 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Lane Detection with Wavelet-Enhanced Context Modeling and Adaptive Sampling
Mar 24, 2025



Lane detection is critical for autonomous driving and ad-vanced driver assistance systems (ADAS). While recent methods like CLRNet achieve strong performance, they struggle under adverse con-ditions such as extreme weather, illumination changes, occlusions, and complex curves. We propose a Wavelet-Enhanced Feature Pyramid Net-work (WE-FPN) to address these challenges. A wavelet-based non-local block is integrated before the feature pyramid to improve global context modeling, especially for occluded and curved lanes. Additionally, we de-sign an adaptive preprocessing module to enhance lane visibility under poor lighting. An attention-guided sampling strategy further reffnes spa-tial features, boosting accuracy on distant and curved lanes. Experiments on CULane and TuSimple demonstrate that our approach signiffcantly outperforms baselines in challenging scenarios, achieving better robust-ness and accuracy in real-world driving conditions.
Flight Testing an Optionally Piloted Aircraft: a Case Study on Trust Dynamics in Human-Autonomy Teaming
Mar 20, 2025



This paper examines how trust is formed, maintained, or diminished over time in the context of human-autonomy teaming with an optionally piloted aircraft. Whereas traditional factor-based trust models offer a static representation of human confidence in technology, here we discuss how variations in the underlying factors lead to variations in trust, trust thresholds, and human behaviours. Over 200 hours of flight test data collected over a multi-year test campaign from 2021 to 2023 were reviewed. The dispositional-situational-learned, process-performance-purpose, and IMPACTS homeostasis trust models are applied to illuminate trust trends during nominal autonomous flight operations. The results offer promising directions for future studies on trust dynamics and design-for-trust in human-autonomy teaming.
A unified uncertainty-aware exploration: Combining epistemic and aleatory uncertainty
Jan 05, 2024
Exploration is a significant challenge in practical reinforcement learning (RL), and uncertainty-aware exploration that incorporates the quantification of epistemic and aleatory uncertainty has been recognized as an effective exploration strategy. However, capturing the combined effect of aleatory and epistemic uncertainty for decision-making is difficult. Existing works estimate aleatory and epistemic uncertainty separately and consider the composite uncertainty as an additive combination of the two. Nevertheless, the additive formulation leads to excessive risk-taking behavior, causing instability. In this paper, we propose an algorithm that clarifies the theoretical connection between aleatory and epistemic uncertainty, unifies aleatory and epistemic uncertainty estimation, and quantifies the combined effect of both uncertainties for a risk-sensitive exploration. Our method builds on a novel extension of distributional RL that estimates a parameterized return distribution whose parameters are random variables encoding epistemic uncertainty. Experimental results on tasks with exploration and risk challenges show that our method outperforms alternative approaches.
Uncertainty-aware transfer across tasks using hybrid model-based successor feature reinforcement learning
Oct 16, 2023



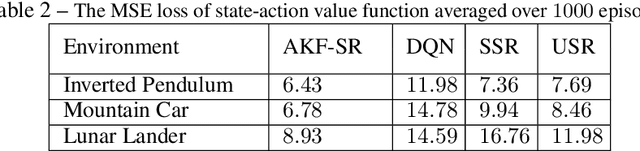
Sample efficiency is central to developing practical reinforcement learning (RL) for complex and large-scale decision-making problems. The ability to transfer and generalize knowledge gained from previous experiences to downstream tasks can significantly improve sample efficiency. Recent research indicates that successor feature (SF) RL algorithms enable knowledge generalization between tasks with different rewards but identical transition dynamics. It has recently been hypothesized that combining model-based (MB) methods with SF algorithms can alleviate the limitation of fixed transition dynamics. Furthermore, uncertainty-aware exploration is widely recognized as another appealing approach for improving sample efficiency. Putting together two ideas of hybrid model-based successor feature (MB-SF) and uncertainty leads to an approach to the problem of sample efficient uncertainty-aware knowledge transfer across tasks with different transition dynamics or/and reward functions. In this paper, the uncertainty of the value of each action is approximated by a Kalman filter (KF)-based multiple-model adaptive estimation. This KF-based framework treats the parameters of a model as random variables. To the best of our knowledge, this is the first attempt at formulating a hybrid MB-SF algorithm capable of generalizing knowledge across large or continuous state space tasks with various transition dynamics while requiring less computation at decision time than MB methods. The number of samples required to learn the tasks was compared to recent SF and MB baselines. The results show that our algorithm generalizes its knowledge across different transition dynamics, learns downstream tasks with significantly fewer samples than starting from scratch, and outperforms existing approaches.
* 40 pages
ViT-CAT: Parallel Vision Transformers with Cross Attention Fusion for Popularity Prediction in MEC Networks
Oct 27, 2022

Mobile Edge Caching (MEC) is a revolutionary technology for the Sixth Generation (6G) of wireless networks with the promise to significantly reduce users' latency via offering storage capacities at the edge of the network. The efficiency of the MEC network, however, critically depends on its ability to dynamically predict/update the storage of caching nodes with the top-K popular contents. Conventional statistical caching schemes are not robust to the time-variant nature of the underlying pattern of content requests, resulting in a surge of interest in using Deep Neural Networks (DNNs) for time-series popularity prediction in MEC networks. However, existing DNN models within the context of MEC fail to simultaneously capture both temporal correlations of historical request patterns and the dependencies between multiple contents. This necessitates an urgent quest to develop and design a new and innovative popularity prediction architecture to tackle this critical challenge. The paper addresses this gap by proposing a novel hybrid caching framework based on the attention mechanism. Referred to as the parallel Vision Transformers with Cross Attention (ViT-CAT) Fusion, the proposed architecture consists of two parallel ViT networks, one for collecting temporal correlation, and the other for capturing dependencies between different contents. Followed by a Cross Attention (CA) module as the Fusion Center (FC), the proposed ViT-CAT is capable of learning the mutual information between temporal and spatial correlations, as well, resulting in improving the classification accuracy, and decreasing the model's complexity about 8 times. Based on the simulation results, the proposed ViT-CAT architecture outperforms its counterparts across the classification accuracy, complexity, and cache-hit ratio.
Multi-Content Time-Series Popularity Prediction with Multiple-Model Transformers in MEC Networks
Oct 12, 2022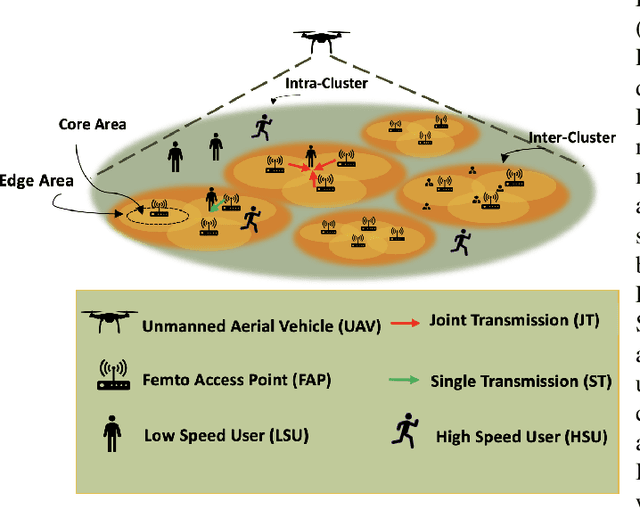
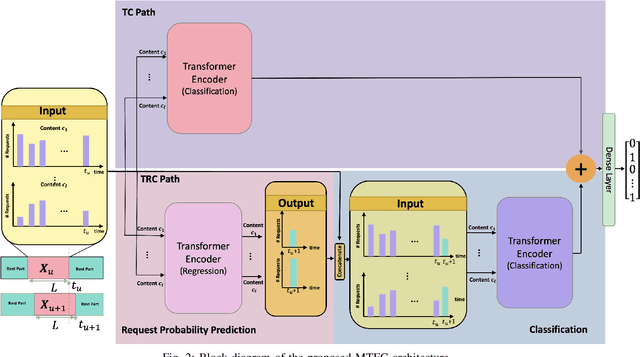
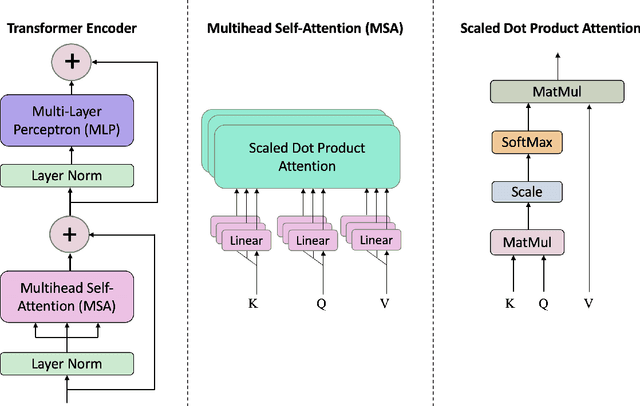
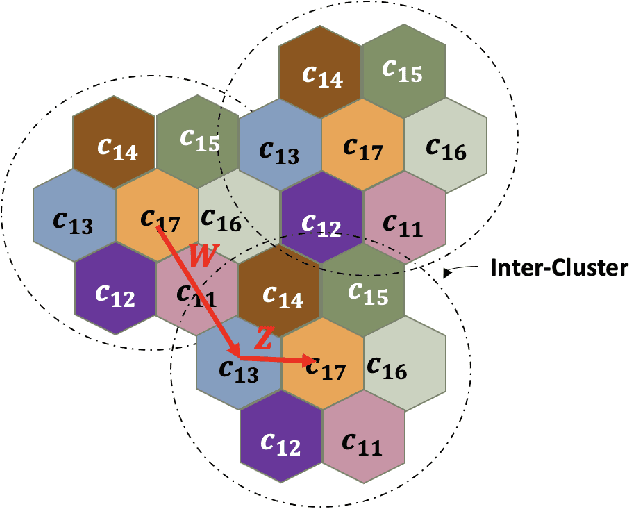
Coded/uncoded content placement in Mobile Edge Caching (MEC) has evolved as an efficient solution to meet the significant growth of global mobile data traffic by boosting the content diversity in the storage of caching nodes. To meet the dynamic nature of the historical request pattern of multimedia contents, the main focus of recent researches has been shifted to develop data-driven and real-time caching schemes. In this regard and with the assumption that users' preferences remain unchanged over a short horizon, the Top-K popular contents are identified as the output of the learning model. Most existing datadriven popularity prediction models, however, are not suitable for the coded/uncoded content placement frameworks. On the one hand, in coded/uncoded content placement, in addition to classifying contents into two groups, i.e., popular and nonpopular, the probability of content request is required to identify which content should be stored partially/completely, where this information is not provided by existing data-driven popularity prediction models. On the other hand, the assumption that users' preferences remain unchanged over a short horizon only works for content with a smooth request pattern. To tackle these challenges, we develop a Multiple-model (hybrid) Transformer-based Edge Caching (MTEC) framework with higher generalization ability, suitable for various types of content with different time-varying behavior, that can be adapted with coded/uncoded content placement frameworks. Simulation results corroborate the effectiveness of the proposed MTEC caching framework in comparison to its counterparts in terms of the cache-hit ratio, classification accuracy, and the transferred byte volume.
JUNO: Jump-Start Reinforcement Learning-based Node Selection for UWB Indoor Localization
May 06, 2022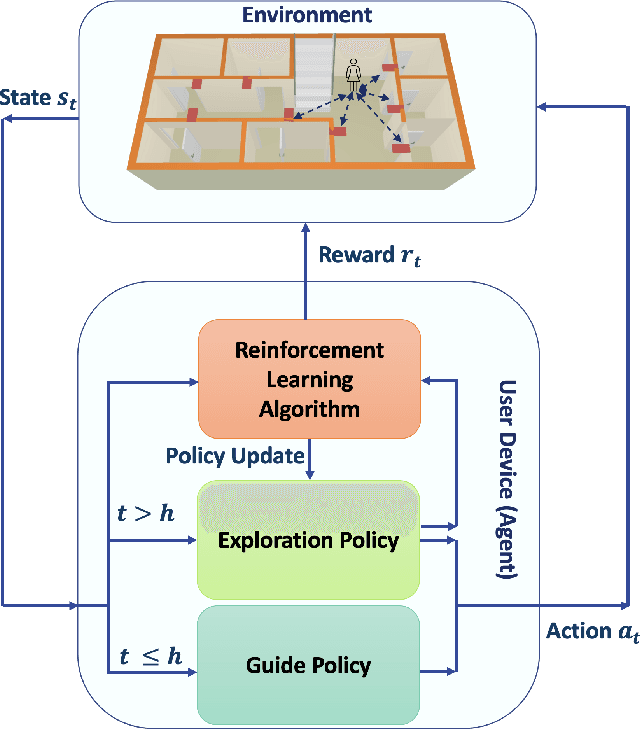
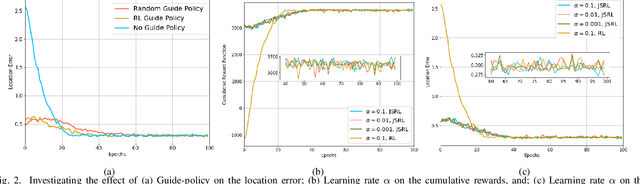
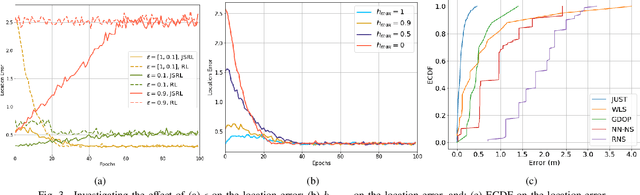
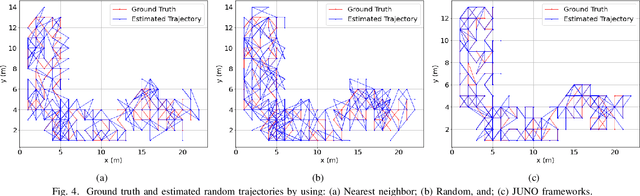
Ultra-Wideband (UWB) is one of the key technologies empowering the Internet of Thing (IoT) concept to perform reliable, energy-efficient, and highly accurate monitoring, screening, and localization in indoor environments. Performance of UWB-based localization systems, however, can significantly degrade because of Non Line of Sight (NLoS) connections between a mobile user and UWB beacons. To mitigate the destructive effects of NLoS connections, we target development of a Reinforcement Learning (RL) anchor selection framework that can efficiently cope with the dynamic nature of indoor environments. Existing RL models in this context, however, lack the ability to generalize well to be used in a new setting. Moreover, it takes a long time for the conventional RL models to reach the optimal policy. To tackle these challenges, we propose the Jump-start RL-based Uwb NOde selection (JUNO) framework, which performs real-time location predictions without relying on complex NLoS identification/mitigation methods. The effectiveness of the proposed JUNO framework is evaluated in term of the location error, where the mobile user moves randomly through an ultra-dense indoor environment with a high chance of establishing NLoS connections. Simulation results corroborate the effectiveness of the proposed framework in comparison to its state-of-the-art counterparts.
AKF-SR: Adaptive Kalman Filtering-based Successor Representation
Mar 31, 2022

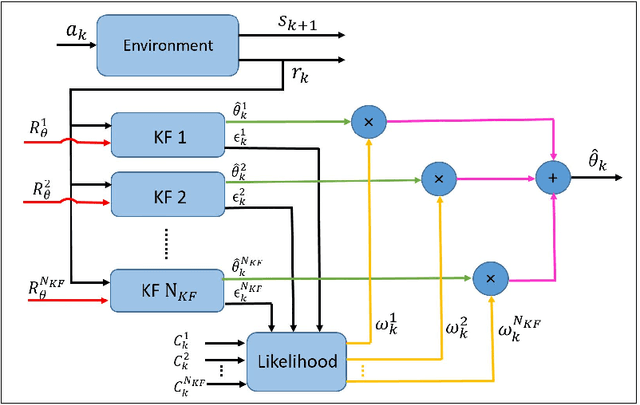
Recent studies in neuroscience suggest that Successor Representation (SR)-based models provide adaptation to changes in the goal locations or reward function faster than model-free algorithms, together with lower computational cost compared to that of model-based algorithms. However, it is not known how such representation might help animals to manage uncertainty in their decision-making. Existing methods for SR learning do not capture uncertainty about the estimated SR. In order to address this issue, the paper presents a Kalman filter-based SR framework, referred to as Adaptive Kalman Filtering-based Successor Representation (AKF-SR). First, Kalman temporal difference approach, which is a combination of the Kalman filter and the temporal difference method, is used within the AKF-SR framework to cast the SR learning procedure into a filtering problem to benefit from the uncertainty estimation of the SR, and also decreases in memory requirement and sensitivity to model's parameters in comparison to deep neural network-based algorithms. An adaptive Kalman filtering approach is then applied within the proposed AKF-SR framework in order to tune the measurement noise covariance and measurement mapping function of Kalman filter as the most important parameters affecting the filter's performance. Moreover, an active learning method that exploits the estimated uncertainty of the SR to form the behaviour policy leading to more visits to less certain values is proposed to improve the overall performance of an agent in terms of received rewards while interacting with its environment.
DQLEL: Deep Q-Learning for Energy-Optimized LoS/NLoS UWB Node Selection
Aug 24, 2021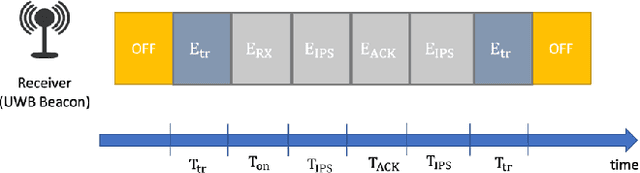
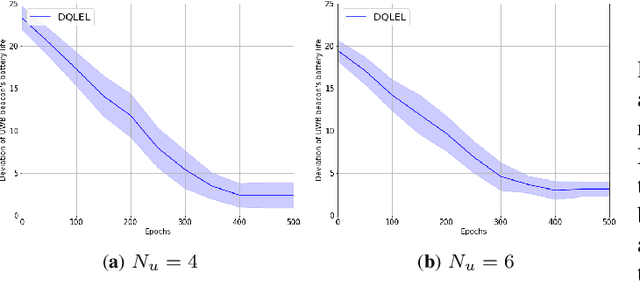
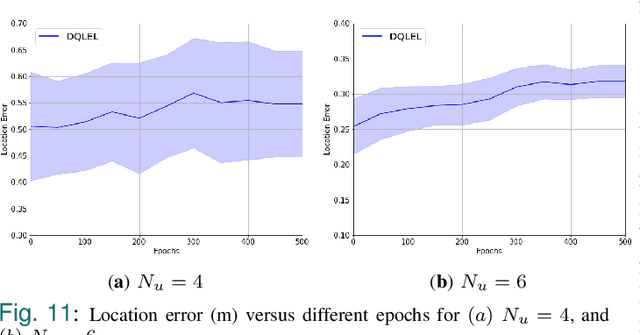
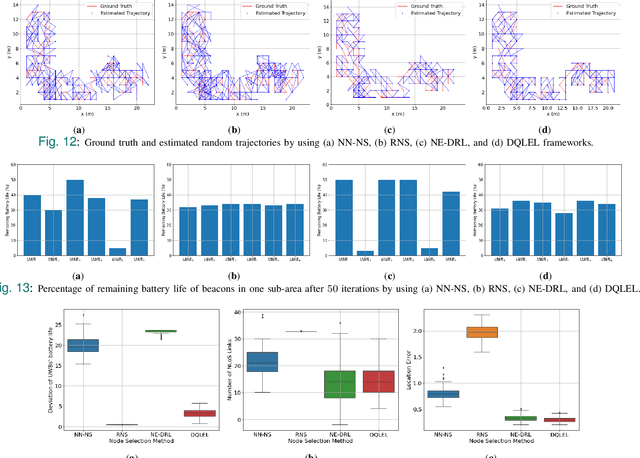
Recent advancements in Internet of Things (IoTs) have brought about a surge of interest in indoor positioning for the purpose of providing reliable, accurate, and energy-efficient indoor navigation/localization systems. Ultra Wide Band (UWB) technology has been emerged as a potential candidate to satisfy the aforementioned requirements. Although UWB technology can enhance the accuracy of indoor positioning due to the use of a wide-frequency spectrum, there are key challenges ahead for its efficient implementation. On the one hand, achieving high precision in positioning relies on the identification/mitigation Non Line of Sight (NLoS) links, leading to a significant increase in the complexity of the localization framework. On the other hand, UWB beacons have a limited battery life, which is especially problematic in practical circumstances with certain beacons located in strategic positions. To address these challenges, we introduce an efficient node selection framework to enhance the location accuracy without using complex NLoS mitigation methods, while maintaining a balance between the remaining battery life of UWB beacons. Referred to as the Deep Q-Learning Energy-optimized LoS/NLoS (DQLEL) UWB node selection framework, the mobile user is autonomously trained to determine the optimal pair of UWB beacons to be localized based on the 2-D Time Difference of Arrival (TDoA) framework. The effectiveness of the proposed DQLEL framework is evaluated in terms of the link condition, the deviation of the remaining battery life of UWB beacons, location error, and cumulative rewards. Based on the simulation results, the proposed DQLEL framework significantly outperformed its counterparts across the aforementioned aspects.
On the Philosophical, Cognitive and Mathematical Foundations of Symbiotic Autonomous Systems (SAS)
Feb 11, 2021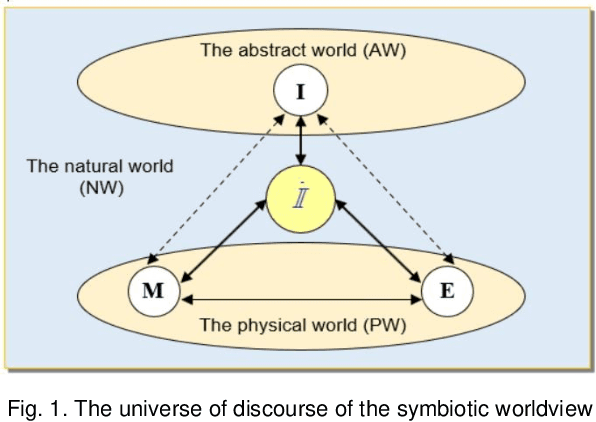

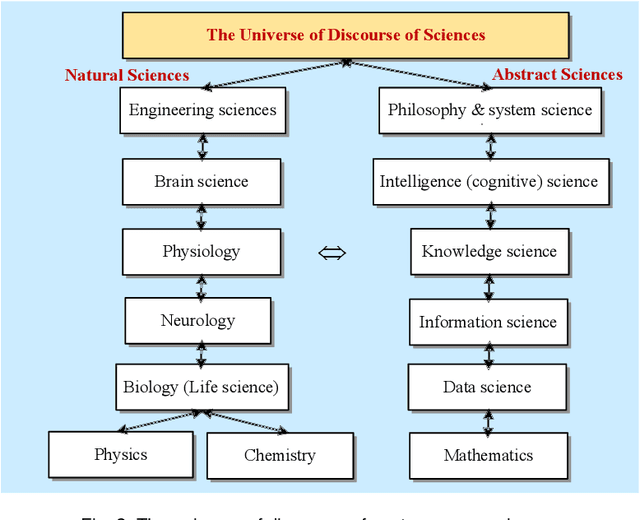
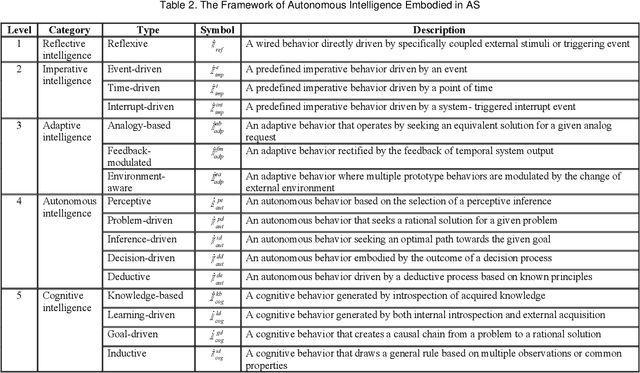
Symbiotic Autonomous Systems (SAS) are advanced intelligent and cognitive systems exhibiting autonomous collective intelligence enabled by coherent symbiosis of human-machine interactions in hybrid societies. Basic research in the emerging field of SAS has triggered advanced general AI technologies functioning without human intervention or hybrid symbiotic systems synergizing humans and intelligent machines into coherent cognitive systems. This work presents a theoretical framework of SAS underpinned by the latest advances in intelligence, cognition, computer, and system sciences. SAS are characterized by the composition of autonomous and symbiotic systems that adopt bio-brain-social-inspired and heterogeneously synergized structures and autonomous behaviors. This paper explores their cognitive and mathematical foundations. The challenge to seamless human-machine interactions in a hybrid environment is addressed. SAS-based collective intelligence is explored in order to augment human capability by autonomous machine intelligence towards the next generation of general AI, autonomous computers, and trustworthy mission-critical intelligent systems. Emerging paradigms and engineering applications of SAS are elaborated via an autonomous knowledge learning system that symbiotically works between humans and cognitive robots.
* Accepted by Phil. Trans. Royal Society (A): Math, Phys & Engg Sci., 379(219x), 2021, Oxford, UK