 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Generative Modeling of Time-Dependent Densities via Optimal Transport and Projection Pursuit
Apr 19, 2023
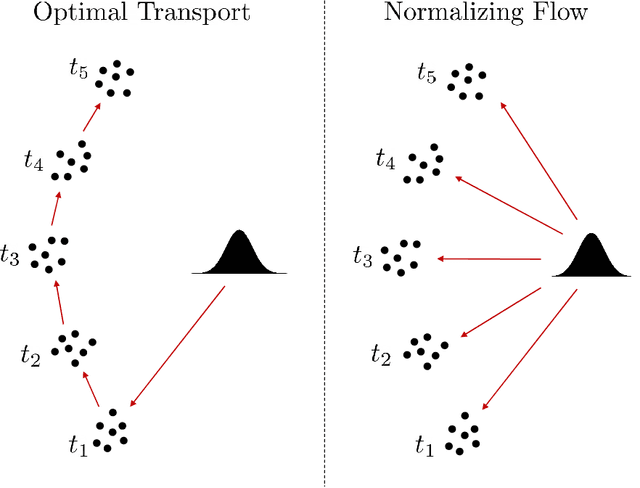
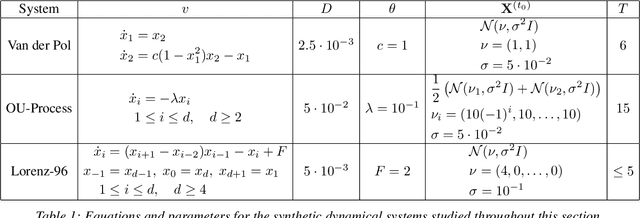
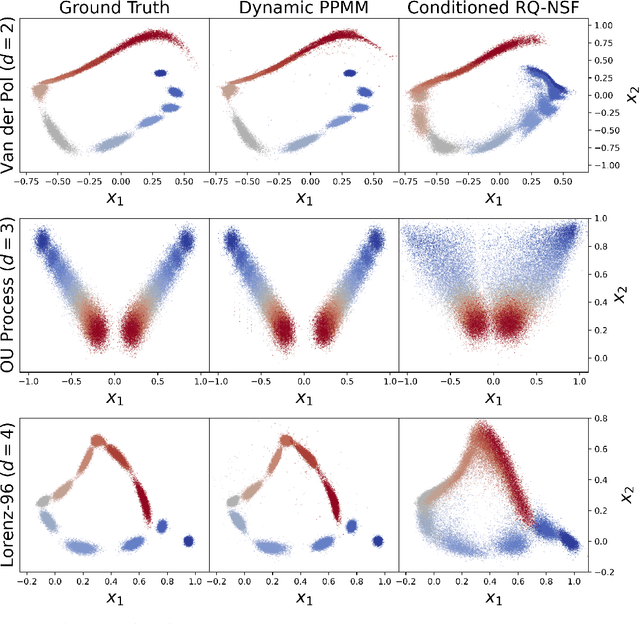

Motivated by the computational difficulties incurred by popular deep learning algorithms for the generative modeling of temporal densities, we propose a cheap alternative which requires minimal hyperparameter tuning and scales favorably to high dimensional problems. In particular, we use a projection-based optimal transport solver [Meng et al., 2019] to join successive samples and subsequently use transport splines [Chewi et al., 2020] to interpolate the evolving density. When the sampling frequency is sufficiently high, the optimal maps are close to the identity and are thus computationally efficient to compute. Moreover, the training process is highly parallelizable as all optimal maps are independent and can thus be learned simultaneously. Finally, the approach is based solely on numerical linear algebra rather than minimizing a nonconvex objective function, allowing us to easily analyze and control the algorithm. We present several numerical experiments on both synthetic and real-world datasets to demonstrate the efficiency of our method. In particular, these experiments show that the proposed approach is highly competitive compared with state-of-the-art normalizing flows conditioned on time across a wide range of dimensionalities.
Towards Open-Domain Topic Classification
Jun 29, 2023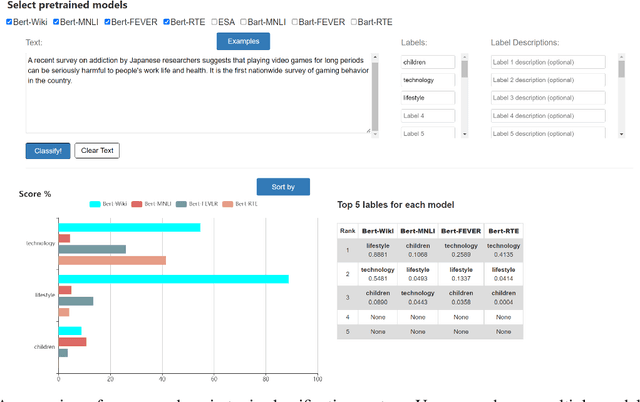

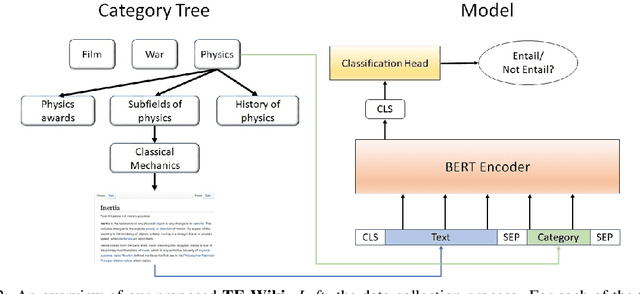
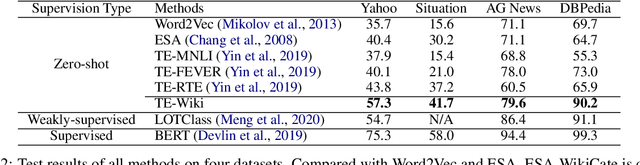
We introduce an open-domain topic classification system that accepts user-defined taxonomy in real time. Users will be able to classify a text snippet with respect to any candidate labels they want, and get instant response from our web interface. To obtain such flexibility, we build the backend model in a zero-shot way. By training on a new dataset constructed from Wikipedia, our label-aware text classifier can effectively utilize implicit knowledge in the pretrained language model to handle labels it has never seen before. We evaluate our model across four datasets from various domains with different label sets. Experiments show that the model significantly improves over existing zero-shot baselines in open-domain scenarios, and performs competitively with weakly-supervised models trained on in-domain data.
Real-time SLAM Pipeline in Dynamics Environment
Mar 04, 2023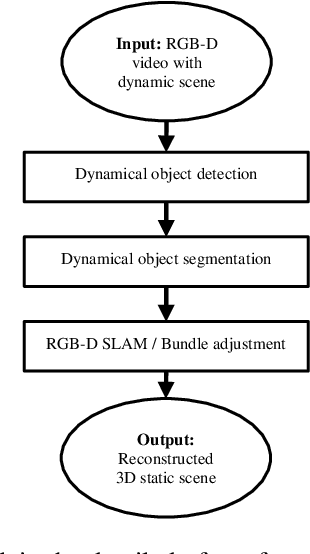
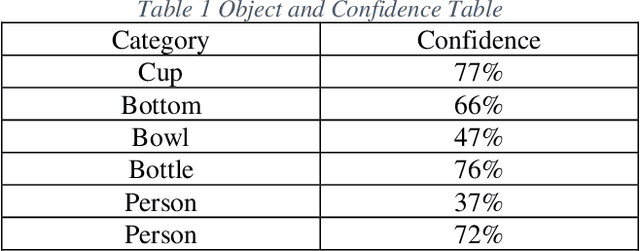

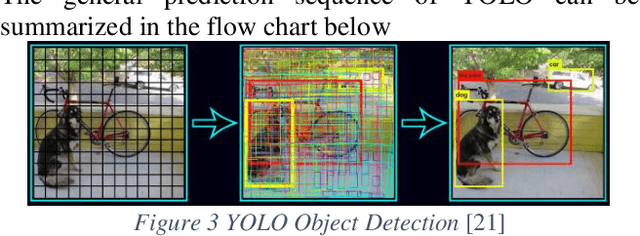
Inspired by the recent success of application of dense data approach by using ORB-SLAM and RGB-D SLAM, we propose a better pipeline of real-time SLAM in dynamics environment. Different from previous SLAM which can only handle static scenes, we are presenting a solution which use RGB-D SLAM as well as YOLO real-time object detection to segment and remove dynamic scene and then construct static scene 3D. We gathered a dataset which allows us to jointly consider semantics, geometry, and physics and thus enables us to reconstruct the static scene while filtering out all dynamic objects.
Real time dense anomaly detection by learning on synthetic negative data
May 24, 2023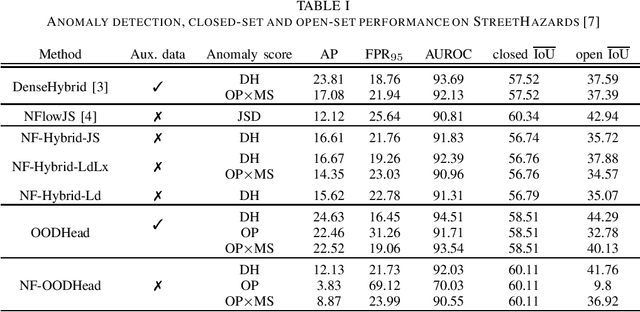

Most approaches to dense anomaly detection rely on generative modeling or on discriminative methods that train with negative data. We consider a recent hybrid method that optimizes the same shared representation according to cross-entropy of the discriminative predictions, and negative log likelihood of the predicted energy-based density. We extend that work with a jointly trained generative flow that samples synthetic negatives at the border of the inlier distribution. The proposed extension provides potential to learn the hybrid method without real negative data. Our experiments analyze the impact of training with synthetic negative data and validate contribution of the energy-based density during training and evaluation.
Denoising of discrete-time chaotic signals using echo state networks
Apr 03, 2023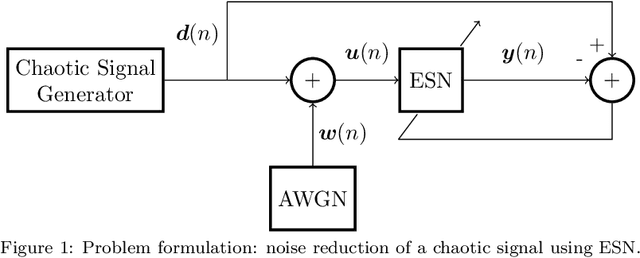
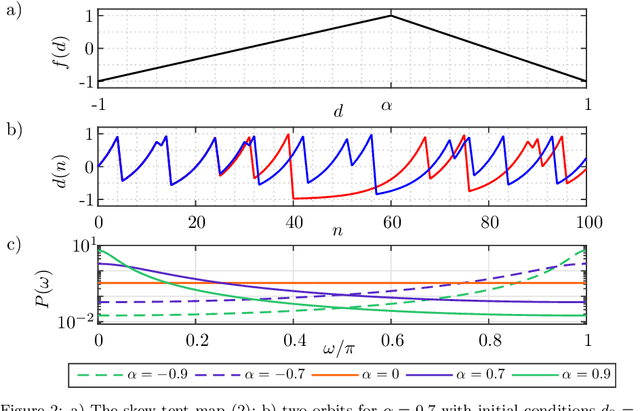
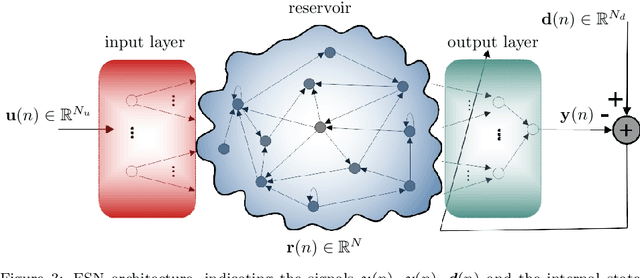
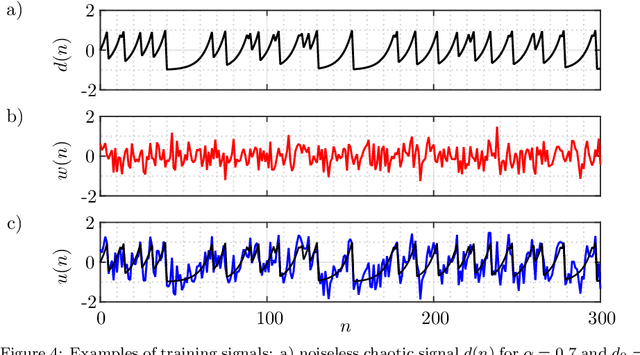
Noise reduction is a relevant topic when considering the application of chaotic signals in practical problems, such as communication systems or modeling biomedical signals. In this paper an echo state network (ESN) is employed to denoise a discrete-time chaotic signal corrupted by additive white Gaussian noise. The choice for applying ESNs in this context is motivated by their successful exploitation for separation and prediction of chaotic signals. The results show that the processing gain of ESN is higher than that of the Wiener filter, especially when the power spectral density of the chaotic signals is white.
Unveiling the Potential of Knowledge-Prompted ChatGPT for Enhancing Drug Trafficking Detection on Social Media
Jul 07, 2023



Social media platforms such as Instagram and Twitter have emerged as critical channels for drug marketing and illegal sale. Detecting and labeling online illicit drug trafficking activities becomes important in addressing this issue. However, the effectiveness of conventional supervised learning methods in detecting drug trafficking heavily relies on having access to substantial amounts of labeled data, while data annotation is time-consuming and resource-intensive. Furthermore, these models often face challenges in accurately identifying trafficking activities when drug dealers use deceptive language and euphemisms to avoid detection. To overcome this limitation, we conduct the first systematic study on leveraging large language models (LLMs), such as ChatGPT, to detect illicit drug trafficking activities on social media. We propose an analytical framework to compose \emph{knowledge-informed prompts}, which serve as the interface that humans can interact with and use LLMs to perform the detection task. Additionally, we design a Monte Carlo dropout based prompt optimization method to further to improve performance and interpretability. Our experimental findings demonstrate that the proposed framework outperforms other baseline language models in terms of drug trafficking detection accuracy, showing a remarkable improvement of nearly 12\%. By integrating prior knowledge and the proposed prompts, ChatGPT can effectively identify and label drug trafficking activities on social networks, even in the presence of deceptive language and euphemisms used by drug dealers to evade detection. The implications of our research extend to social networks, emphasizing the importance of incorporating prior knowledge and scenario-based prompts into analytical tools to improve online security and public safety.
Factors Impacting the Quality of User Answers on Smartphones
Jun 12, 2023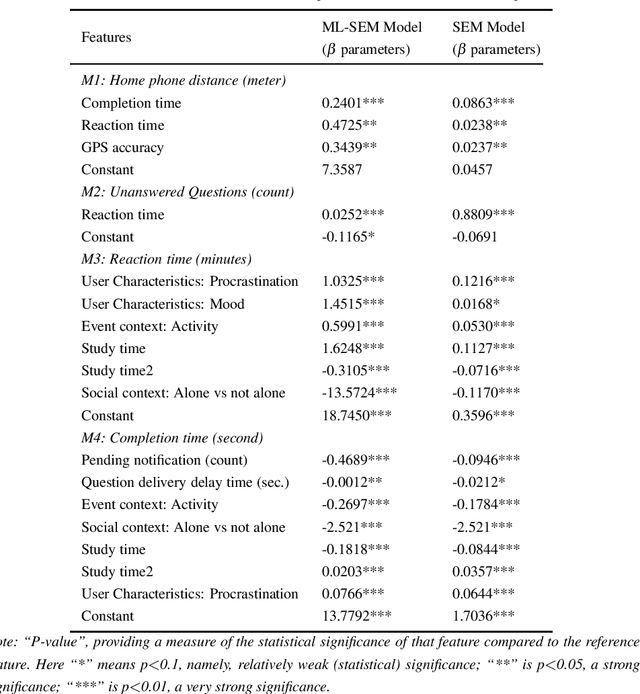
So far, most research investigating the predictability of human behavior, such as mobility and social interactions, has focused mainly on the exploitation of sensor data. However, sensor data can be difficult to capture the subjective motivations behind the individuals' behavior. Understanding personal context (e.g., where one is and what they are doing) can greatly increase predictability. The main limitation is that human input is often missing or inaccurate. The goal of this paper is to identify factors that influence the quality of responses when users are asked about their current context. We find that two key factors influence the quality of responses: user reaction time and completion time. These factors correlate with various exogenous causes (e.g., situational context, time of day) and endogenous causes (e.g., procrastination attitude, mood). In turn, we study how these two factors impact the quality of responses.
* 5 pages, 1 table
Active Learning with Contrastive Pre-training for Facial Expression Recognition
Jul 06, 2023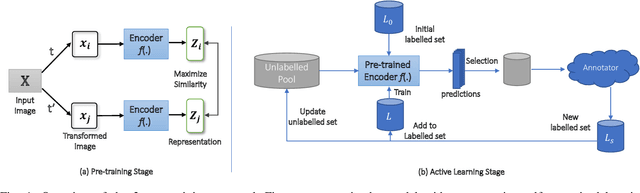
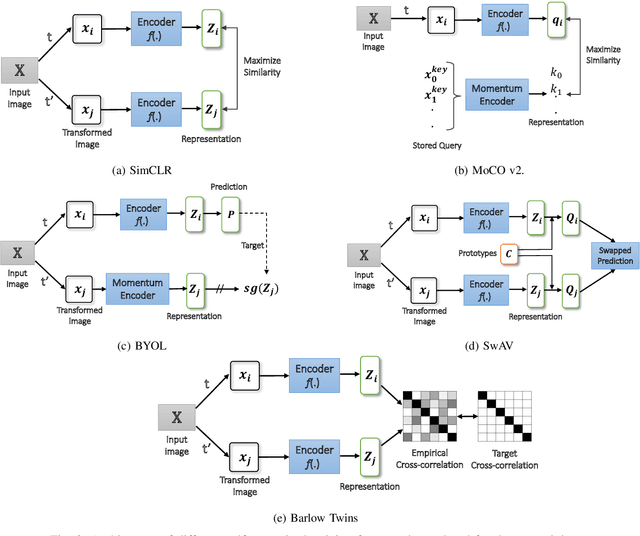
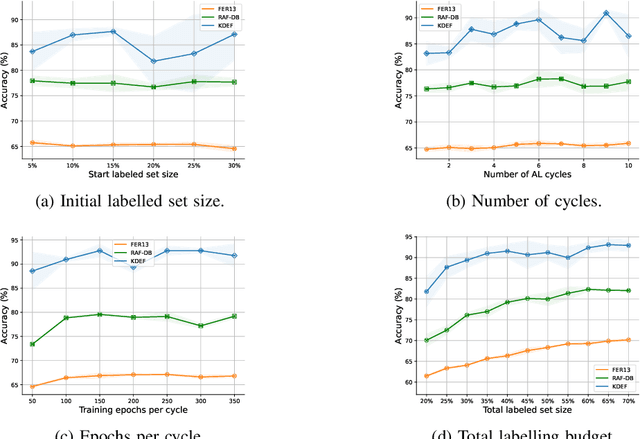

Deep learning has played a significant role in the success of facial expression recognition (FER), thanks to large models and vast amounts of labelled data. However, obtaining labelled data requires a tremendous amount of human effort, time, and financial resources. Even though some prior works have focused on reducing the need for large amounts of labelled data using different unsupervised methods, another promising approach called active learning is barely explored in the context of FER. This approach involves selecting and labelling the most representative samples from an unlabelled set to make the best use of a limited 'labelling budget'. In this paper, we implement and study 8 recent active learning methods on three public FER datasets, FER13, RAF-DB, and KDEF. Our findings show that existing active learning methods do not perform well in the context of FER, likely suffering from a phenomenon called 'Cold Start', which occurs when the initial set of labelled samples is not well representative of the entire dataset. To address this issue, we propose contrastive self-supervised pre-training, which first learns the underlying representations based on the entire unlabelled dataset. We then follow this with the active learning methods and observe that our 2-step approach shows up to 9.2% improvement over random sampling and up to 6.7% improvement over the best existing active learning baseline without the pre-training. We will make the code for this study public upon publication at: github.com/ShuvenduRoy/ActiveFER.
A Meta-Evaluation of C/W/L/A Metrics: System Ranking Similarity, System Ranking Consistency and Discriminative Power
Jul 06, 2023


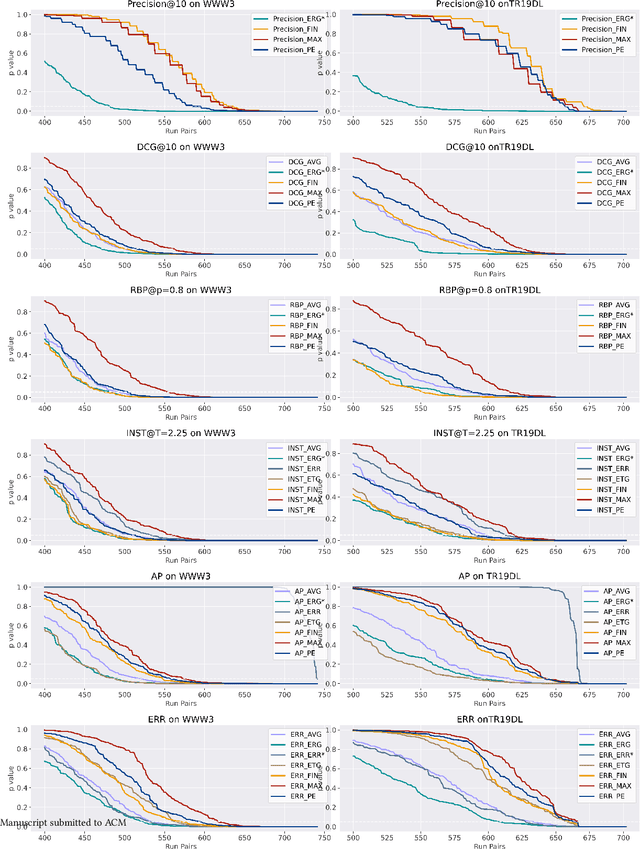
Recently, Moffat et al. proposed an analytic framework, namely C/W/L/A, for offline evaluation metrics. This framework allows information retrieval (IR) researchers to design evaluation metrics through the flexible combination of user browsing models and user gain aggregations. However, the statistical stability of C/W/L/A metrics with different aggregations is not yet investigated. In this study, we investigate the statistical stability of C/W/L/A metrics from the perspective of: (1) the system ranking similarity among aggregations, (2) the system ranking consistency of aggregations and (3) the discriminative power of aggregations. More specifically, we combined various aggregation functions with the browsing model of Precision, Discounted Cumulative Gain (DCG), Rank-Biased Precision (RBP), INST, Average Precision (AP) and Expected Reciprocal Rank (ERR), examing their performances in terms of system ranking similarity, system ranking consistency and discriminative power on two offline test collections. Our experimental result suggests that, in terms of system ranking consistency and discriminative power, the aggregation function of expected rate of gain (ERG) has an outstanding performance while the aggregation function of maximum relevance usually has an insufficient performance. The result also suggests that Precision, DCG, RBP, INST and AP with their canonical aggregation all have favourable performances in system ranking consistency and discriminative power; but for ERR, replacing its canonical aggregation with ERG can further strengthen the discriminative power while obtaining a system ranking list similar to the canonical version at the same time.
A Singular-value-based Marker for the Detection of Atrial Fibrillation Using High-resolution Electrograms and Multi-lead ECG
Jul 06, 2023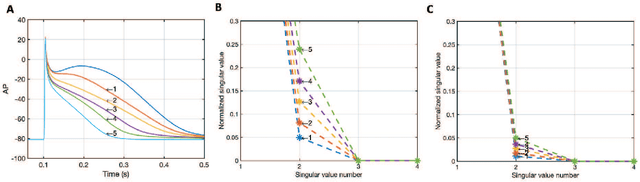
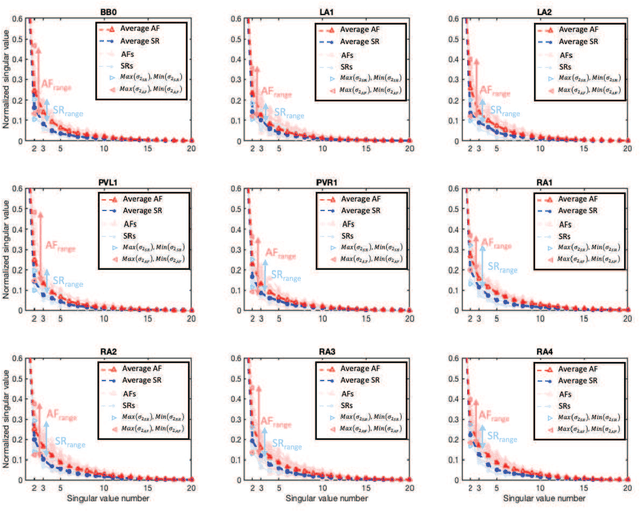
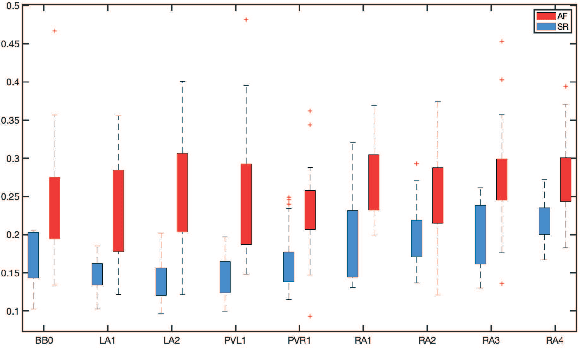
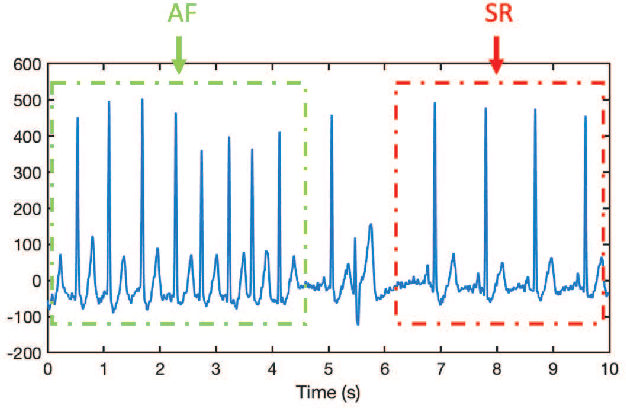
The severity of atrial fibrillation (AF) can be assessed from intra-operative epicardial measurements (high-resolution electrograms), using metrics such as conduction block (CB) and continuous conduction delay and block (cCDCB). These features capture differences in conduction velocity and wavefront propagation. However, they do not clearly differentiate patients with various degrees of AF while they are in sinus rhythm, and complementary features are needed. In this work, we focus on the morphology of the action potentials, and derive features to detect variations in the atrial potential waveforms. Methods: We show that the spatial variation of atrial potential morphology during a single beat may be described by changes in the singular values of the epicardial measurement matrix. The method is non-parametric and requires little preprocessing. A corresponding singular value map points at areas subject to fractionation and block. Further, we developed an experiment where we simultaneously measure electrograms (EGMs) and a multi-lead ECG. Results: The captured data showed that the normalized singular values of the heartbeats during AF are higher than during SR, and that this difference is more pronounced for the (non-invasive) ECG data than for the EGM data, if the electrodes are positioned at favorable locations. Conclusion: Overall, the singular value-based features are a useful indicator to detect and evaluate AF. Significance: The proposed method might be beneficial for identifying electropathological regions in the tissue without estimating the local activation time.