 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
In-Context Unlearning: Language Models as Few Shot Unlearners
Oct 12, 2023
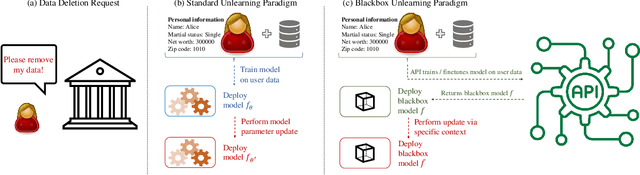
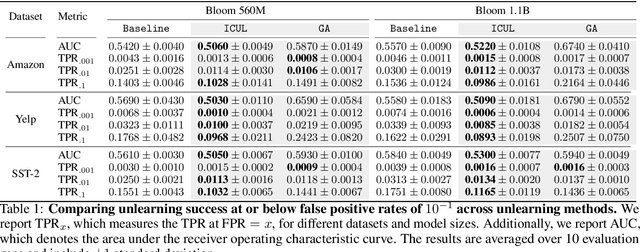

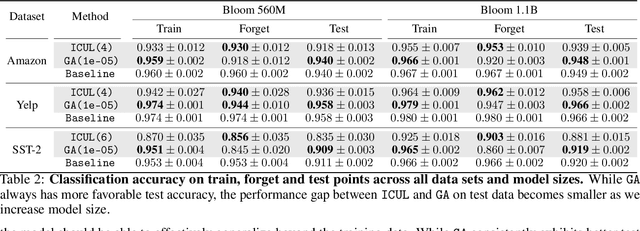
Machine unlearning, the study of efficiently removing the impact of specific training points on the trained model, has garnered increased attention of late, driven by the need to comply with privacy regulations like the Right to be Forgotten. Although unlearning is particularly relevant for LLMs in light of the copyright issues they raise, achieving precise unlearning is computationally infeasible for very large models. To this end, recent work has proposed several algorithms which approximate the removal of training data without retraining the model. These algorithms crucially rely on access to the model parameters in order to update them, an assumption that may not hold in practice due to computational constraints or when the LLM is accessed via API. In this work, we propose a new class of unlearning methods for LLMs we call ''In-Context Unlearning'', providing inputs in context and without having to update model parameters. To unlearn a particular training instance, we provide the instance alongside a flipped label and additional correctly labelled instances which are prepended as inputs to the LLM at inference time. Our experimental results demonstrate that these contexts effectively remove specific information from the training set while maintaining performance levels that are competitive with (or in some cases exceed) state-of-the-art unlearning methods that require access to the LLM parameters.
Towards Robust Multi-Modal Reasoning via Model Selection
Oct 12, 2023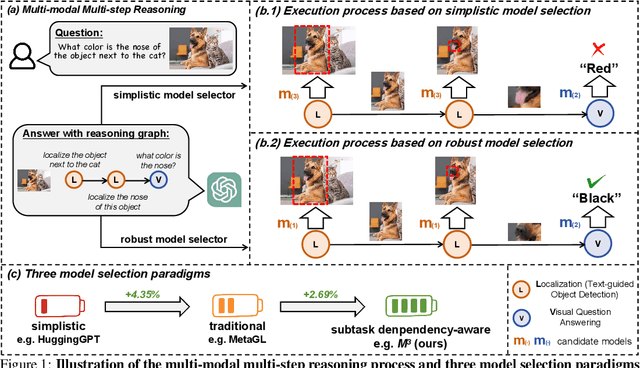
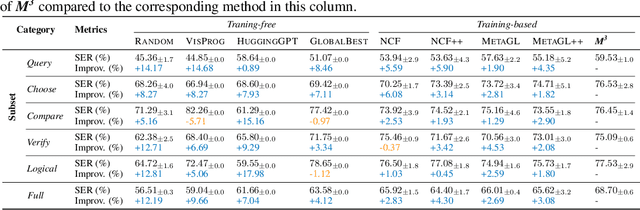
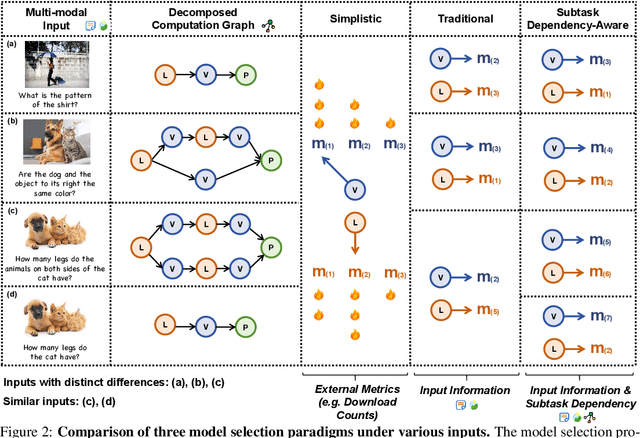

The reasoning capabilities of LLM (Large Language Model) are widely acknowledged in recent research, inspiring studies on tool learning and autonomous agents. LLM serves as the "brain" of agent, orchestrating multiple tools for collaborative multi-step task solving. Unlike methods invoking tools like calculators or weather APIs for straightforward tasks, multi-modal agents excel by integrating diverse AI models for complex challenges. However, current multi-modal agents neglect the significance of model selection: they primarily focus on the planning and execution phases, and will only invoke predefined task-specific models for each subtask, making the execution fragile. Meanwhile, other traditional model selection methods are either incompatible with or suboptimal for the multi-modal agent scenarios, due to ignorance of dependencies among subtasks arising by multi-step reasoning. To this end, we identify the key challenges therein and propose the $\textit{M}^3$ framework as a plug-in with negligible runtime overhead at test-time. This framework improves model selection and bolsters the robustness of multi-modal agents in multi-step reasoning. In the absence of suitable benchmarks, we create MS-GQA, a new dataset specifically designed to investigate the model selection challenge in multi-modal agents. Our experiments reveal that our framework enables dynamic model selection, considering both user inputs and subtask dependencies, thereby robustifying the overall reasoning process. Our code and benchmark: https://github.com/LINs-lab/M3.
A Generic Software Framework for Distributed Topological Analysis Pipelines
Oct 12, 2023This system paper presents a software framework for the support of topological analysis pipelines in a distributed-memory model. While several recent papers introduced topology-based approaches for distributed-memory environments, these were reporting experiments obtained with tailored, mono-algorithm implementations. In contrast, we describe in this paper a general-purpose, generic framework for topological analysis pipelines, i.e. a sequence of topological algorithms interacting together, possibly on distinct numbers of processes. Specifically, we instantiated our framework with the MPI model, within the Topology ToolKit (TTK). While developing this framework, we faced several algorithmic and software engineering challenges, which we document in this paper. We provide a taxonomy for the distributed-memory topological algorithms supported by TTK, depending on their communication needs and provide examples of hybrid MPI+thread parallelizations. Detailed performance analyses show that parallel efficiencies range from $20\%$ to $80\%$ (depending on the algorithms), and that the MPI-specific preconditioning introduced by our framework induces a negligible computation time overhead. We illustrate the new distributed-memory capabilities of TTK with an example of advanced analysis pipeline, combining multiple algorithms, run on the largest publicly available dataset we have found (120 billion vertices) on a standard cluster with 64 nodes (for a total of 1,536 cores). Finally, we provide a roadmap for the completion of TTK's MPI extension, along with generic recommendations for each algorithm communication category.
Reinforcement Learning of Display Transfer Robots in Glass Flow Control Systems: A Physical Simulation-Based Approach
Oct 12, 2023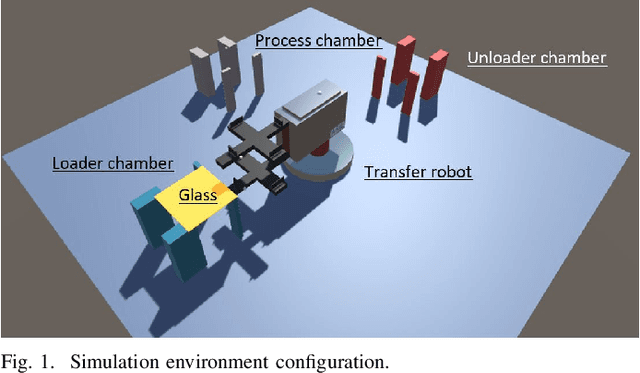
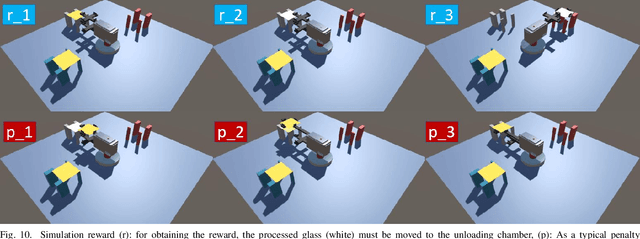
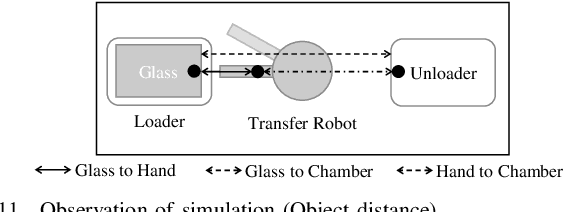

A flow control system is a critical concept for increasing the production capacity of manufacturing systems. To solve the scheduling optimization problem related to the flow control with the aim of improving productivity, existing methods depend on a heuristic design by domain human experts. Therefore, the methods require correction, monitoring, and verification by using real equipment. As system designs increase in complexity, the monitoring time increases, which decreases the probability of arriving at the optimal design. As an alternative approach to the heuristic design of flow control systems, the use of deep reinforcement learning to solve the scheduling optimization problem has been considered. Although the existing research on reinforcement learning has yielded excellent performance in some areas, the applicability of the results to actual FAB such as display and semiconductor manufacturing processes is not evident so far. To this end, we propose a method to implement a physical simulation environment and devise a feasible flow control system design using a transfer robot in display manufacturing through reinforcement learning. We present a model and parameter setting to build a virtual environment for different display transfer robots, and training methods of reinforcement learning on the environment to obtain an optimal scheduling of glass flow control systems. Its feasibility was verified by using different types of robots used in the actual process.
Stabilizing Subject Transfer in EEG Classification with Divergence Estimation
Oct 12, 2023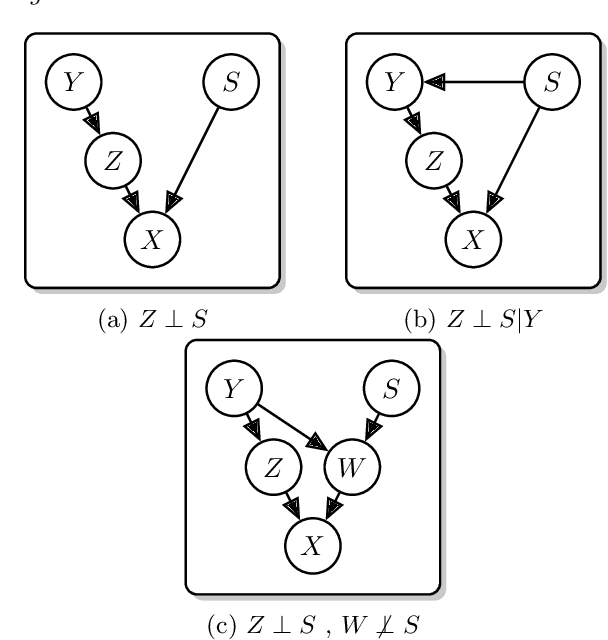

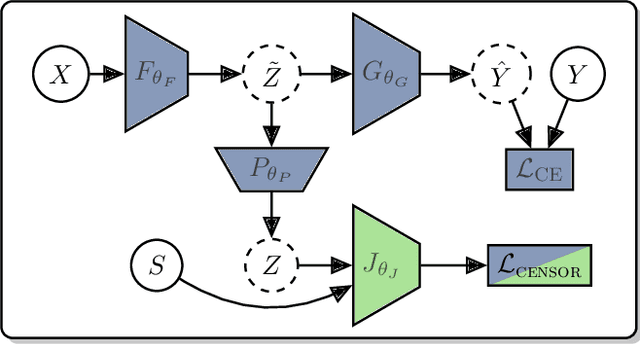
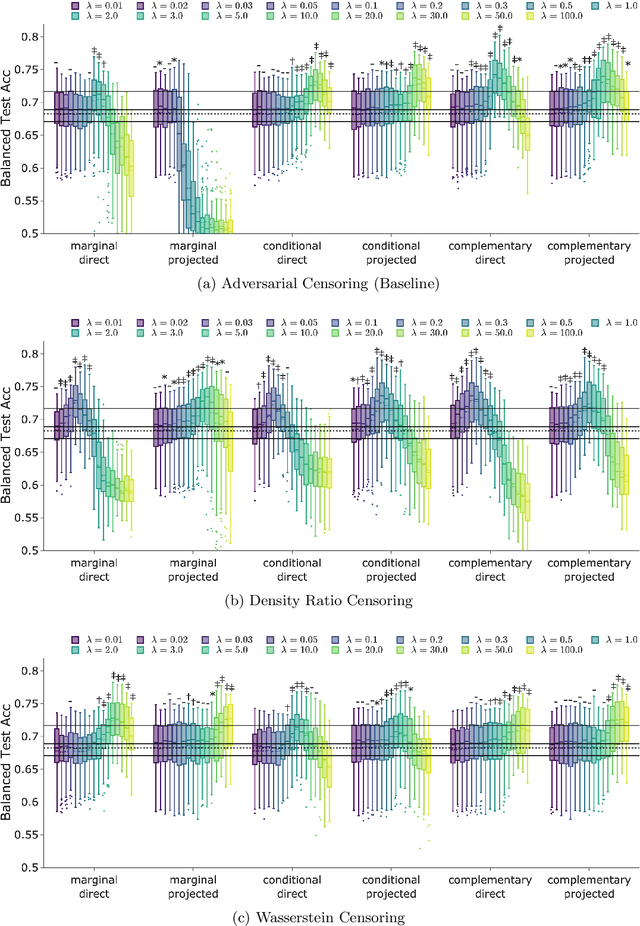
Classification models for electroencephalogram (EEG) data show a large decrease in performance when evaluated on unseen test sub jects. We reduce this performance decrease using new regularization techniques during model training. We propose several graphical models to describe an EEG classification task. From each model, we identify statistical relationships that should hold true in an idealized training scenario (with infinite data and a globally-optimal model) but that may not hold in practice. We design regularization penalties to enforce these relationships in two stages. First, we identify suitable proxy quantities (divergences such as Mutual Information and Wasserstein-1) that can be used to measure statistical independence and dependence relationships. Second, we provide algorithms to efficiently estimate these quantities during training using secondary neural network models. We conduct extensive computational experiments using a large benchmark EEG dataset, comparing our proposed techniques with a baseline method that uses an adversarial classifier. We find our proposed methods significantly increase balanced accuracy on test subjects and decrease overfitting. The proposed methods exhibit a larger benefit over a greater range of hyperparameters than the baseline method, with only a small computational cost at training time. These benefits are largest when used for a fixed training period, though there is still a significant benefit for a subset of hyperparameters when our techniques are used in conjunction with early stopping regularization.
Divorce Prediction with Machine Learning: Insights and LIME Interpretability
Oct 12, 2023Divorce is one of the most common social issues in developed countries like in the United States. Almost 50% of the recent marriages turn into an involuntary divorce or separation. While it is evident that people vary to a different extent, and even over time, an incident like Divorce does not interrupt the individual's daily activities; still, Divorce has a severe effect on the individual's mental health, and personal life. Within the scope of this research, the divorce prediction was carried out by evaluating a dataset named by the 'divorce predictor dataset' to correctly classify between married and Divorce people using six different machine learning algorithms- Logistic Regression (LR), Linear Discriminant Analysis (LDA), K-Nearest Neighbors (KNN), Classification and Regression Trees (CART), Gaussian Na\"ive Bayes (NB), and, Support Vector Machines (SVM). Preliminary computational results show that algorithms such as SVM, KNN, and LDA, can perform that task with an accuracy of 98.57%. This work's additional novel contribution is the detailed and comprehensive explanation of prediction probabilities using Local Interpretable Model-Agnostic Explanations (LIME). Utilizing LIME to analyze test results illustrates the possibility of differentiating between divorced and married couples. Finally, we have developed a divorce predictor app considering ten most important features that potentially affect couples in making decisions in their divorce, such tools can be used by any one in order to identify their relationship condition.
Noisy-ArcMix: Additive Noisy Angular Margin Loss Combined With Mixup Anomalous Sound Detection
Oct 10, 2023Unsupervised anomalous sound detection (ASD) aims to identify anomalous sounds by learning the features of normal operational sounds and sensing their deviations. Recent approaches have focused on the self-supervised task utilizing the classification of normal data, and advanced models have shown that securing representation space for anomalous data is important through representation learning yielding compact intra-class and well-separated intra-class distributions. However, we show that conventional approaches often fail to ensure sufficient intra-class compactness and exhibit angular disparity between samples and their corresponding centers. In this paper, we propose a training technique aimed at ensuring intra-class compactness and increasing the angle gap between normal and abnormal samples. Furthermore, we present an architecture that extracts features for important temporal regions, enabling the model to learn which time frames should be emphasized or suppressed. Experimental results demonstrate that the proposed method achieves the best performance giving 0.90%, 0.83%, and 2.16% improvement in terms of AUC, pAUC, and mAUC, respectively, compared to the state-of-the-art method on DCASE 2020 Challenge Task2 dataset.
Predicting Three Types of Freezing of Gait Events Using Deep Learning Models
Oct 10, 2023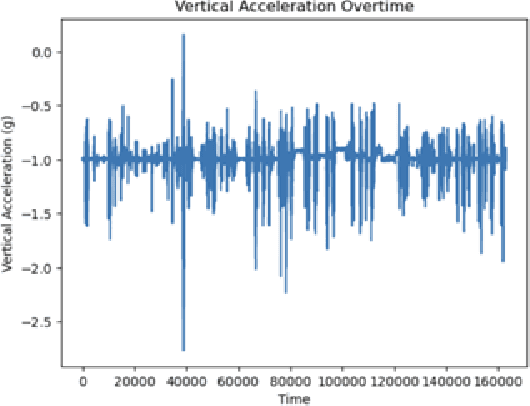
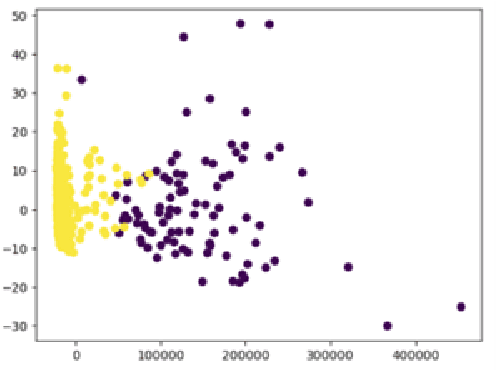
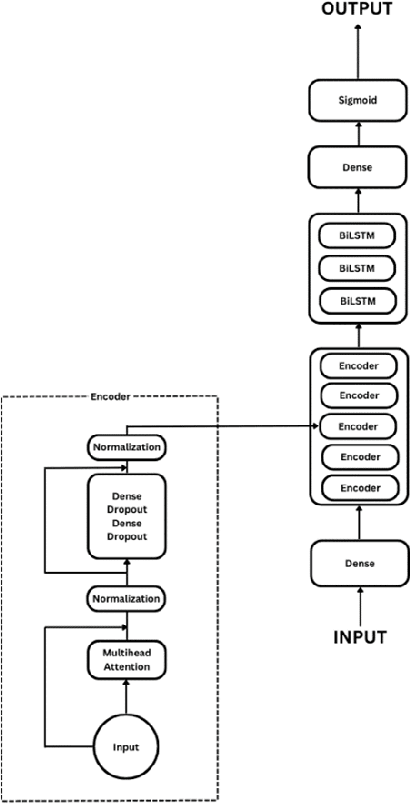
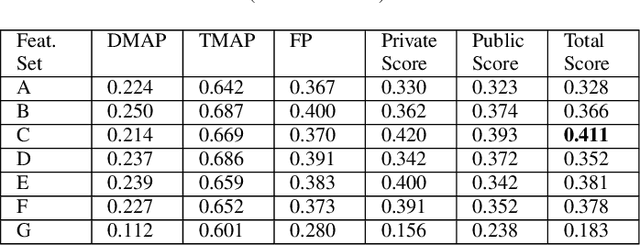
Freezing of gait is a Parkinson's Disease symptom that episodically inflicts a patient with the inability to step or turn while walking. While medical experts have discovered various triggers and alleviating actions for freezing of gait, the underlying causes and prediction models are still being explored today. Current freezing of gait prediction models that utilize machine learning achieve high sensitivity and specificity in freezing of gait predictions based on time-series data; however, these models lack specifications on the type of freezing of gait events. We develop various deep learning models using the transformer encoder architecture plus Bidirectional LSTM layers and different feature sets to predict the three different types of freezing of gait events. The best performing model achieves a score of 0.427 on testing data, which would rank top 5 in Kaggle's Freezing of Gait prediction competition, hosted by THE MICHAEL J. FOX FOUNDATION. However, we also recognize overfitting in training data that could be potentially improved through pseudo labelling on additional data and model architecture simplification.
Hierarchical Mask2Former: Panoptic Segmentation of Crops, Weeds and Leaves
Oct 10, 2023
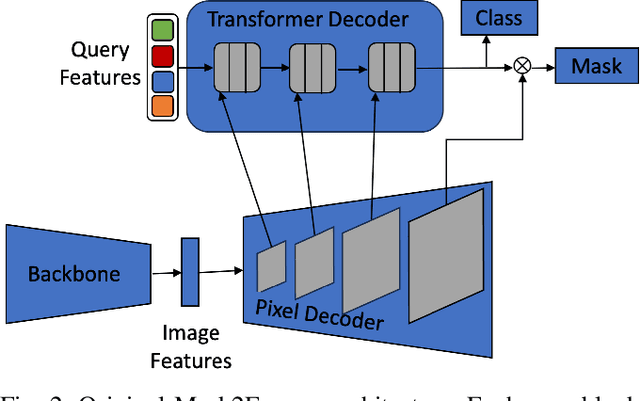
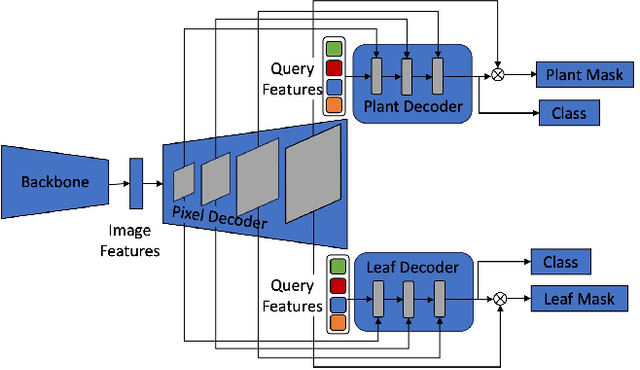
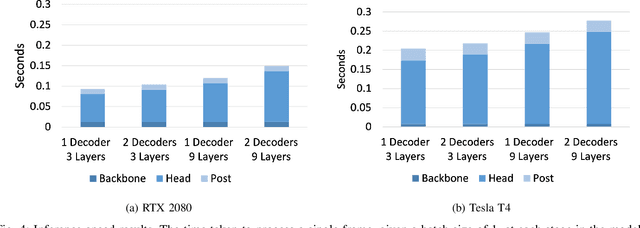
Advancements in machine vision that enable detailed inferences to be made from images have the potential to transform many sectors including agriculture. Precision agriculture, where data analysis enables interventions to be precisely targeted, has many possible applications. Precision spraying, for example, can limit the application of herbicide only to weeds, or limit the application of fertiliser only to undernourished crops, instead of spraying the entire field. The approach promises to maximise yields, whilst minimising resource use and harms to the surrounding environment. To this end, we propose a hierarchical panoptic segmentation method to simultaneously identify indicators of plant growth and locate weeds within an image. We adapt Mask2Former, a state-of-the-art architecture for panoptic segmentation, to predict crop, weed and leaf masks. We achieve a PQ{\dag} of 75.99. Additionally, we explore approaches to make the architecture more compact and therefore more suitable for time and compute constrained applications. With our more compact architecture, inference is up to 60% faster and the reduction in PQ{\dag} is less than 1%.
Neural Harmonium: An Interpretable Deep Structure for Nonlinear Dynamic System Identification with Application to Audio Processing
Oct 10, 2023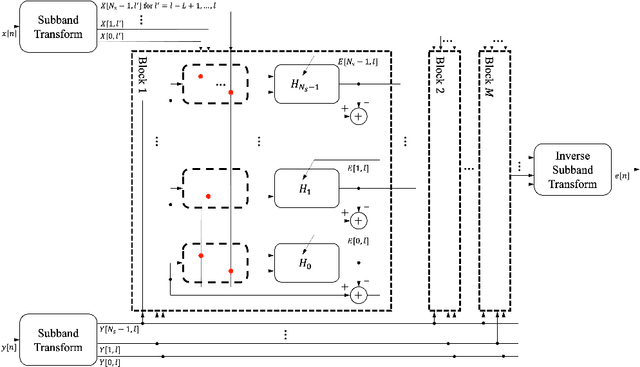
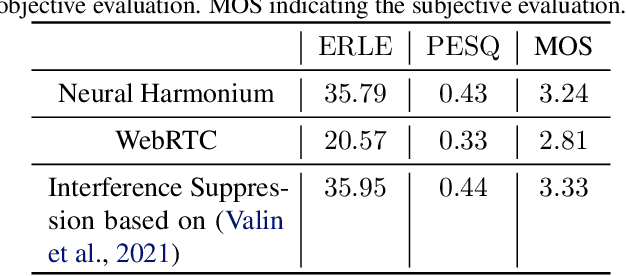
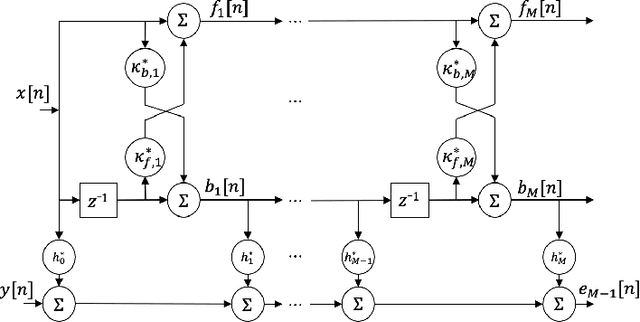

Improving the interpretability of deep neural networks has recently gained increased attention, especially when the power of deep learning is leveraged to solve problems in physics. Interpretability helps us understand a model's ability to generalize and reveal its limitations. In this paper, we introduce a causal interpretable deep structure for modeling dynamic systems. Our proposed model makes use of the harmonic analysis by modeling the system in a time-frequency domain while maintaining high temporal and spectral resolution. Moreover, the model is built in an order recursive manner which allows for fast, robust, and exact second order optimization without the need for an explicit Hessian calculation. To circumvent the resulting high dimensionality of the building blocks of our system, a neural network is designed to identify the frequency interdependencies. The proposed model is illustrated and validated on nonlinear system identification problems as required for audio signal processing tasks. Crowd-sourced experimentation contrasting the performance of the proposed approach to other state-of-the-art solutions on an acoustic echo cancellation scenario confirms the effectiveness of our method for real-life applications.