 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Synthetic Wavelength Imaging -- Utilizing Spectral Correlations for High-Precision Time-of-Flight Sensing
Sep 11, 2022

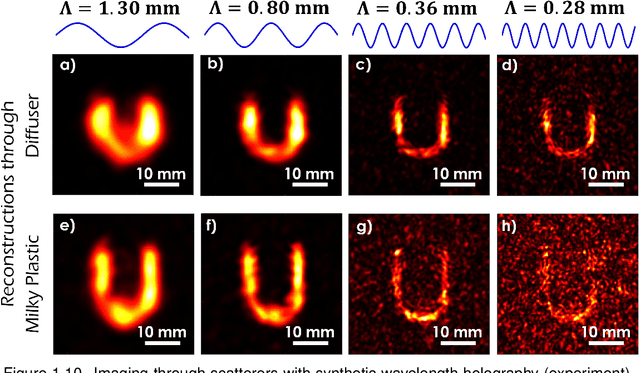
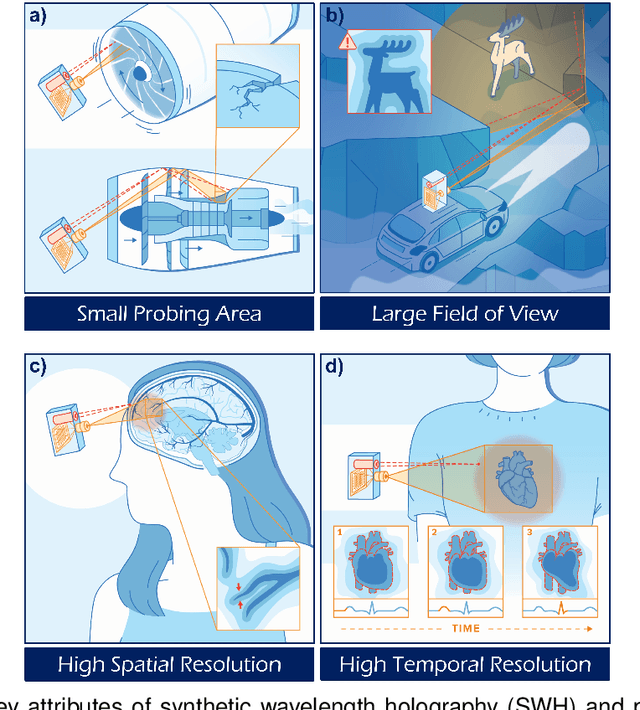
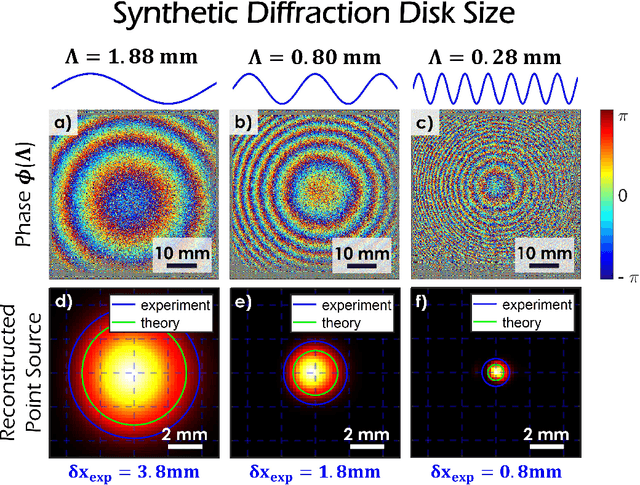
This book chapter describes how spectral correlations in scattered light fields can be utilized for high-precision time-of-flight sensing. The chapter should serve as a gentle introduction and is intended for computational imaging scientists and students new to the fascinating topic of synthetic wavelength imaging. Technical details (such as detector or light source specifications) will be largely omitted. Instead, the similarities between different methods will be emphasized to "draw the bigger picture."
Towards Robust Multivariate Time-Series Forecasting: Adversarial Attacks and Defense Mechanisms
Jul 19, 2022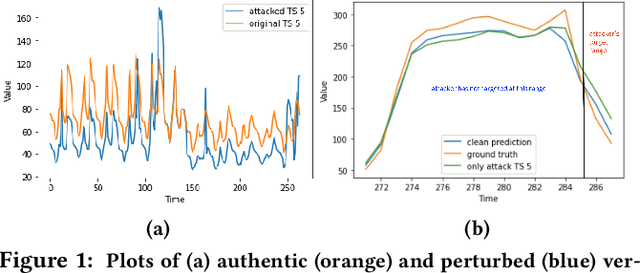
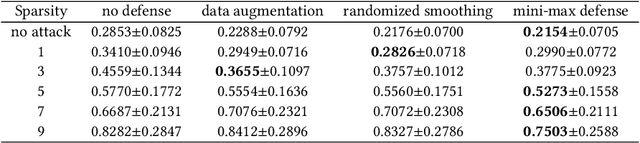

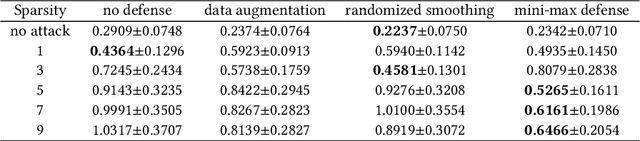
As deep learning models have gradually become the main workhorse of time series forecasting, the potential vulnerability under adversarial attacks to forecasting and decision system accordingly has emerged as a main issue in recent years. Albeit such behaviors and defense mechanisms started to be investigated for the univariate time series forecasting, there are still few studies regarding the multivariate forecasting which is often preferred due to its capacity to encode correlations between different time series. In this work, we study and design adversarial attack on multivariate probabilistic forecasting models, taking into consideration attack budget constraints and the correlation architecture between multiple time series. Specifically, we investigate a sparse indirect attack that hurts the prediction of an item (time series) by only attacking the history of a small number of other items to save attacking cost. In order to combat these attacks, we also develop two defense strategies. First, we adopt randomized smoothing to multivariate time series scenario and verify its effectiveness via empirical experiments. Second, we leverage a sparse attacker to enable end-to-end adversarial training that delivers robust probabilistic forecasters. Extensive experiments on real dataset confirm that our attack schemes are powerful and our defend algorithms are more effective compared with other baseline defense mechanisms.
Energy Prediction using Federated Learning
Jan 22, 2023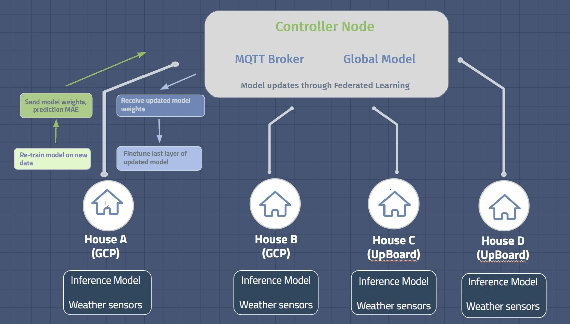
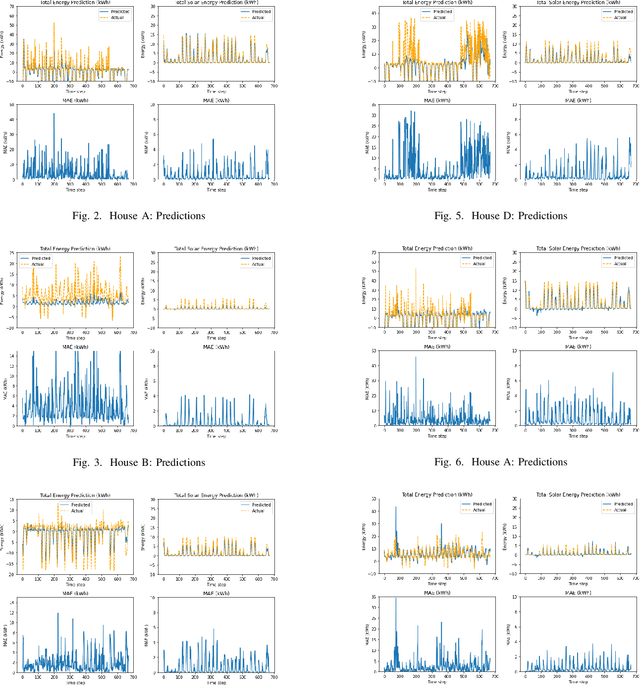
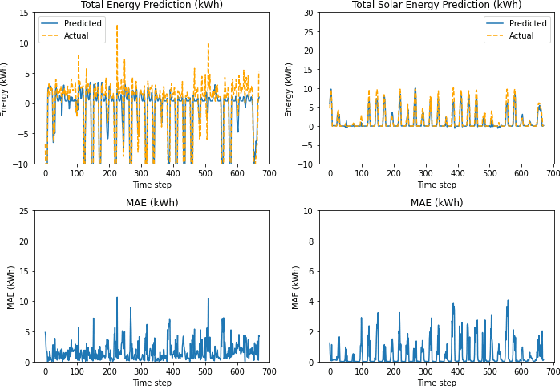
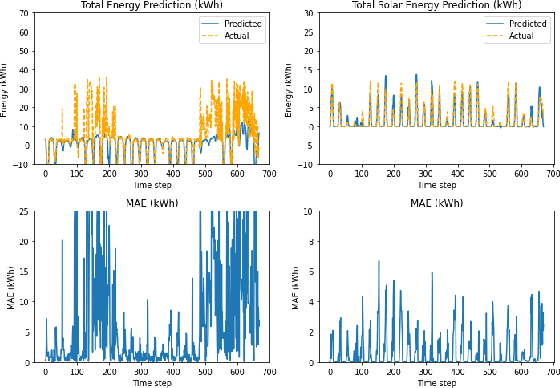
In this work, we demonstrate the viability of using federated learning to successfully predict energy consumption as well as solar production for all households within a certain network using low-power and low-space consuming embedded devices. We also demonstrate our prediction performance improving over time without the need for sharing private consumer energy data. We simulate a system with four nodes using data for one year to show this.
Time-Optimal Handover Trajectory Planning for Aerial Manipulators based on Discrete Mechanics and Complementarity Constraints
Sep 01, 2022
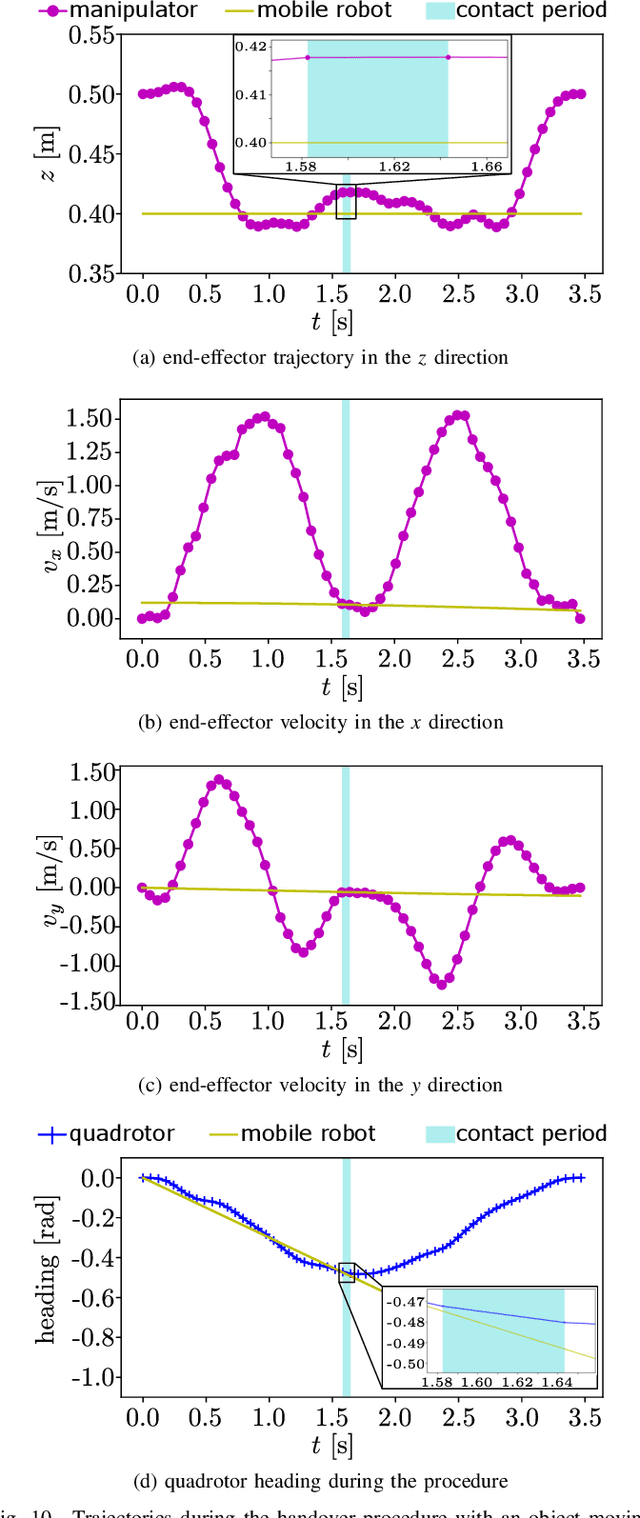
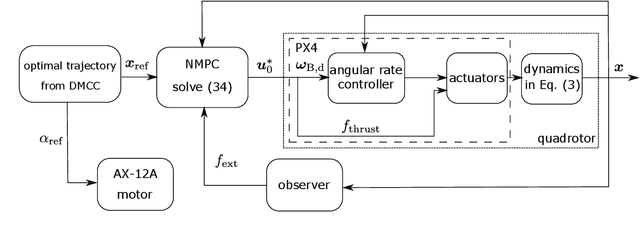
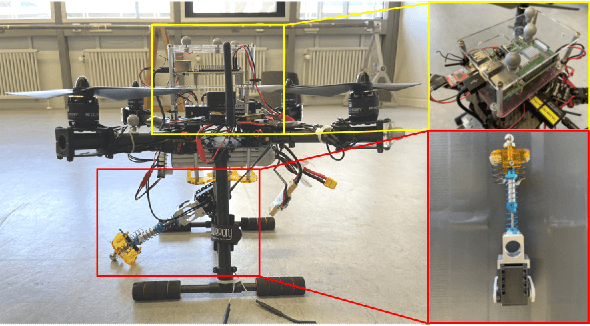
Planning a time-optimal trajectory for aerial robots is critical in many drone applications, such as rescue missions and package delivery, which have been widely researched in recent years. However, it still involves several challenges, particularly when it comes to incorporating special task requirements into the planning as well as the aerial robot's dynamics. In this work, we study a case where an aerial manipulator shall hand over a parcel from a moving mobile robot in a time-optimal manner. Rather than setting up the approach trajectory manually, which makes it difficult to determine the optimal total travel time to accomplish the desired task within dynamic limits, we propose an optimization framework, which combines discrete mechanics and complementarity constraints (DMCC) together. In the proposed framework, the system dynamics is constrained with the discrete variational Lagrangian mechanics that provides reliable estimation results also according to our experiments. The handover opportunities are automatically determined and arranged based on the desired complementarity constraints. Finally, the performance of the proposed framework is verified with numerical simulations and hardware experiments with our self-designed aerial manipulators.
An Efficient Convex Hull-Based Vehicle Pose Estimation Method for 3D LiDAR
Feb 02, 2023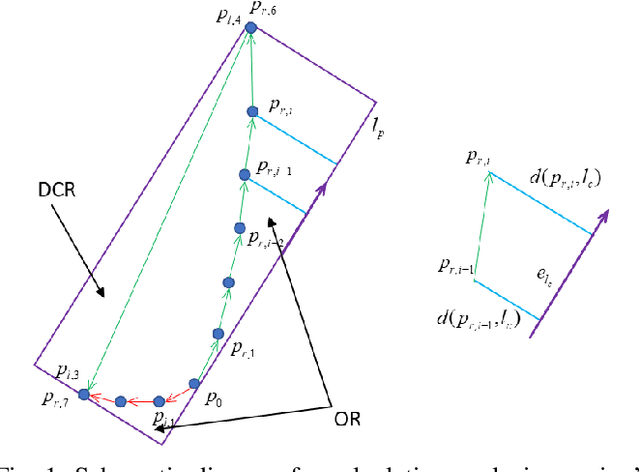
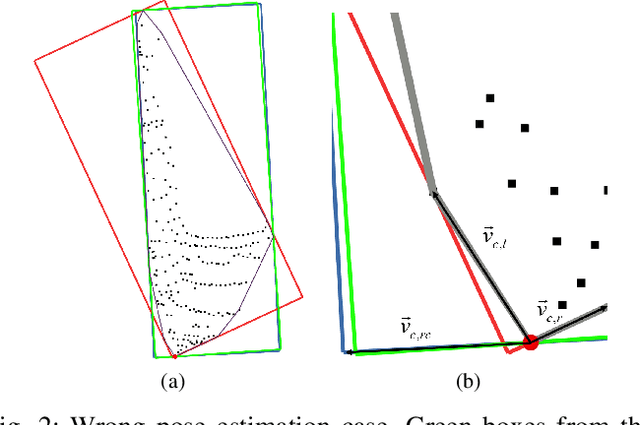
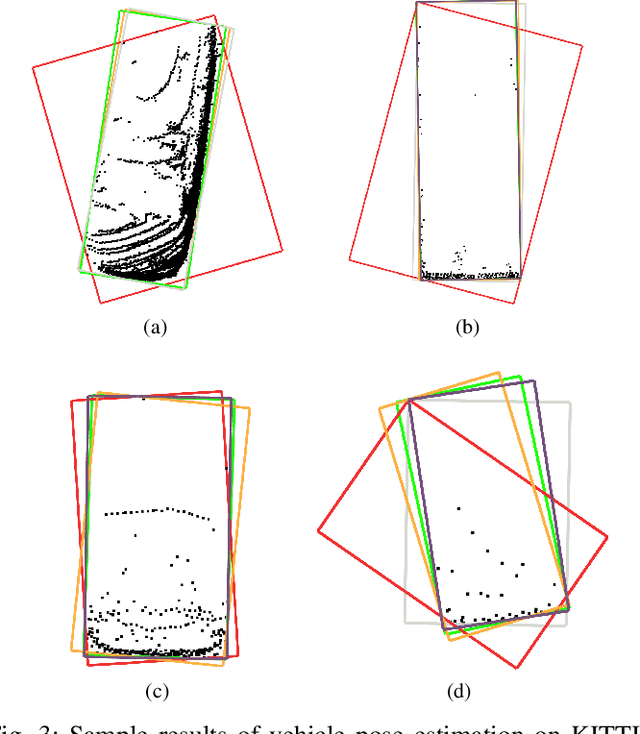
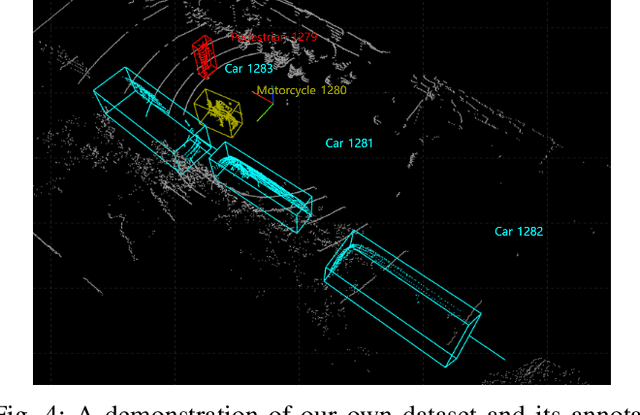
Vehicle pose estimation is essential in the perception technology of autonomous driving. However, due to the different density distributions of the LiDAR point cloud, it is challenging to achieve accurate direction extraction based on 3D LiDAR by using the existing pose estimation methods. In this paper, we proposed a novel convex hull-based vehicle pose estimation method. The extracted 3D cluster is reduced to the convex hull, reducing the computation burden. Then a novel criterion based on the minimum occlusion area is developed for the search-based algorithm, which can achieve accurate pose estimation. The proposed algorithm is validated on the KITTI dataset and a manually labeled dataset acquired at an industrial park. The results show that our proposed method can achieve better accuracy than the three mainstream algorithms while maintaining real-time speed.
A survey on online active learning
Feb 17, 2023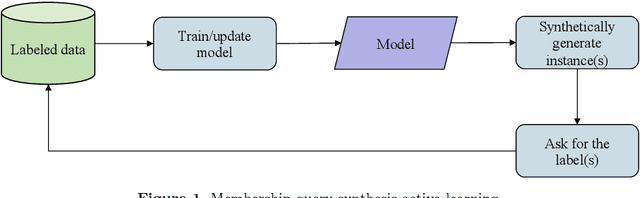
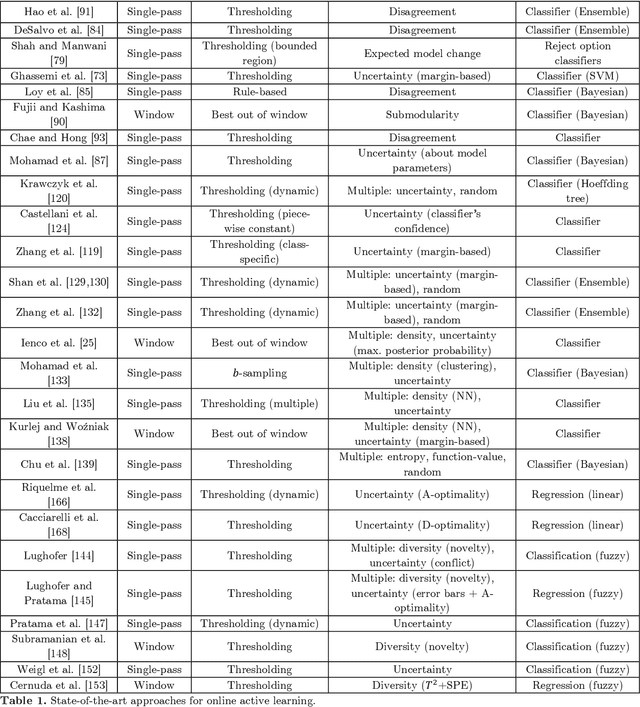
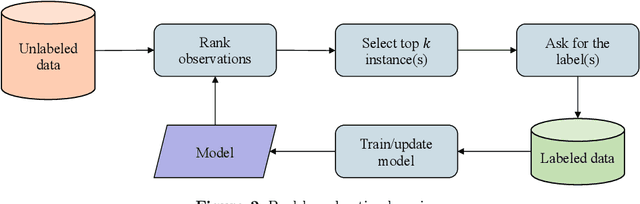
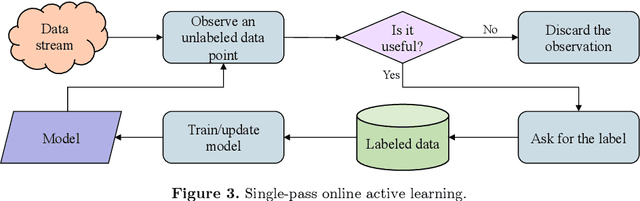
Online active learning is a paradigm in machine learning that aims to select the most informative data points to label from a data stream. The problem of minimizing the cost associated with collecting labeled observations has gained a lot of attention in recent years, particularly in real-world applications where data is only available in an unlabeled form. Annotating each observation can be time-consuming and costly, making it difficult to obtain large amounts of labeled data. To overcome this issue, many active learning strategies have been proposed in the last decades, aiming to select the most informative observations for labeling in order to improve the performance of machine learning models. These approaches can be broadly divided into two categories: static pool-based and stream-based active learning. Pool-based active learning involves selecting a subset of observations from a closed pool of unlabeled data, and it has been the focus of many surveys and literature reviews. However, the growing availability of data streams has led to an increase in the number of approaches that focus on online active learning, which involves continuously selecting and labeling observations as they arrive in a stream. This work aims to provide an overview of the most recently proposed approaches for selecting the most informative observations from data streams in the context of online active learning. We review the various techniques that have been proposed and discuss their strengths and limitations, as well as the challenges and opportunities that exist in this area of research. Our review aims to provide a comprehensive and up-to-date overview of the field and to highlight directions for future work.
Binary Embedding-based Retrieval at Tencent
Feb 17, 2023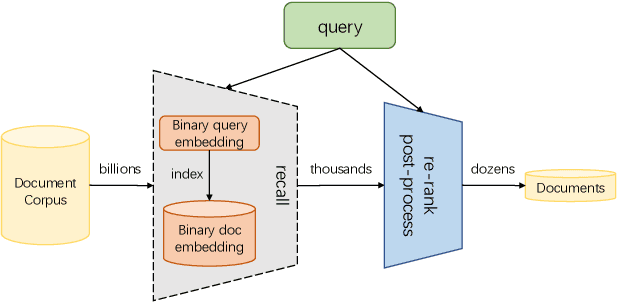

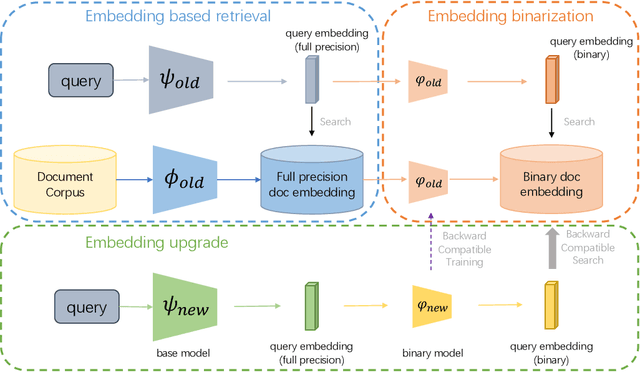

Large-scale embedding-based retrieval (EBR) is the cornerstone of search-related industrial applications. Given a user query, the system of EBR aims to identify relevant information from a large corpus of documents that may be tens or hundreds of billions in size. The storage and computation turn out to be expensive and inefficient with massive documents and high concurrent queries, making it difficult to further scale up. To tackle the challenge, we propose a binary embedding-based retrieval (BEBR) engine equipped with a recurrent binarization algorithm that enables customized bits per dimension. Specifically, we compress the full-precision query and document embeddings, formulated as float vectors in general, into a composition of multiple binary vectors using a lightweight transformation model with residual multilayer perception (MLP) blocks. We can therefore tailor the number of bits for different applications to trade off accuracy loss and cost savings. Importantly, we enable task-agnostic efficient training of the binarization model using a new embedding-to-embedding strategy. We also exploit the compatible training of binary embeddings so that the BEBR engine can support indexing among multiple embedding versions within a unified system. To further realize efficient search, we propose Symmetric Distance Calculation (SDC) to achieve lower response time than Hamming codes. We successfully employed the introduced BEBR to Tencent products, including Sogou, Tencent Video, QQ World, etc. The binarization algorithm can be seamlessly generalized to various tasks with multiple modalities. Extensive experiments on offline benchmarks and online A/B tests demonstrate the efficiency and effectiveness of our method, significantly saving 30%~50% index costs with almost no loss of accuracy at the system level.
OTFS -- A Mathematical Foundation for Communication and Radar Sensing in the Delay-Doppler Domain
Feb 17, 2023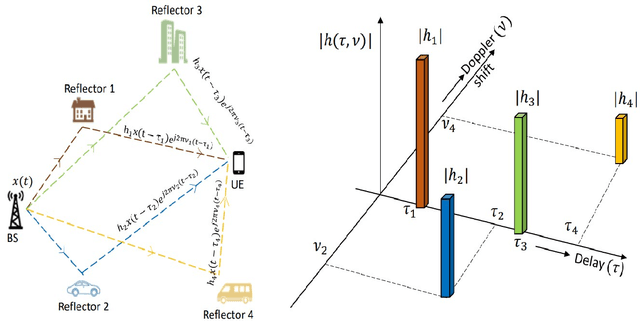
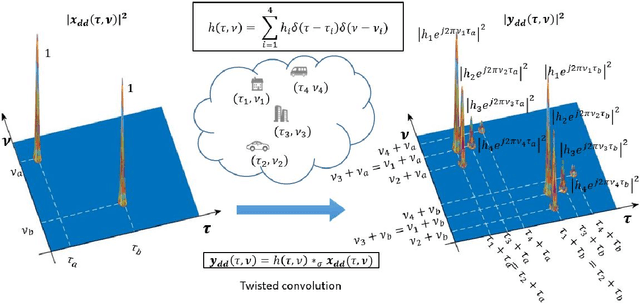
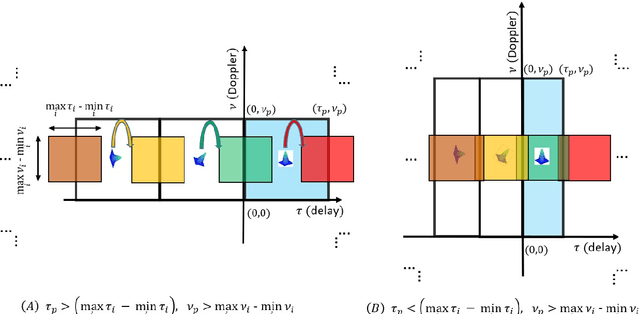
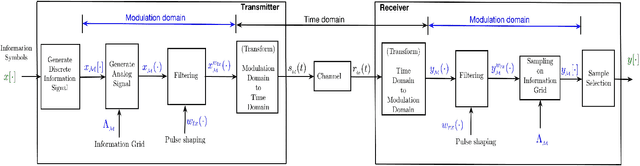
Orthogonal time frequency space (OTFS) is a framework for communication and active sensing that processes signals in the delay-Doppler (DD) domain. This paper explores three key features of the OTFS framework, and explains their value to applications. The first feature is a compact and sparse DD domain parameterization of the wireless channel, where the parameters map directly to physical attributes of the reflectors that comprise the scattering environment, and as a consequence these parameters evolve predictably. The second feature is a novel waveform / modulation technique, matched to the DD channel model, that embeds information symbols in the DD domain. The relation between channel inputs and outputs is localized, non-fading and predictable, even in the presence of significant delay and Doppler spread, and as a consequence the channel can be efficiently acquired and equalized. By avoiding fading, the post equalization SNR remains constant across all information symbols in a packet, so that bit error performance is superior to contemporary multi-carrier waveforms. Further, the OTFS carrier waveform is a localized pulse in the DD domain, making it possible to separate reflectors along both delay and Doppler simultaneously, and to achieve a high-resolution delay-Doppler radar image of the environment. In other words, the DD parameterization provides a common mathematical framework for communication and radar. This is the third feature of the OTFS framework, and it is ideally suited to intelligent transportation systems involving self-driving cars and unmanned ground/aerial vehicles which are self/network controlled. The OTFS waveform is able to support stable and superior performance over a wide range of user speeds.
Combining Generative Artificial Intelligence (AI) and the Internet: Heading towards Evolution or Degradation?
Feb 17, 2023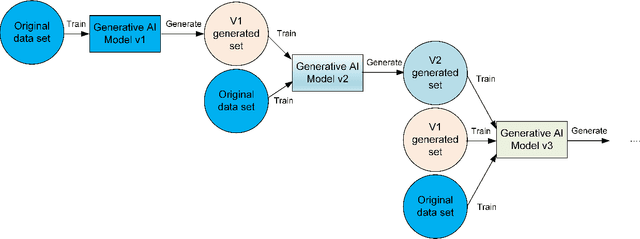



In the span of a few months, generative Artificial Intelligence (AI) tools that can generate realistic images or text have taken the Internet by storm, making them one of the technologies with fastest adoption ever. Some of these generative AI tools such as DALL-E, MidJourney, or ChatGPT have gained wide public notoriety. Interestingly, these tools are possible because of the massive amount of data (text and images) available on the Internet. The tools are trained on massive data sets that are scraped from Internet sites. And now, these generative AI tools are creating massive amounts of new data that are being fed into the Internet. Therefore, future versions of generative AI tools will be trained with Internet data that is a mix of original and AI-generated data. As time goes on, a mixture of original data and data generated by different versions of AI tools will populate the Internet. This raises a few intriguing questions: how will future versions of generative AI tools behave when trained on a mixture of real and AI generated data? Will they evolve with the new data sets or degenerate? Will evolution introduce biases in subsequent generations of generative AI tools? In this document, we explore these questions and report some very initial simulation results using a simple image-generation AI tool. These results suggest that the quality of the generated images degrades as more AI-generated data is used for training thus suggesting that generative AI may degenerate. Although these results are preliminary and cannot be generalised without further study, they serve to illustrate the potential issues of the interaction between generative AI and the Internet.
Improved High-Probability Regret for Adversarial Bandits with Time-Varying Feedback Graphs
Oct 04, 2022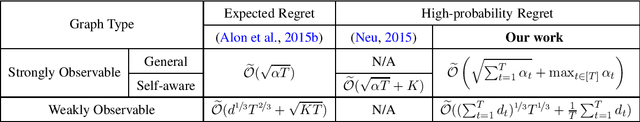
We study high-probability regret bounds for adversarial $K$-armed bandits with time-varying feedback graphs over $T$ rounds. For general strongly observable graphs, we develop an algorithm that achieves the optimal regret $\widetilde{\mathcal{O}}((\sum_{t=1}^T\alpha_t)^{1/2}+\max_{t\in[T]}\alpha_t)$ with high probability, where $\alpha_t$ is the independence number of the feedback graph at round $t$. Compared to the best existing result [Neu, 2015] which only considers graphs with self-loops for all nodes, our result not only holds more generally, but importantly also removes any $\text{poly}(K)$ dependence that can be prohibitively large for applications such as contextual bandits. Furthermore, we also develop the first algorithm that achieves the optimal high-probability regret bound for weakly observable graphs, which even improves the best expected regret bound of [Alon et al., 2015] by removing the $\mathcal{O}(\sqrt{KT})$ term with a refined analysis. Our algorithms are based on the online mirror descent framework, but importantly with an innovative combination of several techniques. Notably, while earlier works use optimistic biased loss estimators for achieving high-probability bounds, we find it important to use a pessimistic one for nodes without self-loop in a strongly observable graph.