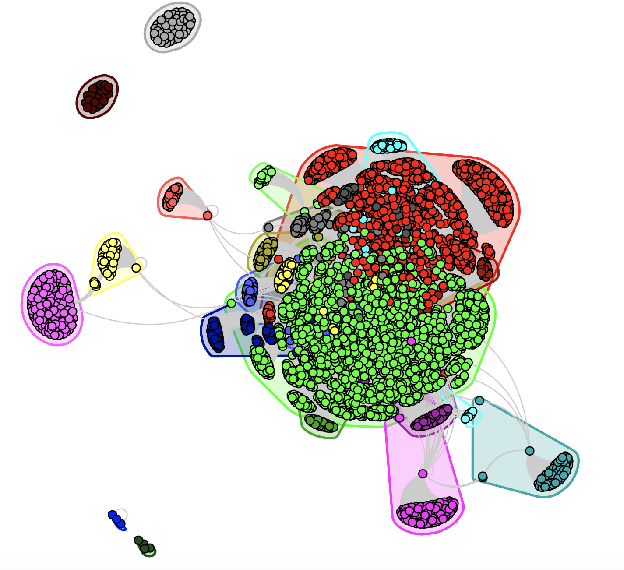
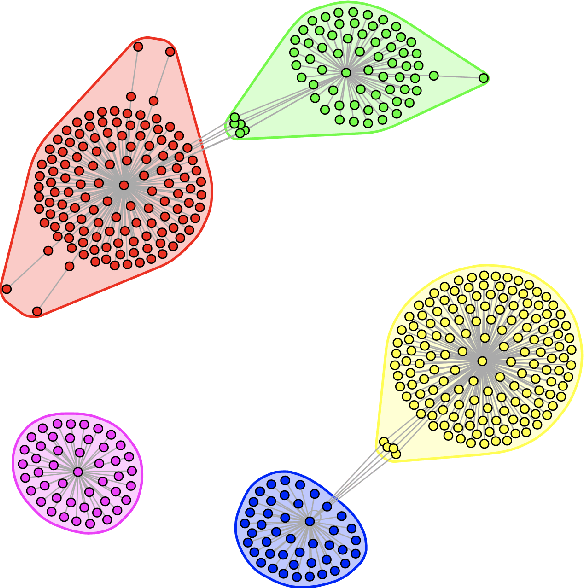
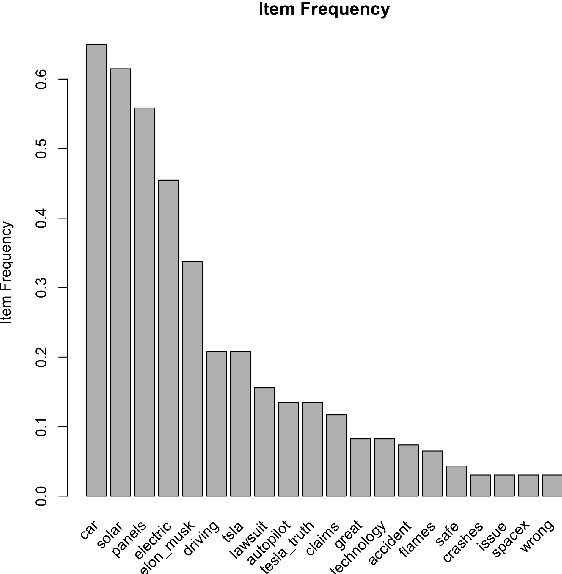
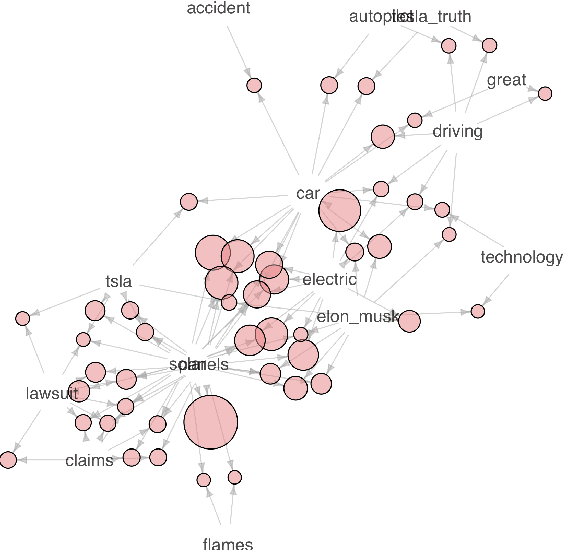
The article describes the approaches for forming different predictive features of tweet data sets and using them in the predictive analysis for decision-making support. The graph theory as well as frequent itemsets and association rules theory is used for forming and retrieving different features from these datasests. The use of these approaches makes it possible to reveal a semantic structure in tweets related to a specified entity. It is shown that quantitative characteristics of semantic frequent itemsets can be used in predictive regression models with specified target variables.