 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Constant Approximation for Normalized Modularity and Associations Clustering
Dec 29, 2022
We study the problem of graph clustering under a broad class of objectives in which the quality of a cluster is defined based on the ratio between the number of edges in the cluster, and the total weight of vertices in the cluster. We show that our definition is closely related to popular clustering measures, namely normalized associations, which is a dual of the normalized cut objective, and normalized modularity. We give a linear time constant-approximate algorithm for our objective, which implies the first constant-factor approximation algorithms for normalized modularity and normalized associations.
MMMNA-Net for Overall Survival Time Prediction of Brain Tumor Patients
Jun 13, 2022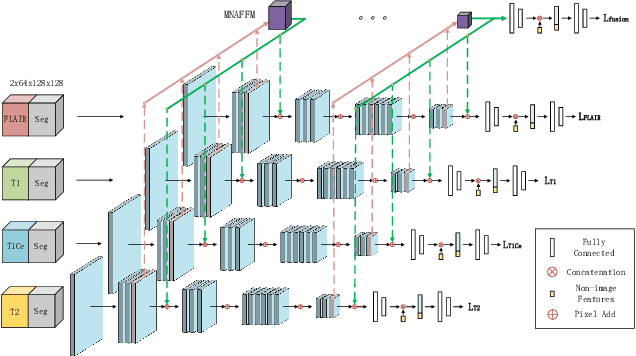
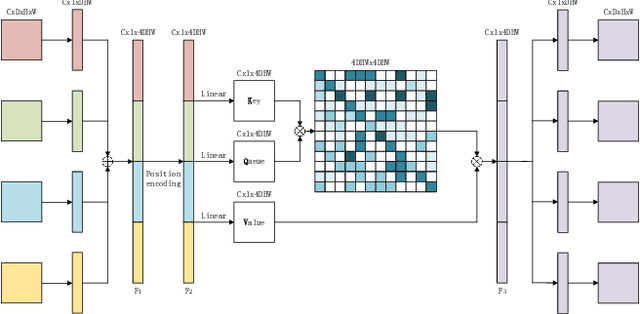
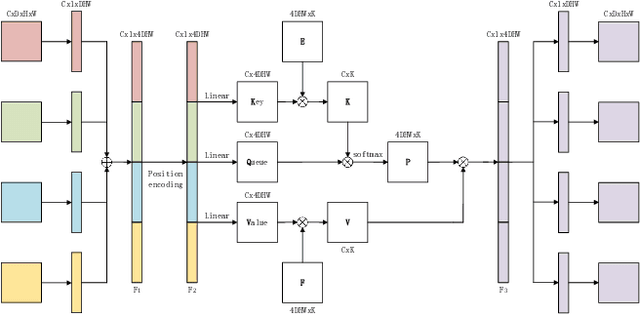
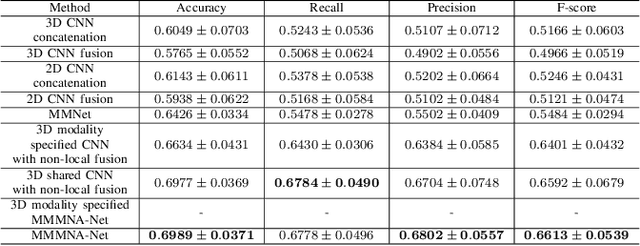
Overall survival (OS) time is one of the most important evaluation indices for gliomas situations. Multimodal Magnetic Resonance Imaging (MRI) scans play an important role in the study of glioma prognosis OS time. Several deep learning-based methods are proposed for the OS time prediction on multi-modal MRI problems. However, these methods usually fuse multi-modal information at the beginning or at the end of the deep learning networks and lack the fusion of features from different scales. In addition, the fusion at the end of networks always adapts global with global (eg. fully connected after concatenation of global average pooling output) or local with local (eg. bilinear pooling), which loses the information of local with global. In this paper, we propose a novel method for multi-modal OS time prediction of brain tumor patients, which contains an improved nonlocal features fusion module introduced on different scales. Our method obtains a relative 8.76% improvement over the current state-of-art method (0.6989 vs. 0.6426 on accuracy). Extensive testing demonstrates that our method could adapt to situations with missing modalities. The code is available at https://github.com/TangWen920812/mmmna-net.
Test-time image-to-image translation ensembling improves out-of-distribution generalization in histopathology
Jun 30, 2022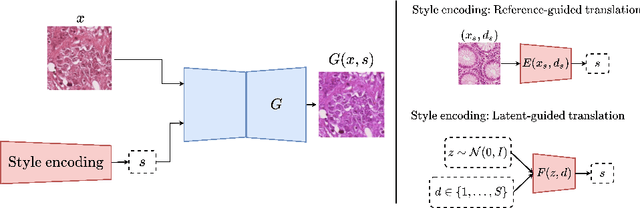
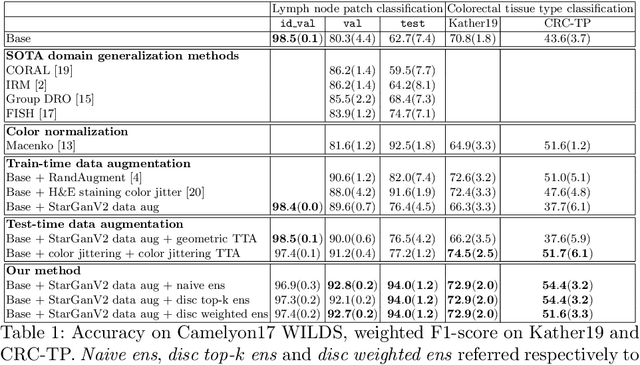
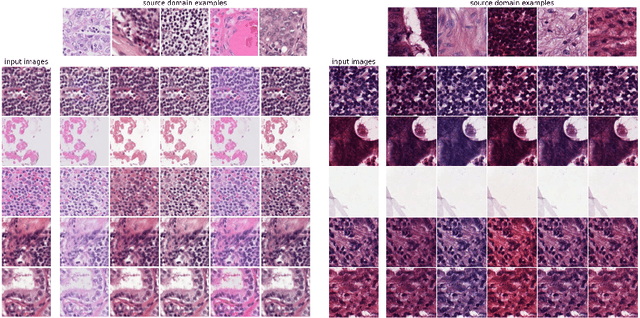
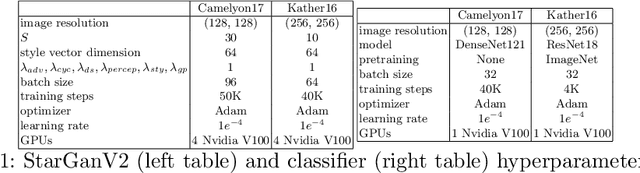
Histopathology whole slide images (WSIs) can reveal significant inter-hospital variability such as illumination, color or optical artifacts. These variations, caused by the use of different scanning protocols across medical centers (staining, scanner), can strongly harm algorithms generalization on unseen protocols. This motivates development of new methods to limit such drop of performances. In this paper, to enhance robustness on unseen target protocols, we propose a new test-time data augmentation based on multi domain image-to-image translation. It allows to project images from unseen protocol into each source domain before classifying them and ensembling the predictions. This test-time augmentation method results in a significant boost of performances for domain generalization. To demonstrate its effectiveness, our method has been evaluated on 2 different histopathology tasks where it outperforms conventional domain generalization, standard H&E specific color augmentation/normalization and standard test-time augmentation techniques. Our code is publicly available at https://gitlab.com/vitadx/articles/test-time-i2i-translation-ensembling.
Towards Rapid Prototyping and Comparability in Active Learning for Deep Object Detection
Dec 21, 2022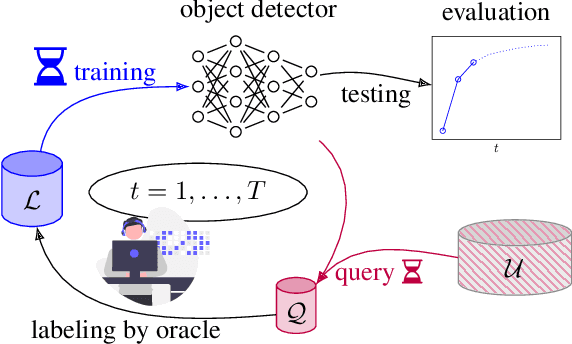
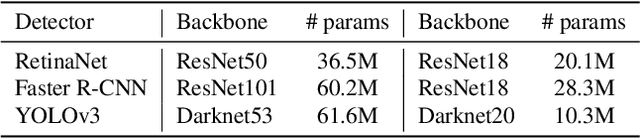

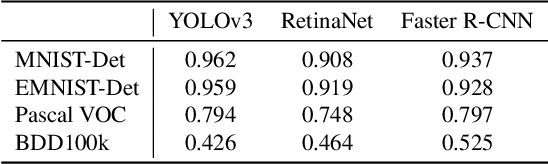
Active learning as a paradigm in deep learning is especially important in applications involving intricate perception tasks such as object detection where labels are difficult and expensive to acquire. Development of active learning methods in such fields is highly computationally expensive and time consuming which obstructs the progression of research and leads to a lack of comparability between methods. In this work, we propose and investigate a sandbox setup for rapid development and transparent evaluation of active learning in deep object detection. Our experiments with commonly used configurations of datasets and detection architectures found in the literature show that results obtained in our sandbox environment are representative of results on standard configurations. The total compute time to obtain results and assess the learning behavior can thereby be reduced by factors of up to 14 when comparing with Pascal VOC and up to 32 when comparing with BDD100k. This allows for testing and evaluating data acquisition and labeling strategies in under half a day and contributes to the transparency and development speed in the field of active learning for object detection.
Predicting Future Mosquito Habitats Using Time Series Climate Forecasting and Deep Learning
Aug 01, 2022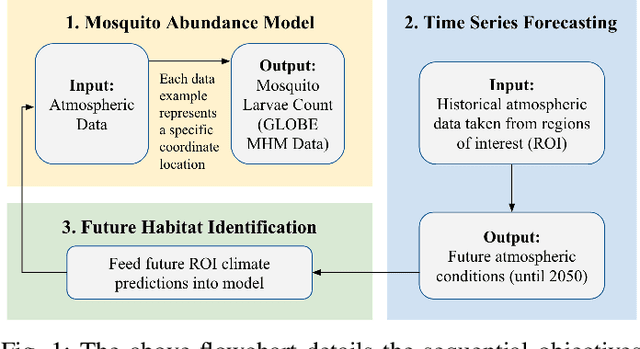
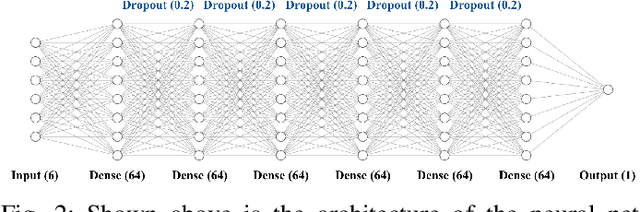
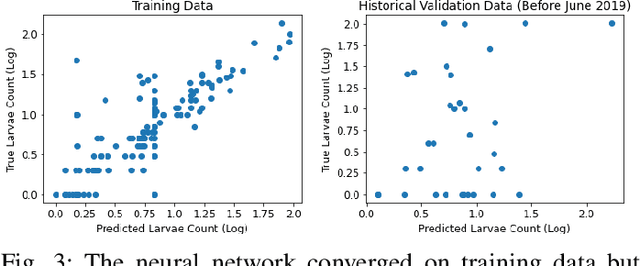
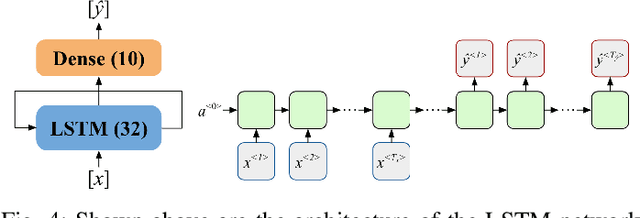
Mosquito habitat ranges are projected to expand due to climate change. This investigation aims to identify future mosquito habitats by analyzing preferred ecological conditions of mosquito larvae. After assembling a data set with atmospheric records and larvae observations, a neural network is trained to predict larvae counts from ecological inputs. Time series forecasting is conducted on these variables and climate projections are passed into the initial deep learning model to generate location-specific larvae abundance predictions. The results support the notion of regional ecosystem-driven changes in mosquito spread, with high-elevation regions in particular experiencing an increase in susceptibility to mosquito infestation.
Spatial-Temporal Anomaly Detection for Sensor Attacks in Autonomous Vehicles
Dec 15, 2022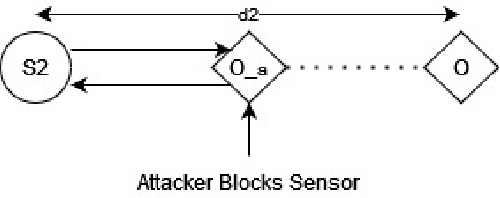
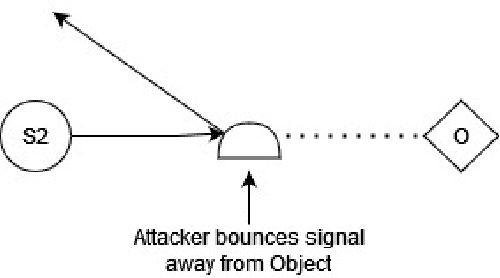
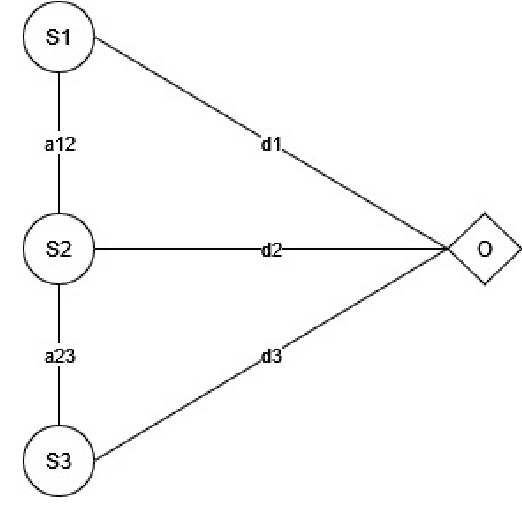
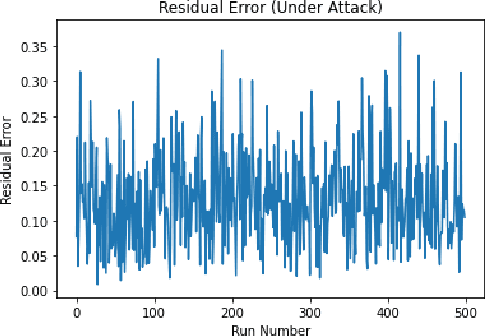
Time-of-flight (ToF) distance measurement devices such as ultrasonics, LiDAR and radar are widely used in autonomous vehicles for environmental perception, navigation and assisted braking control. Despite their relative importance in making safer driving decisions, these devices are vulnerable to multiple attack types including spoofing, triggering and false data injection. When these attacks are successful they can compromise the security of autonomous vehicles leading to severe consequences for the driver, nearby vehicles and pedestrians. To handle these attacks and protect the measurement devices, we propose a spatial-temporal anomaly detection model \textit{STAnDS} which incorporates a residual error spatial detector, with a time-based expected change detection. This approach is evaluated using a simulated quantitative environment and the results show that \textit{STAnDS} is effective at detecting multiple attack types.
Drift Identification for Lévy alpha-Stable Stochastic Systems
Dec 06, 2022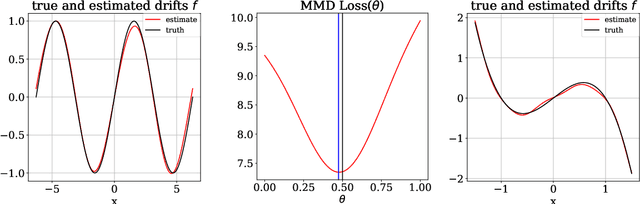
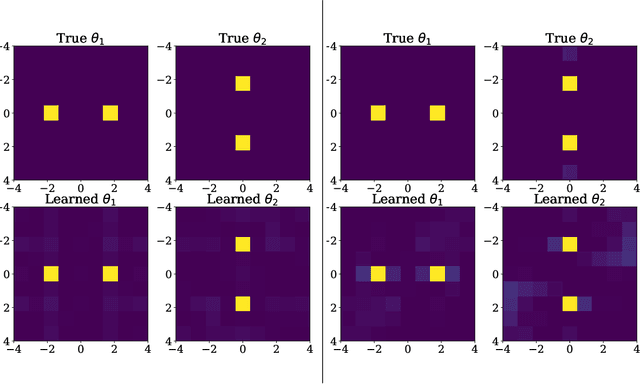
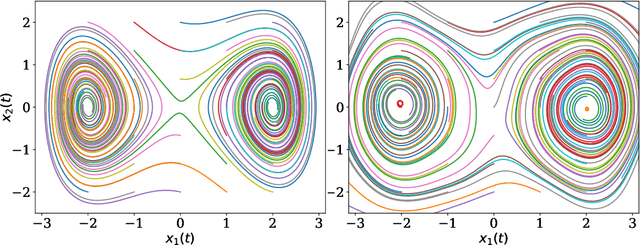
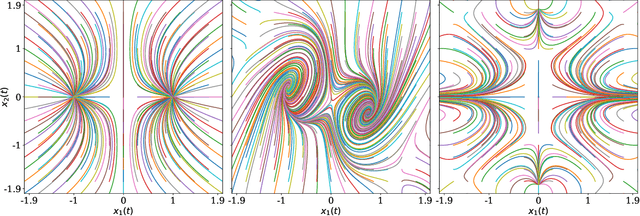
This paper focuses on a stochastic system identification problem: given time series observations of a stochastic differential equation (SDE) driven by L\'{e}vy $\alpha$-stable noise, estimate the SDE's drift field. For $\alpha$ in the interval $[1,2)$, the noise is heavy-tailed, leading to computational difficulties for methods that compute transition densities and/or likelihoods in physical space. We propose a Fourier space approach that centers on computing time-dependent characteristic functions, i.e., Fourier transforms of time-dependent densities. Parameterizing the unknown drift field using Fourier series, we formulate a loss consisting of the squared error between predicted and empirical characteristic functions. We minimize this loss with gradients computed via the adjoint method. For a variety of one- and two-dimensional problems, we demonstrate that this method is capable of learning drift fields in qualitative and/or quantitative agreement with ground truth fields.
Artificial Intelligence to Enhance Mission Science Output for In-situ Observations: Dealing with the Sparse Data Challenge
Dec 26, 2022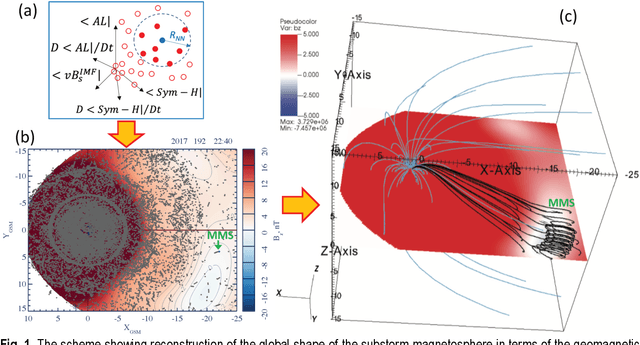
In the Earth's magnetosphere, there are fewer than a dozen dedicated probes beyond low-Earth orbit making in-situ observations at any given time. As a result, we poorly understand its global structure and evolution, the mechanisms of its main activity processes, magnetic storms, and substorms. New Artificial Intelligence (AI) methods, including machine learning, data mining, and data assimilation, as well as new AI-enabled missions will need to be developed to meet this Sparse Data challenge.
End-to-end Unsupervised Learning of Long-Term 3D Stable objects
Jan 09, 2023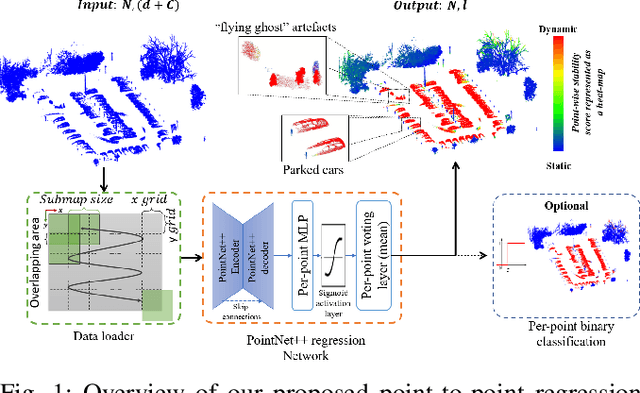
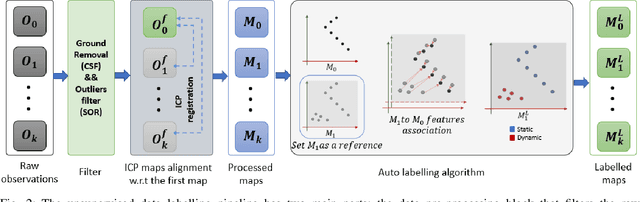
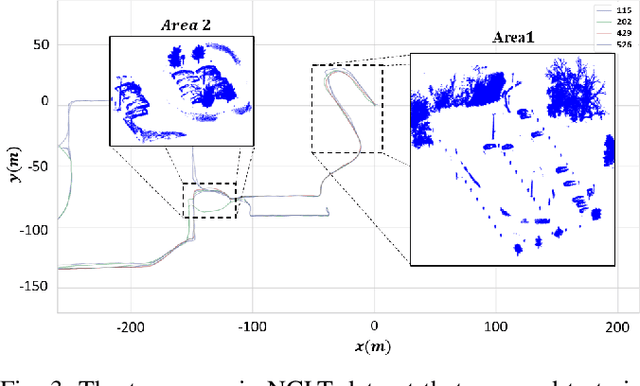
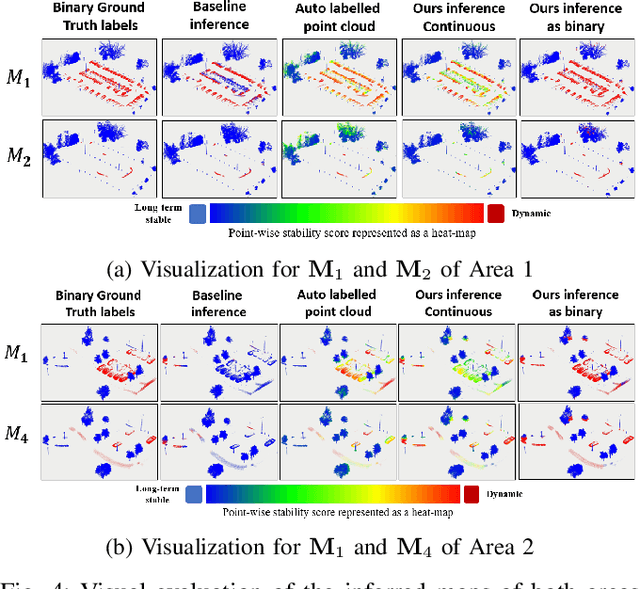
3D point cloud semantic classification is an important task in robotics as it enables a better understanding of the mapped environment. This work proposes to learn the long-term stability of the 3D objects using a neural network based on PointNet++, where the long-term stable object refers to a static object that cannot move on its own (e.g. tree, pole, building). The training data is generated in an unsupervised manner by assigning a continuous label to individual points by exploiting multiple time slices of the same environment. Instead of using discrete labels, i.e. static/dynamic, we propose to use a continuous label value indicating point temporal stability to train a regression PointNet++ network. We evaluated our approach on point cloud data of two parking lots from the NCLT dataset. The experiments' performance reveals that static vs dynamic object classification is best performed by training a regression model, followed by thresholding, compared to directly training a classification model.
Transformers as Algorithms: Generalization and Implicit Model Selection in In-context Learning
Jan 17, 2023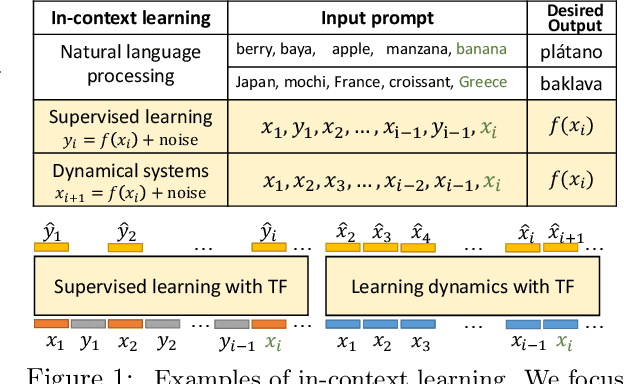
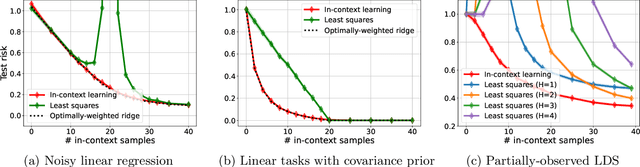
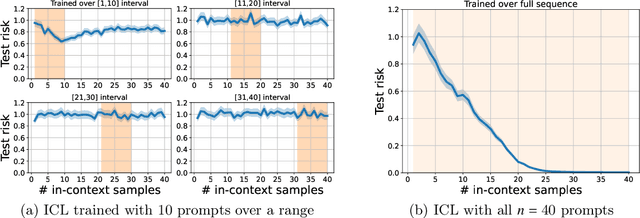
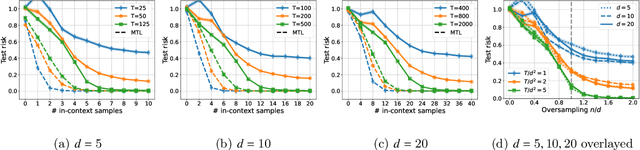
In-context learning (ICL) is a type of prompting where a transformer model operates on a sequence of (input, output) examples and performs inference on-the-fly. This implicit training is in contrast to explicitly tuning the model weights based on examples. In this work, we formalize in-context learning as an algorithm learning problem, treating the transformer model as a learning algorithm that can be specialized via training to implement-at inference-time-another target algorithm. We first explore the statistical aspects of this abstraction through the lens of multitask learning: We obtain generalization bounds for ICL when the input prompt is (1) a sequence of i.i.d. (input, label) pairs or (2) a trajectory arising from a dynamical system. The crux of our analysis is relating the excess risk to the stability of the algorithm implemented by the transformer, which holds under mild assumptions. Secondly, we use our abstraction to show that transformers can act as an adaptive learning algorithm and perform model selection across different hypothesis classes. We provide numerical evaluations that (1) demonstrate transformers can indeed implement near-optimal algorithms on classical regression problems with i.i.d. and dynamic data, (2) identify an inductive bias phenomenon where the transfer risk on unseen tasks is independent of the transformer complexity, and (3) empirically verify our theoretical predictions.