 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Local-to-Global Information Communication for Real-Time Semantic Segmentation Network Search
Feb 16, 2023
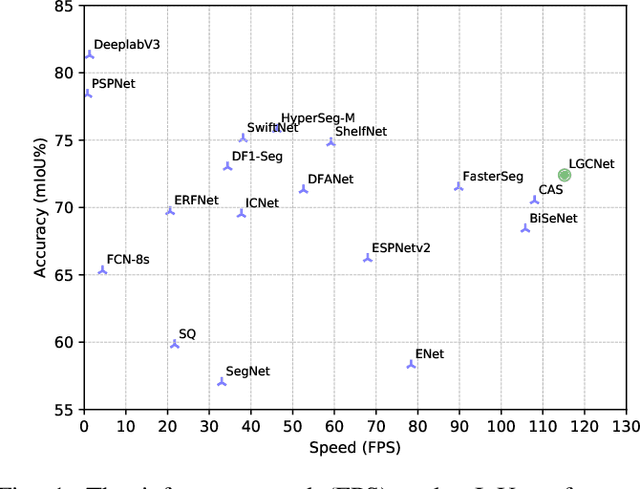
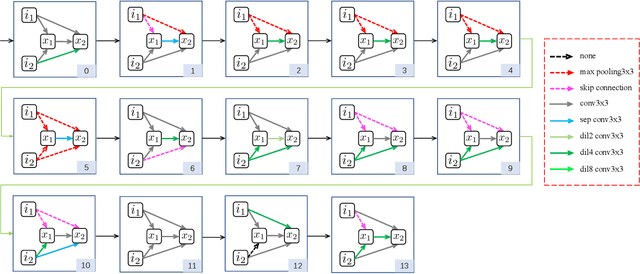
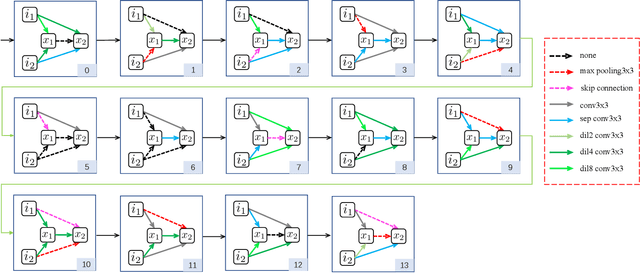
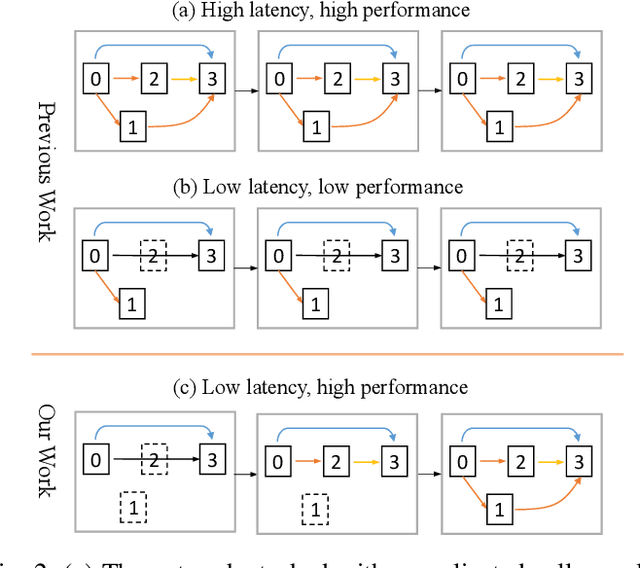
Neural Architecture Search (NAS) has shown great potentials in automatically designing neural network architectures for real-time semantic segmentation. Unlike previous works that utilize a simplified search space with cell-sharing way, we introduce a new search space where a lightweight model can be more effectively searched by replacing the cell-sharing manner with cell-independent one. Based on this, the communication of local to global information is achieved through two well-designed modules. For local information exchange, a graph convolutional network (GCN) guided module is seamlessly integrated as a communication deliver between cells. For global information aggregation, we propose a novel dense-connected fusion module (cell) which aggregates long-range multi-level features in the network automatically. In addition, a latency-oriented constraint is endowed into the search process to balance the accuracy and latency. We name the proposed framework as Local-to-Global Information Communication Network Search (LGCNet). Extensive experiments on Cityscapes and CamVid datasets demonstrate that LGCNet achieves the new state-of-the-art trade-off between accuracy and speed. In particular, on Cityscapes dataset, LGCNet achieves the new best performance of 74.0\% mIoU with the speed of 115.2 FPS on Titan Xp.
Understanding of Normal and Abnormal Hearts by Phase Space Analysis and Convolutional Neural Networks
May 16, 2023Cardiac diseases are one of the leading mortality factors in modern, industrialized societies, which cause high expenses in public health systems. Due to high costs, developing analytical methods to improve cardiac diagnostics is essential. The heart's electric activity was first modeled using a set of nonlinear differential equations. Following this, variations of cardiac spectra originating from deterministic dynamics are investigated. Analyzing a normal human heart's power spectra offers His-Purkinje network, which possesses a fractal-like structure. Phase space trajectories are extracted from the time series electrocardiogram (ECG) graph with third-order derivate Taylor Series. Here in this study, phase space analysis and Convolutional Neural Networks (CNNs) method are applied to 44 records via the MIT-BIH database recorded with MLII. In order to increase accuracy, a straight line is drawn between the highest Q-R distance in the phase space images of the records. Binary CNN classification is used to determine healthy or unhealthy hearts. With a 90.90% accuracy rate, this model could classify records according to their heart status.
Efficient Computation of General Modules for ALC Ontologies (Extended Version)
May 16, 2023

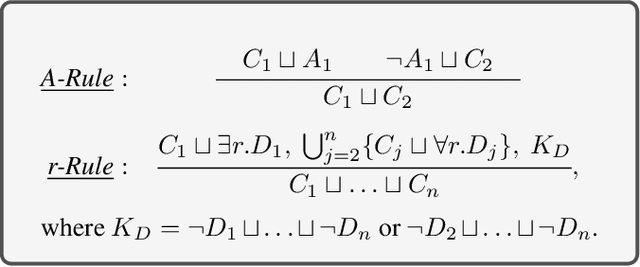

We present a method for extracting general modules for ontologies formulated in the description logic ALC. A module for an ontology is an ideally substantially smaller ontology that preserves all entailments for a user-specified set of terms. As such, it has applications such as ontology reuse and ontology analysis. Different from classical modules, general modules may use axioms not explicitly present in the input ontology, which allows for additional conciseness. So far, general modules have only been investigated for lightweight description logics. We present the first work that considers the more expressive description logic ALC. In particular, our contribution is a new method based on uniform interpolation supported by some new theoretical results. Our evaluation indicates that our general modules are often smaller than classical modules and uniform interpolants computed by the state-of-the-art, and compared with uniform interpolants, can be computed in a significantly shorter time. Moreover, our method can be used for, and in fact improves, the computation of uniform interpolants and classical modules.
Unlimiformer: Long-Range Transformers with Unlimited Length Input
May 02, 2023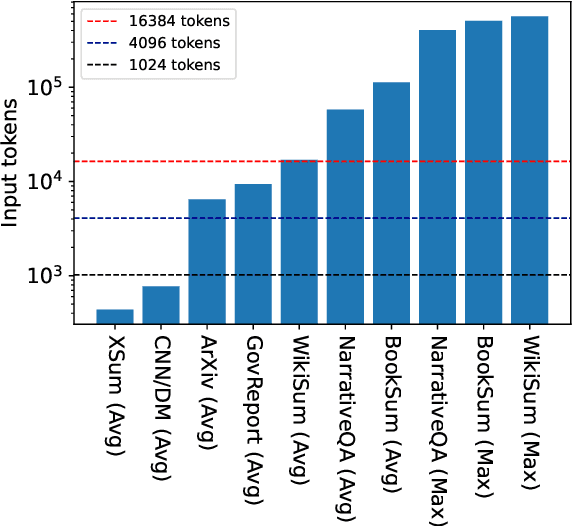


Transformer-based models typically have a predefined bound to their input length, because of their need to potentially attend to every token in the input. In this work, we propose Unlimiformer: a general approach that can wrap any existing pretrained encoder-decoder transformer, and offload the attention computation across all layers to a single $k$-nearest-neighbor index; this index can be kept on either the GPU or CPU memory and queried in sub-linear time. This way, we can index extremely long input sequences, while every attention head in every decoder layer retrieves its top-$k$ keys, instead of attending to every key. We demonstrate Unlimiformers's efficacy on several long-document and multi-document summarization benchmarks, showing that it can summarize even 350k token-long inputs from the BookSum dataset, without any input truncation at test time. Unlimiformer improves pretrained models such as BART and Longformer by extending them to unlimited inputs without additional learned weights and without modifying their code. We make our code and models publicly available at https://github.com/abertsch72/unlimiformer .
Mixed-Integer Optimal Control via Reinforcement Learning: A Case Study on Hybrid Vehicle Energy Management
May 02, 2023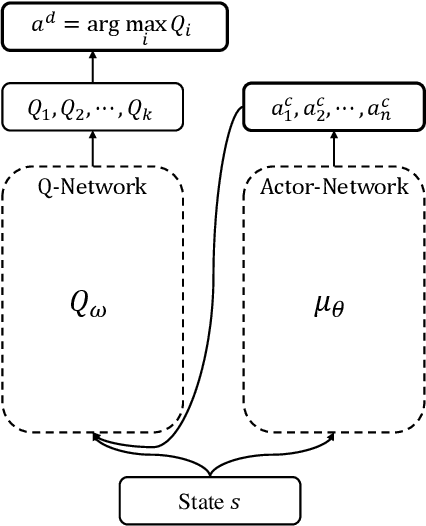
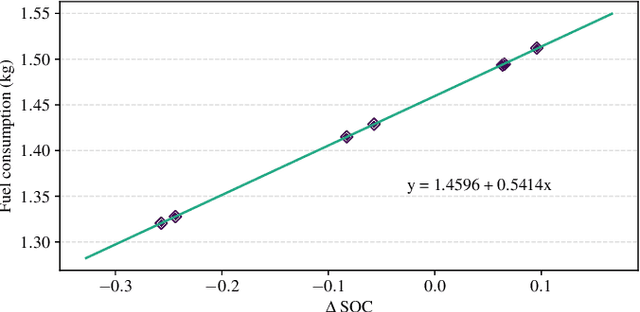
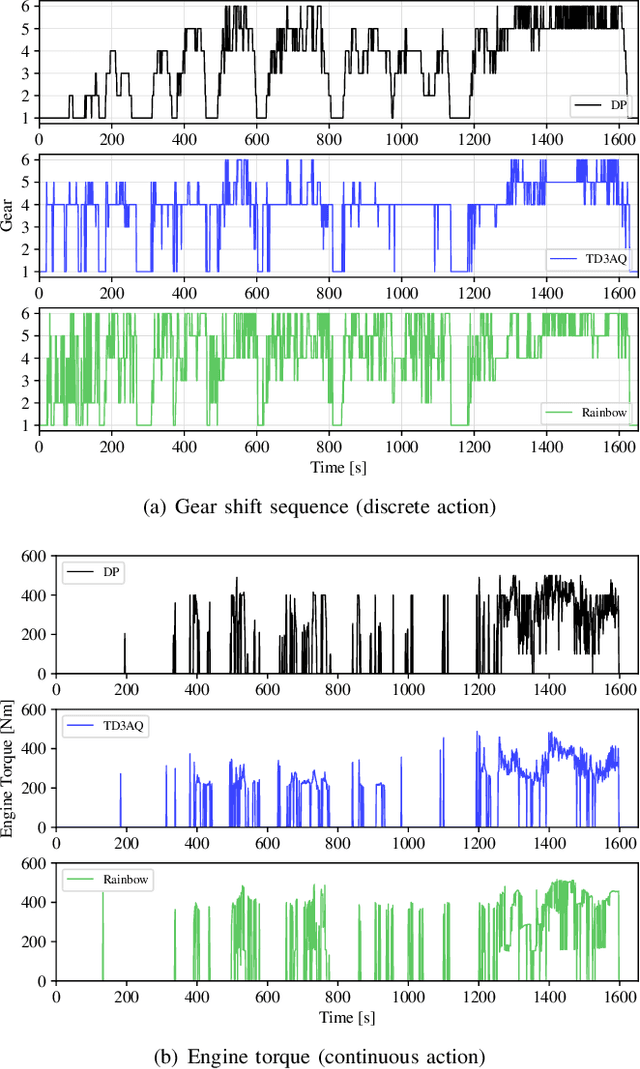
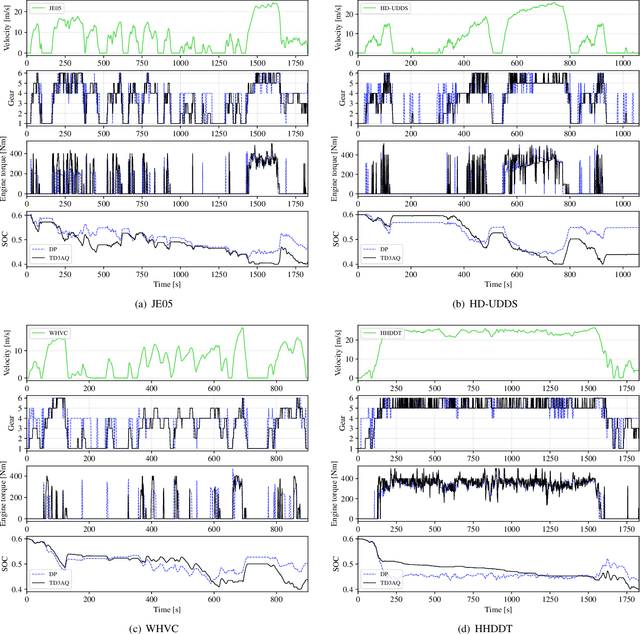
Many optimal control problems require the simultaneous output of continuous and discrete control variables. Such problems are usually formulated as mixed-integer optimal control (MIOC) problems, which are challenging to solve due to the complexity of the solution space. Numerical methods such as branch-and-bound are computationally expensive and unsuitable for real-time control. This paper proposes a novel continuous-discrete reinforcement learning (CDRL) algorithm, twin delayed deep deterministic actor-Q (TD3AQ), for MIOC problems. TD3AQ combines the advantages of both actor-critic and Q-learning methods, and can handle the continuous and discrete action spaces simultaneously. The proposed algorithm is evaluated on a hybrid electric vehicle (HEV) energy management problem, where real-time control of the continuous variable engine torque and discrete variable gear ratio is essential to maximize fuel economy while satisfying driving constraints. Simulation results on different drive cycles show that TD3AQ can achieve near-optimal solutions compared to dynamic programming (DP) and outperforms the state-of-the-art discrete RL algorithm Rainbow, which is adopted for MIOC by discretizing continuous actions into a finite set of discrete values.
Real-Time Model-Free Deep Reinforcement Learning for Force Control of a Series Elastic Actuator
Apr 11, 2023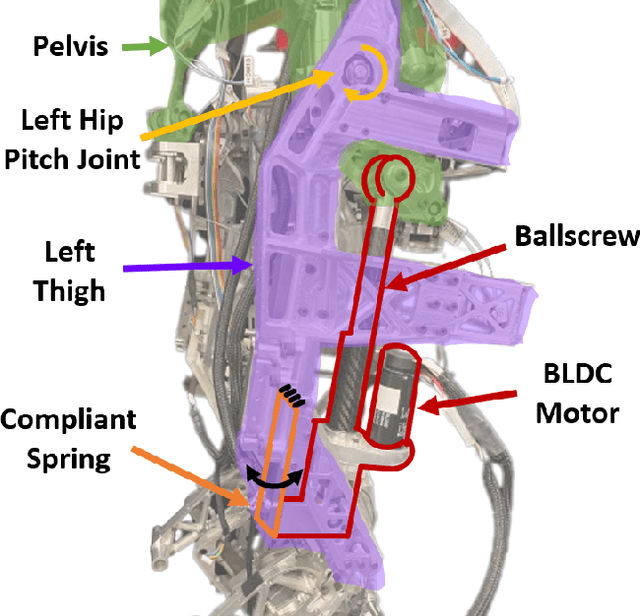
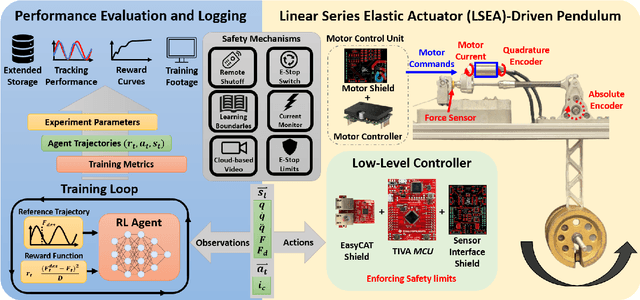
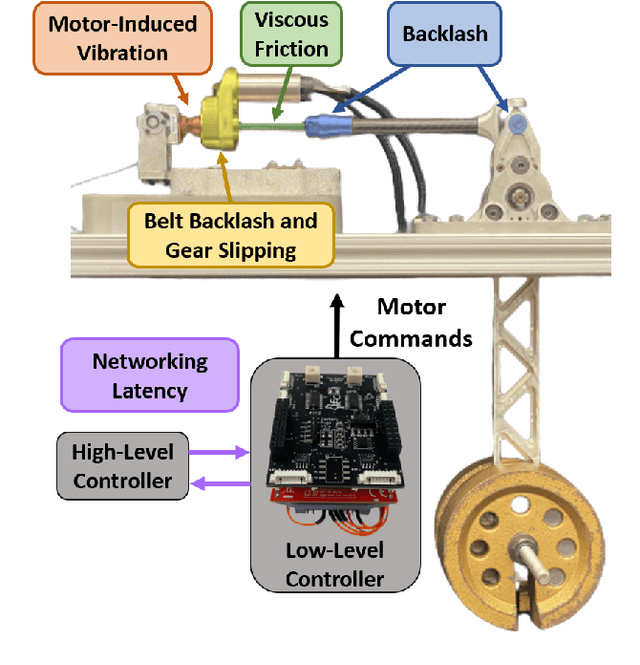
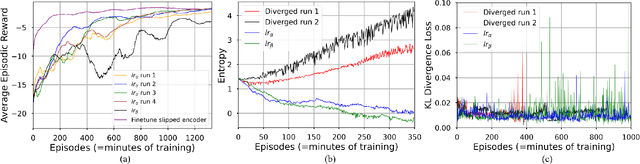
Many state-of-the art robotic applications utilize series elastic actuators (SEAs) with closed-loop force control to achieve complex tasks such as walking, lifting, and manipulation. Model-free PID control methods are more prone to instability due to nonlinearities in the SEA where cascaded model-based robust controllers can remove these effects to achieve stable force control. However, these model-based methods require detailed investigations to characterize the system accurately. Deep reinforcement learning (DRL) has proved to be an effective model-free method for continuous control tasks, where few works deal with hardware learning. This paper describes the training process of a DRL policy on hardware of an SEA pendulum system for tracking force control trajectories from 0.05 - 0.35 Hz at 50 N amplitude using the Proximal Policy Optimization (PPO) algorithm. Safety mechanisms are developed and utilized for training the policy for 12 hours (overnight) without an operator present within the full 21 hours training period. The tracking performance is evaluated showing improvements of $25$ N in mean absolute error when comparing the first 18 min. of training to the full 21 hours for a 50 N amplitude, 0.1 Hz sinusoid desired force trajectory. Finally, the DRL policy exhibits better tracking and stability margins when compared to a model-free PID controller for a 50 N chirp force trajectory.
On Mini-Batch Training with Varying Length Time Series
Dec 13, 2022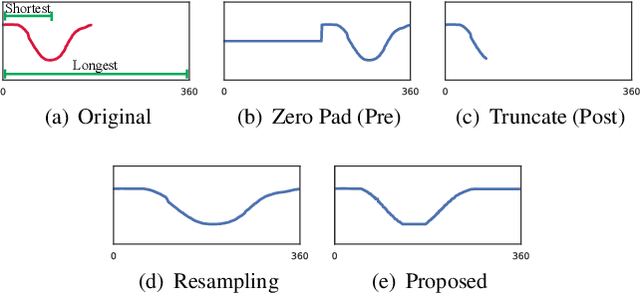
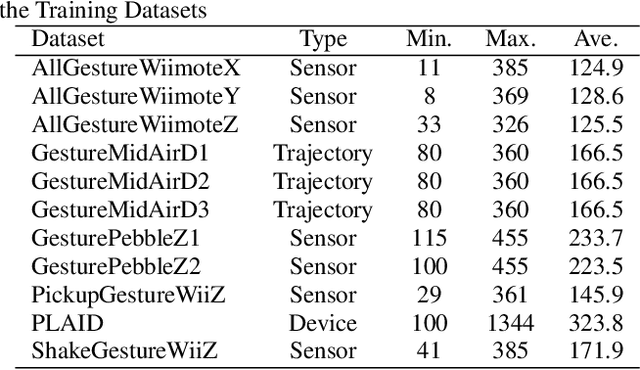
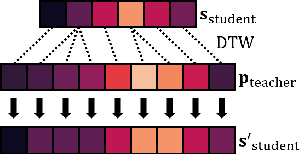
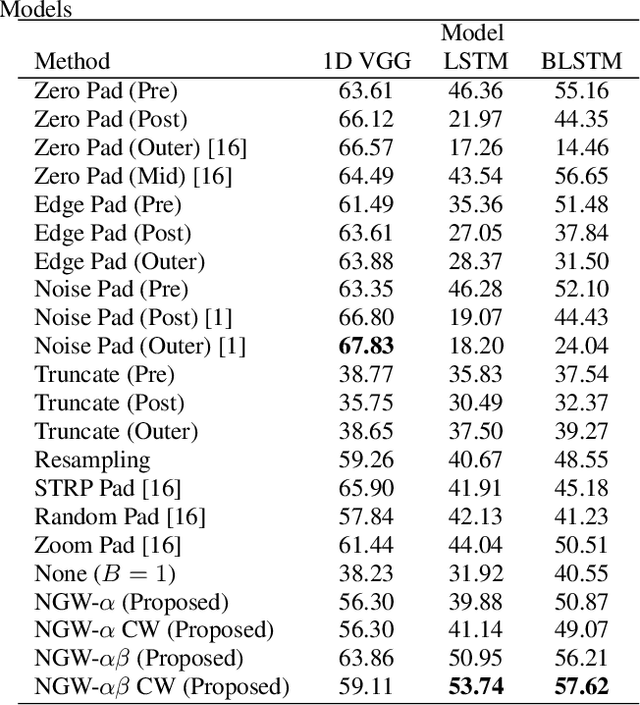
In real-world time series recognition applications, it is possible to have data with varying length patterns. However, when using artificial neural networks (ANN), it is standard practice to use fixed-sized mini-batches. To do this, time series data with varying lengths are typically normalized so that all the patterns are the same length. Normally, this is done using zero padding or truncation without much consideration. We propose a novel method of normalizing the lengths of the time series in a dataset by exploiting the dynamic matching ability of Dynamic Time Warping (DTW). In this way, the time series lengths in a dataset can be set to a fixed size while maintaining features typical to the dataset. In the experiments, all 11 datasets with varying length time series from the 2018 UCR Time Series Archive are used. We evaluate the proposed method by comparing it with 18 other length normalization methods on a Convolutional Neural Network (CNN), a Long-Short Term Memory network (LSTM), and a Bidirectional LSTM (BLSTM).
Designing for Meaningful Human Control in Military Human-Machine Teams
May 12, 2023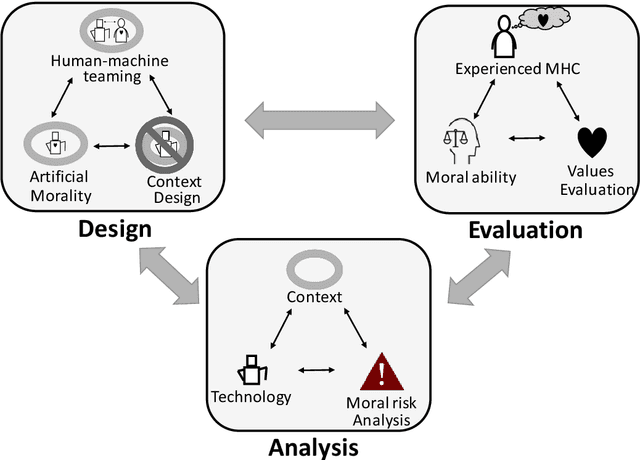
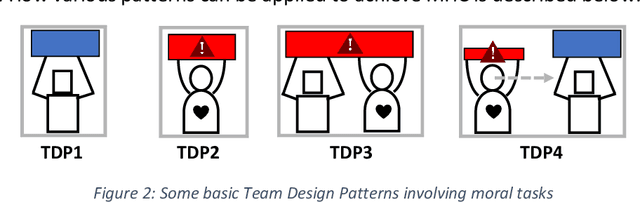
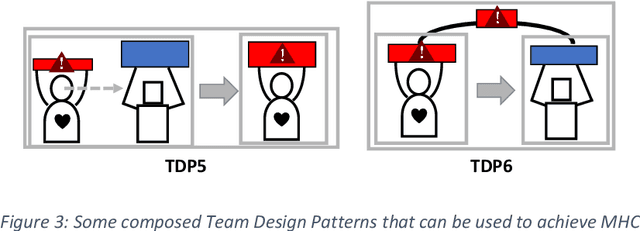
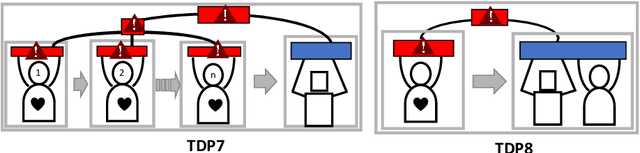
We propose methods for analysis, design, and evaluation of Meaningful Human Control (MHC) for defense technologies from the perspective of military human-machine teaming (HMT). Our approach is based on three principles. Firstly, MHC should be regarded as a core objective that guides all phases of analysis, design and evaluation. Secondly, MHC affects all parts of the socio-technical system, including humans, machines, AI, interactions, and context. Lastly, MHC should be viewed as a property that spans longer periods of time, encompassing both prior and realtime control by multiple actors. To describe macrolevel design options for achieving MHC, we propose various Team Design Patterns. Furthermore, we present a case study, where we applied some of these methods to envision HMT, involving robots and soldiers in a search and rescue task in a military context.
ContCommRTD: A Distributed Content-based Misinformation-aware Community Detection System for Real-Time Disaster Reporting
Jan 30, 2023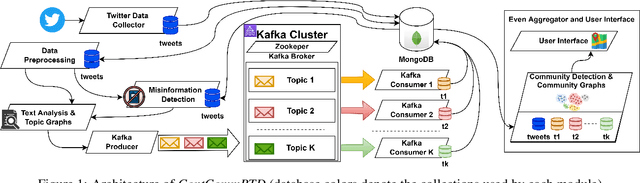
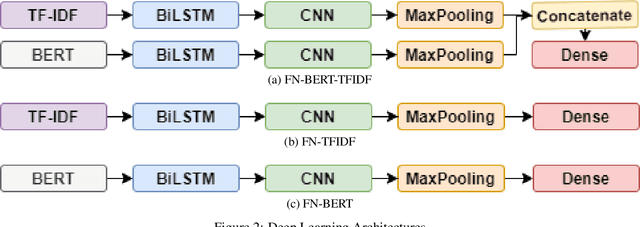
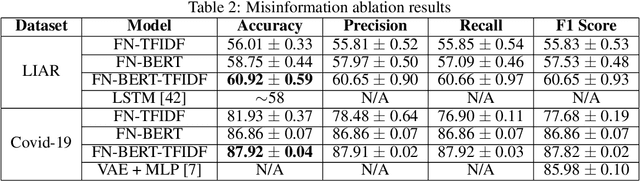
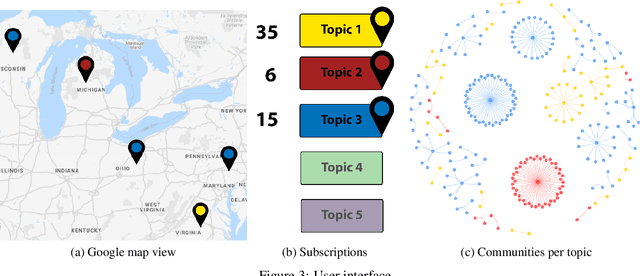
Real-time social media data can provide useful information on evolving hazards. Alongside traditional methods of disaster detection, the integration of social media data can considerably enhance disaster management. In this paper, we investigate the problem of detecting geolocation-content communities on Twitter and propose a novel distributed system that provides in near real-time information on hazard-related events and their evolution. We show that content-based community analysis leads to better and faster dissemination of reports on hazards. Our distributed disaster reporting system analyzes the social relationship among worldwide geolocated tweets, and applies topic modeling to group tweets by topics. Considering for each tweet the following information: user, timestamp, geolocation, retweets, and replies, we create a publisher-subscriber distribution model for topics. We use content similarity and the proximity of nodes to create a new model for geolocation-content based communities. Users can subscribe to different topics in specific geographical areas or worldwide and receive real-time reports regarding these topics. As misinformation can lead to increase damage if propagated in hazards related tweets, we propose a new deep learning model to detect fake news. The misinformed tweets are then removed from display. We also show empirically the scalability capabilities of the proposed system.
OSTA: One-shot Task-adaptive Channel Selection for Semantic Segmentation of Multichannel Images
May 08, 2023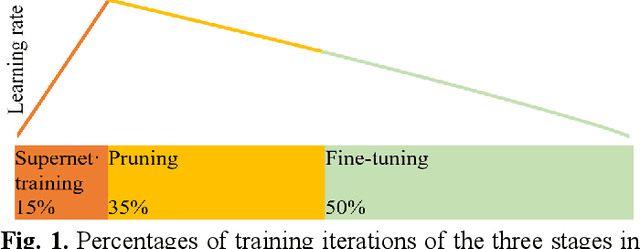
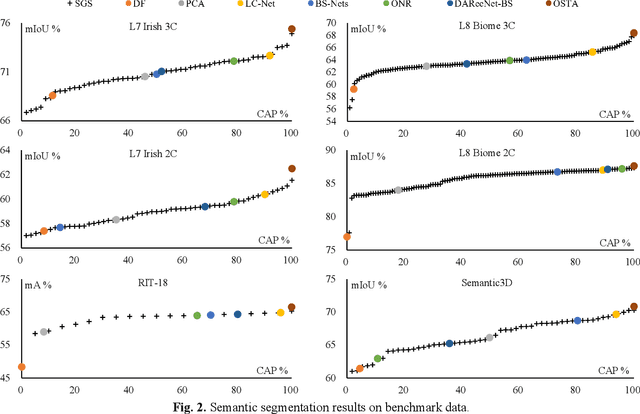

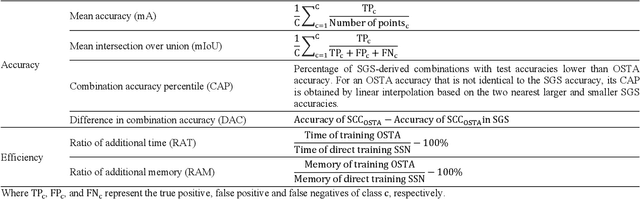
Semantic segmentation of multichannel images is a fundamental task for many applications. Selecting an appropriate channel combination from the original multichannel image can improve the accuracy of semantic segmentation and reduce the cost of data storage, processing and future acquisition. Existing channel selection methods typically use a reasonable selection procedure to determine a desirable channel combination, and then train a semantic segmentation network using that combination. In this study, the concept of pruning from a supernet is used for the first time to integrate the selection of channel combination and the training of a semantic segmentation network. Based on this concept, a One-Shot Task-Adaptive (OSTA) channel selection method is proposed for the semantic segmentation of multichannel images. OSTA has three stages, namely the supernet training stage, the pruning stage and the fine-tuning stage. The outcomes of six groups of experiments (L7Irish3C, L7Irish2C, L8Biome3C, L8Biome2C, RIT-18 and Semantic3D) demonstrated the effectiveness and efficiency of OSTA. OSTA achieved the highest segmentation accuracies in all tests (62.49% (mIoU), 75.40% (mIoU), 68.38% (mIoU), 87.63% (mIoU), 66.53% (mA) and 70.86% (mIoU), respectively). It even exceeded the highest accuracies of exhaustive tests (61.54% (mIoU), 74.91% (mIoU), 67.94% (mIoU), 87.32% (mIoU), 65.32% (mA) and 70.27% (mIoU), respectively), where all possible channel combinations were tested. All of this can be accomplished within a predictable and relatively efficient timeframe, ranging from 101.71% to 298.1% times the time required to train the segmentation network alone. In addition, there were interesting findings that were deemed valuable for several fields.