 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Approximate information state based convergence analysis of recurrent Q-learning
Jun 09, 2023
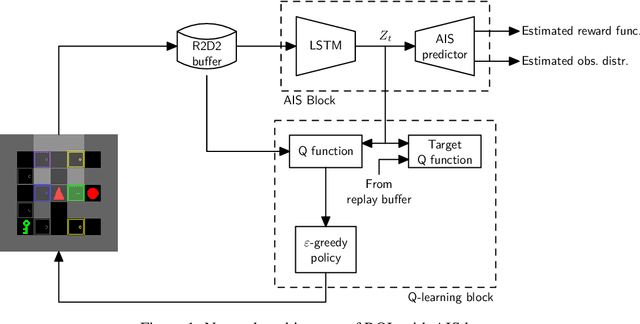
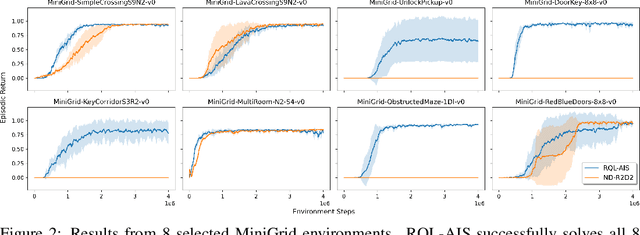
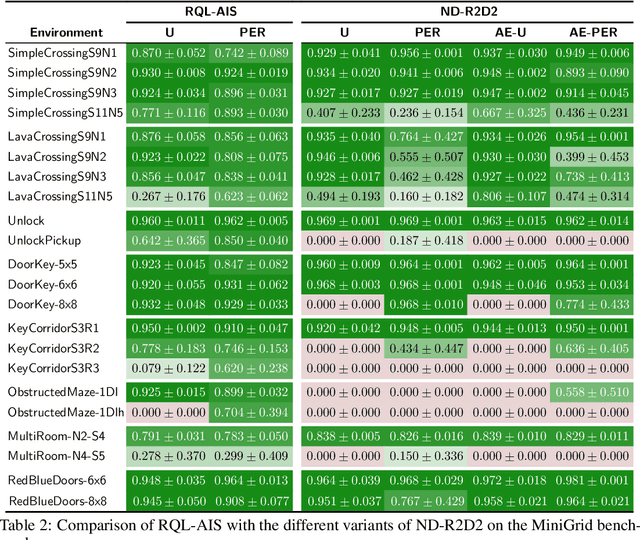
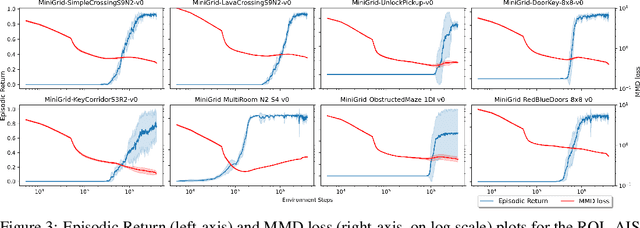
In spite of the large literature on reinforcement learning (RL) algorithms for partially observable Markov decision processes (POMDPs), a complete theoretical understanding is still lacking. In a partially observable setting, the history of data available to the agent increases over time so most practical algorithms either truncate the history to a finite window or compress it using a recurrent neural network leading to an agent state that is non-Markovian. In this paper, it is shown that in spite of the lack of the Markov property, recurrent Q-learning (RQL) converges in the tabular setting. Moreover, it is shown that the quality of the converged limit depends on the quality of the representation which is quantified in terms of what is known as an approximate information state (AIS). Based on this characterization of the approximation error, a variant of RQL with AIS losses is presented. This variant performs better than a strong baseline for RQL that does not use AIS losses. It is demonstrated that there is a strong correlation between the performance of RQL over time and the loss associated with the AIS representation.
QuOTeS: Query-Oriented Technical Summarization
Jun 20, 2023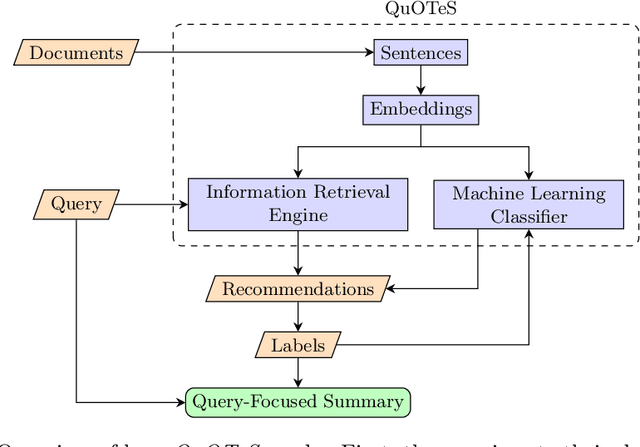


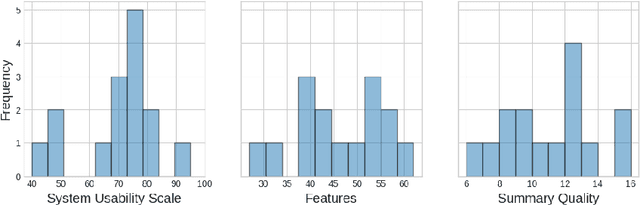
Abstract. When writing an academic paper, researchers often spend considerable time reviewing and summarizing papers to extract relevant citations and data to compose the Introduction and Related Work sections. To address this problem, we propose QuOTeS, an interactive system designed to retrieve sentences related to a summary of the research from a collection of potential references and hence assist in the composition of new papers. QuOTeS integrates techniques from Query-Focused Extractive Summarization and High-Recall Information Retrieval to provide Interactive Query-Focused Summarization of scientific documents. To measure the performance of our system, we carried out a comprehensive user study where participants uploaded papers related to their research and evaluated the system in terms of its usability and the quality of the summaries it produces. The results show that QuOTeS provides a positive user experience and consistently provides query-focused summaries that are relevant, concise, and complete. We share the code of our system and the novel Query-Focused Summarization dataset collected during our experiments at https://github.com/jarobyte91/quotes.
Accelerating Generalized Random Forests with Fixed-Point Trees
Jun 20, 2023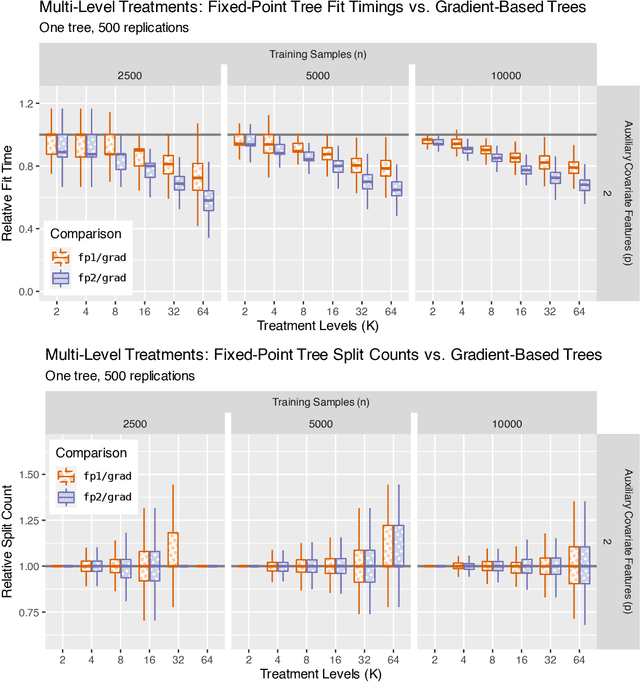
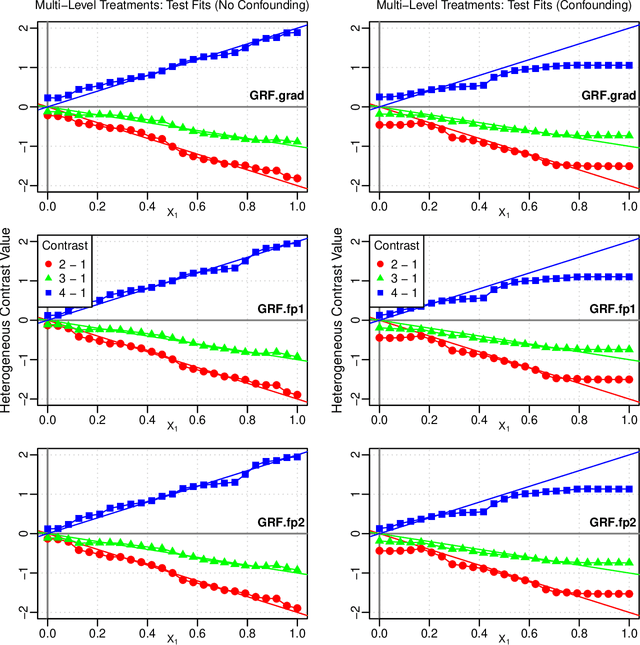
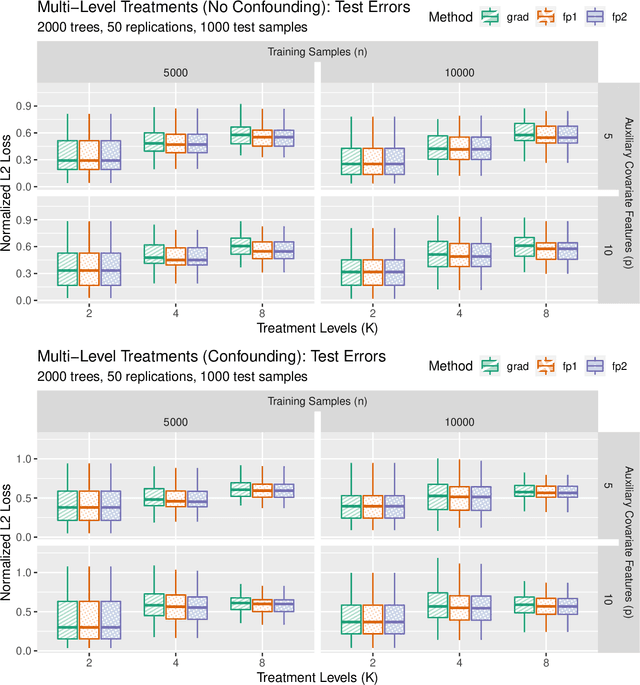
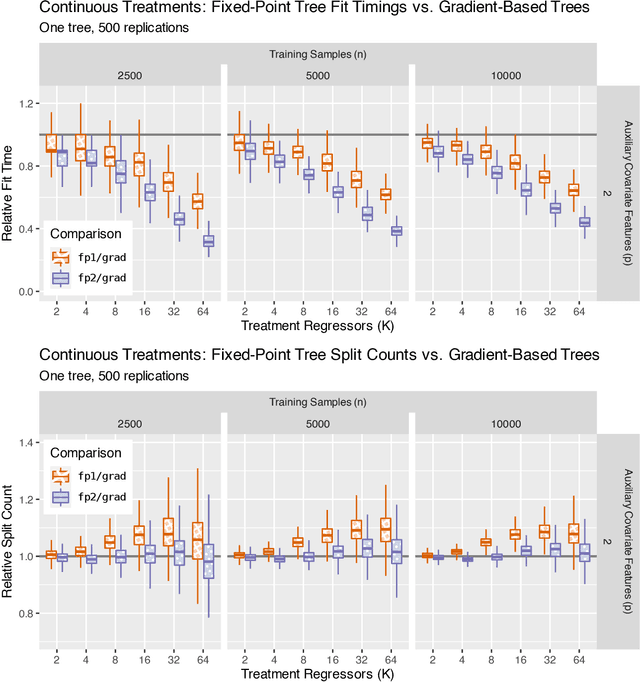
Generalized random forests arXiv:1610.01271 build upon the well-established success of conventional forests (Breiman, 2001) to offer a flexible and powerful non-parametric method for estimating local solutions of heterogeneous estimating equations. Estimators are constructed by leveraging random forests as an adaptive kernel weighting algorithm and implemented through a gradient-based tree-growing procedure. By expressing this gradient-based approximation as being induced from a single Newton-Raphson root-finding iteration, and drawing upon the connection between estimating equations and fixed-point problems arXiv:2110.11074, we propose a new tree-growing rule for generalized random forests induced from a fixed-point iteration type of approximation, enabling gradient-free optimization, and yielding substantial time savings for tasks involving even modest dimensionality of the target quantity (e.g. multiple/multi-level treatment effects). We develop an asymptotic theory for estimators obtained from forests whose trees are grown through the fixed-point splitting rule, and provide numerical simulations demonstrating that the estimators obtained from such forests are comparable to those obtained from the more costly gradient-based rule.
On Frequency-Wise Normalizations for Better Recording Device Generalization in Audio Spectrogram Transformers
Jun 20, 2023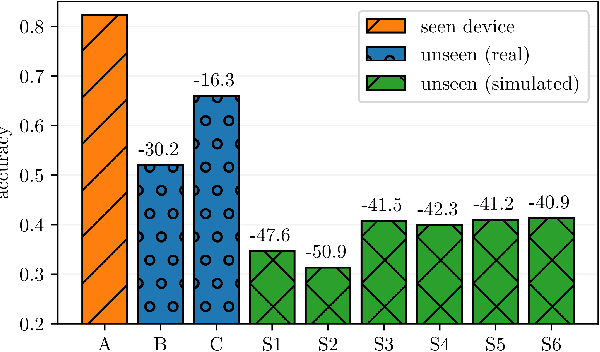


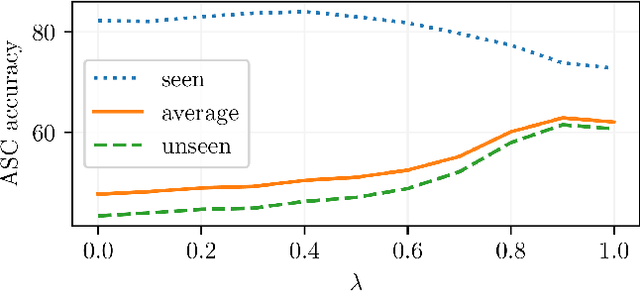
Varying conditions between the data seen at training and at application time remain a major challenge for machine learning. We study this problem in the context of Acoustic Scene Classification (ASC) with mismatching recording devices. Previous works successfully employed frequency-wise normalization of inputs and hidden layer activations in convolutional neural networks to reduce the recording device discrepancy. The main objective of this work was to adopt frequency-wise normalization for Audio Spectrogram Transformers (ASTs), which have recently become the dominant model architecture in ASC. To this end, we first investigate how recording device characteristics are encoded in the hidden layer activations of ASTs. We find that recording device information is initially encoded in the frequency dimension; however, after the first self-attention block, it is largely transformed into the token dimension. Based on this observation, we conjecture that suppressing recording device characteristics in the input spectrogram is the most effective. We propose a frequency-centering operation for spectrograms that improves the ASC performance on unseen recording devices on average by up to 18.2 percentage points.
A Systematic Survey in Geometric Deep Learning for Structure-based Drug Design
Jun 20, 2023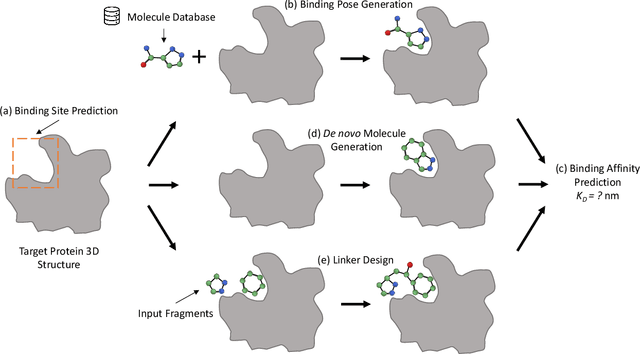
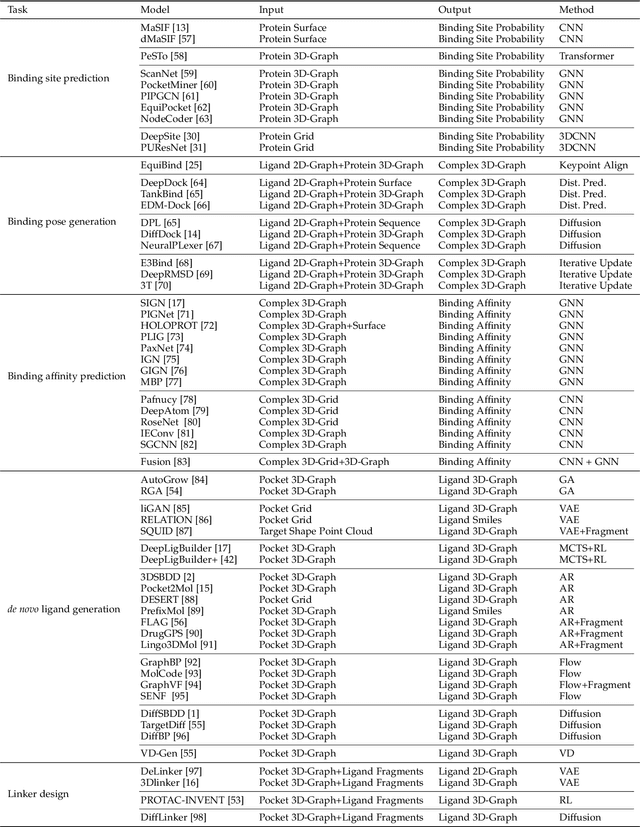
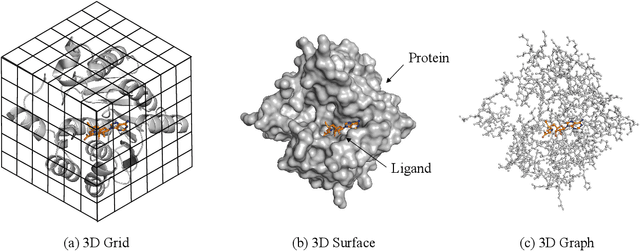
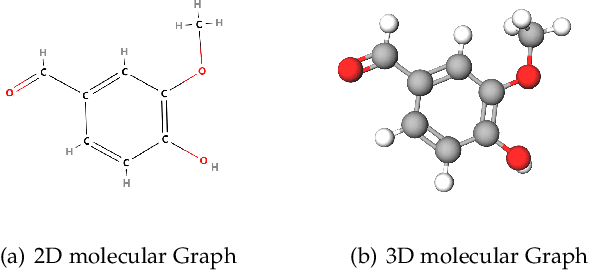
Structure-based drug design (SBDD), which utilizes the three-dimensional geometry of proteins to identify potential drug candidates, is becoming increasingly vital in drug discovery. However, traditional methods based on physiochemical modeling and experts' domain knowledge are time-consuming and laborious. The recent advancements in geometric deep learning, which integrates and processes 3D geometric data, coupled with the availability of accurate protein 3D structure predictions from tools like AlphaFold, have significantly propelled progress in structure-based drug design. In this paper, we systematically review the recent progress of geometric deep learning for structure-based drug design. We start with a brief discussion of the mainstream tasks in structure-based drug design, commonly used 3D protein representations and representative predictive/generative models. Then we delve into detailed reviews for each task (binding site prediction, binding pose generation, \emph{de novo} molecule generation, linker design, and binding affinity prediction), including the problem setup, representative methods, datasets, and evaluation metrics. Finally, we conclude this survey with the current challenges and highlight potential opportunities of geometric deep learning for structure-based drug design.
Prior-knowledge-informed deep learning for lacune detection and quantification using multi-site brain MRI
Jun 18, 2023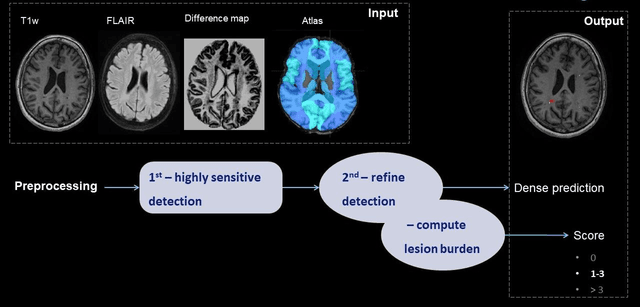
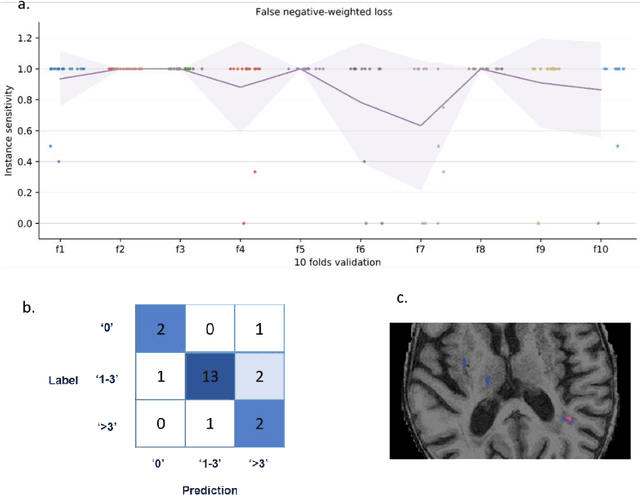
Lacunes of presumed vascular origin, also referred to as lacunar infarcts, are important to assess cerebral small vessel disease and cognitive diseases such as dementia. However, visual rating of lacunes from imaging data is challenging, time-consuming, and rater-dependent, owing to their small size, sparsity, and mimics. Whereas recent developments in automatic algorithms have shown to make the detection of lacunes faster while preserving sensitivity, they also showed a large number of false positives, which makes them impractical for use in clinical practice or large-scale studies. Here, we develop a novel framework that, in addition to lacune detection, outputs a categorical burden score. This score could provide a more practical estimate of lacune presence that simplifies and effectively accelerates the imaging assessment of lacunes. We hypothesize that the combination of detection and the categorical score makes the procedure less sensitive to noisy labels.
Learning to Predict Scene-Level Implicit 3D from Posed RGBD Data
Jun 14, 2023
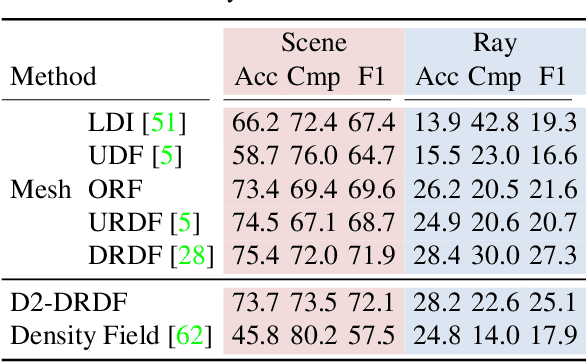
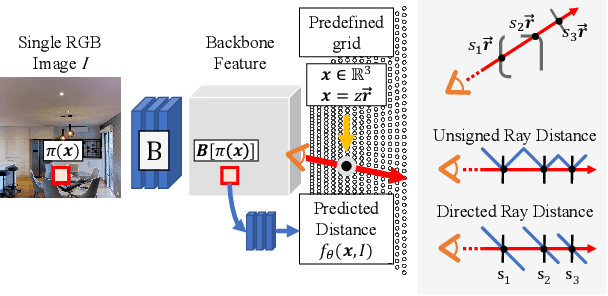
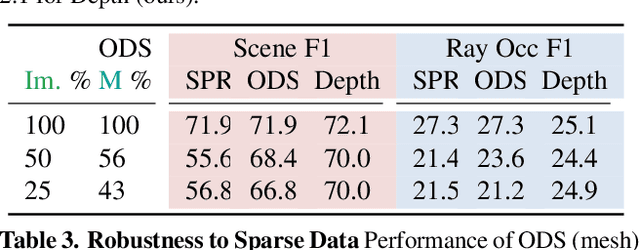
We introduce a method that can learn to predict scene-level implicit functions for 3D reconstruction from posed RGBD data. At test time, our system maps a previously unseen RGB image to a 3D reconstruction of a scene via implicit functions. While implicit functions for 3D reconstruction have often been tied to meshes, we show that we can train one using only a set of posed RGBD images. This setting may help 3D reconstruction unlock the sea of accelerometer+RGBD data that is coming with new phones. Our system, D2-DRDF, can match and sometimes outperform current methods that use mesh supervision and shows better robustness to sparse data.
Im2win: An Efficient Convolution Paradigm on GPU
Jun 25, 2023Convolution is the most time-consuming operation in deep neural network operations, so its performance is critical to the overall performance of the neural network. The commonly used methods for convolution on GPU include the general matrix multiplication (GEMM)-based convolution and the direct convolution. GEMM-based convolution relies on the im2col algorithm, which results in a large memory footprint and reduced performance. Direct convolution does not have the large memory footprint problem, but the performance is not on par with GEMM-based approach because of the discontinuous memory access. This paper proposes a window-order-based convolution paradigm on GPU, called im2win, which not only reduces memory footprint but also offers continuous memory accesses, resulting in improved performance. Furthermore, we apply a range of optimization techniques on the convolution CUDA kernel, including shared memory, tiling, micro-kernel, double buffer, and prefetching. We compare our implementation with the direct convolution, and PyTorch's GEMM-based convolution with cuBLAS and six cuDNN-based convolution implementations, with twelve state-of-the-art DNN benchmarks. The experimental results show that our implementation 1) uses less memory footprint by 23.1% and achieves 3.5$\times$ TFLOPS compared with cuBLAS, 2) uses less memory footprint by 32.8% and achieves up to 1.8$\times$ TFLOPS compared with the best performant convolutions in cuDNN, and 3) achieves up to 155$\times$ TFLOPS compared with the direct convolution. We further perform an ablation study on the applied optimization techniques and find that the micro-kernel has the greatest positive impact on performance.
A Gated Cross-domain Collaborative Network for Underwater Object Detection
Jun 25, 2023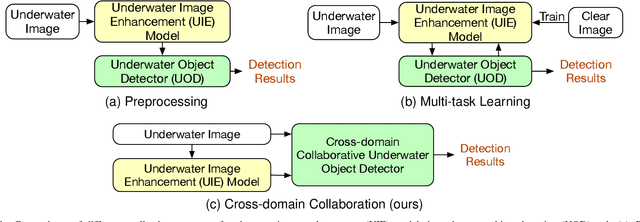
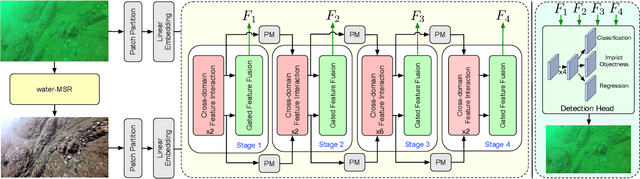
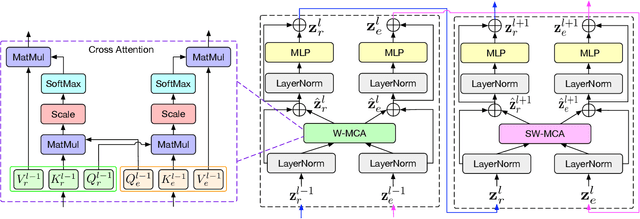

Underwater object detection (UOD) plays a significant role in aquaculture and marine environmental protection. Considering the challenges posed by low contrast and low-light conditions in underwater environments, several underwater image enhancement (UIE) methods have been proposed to improve the quality of underwater images. However, only using the enhanced images does not improve the performance of UOD, since it may unavoidably remove or alter critical patterns and details of underwater objects. In contrast, we believe that exploring the complementary information from the two domains is beneficial for UOD. The raw image preserves the natural characteristics of the scene and texture information of the objects, while the enhanced image improves the visibility of underwater objects. Based on this perspective, we propose a Gated Cross-domain Collaborative Network (GCC-Net) to address the challenges of poor visibility and low contrast in underwater environments, which comprises three dedicated components. Firstly, a real-time UIE method is employed to generate enhanced images, which can improve the visibility of objects in low-contrast areas. Secondly, a cross-domain feature interaction module is introduced to facilitate the interaction and mine complementary information between raw and enhanced image features. Thirdly, to prevent the contamination of unreliable generated results, a gated feature fusion module is proposed to adaptively control the fusion ratio of cross-domain information. Our method presents a new UOD paradigm from the perspective of cross-domain information interaction and fusion. Experimental results demonstrate that the proposed GCC-Net achieves state-of-the-art performance on four underwater datasets.
Quantifying Causes of Arctic Amplification via Deep Learning based Time-series Causal Inference
Mar 14, 2023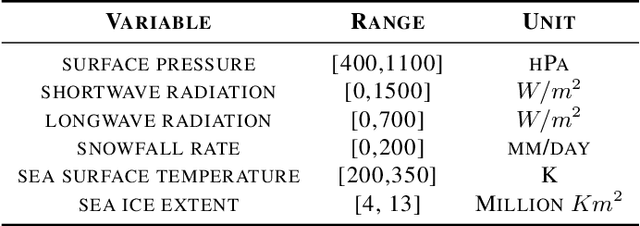
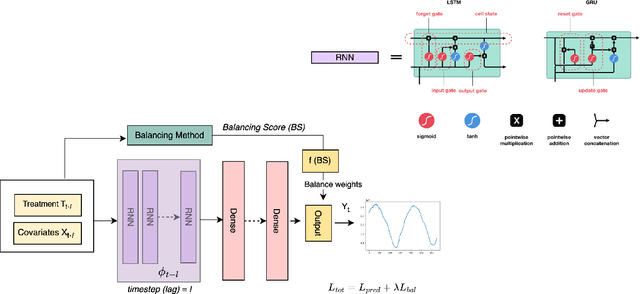

The warming of the Arctic, also known as Arctic amplification, is led by several atmospheric and oceanic drivers, however, the details of its underlying thermodynamic causes are still unknown. Inferring the causal effects of atmospheric processes on sea ice melt using fixed treatment effect strategies leads to unrealistic counterfactual estimations. Such models are also prone to bias due to time-varying confoundedness. In order to tackle these challenges, we propose TCINet - time-series causal inference model to infer causation under continuous treatment using recurrent neural networks. Through experiments on synthetic and observational data, we show how our research can substantially improve the ability to quantify the leading causes of Arctic sea ice melt.