 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Evil from Within: Machine Learning Backdoors through Hardware Trojans
Apr 18, 2023
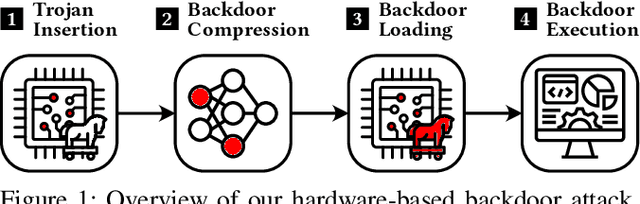
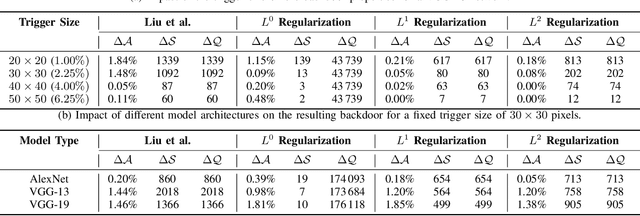
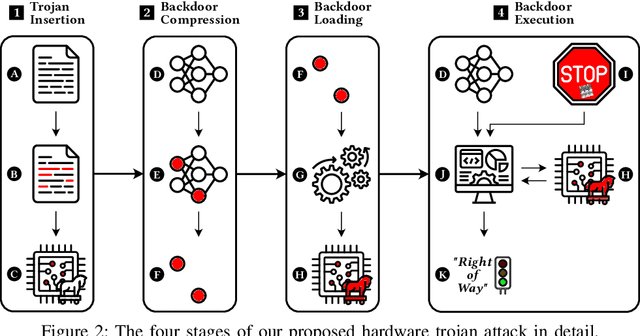
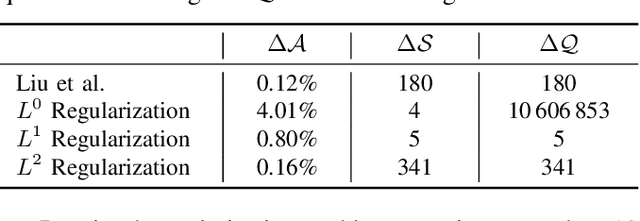
Backdoors pose a serious threat to machine learning, as they can compromise the integrity of security-critical systems, such as self-driving cars. While different defenses have been proposed to address this threat, they all rely on the assumption that the hardware on which the learning models are executed during inference is trusted. In this paper, we challenge this assumption and introduce a backdoor attack that completely resides within a common hardware accelerator for machine learning. Outside of the accelerator, neither the learning model nor the software is manipulated, so that current defenses fail. To make this attack practical, we overcome two challenges: First, as memory on a hardware accelerator is severely limited, we introduce the concept of a minimal backdoor that deviates as little as possible from the original model and is activated by replacing a few model parameters only. Second, we develop a configurable hardware trojan that can be provisioned with the backdoor and performs a replacement only when the specific target model is processed. We demonstrate the practical feasibility of our attack by implanting our hardware trojan into the Xilinx Vitis AI DPU, a commercial machine-learning accelerator. We configure the trojan with a minimal backdoor for a traffic-sign recognition system. The backdoor replaces only 30 (0.069%) model parameters, yet it reliably manipulates the recognition once the input contains a backdoor trigger. Our attack expands the hardware circuit of the accelerator by 0.24% and induces no run-time overhead, rendering a detection hardly possible. Given the complex and highly distributed manufacturing process of current hardware, our work points to a new threat in machine learning that is inaccessible to current security mechanisms and calls for hardware to be manufactured only in fully trusted environments.
Differentiable Genetic Programming for High-dimensional Symbolic Regression
Apr 18, 2023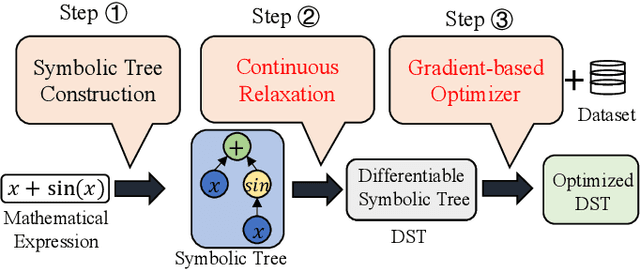
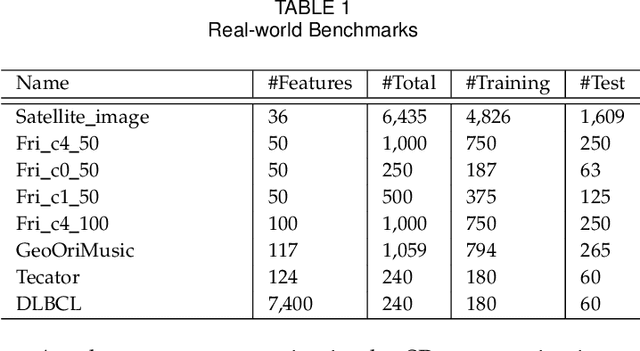
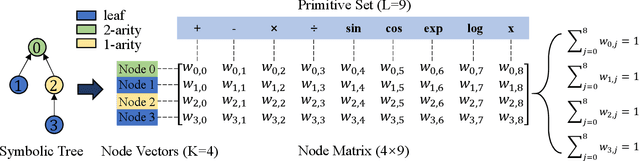

Symbolic regression (SR) is the process of discovering hidden relationships from data with mathematical expressions, which is considered an effective way to reach interpretable machine learning (ML). Genetic programming (GP) has been the dominator in solving SR problems. However, as the scale of SR problems increases, GP often poorly demonstrates and cannot effectively address the real-world high-dimensional problems. This limitation is mainly caused by the stochastic evolutionary nature of traditional GP in constructing the trees. In this paper, we propose a differentiable approach named DGP to construct GP trees towards high-dimensional SR for the first time. Specifically, a new data structure called differentiable symbolic tree is proposed to relax the discrete structure to be continuous, thus a gradient-based optimizer can be presented for the efficient optimization. In addition, a sampling method is proposed to eliminate the discrepancy caused by the above relaxation for valid symbolic expressions. Furthermore, a diversification mechanism is introduced to promote the optimizer escaping from local optima for globally better solutions. With these designs, the proposed DGP method can efficiently search for the GP trees with higher performance, thus being capable of dealing with high-dimensional SR. To demonstrate the effectiveness of DGP, we conducted various experiments against the state of the arts based on both GP and deep neural networks. The experiment results reveal that DGP can outperform these chosen peer competitors on high-dimensional regression benchmarks with dimensions varying from tens to thousands. In addition, on the synthetic SR problems, the proposed DGP method can also achieve the best recovery rate even with different noisy levels. It is believed this work can facilitate SR being a powerful alternative to interpretable ML for a broader range of real-world problems.
An Extreme-Adaptive Time Series Prediction Model Based on Probability-Enhanced LSTM Neural Networks
Nov 29, 2022

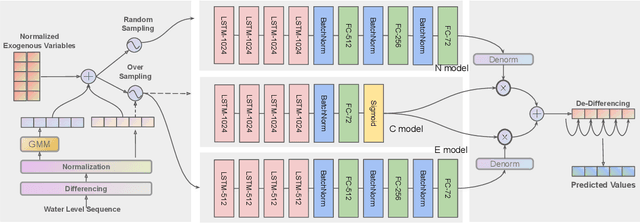
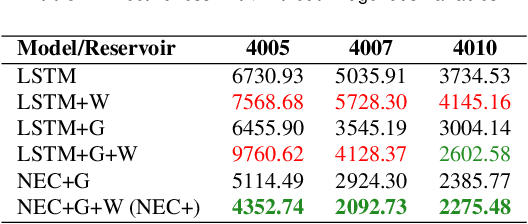
Forecasting time series with extreme events has been a challenging and prevalent research topic, especially when the time series data are affected by complicated uncertain factors, such as is the case in hydrologic prediction. Diverse traditional and deep learning models have been applied to discover the nonlinear relationships and recognize the complex patterns in these types of data. However, existing methods usually ignore the negative influence of imbalanced data, or severe events, on model training. Moreover, methods are usually evaluated on a small number of generally well-behaved time series, which does not show their ability to generalize. To tackle these issues, we propose a novel probability-enhanced neural network model, called NEC+, which concurrently learns extreme and normal prediction functions and a way to choose among them via selective back propagation. We evaluate the proposed model on the difficult 3-day ahead hourly water level prediction task applied to 9 reservoirs in California. Experimental results demonstrate that the proposed model significantly outperforms state-of-the-art baselines and exhibits superior generalization ability on data with diverse distributions.
Vicious Classifiers: Data Reconstruction Attack at Inference Time
Dec 08, 2022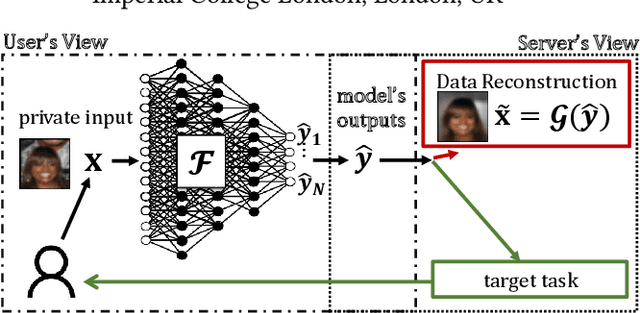
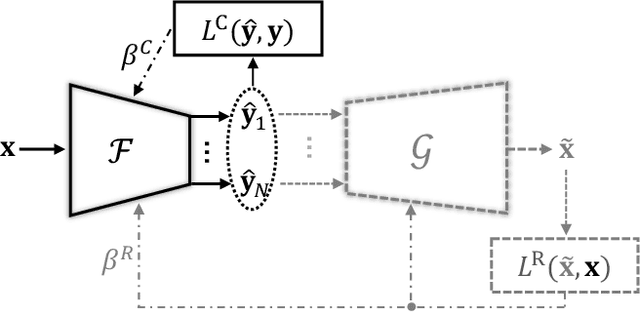
Privacy-preserving inference via edge or encrypted computing paradigms encourages users of machine learning services to confidentially run a model on their personal data for a target task and only share the model's outputs with the service provider; e.g., to activate further services. Nevertheless, despite all confidentiality efforts, we show that a ''vicious'' service provider can approximately reconstruct its users' personal data by observing only the model's outputs, while keeping the target utility of the model very close to that of a ''honest'' service provider. We show the possibility of jointly training a target model (to be run at users' side) and an attack model for data reconstruction (to be secretly used at server's side). We introduce the ''reconstruction risk'': a new measure for assessing the quality of reconstructed data that better captures the privacy risk of such attacks. Experimental results on 6 benchmark datasets show that for low-complexity data types, or for tasks with larger number of classes, a user's personal data can be approximately reconstructed from the outputs of a single target inference task. We propose a potential defense mechanism that helps to distinguish vicious vs. honest classifiers at inference time. We conclude this paper by discussing current challenges and open directions for future studies. We open-source our code and results, as a benchmark for future work.
Machine Learning Enhanced Hankel Dynamic-Mode Decomposition
Mar 11, 2023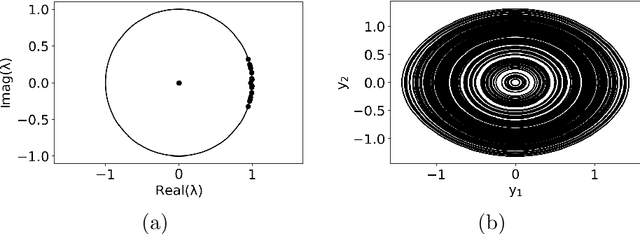
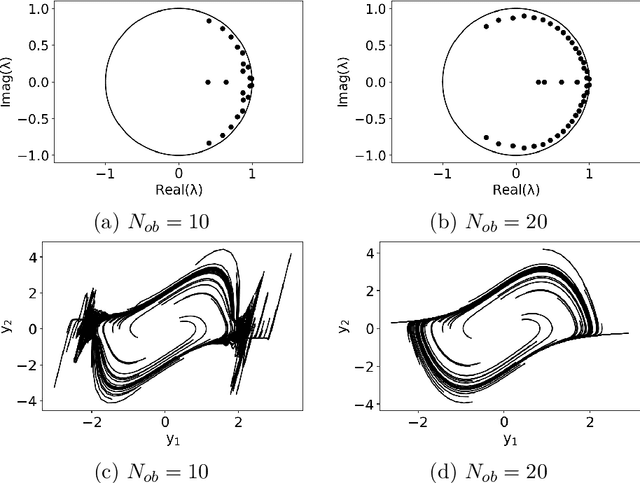
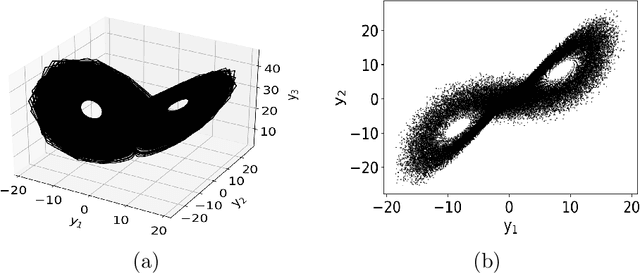
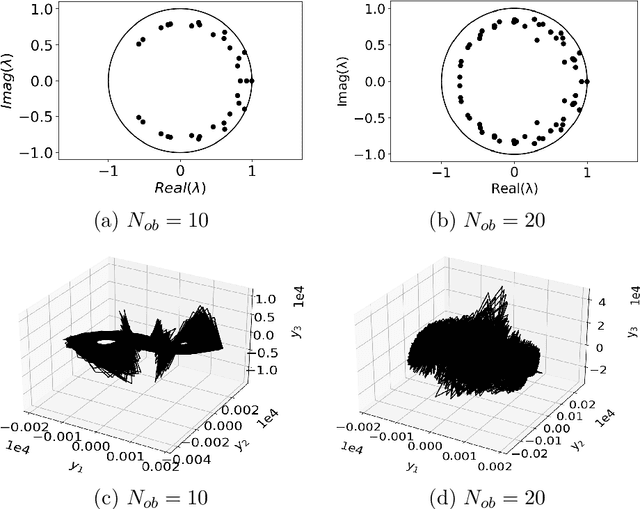
While the acquisition of time series has become increasingly more straightforward and sophisticated, developing dynamical models from time series is still a challenging and ever evolving problem domain. Within the last several years, to address this problem, there has been a merging of machine learning tools with what is called the dynamic mode decomposition (DMD). This general approach has been shown to be an especially promising avenue for sophisticated and accurate model development. Building on this prior body of work, we develop a deep learning DMD based method which makes use of the fundamental insight of Takens' Embedding Theorem to develop an adaptive learning scheme that better captures higher dimensional and chaotic dynamics. We call this method the Deep Learning Hankel DMD (DLHDMD). We show that the DLHDMD is able to generate accurate dynamics for chaotic time series, and we likewise explore how our method learns mappings which tend, after successful training, to significantly change the mutual information between dimensions in the dynamics. This appears to be a key feature in enhancing the DMD overall, and it should help provide further insight for developing more sophisticated deep learning methods for time series forecasting.
UniverSeg: Universal Medical Image Segmentation
Apr 12, 2023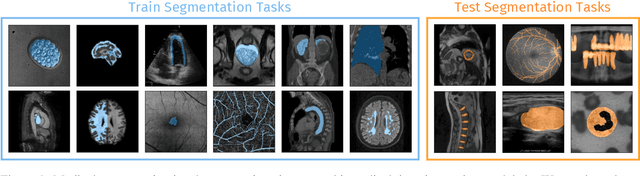

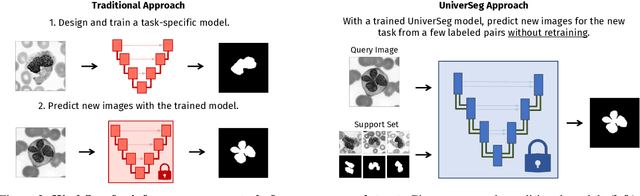
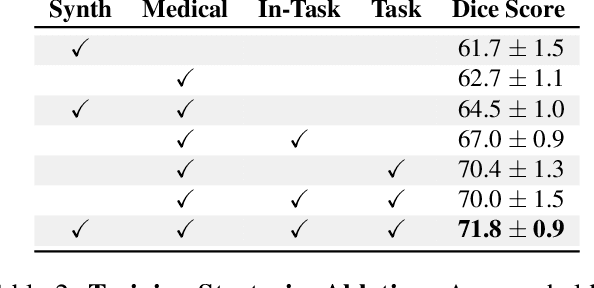
While deep learning models have become the predominant method for medical image segmentation, they are typically not capable of generalizing to unseen segmentation tasks involving new anatomies, image modalities, or labels. Given a new segmentation task, researchers generally have to train or fine-tune models, which is time-consuming and poses a substantial barrier for clinical researchers, who often lack the resources and expertise to train neural networks. We present UniverSeg, a method for solving unseen medical segmentation tasks without additional training. Given a query image and example set of image-label pairs that define a new segmentation task, UniverSeg employs a new Cross-Block mechanism to produce accurate segmentation maps without the need for additional training. To achieve generalization to new tasks, we have gathered and standardized a collection of 53 open-access medical segmentation datasets with over 22,000 scans, which we refer to as MegaMedical. We used this collection to train UniverSeg on a diverse set of anatomies and imaging modalities. We demonstrate that UniverSeg substantially outperforms several related methods on unseen tasks, and thoroughly analyze and draw insights about important aspects of the proposed system. The UniverSeg source code and model weights are freely available at https://universeg.csail.mit.edu
RESET: Revisiting Trajectory Sets for Conditional Behavior Prediction
Apr 12, 2023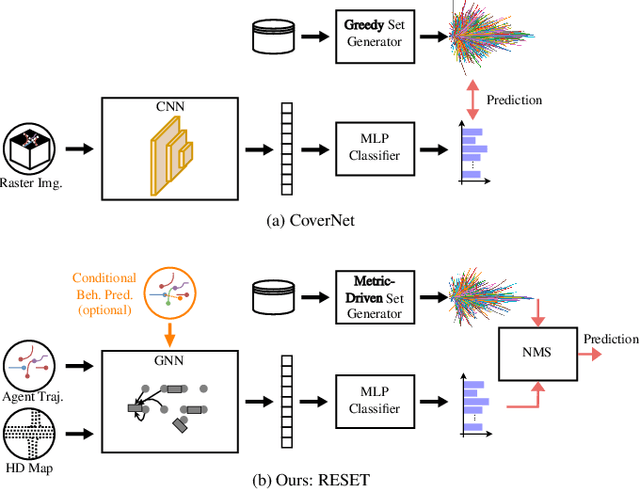
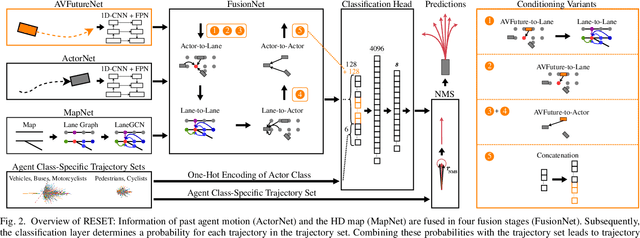
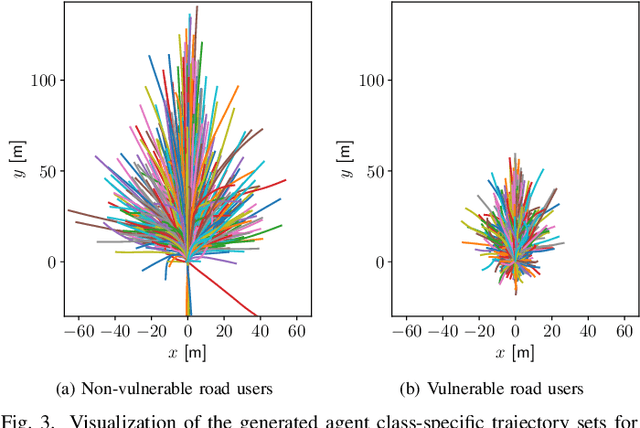
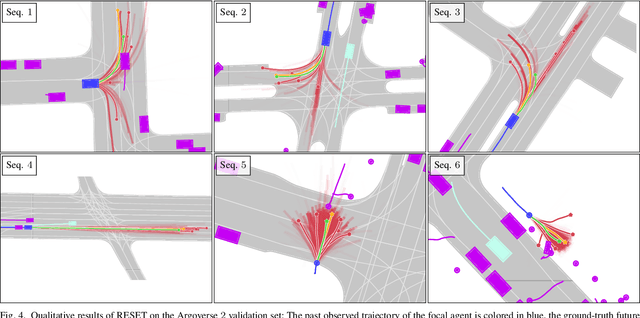
It is desirable to predict the behavior of traffic participants conditioned on different planned trajectories of the autonomous vehicle. This allows the downstream planner to estimate the impact of its decisions. Recent approaches for conditional behavior prediction rely on a regression decoder, meaning that coordinates or polynomial coefficients are regressed. In this work we revisit set-based trajectory prediction, where the probability of each trajectory in a predefined trajectory set is determined by a classification model, and first-time employ it to the task of conditional behavior prediction. We propose RESET, which combines a new metric-driven algorithm for trajectory set generation with a graph-based encoder. For unconditional prediction, RESET achieves comparable performance to a regression-based approach. Due to the nature of set-based approaches, it has the advantageous property of being able to predict a flexible number of trajectories without influencing runtime or complexity. For conditional prediction, RESET achieves reasonable results with late fusion of the planned trajectory, which was not observed for regression-based approaches before. This means that RESET is computationally lightweight to combine with a planner that proposes multiple future plans of the autonomous vehicle, as large parts of the forward pass can be reused.
Precise localization of corneal reflections in eye images using deep learning trained on synthetic data
Apr 12, 2023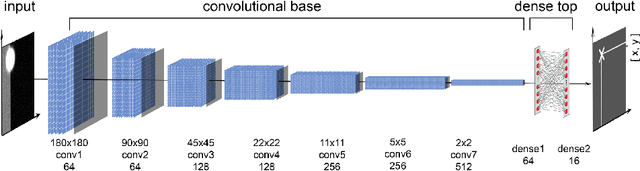

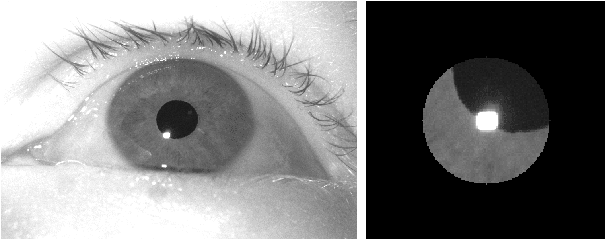
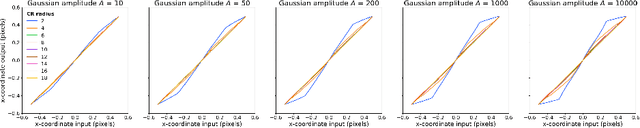
We present a deep learning method for accurately localizing the center of a single corneal reflection (CR) in an eye image. Unlike previous approaches, we use a convolutional neural network (CNN) that was trained solely using simulated data. Using only simulated data has the benefit of completely sidestepping the time-consuming process of manual annotation that is required for supervised training on real eye images. To systematically evaluate the accuracy of our method, we first tested it on images with simulated CRs placed on different backgrounds and embedded in varying levels of noise. Second, we tested the method on high-quality videos captured from real eyes. Our method outperformed state-of-the-art algorithmic methods on real eye images with a 35% reduction in terms of spatial precision, and performed on par with state-of-the-art on simulated images in terms of spatial accuracy.We conclude that our method provides a precise method for CR center localization and provides a solution to the data availability problem which is one of the important common roadblocks in the development of deep learning models for gaze estimation. Due to the superior CR center localization and ease of application, our method has the potential to improve the accuracy and precision of CR-based eye trackers
Modality-Invariant Representation for Infrared and Visible Image Registration
Apr 12, 2023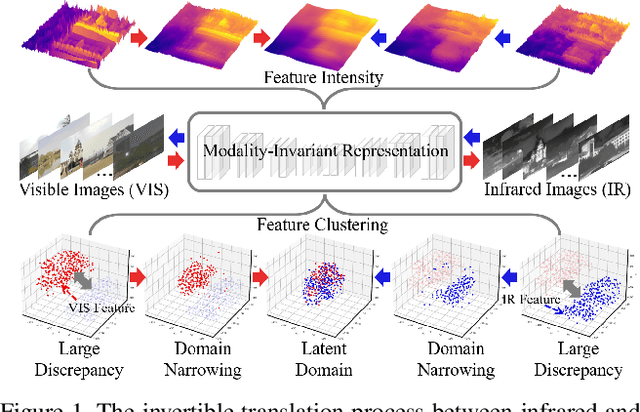
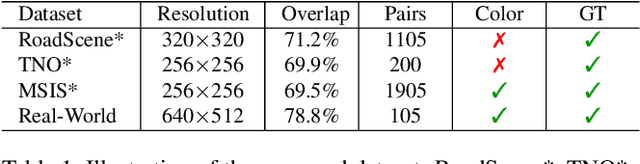
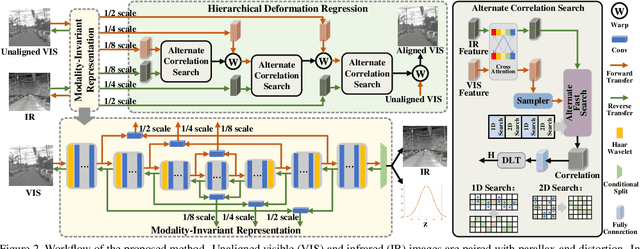
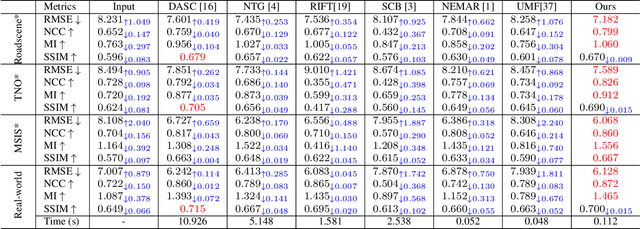
Since the differences in viewing range, resolution and relative position, the multi-modality sensing module composed of infrared and visible cameras needs to be registered so as to have more accurate scene perception. In practice, manual calibration-based registration is the most widely used process, and it is regularly calibrated to maintain accuracy, which is time-consuming and labor-intensive. To cope with these problems, we propose a scene-adaptive infrared and visible image registration. Specifically, in regard of the discrepancy between multi-modality images, an invertible translation process is developed to establish a modality-invariant domain, which comprehensively embraces the feature intensity and distribution of both infrared and visible modalities. We employ homography to simulate the deformation between different planes and develop a hierarchical framework to rectify the deformation inferred from the proposed latent representation in a coarse-to-fine manner. For that, the advanced perception ability coupled with the residual estimation conducive to the regression of sparse offsets, and the alternate correlation search facilitates a more accurate correspondence matching. Moreover, we propose the first ground truth available misaligned infrared and visible image dataset, involving three synthetic sets and one real-world set. Extensive experiments validate the effectiveness of the proposed method against the state-of-the-arts, advancing the subsequent applications.
A Scalable Framework for Automatic Playlist Continuation on Music Streaming Services
Apr 12, 2023
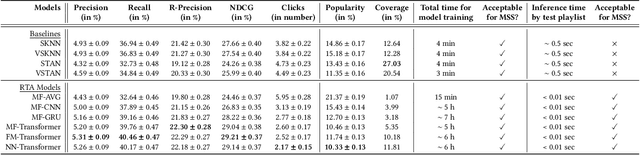
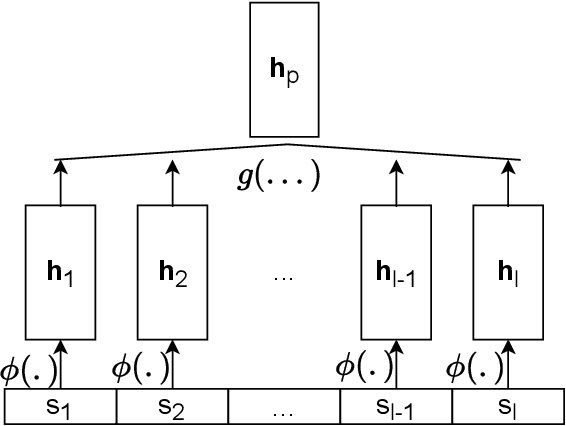
Music streaming services often aim to recommend songs for users to extend the playlists they have created on these services. However, extending playlists while preserving their musical characteristics and matching user preferences remains a challenging task, commonly referred to as Automatic Playlist Continuation (APC). Besides, while these services often need to select the best songs to recommend in real-time and among large catalogs with millions of candidates, recent research on APC mainly focused on models with few scalability guarantees and evaluated on relatively small datasets. In this paper, we introduce a general framework to build scalable yet effective APC models for large-scale applications. Based on a represent-then-aggregate strategy, it ensures scalability by design while remaining flexible enough to incorporate a wide range of representation learning and sequence modeling techniques, e.g., based on Transformers. We demonstrate the relevance of this framework through in-depth experimental validation on Spotify's Million Playlist Dataset (MPD), the largest public dataset for APC. We also describe how, in 2022, we successfully leveraged this framework to improve APC in production on Deezer. We report results from a large-scale online A/B test on this service, emphasizing the practical impact of our approach in such a real-world application.