 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning Approaches for Blood Disease Diagnosis Across Hematopoietic Lineages
Mar 25, 2025We present a foundation modeling framework that leverages deep learning to uncover latent genetic signatures across the hematopoietic hierarchy. Our approach trains a fully connected autoencoder on multipotent progenitor cells, reducing over 20,000 gene features to a 256-dimensional latent space that captures predictive information for both progenitor and downstream differentiated cells such as monocytes and lymphocytes. We validate the quality of these embeddings by training feed-forward, transformer, and graph convolutional architectures for blood disease diagnosis tasks. We also explore zero-shot prediction using a progenitor disease state classification model to classify downstream cell conditions. Our models achieve greater than 95% accuracy for multi-class classification, and in the zero-shot setting, we achieve greater than 0.7 F1-score on the binary classification task. Future work should improve embeddings further to increase robustness on lymphocyte classification specifically.
Improving Machine Learning Based Sepsis Diagnosis Using Heart Rate Variability
Aug 01, 2024The early and accurate diagnosis of sepsis is critical for enhancing patient outcomes. This study aims to use heart rate variability (HRV) features to develop an effective predictive model for sepsis detection. Critical HRV features are identified through feature engineering methods, including statistical bootstrapping and the Boruta algorithm, after which XGBoost and Random Forest classifiers are trained with differential hyperparameter settings. In addition, ensemble models are constructed to pool the prediction probabilities of high-recall and high-precision classifiers and improve model performance. Finally, a neural network model is trained on the HRV features, achieving an F1 score of 0.805, a precision of 0.851, and a recall of 0.763. The best-performing machine learning model is compared to this neural network through an interpretability analysis, where Local Interpretable Model-agnostic Explanations are implemented to determine decision-making criterion based on numerical ranges and thresholds for specific features. This study not only highlights the efficacy of HRV in automated sepsis diagnosis but also increases the transparency of black box outputs, maximizing clinical applicability.
Predicting Future Mosquito Habitats Using Time Series Climate Forecasting and Deep Learning
Aug 01, 2022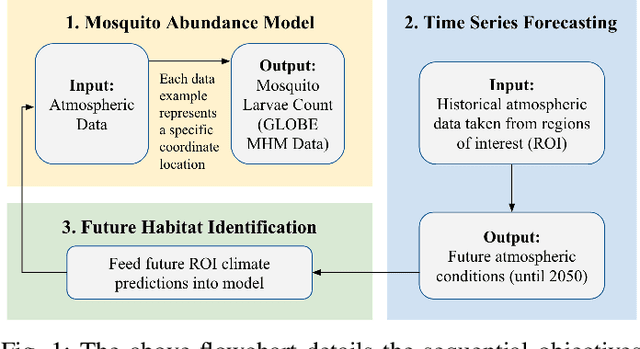
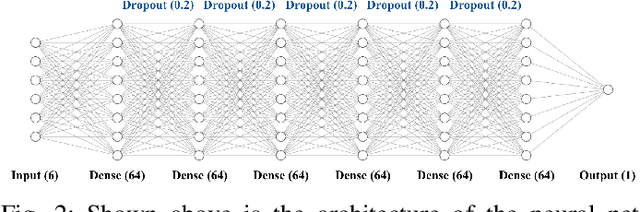
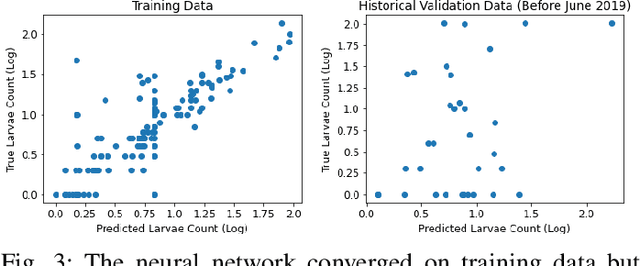
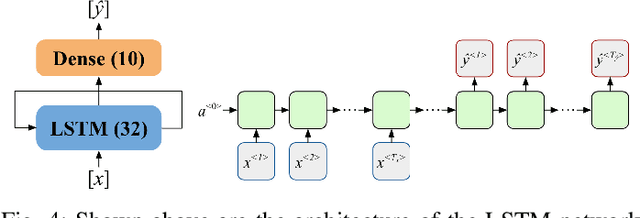
Mosquito habitat ranges are projected to expand due to climate change. This investigation aims to identify future mosquito habitats by analyzing preferred ecological conditions of mosquito larvae. After assembling a data set with atmospheric records and larvae observations, a neural network is trained to predict larvae counts from ecological inputs. Time series forecasting is conducted on these variables and climate projections are passed into the initial deep learning model to generate location-specific larvae abundance predictions. The results support the notion of regional ecosystem-driven changes in mosquito spread, with high-elevation regions in particular experiencing an increase in susceptibility to mosquito infestation.
Analyzing Multispectral Satellite Imagery of South American Wildfires Using CNNs and Unsupervised Learning
Jan 19, 2022


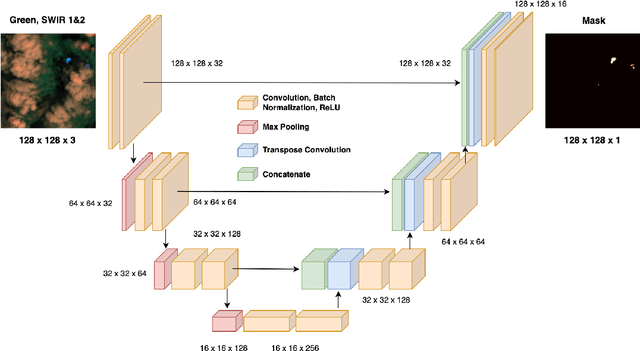
Since severe droughts are occurring more frequently and lengthening the dry season in the Amazon Rainforest, it is important to respond to active wildfires promptly and to forecast them before they become inextinguishable. Though computer vision researchers have applied algorithms on large databases to automatically detect wildfires, current models are computationally expensive and are not versatile enough for the low technology conditions of regions in South America. This comprehensive deep learning study first trains a Fully Convolutional Neural Network with skip connections on multispectral Landsat 8 images of Ecuador and the Galapagos. The model uses Green and Short-wave Infrared bands as inputs to predict each image's corresponding pixel-level binary fire mask. This model achieves a 0.962 validation F2 score and a 0.932 F2 score on test data from Guyana and Suriname. Afterward, image segmentation is conducted on the Cirrus Cloud band using K-Means Clustering to simplify continuous pixel values into three discrete classes representing the degree of cirrus cloud contamination. Two additional Convolutional Neural Networks are trained to classify the presence of a wildfire in a patch of land using these segmented cirrus images. The "experimental" model trained on the segmented inputs achieves 96.5% binary accuracy and has smoother learning curves than the "control model" that is not given the segmented inputs. This proof of concept reveals that feature simplification can improve the performance of wildfire detection models. Overall, the software built in this study is useful for early and accurate detection of wildfires in South America.
Investigating the Relationship Between Dropout Regularization and Model Complexity in Neural Networks
Aug 26, 2021



Dropout Regularization, serving to reduce variance, is nearly ubiquitous in Deep Learning models. We explore the relationship between the dropout rate and model complexity by training 2,000 neural networks configured with random combinations of the dropout rate and the number of hidden units in each dense layer, on each of the three data sets we selected. The generated figures, with binary cross entropy loss and binary accuracy on the z-axis, question the common assumption that adding depth to a dense layer while increasing the dropout rate will certainly enhance performance. We also discover a complex correlation between the two hyperparameters that we proceed to quantify by building additional machine learning and Deep Learning models which predict the optimal dropout rate given some hidden units in each dense layer. Linear regression and polynomial logistic regression require the use of arbitrary thresholds to select the cost data points included in the regression and to assign the cost data points a binary classification, respectively. These machine learning models have mediocre performance because their naive nature prevented the modeling of complex decision boundaries. Turning to Deep Learning models, we build neural networks that predict the optimal dropout rate given the number of hidden units in each dense layer, the desired cost, and the desired accuracy of the model. Though, this attempt encounters a mathematical error that can be attributed to the failure of the vertical line test. The ultimate Deep Learning model is a neural network whose decision boundary represents the 2,000 previously generated data points. This final model leads us to devise a promising method for tuning hyperparameters to minimize computational expense yet maximize performance. The strategy can be applied to any model hyperparameters, with the prospect of more efficient tuning in industrial models.