 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient Rigid Body Localization based on Euclidean Distance Matrix Completion for AGV Positioning under Harsh Environment
Nov 23, 2022
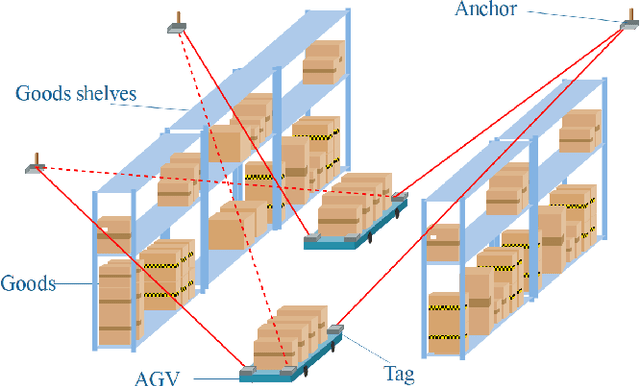
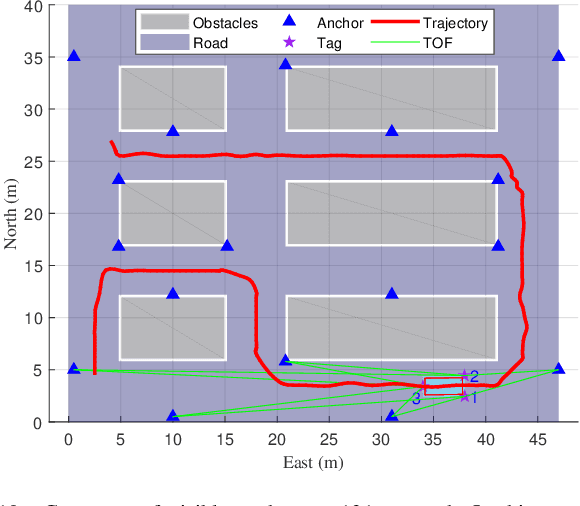
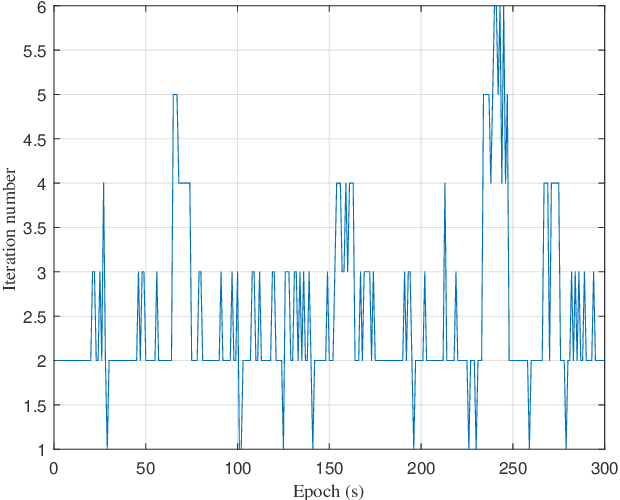
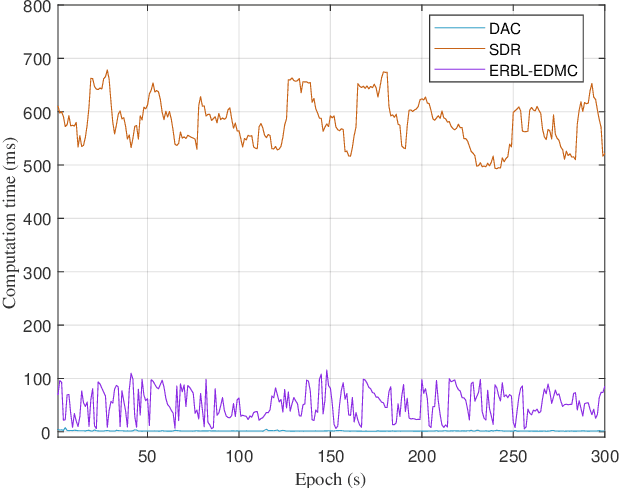
In real-world applications for automatic guided vehicle (AGV) navigation, the positioning system based on the time-of-flight (TOF) measurements between anchors and tags is confronted with the problem of insufficient measurements caused by blockages to radio signals or lasers, etc. Mounting multiple tags at different positions of the AGV to collect more TOFs is a feasible solution to tackle this difficulty. Vehicle localization by exploiting the measurements between multiple tags and anchors is a rigid body localization (RBL) problem, which estimates both the position and attitude of the vehicle. However, the state-of-the-art solutions to the RBL problem do not deal with missing measurements, and thus will result in degraded localization availability and accuracy in harsh environments. In this paper, different from these existing solutions for RBL, we model this problem as a sensor network localization problem with missing TOFs. To solve this problem, we propose a new efficient RBL solution based on Euclidean distance matrix (EDM) completion, abbreviated as ERBL-EDMC. Firstly, we develop a method to determine the upper and lower bounds of the missing measurements to complete the EDM reliably, using the known relative positions between tags and the statistics of the TOF measurements. Then, based on the completed EDM, the global tag positions are obtained from a coarse estimation followed by a refinement step assisted with inter-tag distances. Finally, the optimal vehicle position and attitude are obtained iteratively based on the estimated tag positions from the previous step. Theoretical analysis and simulation results show that the proposed ERBL-EDMC method effectively solves the RBL problem with incomplete measurements. It obtains the optimal positioning results while maintaining low computational complexity compared with the existing RBL methods based on semi-definite relaxation.
On the impact of incorporating task-information in learning-based image denoising
Nov 23, 2022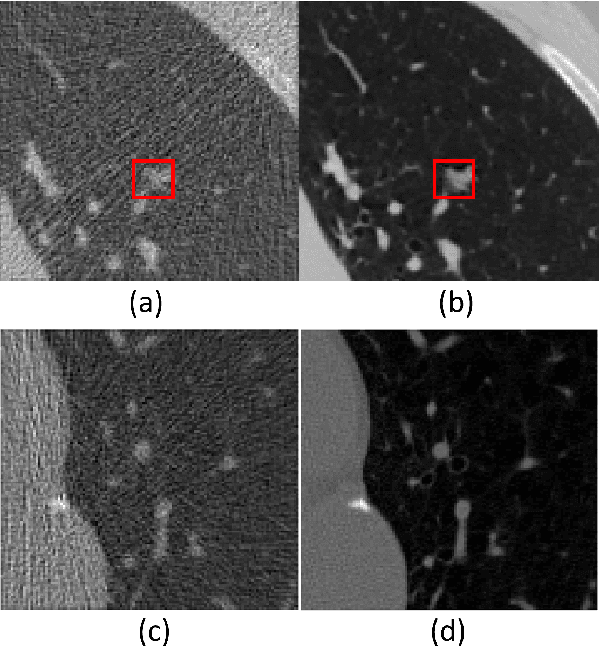
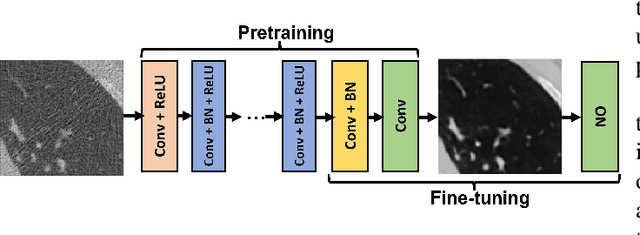
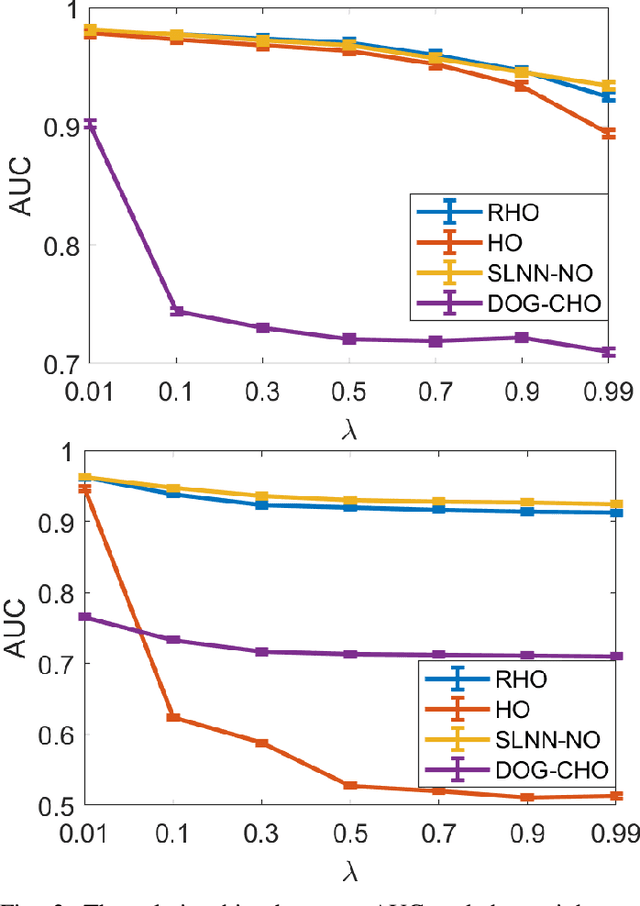
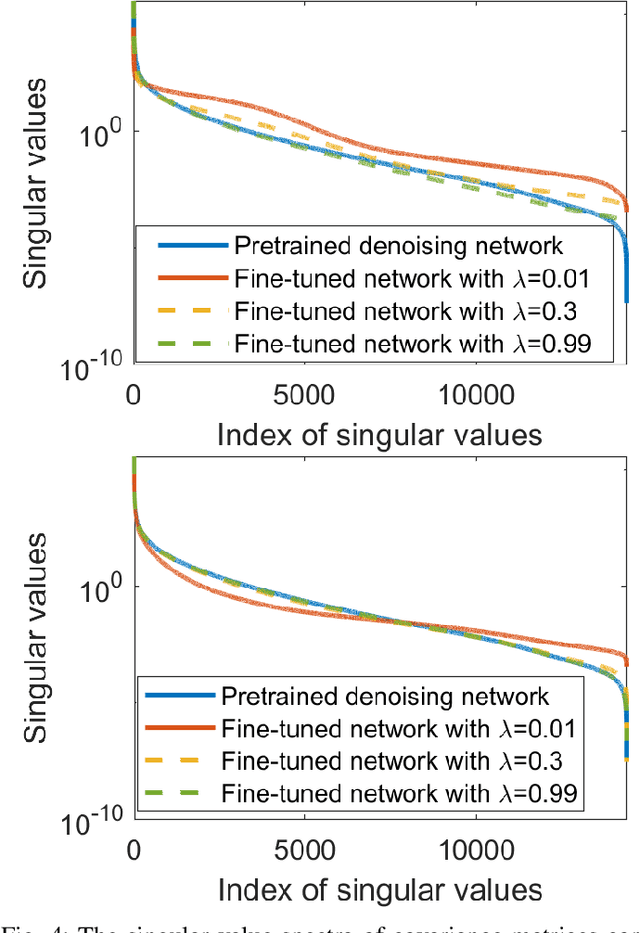
A variety of deep neural network (DNN)-based image denoising methods have been proposed for use with medical images. These methods are typically trained by minimizing loss functions that quantify a distance between the denoised image, or a transformed version of it, and the defined target image (e.g., a noise-free or low-noise image). They have demonstrated high performance in terms of traditional image quality metrics such as root mean square error (RMSE), structural similarity index measure (SSIM), or peak signal-to-noise ratio (PSNR). However, it has been reported recently that such denoising methods may not always improve objective measures of image quality. In this work, a task-informed DNN-based image denoising method was established and systematically evaluated. A transfer learning approach was employed, in which the DNN is first pre-trained by use of a conventional (non-task-informed) loss function and subsequently fine-tuned by use of the hybrid loss that includes a task-component. The task-component was designed to measure the performance of a numerical observer (NO) on a signal detection task. The impact of network depth and constraining the fine-tuning to specific layers of the DNN was explored. The task-informed training method was investigated in a stylized low-dose X-ray computed tomography (CT) denoising study for which binary signal detection tasks under signal-known-statistically (SKS) with background-known-statistically (BKS) conditions were considered. The impact of changing the specified task at inference time to be different from that employed for model training, a phenomenon we refer to as "task-shift", was also investigated. The presented results indicate that the task-informed training method can improve observer performance while providing control over the trade off between traditional and task-based measures of image quality.
Principled Data-Driven Decision Support for Cyber-Forensic Investigations
Nov 23, 2022
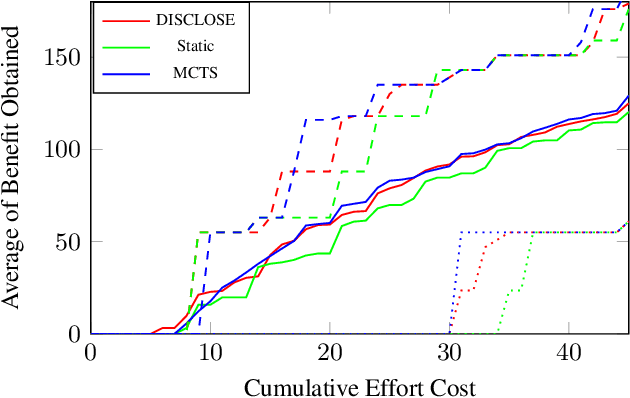
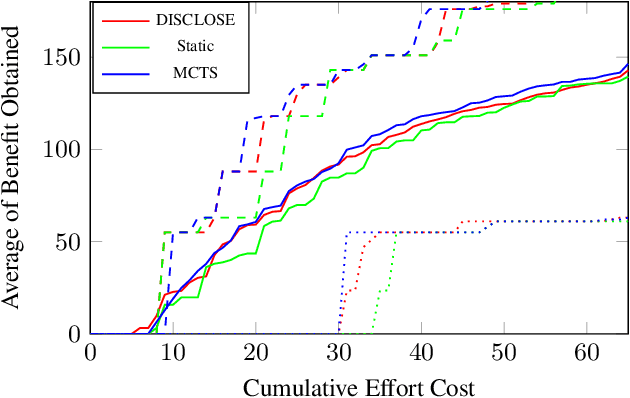
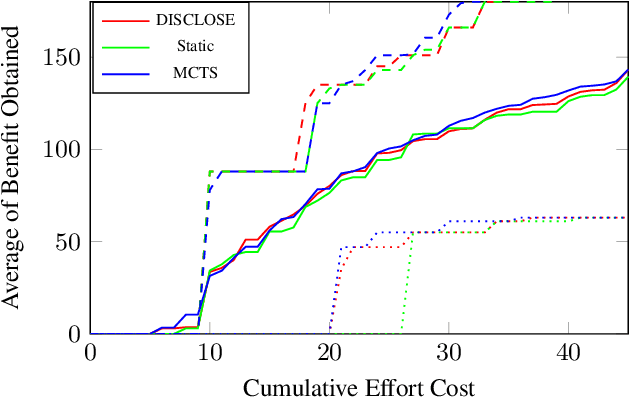
In the wake of a cybersecurity incident, it is crucial to promptly discover how the threat actors breached security in order to assess the impact of the incident and to develop and deploy countermeasures that can protect against further attacks. To this end, defenders can launch a cyber-forensic investigation, which discovers the techniques that the threat actors used in the incident. A fundamental challenge in such an investigation is prioritizing the investigation of particular techniques since the investigation of each technique requires time and effort, but forensic analysts cannot know which ones were actually used before investigating them. To ensure prompt discovery, it is imperative to provide decision support that can help forensic analysts with this prioritization. A recent study demonstrated that data-driven decision support, based on a dataset of prior incidents, can provide state-of-the-art prioritization. However, this data-driven approach, called DISCLOSE, is based on a heuristic that utilizes only a subset of the available information and does not approximate optimal decisions. To improve upon this heuristic, we introduce a principled approach for data-driven decision support for cyber-forensic investigations. We formulate the decision-support problem using a Markov decision process, whose states represent the states of a forensic investigation. To solve the decision problem, we propose a Monte Carlo tree search based method, which relies on a k-NN regression over prior incidents to estimate state-transition probabilities. We evaluate our proposed approach on multiple versions of the MITRE ATT&CK dataset, which is a knowledge base of adversarial techniques and tactics based on real-world cyber incidents, and demonstrate that our approach outperforms DISCLOSE in terms of techniques discovered per effort spent.
Continuous-Time Analog Filters for Audio Edge Intelligence: Review and Analysis on Design Techniques
Jun 06, 2022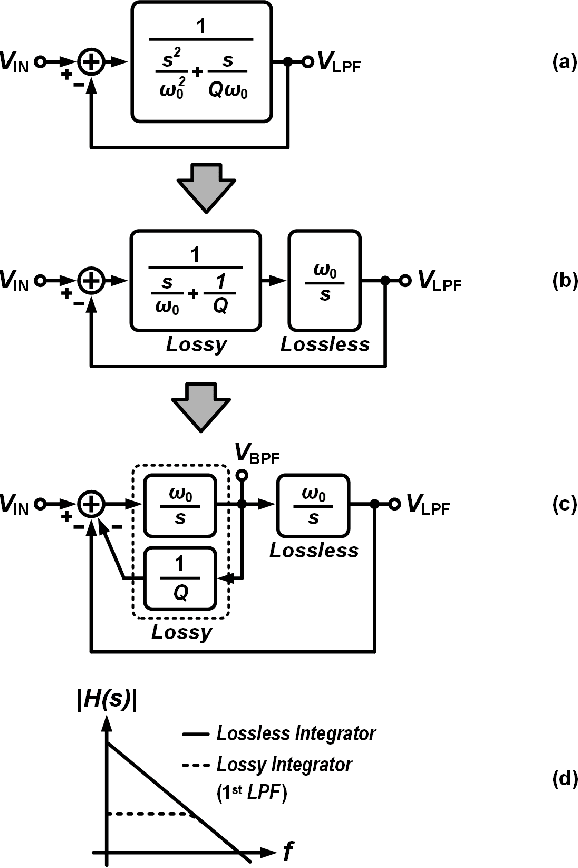
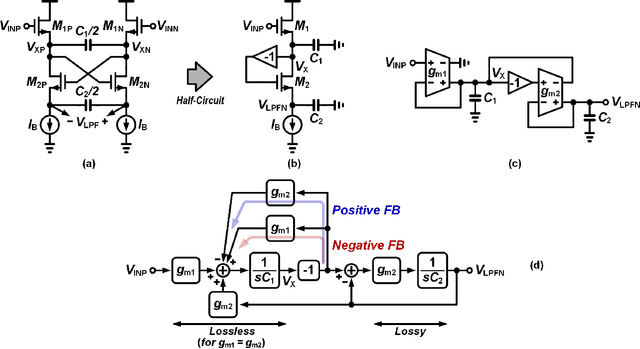
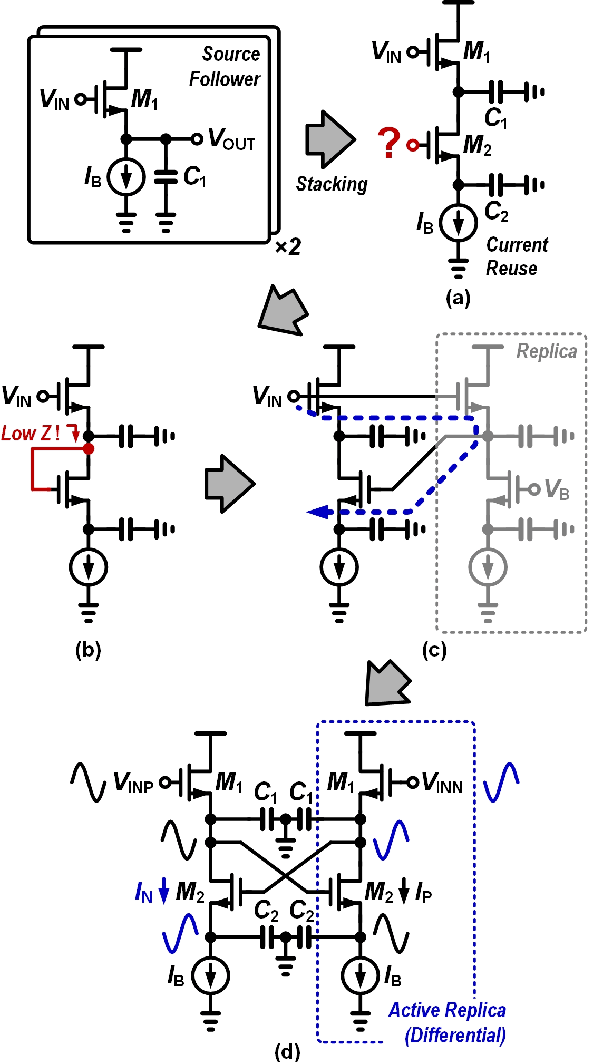
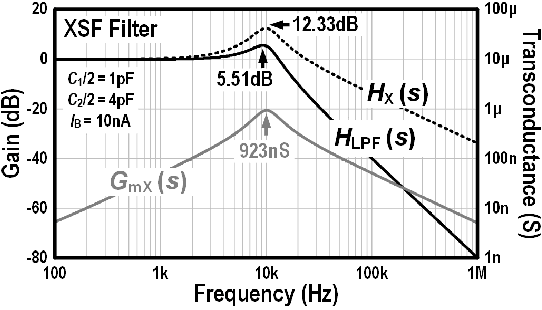
Silicon cochlea designs capture the functionality of the biological cochlea. Their use has been explored for cochlea prosthesis applications and more recently in edge audio devices which are required to support always-on operation. As their stringent power constraints pose several design challenges, IC designers are forced to look for solutions that use low standby power. One promising bio-inspired approach is to combine the continuous-time analog filter channels of the silicon cochlea with a small memory footprint deep neural network that is trained on edge tasks such as keyword spotting, thereby allowing all blocks to be embedded in an IC. This paper reviews the analog filter circuits used as feature extractors for current edge audio devices, starting with the original biquad filter circuits proposed for the silicon cochlea. Our analysis starts from the interpretation of a basic biquad filter as a two-integrator-loop topology and reviews the progression in the design of second-order low-pass and band-pass filters ranging from OTA-based to source-follower-based architectures. We also derive and analyze the small-signal transfer function and discuss performance aspects of these filters. The analysis of these different filter configurations can be applied to other application domains such as biomedical devices which employ a front-end bandpass filter.
CVFNet: Real-time 3D Object Detection by Learning Cross View Features
Mar 13, 2022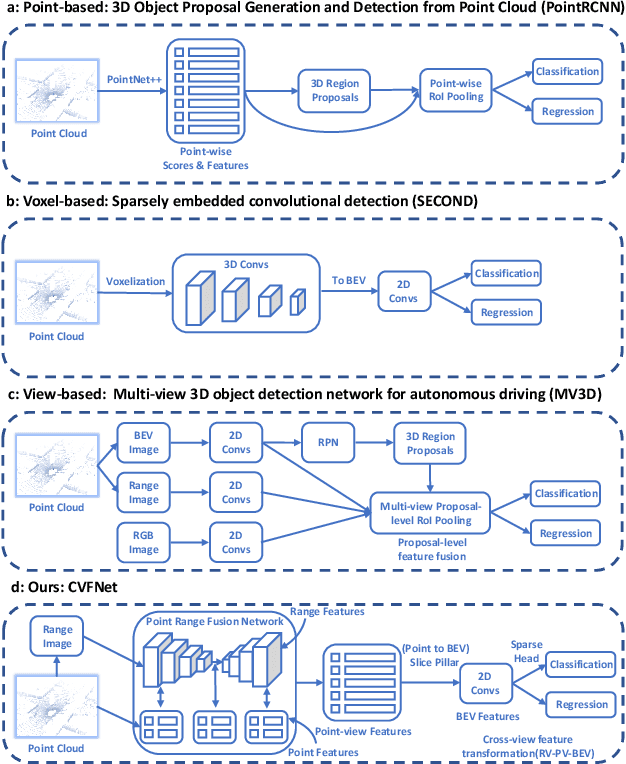

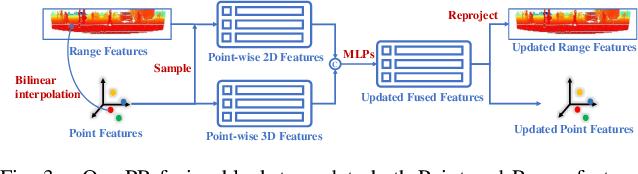
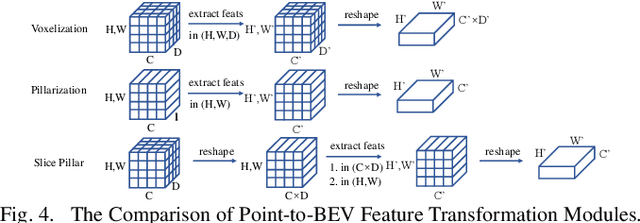
In recent years 3D object detection from LiDAR point clouds has made great progress thanks to the development of deep learning technologies. Although voxel or point based methods are popular in 3D object detection, they usually involve time-consuming operations such as 3D convolutions on voxels or ball query among points, making the resulting network inappropriate for time critical applications. On the other hand, 2D view-based methods feature high computing efficiency while usually obtaining inferior performance than the voxel or point based methods. In this work, we present a real-time view-based single stage 3D object detector, namely CVFNet to fulfill this task. To strengthen the cross-view feature learning under the condition of demanding efficiency, our framework extracts the features of different views and fuses them in an efficient progressive way. We first propose a novel Point-Range feature fusion module that deeply integrates point and range view features in multiple stages. Then, a special Slice Pillar is designed to well maintain the 3D geometry when transforming the obtained deep point-view features into bird's eye view. To better balance the ratio of samples, a sparse pillar detection head is presented to focus the detection on the nonempty grids. We conduct experiments on the popular KITTI and NuScenes benchmark, and state-of-the-art performances are achieved in terms of both accuracy and speed.
Accelerated partial separable model using dimension-reduced optimization technique for ultra-fast cardiac MRI
Oct 02, 2022
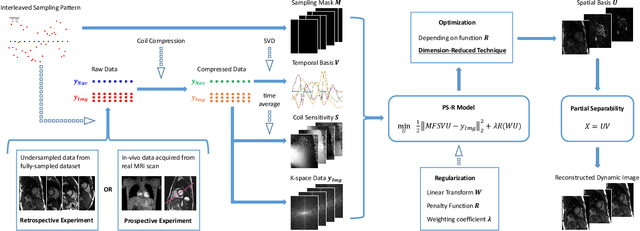
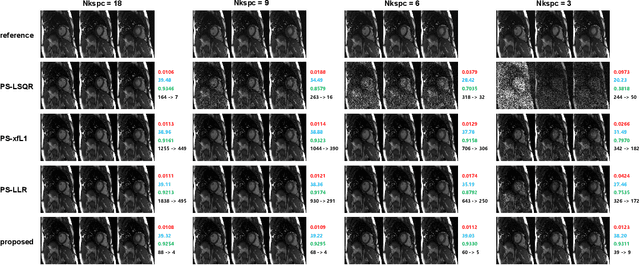
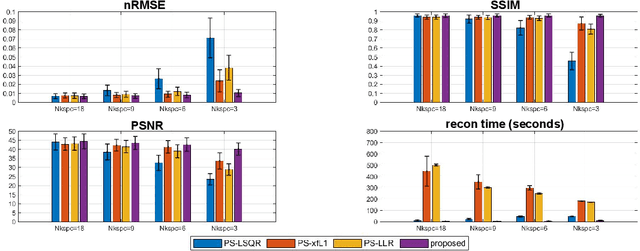
Partial separable(PS) model is a powerful model for dynamic magnetic resonance imaging (MRI). PS model explicitly reduces the degree of freedom in the reconstruction problem, which is beneficial for high temporal resolution applications. However, long acquisition time and even longer reconstruction time prohibit the acceptance of PS model in daily practice. In this work, we propose to fully exploit the dimension-reduction property to accelerate the PS model. We optimize the data consistency term, and use a Tikhonov regularization term based on Frobenius norm of temporal difference, resulting in a totally dimension-reduced optimization technique. The proposed method is used for accelerating the free-running cardiac MRI. We have performed both retrospective experiments on public dataset and prospective experiments on in-vivo data, and compared the proposed method with least-square method and another two popular regularized PS model methods. The results show that the proposed method has robust performance against shortened acquisition time or suboptimal hyper-parameter settings, and achieves superior image quality over all other competing algorithms. The proposed method is 20-fold faster than the widely accepted PS+Sparse method, enabling data acquisition and image reconstruction to be completed in just a few seconds.
A Linearithmic Time Locally Optimal Algorithm for the Multiway Number Partition Optimization
Mar 10, 2022We study the problem of multiway number partition optimization, which has a myriad of applications in the decision, learning and optimization literature. Even though the original multiway partitioning problem is NP-hard and requires exponential time complexity algorithms; we formulate an easier optimization problem, where our goal is to find a solution that is locally optimal. We propose a linearithmic time complexity $O(N\log N)$ algorithm that can produce such a locally optimal solution. Our method is robust against the input and requires neither positive nor integer inputs.
When regression coefficients change over time: A proposal
Mar 19, 2022
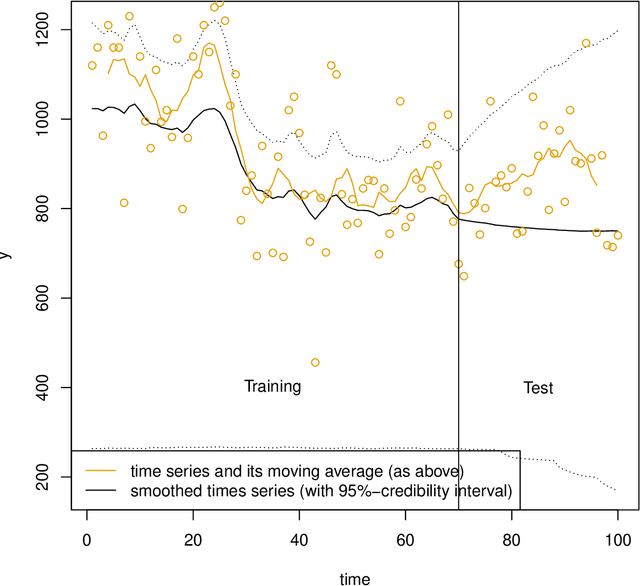
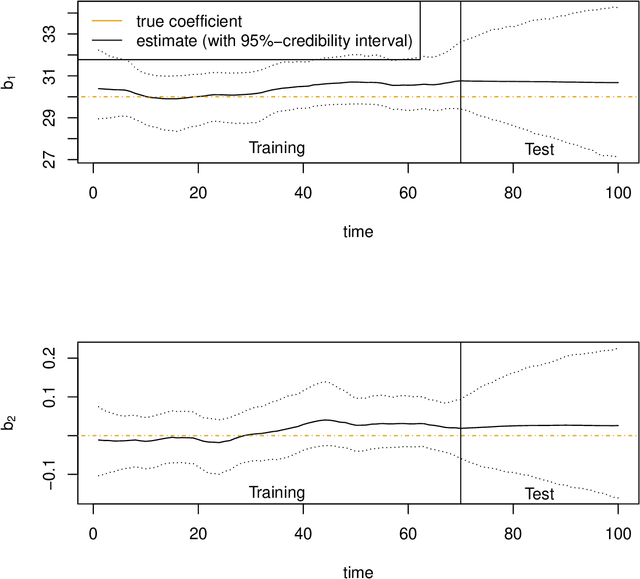
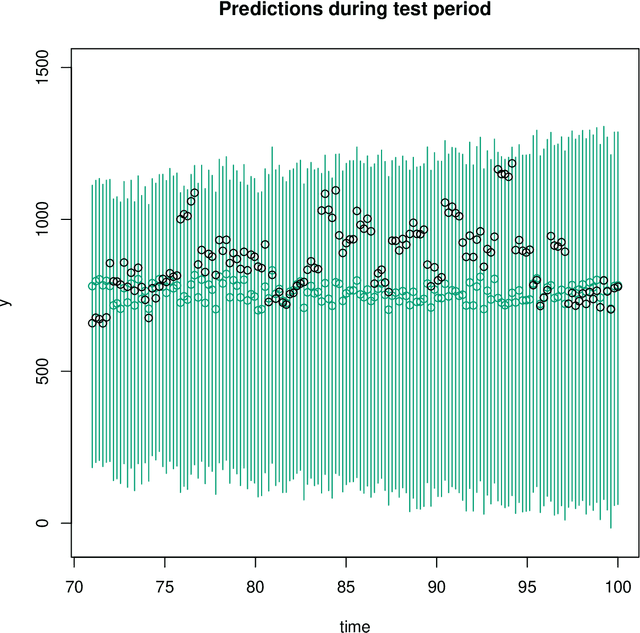
A common approach in forecasting problems is to estimate a least-squares regression (or other statistical learning models) from past data, which is then applied to predict future outcomes. An underlying assumption is that the same correlations that were observed in the past still hold for the future. We propose a model for situations when this assumption is not met: adopting methods from the state space literature, we model how regression coefficients change over time. Our approach can shed light on the large uncertainties associated with forecasting the future, and how much of this is due to changing dynamics of the past. Our simulation study shows that accurate estimates are obtained when the outcome is continuous, but the procedure fails for binary outcomes.
FS-DETR: Few-Shot DEtection TRansformer with prompting and without re-training
Oct 10, 2022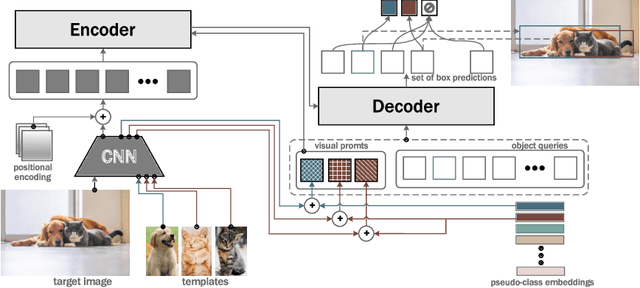
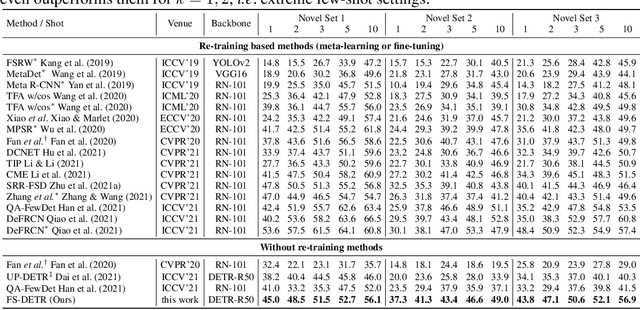
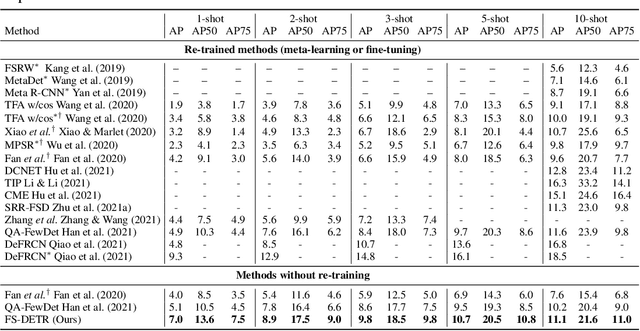
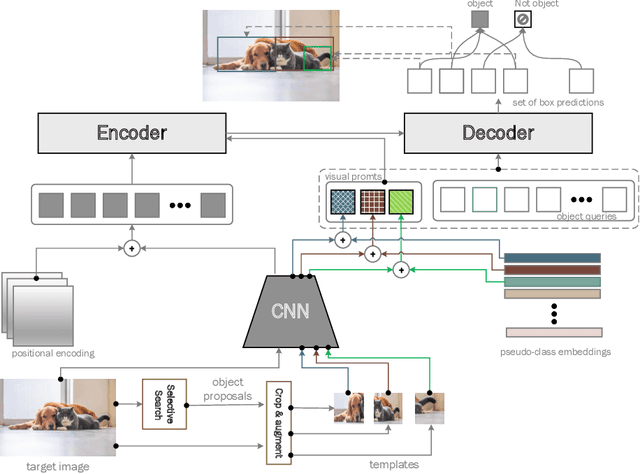
This paper is on Few-Shot Object Detection (FSOD), where given a few templates (examples) depicting a novel class (not seen during training), the goal is to detect all of its occurrences within a set of images. From a practical perspective, an FSOD system must fulfil the following desiderata: (a) it must be used as is, without requiring any fine-tuning at test time, (b) it must be able to process an arbitrary number of novel objects concurrently while supporting an arbitrary number of examples from each class and (c) it must achieve accuracy comparable to a closed system. While there are (relatively) few systems that support (a), to our knowledge, there is no system supporting (b) and (c). In this work, we make the following contributions: We introduce, for the first time, a simple, yet powerful, few-shot detection transformer (FS-DETR) that can address both desiderata (a) and (b). Our system builds upon the DETR framework, extending it based on two key ideas: (1) feed the provided visual templates of the novel classes as visual prompts during test time, and (2) ``stamp'' these prompts with pseudo-class embeddings, which are then predicted at the output of the decoder. Importantly, we show that our system is not only more flexible than existing methods, but also, making a step towards satisfying desideratum (c), it is more accurate, matching and outperforming the current state-of-the-art on the most well-established benchmarks (PASCAL VOC & MSCOCO) for FSOD. Code will be made available.
ViT-CAT: Parallel Vision Transformers with Cross Attention Fusion for Popularity Prediction in MEC Networks
Oct 27, 2022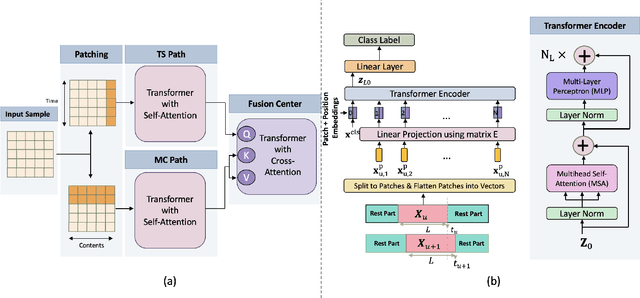
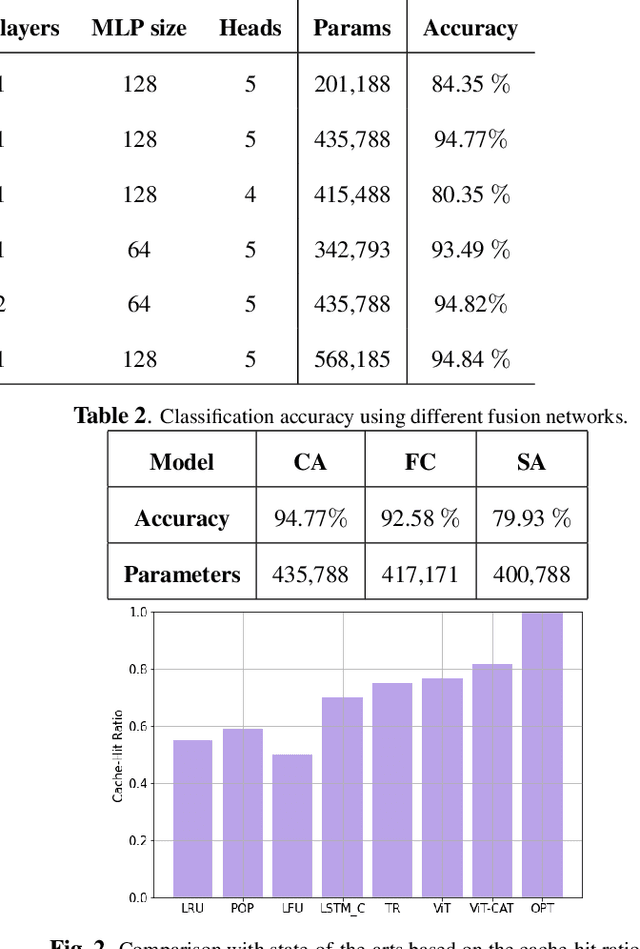
Mobile Edge Caching (MEC) is a revolutionary technology for the Sixth Generation (6G) of wireless networks with the promise to significantly reduce users' latency via offering storage capacities at the edge of the network. The efficiency of the MEC network, however, critically depends on its ability to dynamically predict/update the storage of caching nodes with the top-K popular contents. Conventional statistical caching schemes are not robust to the time-variant nature of the underlying pattern of content requests, resulting in a surge of interest in using Deep Neural Networks (DNNs) for time-series popularity prediction in MEC networks. However, existing DNN models within the context of MEC fail to simultaneously capture both temporal correlations of historical request patterns and the dependencies between multiple contents. This necessitates an urgent quest to develop and design a new and innovative popularity prediction architecture to tackle this critical challenge. The paper addresses this gap by proposing a novel hybrid caching framework based on the attention mechanism. Referred to as the parallel Vision Transformers with Cross Attention (ViT-CAT) Fusion, the proposed architecture consists of two parallel ViT networks, one for collecting temporal correlation, and the other for capturing dependencies between different contents. Followed by a Cross Attention (CA) module as the Fusion Center (FC), the proposed ViT-CAT is capable of learning the mutual information between temporal and spatial correlations, as well, resulting in improving the classification accuracy, and decreasing the model's complexity about 8 times. Based on the simulation results, the proposed ViT-CAT architecture outperforms its counterparts across the classification accuracy, complexity, and cache-hit ratio.