 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSound Source Separation Using Latent Variational Block-Wise Disentanglement
Feb 08, 2024

While neural network approaches have made significant strides in resolving classical signal processing problems, it is often the case that hybrid approaches that draw insight from both signal processing and neural networks produce more complete solutions. In this paper, we present a hybrid classical digital signal processing/deep neural network (DSP/DNN) approach to source separation (SS) highlighting the theoretical link between variational autoencoder and classical approaches to SS. We propose a system that transforms the single channel under-determined SS task to an equivalent multichannel over-determined SS problem in a properly designed latent space. The separation task in the latent space is treated as finding a variational block-wise disentangled representation of the mixture. We show empirically, that the design choices and the variational formulation of the task at hand motivated by the classical signal processing theoretical results lead to robustness to unseen out-of-distribution data and reduction of the overfitting risk. To address the resulting permutation issue we explicitly incorporate a novel differentiable permutation loss function and augment the model with a memory mechanism to keep track of the statistics of the individual sources.
Real-time Stereo Speech Enhancement with Spatial-Cue Preservation based on Dual-Path Structure
Feb 01, 2024



We introduce a real-time, multichannel speech enhancement algorithm which maintains the spatial cues of stereo recordings including two speech sources. Recognizing that each source has unique spatial information, our method utilizes a dual-path structure, ensuring the spatial cues remain unaffected during enhancement by applying source-specific common-band gain. This method also seamlessly integrates pretrained monaural speech enhancement, eliminating the need for retraining on stereo inputs. Source separation from stereo mixtures is achieved via spatial beamforming, with the steering vector for each source being adaptively updated using post-enhancement output signal. This ensures accurate tracking of the spatial information. The final stereo output is derived by merging the spatial images of the enhanced sources, with its efficacy not heavily reliant on the separation performance of the beamforming. The algorithm runs in real-time on 10-ms frames with a 40 ms of look-ahead. Evaluations reveal its effectiveness in enhancing speech and preserving spatial cues in both fully and sparsely overlapped mixtures.
Neural Harmonium: An Interpretable Deep Structure for Nonlinear Dynamic System Identification with Application to Audio Processing
Oct 10, 2023



Improving the interpretability of deep neural networks has recently gained increased attention, especially when the power of deep learning is leveraged to solve problems in physics. Interpretability helps us understand a model's ability to generalize and reveal its limitations. In this paper, we introduce a causal interpretable deep structure for modeling dynamic systems. Our proposed model makes use of the harmonic analysis by modeling the system in a time-frequency domain while maintaining high temporal and spectral resolution. Moreover, the model is built in an order recursive manner which allows for fast, robust, and exact second order optimization without the need for an explicit Hessian calculation. To circumvent the resulting high dimensionality of the building blocks of our system, a neural network is designed to identify the frequency interdependencies. The proposed model is illustrated and validated on nonlinear system identification problems as required for audio signal processing tasks. Crowd-sourced experimentation contrasting the performance of the proposed approach to other state-of-the-art solutions on an acoustic echo cancellation scenario confirms the effectiveness of our method for real-life applications.
NoLACE: Improving Low-Complexity Speech Codec Enhancement Through Adaptive Temporal Shaping
Sep 25, 2023



Speech codec enhancement methods are designed to remove distortions added by speech codecs. While classical methods are very low in complexity and add zero delay, their effectiveness is rather limited. Compared to that, DNN-based methods deliver higher quality but they are typically high in complexity and/or require delay. The recently proposed Linear Adaptive Coding Enhancer (LACE) addresses this problem by combining DNNs with classical long-term/short-term postfiltering resulting in a causal low-complexity model. A short-coming of the LACE model is, however, that quality quickly saturates when the model size is scaled up. To mitigate this problem, we propose a novel adatpive temporal shaping module that adds high temporal resolution to the LACE model resulting in the Non-Linear Adaptive Coding Enhancer (NoLACE). We adapt NoLACE to enhance the Opus codec and show that NoLACE significantly outperforms both the Opus baseline and an enlarged LACE model at 6, 9 and 12 kb/s. We also show that LACE and NoLACE are well-behaved when used with an ASR system.
A Framework for Unified Real-time Personalized and Non-Personalized Speech Enhancement
Feb 23, 2023



In this study, we present an approach to train a single speech enhancement network that can perform both personalized and non-personalized speech enhancement. This is achieved by incorporating a frame-wise conditioning input that specifies the type of enhancement output. To improve the quality of the enhanced output and mitigate oversuppression, we experiment with re-weighting frames by the presence or absence of speech activity and applying augmentations to speaker embeddings. By training under a multi-task learning setting, we empirically show that the proposed unified model obtains promising results on both personalized and non-personalized speech enhancement benchmarks and reaches similar performance to models that are trained specialized for either task. The strong performance of the proposed method demonstrates that the unified model is a more economical alternative compared to keeping separate task-specific models during inference.
Improved singing voice separation with chromagram-based pitch-aware remixing
Mar 28, 2022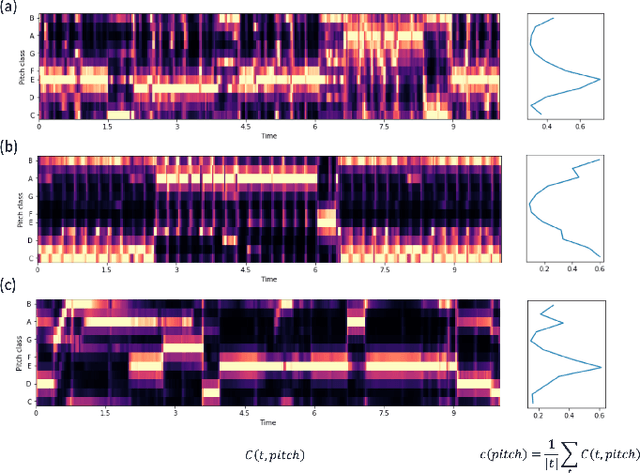
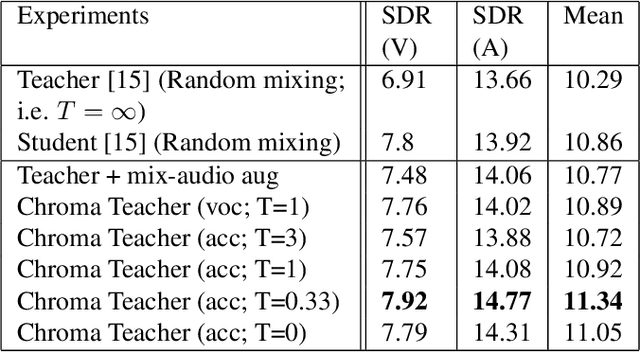
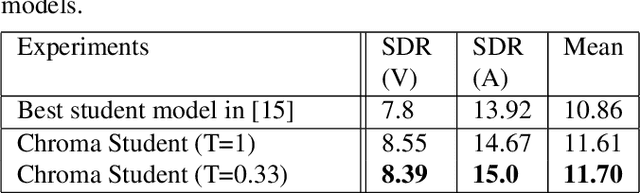
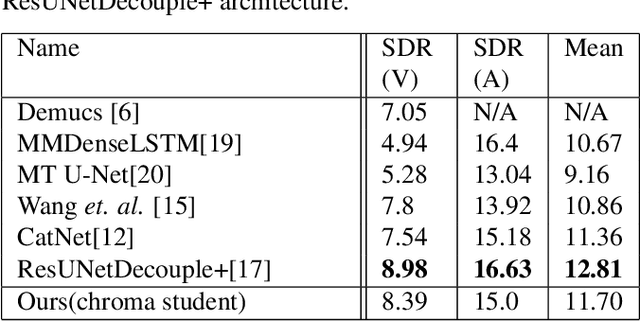
Singing voice separation aims to separate music into vocals and accompaniment components. One of the major constraints for the task is the limited amount of training data with separated vocals. Data augmentation techniques such as random source mixing have been shown to make better use of existing data and mildly improve model performance. We propose a novel data augmentation technique, chromagram-based pitch-aware remixing, where music segments with high pitch alignment are mixed. By performing controlled experiments in both supervised and semi-supervised settings, we demonstrate that training models with pitch-aware remixing significantly improves the test signal-to-distortion ratio (SDR)