 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Open-Domain Topic Classification
Jun 29, 2023



We introduce an open-domain topic classification system that accepts user-defined taxonomy in real time. Users will be able to classify a text snippet with respect to any candidate labels they want, and get instant response from our web interface. To obtain such flexibility, we build the backend model in a zero-shot way. By training on a new dataset constructed from Wikipedia, our label-aware text classifier can effectively utilize implicit knowledge in the pretrained language model to handle labels it has never seen before. We evaluate our model across four datasets from various domains with different label sets. Experiments show that the model significantly improves over existing zero-shot baselines in open-domain scenarios, and performs competitively with weakly-supervised models trained on in-domain data.
Extracting or Guessing? Improving Faithfulness of Event Temporal Relation Extraction
Oct 12, 2022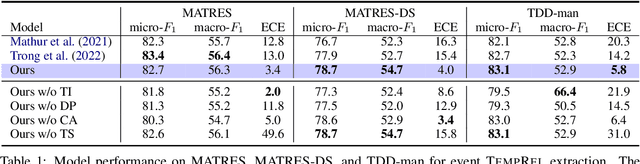
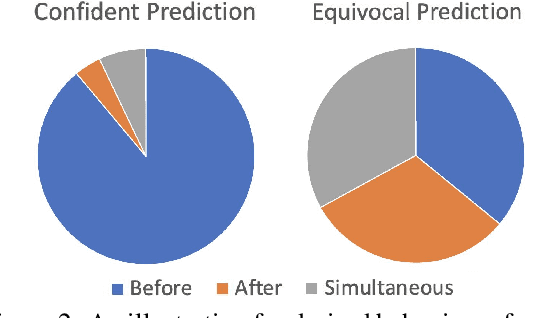
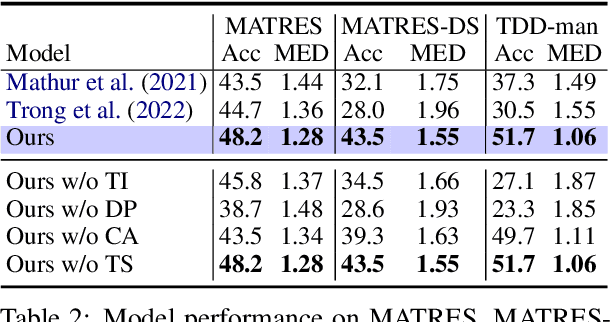
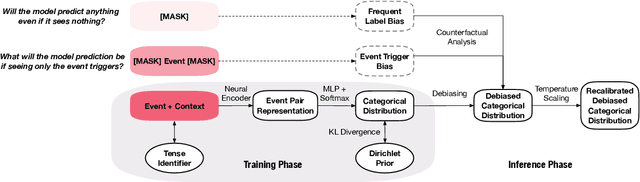
In this paper, we seek to improve the faithfulness of TempRel extraction models from two perspectives. The first perspective is to extract genuinely based on contextual description. To achieve this, we propose to conduct counterfactual analysis to attenuate the effects of two significant types of training biases: the event trigger bias and the frequent label bias. We also add tense information into event representations to explicitly place an emphasis on the contextual description. The second perspective is to provide proper uncertainty estimation and abstain from extraction when no relation is described in the text. By parameterization of Dirichlet Prior over the model-predicted categorical distribution, we improve the model estimates of the correctness likelihood and make TempRel predictions more selective. We also employ temperature scaling to recalibrate the model confidence measure after bias mitigation. Through experimental analysis on MATRES, MATRES-DS, and TDDiscourse, we demonstrate that our model extracts TempRel and timelines more faithfully compared to SOTA methods, especially under distribution shifts.
Are All Steps Equally Important? Benchmarking Essentiality Detection of Events
Oct 12, 2022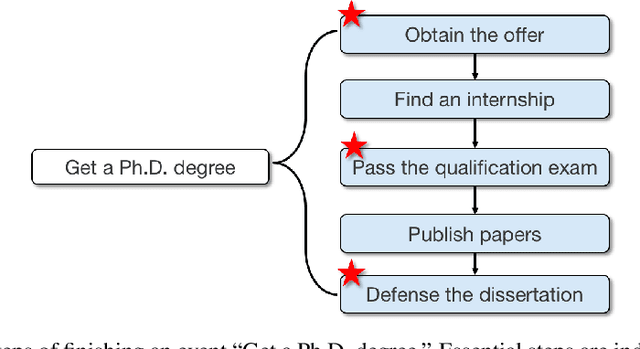

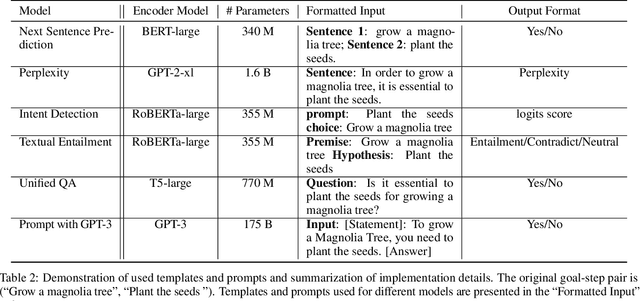
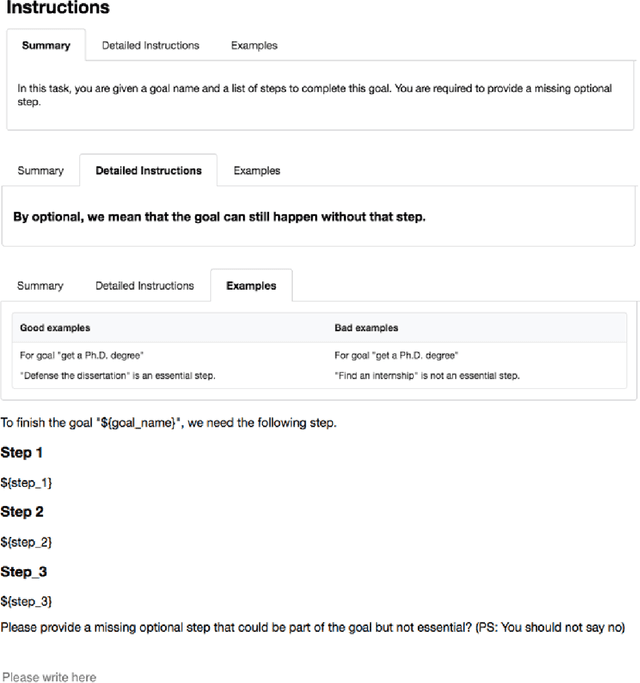
Natural language often describes events in different granularities, such that more coarse-grained (goal) events can often be decomposed into fine-grained sequences of (step) events. A critical but overlooked challenge in understanding an event process lies in the fact that the step events are not equally important to the central goal. In this paper, we seek to fill this gap by studying how well current models can understand the essentiality of different step events towards a goal event. As discussed by cognitive studies, such an ability enables the machine to mimic human's commonsense reasoning about preconditions and necessary efforts of daily-life tasks. Our work contributes with a high-quality corpus of (goal, step) pairs from a community guideline website WikiHow, where the steps are manually annotated with their essentiality w.r.t. the goal. The high IAA indicates that humans have a consistent understanding of the events. Despite evaluating various statistical and massive pre-trained NLU models, we observe that existing SOTA models all perform drastically behind humans, indicating the need for future investigation of this crucial yet challenging task.