 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Generative AI Perceptions: A Survey to Measure the Perceptions of Faculty, Staff, and Students on Generative AI Tools in Academia
Apr 21, 2023



ChatGPT is a natural language processing tool that can engage in human-like conversations and generate coherent and contextually relevant responses to various prompts. ChatGPT is capable of understanding natural text that is input by a user and generating appropriate responses in various forms. This tool represents a major step in how humans are interacting with technology. This paper specifically focuses on how ChatGPT is revolutionizing the realm of engineering education and the relationship between technology, students, and faculty and staff. Because this tool is quickly changing and improving with the potential for even greater future capability, it is a critical time to collect pertinent data. A survey was created to measure the effects of ChatGPT on students, faculty, and staff. This survey is shared as a Texas A&M University technical report to allow other universities and entities to use this survey and measure the effects elsewhere.
Consensus Complementarity Control for Multi-Contact MPC
Apr 21, 2023
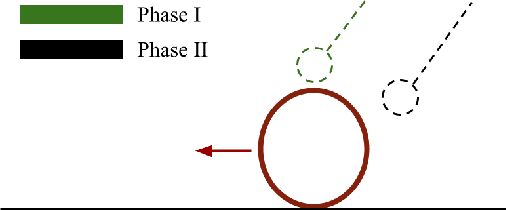
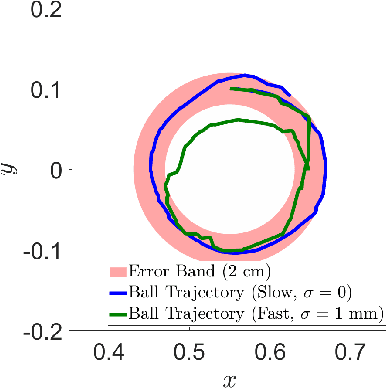

We propose a hybrid model predictive control algorithm, consensus complementarity control (C3), for systems that make and break contact with their environment. Many state-of-the-art controllers for tasks which require initiating contact with the environment, such as locomotion and manipulation, require a priori mode schedules or are too computationally complex to run at real-time rates. We present a method based on the alternating direction method of multipliers (ADMM) that is capable of high-speed reasoning over potential contact events. Via a consensus formulation, our approach enables parallelization of the contact scheduling problem. We validate our results on five numerical examples, including four high-dimensional frictional contact problems, and a physical experimentation on an underactuated multi-contact system. We further demonstrate the effectiveness of our method on a physical experiment accomplishing a high-dimensional, multi-contact manipulation task with a robot arm.
BoDiffusion: Diffusing Sparse Observations for Full-Body Human Motion Synthesis
Apr 21, 2023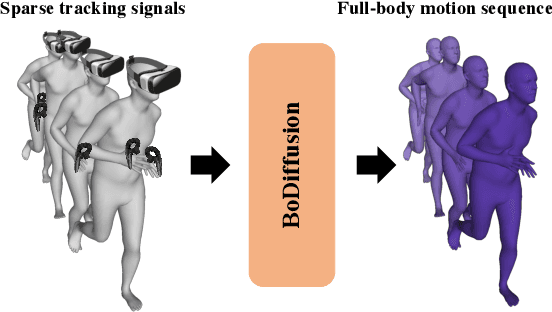

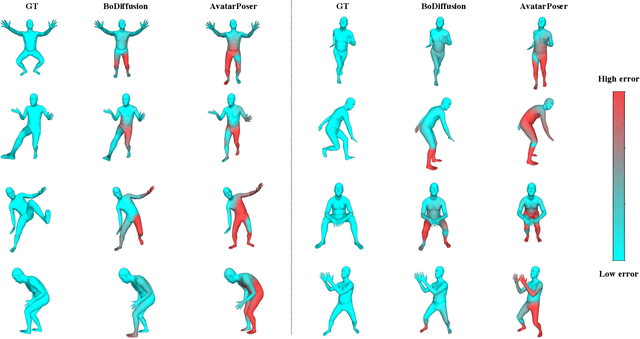
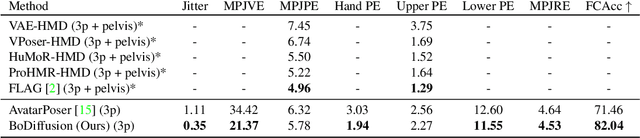
Mixed reality applications require tracking the user's full-body motion to enable an immersive experience. However, typical head-mounted devices can only track head and hand movements, leading to a limited reconstruction of full-body motion due to variability in lower body configurations. We propose BoDiffusion -- a generative diffusion model for motion synthesis to tackle this under-constrained reconstruction problem. We present a time and space conditioning scheme that allows BoDiffusion to leverage sparse tracking inputs while generating smooth and realistic full-body motion sequences. To the best of our knowledge, this is the first approach that uses the reverse diffusion process to model full-body tracking as a conditional sequence generation task. We conduct experiments on the large-scale motion-capture dataset AMASS and show that our approach outperforms the state-of-the-art approaches by a significant margin in terms of full-body motion realism and joint reconstruction error.
Panoramic Image-to-Image Translation
Apr 11, 2023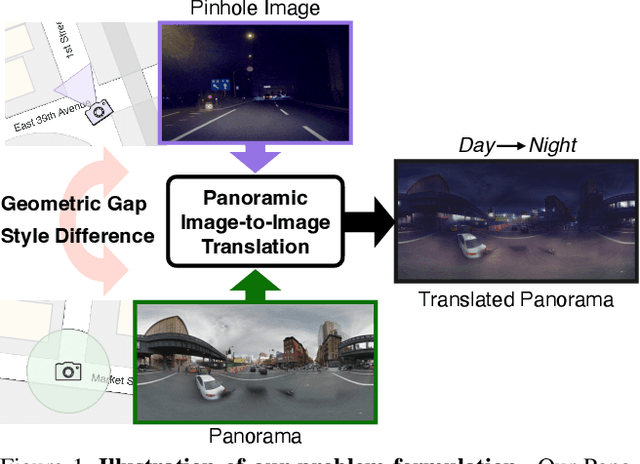
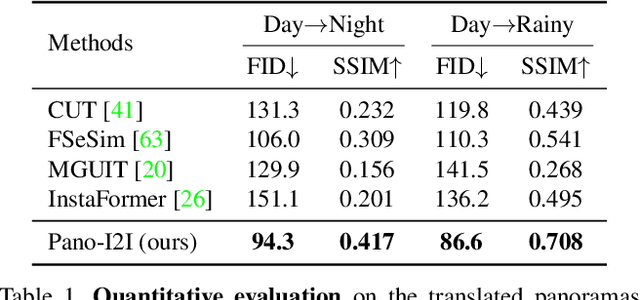
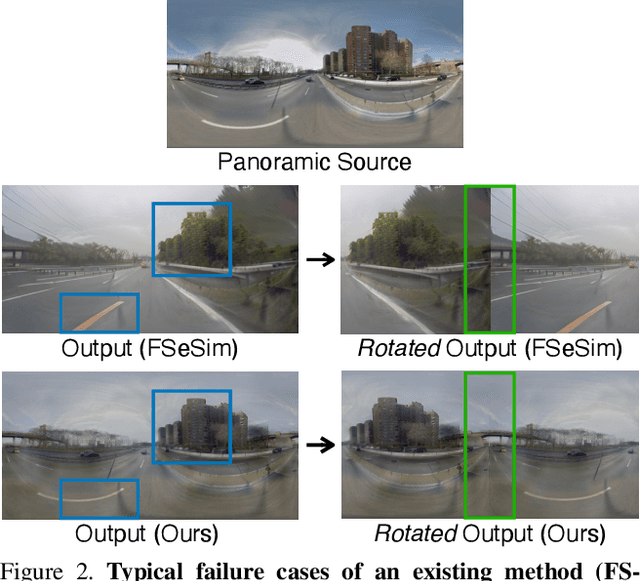

In this paper, we tackle the challenging task of Panoramic Image-to-Image translation (Pano-I2I) for the first time. This task is difficult due to the geometric distortion of panoramic images and the lack of a panoramic image dataset with diverse conditions, like weather or time. To address these challenges, we propose a panoramic distortion-aware I2I model that preserves the structure of the panoramic images while consistently translating their global style referenced from a pinhole image. To mitigate the distortion issue in naive 360 panorama translation, we adopt spherical positional embedding to our transformer encoders, introduce a distortion-free discriminator, and apply sphere-based rotation for augmentation and its ensemble. We also design a content encoder and a style encoder to be deformation-aware to deal with a large domain gap between panoramas and pinhole images, enabling us to work on diverse conditions of pinhole images. In addition, considering the large discrepancy between panoramas and pinhole images, our framework decouples the learning procedure of the panoramic reconstruction stage from the translation stage. We show distinct improvements over existing I2I models in translating the StreetLearn dataset in the daytime into diverse conditions. The code will be publicly available online for our community.
Fracture Detection in Pediatric Wrist Trauma X-ray Images Using YOLOv8 Algorithm
Apr 11, 2023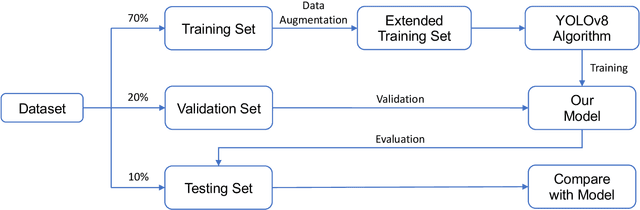
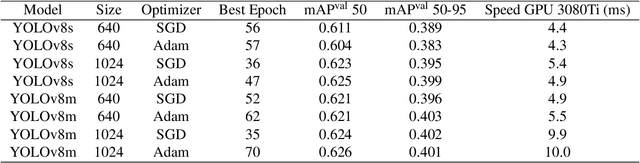
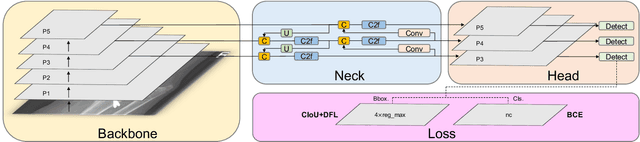
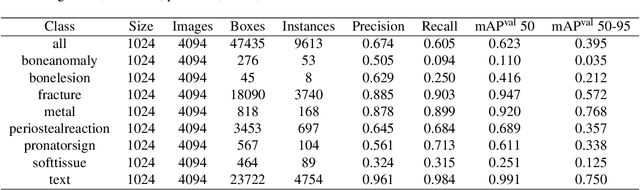
Hospital emergency departments frequently receive lots of bone fracture cases, with pediatric wrist trauma fracture accounting for the majority of them. Before pediatric surgeons perform surgery, they need to ask patients how the fracture occurred and analyze the fracture situation by interpreting X-ray images. The interpretation of X-ray images often requires a combination of techniques from radiologists and surgeons, which requires time-consuming specialized training. With the rise of deep learning in the field of computer vision, network models applying for fracture detection has become an important research topic. In this paper, YOLOv8 algorithm is used to train models on the GRAZPEDWRI-DX dataset, which includes X-ray images from 6,091 pediatric patients with wrist trauma. The experimental results show that YOLOv8 algorithm models have different advantages for different model sizes, with YOLOv8l model achieving the highest mean average precision (mAP 50) of 63.6\%, and YOLOv8n model achieving the inference time of 67.4ms per X-ray image on one single CPU with low computing power. In this way, we create "Fracture Detection Using YOLOv8 App" to assist surgeons in interpreting X-ray images without the help of radiologists. Our implementation code is released at https://github.com/RuiyangJu/Bone_Fracture_Detection_YOLOv8.
Bounding Box Annotation with Visible Status
Apr 11, 2023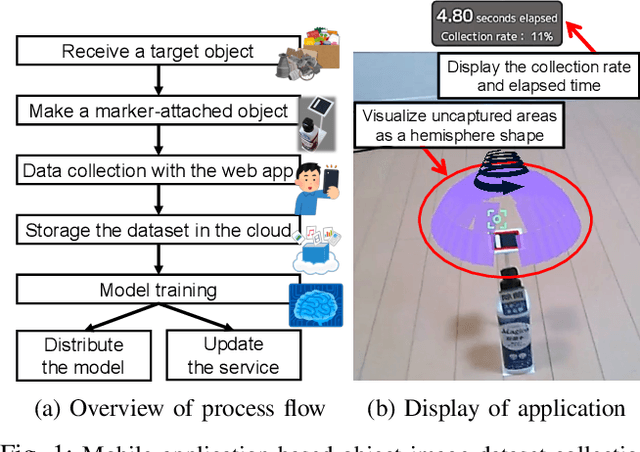
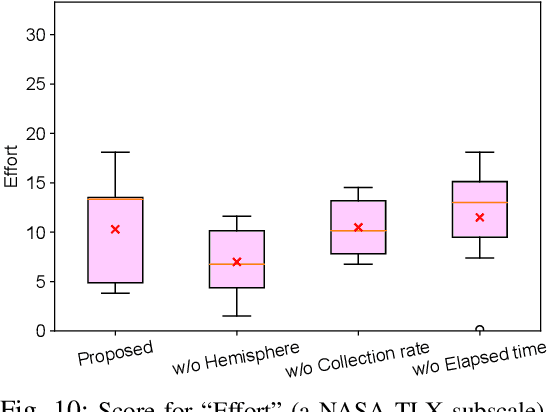
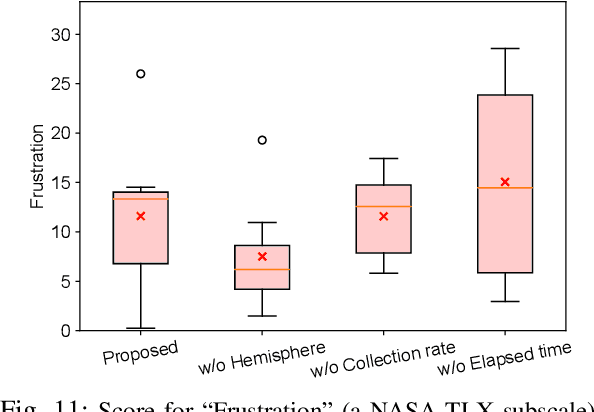
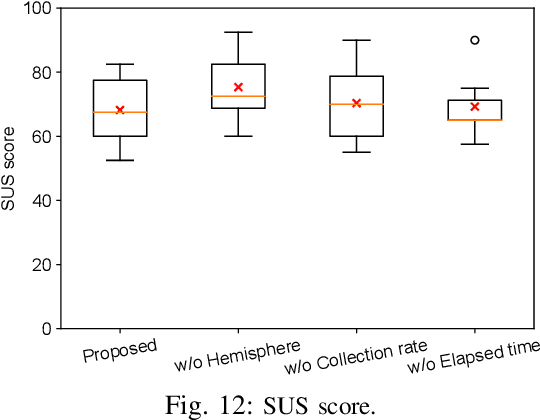
Training deep-learning-based vision systems requires the manual annotation of a significant amount of data to optimize several parameters of the deep convolutional neural networks. Such manual annotation is highly time-consuming and labor-intensive. To reduce this burden, a previous study presented a fully automated annotation approach that does not require any manual intervention. The proposed method associates a visual marker with an object and captures it in the same image. However, because the previous method relied on moving the object within the capturing range using a fixed-point camera, the collected image dataset was limited in terms of capturing viewpoints. To overcome this limitation, this study presents a mobile application-based free-viewpoint image-capturing method. With the proposed application, users can collect multi-view image datasets automatically that are annotated with bounding boxes by moving the camera. However, capturing images through human involvement is laborious and monotonous. Therefore, we propose gamified application features to track the progress of the collection status. Our experiments demonstrated that using the gamified mobile application for bounding box annotation, with visible collection progress status, can motivate users to collect multi-view object image datasets with less mental workload and time pressure in an enjoyable manner, leading to increased engagement.
DeFT-AN: Dense Frequency-Time Attentive Network for Multichannel Speech Enhancement
Dec 15, 2022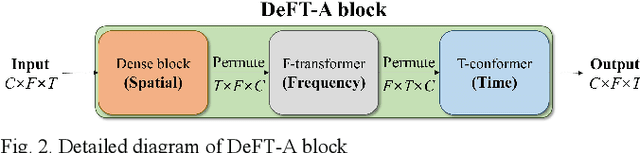
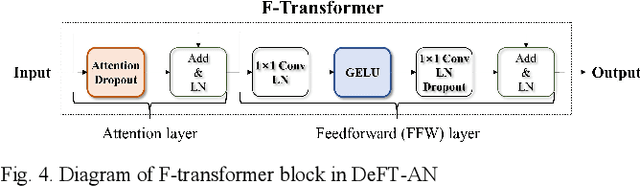
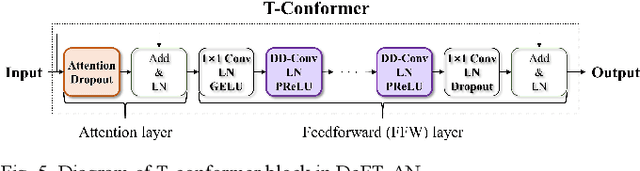
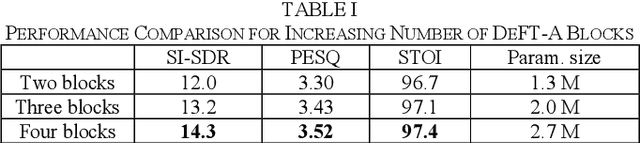
In this study, we propose a dense frequency-time attentive network (DeFT-AN) for multichannel speech enhancement. DeFT-AN is a mask estimation network that predicts a complex spectral masking pattern for suppressing the noise and reverberation embedded in the short-time Fourier transform (STFT) of an input signal. The proposed mask estimation network incorporates three different types of blocks for aggregating information in the spatial, spectral, and temporal dimensions. It utilizes a spectral transformer with a modified feed-forward network and a temporal conformer with sequential dilated convolutions. The use of dense blocks and transformers dedicated to the three different characteristics of audio signals enables more comprehensive denoising and dereverberation. The remarkable performance of DeFT-AN over state-of-the-art multichannel models is demonstrated based on two popular noisy and reverberant datasets in terms of various metrics for speech quality and intelligibility.
Aiding reinforcement learning for set point control
Apr 20, 2023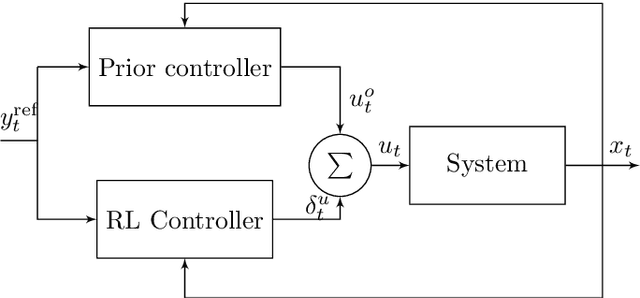

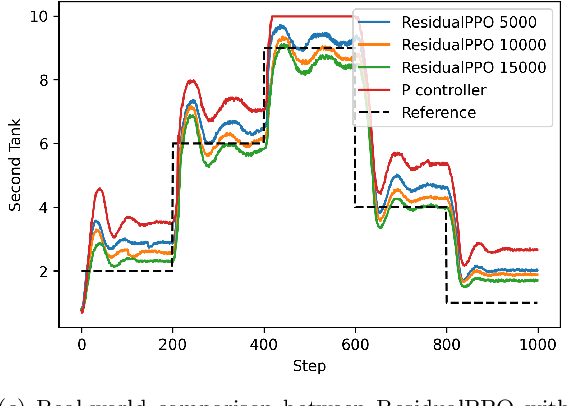
While reinforcement learning has made great improvements, state-of-the-art algorithms can still struggle with seemingly simple set-point feedback control problems. One reason for this is that the learned controller may not be able to excite the system dynamics well enough initially, and therefore it can take a long time to get data that is informative enough to learn for good control. The paper contributes by augmentation of reinforcement learning with a simple guiding feedback controller, for example, a proportional controller. The key advantage in set point control is a much improved excitation that improves the convergence properties of the reinforcement learning controller significantly. This can be very important in real-world control where quick and accurate convergence is needed. The proposed method is evaluated with simulation and on a real-world double tank process with promising results.
Autonomous Agent for Beyond Visual Range Air Combat: A Deep Reinforcement Learning Approach
Apr 19, 2023
This work contributes to developing an agent based on deep reinforcement learning capable of acting in a beyond visual range (BVR) air combat simulation environment. The paper presents an overview of building an agent representing a high-performance fighter aircraft that can learn and improve its role in BVR combat over time based on rewards calculated using operational metrics. Also, through self-play experiments, it expects to generate new air combat tactics never seen before. Finally, we hope to examine a real pilot's ability, using virtual simulation, to interact in the same environment with the trained agent and compare their performances. This research will contribute to the air combat training context by developing agents that can interact with real pilots to improve their performances in air defense missions.
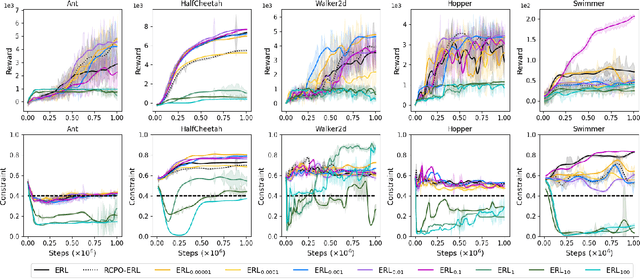
Evolving Constrained Reinforcement Learning Policy
Apr 19, 2023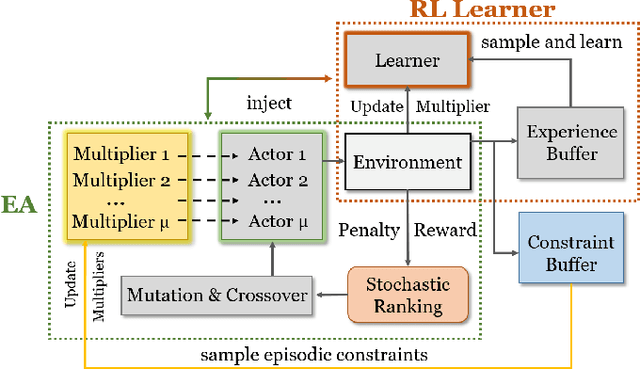

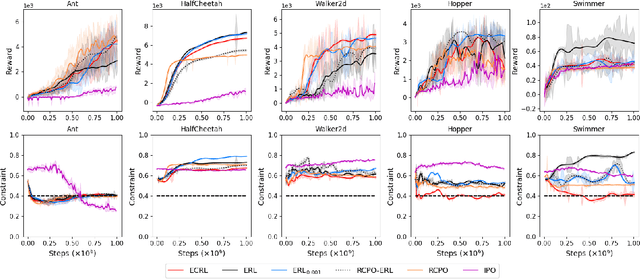
Evolutionary algorithms have been used to evolve a population of actors to generate diverse experiences for training reinforcement learning agents, which helps to tackle the temporal credit assignment problem and improves the exploration efficiency. However, when adapting this approach to address constrained problems, balancing the trade-off between the reward and constraint violation is hard. In this paper, we propose a novel evolutionary constrained reinforcement learning (ECRL) algorithm, which adaptively balances the reward and constraint violation with stochastic ranking, and at the same time, restricts the policy's behaviour by maintaining a set of Lagrange relaxation coefficients with a constraint buffer. Extensive experiments on robotic control benchmarks show that our ECRL achieves outstanding performance compared to state-of-the-art algorithms. Ablation analysis shows the benefits of introducing stochastic ranking and constraint buffer.