 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Cold-Start Safety Gap in LLM Agents
Jun 05, 2026Are tool-calling LLM agents equally safe throughout a conversation? We discover they are not: agents are most vulnerable at the very start of a session and become substantially safer after a few regular agentic tasks -- a phenomenon we term the cold-start safety gap. To study this systematically, we introduce Safety Over Depth for Agents (SODA), a benchmark that controls how many regular agentic tasks the agent completes before encountering a safety threat, supporting up to 20 preceding tasks. Evaluating 7 models from 4 families, safety improves by 9--52% as the number of preceding regular agentic tasks increases from zero to twenty. Representation analysis confirms that model hidden states gradually shift toward a safety-aligned region as more preceding tasks are present. By systematically studying which part of the preceding conversation matters most, we find that the regular agentic tasks themselves are the primary driver of safety, while the agent's own prior responses have less effect on safety but are essential for preserving later utility. This conclusion is further supported by evaluation on open-source safety benchmarks (AgentHarm, Agent Safety Bench) and utility benchmarks (BFCL, API-Bank), confirming that warming up the agent with regular agentic tasks before deployment makes it safer and preserves full capability. Based on these findings, we recommend a simple deployment strategy: having the agent complete a few regular agentic tasks before possible exposure to safety-critical requests mitigates the cold-start safety gap. Our code is available at https://github.com/Trustworthy-ML-Lab/Agent-Cold-Start-Safety-Gap
LLM Agents Already Know When to Call Tools -- Even Without Reasoning
May 10, 2026Tool-augmented LLM agents tend to call tools indiscriminately, even when the model can answer directly. Each unnecessary call wastes API fees and latency, yet no existing benchmark systematically studies when a tool call is actually needed. We propose When2Tool, a benchmark of 18 environments (15 single-hop, 3 multi-hop) spanning three categories of tool necessity -- computational scale, knowledge boundaries, and execution reliability -- each with controlled difficulty levels that create a clear decision boundary between tool-necessary and tool-unnecessary tasks. We evaluate two families of training-free baselines: Prompt-only (varying the prompt to discourage unnecessary calls) and Reason-then-Act (requiring the model to reason about tool necessity before acting). Both provide limited control: Prompt-only suppresses necessary calls alongside unnecessary ones, and Reason-then-Act still incurs a disproportionate accuracy cost on hard tasks. To understand why these baselines fail, we probe the models' hidden states and find that tool necessity is linearly decodable from the pre-generation representation with AUROC 0.89--0.96 across six models, substantially exceeding the model's own verbalized reasoning. This reveals that models already know when tools are needed, but fail to act on this knowledge during generation. Building on this finding, we propose Probe&Prefill, which uses a lightweight linear probe to read the hidden-state signal and prefills the model's response with a steering sentence. Across all models tested, Probe&Prefill reduces tool calls by 48% with only 1.7% accuracy loss, while the best baseline at comparable accuracy only reduces 6% of tool calls, or achieves a similar tool call reduction but incurs a 5$\times$ higher accuracy loss. Our code is available at https://github.com/Trustworthy-ML-Lab/when2tool
CLEAR: Context Augmentation from Contrastive Learning of Experience via Agentic Reflection
Apr 08, 2026Large language model agents rely on effective model context to obtain task-relevant information for decision-making. Many existing context engineering approaches primarily rely on the context generated from the past experience and retrieval mechanisms that reuse these context. However, retrieved context from past tasks must be adapted by the execution agent to fit new situations, placing additional reasoning burden on the underlying LLM. To address this limitation, we propose a generative context augmentation framework using Contrastive Learning of Experience via Agentic Reflection (CLEAR). CLEAR first employs a reflection agent to perform contrastive analysis over past execution trajectories and summarize useful context for each observed task. These summaries are then used as supervised fine-tuning data to train a context augmentation model (CAM). Then we further optimize CAM using reinforcement learning, where the reward signal is obtained by running the task execution agent. By learning to generate task-specific knowledge rather than retrieve knowledge from the past, CAM produces context that is better tailored to the current task. We conduct comprehensive evaluations on the AppWorld and WebShop benchmarks. Experimental results show that CLEAR consistently outperforms strong baselines. It improves task completion rate from 72.62% to 81.15% on AppWorld test set and averaged reward from 0.68 to 0.74 on a subset of WebShop, compared with baseline agent. Our code is publicly available at https://github.com/awslabs/CLEAR.
Toward ground-truth optical coherence tomography via three-dimensional unsupervised deep learning processing and data
Nov 07, 2023



Optical coherence tomography (OCT) can perform non-invasive high-resolution three-dimensional (3D) imaging and has been widely used in biomedical fields, while it is inevitably affected by coherence speckle noise which degrades OCT imaging performance and restricts its applications. Here we present a novel speckle-free OCT imaging strategy, named toward-ground-truth OCT (tGT-OCT), that utilizes unsupervised 3D deep-learning processing and leverages OCT 3D imaging features to achieve speckle-free OCT imaging. Specifically, our proposed tGT-OCT utilizes an unsupervised 3D-convolution deep-learning network trained using random 3D volumetric data to distinguish and separate speckle from real structures in 3D imaging volumetric space; moreover, tGT-OCT effectively further reduces speckle noise and reveals structures that would otherwise be obscured by speckle noise while preserving spatial resolution. Results derived from different samples demonstrated the high-quality speckle-free 3D imaging performance of tGT-OCT and its advancement beyond the previous state-of-the-art.
Promoting Robustness of Randomized Smoothing: Two Cost-Effective Approaches
Oct 11, 2023



Randomized smoothing has recently attracted attentions in the field of adversarial robustness to provide provable robustness guarantees on smoothed neural network classifiers. However, existing works show that vanilla randomized smoothing usually does not provide good robustness performance and often requires (re)training techniques on the base classifier in order to boost the robustness of the resulting smoothed classifier. In this work, we propose two cost-effective approaches to boost the robustness of randomized smoothing while preserving its clean performance. The first approach introduces a new robust training method AdvMacerwhich combines adversarial training and robustness certification maximization for randomized smoothing. We show that AdvMacer can improve the robustness performance of randomized smoothing classifiers compared to SOTA baselines, while being 3x faster to train than MACER baseline. The second approach introduces a post-processing method EsbRS which greatly improves the robustness certificate based on building model ensembles. We explore different aspects of model ensembles that has not been studied by prior works and propose a novel design methodology to further improve robustness of the ensemble based on our theoretical analysis.
Towards Robust Multivariate Time-Series Forecasting: Adversarial Attacks and Defense Mechanisms
Jul 19, 2022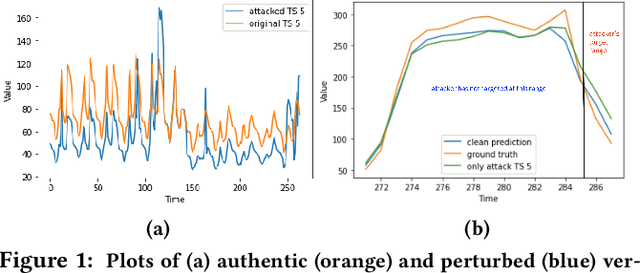
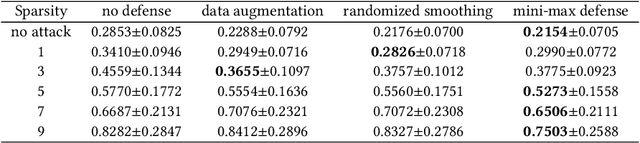

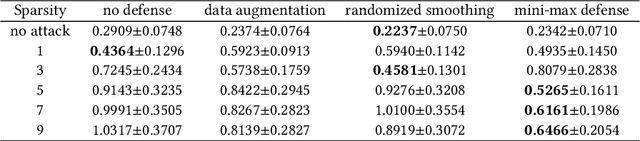
As deep learning models have gradually become the main workhorse of time series forecasting, the potential vulnerability under adversarial attacks to forecasting and decision system accordingly has emerged as a main issue in recent years. Albeit such behaviors and defense mechanisms started to be investigated for the univariate time series forecasting, there are still few studies regarding the multivariate forecasting which is often preferred due to its capacity to encode correlations between different time series. In this work, we study and design adversarial attack on multivariate probabilistic forecasting models, taking into consideration attack budget constraints and the correlation architecture between multiple time series. Specifically, we investigate a sparse indirect attack that hurts the prediction of an item (time series) by only attacking the history of a small number of other items to save attacking cost. In order to combat these attacks, we also develop two defense strategies. First, we adopt randomized smoothing to multivariate time series scenario and verify its effectiveness via empirical experiments. Second, we leverage a sparse attacker to enable end-to-end adversarial training that delivers robust probabilistic forecasters. Extensive experiments on real dataset confirm that our attack schemes are powerful and our defend algorithms are more effective compared with other baseline defense mechanisms.