 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Long-Term Modeling of Financial Machine Learning for Active Portfolio Management
Jan 29, 2023
In the practical business of asset management by investment trusts and the like, the general practice is to manage over the medium to long term owing to the burden of operations and increase in transaction costs with the increase in turnover ratio. However, when machine learning is used to construct a management model, the number of learning data decreases with the increase in the long-term time scale; this causes a decline in the learning precision. Accordingly, in this study, data augmentation was applied by the combined use of not only the time scales of the target tasks but also the learning data of shorter term time scales, demonstrating that degradation of the generalization performance can be inhibited even if the target tasks of machine learning have long-term time scales. Moreover, as an illustration of how this data augmentation can be applied, we conducted portfolio management in which machine learning of a multifactor model was done by an autoencoder and mispricing was used from the estimated theoretical values. The effectiveness could be confirmed in not only the stock market but also the FX market, and a general-purpose management model could be constructed in various financial markets.
HOOV: Hand Out-Of-View Tracking for Proprioceptive Interaction using Inertial Sensing
Mar 13, 2023
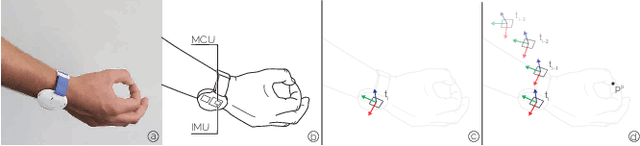
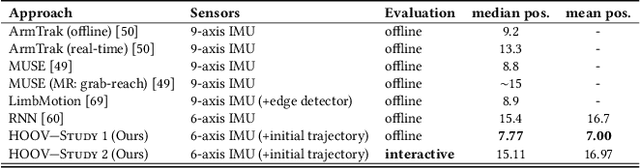
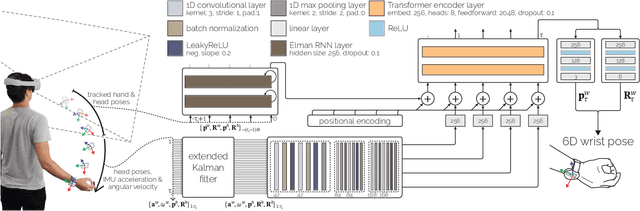
Current Virtual Reality systems are designed for interaction under visual control. Using built-in cameras, headsets track the user's hands or hand-held controllers while they are inside the field of view. Current systems thus ignore the user's interaction with off-screen content -- virtual objects that the user could quickly access through proprioception without requiring laborious head motions to bring them into focus. In this paper, we present HOOV, a wrist-worn sensing method that allows VR users to interact with objects outside their field of view. Based on the signals of a single wrist-worn inertial sensor, HOOV continuously estimates the user's hand position in 3-space to complement the headset's tracking as the hands leave the tracking range. Our novel data-driven method predicts hand positions and trajectories from just the continuous estimation of hand orientation, which by itself is stable based solely on inertial observations. Our inertial sensing simultaneously detects finger pinching to register off-screen selection events, confirms them using a haptic actuator inside our wrist device, and thus allows users to select, grab, and drop virtual content. We compared HOOV's performance with a camera-based optical motion capture system in two folds. In the first evaluation, participants interacted based on tracking information from the motion capture system to assess the accuracy of their proprioceptive input, whereas in the second, they interacted based on HOOV's real-time estimations. We found that HOOV's target-agnostic estimations had a mean tracking error of 7.7 cm, which allowed participants to reliably access virtual objects around their body without first bringing them into focus. We demonstrate several applications that leverage the larger input space HOOV opens up for quick proprioceptive interaction, and conclude by discussing the potential of our technique.
Evaluation of Automatically Constructed Word Meaning Explanations
Feb 27, 2023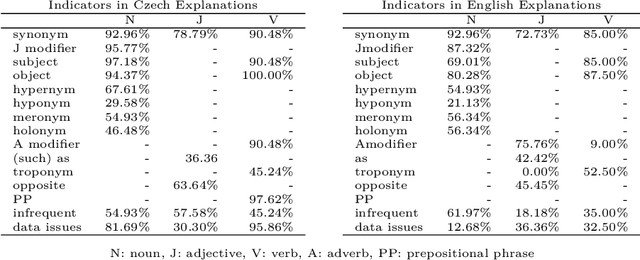

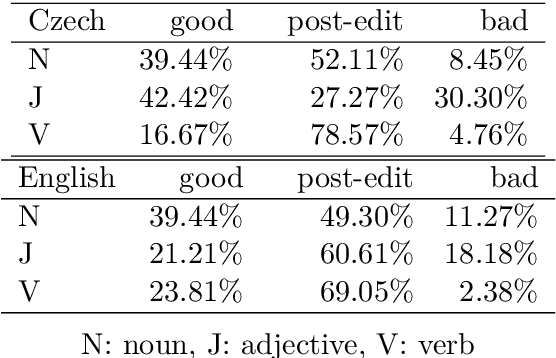

Preparing exact and comprehensive word meaning explanations is one of the key steps in the process of monolingual dictionary writing. In standard methodology, the explanations need an expert lexicographer who spends a substantial amount of time checking the consistency between the descriptive text and corpus evidence. In the following text, we present a new tool that derives explanations automatically based on collective information from very large corpora, particularly on word sketches. We also propose a quantitative evaluation of the constructed explanations, concentrating on explanations of nouns. The methodology is to a certain extent language independent; however, the presented verification is limited to Czech and English. We show that the presented approach allows to create explanations that contain data useful for understanding the word meaning in approximately 90% of cases. However, in many cases, the result requires post-editing to remove redundant information.
* preprint of a chapter published by College Publications at https://www.collegepublications.co.uk/tributes/?00049
Changes in Commuter Behavior from COVID-19 Lockdowns in the Atlanta Metropolitan Area
Feb 27, 2023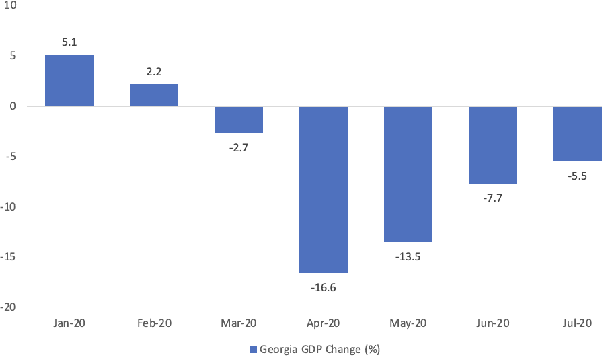
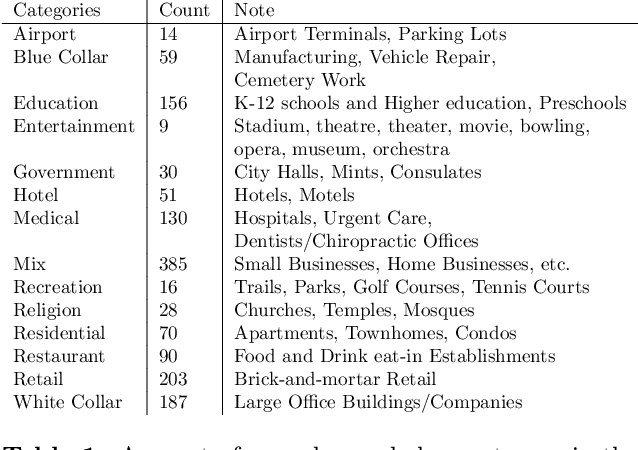

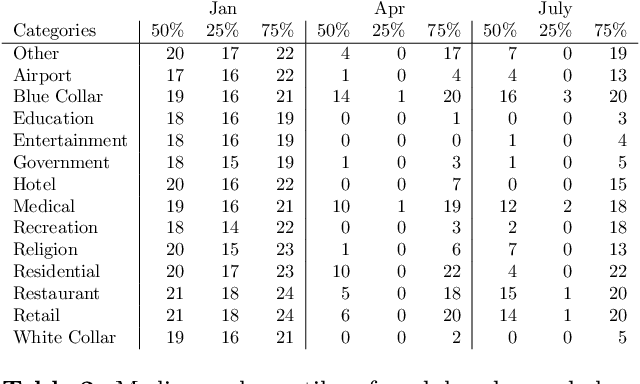
This paper analyzes the impact of COVID-19 related lockdowns in the Atlanta, Georgia metropolitan area by examining commuter patterns in three periods: prior to, during, and after the pandemic lockdown. A cellular phone location dataset is utilized in a novel pipeline to infer the home and work locations of thousands of users from the Density-based Spatial Clustering of Applications with Noise (DBSCAN) algorithm. The coordinates derived from the clustering are put through a reverse geocoding process from which word embeddings are extracted in order to categorize the industry of each work place based on the workplace name and Point of Interest (POI) mapping. Frequencies of commute from home locations to work locations are analyzed in and across all three time periods. Public health and economic factors are discussed to explain potential reasons for the observed changes in commuter patterns.
PyReason: Software for Open World Temporal Logic
Feb 27, 2023

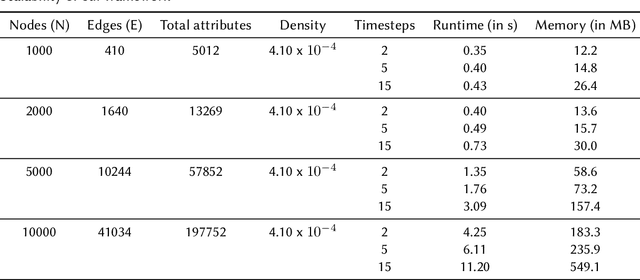
The growing popularity of neuro symbolic reasoning has led to the adoption of various forms of differentiable (i.e., fuzzy) first order logic. We introduce PyReason, a software framework based on generalized annotated logic that both captures the current cohort of differentiable logics and temporal extensions to support inference over finite periods of time with capabilities for open world reasoning. Further, PyReason is implemented to directly support reasoning over graphical structures (e.g., knowledge graphs, social networks, biological networks, etc.), produces fully explainable traces of inference, and includes various practical features such as type checking and a memory-efficient implementation. This paper reviews various extensions of generalized annotated logic integrated into our implementation, our modern, efficient Python-based implementation that conducts exact yet scalable deductive inference, and a suite of experiments. PyReason is available at: github.com/lab-v2/pyreason.
Rethinking the Effect of Data Augmentation in Adversarial Contrastive Learning
Mar 03, 2023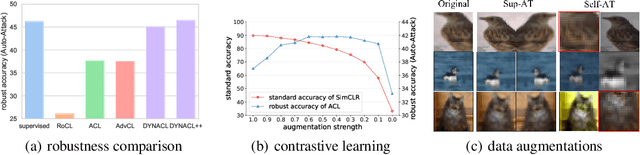
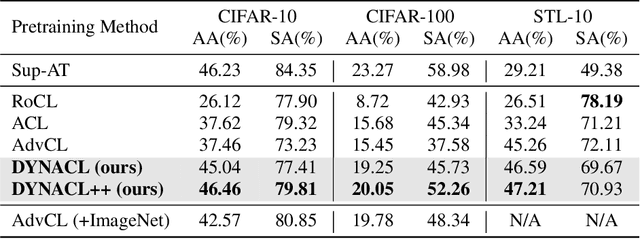
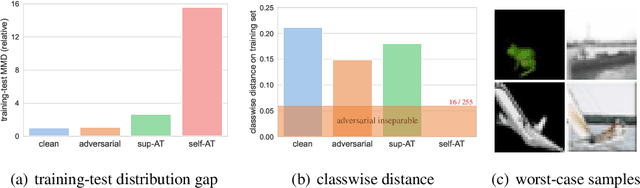
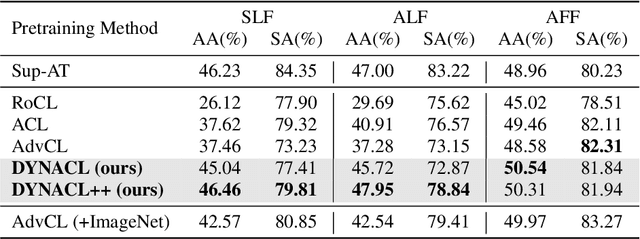
Recent works have shown that self-supervised learning can achieve remarkable robustness when integrated with adversarial training (AT). However, the robustness gap between supervised AT (sup-AT) and self-supervised AT (self-AT) remains significant. Motivated by this observation, we revisit existing self-AT methods and discover an inherent dilemma that affects self-AT robustness: either strong or weak data augmentations are harmful to self-AT, and a medium strength is insufficient to bridge the gap. To resolve this dilemma, we propose a simple remedy named DYNACL (Dynamic Adversarial Contrastive Learning). In particular, we propose an augmentation schedule that gradually anneals from a strong augmentation to a weak one to benefit from both extreme cases. Besides, we adopt a fast post-processing stage for adapting it to downstream tasks. Through extensive experiments, we show that DYNACL can improve state-of-the-art self-AT robustness by 8.84% under Auto-Attack on the CIFAR-10 dataset, and can even outperform vanilla supervised adversarial training for the first time. Our code is available at \url{https://github.com/PKU-ML/DYNACL}.
GETNext: Trajectory Flow Map Enhanced Transformer for Next POI Recommendation
Mar 03, 2023
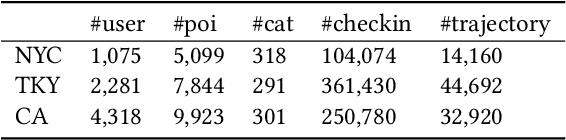
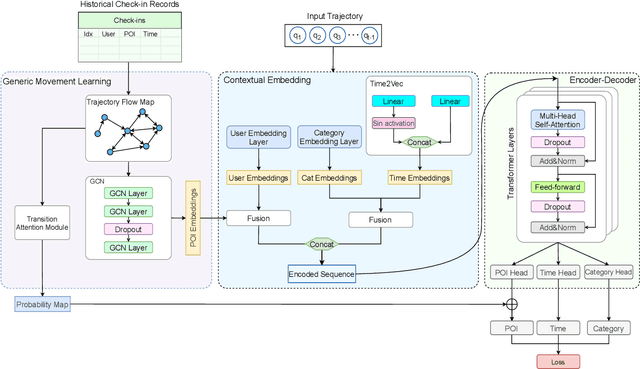
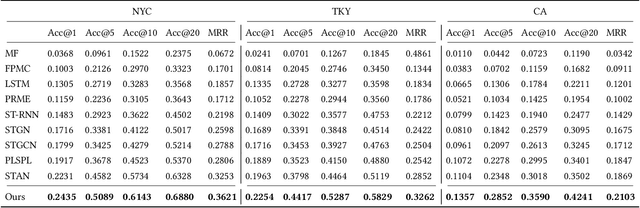
Next POI recommendation intends to forecast users' immediate future movements given their current status and historical information, yielding great values for both users and service providers. However, this problem is perceptibly complex because various data trends need to be considered together. This includes the spatial locations, temporal contexts, user's preferences, etc. Most existing studies view the next POI recommendation as a sequence prediction problem while omitting the collaborative signals from other users. Instead, we propose a user-agnostic global trajectory flow map and a novel Graph Enhanced Transformer model (GETNext) to better exploit the extensive collaborative signals for a more accurate next POI prediction, and alleviate the cold start problem in the meantime. GETNext incorporates the global transition patterns, user's general preference, spatio-temporal context, and time-aware category embeddings together into a transformer model to make the prediction of user's future moves. With this design, our model outperforms the state-of-the-art methods with a large margin and also sheds light on the cold start challenges within the spatio-temporal involved recommendation problems.
When does Privileged Information Explain Away Label Noise?
Mar 03, 2023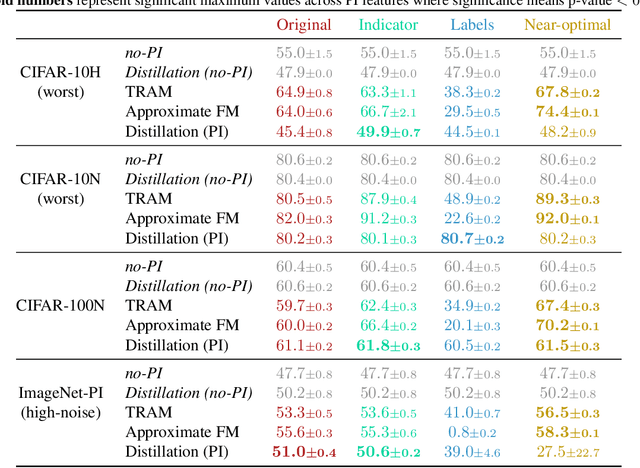
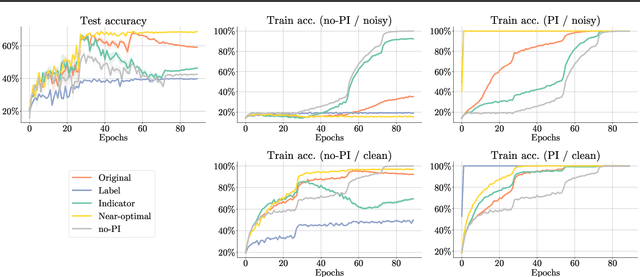
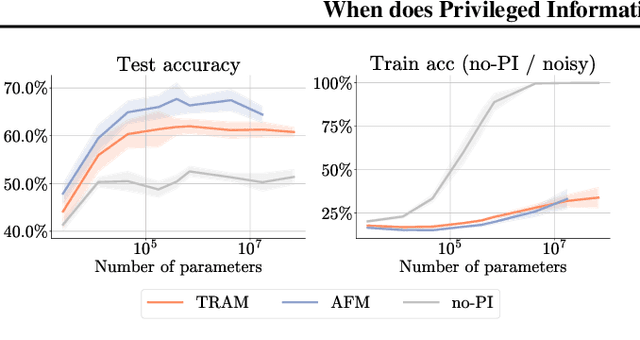

Leveraging privileged information (PI), or features available during training but not at test time, has recently been shown to be an effective method for addressing label noise. However, the reasons for its effectiveness are not well understood. In this study, we investigate the role played by different properties of the PI in explaining away label noise. Through experiments on multiple datasets with real PI (CIFAR-N/H) and a new large-scale benchmark ImageNet-PI, we find that PI is most helpful when it allows networks to easily distinguish clean from noisy data, while enabling a learning shortcut to memorize the noisy examples. Interestingly, when PI becomes too predictive of the target label, PI methods often perform worse than their no-PI baselines. Based on these findings, we propose several enhancements to the state-of-the-art PI methods and demonstrate the potential of PI as a means of tackling label noise. Finally, we show how we can easily combine the resulting PI approaches with existing no-PI techniques designed to deal with label noise.
Spectrogram Inversion for Audio Source Separation via Consistency, Mixing, and Magnitude Constraints
Mar 03, 2023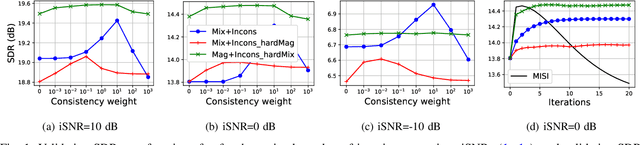
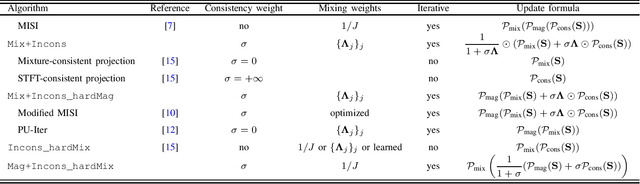
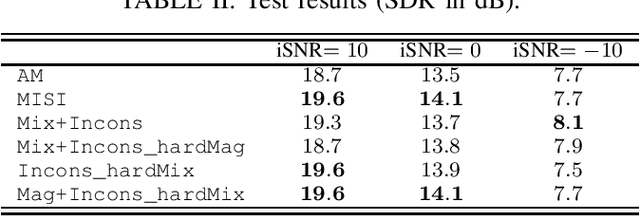
Audio source separation is often achieved by estimating the magnitude spectrogram of each source, and then applying a phase recovery (or spectrogram inversion) algorithm to retrieve time-domain signals. Typically, spectrogram inversion is treated as an optimization problem involving one or several terms in order to promote estimates that comply with a consistency property, a mixing constraint, and/or a target magnitude objective. Nonetheless, it is still unclear which set of constraints and problem formulation is the most appropriate in practice. In this paper, we design a general framework for deriving spectrogram inversion algorithm, which is based on formulating optimization problems by combining these objectives either as soft penalties or hard constraints. We solve these by means of algorithms that perform alternating projections on the subsets corresponding to each objective/constraint. Our framework encompasses existing techniques from the literature as well as novel algorithms. We investigate the potential of these approaches for a speech enhancement task. In particular, one of our novel algorithms outperforms other approaches in a realistic setting where the magnitudes are estimated beforehand using a neural network.
Deep Neural Network Architecture Search for Accurate Visual Pose Estimation aboard Nano-UAVs
Mar 03, 2023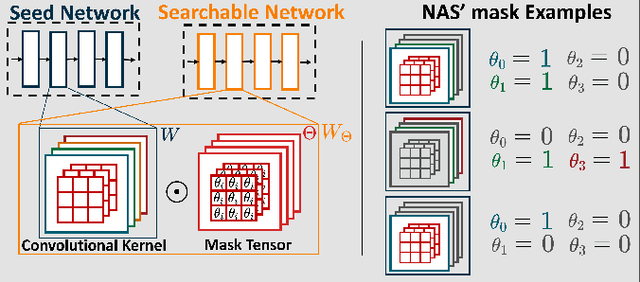
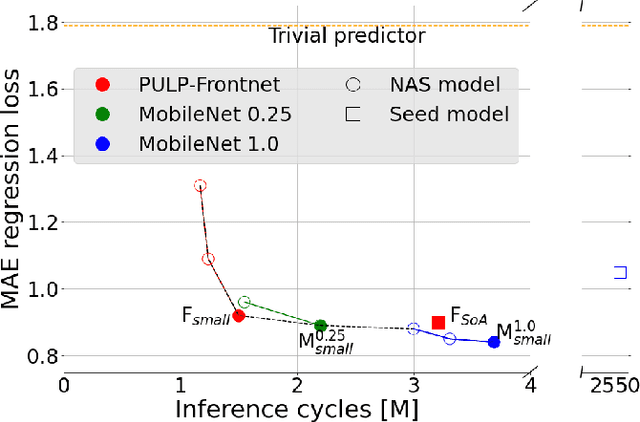
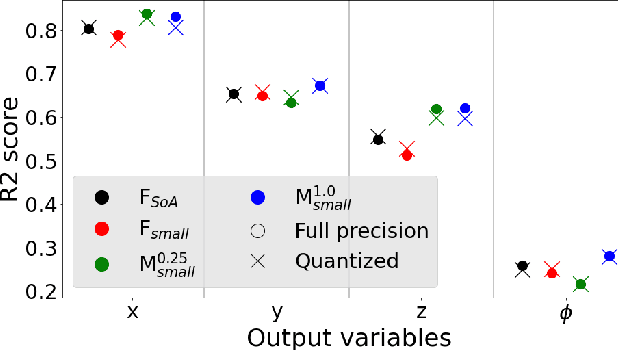
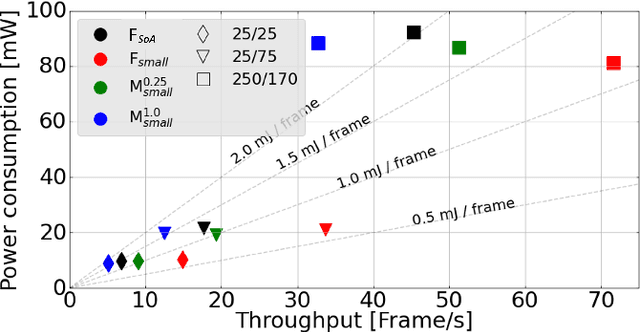
Miniaturized autonomous unmanned aerial vehicles (UAVs) are an emerging and trending topic. With their form factor as big as the palm of one hand, they can reach spots otherwise inaccessible to bigger robots and safely operate in human surroundings. The simple electronics aboard such robots (sub-100mW) make them particularly cheap and attractive but pose significant challenges in enabling onboard sophisticated intelligence. In this work, we leverage a novel neural architecture search (NAS) technique to automatically identify several Pareto-optimal convolutional neural networks (CNNs) for a visual pose estimation task. Our work demonstrates how real-life and field-tested robotics applications can concretely leverage NAS technologies to automatically and efficiently optimize CNNs for the specific hardware constraints of small UAVs. We deploy several NAS-optimized CNNs and run them in closed-loop aboard a 27-g Crazyflie nano-UAV equipped with a parallel ultra-low power System-on-Chip. Our results improve the State-of-the-Art by reducing the in-field control error of 32% while achieving a real-time onboard inference-rate of ~10Hz@10mW and ~50Hz@90mW.