 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Modelling the Spread of COVID-19 in Indoor Spaces using Automated Probabilistic Planning
Aug 16, 2023
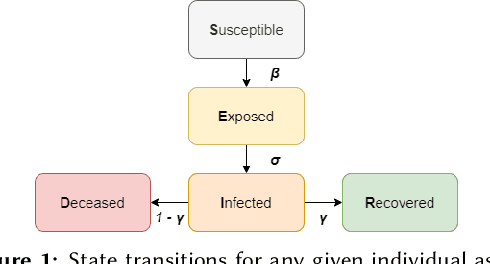
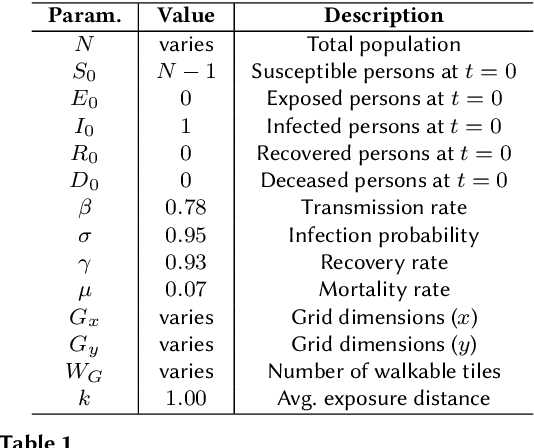
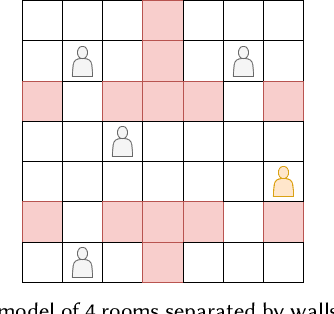
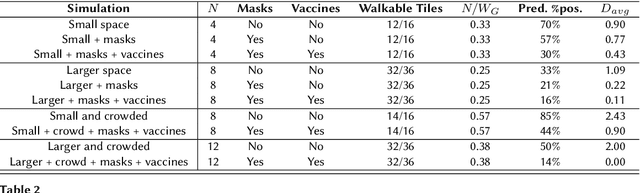
The coronavirus disease 2019 (COVID-19) pandemic has been ongoing for around 3 years, and has infected over 750 million people and caused over 6 million deaths worldwide at the time of writing. Throughout the pandemic, several strategies for controlling the spread of the disease have been debated by healthcare professionals, government authorities, and international bodies. To anticipate the potential impact of the disease, and to simulate the effectiveness of different mitigation strategies, a robust model of disease spread is needed. In this work, we explore a novel approach based on probabilistic planning and dynamic graph analysis to model the spread of COVID-19 in indoor spaces. We endow the planner with means to control the spread of the disease through non-pharmaceutical interventions (NPIs) such as mandating masks and vaccines, and we compare the impact of crowds and capacity limits on the spread of COVID-19 in these settings. We demonstrate that the use of probabilistic planning is effective in predicting the amount of infections that are likely to occur in shared spaces, and that automated planners have the potential to design competent interventions to limit the spread of the disease. Our code is fully open-source and is available at: https://github.com/mharmanani/prob-planning-covid19 .
Counterfactual Generative Models for Time-Varying Treatments
May 25, 2023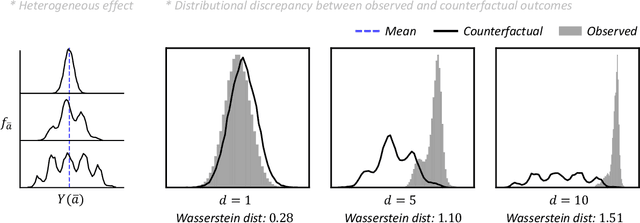
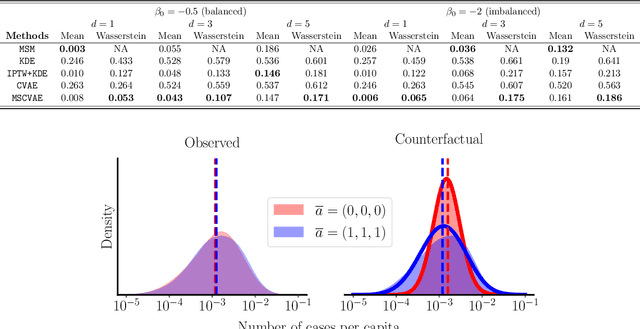
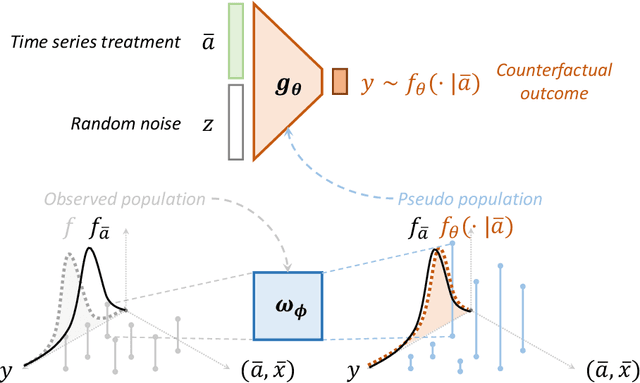

Estimating average causal effects is a common practice to test new treatments. However, the average effect ''masks'' important individual characteristics in the counterfactual distribution, which may lead to safety, fairness, and ethical concerns. This issue is exacerbated in the temporal setting, where the treatment is sequential and time-varying, leading to an intricate influence on the counterfactual distribution. In this paper, we propose a novel conditional generative modeling approach to capture the whole counterfactual distribution, allowing efficient inference on certain statistics of the counterfactual distribution. This makes the proposed approach particularly suitable for healthcare and public policy making. Our generative modeling approach carefully tackles the distribution mismatch in the observed data and the targeted counterfactual distribution via a marginal structural model. Our method outperforms state-of-the-art baselines on both synthetic and real data.
Appliance Detection Using Very Low-Frequency Smart Meter Time Series
May 21, 2023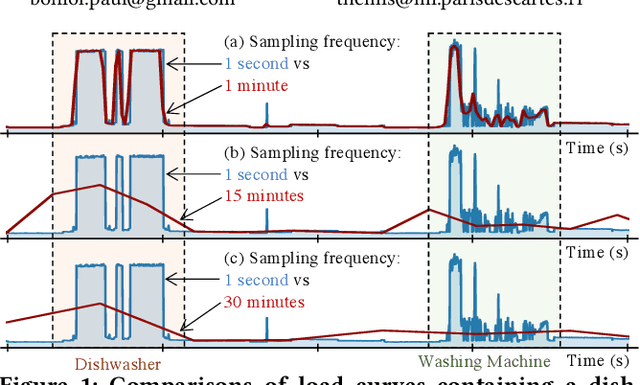
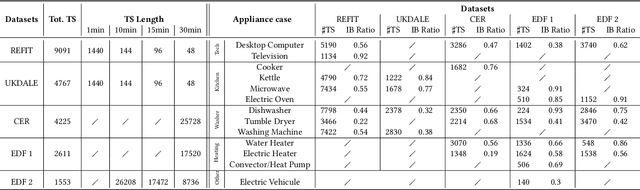
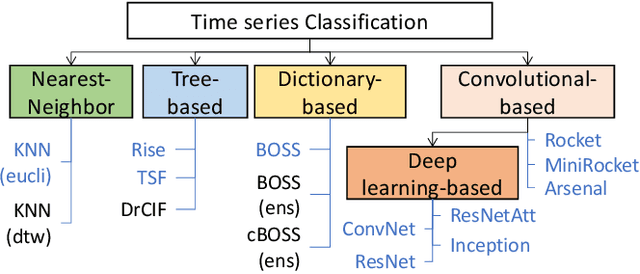
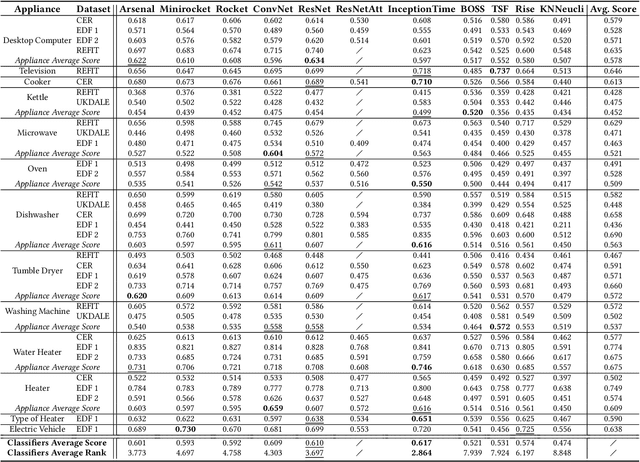
In recent years, smart meters have been widely adopted by electricity suppliers to improve the management of the smart grid system. These meters usually collect energy consumption data at a very low frequency (every 30min), enabling utilities to bill customers more accurately. To provide more personalized recommendations, the next step is to detect the appliances owned by customers, which is a challenging problem, due to the very-low meter reading frequency. Even though the appliance detection problem can be cast as a time series classification problem, with many such classifiers having been proposed in the literature, no study has applied and compared them on this specific problem. This paper presents an in-depth evaluation and comparison of state-of-the-art time series classifiers applied to detecting the presence/absence of diverse appliances in very low-frequency smart meter data. We report results with five real datasets. We first study the impact of the detection quality of 13 different appliances using 30min sampled data, and we subsequently propose an analysis of the possible detection performance gain by using a higher meter reading frequency. The results indicate that the performance of current time series classifiers varies significantly. Some of them, namely deep learning-based classifiers, provide promising results in terms of accuracy (especially for certain appliances), even using 30min sampled data, and are scalable to the large smart meter time series collections of energy consumption data currently available to electricity suppliers. Nevertheless, our study shows that more work is needed in this area to further improve the accuracy of the proposed solutions. This paper appeared in ACM e-Energy 2023.
Event Stream GPT: A Data Pre-processing and Modeling Library for Generative, Pre-trained Transformers over Continuous-time Sequences of Complex Events
Jun 21, 2023
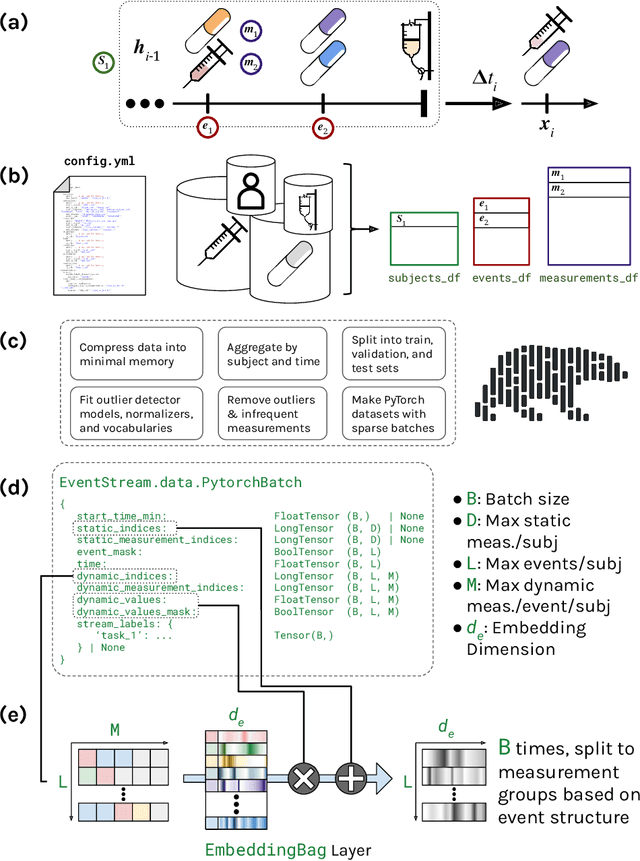


Generative, pre-trained transformers (GPTs, a.k.a. "Foundation Models") have reshaped natural language processing (NLP) through their versatility in diverse downstream tasks. However, their potential extends far beyond NLP. This paper provides a software utility to help realize this potential, extending the applicability of GPTs to continuous-time sequences of complex events with internal dependencies, such as medical record datasets. Despite their potential, the adoption of foundation models in these domains has been hampered by the lack of suitable tools for model construction and evaluation. To bridge this gap, we introduce Event Stream GPT (ESGPT), an open-source library designed to streamline the end-to-end process for building GPTs for continuous-time event sequences. ESGPT allows users to (1) build flexible, foundation-model scale input datasets by specifying only a minimal configuration file, (2) leverage a Hugging Face compatible modeling API for GPTs over this modality that incorporates intra-event causal dependency structures and autoregressive generation capabilities, and (3) evaluate models via standardized processes that can assess few and even zero-shot performance of pre-trained models on user-specified fine-tuning tasks.
AdaptEx: A Self-Service Contextual Bandit Platform
Aug 08, 2023This paper presents AdaptEx, a self-service contextual bandit platform widely used at Expedia Group, that leverages multi-armed bandit algorithms to personalize user experiences at scale. AdaptEx considers the unique context of each visitor to select the optimal variants and learns quickly from every interaction they make. It offers a powerful solution to improve user experiences while minimizing the costs and time associated with traditional testing methods. The platform unlocks the ability to iterate towards optimal product solutions quickly, even in ever-changing content and continuous "cold start" situations gracefully.
Whale Detection Enhancement through Synthetic Satellite Images
Aug 15, 2023
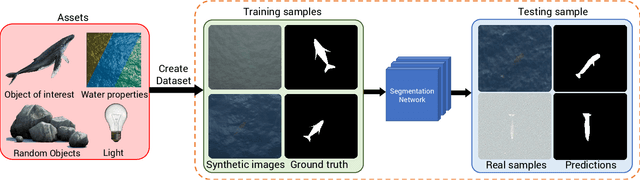
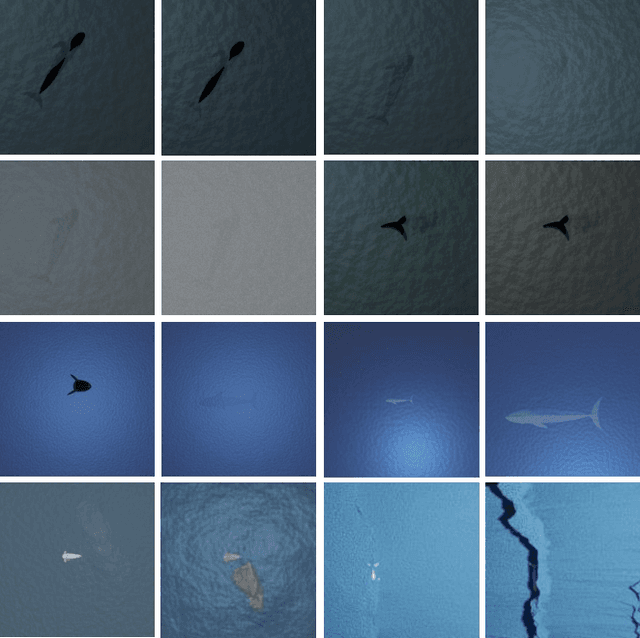

With a number of marine populations in rapid decline, collecting and analyzing data about marine populations has become increasingly important to develop effective conservation policies for a wide range of marine animals, including whales. Modern computer vision algorithms allow us to detect whales in images in a wide range of domains, further speeding up and enhancing the monitoring process. However, these algorithms heavily rely on large training datasets, which are challenging and time-consuming to collect particularly in marine or aquatic environments. Recent advances in AI however have made it possible to synthetically create datasets for training machine learning algorithms, thus enabling new solutions that were not possible before. In this work, we present a solution - SeaDroneSim2 benchmark suite, which addresses this challenge by generating aerial, and satellite synthetic image datasets to improve the detection of whales and reduce the effort required for training data collection. We show that we can achieve a 15% performance boost on whale detection compared to using the real data alone for training, by augmenting a 10% real data. We open source both the code of the simulation platform SeaDroneSim2 and the dataset generated through it.
NeFL: Nested Federated Learning for Heterogeneous Clients
Aug 15, 2023Federated learning (FL) is a promising approach in distributed learning keeping privacy. However, during the training pipeline of FL, slow or incapable clients (i.e., stragglers) slow down the total training time and degrade performance. System heterogeneity, including heterogeneous computing and network bandwidth, has been addressed to mitigate the impact of stragglers. Previous studies split models to tackle the issue, but with less degree-of-freedom in terms of model architecture. We propose nested federated learning (NeFL), a generalized framework that efficiently divides a model into submodels using both depthwise and widthwise scaling. NeFL is implemented by interpreting models as solving ordinary differential equations (ODEs) with adaptive step sizes. To address the inconsistency that arises when training multiple submodels with different architecture, we decouple a few parameters. NeFL enables resource-constrained clients to effectively join the FL pipeline and the model to be trained with a larger amount of data. Through a series of experiments, we demonstrate that NeFL leads to significant gains, especially for the worst-case submodel (e.g., 8.33 improvement on CIFAR-10). Furthermore, we demonstrate NeFL aligns with recent studies in FL.
Quantifying the Cost of Learning in Queueing Systems
Aug 15, 2023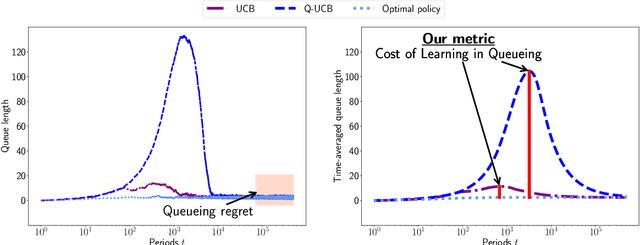
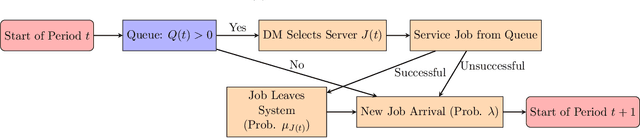
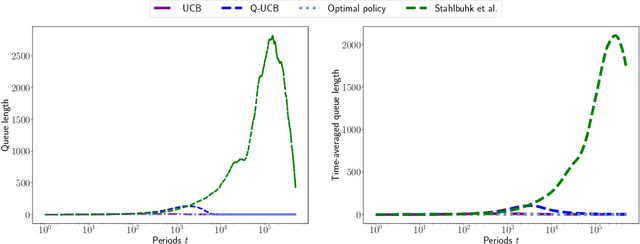
Queueing systems are widely applicable stochastic models with use cases in communication networks, healthcare, service systems, etc. Although their optimal control has been extensively studied, most existing approaches assume perfect knowledge of system parameters. Of course, this assumption rarely holds in practice where there is parameter uncertainty, thus motivating a recent line of work on bandit learning for queueing systems. This nascent stream of research focuses on the asymptotic performance of the proposed algorithms. In this paper, we argue that an asymptotic metric, which focuses on late-stage performance, is insufficient to capture the intrinsic statistical complexity of learning in queueing systems which typically occurs in the early stage. Instead, we propose the Cost of Learning in Queueing (CLQ), a new metric that quantifies the maximum increase in time-averaged queue length caused by parameter uncertainty. We characterize the CLQ of a single-queue multi-server system, and then extend these results to multi-queue multi-server systems and networks of queues. In establishing our results, we propose a unified analysis framework for CLQ that bridges Lyapunov and bandit analysis, which could be of independent interest.
XMem++: Production-level Video Segmentation From Few Annotated Frames
Aug 15, 2023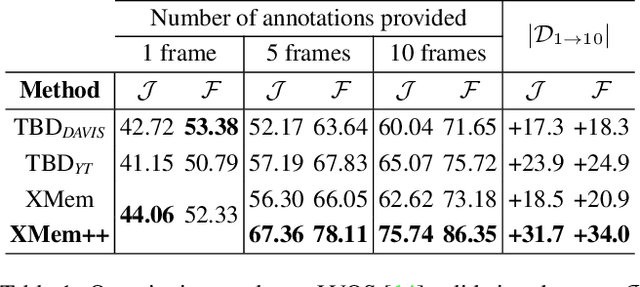

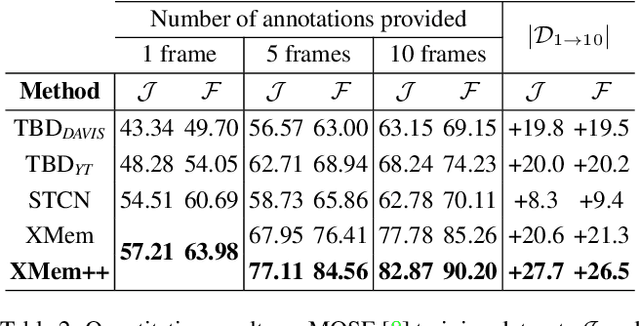
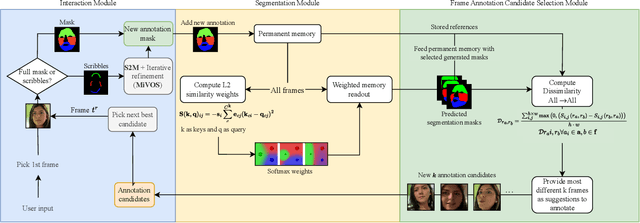
Despite advancements in user-guided video segmentation, extracting complex objects consistently for highly complex scenes is still a labor-intensive task, especially for production. It is not uncommon that a majority of frames need to be annotated. We introduce a novel semi-supervised video object segmentation (SSVOS) model, XMem++, that improves existing memory-based models, with a permanent memory module. Most existing methods focus on single frame annotations, while our approach can effectively handle multiple user-selected frames with varying appearances of the same object or region. Our method can extract highly consistent results while keeping the required number of frame annotations low. We further introduce an iterative and attention-based frame suggestion mechanism, which computes the next best frame for annotation. Our method is real-time and does not require retraining after each user input. We also introduce a new dataset, PUMaVOS, which covers new challenging use cases not found in previous benchmarks. We demonstrate SOTA performance on challenging (partial and multi-class) segmentation scenarios as well as long videos, while ensuring significantly fewer frame annotations than any existing method. Project page: https://max810.github.io/xmem2-project-page/
Shortcut-V2V: Compression Framework for Video-to-Video Translation based on Temporal Redundancy Reduction
Aug 15, 2023Video-to-video translation aims to generate video frames of a target domain from an input video. Despite its usefulness, the existing networks require enormous computations, necessitating their model compression for wide use. While there exist compression methods that improve computational efficiency in various image/video tasks, a generally-applicable compression method for video-to-video translation has not been studied much. In response, we present Shortcut-V2V, a general-purpose compression framework for video-to-video translation. Shourcut-V2V avoids full inference for every neighboring video frame by approximating the intermediate features of a current frame from those of the previous frame. Moreover, in our framework, a newly-proposed block called AdaBD adaptively blends and deforms features of neighboring frames, which makes more accurate predictions of the intermediate features possible. We conduct quantitative and qualitative evaluations using well-known video-to-video translation models on various tasks to demonstrate the general applicability of our framework. The results show that Shourcut-V2V achieves comparable performance compared to the original video-to-video translation model while saving 3.2-5.7x computational cost and 7.8-44x memory at test time.