 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Pay Less But Get More: A Dual-Attention-based Channel Estimation Network for Massive MIMO Systems with Low-Density Pilots
Mar 02, 2023
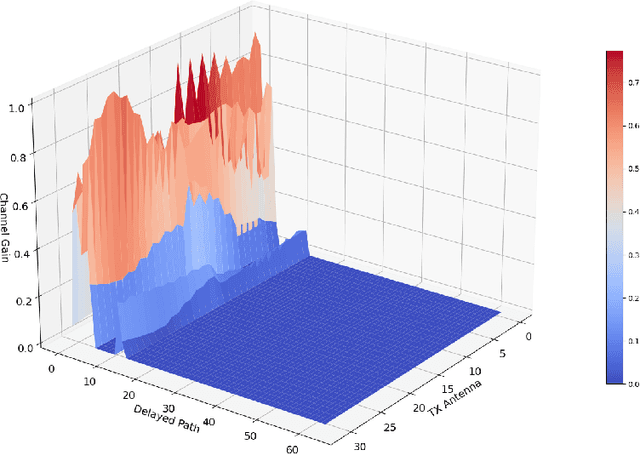
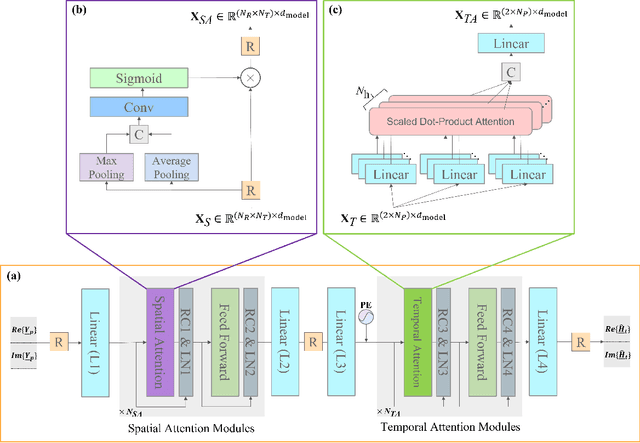
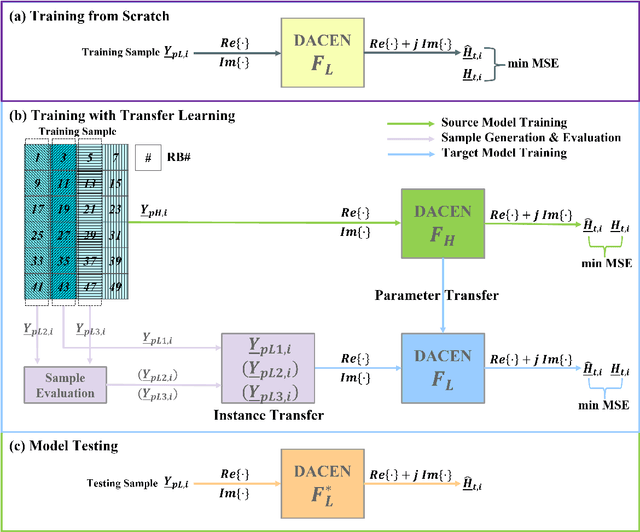
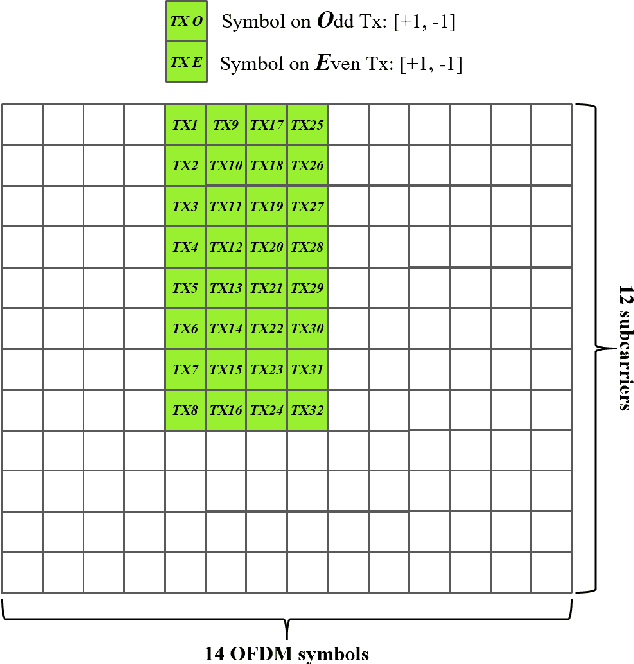
To reap the promising benefits of massive multiple-input multiple-output (MIMO) systems, accurate channel state information (CSI) is required through channel estimation. However, due to the complicated wireless propagation environment and large-scale antenna arrays, precise channel estimation for massive MIMO systems is significantly challenging and costs an enormous training overhead. Considerable time-frequency resources are consumed to acquire sufficient accuracy of CSI, which thus severely degrades systems' spectral and energy efficiencies. In this paper, we propose a dual-attention-based channel estimation network (DACEN) to realize accurate channel estimation via low-density pilots, by decoupling the spatial-temporal domain features of massive MIMO channels with the temporal attention module and the spatial attention module. To further improve the estimation accuracy, we propose a parameter-instance transfer learning approach based on the DACEN to transfer the channel knowledge learned from the high-density pilots pre-acquired during the training dataset collection period. Experimental results on a publicly available dataset reveal that the proposed DACEN-based method with low-density pilots ($\rho_L=6/52$) achieves better channel estimation performance than the existing methods even with higher-density pilots ($\rho_H=26/52$). Additionally, with the proposed transfer learning approach, the DACEN-based method with ultra-low-density pilots ($\rho_L^\prime=2/52$) achieves higher estimation accuracy than the existing methods with low-density pilots, thereby demonstrating the effectiveness and the superiority of the proposed method.
Image Labels Are All You Need for Coarse Seagrass Segmentation
Mar 02, 2023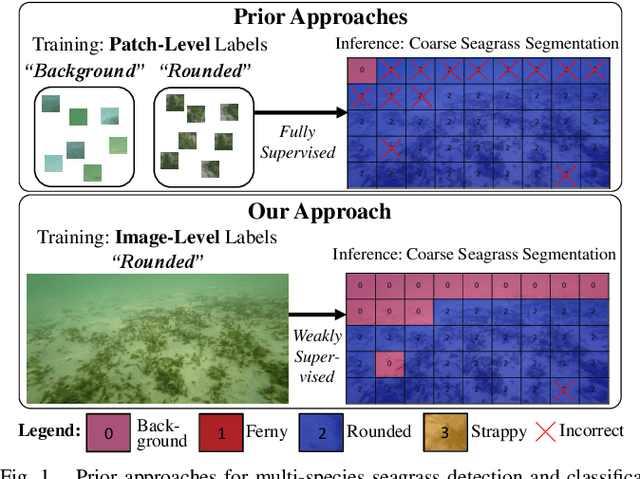
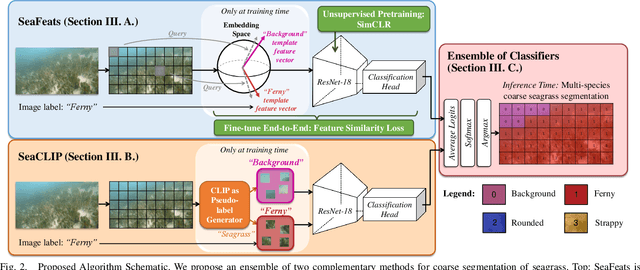
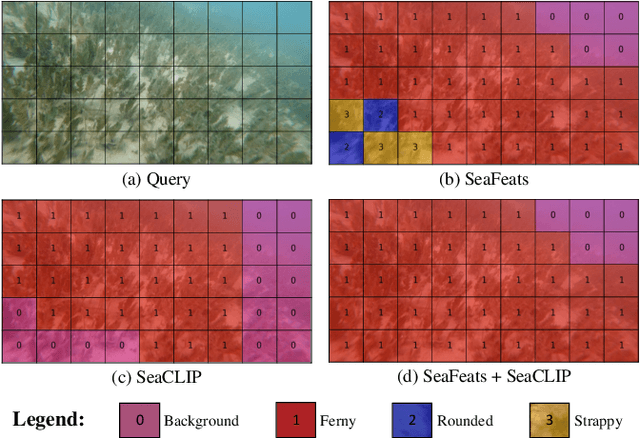
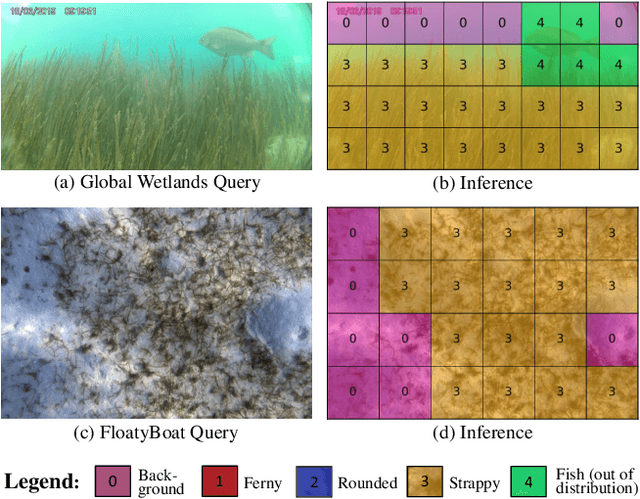
Seagrass meadows serve as critical carbon sinks, but accurately estimating the amount of carbon they store requires knowledge of the seagrass species present. Using underwater and surface vehicles equipped with machine learning algorithms can help to accurately estimate the composition and extent of seagrass meadows at scale. However, previous approaches for seagrass detection and classification have required full supervision from patch-level labels. In this paper, we reframe seagrass classification as a weakly supervised coarse segmentation problem where image-level labels are used during training (25 times fewer labels compared to patch-level labeling) and patch-level outputs are obtained at inference time. To this end, we introduce SeaFeats, an architecture that uses unsupervised contrastive pretraining and feature similarity to separate background and seagrass patches, and SeaCLIP, a model that showcases the effectiveness of large language models as a supervisory signal in domain-specific applications. We demonstrate that an ensemble of SeaFeats and SeaCLIP leads to highly robust performance, with SeaCLIP conservatively predicting the background class to avoid false seagrass misclassifications in blurry or dark patches. Our method outperforms previous approaches that require patch-level labels on the multi-species 'DeepSeagrass' dataset by 6.8% (absolute) for the class-weighted F1 score, and by 12.1% (absolute) F1 score for seagrass presence/absence on the 'Global Wetlands' dataset. We also present two case studies for real-world deployment: outlier detection on the Global Wetlands dataset, and application of our method on imagery collected by FloatyBoat, an autonomous surface vehicle.
QuickCent: a fast and frugal heuristic for harmonic centrality estimation on scale-free networks
Mar 02, 2023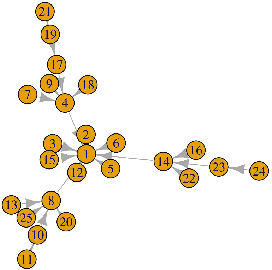


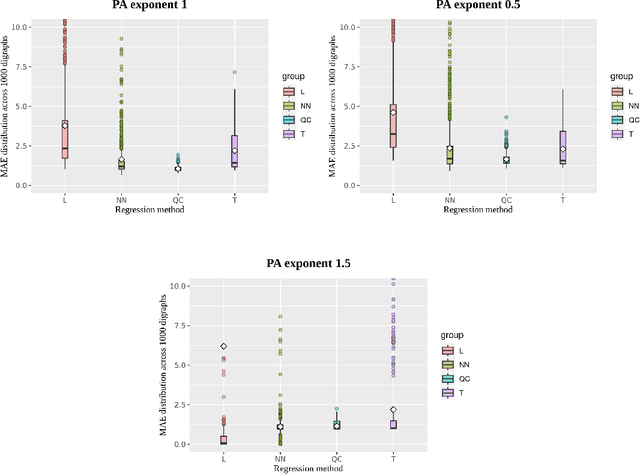
We present a simple and quick method to approximate network centrality indexes. Our approach, called QuickCent, is inspired by so-called fast and frugal heuristics, which are heuristics initially proposed to model some human decision and inference processes. The centrality index that we estimate is the harmonic centrality, which is a measure based on shortest-path distances, so infeasible to compute on large networks. We compare QuickCent with known machine learning algorithms on synthetic data generated with preferential attachment, and some empirical networks. Our experiments show that QuickCent is able to make estimates that are competitive in accuracy with the best alternative methods tested, either on synthetic scale-free networks or empirical networks. QuickCent has the feature of achieving low error variance estimates, even with a small training set. Moreover, QuickCent is comparable in efficiency -- accuracy and time cost -- to those produced by more complex methods. We discuss and provide some insight into how QuickCent exploits the fact that in some networks, such as those generated by preferential attachment, local density measures such as the in-degree, can be a proxy for the size of the network region to which a node has access, opening up the possibility of approximating centrality indices based on size such as the harmonic centrality. Our initial results show that simple heuristics and biologically inspired computational methods are a promising line of research in the context of network measure estimations.
Real-Time Mask Detection Based on SSD-MobileNetV2
Aug 29, 2022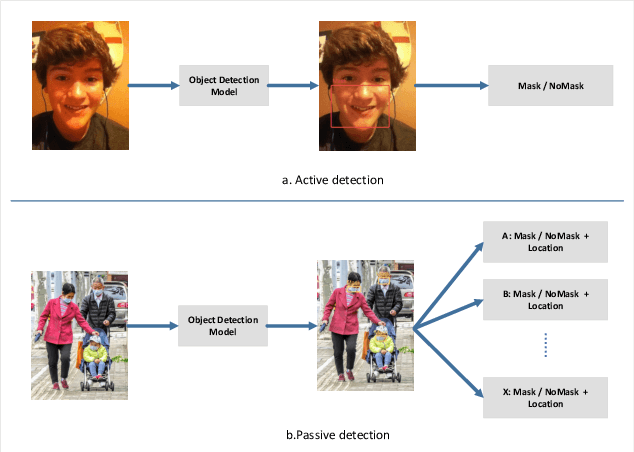
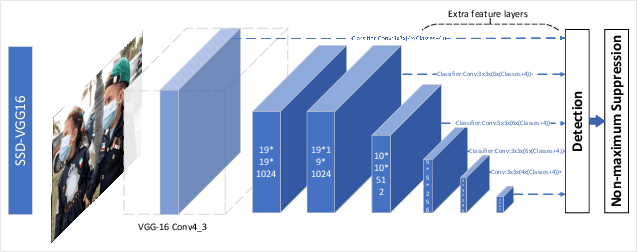
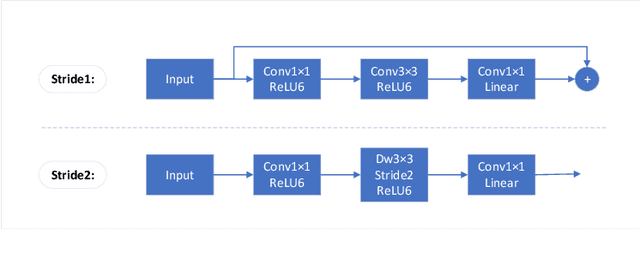
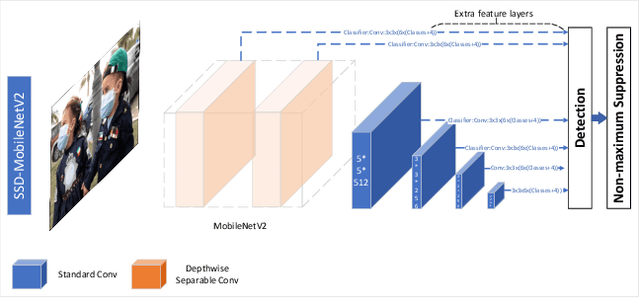
After the outbreak of COVID-19, mask detection, as the most convenient and effective means of prevention, plays a crucial role in epidemic prevention and control. An excellent automatic real-time mask detection system can reduce a lot of work pressure for relevant staff. However, by analyzing the existing mask detection approaches, we find that they are mostly resource-intensive and do not achieve a good balance between speed and accuracy. And there is no perfect face mask dataset at present. In this paper, we propose a new architecture for mask detection. Our system uses SSD as the mask locator and classifier, and further replaces VGG-16 with MobileNetV2 to extract the features of the image and reduce a lot of parameters. Therefore, our system can be deployed on embedded devices. Transfer learning methods are used to transfer pre-trained models from other domains to our model. Data enhancement methods in our system such as MixUp effectively prevent overfitting. It also effectively reduces the dependence on large-scale datasets. By doing experiments in practical scenarios, the results demonstrate that our system performed well in real-time mask detection.
Sparse Dimensionality Reduction Revisited
Feb 13, 2023The sparse Johnson-Lindenstrauss transform is one of the central techniques in dimensionality reduction. It supports embedding a set of $n$ points in $\mathbb{R}^d$ into $m=O(\varepsilon^{-2} \lg n)$ dimensions while preserving all pairwise distances to within $1 \pm \varepsilon$. Each input point $x$ is embedded to $Ax$, where $A$ is an $m \times d$ matrix having $s$ non-zeros per column, allowing for an embedding time of $O(s \|x\|_0)$. Since the sparsity of $A$ governs the embedding time, much work has gone into improving the sparsity $s$. The current state-of-the-art by Kane and Nelson (JACM'14) shows that $s = O(\varepsilon ^{-1} \lg n)$ suffices. This is almost matched by a lower bound of $s = \Omega(\varepsilon ^{-1} \lg n/\lg(1/\varepsilon))$ by Nelson and Nguyen (STOC'13). Previous work thus suggests that we have near-optimal embeddings. In this work, we revisit sparse embeddings and identify a loophole in the lower bound. Concretely, it requires $d \geq n$, which in many applications is unrealistic. We exploit this loophole to give a sparser embedding when $d = o(n)$, achieving $s = O(\varepsilon^{-1}(\lg n/\lg(1/\varepsilon)+\lg^{2/3}n \lg^{1/3} d))$. We also complement our analysis by strengthening the lower bound of Nelson and Nguyen to hold also when $d \ll n$, thereby matching the first term in our new sparsity upper bound. Finally, we also improve the sparsity of the best oblivious subspace embeddings for optimal embedding dimensionality.
Multiscale Graph Neural Network Autoencoders for Interpretable Scientific Machine Learning
Feb 13, 2023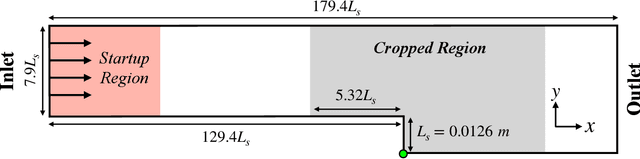
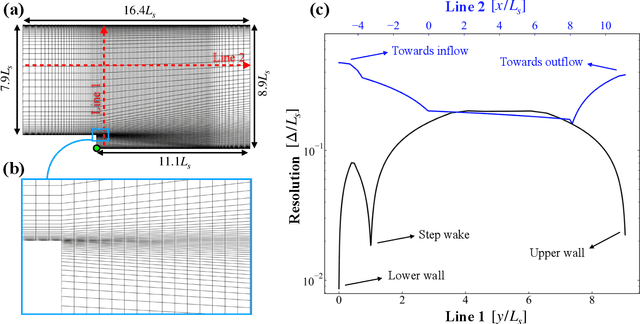
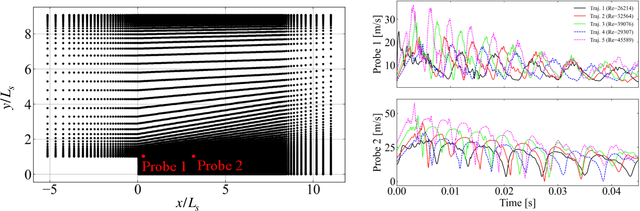
The goal of this work is to address two limitations in autoencoder-based models: latent space interpretability and compatibility with unstructured meshes. This is accomplished here with the development of a novel graph neural network (GNN) autoencoding architecture with demonstrations on complex fluid flow applications. To address the first goal of interpretability, the GNN autoencoder achieves reduction in the number nodes in the encoding stage through an adaptive graph reduction procedure. This reduction procedure essentially amounts to flowfield-conditioned node sampling and sensor identification, and produces interpretable latent graph representations tailored to the flowfield reconstruction task in the form of so-called masked fields. These masked fields allow the user to (a) visualize where in physical space a given latent graph is active, and (b) interpret the time-evolution of the latent graph connectivity in accordance with the time-evolution of unsteady flow features (e.g. recirculation zones, shear layers) in the domain. To address the goal of unstructured mesh compatibility, the autoencoding architecture utilizes a series of multi-scale message passing (MMP) layers, each of which models information exchange among node neighborhoods at various lengthscales. The MMP layer, which augments standard single-scale message passing with learnable coarsening operations, allows the decoder to more efficiently reconstruct the flowfield from the identified regions in the masked fields. Analysis of latent graphs produced by the autoencoder for various model settings are conducted using using unstructured snapshot data sourced from large-eddy simulations in a backward-facing step (BFS) flow configuration with an OpenFOAM-based flow solver at high Reynolds numbers.
Self-Supervised Pre-Training for Deep Image Prior-Based Robust PET Image Denoising
Feb 27, 2023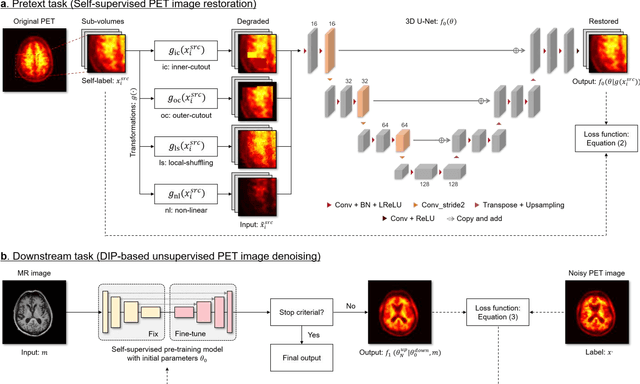
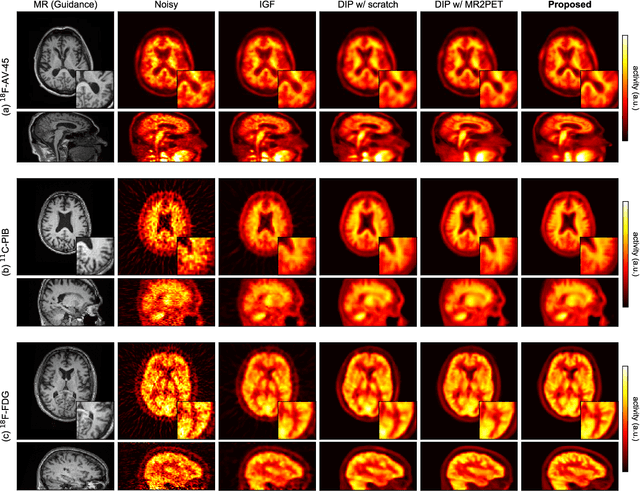
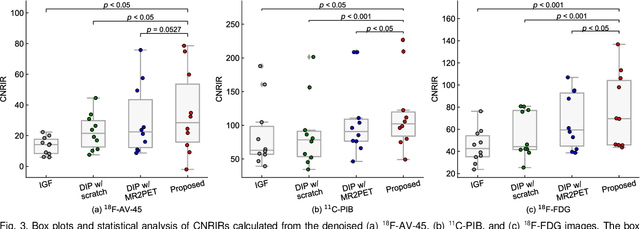

Deep image prior (DIP) has been successfully applied to positron emission tomography (PET) image restoration, enabling represent implicit prior using only convolutional neural network architecture without training dataset, whereas the general supervised approach requires massive low- and high-quality PET image pairs. To answer the increased need for PET imaging with DIP, it is indispensable to improve the performance of the underlying DIP itself. Here, we propose a self-supervised pre-training model to improve the DIP-based PET image denoising performance. Our proposed pre-training model acquires transferable and generalizable visual representations from only unlabeled PET images by restoring various degraded PET images in a self-supervised approach. We evaluated the proposed method using clinical brain PET data with various radioactive tracers ($^{18}$F-florbetapir, $^{11}$C-Pittsburgh compound-B, $^{18}$F-fluoro-2-deoxy-D-glucose, and $^{15}$O-CO$_{2}$) acquired from different PET scanners. The proposed method using the self-supervised pre-training model achieved robust and state-of-the-art denoising performance while retaining spatial details and quantification accuracy compared to other unsupervised methods and pre-training model. These results highlight the potential that the proposed method is particularly effective against rare diseases and probes and helps reduce the scan time or the radiotracer dose without affecting the patients.
Exposure-Based Multi-Agent Inspection of a Tumbling Target Using Deep Reinforcement Learning
Feb 27, 2023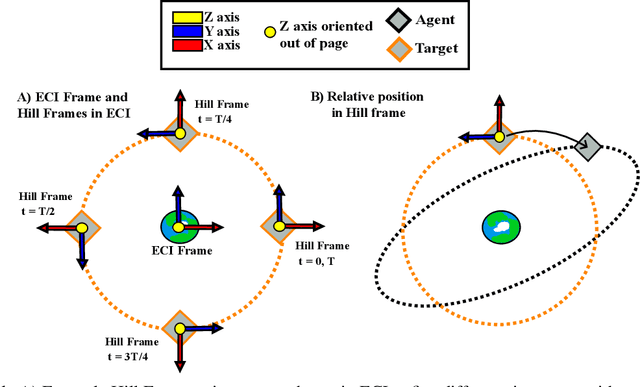
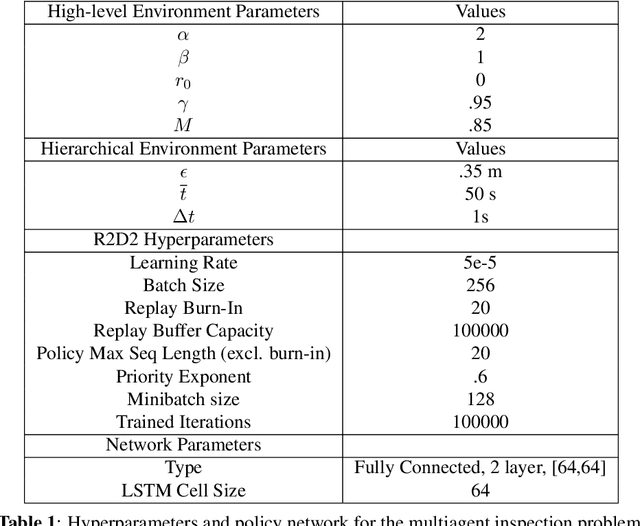
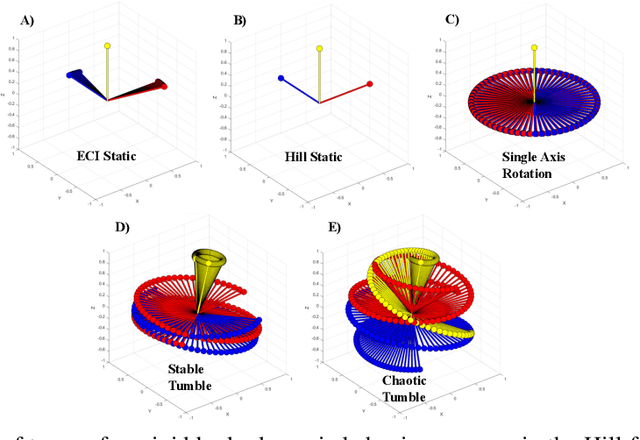

As space becomes more congested, on orbit inspection is an increasingly relevant activity whether to observe a defunct satellite for planning repairs or to de-orbit it. However, the task of on orbit inspection itself is challenging, typically requiring the careful coordination of multiple observer satellites. This is complicated by a highly nonlinear environment where the target may be unknown or moving unpredictably without time for continuous command and control from the ground. There is a need for autonomous, robust, decentralized solutions to the inspection task. To achieve this, we consider a hierarchical, learned approach for the decentralized planning of multi-agent inspection of a tumbling target. Our solution consists of two components: a viewpoint or high-level planner trained using deep reinforcement learning and a navigation planner handling point-to-point navigation between pre-specified viewpoints. We present a novel problem formulation and methodology that is suitable not only to reinforcement learning-derived robust policies, but extendable to unknown target geometries and higher fidelity information theoretic objectives received directly from sensor inputs. Operating under limited information, our trained multi-agent high-level policies successfully contextualize information within the global hierarchical environment and are correspondingly able to inspect over 90% of non-convex tumbling targets, even in the absence of additional agent attitude control.
Semi-unsupervised Learning for Time Series Classification
Jul 07, 2022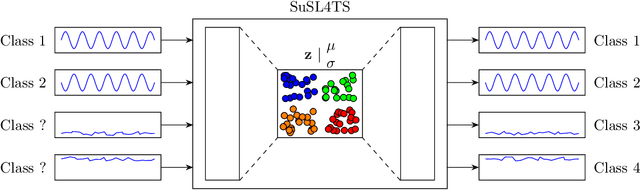


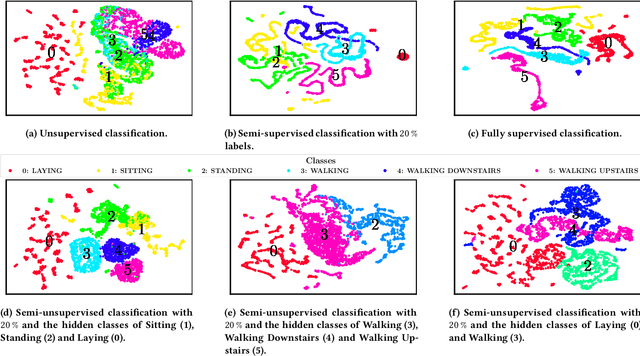
Time series are ubiquitous and therefore inherently hard to analyze and ultimately to label or cluster. With the rise of the Internet of Things (IoT) and its smart devices, data is collected in large amounts any given second. The collected data is rich in information, as one can detect accidents (e.g. cars) in real time, or assess injury/sickness over a given time span (e.g. health devices). Due to its chaotic nature and massive amounts of datapoints, timeseries are hard to label manually. Furthermore new classes within the data could emerge over time (contrary to e.g. handwritten digits), which would require relabeling the data. In this paper we present SuSL4TS, a deep generative Gaussian mixture model for semi-unsupervised learning, to classify time series data. With our approach we can alleviate manual labeling steps, since we can detect sparsely labeled classes (semi-supervised) and identify emerging classes hidden in the data (unsupervised). We demonstrate the efficacy of our approach with established time series classification datasets from different domains.
Multi-Content Time-Series Popularity Prediction with Multiple-Model Transformers in MEC Networks
Oct 12, 2022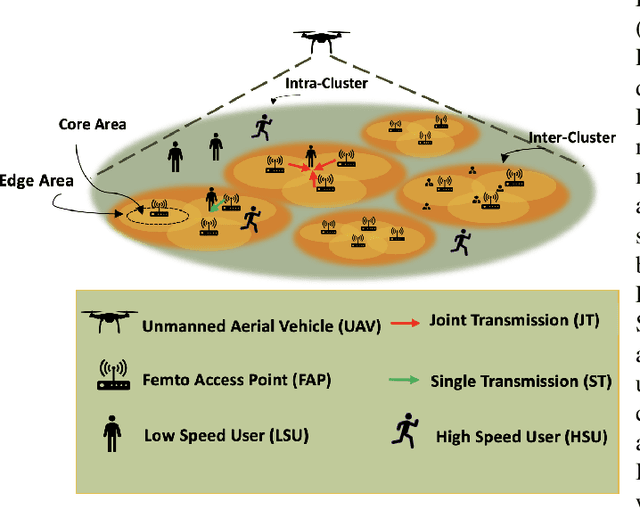
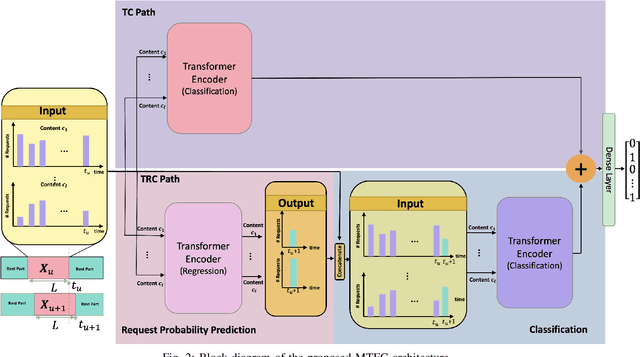
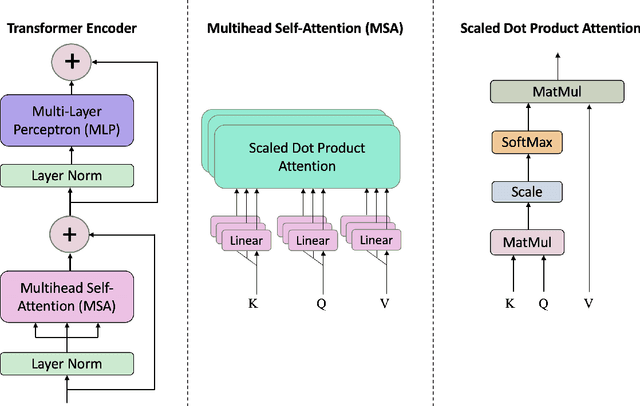
Coded/uncoded content placement in Mobile Edge Caching (MEC) has evolved as an efficient solution to meet the significant growth of global mobile data traffic by boosting the content diversity in the storage of caching nodes. To meet the dynamic nature of the historical request pattern of multimedia contents, the main focus of recent researches has been shifted to develop data-driven and real-time caching schemes. In this regard and with the assumption that users' preferences remain unchanged over a short horizon, the Top-K popular contents are identified as the output of the learning model. Most existing datadriven popularity prediction models, however, are not suitable for the coded/uncoded content placement frameworks. On the one hand, in coded/uncoded content placement, in addition to classifying contents into two groups, i.e., popular and nonpopular, the probability of content request is required to identify which content should be stored partially/completely, where this information is not provided by existing data-driven popularity prediction models. On the other hand, the assumption that users' preferences remain unchanged over a short horizon only works for content with a smooth request pattern. To tackle these challenges, we develop a Multiple-model (hybrid) Transformer-based Edge Caching (MTEC) framework with higher generalization ability, suitable for various types of content with different time-varying behavior, that can be adapted with coded/uncoded content placement frameworks. Simulation results corroborate the effectiveness of the proposed MTEC caching framework in comparison to its counterparts in terms of the cache-hit ratio, classification accuracy, and the transferred byte volume.