 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Improving embedding of graphs with missing data by soft manifolds
Nov 29, 2023
Embedding graphs in continous spaces is a key factor in designing and developing algorithms for automatic information extraction to be applied in diverse tasks (e.g., learning, inferring, predicting). The reliability of graph embeddings directly depends on how much the geometry of the continuous space matches the graph structure. Manifolds are mathematical structure that can enable to incorporate in their topological spaces the graph characteristics, and in particular nodes distances. State-of-the-art of manifold-based graph embedding algorithms take advantage of the assumption that the projection on a tangential space of each point in the manifold (corresponding to a node in the graph) would locally resemble a Euclidean space. Although this condition helps in achieving efficient analytical solutions to the embedding problem, it does not represent an adequate set-up to work with modern real life graphs, that are characterized by weighted connections across nodes often computed over sparse datasets with missing records. In this work, we introduce a new class of manifold, named soft manifold, that can solve this situation. In particular, soft manifolds are mathematical structures with spherical symmetry where the tangent spaces to each point are hypocycloids whose shape is defined according to the velocity of information propagation across the data points. Using soft manifolds for graph embedding, we can provide continuous spaces to pursue any task in data analysis over complex datasets. Experimental results on reconstruction tasks on synthetic and real datasets show how the proposed approach enable more accurate and reliable characterization of graphs in continuous spaces with respect to the state-of-the-art.
Multi-dimensional Energy Limitation in Sphere Shaping for Nonlinear Interference Noise Mitigation
Nov 29, 2023We propose Four-Dimensional (4D) energy limit enumerative sphere shaping (ESS) of $M$-QAM signaling to minimize rate loss and improve the transmission performance over non-linear WDM optical-fiber systems. Simulation results show that the proposed scheme outperforms the conventional ESS by $0.19$~bit/4D-symbol in achievable information rate over a $205$-km single-span link and a WDM transmission of five polarization-division-multiplexed channels with $400$-Gbit/s net rate per channel. We also study the achieved performance over several shaping block lengths and show that the achieved gains do not scale well over multi-span systems.
USat: A Unified Self-Supervised Encoder for Multi-Sensor Satellite Imagery
Dec 02, 2023Large, self-supervised vision models have led to substantial advancements for automatically interpreting natural images. Recent works have begun tailoring these methods to remote sensing data which has rich structure with multi-sensor, multi-spectral, and temporal information providing massive amounts of self-labeled data that can be used for self-supervised pre-training. In this work, we develop a new encoder architecture called USat that can input multi-spectral data from multiple sensors for self-supervised pre-training. USat is a vision transformer with modified patch projection layers and positional encodings to model spectral bands with varying spatial scales from multiple sensors. We integrate USat into a Masked Autoencoder (MAE) self-supervised pre-training procedure and find that a pre-trained USat outperforms state-of-the-art self-supervised MAE models trained on remote sensing data on multiple remote sensing benchmark datasets (up to 8%) and leads to improvements in low data regimes (up to 7%). Code and pre-trained weights are available at https://github.com/stanfordmlgroup/USat .
Cancer Subtype Identification through Integrating Inter and Intra Dataset Relationships in Multi-Omics Data
Dec 02, 2023The integration of multi-omics data has emerged as a promising approach for gaining comprehensive insights into complex diseases such as cancer. This paper proposes a novel approach to identify cancer subtypes through the integration of multi-omics data for clustering. The proposed method, named LIDAF utilises affinity matrices based on linear relationships between and within different omics datasets (Linear Inter and Intra Dataset Affinity Fusion (LIDAF)). Canonical Correlation Analysis is in this paper employed to create distance matrices based on Euclidean distances between canonical variates. The distance matrices are converted to affinity matrices and those are fused in a three-step process. The proposed LIDAF addresses the limitations of the existing method resulting in improvement of clustering performance as measured by the Adjusted Rand Index and the Normalized Mutual Information score. Moreover, our proposed LIDAF approach demonstrates a notable enhancement in 50% of the log10 rank p-values obtained from Cox survival analysis, surpassing the performance of the best reported method, highlighting its potential of identifying distinct cancer subtypes.
QPoser: Quantized Explicit Pose Prior Modeling for Controllable Pose Generation
Dec 02, 2023Explicit pose prior models compress human poses into latent representations for using in pose-related downstream tasks. A desirable explicit pose prior model should satisfy three desirable abilities: 1) correctness, i.e. ensuring to generate physically possible poses; 2) expressiveness, i.e. ensuring to preserve details in generation; 3) controllability, meaning that generation from reference poses and explicit instructions should be convenient. Existing explicit pose prior models fail to achieve all of three properties, in special controllability. To break this situation, we propose QPoser, a highly controllable explicit pose prior model which guarantees correctness and expressiveness. In QPoser, a multi-head vector quantized autoencoder (MS-VQVAE) is proposed for obtaining expressive and distributed pose representations. Furthermore, a global-local feature integration mechanism (GLIF-AE) is utilized to disentangle the latent representation and integrate full-body information into local-joint features. Experimental results show that QPoser significantly outperforms state-of-the-art approaches in representing expressive and correct poses, meanwhile is easily to be used for detailed conditional generation from reference poses and prompting instructions.
Prior-Aware Robust Beam Alignment for Low-SNR Millimeter-Wave Communications
Dec 02, 2023This paper presents a robust beam alignment technique for millimeter-wave communications in low signal-to-noise ratio (SNR) environments. The core strategy of our technique is to repeatedly transmit the most probable beam candidates to reduce beam misalignment probability induced by noise. Specifically, for a given beam training overhead, both the selection of candidates and the number of repetitions for each beam candidate are optimized based on channel prior information. To achieve this, a deep neural network is employed to learn the prior probability of the optimal beam at each location. The beam misalignment probability is then analyzed based on the channel prior, forming the basis for an optimization problem aimed at minimizing the analyzed beam misalignment probability. A closed-form solution is derived for a special case with two beam candidates, and an efficient algorithm is developed for general cases with multiple beam candidates. Simulation results using the DeepMIMO dataset demonstrate the superior performance of our technique in dynamic low-SNR communication environments when compared to existing beam alignment techniques.
$t^3$-Variational Autoencoder: Learning Heavy-tailed Data with Student's t and Power Divergence
Dec 02, 2023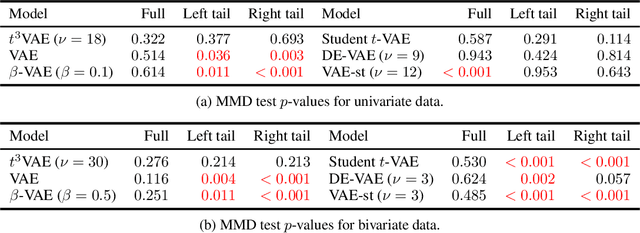
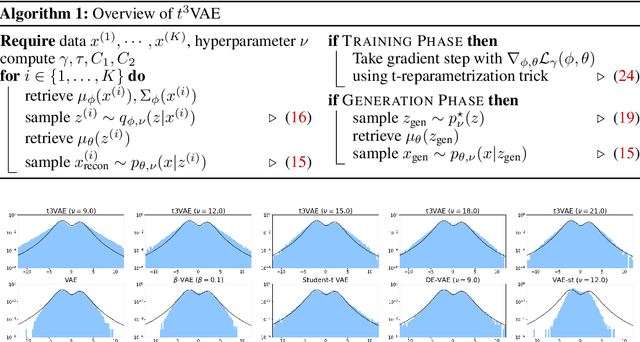


The variational autoencoder (VAE) typically employs a standard normal prior as a regularizer for the probabilistic latent encoder. However, the Gaussian tail often decays too quickly to effectively accommodate the encoded points, failing to preserve crucial structures hidden in the data. In this paper, we explore the use of heavy-tailed models to combat over-regularization. Drawing upon insights from information geometry, we propose $t^3$VAE, a modified VAE framework that incorporates Student's t-distributions for the prior, encoder, and decoder. This results in a joint model distribution of a power form which we argue can better fit real-world datasets. We derive a new objective by reformulating the evidence lower bound as joint optimization of KL divergence between two statistical manifolds and replacing with $\gamma$-power divergence, a natural alternative for power families. $t^3$VAE demonstrates superior generation of low-density regions when trained on heavy-tailed synthetic data. Furthermore, we show that $t^3$VAE significantly outperforms other models on CelebA and imbalanced CIFAR-100 datasets.
Few-shot Shape Recognition by Learning Deep Shape-aware Features
Dec 03, 2023Traditional shape descriptors have been gradually replaced by convolutional neural networks due to their superior performance in feature extraction and classification. The state-of-the-art methods recognize object shapes via image reconstruction or pixel classification. However , these methods are biased toward texture information and overlook the essential shape descriptions, thus, they fail to generalize to unseen shapes. We are the first to propose a fewshot shape descriptor (FSSD) to recognize object shapes given only one or a few samples. We employ an embedding module for FSSD to extract transformation-invariant shape features. Secondly, we develop a dual attention mechanism to decompose and reconstruct the shape features via learnable shape primitives. In this way, any shape can be formed through a finite set basis, and the learned representation model is highly interpretable and extendable to unseen shapes. Thirdly, we propose a decoding module to include the supervision of shape masks and edges and align the original and reconstructed shape features, enforcing the learned features to be more shape-aware. Lastly, all the proposed modules are assembled into a few-shot shape recognition scheme. Experiments on five datasets show that our FSSD significantly improves the shape classification compared to the state-of-the-art under the few-shot setting.
Token Recycling for Efficient Sequential Inference with Vision Transformers
Nov 26, 2023Vision Transformers (ViTs) overpass Convolutional Neural Networks in processing incomplete inputs because they do not require the imputation of missing values. Therefore, ViTs are well suited for sequential decision-making, e.g. in the Active Visual Exploration problem. However, they are computationally inefficient because they perform a full forward pass each time a piece of new sequential information arrives. To reduce this computational inefficiency, we introduce the TOken REcycling (TORE) modification for the ViT inference, which can be used with any architecture. TORE divides ViT into two parts, iterator and aggregator. An iterator processes sequential information separately into midway tokens, which are cached. The aggregator processes midway tokens jointly to obtain the prediction. This way, we can reuse the results of computations made by iterator. Except for efficient sequential inference, we propose a complementary training policy, which significantly reduces the computational burden associated with sequential decision-making while achieving state-of-the-art accuracy.
A Deep Q-Learning based, Base-Station Connectivity-Aware, Decentralized Pheromone Mobility Model for Autonomous UAV Networks
Nov 28, 2023UAV networks consisting of low SWaP (size, weight, and power), fixed-wing UAVs are used in many applications, including area monitoring, search and rescue, surveillance, and tracking. Performing these operations efficiently requires a scalable, decentralized, autonomous UAV network architecture with high network connectivity. Whereas fast area coverage is needed for quickly sensing the area, strong node degree and base station (BS) connectivity are needed for UAV control and coordination and for transmitting sensed information to the BS in real time. However, the area coverage and connectivity exhibit a fundamental trade-off: maintaining connectivity restricts the UAVs' ability to explore. In this paper, we first present a node degree and BS connectivity-aware distributed pheromone (BS-CAP) mobility model to autonomously coordinate the UAV movements in a decentralized UAV network. This model maintains a desired connectivity among 1-hop neighbors and to the BS while achieving fast area coverage. Next, we propose a deep Q-learning policy based BS-CAP model (BSCAP-DQN) to further tune and improve the coverage and connectivity trade-off. Since it is not practical to know the complete topology of such a network in real time, the proposed mobility models work online, are fully distributed, and rely on neighborhood information. Our simulations demonstrate that both proposed models achieve efficient area coverage and desired node degree and BS connectivity, improving significantly over existing schemes.