 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learned Interferometric Imaging for the SPIDER Instrument
Jan 24, 2023
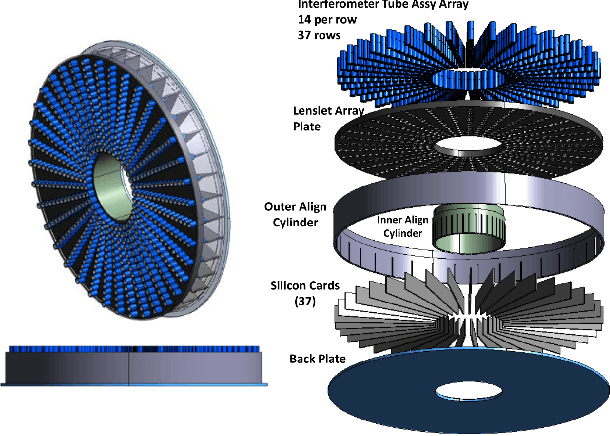

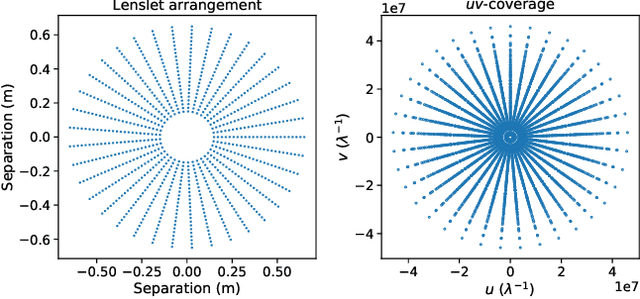
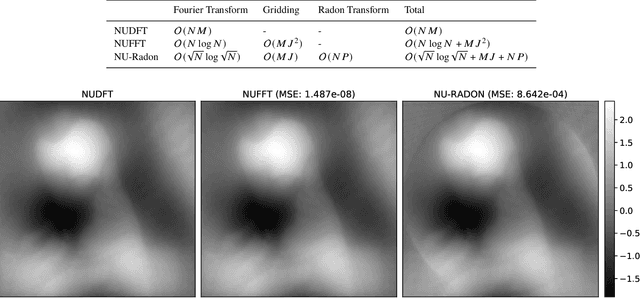
The Segmented Planar Imaging Detector for Electro-Optical Reconnaissance (SPIDER) is an optical interferometric imaging device that aims to offer an alternative to the large space telescope designs of today with reduced size, weight and power consumption. This is achieved through interferometric imaging. State-of-the-art methods for reconstructing images from interferometric measurements adopt proximal optimization techniques, which are computationally expensive and require handcrafted priors. In this work we present two data-driven approaches for reconstructing images from measurements made by the SPIDER instrument. These approaches use deep learning to learn prior information from training data, increasing the reconstruction quality, and significantly reducing the computation time required to recover images by orders of magnitude. Reconstruction time is reduced to ${\sim} 10$ milliseconds, opening up the possibility of real-time imaging with SPIDER for the first time. Furthermore, we show that these methods can also be applied in domains where training data is scarce, such as astronomical imaging, by leveraging transfer learning from domains where plenty of training data are available.
Spatio-Temporal Graph Neural Networks: A Survey
Jan 25, 2023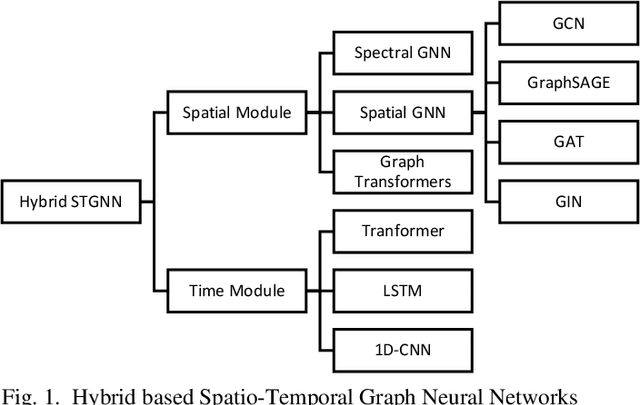
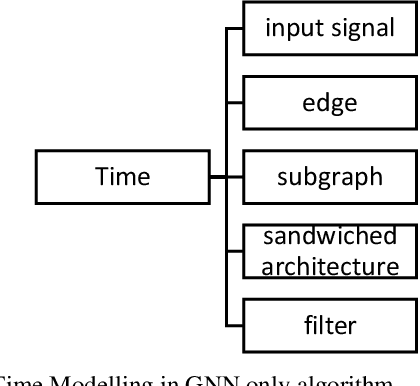
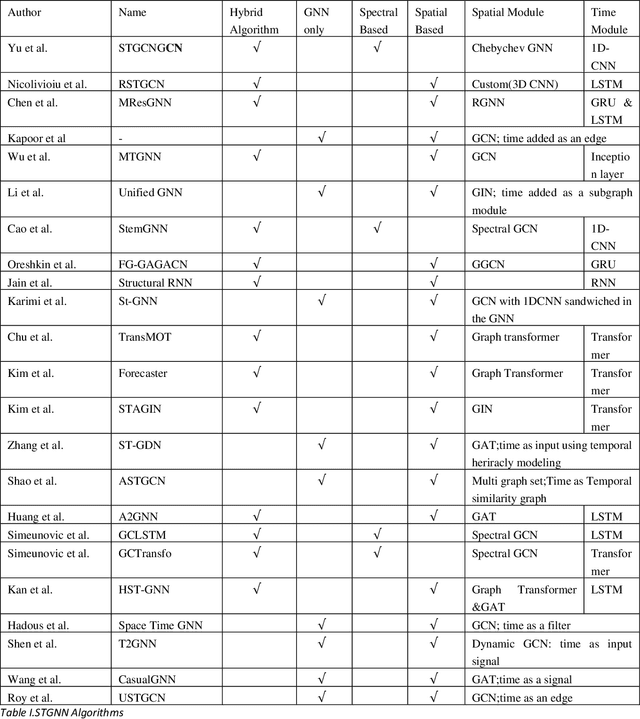
Graph Neural Networks have gained huge interest in the past few years. These powerful algorithms expanded deep learning models to non-Euclidean space and were able to achieve state of art performance in various applications including recommender systems and social networks. However, this performance is based on static graph structures assumption which limits the Graph Neural Networks performance when the data varies with time. Temporal Graph Neural Networks are extension of Graph Neural Networks that takes the time factor into account. Recently, various Temporal Graph Neural Network algorithms were proposed and achieved superior performance compared to other deep learning algorithms in several time dependent applications. This survey discusses interesting topics related to Spatio temporal Graph Neural Networks, including algorithms, application, and open challenges.
Chronological Self-Training for Real-Time Speaker Diarization
Aug 05, 2022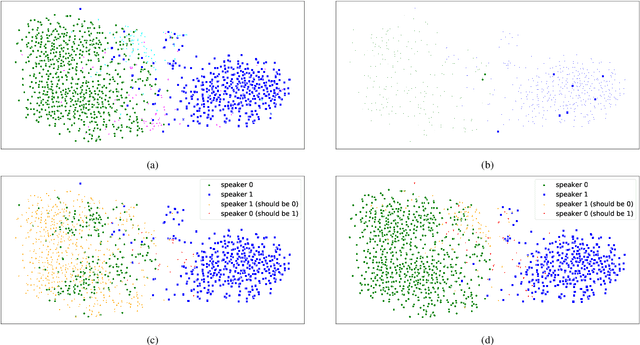
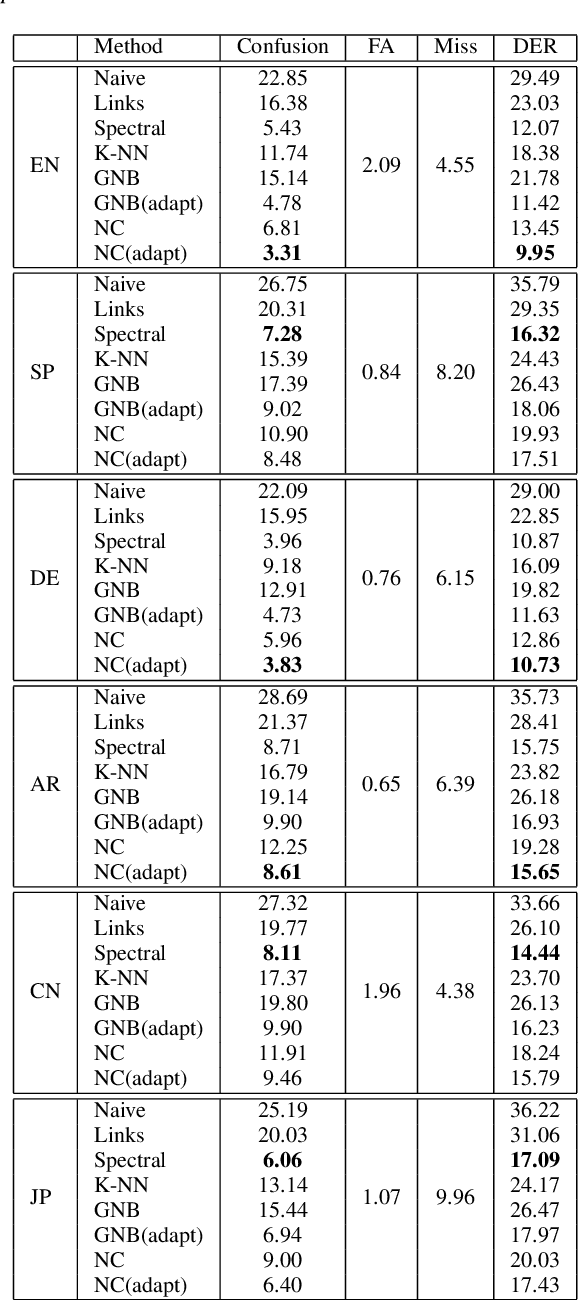
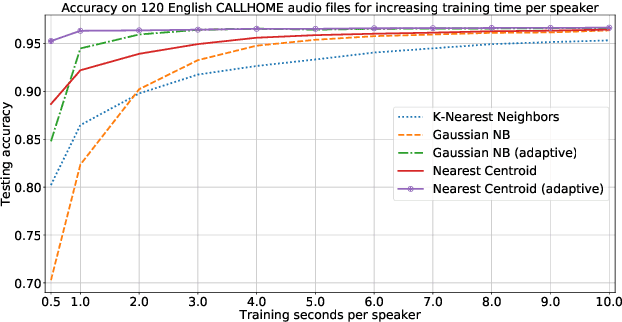
Diarization partitions an audio stream into segments based on the voices of the speakers. Real-time diarization systems that include an enrollment step should limit enrollment training samples to reduce user interaction time. Although training on a small number of samples yields poor performance, we show that the accuracy can be improved dramatically using a chronological self-training approach. We studied the tradeoff between training time and classification performance and found that 1 second is sufficient to reach over 95% accuracy. We evaluated on 700 audio conversation files of about 10 minutes each from 6 different languages and demonstrated average diarization error rates as low as 10%.
* 5 pages, 5 figures, ICASSP 2021
Dynamic Time-Alignment of Dimensional Annotations of Emotion using Recurrent Neural Networks
Sep 21, 2022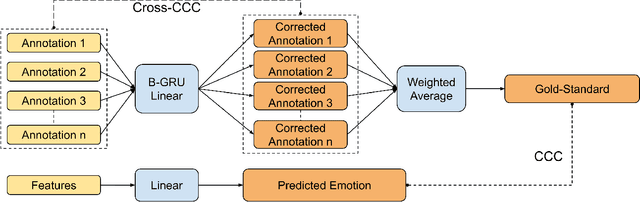


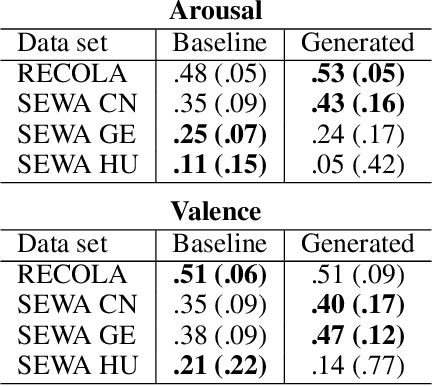
Most automatic emotion recognition systems exploit time-continuous annotations of emotion to provide fine-grained descriptions of spontaneous expressions as observed in real-life interactions. As emotion is rather subjective, its annotation is usually performed by several annotators who provide a trace for a given dimension, i.e. a time-continuous series describing a dimension such as arousal or valence. However, annotations of the same expression are rarely consistent between annotators, either in time or in value, which adds bias and delay in the trace that is used to learn predictive models of emotion. We therefore propose a method that can dynamically compensate inconsistencies across annotations and synchronise the traces with the corresponding acoustic features using Recurrent Neural Networks. Experimental evaluations were carried on several emotion data sets that include Chinese, French, German, and Hungarian participants who interacted remotely in either noise-free conditions or in-the-wild. The results show that our method can significantly increase inter-annotator agreement, as well as correlation between traces and audio features, for both arousal and valence. In addition, improvements are obtained in the automatic prediction of these dimensions using simple light-weight models, especially for valence in noise-free conditions, and arousal for recordings captured in-the-wild.
Square-root regret bounds for continuous-time episodic Markov decision processes
Oct 03, 2022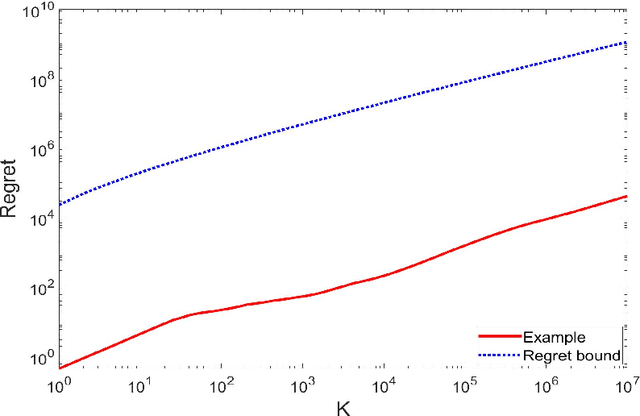
We study reinforcement learning for continuous-time Markov decision processes (MDPs) in the finite-horizon episodic setting. We present a learning algorithm based on the methods of value iteration and upper confidence bound. We derive an upper bound on the worst-case expected regret for the proposed algorithm, and establish a worst-case lower bound, both bounds are of the order of square-root on the number of episodes. Finally, we conduct simulation experiments to illustrate the performance of our algorithm.
A Miniaturised Camera-based Multi-Modal Tactile Sensor
Mar 06, 2023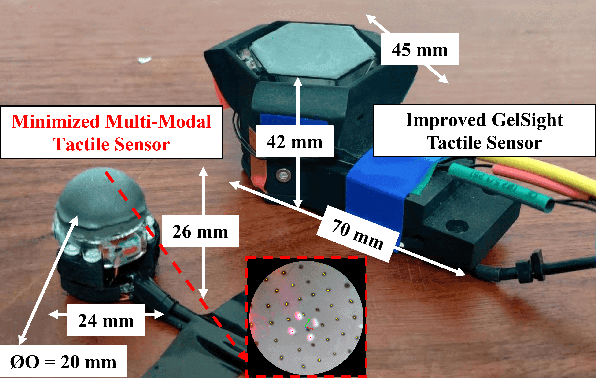
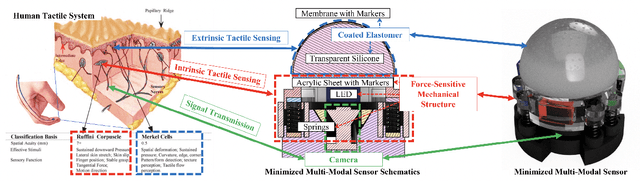
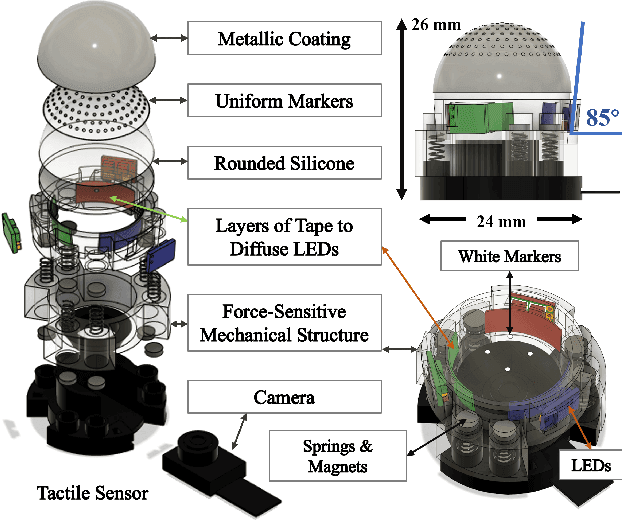
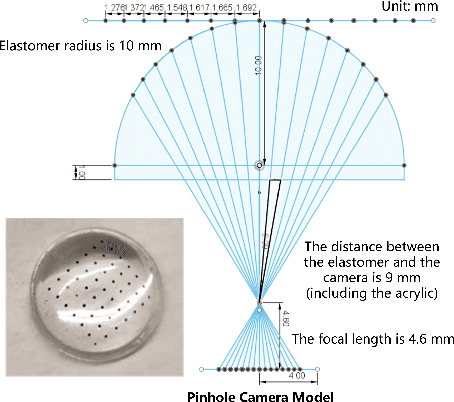
In conjunction with huge recent progress in camera and computer vision technology, camera-based sensors have increasingly shown considerable promise in relation to tactile sensing. In comparison to competing technologies (be they resistive, capacitive or magnetic based), they offer super-high-resolution, while suffering from fewer wiring problems. The human tactile system is composed of various types of mechanoreceptors, each able to perceive and process distinct information such as force, pressure, texture, etc. Camera-based tactile sensors such as GelSight mainly focus on high-resolution geometric sensing on a flat surface, and their force measurement capabilities are limited by the hysteresis and non-linearity of the silicone material. In this paper, we present a miniaturised dome-shaped camera-based tactile sensor that allows accurate force and tactile sensing in a single coherent system. The key novelty of the sensor design is as follows. First, we demonstrate how to build a smooth silicone hemispheric sensing medium with uniform markers on its curved surface. Second, we enhance the illumination of the rounded silicone with diffused LEDs. Third, we construct a force-sensitive mechanical structure in a compact form factor with usage of springs to accurately perceive forces. Our multi-modal sensor is able to acquire tactile information from multi-axis forces, local force distribution, and contact geometry, all in real-time. We apply an end-to-end deep learning method to process all the information.
HARDC : A novel ECG-based heartbeat classification method to detect arrhythmia using hierarchical attention based dual structured RNN with dilated CNN
Mar 06, 2023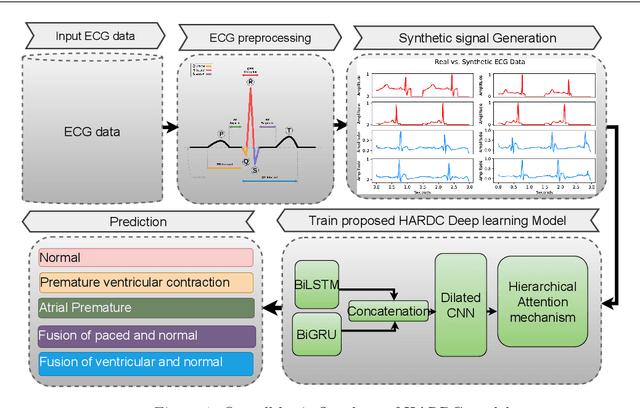
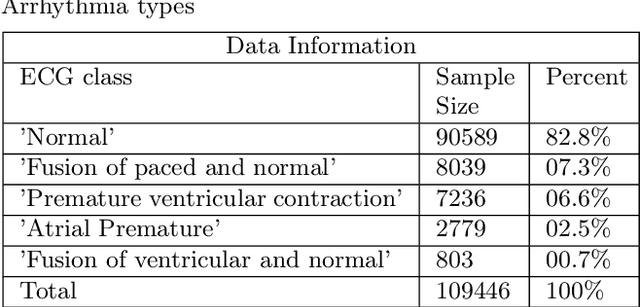
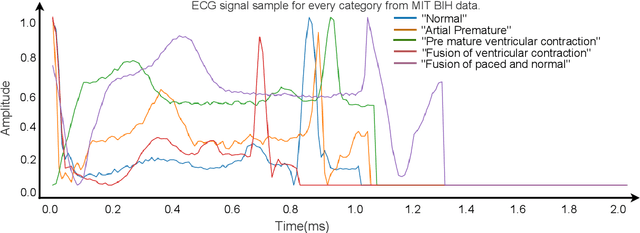
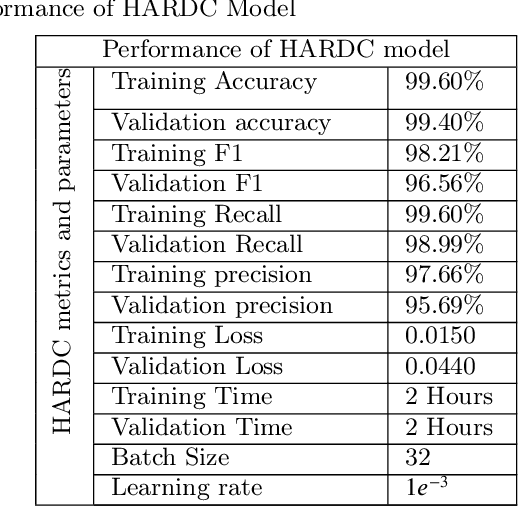
In this paper have developed a novel hybrid hierarchical attention-based bidirectional recurrent neural network with dilated CNN (HARDC) method for arrhythmia classification. This solves problems that arise when traditional dilated convolutional neural network (CNN) models disregard the correlation between contexts and gradient dispersion. The proposed HARDC fully exploits the dilated CNN and bidirectional recurrent neural network unit (BiGRU-BiLSTM) architecture to generate fusion features. As a result of incorporating both local and global feature information and an attention mechanism, the model's performance for prediction is improved.By combining the fusion features with a dilated CNN and a hierarchical attention mechanism, the trained HARDC model showed significantly improved classification results and interpretability of feature extraction on the PhysioNet 2017 challenge dataset. Sequential Z-Score normalization, filtering, denoising, and segmentation are used to prepare the raw data for analysis. CGAN (Conditional Generative Adversarial Network) is then used to generate synthetic signals from the processed data. The experimental results demonstrate that the proposed HARDC model significantly outperforms other existing models, achieving an accuracy of 99.60\%, F1 score of 98.21\%, a precision of 97.66\%, and recall of 99.60\% using MIT-BIH generated ECG. In addition, this approach substantially reduces run time when using dilated CNN compared to normal convolution. Overall, this hybrid model demonstrates an innovative and cost-effective strategy for ECG signal compression and high-performance ECG recognition. Our results indicate that an automated and highly computed method to classify multiple types of arrhythmia signals holds considerable promise.
Domain adaptation using optimal transport for invariant learning using histopathology datasets
Mar 03, 2023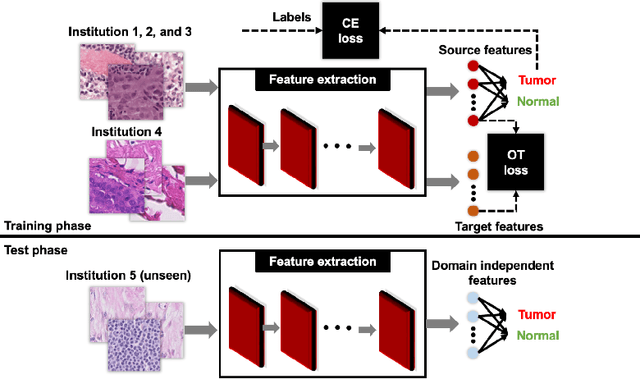


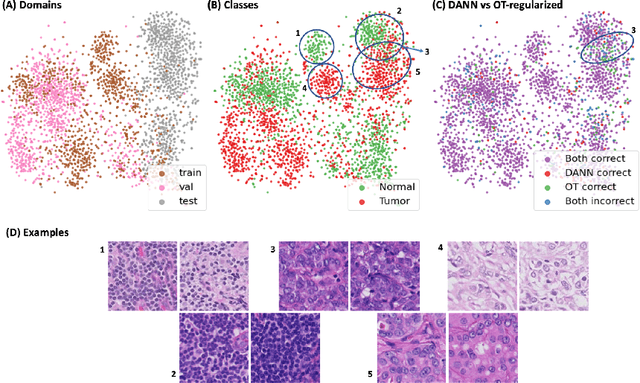
Histopathology is critical for the diagnosis of many diseases, including cancer. These protocols typically require pathologists to manually evaluate slides under a microscope, which is time-consuming and subjective, leading to interest in machine learning to automate analysis. However, computational techniques are limited by batch effects, where technical factors like differences in preparation protocol or scanners can alter the appearance of slides, causing models trained on one institution to fail when generalizing to others. Here, we propose a domain adaptation method that improves the generalization of histopathological models to data from unseen institutions, without the need for labels or retraining in these new settings. Our approach introduces an optimal transport (OT) loss, that extends adversarial methods that penalize models if images from different institutions can be distinguished in their representation space. Unlike previous methods, which operate on single samples, our loss accounts for distributional differences between batches of images. We show that on the Camelyon17 dataset, while both methods can adapt to global differences in color distribution, only our OT loss can reliably classify a cancer phenotype unseen during training. Together, our results suggest that OT improves generalization on rare but critical phenotypes that may only make up a small fraction of the total tiles and variation in a slide.
Decision Transformer under Random Frame Dropping
Mar 03, 2023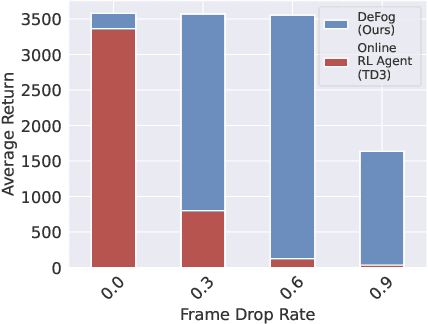
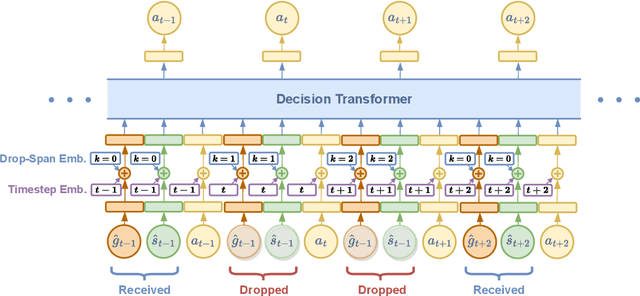
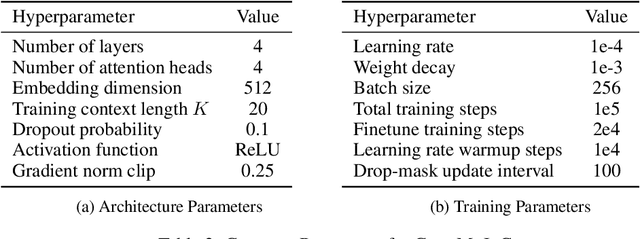
Controlling agents remotely with deep reinforcement learning~(DRL) in the real world is yet to come. One crucial stepping stone is to devise RL algorithms that are robust in the face of dropped information from corrupted communication or malfunctioning sensors. Typical RL methods usually require considerable online interaction data that are costly and unsafe to collect in the real world. Furthermore, when applying to the frame dropping scenarios, they perform unsatisfactorily even with moderate drop rates. To address these issues, we propose Decision Transformer under Random Frame Dropping~(DeFog), an offline RL algorithm that enables agents to act robustly in frame dropping scenarios without online interaction. DeFog first randomly masks out data in the offline datasets and explicitly adds the time span of frame dropping as inputs. After that, a finetuning stage on the same offline dataset with a higher mask rate would further boost the performance. Empirical results show that DeFog outperforms strong baselines under severe frame drop rates like 90\%, while maintaining similar returns under non-frame-dropping conditions in the regular MuJoCo control benchmarks and the Atari environments. Our approach offers a robust and deployable solution for controlling agents in real-world environments with limited or unreliable data.
Ultra-low Power Deep Learning-based Monocular Relative Localization Onboard Nano-quadrotors
Mar 03, 2023
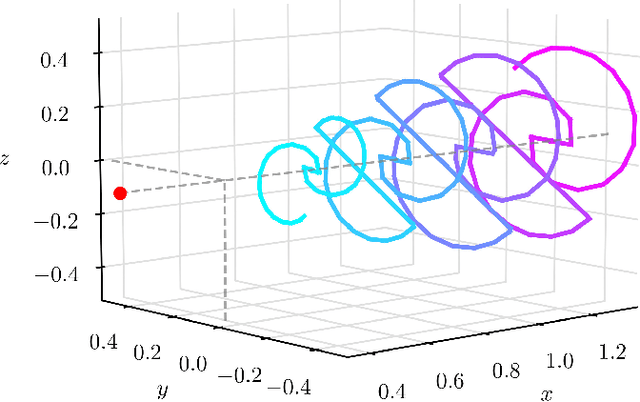

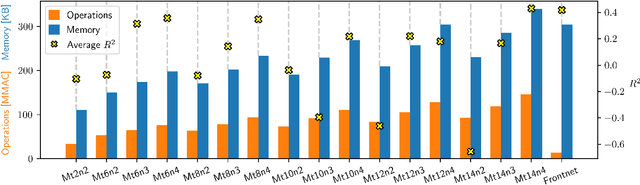
Precise relative localization is a crucial functional block for swarm robotics. This work presents a novel autonomous end-to-end system that addresses the monocular relative localization, through deep neural networks (DNNs), of two peer nano-drones, i.e., sub-40g of weight and sub-100mW processing power. To cope with the ultra-constrained nano-drone platform, we propose a vertically-integrated framework, from the dataset collection to the final in-field deployment, including dataset augmentation, quantization, and system optimizations. Experimental results show that our DNN can precisely localize a 10cm-size target nano-drone by employing only low-resolution monochrome images, up to ~2m distance. On a disjoint testing dataset our model yields a mean R2 score of 0.42 and a root mean square error of 18cm, which results in a mean in-field prediction error of 15cm and in a closed-loop control error of 17cm, over a ~60s-flight test. Ultimately, the proposed system improves the State-of-the-Art by showing long-endurance tracking performance (up to 2min continuous tracking), generalization capabilities being deployed in a never-seen-before environment, and requiring a minimal power consumption of 95mW for an onboard real-time inference-rate of 48Hz.