 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Dynamics of Social Networks: Multi-agent Information Fusion, Anticipatory Decision Making and Polling
Dec 26, 2022
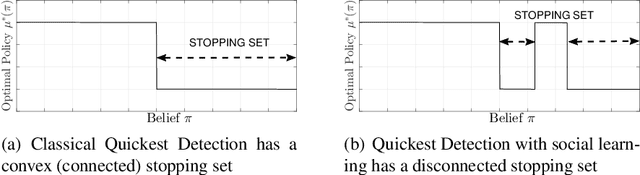
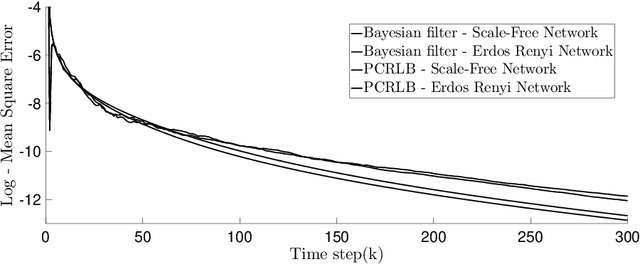
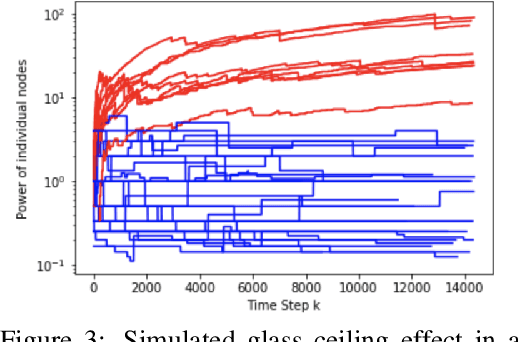
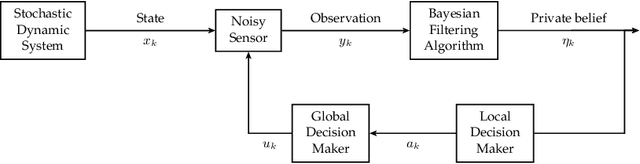
This paper surveys mathematical models, structural results and algorithms in controlled sensing with social learning in social networks. Part 1, namely Bayesian Social Learning with Controlled Sensing addresses the following questions: How does risk averse behavior in social learning affect quickest change detection? How can information fusion be priced? How is the convergence rate of state estimation affected by social learning? The aim is to develop and extend structural results in stochastic control and Bayesian estimation to answer these questions. Such structural results yield fundamental bounds on the optimal performance, give insight into what parameters affect the optimal policies, and yield computationally efficient algorithms. Part 2, namely, Multi-agent Information Fusion with Behavioral Economics Constraints generalizes Part 1. The agents exhibit sophisticated decision making in a behavioral economics sense; namely the agents make anticipatory decisions (thus the decision strategies are time inconsistent and interpreted as subgame Bayesian Nash equilibria). Part 3, namely {\em Interactive Sensing in Large Networks}, addresses the following questions: How to track the degree distribution of an infinite random graph with dynamics (via a stochastic approximation on a Hilbert space)? How can the infected degree distribution of a Markov modulated power law network and its mean field dynamics be tracked via Bayesian filtering given incomplete information obtained by sampling the network? We also briefly discuss how the glass ceiling effect emerges in social networks. Part 4, namely \emph{Efficient Network Polling} deals with polling in large scale social networks. In such networks, only a fraction of nodes can be polled to determine their decisions. Which nodes should be polled to achieve a statistically accurate estimates?
Multimodal Emotion Recognition among Couples from Lab Settings to Daily Life using Smartwatches
Dec 21, 2022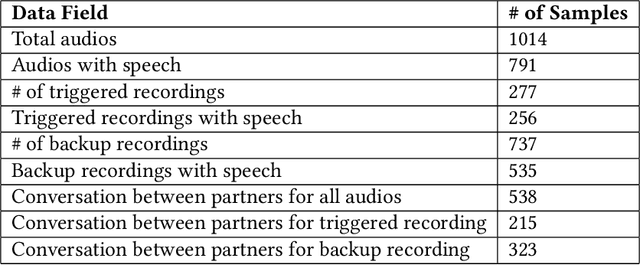
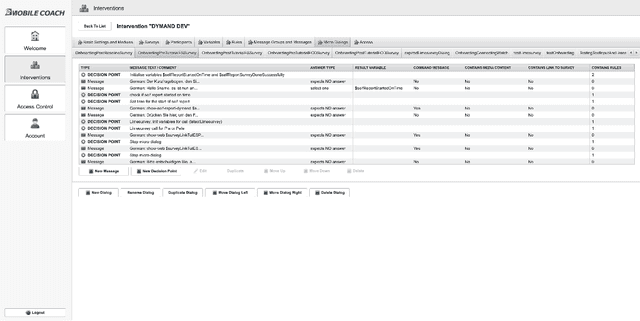
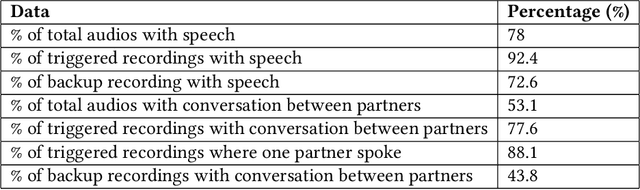
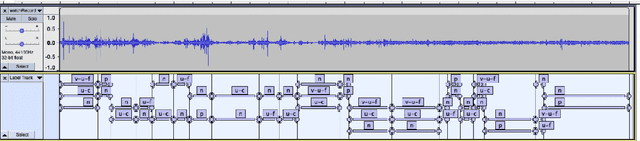
Couples generally manage chronic diseases together and the management takes an emotional toll on both patients and their romantic partners. Consequently, recognizing the emotions of each partner in daily life could provide an insight into their emotional well-being in chronic disease management. The emotions of partners are currently inferred in the lab and daily life using self-reports which are not practical for continuous emotion assessment or observer reports which are manual, time-intensive, and costly. Currently, there exists no comprehensive overview of works on emotion recognition among couples. Furthermore, approaches for emotion recognition among couples have (1) focused on English-speaking couples in the U.S., (2) used data collected from the lab, and (3) performed recognition using observer ratings rather than partner's self-reported / subjective emotions. In this body of work contained in this thesis (8 papers - 5 published and 3 currently under review in various journals), we fill the current literature gap on couples' emotion recognition, develop emotion recognition systems using 161 hours of data from a total of 1,051 individuals, and make contributions towards taking couples' emotion recognition from the lab which is the status quo, to daily life. This thesis contributes toward building automated emotion recognition systems that would eventually enable partners to monitor their emotions in daily life and enable the delivery of interventions to improve their emotional well-being.
Parallel Context Windows Improve In-Context Learning of Large Language Models
Dec 21, 2022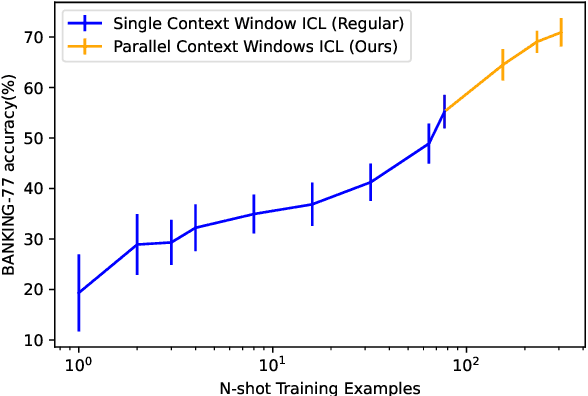
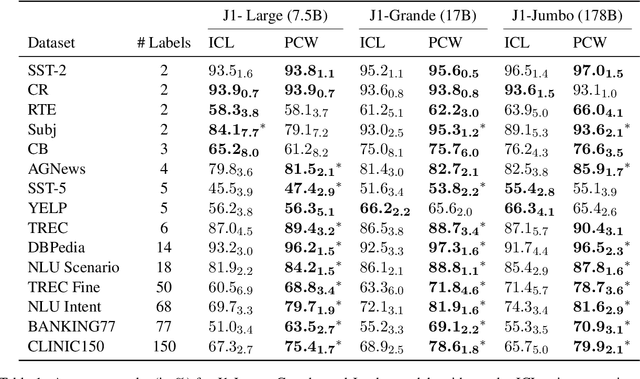
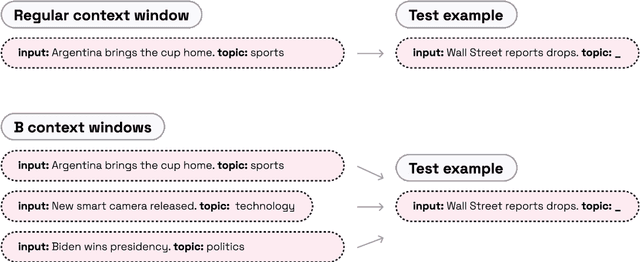
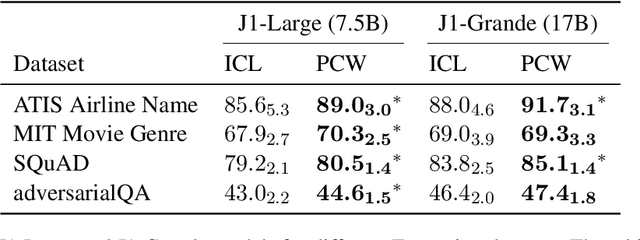
For applications that require processing large amounts of text at inference time, Large Language Models (LLMs) are handicapped by their limited context windows, which are typically 2048 tokens. In-context learning, an emergent phenomenon in LLMs in sizes above a certain parameter threshold, constitutes one significant example because it can only leverage training examples that fit into the context window. Existing efforts to address the context window limitation involve training specialized architectures, which tend to be smaller than the sizes in which in-context learning manifests due to the memory footprint of processing long texts. We present Parallel Context Windows (PCW), a method that alleviates the context window restriction for any off-the-shelf LLM without further training. The key to the approach is to carve a long context into chunks (``windows'') that fit within the architecture, restrict the attention mechanism to apply only within each window, and re-use the positional embeddings among the windows. We test the PCW approach on in-context learning with models that range in size between 750 million and 178 billion parameters, and show substantial improvements for tasks with diverse input and output spaces. Our results motivate further investigation of Parallel Context Windows as a method for applying off-the-shelf LLMs in other settings that require long text sequences.
KL Regularized Normalization Framework for Low Resource Tasks
Dec 21, 2022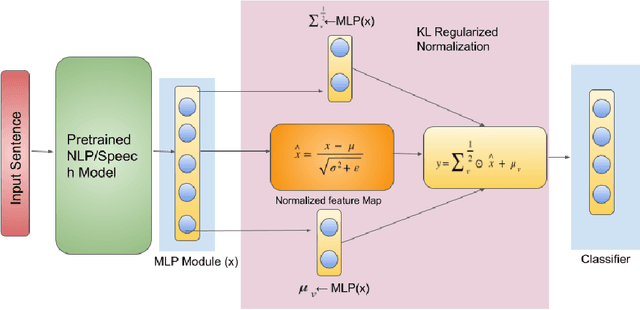
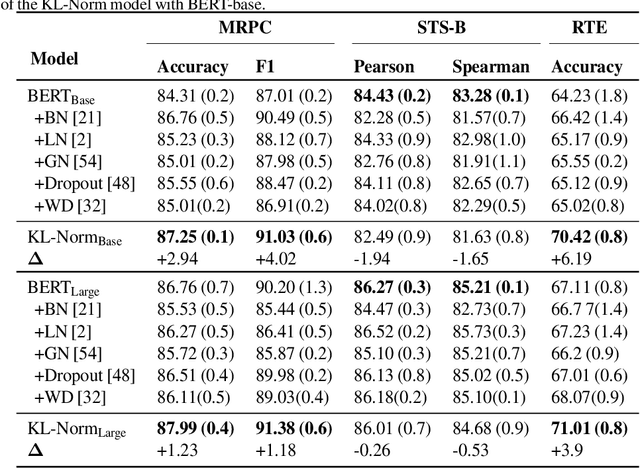
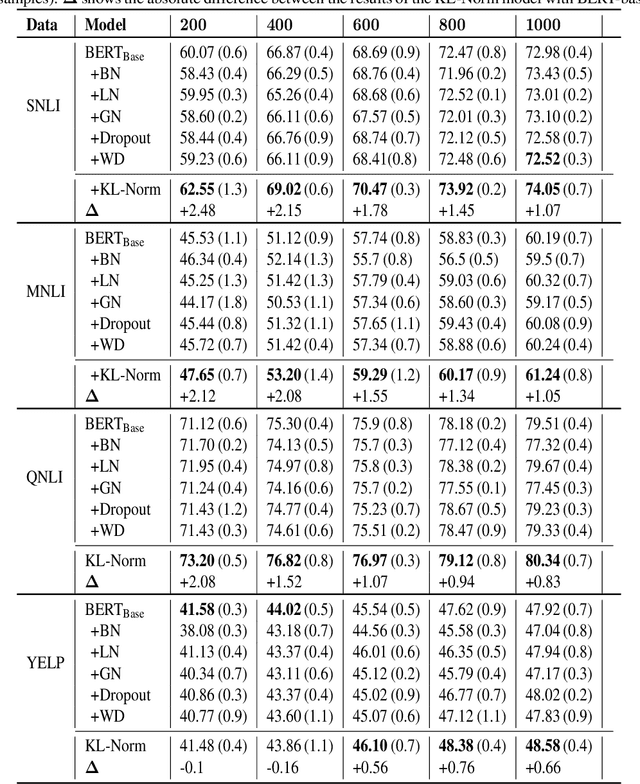
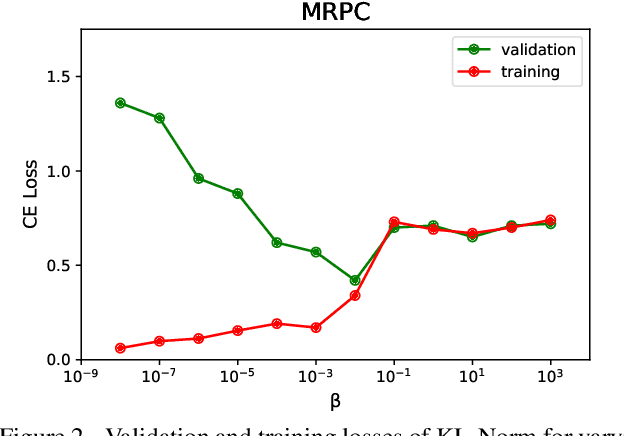
Large pre-trained models, such as Bert, GPT, and Wav2Vec, have demonstrated great potential for learning representations that are transferable to a wide variety of downstream tasks . It is difficult to obtain a large quantity of supervised data due to the limited availability of resources and time. In light of this, a significant amount of research has been conducted in the area of adopting large pre-trained datasets for diverse downstream tasks via fine tuning, linear probing, or prompt tuning in low resource settings. Normalization techniques are essential for accelerating training and improving the generalization of deep neural networks and have been successfully used in a wide variety of applications. A lot of normalization techniques have been proposed but the success of normalization in low resource downstream NLP and speech tasks is limited. One of the reasons is the inability to capture expressiveness by rescaling parameters of normalization. We propose KullbackLeibler(KL) Regularized normalization (KL-Norm) which make the normalized data well behaved and helps in better generalization as it reduces over-fitting, generalises well on out of domain distributions and removes irrelevant biases and features with negligible increase in model parameters and memory overheads. Detailed experimental evaluation on multiple low resource NLP and speech tasks, demonstrates the superior performance of KL-Norm as compared to other popular normalization and regularization techniques.
Contrastive Distillation Is a Sample-Efficient Self-Supervised Loss Policy for Transfer Learning
Dec 21, 2022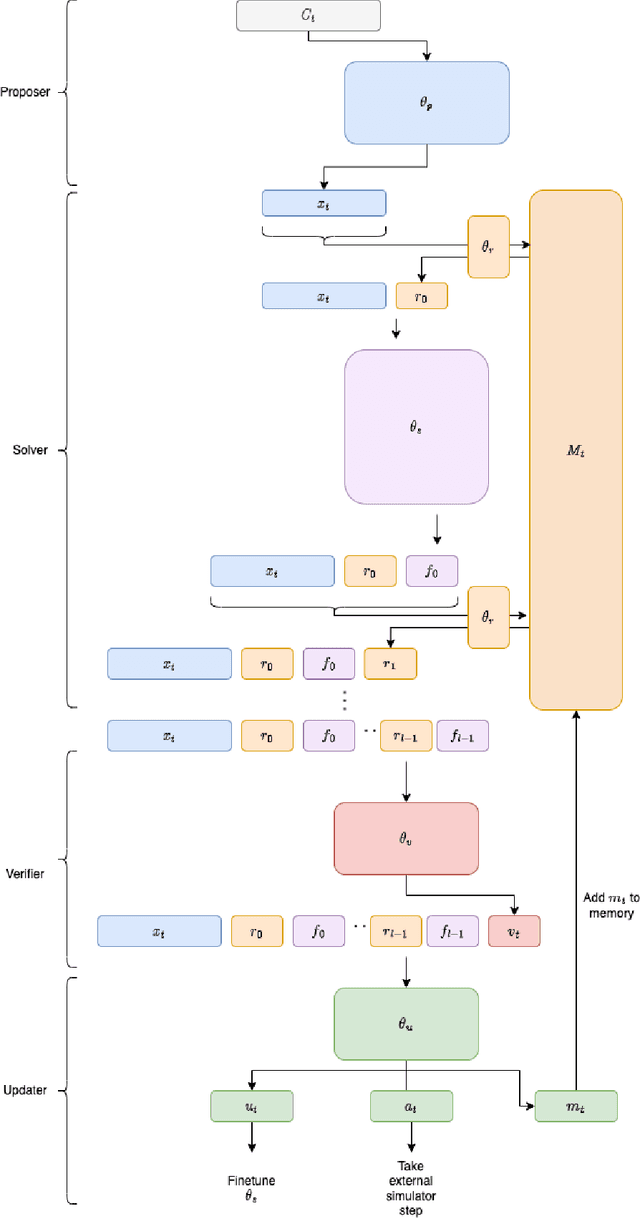
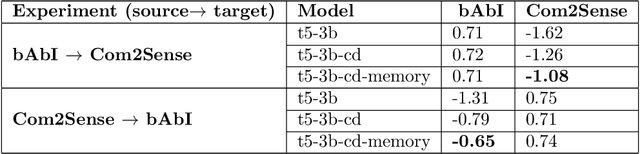
Traditional approaches to RL have focused on learning decision policies directly from episodic decisions, while slowly and implicitly learning the semantics of compositional representations needed for generalization. While some approaches have been adopted to refine representations via auxiliary self-supervised losses while simultaneously learning decision policies, learning compositional representations from hand-designed and context-independent self-supervised losses (multi-view) still adapts relatively slowly to the real world, which contains many non-IID subspaces requiring rapid distribution shift in both time and spatial attention patterns at varying levels of abstraction. In contrast, supervised language model cascades have shown the flexibility to adapt to many diverse manifolds, and hints of self-learning needed for autonomous task transfer. However, to date, transfer methods for language models like few-shot learning and fine-tuning still require human supervision and transfer learning using self-learning methods has been underexplored. We propose a self-supervised loss policy called contrastive distillation which manifests latent variables with high mutual information with both source and target tasks from weights to tokens. We show how this outperforms common methods of transfer learning and suggests a useful design axis of trading off compute for generalizability for online transfer. Contrastive distillation is improved through sampling from memory and suggests a simple algorithm for more efficiently sampling negative examples for contrastive losses than random sampling.
Selected Trends in Artificial Intelligence for Space Applications
Dec 17, 2022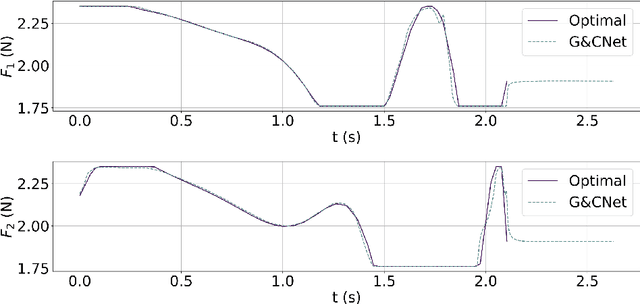
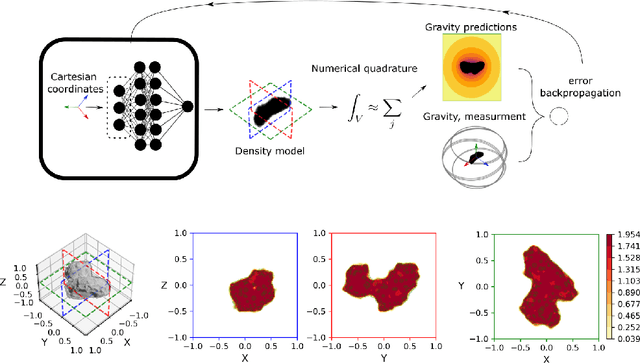
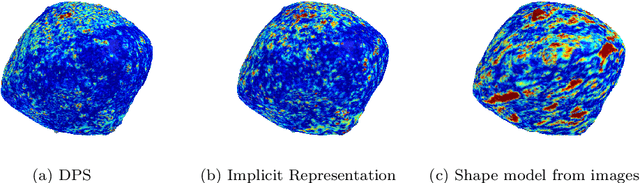
The development and adoption of artificial intelligence (AI) technologies in space applications is growing quickly as the consensus increases on the potential benefits introduced. As more and more aerospace engineers are becoming aware of new trends in AI, traditional approaches are revisited to consider the applications of emerging AI technologies. Already at the time of writing, the scope of AI-related activities across academia, the aerospace industry and space agencies is so wide that an in-depth review would not fit in these pages. In this chapter we focus instead on two main emerging trends we believe capture the most relevant and exciting activities in the field: differentiable intelligence and on-board machine learning. Differentiable intelligence, in a nutshell, refers to works making extensive use of automatic differentiation frameworks to learn the parameters of machine learning or related models. Onboard machine learning considers the problem of moving inference, as well as learning, onboard. Within these fields, we discuss a few selected projects originating from the European Space Agency's (ESA) Advanced Concepts Team (ACT), giving priority to advanced topics going beyond the transposition of established AI techniques and practices to the space domain.
Two-Scale Gradient Descent Ascent Dynamics Finds Mixed Nash Equilibria of Continuous Games: A Mean-Field Perspective
Dec 17, 2022Finding the mixed Nash equilibria (MNE) of a two-player zero sum continuous game is an important and challenging problem in machine learning. A canonical algorithm to finding the MNE is the noisy gradient descent ascent method which in the infinite particle limit gives rise to the {\em Mean-Field Gradient Descent Ascent} (GDA) dynamics on the space of probability measures. In this paper, we first study the convergence of a two-scale Mean-Field GDA dynamics for finding the MNE of the entropy-regularized objective. More precisely we show that for any fixed positive temperature (or regularization parameter), the two-scale Mean-Field GDA with a {\em finite} scale ratio converges to exponentially to the unique MNE without assuming the convexity or concavity of the interaction potential. The key ingredient of our proof lies in the construction of new Lyapunov functions that dissipate exponentially along the Mean-Field GDA. We further study the simulated annealing of the Mean-Field GDA dynamics. We show that with a temperature schedule that decays logarithmically in time the annealed Mean-Field GDA converges to the MNE of the original unregularized objective function.
Shape Aware Automatic Region-of-Interest Subdivisions
Dec 17, 2022
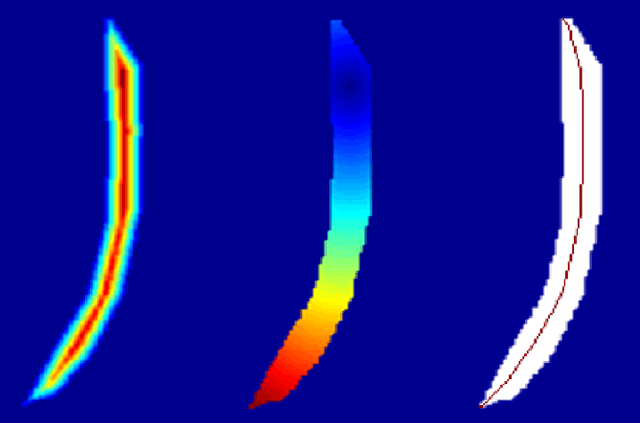
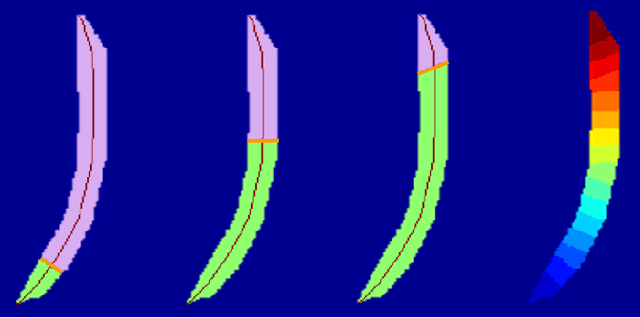
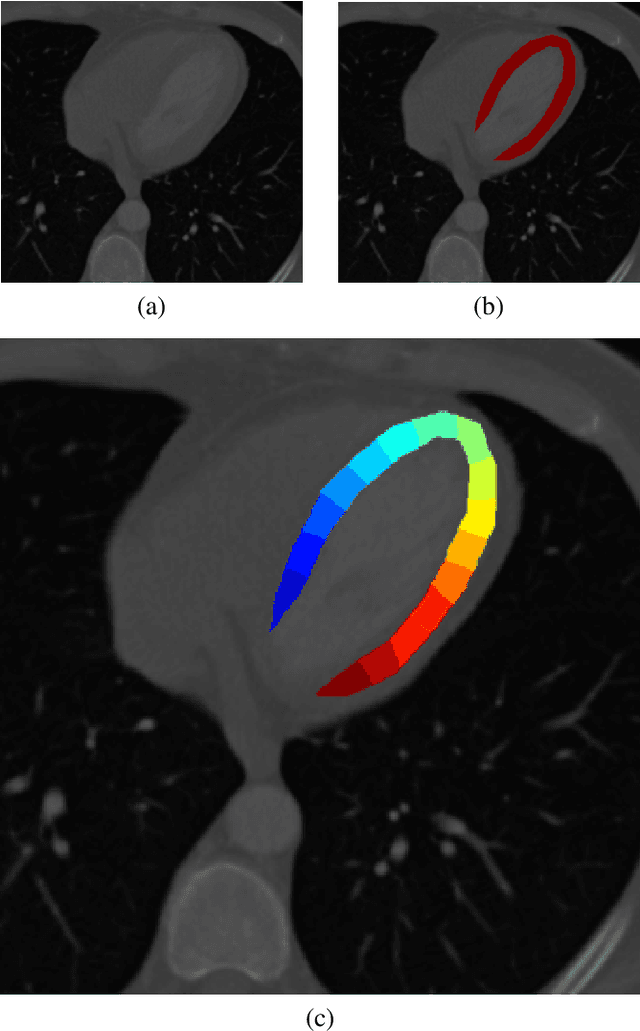
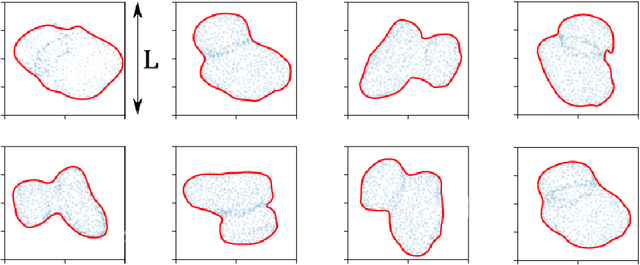
In a wide variety of fields, analysis of images involves defining a region and measuring its inherent properties. Such measurements include a region's surface area, curvature, volume, average gray and/or color scale, and so on. Furthermore, the subsequent subdivision of these regions is sometimes performed. These subdivisions are then used to measure local information, at even finer scales. However, simple griding or manual editing methods are typically used to subdivide a region into smaller units. The resulting subdivisions can therefore either not relate well to the actual shape or property of the region being studied (i.e., gridding methods), or be time consuming and based on user subjectivity (i.e., manual methods). The method discussed in this work extracts subdivisional units based on a region's general shape information. We present the results of applying our method to the medical image analysis of nested regions-of-interest of myocardial wall, where the subdivisions are used to study temporal and/or spatial heterogeneity of myocardial perfusion. This method is of particular interest for creating subdivision regions-of-interest (SROIs) when no variable intensity or other criteria within a region need be used to separate a particular region into subunits.
Graph Learning for Anomaly Analytics: Algorithms, Applications, and Challenges
Dec 11, 2022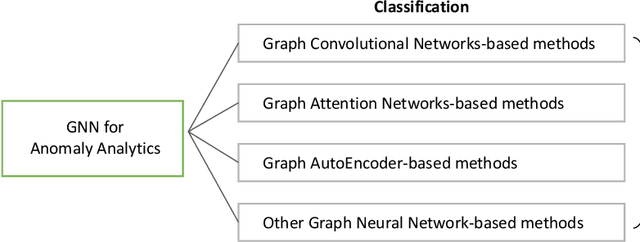
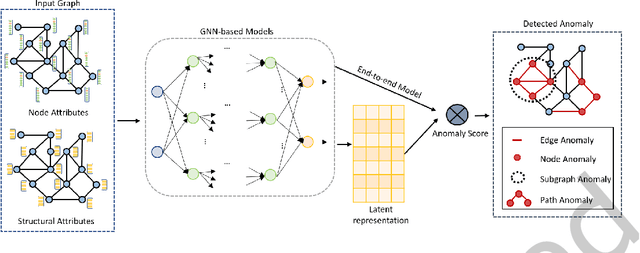
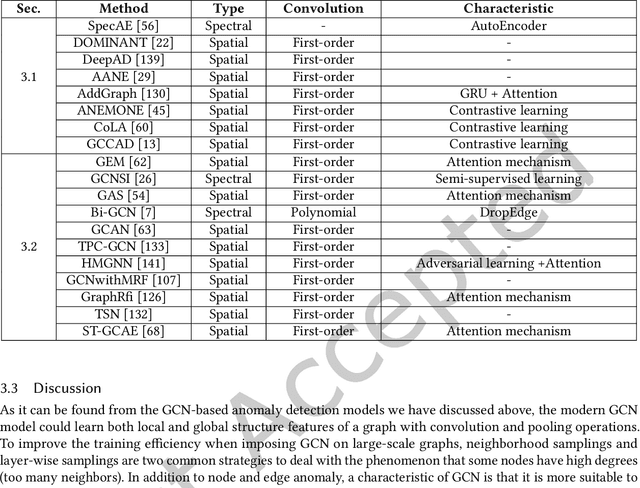
Anomaly analytics is a popular and vital task in various research contexts, which has been studied for several decades. At the same time, deep learning has shown its capacity in solving many graph-based tasks like, node classification, link prediction, and graph classification. Recently, many studies are extending graph learning models for solving anomaly analytics problems, resulting in beneficial advances in graph-based anomaly analytics techniques. In this survey, we provide a comprehensive overview of graph learning methods for anomaly analytics tasks. We classify them into four categories based on their model architectures, namely graph convolutional network (GCN), graph attention network (GAT), graph autoencoder (GAE), and other graph learning models. The differences between these methods are also compared in a systematic manner. Furthermore, we outline several graph-based anomaly analytics applications across various domains in the real world. Finally, we discuss five potential future research directions in this rapidly growing field.
AIONER: All-in-one scheme-based biomedical named entity recognition using deep learning
Dec 19, 2022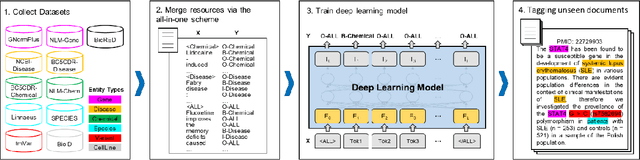
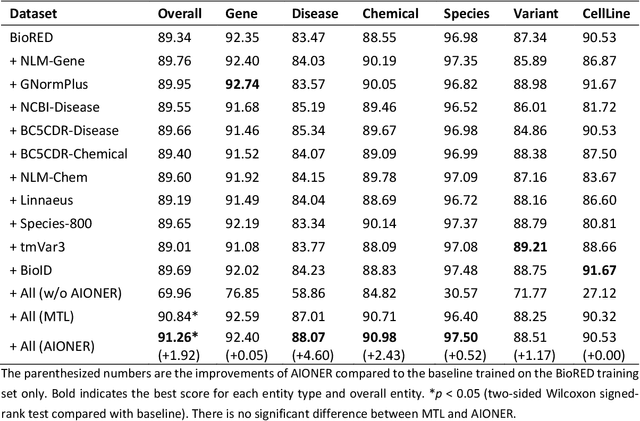
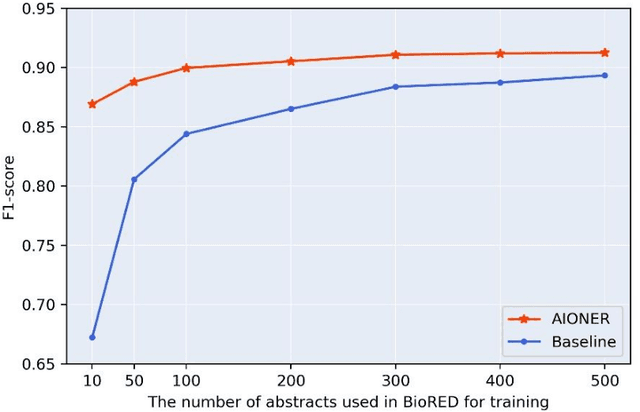
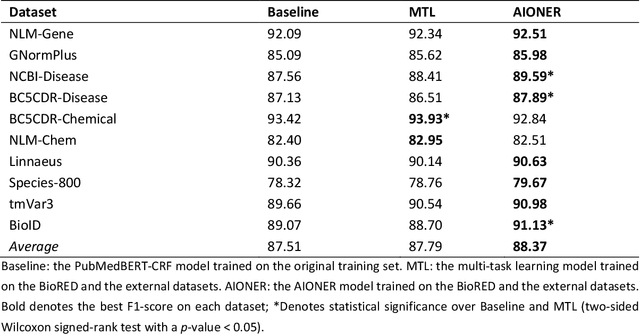
Biomedical named entity recognition (BioNER) seeks to automatically recognize biomedical entities in natural language text, serving as a necessary foundation for downstream text mining tasks and applications such as information extraction and question answering. Manually labeling training data for the BioNER task is costly, however, due to the significant domain expertise required for accurate annotation. The resulting data scarcity causes current BioNER approaches to be prone to overfitting, to suffer from limited generalizability, and to address a single entity type at a time (e.g., gene or disease). We therefore propose a novel all-in-one (AIO) scheme that uses external data from existing annotated resources to improve generalization. We further present AIONER, a general-purpose BioNER tool based on cutting-edge deep learning and our AIO schema. We evaluate AIONER on 14 BioNER benchmark tasks and show that AIONER is effective, robust, and compares favorably to other state-of-the-art approaches such as multi-task learning. We further demonstrate the practical utility of AIONER in three independent tasks to recognize entity types not previously seen in training data, as well as the advantages of AIONER over existing methods for processing biomedical text at a large scale (e.g., the entire PubMed data).