 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fine-Tuning Pre-trained Transformers into Decaying Fast Weights
Oct 09, 2022
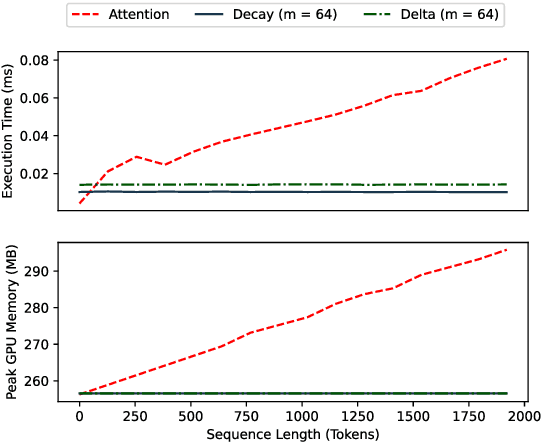

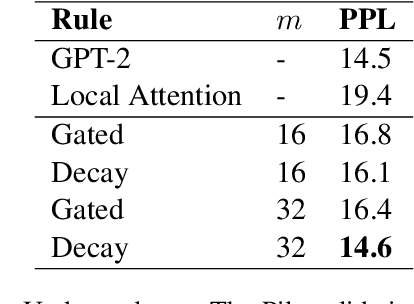
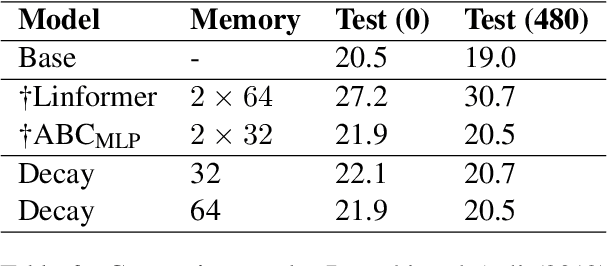
Autoregressive Transformers are strong language models but incur O(T) complexity during per-token generation due to the self-attention mechanism. Recent work proposes kernel-based methods to approximate causal self-attention by replacing it with recurrent formulations with various update rules and feature maps to achieve O(1) time and memory complexity. We explore these approaches and find that they are unnecessarily complex, and propose a simple alternative - decaying fast weights - that runs fast on GPU, outperforms prior methods, and retains 99% of attention's performance for GPT-2. We also show competitive performance on WikiText-103 against more complex attention substitutes.
Local Connection Reinforcement Learning Method for Efficient Control of Robotic Peg-in-Hole Assembly
Oct 24, 2022
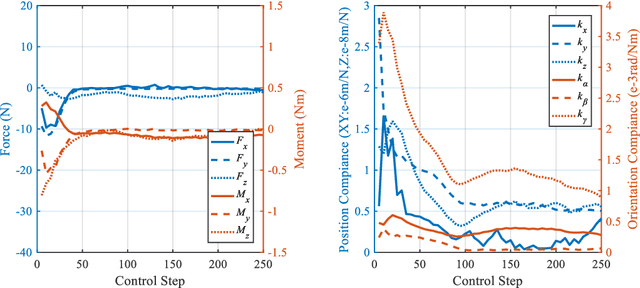
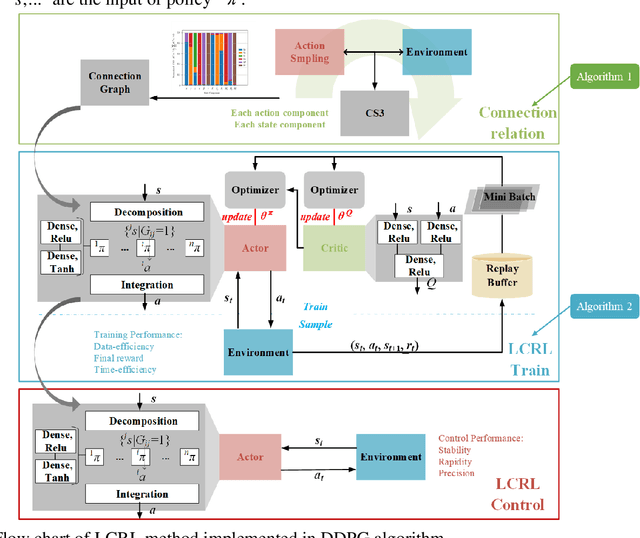
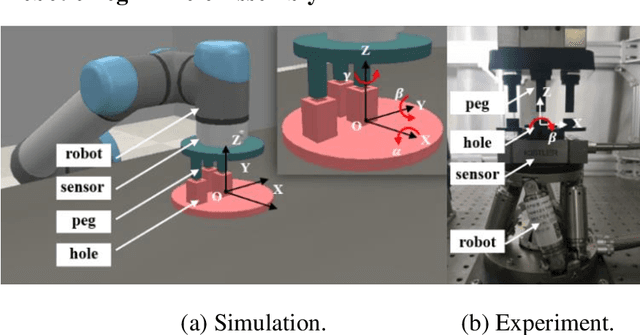
Traditional control methods of robotic peg-in-hole assembly rely on complex contact state analysis. Reinforcement learning (RL) is gradually becoming a preferred method of controlling robotic peg-in-hole assembly tasks. However, the training process of RL is quite time-consuming because RL methods are always globally connected, which means all state components are assumed to be the input of policies for all action components, thus increasing action space and state space to be explored. In this paper, we first define continuous space serialized Shapley value (CS3) and construct a connection graph to clarify the correlativity of action components on state components. Then we propose a local connection reinforcement learning (LCRL) method based on the connection graph, which eliminates the influence of irrelevant state components on the selection of action components. The simulation and experiment results demonstrate that the control strategy obtained through LCRL method improves the stability and rapidity of the control process. LCRL method will enhance the data-efficiency and increase the final reward of the training process.
Towards Out-of-Distribution Sequential Event Prediction: A Causal Treatment
Oct 24, 2022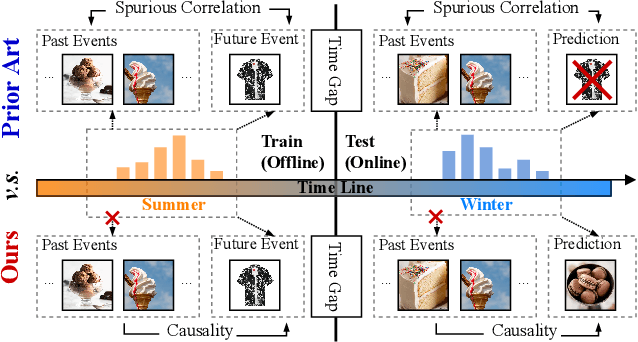
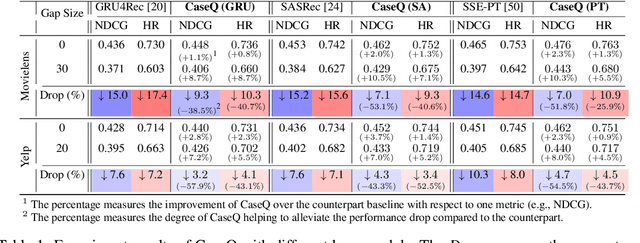
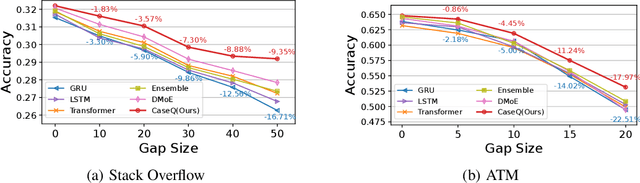
The goal of sequential event prediction is to estimate the next event based on a sequence of historical events, with applications to sequential recommendation, user behavior analysis and clinical treatment. In practice, the next-event prediction models are trained with sequential data collected at one time and need to generalize to newly arrived sequences in remote future, which requires models to handle temporal distribution shift from training to testing. In this paper, we first take a data-generating perspective to reveal a negative result that existing approaches with maximum likelihood estimation would fail for distribution shift due to the latent context confounder, i.e., the common cause for the historical events and the next event. Then we devise a new learning objective based on backdoor adjustment and further harness variational inference to make it tractable for sequence learning problems. On top of that, we propose a framework with hierarchical branching structures for learning context-specific representations. Comprehensive experiments on diverse tasks (e.g., sequential recommendation) demonstrate the effectiveness, applicability and scalability of our method with various off-the-shelf models as backbones.
Semantic Image Segmentation with Deep Learning for Vine Leaf Phenotyping
Oct 24, 2022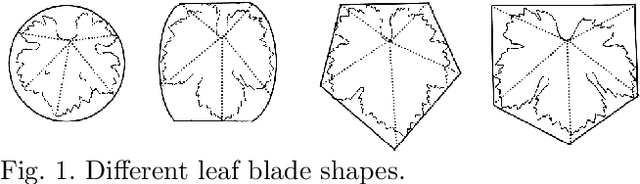
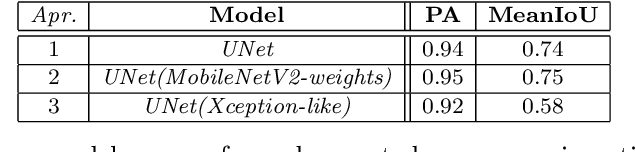
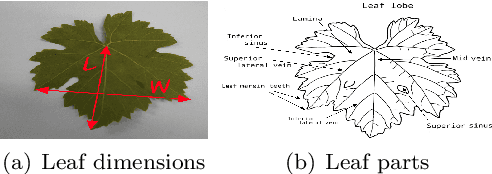
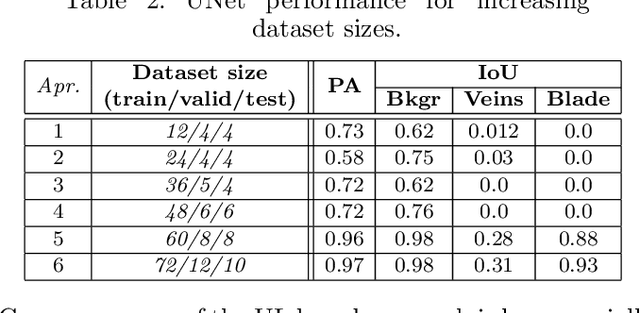
Plant phenotyping refers to a quantitative description of the plants properties, however in image-based phenotyping analysis, our focus is primarily on the plants anatomical, ontogenetical and physiological properties.This technique reinforced by the success of Deep Learning in the field of image based analysis is applicable to a wide range of research areas making high-throughput screens of plants possible, reducing the time and effort needed for phenotypic characterization.In this study, we use Deep Learning methods (supervised and unsupervised learning based approaches) to semantically segment grapevine leaves images in order to develop an automated object detection (through segmentation) system for leaf phenotyping which will yield information regarding their structure and function.In these directions we studied several deep learning approaches with promising results as well as we reported some future challenging tasks in the area of precision agriculture.Our work contributes to plant lifecycle monitoring through which dynamic traits such as growth and development can be captured and quantified, targeted intervention and selective application of agrochemicals and grapevine variety identification which are key prerequisites in sustainable agriculture.
Less is More: Simplifying Feature Extractors Prevents Overfitting for Neural Discourse Parsing Models
Oct 18, 2022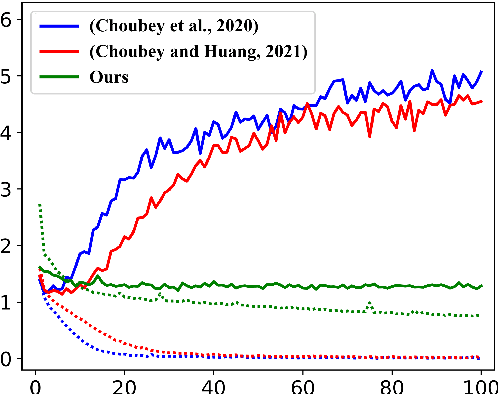
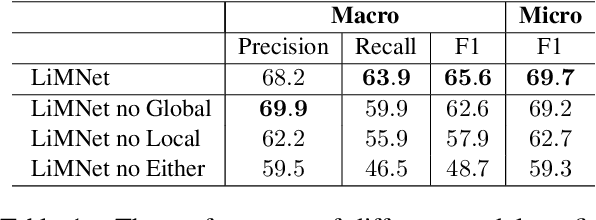
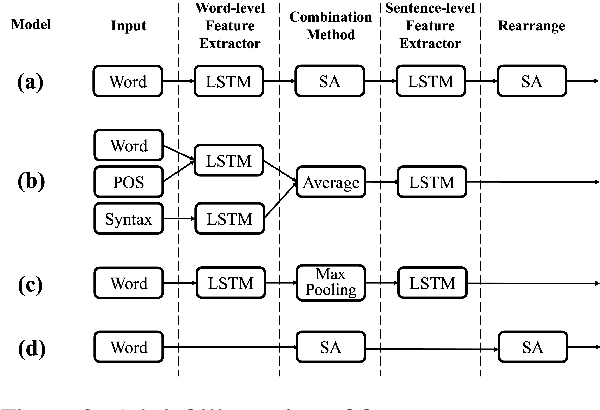
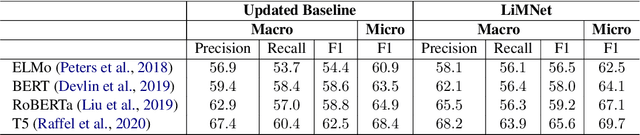
Complex feature extractors are widely employed for text representation building. However, these complex feature extractors can lead to severe overfitting problems especially when the training datasets are small, which is especially the case for several discourse parsing tasks. Thus, we propose to remove additional feature extractors and only utilize self-attention mechanism to exploit pretrained neural language models in order to mitigate the overfitting problem. Experiments on three common discourse parsing tasks (News Discourse Profiling, Rhetorical Structure Theory based Discourse Parsing and Penn Discourse Treebank based Discourse Parsing) show that powered by recent pretrained language models, our simplied feature extractors obtain better generalizabilities and meanwhile achieve comparable or even better system performance. The simplified feature extractors have fewer learnable parameters and less processing time. Codes will be released and this simple yet effective model can serve as a better baseline for future research.
CNT (Conditioning on Noisy Targets): A new Algorithm for Leveraging Top-Down Feedback
Oct 18, 2022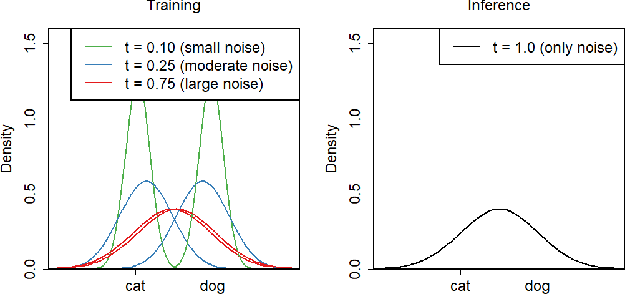
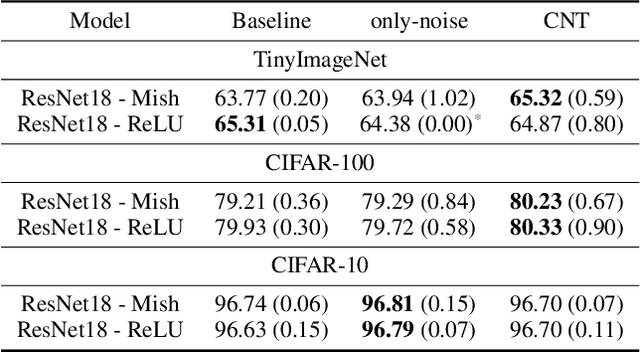
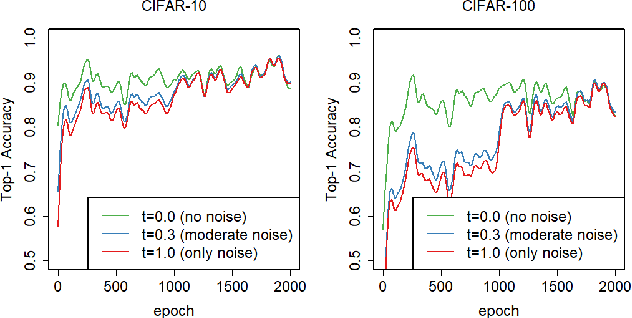
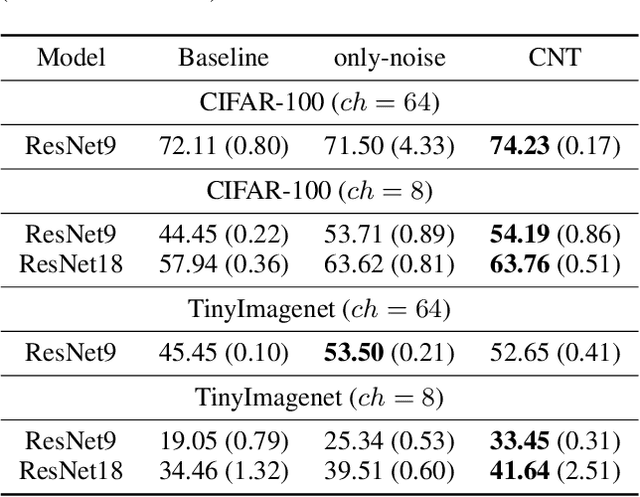
We propose a novel regularizer for supervised learning called Conditioning on Noisy Targets (CNT). This approach consists in conditioning the model on a noisy version of the target(s) (e.g., actions in imitation learning or labels in classification) at a random noise level (from small to large noise). At inference time, since we do not know the target, we run the network with only noise in place of the noisy target. CNT provides hints through the noisy label (with less noise, we can more easily infer the true target). This give two main benefits: 1) the top-down feedback allows the model to focus on simpler and more digestible sub-problems and 2) rather than learning to solve the task from scratch, the model will first learn to master easy examples (with less noise), while slowly progressing toward harder examples (with more noise).
Imputing Missing Observations with Time Sliced Synthetic Minority Oversampling Technique
Jan 14, 2022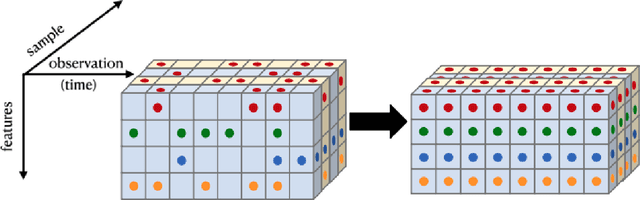
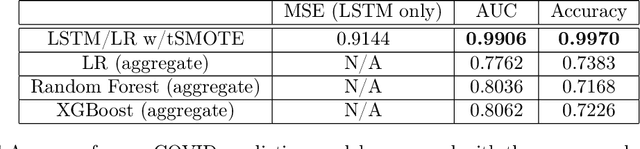
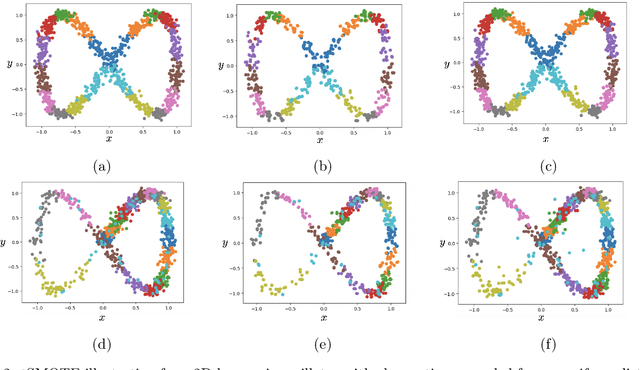
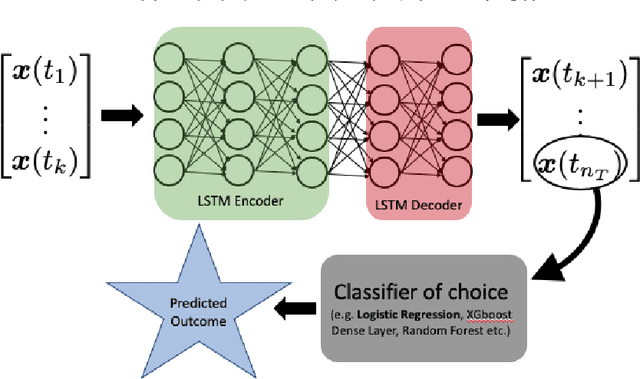
We present a simple yet novel time series imputation technique with the goal of constructing an irregular time series that is uniform across every sample in a data set. Specifically, we fix a grid defined by the midpoints of non-overlapping bins (dubbed "slices") of observation times and ensure that each sample has values for all of the features at that given time. This allows one to both impute fully missing observations to allow uniform time series classification across the entire data and, in special cases, to impute individually missing features. To do so, we slightly generalize the well-known class imbalance algorithm SMOTE \cite{smote} to allow component wise nearest neighbor interpolation that preserves correlations when there are no missing features. We visualize the method in the simplified setting of 2-dimensional uncoupled harmonic oscillators. Next, we use tSMOTE to train an Encoder/Decoder long-short term memory (LSTM) model with Logistic Regression for predicting and classifying distinct trajectories of different 2D oscillators. After illustrating the the utility of tSMOTE in this context, we use the same architecture to train a clinical model for COVID-19 disease severity on an imputed data set. Our experiments show an improvement over standard mean and median imputation techniques by allowing a wider class of patient trajectories to be recognized by the model, as well as improvement over aggregated classification models.
Geometric Tracking Control of Omnidirectional Multirotors in the Presence of Rotor Dynamics
Sep 20, 2022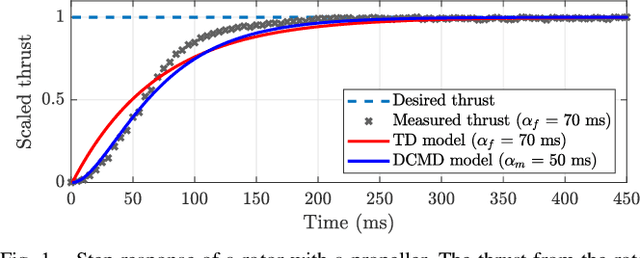
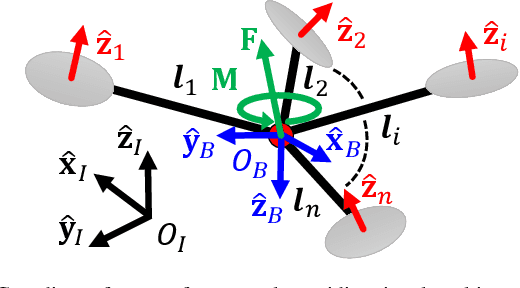

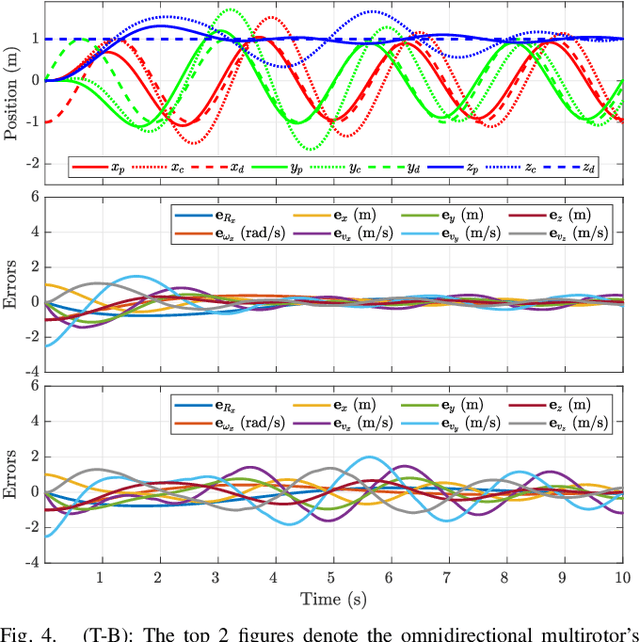
An omnidirectional multirotor has the advantageous maneuverability of decoupled translational and rotational motions, drastically superseding the traditional multirotors' motion capability. Such maneuverability requires an omnidirectional multirotor to frequently alter the thrust amplitude and even direction, which is prone to the rotors' settling time induced from the rotors' own dynamics. Furthermore, the omnidirectional multirotor's stability for tracking control in the presence of rotor dynamics has not yet been addressed. To resolve this issue, we propose a geometric tracking controller that takes the rotor dynamics into account. We show that the proposed controller yields the zero equilibrium of the error dynamics almost globally exponentially stable. The controller's tracking performance and stability are verified in simulations. Furthermore, the single-axis force experiment with the omnidirectional multirotor has been performed to confirm the proposed controller's performance in mitigating the rotors' settling time in the real world.
Comparative analysis of real bugs in open-source Machine Learning projects -- A Registered Report
Sep 20, 2022

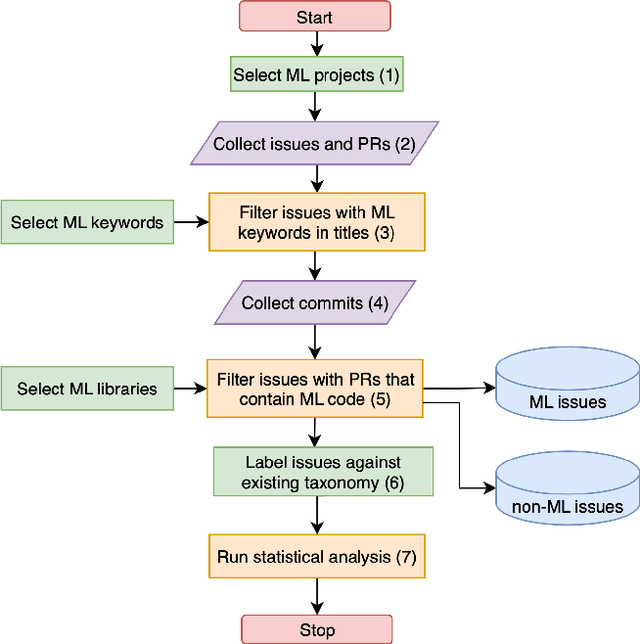
Background: Machine Learning (ML) systems rely on data to make predictions, the systems have many added components compared to traditional software systems such as the data processing pipeline, serving pipeline, and model training. Existing research on software maintenance has studied the issue-reporting needs and resolution process for different types of issues, such as performance and security issues. However, ML systems have specific classes of faults, and reporting ML issues requires domain-specific information. Because of the different characteristics between ML and traditional Software Engineering systems, we do not know to what extent the reporting needs are different, and to what extent these differences impact the issue resolution process. Objective: Our objective is to investigate whether there is a discrepancy in the distribution of resolution time between ML and non-ML issues and whether certain categories of ML issues require a longer time to resolve based on real issue reports in open-source applied ML projects. We further investigate the size of fix of ML issues and non-ML issues. Method: We extract issues reports, pull requests and code files in recent active applied ML projects from Github, and use an automatic approach to filter ML and non-ML issues. We manually label the issues using a known taxonomy of deep learning bugs. We measure the resolution time and size of fix of ML and non-ML issues on a controlled sample and compare the distributions for each category of issue.
Adaptive Selection of the Optimal Strategy to Improve Precision and Power in Randomized Trials
Oct 31, 2022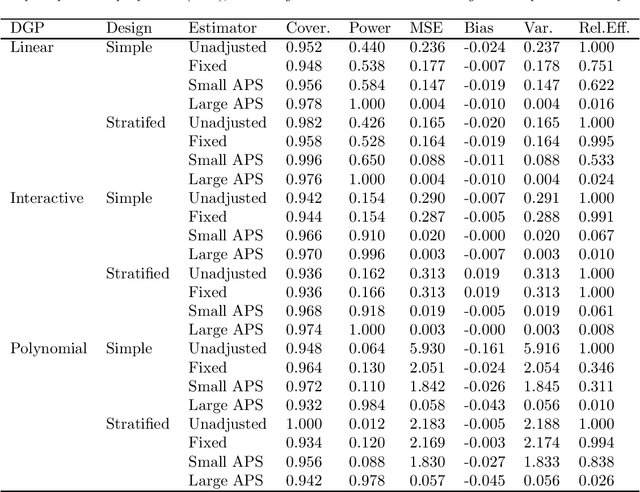
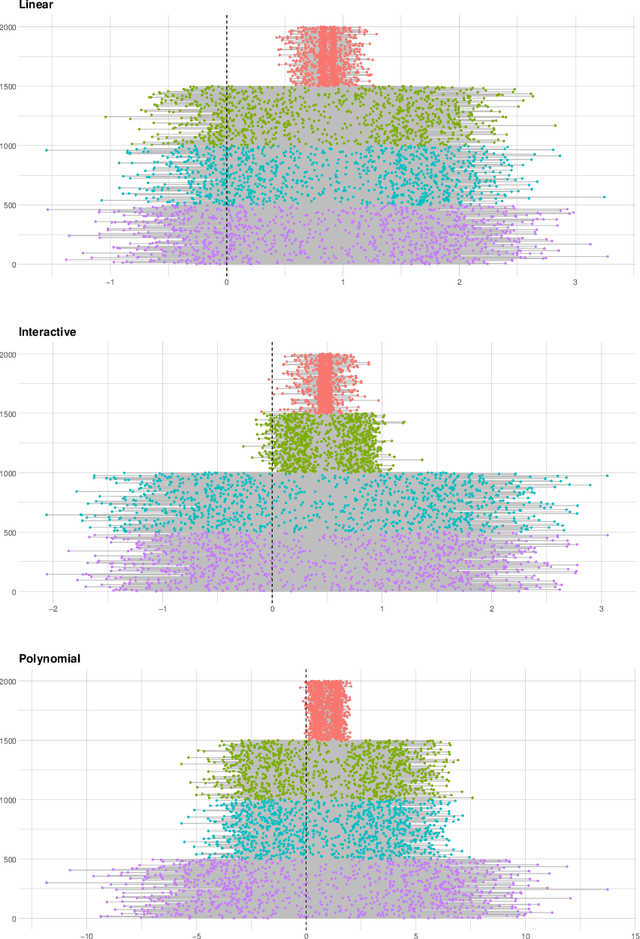
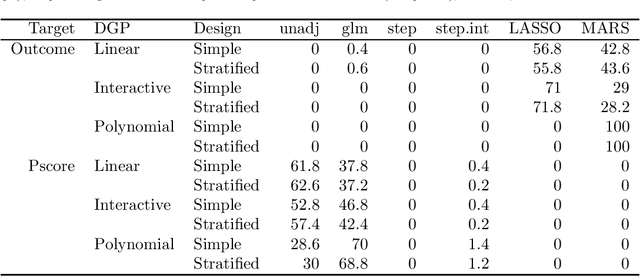
Benkeser et al. demonstrate how adjustment for baseline covariates in randomized trials can meaningfully improve precision for a variety of outcome types, including binary, ordinal, and time-to-event. Their findings build on a long history, starting in 1932 with R.A. Fisher and including the more recent endorsements by the U.S. Food and Drug Administration and the European Medicines Agency. Here, we address an important practical consideration: how to select the adjustment approach -- which variables and in which form -- to maximize precision, while maintaining nominal confidence interval coverage. Balzer et al. previously proposed, evaluated, and applied Adaptive Prespecification to flexibly select, from a prespecified set, the variables that maximize empirical efficiency in small randomized trials (N<40). To avoid overfitting with few randomized units, adjustment was previously limited to a single covariate in a working generalized linear model (GLM) for the expected outcome and a single covariate in a working GLM for the propensity score. Here, we tailor Adaptive Prespecification to trials with many randomized units. Specifically, using V-fold cross-validation and the squared influence curve as the loss function, we select from an expanded set of candidate algorithms, including both parametric and semi-parametric methods, the optimal combination of estimators of the expected outcome and known propensity score. Using simulations, under a variety of data generating processes, we demonstrate the dramatic gains in precision offered by our novel approach.