 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Zero-Shot Self-Supervised Joint Temporal Image and Sensitivity Map Reconstruction via Linear Latent Space
Mar 03, 2023
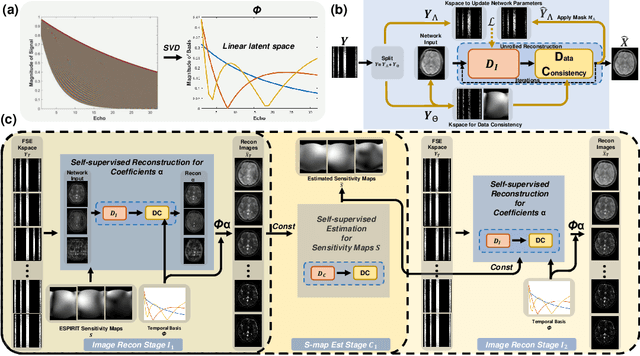
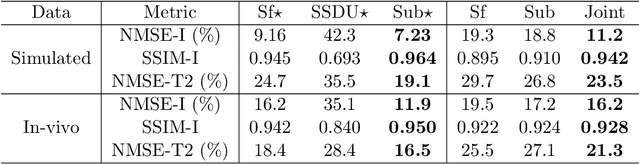
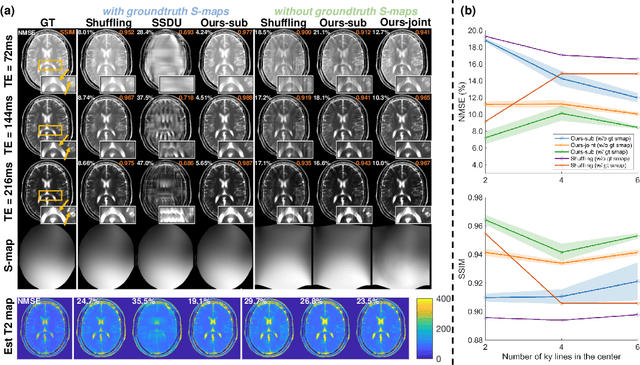
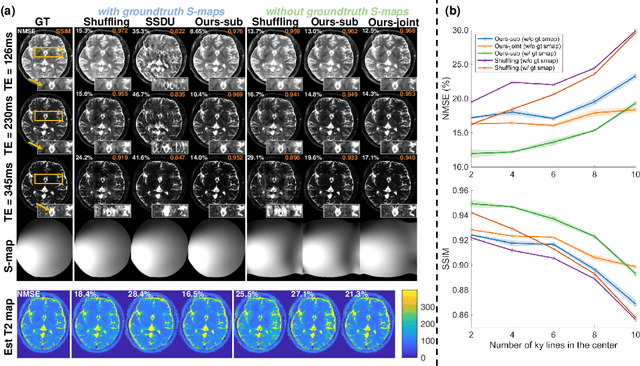
Fast spin-echo (FSE) pulse sequences for Magnetic Resonance Imaging (MRI) offer important imaging contrast in clinically feasible scan times. T2-shuffling is widely used to resolve temporal signal dynamics in FSE acquisitions by exploiting temporal correlations via linear latent space and a predefined regularizer. However, predefined regularizers fail to exploit the incoherence especially for 2D acquisitions.Recent self-supervised learning methods achieve high-fidelity reconstructions by learning a regularizer from undersampled data without a standard supervised training data set. In this work, we propose a novel approach that utilizes a self supervised learning framework to learn a regularizer constrained on a linear latent space which improves time-resolved FSE images reconstruction quality. Additionally, in regimes without groundtruth sensitivity maps, we propose joint estimation of coil-sensitivity maps using an iterative reconstruction technique. Our technique functions is in a zero-shot fashion, as it only utilizes data from a single scan of highly undersampled time series images. We perform experiments on simulated and retrospective in-vivo data to evaluate the performance of the proposed zero-shot learning method for temporal FSE reconstruction. The results demonstrate the success of our proposed method where NMSE and SSIM are significantly increased and the artifacts are reduced.
Adaptive Turbo Equalization of Probabilistically Shaped Constellations
Feb 24, 2023
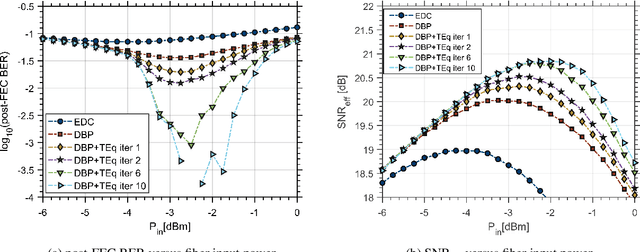

Fiber nonlinearity compensation of probabilistically shaped constellations with adaptive turbo equalization is investigated for the first time. Potential for more than 100% transmission reach extension is demonstrated by combining probabilistic shaping, single-channel digital backpropagation, and adaptive turbo equalization.
Spectrum-inspired Low-light Image Translation for Saliency Detection
Mar 17, 2023
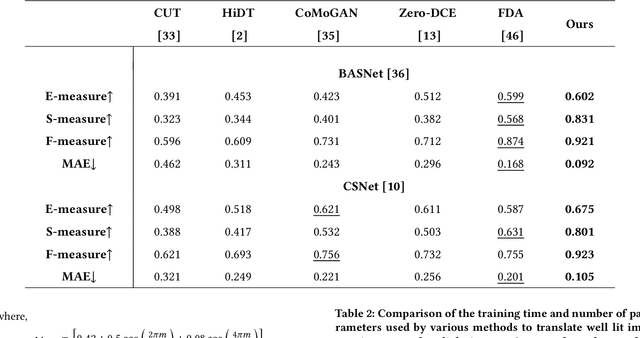
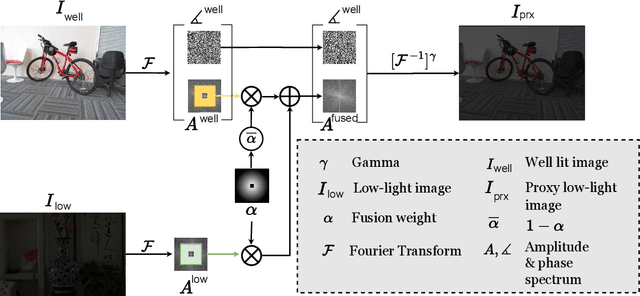

Saliency detection methods are central to several real-world applications such as robot navigation and satellite imagery. However, the performance of existing methods deteriorate under low-light conditions because training datasets mostly comprise of well-lit images. One possible solution is to collect a new dataset for low-light conditions. This involves pixel-level annotations, which is not only tedious and time-consuming but also infeasible if a huge training corpus is required. We propose a technique that performs classical band-pass filtering in the Fourier space to transform well-lit images to low-light images and use them as a proxy for real low-light images. Unlike popular deep learning approaches which require learning thousands of parameters and enormous amounts of training data, the proposed transformation is fast and simple and easy to extend to other tasks such as low-light depth estimation. Our experiments show that the state-of-the-art saliency detection and depth estimation networks trained on our proxy low-light images perform significantly better on real low-light images than networks trained using existing strategies.
Recent Developments in Machine Learning Methods for Stochastic Control and Games
Mar 17, 2023
Stochastic optimal control and games have found a wide range of applications, from finance and economics to social sciences, robotics and energy management. Many real-world applications involve complex models which have driven the development of sophisticated numerical methods. Recently, computational methods based on machine learning have been developed for stochastic control problems and games. We review such methods, with a focus on deep learning algorithms that have unlocked the possibility to solve such problems even when the dimension is high or when the structure is very complex, beyond what is feasible with traditional numerical methods. Here, we consider mostly the continuous time and continuous space setting. Many of the new approaches build on recent neural-network based methods for high-dimensional partial differential equations or backward stochastic differential equations, or on model-free reinforcement learning for Markov decision processes that have led to breakthrough results. In this paper we provide an introduction to these methods and summarize state-of-the-art works on machine learning for stochastic control and games.
No Fear of Classifier Biases: Neural Collapse Inspired Federated Learning with Synthetic and Fixed Classifier
Mar 17, 2023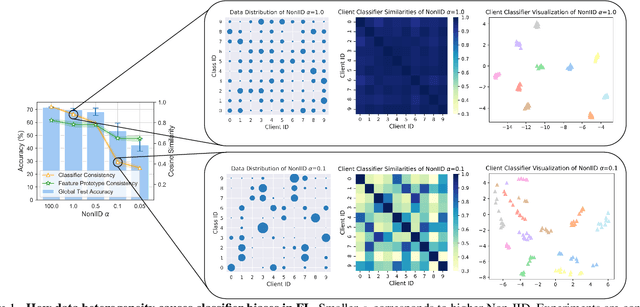
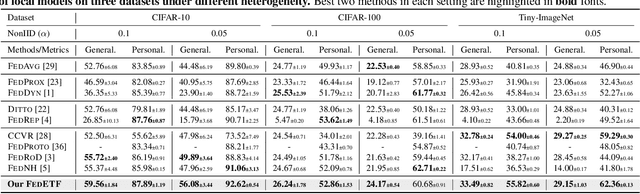
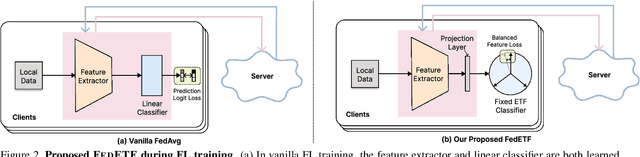
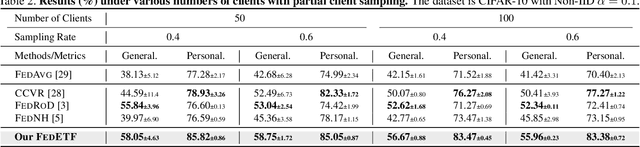
Data heterogeneity is an inherent challenge that hinders the performance of federated learning (FL). Recent studies have identified the biased classifiers of local models as the key bottleneck. Previous attempts have used classifier calibration after FL training, but this approach falls short in improving the poor feature representations caused by training-time classifier biases. Resolving the classifier bias dilemma in FL requires a full understanding of the mechanisms behind the classifier. Recent advances in neural collapse have shown that the classifiers and feature prototypes under perfect training scenarios collapse into an optimal structure called simplex equiangular tight frame (ETF). Building on this neural collapse insight, we propose a solution to the FL's classifier bias problem by utilizing a synthetic and fixed ETF classifier during training. The optimal classifier structure enables all clients to learn unified and optimal feature representations even under extremely heterogeneous data. We devise several effective modules to better adapt the ETF structure in FL, achieving both high generalization and personalization. Extensive experiments demonstrate that our method achieves state-of-the-art performances on CIFAR-10, CIFAR-100, and Tiny-ImageNet.
Mpox-AISM: AI-Mediated Super Monitoring for Forestalling Monkeypox Spread
Mar 17, 2023The challenge on forestalling monkeypox (Mpox) spread is the timely, convenient and accurate diagnosis for earlystage infected individuals. Here, we propose a remote and realtime online visualization strategy, called "Super Monitoring" to construct a low cost, convenient, timely and unspecialized diagnosis of early-stage Mpox. Such AI-mediated "Super Monitoring" (Mpox-AISM) invokes a framework assembled by deep learning, data augmentation and self-supervised learning, as well as professionally classifies four subtypes according to dataset characteristics and evolution trend of Mpox and seven other types of dermatopathya with high similarity, hence these features together with reasonable program interface and threshold setting ensure that its Recall (Sensitivity) was beyond 95.9% and the specificity was almost 100%. As a result, with the help of cloud service on Internet and communication terminal, this strategy can be potentially utilized for the real-time detection of earlystage Mpox in various scenarios including entry-exit inspection in airport, family doctor, rural area in underdeveloped region and wild to effectively shorten the window period of Mpox spread.
Edge Deep Learning Model Protection via Neuron Authorization
Mar 23, 2023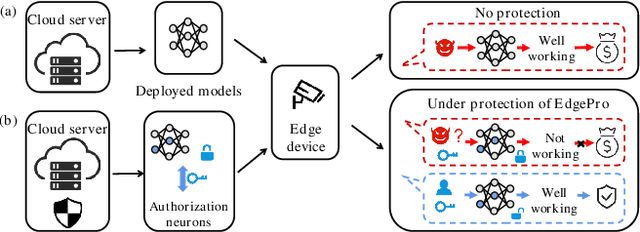
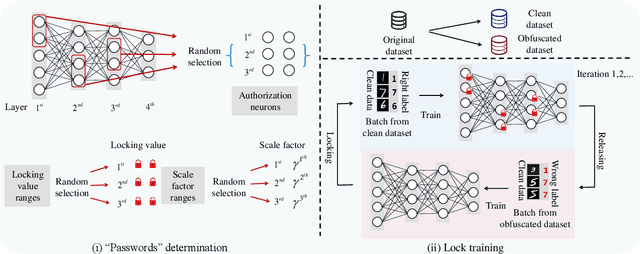

With the development of deep learning processors and accelerators, deep learning models have been widely deployed on edge devices as part of the Internet of Things. Edge device models are generally considered as valuable intellectual properties that are worth for careful protection. Unfortunately, these models have a great risk of being stolen or illegally copied. The existing model protections using encryption algorithms are suffered from high computation overhead which is not practical due to the limited computing capacity on edge devices. In this work, we propose a light-weight, practical, and general Edge device model Pro tection method at neuron level, denoted as EdgePro. Specifically, we select several neurons as authorization neurons and set their activation values to locking values and scale the neuron outputs as the "asswords" during training. EdgePro protects the model by ensuring it can only work correctly when the "passwords" are met, at the cost of encrypting and storing the information of the "passwords" instead of the whole model. Extensive experimental results indicate that EdgePro can work well on the task of protecting on datasets with different modes. The inference time increase of EdgePro is only 60% of state-of-the-art methods, and the accuracy loss is less than 1%. Additionally, EdgePro is robust against adaptive attacks including fine-tuning and pruning, which makes it more practical in real-world applications. EdgePro is also open sourced to facilitate future research: https://github.com/Leon022/Edg
Semantic Image Attack for Visual Model Diagnosis
Mar 23, 2023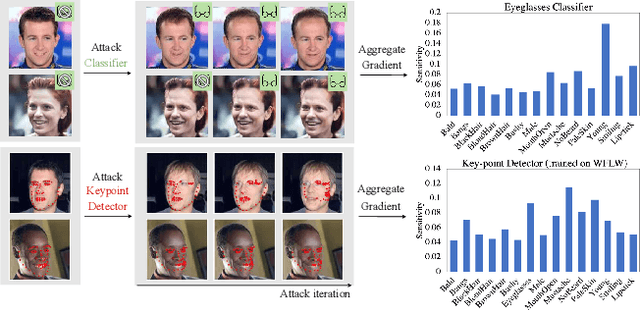

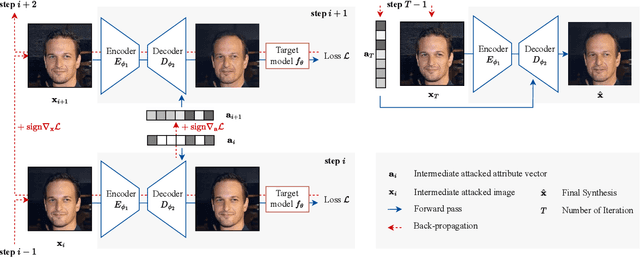
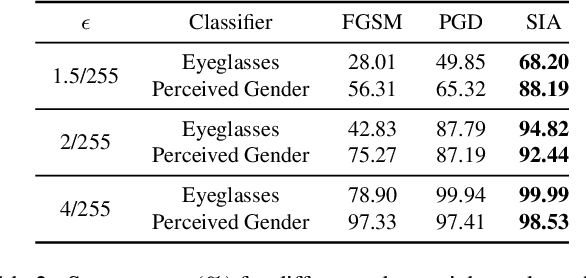
In practice, metric analysis on a specific train and test dataset does not guarantee reliable or fair ML models. This is partially due to the fact that obtaining a balanced, diverse, and perfectly labeled dataset is typically expensive, time-consuming, and error-prone. Rather than relying on a carefully designed test set to assess ML models' failures, fairness, or robustness, this paper proposes Semantic Image Attack (SIA), a method based on the adversarial attack that provides semantic adversarial images to allow model diagnosis, interpretability, and robustness. Traditional adversarial training is a popular methodology for robustifying ML models against attacks. However, existing adversarial methods do not combine the two aspects that enable the interpretation and analysis of the model's flaws: semantic traceability and perceptual quality. SIA combines the two features via iterative gradient ascent on a predefined semantic attribute space and the image space. We illustrate the validity of our approach in three scenarios for keypoint detection and classification. (1) Model diagnosis: SIA generates a histogram of attributes that highlights the semantic vulnerability of the ML model (i.e., attributes that make the model fail). (2) Stronger attacks: SIA generates adversarial examples with visually interpretable attributes that lead to higher attack success rates than baseline methods. The adversarial training on SIA improves the transferable robustness across different gradient-based attacks. (3) Robustness to imbalanced datasets: we use SIA to augment the underrepresented classes, which outperforms strong augmentation and re-balancing baselines.
OFA$^2$: A Multi-Objective Perspective for the Once-for-All Neural Architecture Search
Mar 23, 2023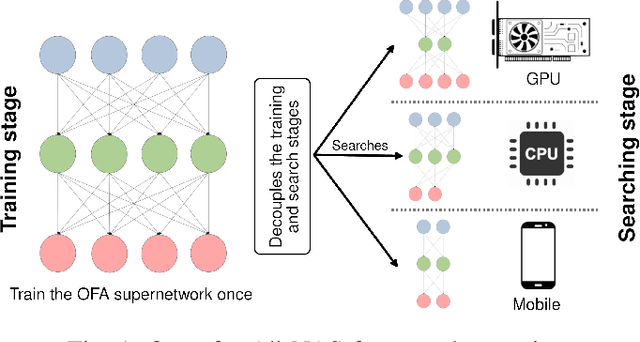
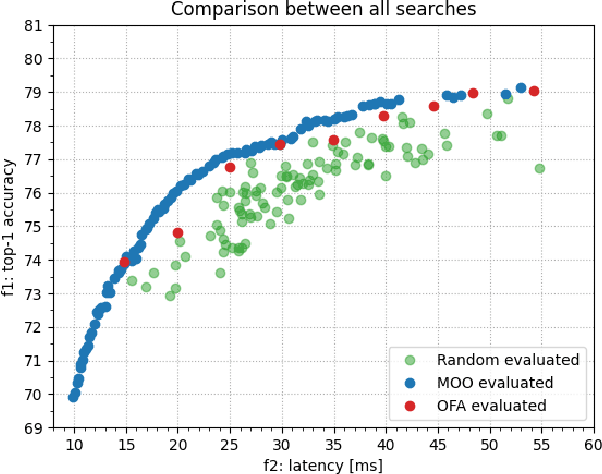
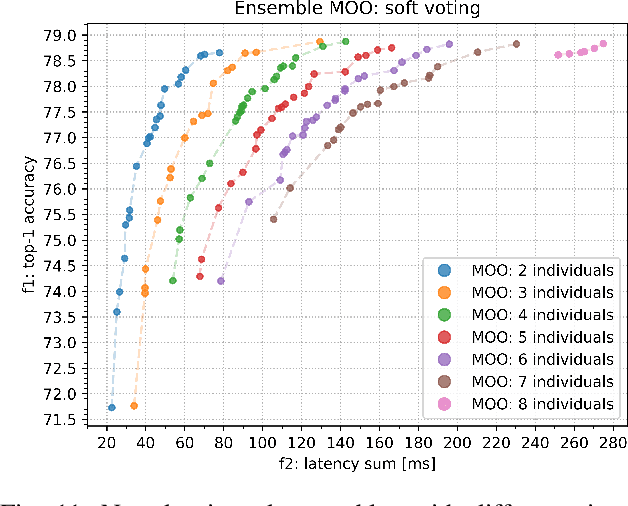
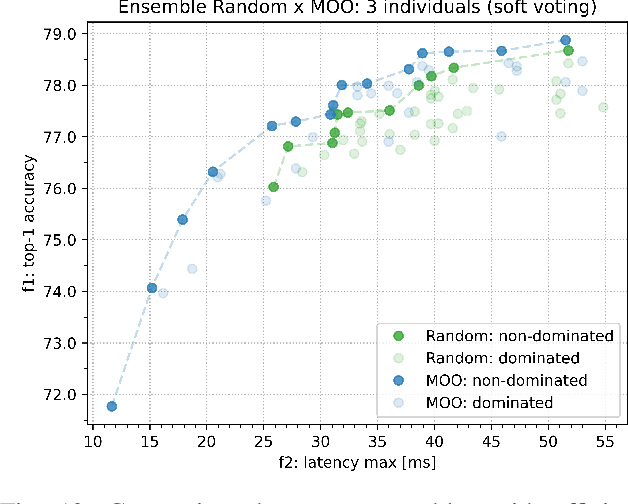
Once-for-All (OFA) is a Neural Architecture Search (NAS) framework designed to address the problem of searching efficient architectures for devices with different resources constraints by decoupling the training and the searching stages. The computationally expensive process of training the OFA neural network is done only once, and then it is possible to perform multiple searches for subnetworks extracted from this trained network according to each deployment scenario. In this work we aim to give one step further in the search for efficiency by explicitly conceiving the search stage as a multi-objective optimization problem. A Pareto frontier is then populated with efficient, and already trained, neural architectures exhibiting distinct trade-offs among the conflicting objectives. This could be achieved by using any multi-objective evolutionary algorithm during the search stage, such as NSGA-II and SMS-EMOA. In other words, the neural network is trained once, the searching for subnetworks considering different hardware constraints is also done one single time, and then the user can choose a suitable neural network according to each deployment scenario. The conjugation of OFA and an explicit algorithm for multi-objective optimization opens the possibility of a posteriori decision-making in NAS, after sampling efficient subnetworks which are a very good approximation of the Pareto frontier, given that those subnetworks are already trained and ready to use. The source code and the final search algorithm will be released at https://github.com/ito-rafael/once-for-all-2
Improvement of Color Image Analysis Using a New Hybrid Face Recognition Algorithm based on Discrete Wavelets and Chebyshev Polynomials
Mar 23, 2023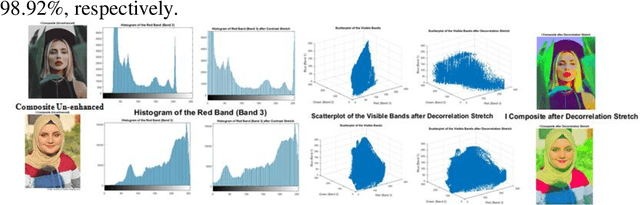
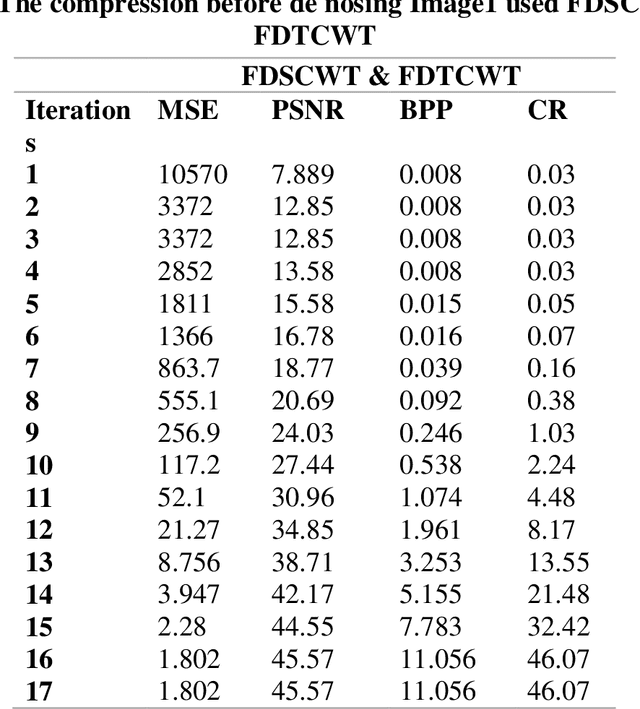
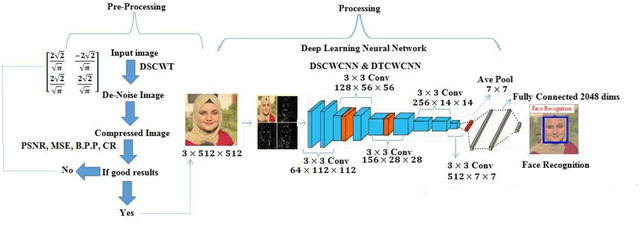
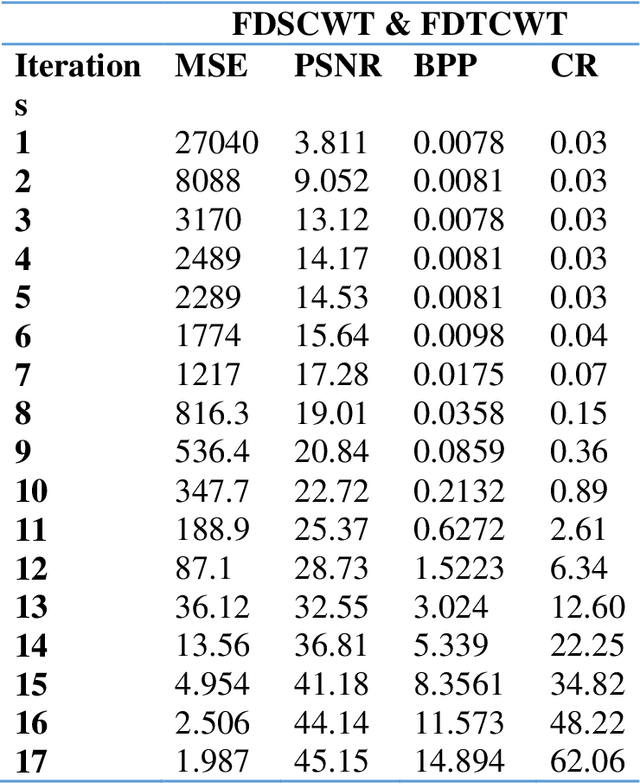
This work is unique in the use of discrete wavelets that were built from or derived from Chebyshev polynomials of the second and third kind, filter the Discrete Second Chebyshev Wavelets Transform (DSCWT), and derive two effective filters. The Filter Discrete Third Chebyshev Wavelets Transform (FDTCWT) is used in the process of analyzing color images and removing noise and impurities that accompany the image, as well as because of the large amount of data that makes up the image as it is taken. These data are massive, making it difficult to deal with each other during transmission. However to address this issue, the image compression technique is used, with the image not losing information due to the readings that were obtained, and the results were satisfactory. Mean Square Error (MSE), Peak Signal Noise Ratio (PSNR), Bit Per Pixel (BPP), and Compression Ratio (CR) Coronavirus is the initial treatment, while the processing stage is done with network training for Convolutional Neural Networks (CNN) with Discrete Second Chebeshev Wavelets Convolutional Neural Network (DSCWCNN) and Discrete Third Chebeshev Wavelets Convolutional Neural Network (DTCWCNN) to create an efficient algorithm for face recognition, and the best results were achieved in accuracy and in the least amount of time. Two samples of color images that were made or implemented were used. The proposed theory was obtained with fast and good results; the results are evident shown in the tables below.