 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Evaluating the reliability of automatically generated pedestrian and bicycle crash surrogates
Jul 24, 2023

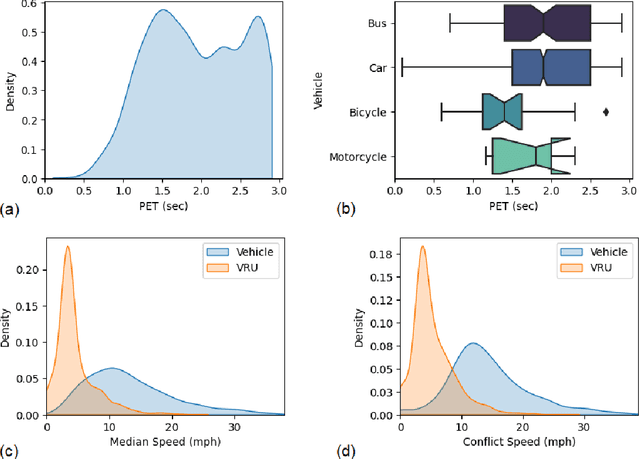
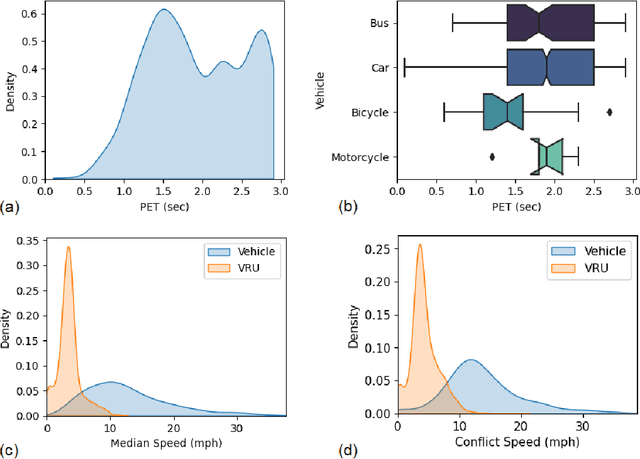
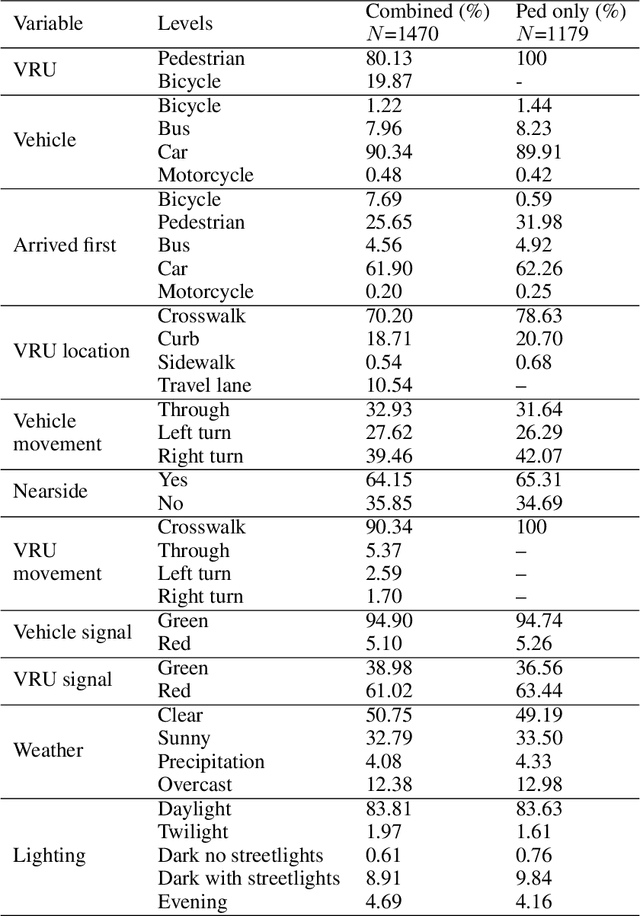
Vulnerable road users (VRUs), such as pedestrians and bicyclists, are at a higher risk of being involved in crashes with motor vehicles, and crashes involving VRUs also are more likely to result in severe injuries or fatalities. Signalized intersections are a major safety concern for VRUs due to their complex and dynamic nature, highlighting the need to understand how these road users interact with motor vehicles and deploy evidence-based countermeasures to improve safety performance. Crashes involving VRUs are relatively infrequent, making it difficult to understand the underlying contributing factors. An alternative is to identify and use conflicts between VRUs and motorized vehicles as a surrogate for safety performance. Automatically detecting these conflicts using a video-based systems is a crucial step in developing smart infrastructure to enhance VRU safety. The Pennsylvania Department of Transportation conducted a study using video-based event monitoring system to assess VRU and motor vehicle interactions at fifteen signalized intersections across Pennsylvania to improve VRU safety performance. This research builds on that study to assess the reliability of automatically generated surrogates in predicting confirmed conflicts using advanced data-driven models. The surrogate data used for analysis include automatically collectable variables such as vehicular and VRU speeds, movements, post-encroachment time, in addition to manually collected variables like signal states, lighting, and weather conditions. The findings highlight the varying importance of specific surrogates in predicting true conflicts, some being more informative than others. The findings can assist transportation agencies to collect the right types of data to help prioritize infrastructure investments, such as bike lanes and crosswalks, and evaluate their effectiveness.
Calibration of Wideband LFM Radars based on Sliding Window Algorithm
Jun 26, 2023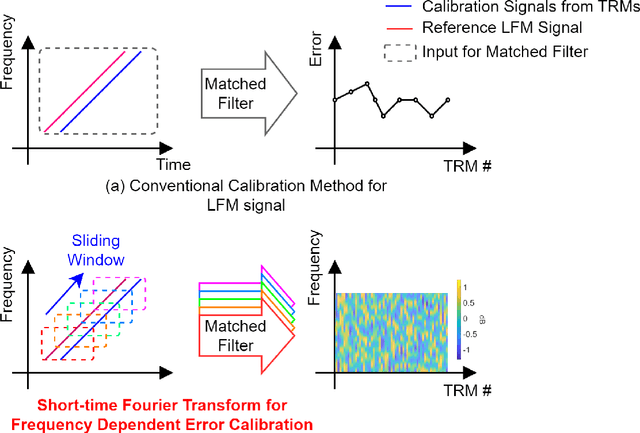
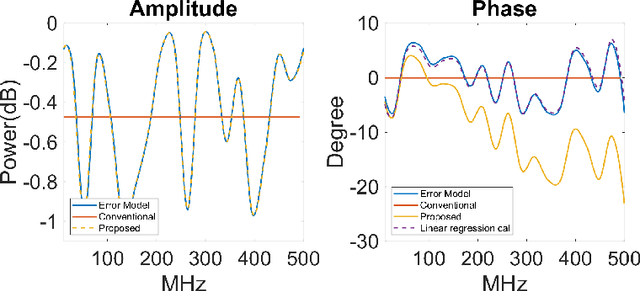
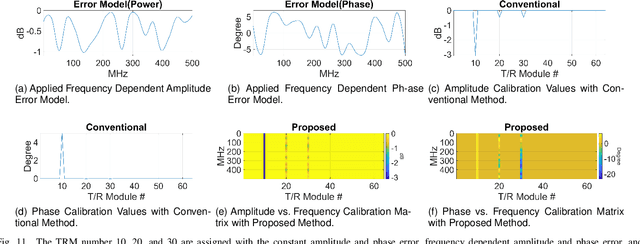
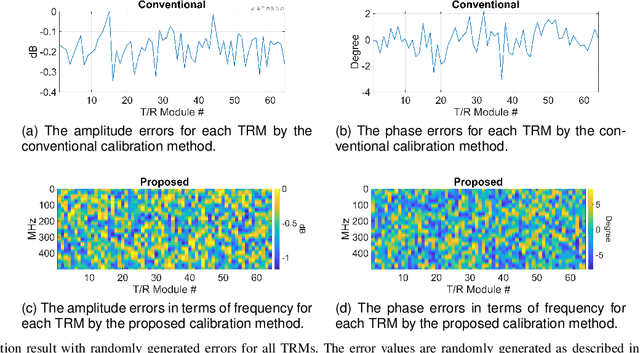
This paper addresses the challenges of wideband signal beamforming in radar systems and proposes a new calibration method. Due to operating conditions, the frequency dependent characteristics of the system can be changed, and amplitude, phase, and time delay error can be generated. The proposed method is based on the concept of sliding window algorithm for linear frequency modulated (LFM) signals. To calibrate the frequency-dependent errors from transceiver and the time delay error from true time delay elements, the proposed method utilizes the characteristic of the LFM signal. The LFM signal changes its frequency linearly with time, and the frequency domain characteristics of the hardware are presented in time. Therefore, by applying matched filter to a part of the LFM signal, the frequency dependent characteristics can be monitored and calibrated. The proposed method is compared with the conventional matched filter based calibration results and verified by simulation results and beampatterns. Since the proposed method utilizes LFM signal as calibration tone, the proposed method can be applied to any beamforming systems, not limited to LFM radars.
Badgers: generating data quality deficits with Python
Jul 10, 2023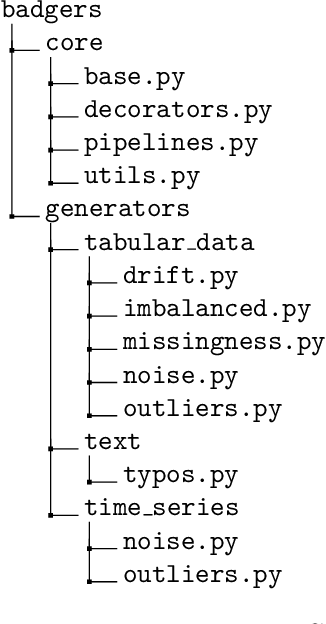
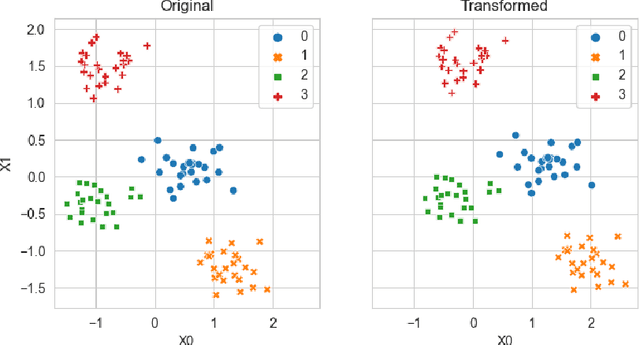
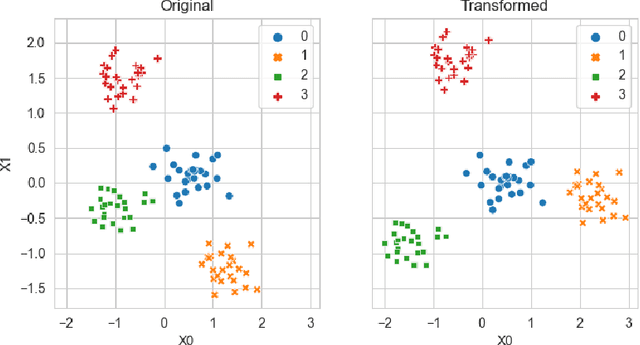
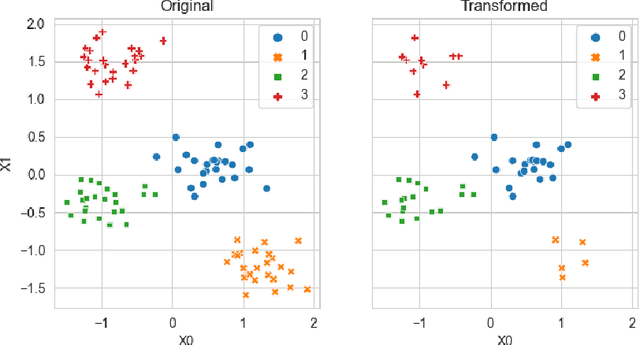
Generating context specific data quality deficits is necessary to experimentally assess data quality of data-driven (artificial intelligence (AI) or machine learning (ML)) applications. In this paper we present badgers, an extensible open-source Python library to generate data quality deficits (outliers, imbalanced data, drift, etc.) for different modalities (tabular data, time-series, text, etc.). The documentation is accessible at https://fraunhofer-iese.github.io/badgers/ and the source code at https://github.com/Fraunhofer-IESE/badgers
Conformal Prediction Regions for Time Series using Linear Complementarity Programming
Apr 03, 2023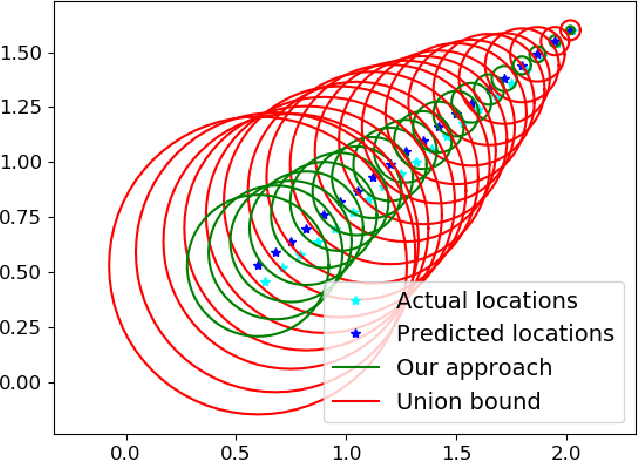
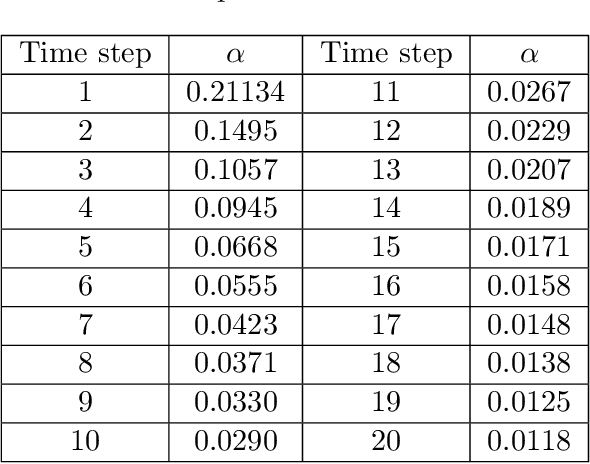
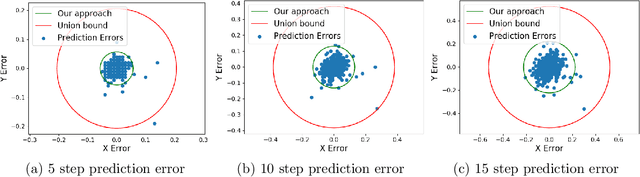
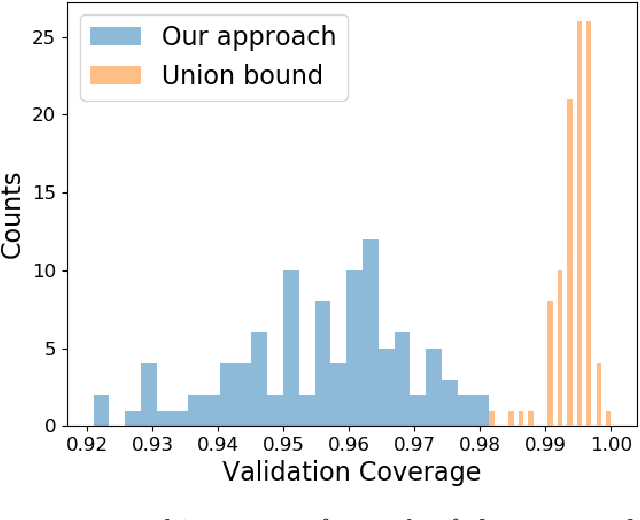
Conformal prediction is a statistical tool for producing prediction regions of machine learning models that are valid with high probability. However, applying conformal prediction to time series data leads to conservative prediction regions. In fact, to obtain prediction regions over $T$ time steps with confidence $1-\delta$, {previous works require that each individual prediction region is valid} with confidence $1-\delta/T$. We propose an optimization-based method for reducing this conservatism to enable long horizon planning and verification when using learning-enabled time series predictors. Instead of considering prediction errors individually at each time step, we consider a parameterized prediction error over multiple time steps. By optimizing the parameters over an additional dataset, we find prediction regions that are not conservative. We show that this problem can be cast as a mixed integer linear complementarity program (MILCP), which we then relax into a linear complementarity program (LCP). Additionally, we prove that the relaxed LP has the same optimal cost as the original MILCP. Finally, we demonstrate the efficacy of our method on a case study using pedestrian trajectory predictors.
Steel Surface Roughness Parameter Calculations Using Lasers and Machine Learning Models
Jul 06, 2023
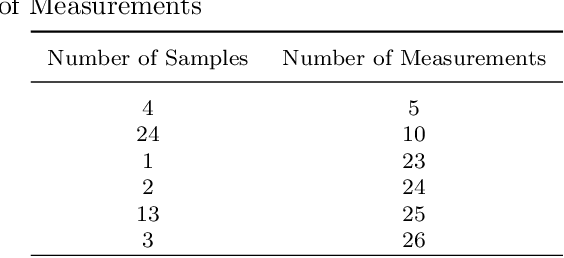
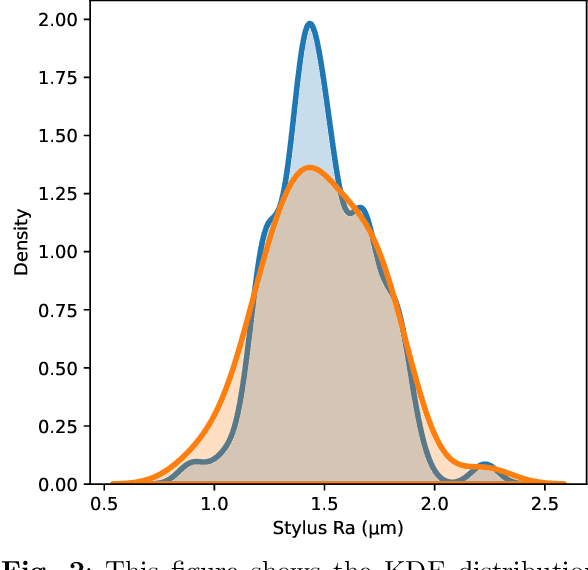
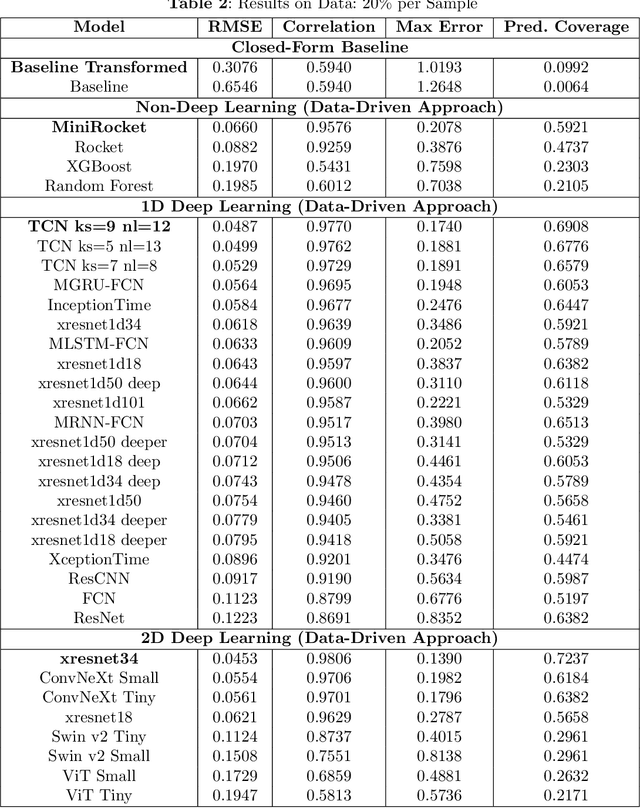
Control of surface texture in strip steel is essential to meet customer requirements during galvanizing and temper rolling processes. Traditional methods rely on post-production stylus measurements, while on-line techniques offer non-contact and real-time measurements of the entire strip. However, ensuring accurate measurement is imperative for their effective utilization in the manufacturing pipeline. Moreover, accurate on-line measurements enable real-time adjustments of manufacturing processing parameters during production, ensuring consistent quality and the possibility of closed-loop control of the temper mill. In this study, we leverage state-of-the-art machine learning models to enhance the transformation of on-line measurements into significantly a more accurate Ra surface roughness metric. By comparing a selection of data-driven approaches, including both deep learning and non-deep learning methods, to the close-form transformation, we evaluate their potential for improving surface texture control in temper strip steel manufacturing.
PC-Droid: Faster diffusion and improved quality for particle cloud generation
Jul 14, 2023Building on the success of PC-JeDi we introduce PC-Droid, a substantially improved diffusion model for the generation of jet particle clouds. By leveraging a new diffusion formulation, studying more recent integration solvers, and training on all jet types simultaneously, we are able to achieve state-of-the-art performance for all types of jets across all evaluation metrics. We study the trade-off between generation speed and quality by comparing two attention based architectures, as well as the potential of consistency distillation to reduce the number of diffusion steps. Both the faster architecture and consistency models demonstrate performance surpassing many competing models, with generation time up to two orders of magnitude faster than PC-JeDi.
Cardiac CT perfusion imaging of pericoronary adipose tissue (PCAT) highlights potential confounds in coronary CTA
Jun 27, 2023Features of pericoronary adipose tissue (PCAT) assessed from coronary computed tomography angiography (CCTA) are associated with inflammation and cardiovascular risk. As PCAT is vascularly connected with coronary vasculature, the presence of iodine is a potential confounding factor on PCAT HU and textures that has not been adequately investigated. Use dynamic cardiac CT perfusion (CCTP) to inform contrast determinants of PCAT assessment. From CCTP, we analyzed HU dynamics of territory-specific PCAT, myocardium, and other adipose depots in patients with coronary artery disease. HU, blood flow, and radiomics were assessed over time. Changes from peak aorta time, Pa, chosen to model the time of CCTA, were obtained. HU in PCAT increased more than in other adipose depots. The estimated blood flow in PCAT was ~23% of that in the contiguous myocardium. Comparing PCAT distal and proximal to a significant stenosis, we found less enhancement and longer time-to-peak distally. Two-second offsets [before, after] Pa resulted in [ 4-HU, 3-HU] differences in PCAT. Due to changes in HU, the apparent PCAT volume reduced ~15% from the first scan (P1) to Pa using a conventional fat window. Comparing radiomic features over time, 78% of features changed >10% relative to P1. CCTP elucidates blood flow in PCAT and enables analysis of PCAT features over time. PCAT assessments (HU, apparent volume, and radiomics) are sensitive to acquisition timing and the presence of obstructive stenosis, which may confound the interpretation of PCAT in CCTA images. Data normalization may be in order.
Automatic MILP Solver Configuration By Learning Problem Similarities
Jul 02, 2023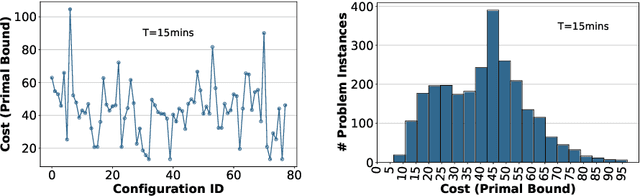

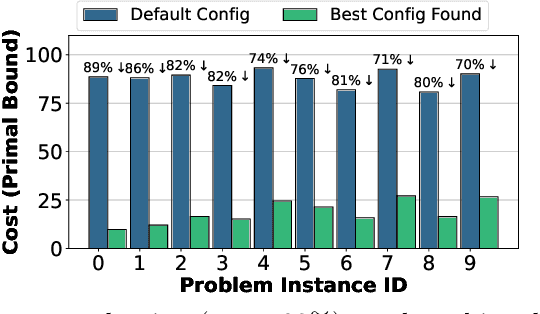
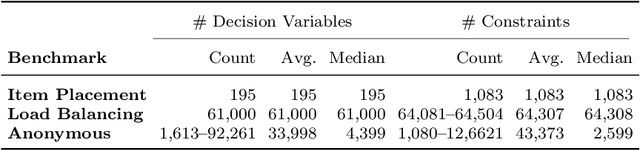
A large number of real-world optimization problems can be formulated as Mixed Integer Linear Programs (MILP). MILP solvers expose numerous configuration parameters to control their internal algorithms. Solutions, and their associated costs or runtimes, are significantly affected by the choice of the configuration parameters, even when problem instances have the same number of decision variables and constraints. On one hand, using the default solver configuration leads to suboptimal solutions. On the other hand, searching and evaluating a large number of configurations for every problem instance is time-consuming and, in some cases, infeasible. In this study, we aim to predict configuration parameters for unseen problem instances that yield lower-cost solutions without the time overhead of searching-and-evaluating configurations at the solving time. Toward that goal, we first investigate the cost correlation of MILP problem instances that come from the same distribution when solved using different configurations. We show that instances that have similar costs using one solver configuration also have similar costs using another solver configuration in the same runtime environment. After that, we present a methodology based on Deep Metric Learning to learn MILP similarities that correlate with their final solutions' costs. At inference time, given a new problem instance, it is first projected into the learned metric space using the trained model, and configuration parameters are instantly predicted using previously-explored configurations from the nearest neighbor instance in the learned embedding space. Empirical results on real-world problem benchmarks show that our method predicts configuration parameters that improve solutions' costs by up to 38% compared to existing approaches.
Improved Test-Time Adaptation for Domain Generalization
Apr 10, 2023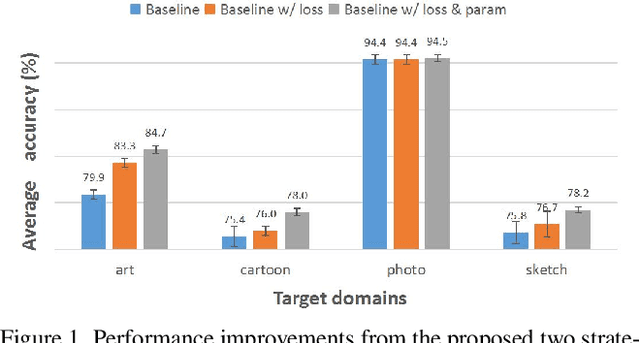
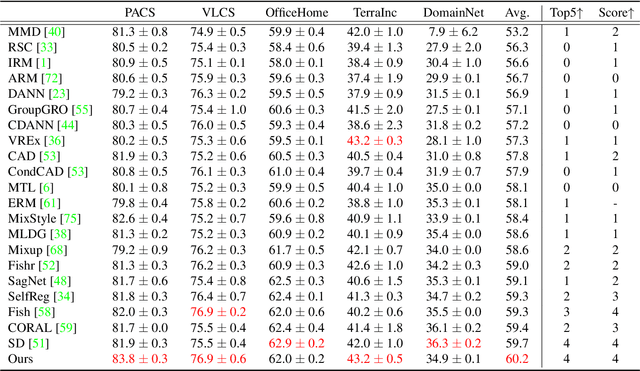
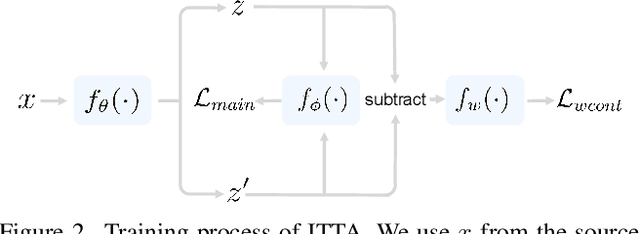
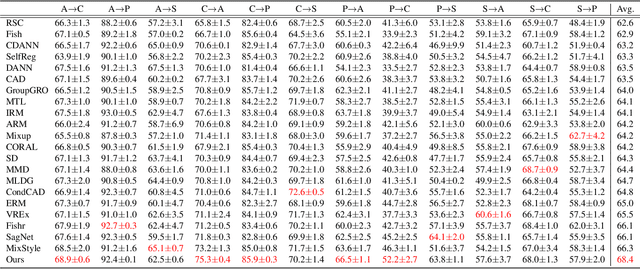
The main challenge in domain generalization (DG) is to handle the distribution shift problem that lies between the training and test data. Recent studies suggest that test-time training (TTT), which adapts the learned model with test data, might be a promising solution to the problem. Generally, a TTT strategy hinges its performance on two main factors: selecting an appropriate auxiliary TTT task for updating and identifying reliable parameters to update during the test phase. Both previous arts and our experiments indicate that TTT may not improve but be detrimental to the learned model if those two factors are not properly considered. This work addresses those two factors by proposing an Improved Test-Time Adaptation (ITTA) method. First, instead of heuristically defining an auxiliary objective, we propose a learnable consistency loss for the TTT task, which contains learnable parameters that can be adjusted toward better alignment between our TTT task and the main prediction task. Second, we introduce additional adaptive parameters for the trained model, and we suggest only updating the adaptive parameters during the test phase. Through extensive experiments, we show that the proposed two strategies are beneficial for the learned model (see Figure 1), and ITTA could achieve superior performance to the current state-of-the-art methods on several DG benchmarks. Code is available at https://github.com/liangchen527/ITTA.
A Cascade Transformer-based Model for 3D Dose Distribution Prediction in Head and Neck Cancer Radiotherapy
Jul 22, 2023Radiation therapy is the primary method used to treat cancer in the clinic. Its goal is to deliver a precise dose to the planning target volume (PTV) while protecting the surrounding organs at risk (OARs). However, the traditional workflow used by dosimetrists to plan the treatment is time-consuming and subjective, requiring iterative adjustments based on their experience. Deep learning methods can be used to predict dose distribution maps to address these limitations. The study proposes a cascade model for organs at risk segmentation and dose distribution prediction. An encoder-decoder network has been developed for the segmentation task, in which the encoder consists of transformer blocks, and the decoder uses multi-scale convolutional blocks. Another cascade encoder-decoder network has been proposed for dose distribution prediction using a pyramid architecture. The proposed model has been evaluated using an in-house head and neck cancer dataset of 96 patients and OpenKBP, a public head and neck cancer dataset of 340 patients. The segmentation subnet achieved 0.79 and 2.71 for Dice and HD95 scores, respectively. This subnet outperformed the existing baselines. The dose distribution prediction subnet outperformed the winner of the OpenKBP2020 competition with 2.77 and 1.79 for dose and DVH scores, respectively. The predicted dose maps showed good coincidence with ground truth, with a superiority after linking with the auxiliary segmentation task. The proposed model outperformed state-of-the-art methods, especially in regions with low prescribed doses.