 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Response to NITRD, NCO, NSF Request for Information on "Update to the 2016 National Artificial Intelligence Research and Development Strategic Plan"
Nov 05, 2019
We present a response to the 2018 Request for Information (RFI) from the NITRD, NCO, NSF regarding the "Update to the 2016 National Artificial Intelligence Research and Development Strategic Plan." Through this document, we provide a response to the question of whether and how the National Artificial Intelligence Research and Development Strategic Plan (NAIRDSP) should be updated from the perspective of Fermilab, America's premier national laboratory for High Energy Physics (HEP). We believe the NAIRDSP should be extended in light of the rapid pace of development and innovation in the field of Artificial Intelligence (AI) since 2016, and present our recommendations below. AI has profoundly impacted many areas of human life, promising to dramatically reshape society --- e.g., economy, education, science --- in the coming years. We are still early in this process. It is critical to invest now in this technology to ensure it is safe and deployed ethically. Science and society both have a strong need for accuracy, efficiency, transparency, and accountability in algorithms, making investments in scientific AI particularly valuable. Thus far the US has been a leader in AI technologies, and we believe as a national Laboratory it is crucial to help maintain and extend this leadership. Moreover, investments in AI will be important for maintaining US leadership in the physical sciences.
Hybrid analysis and modeling, eclecticism, and multifidelity computing toward digital twin revolution
Mar 26, 2021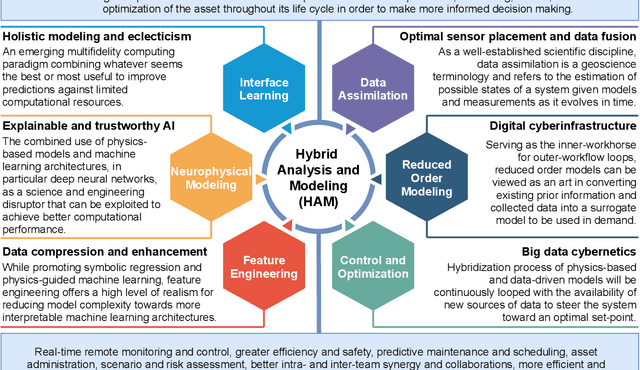
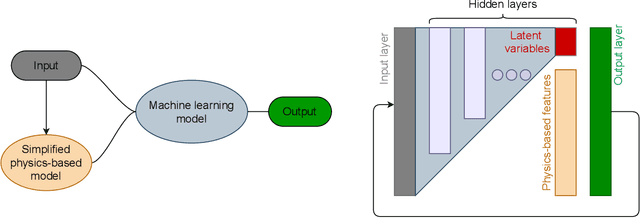
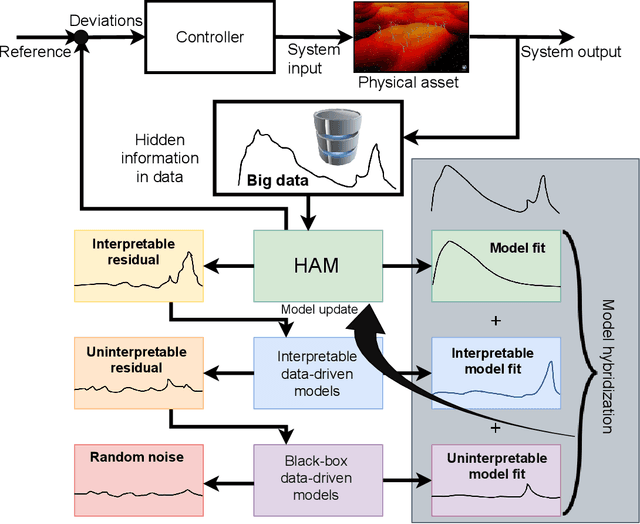
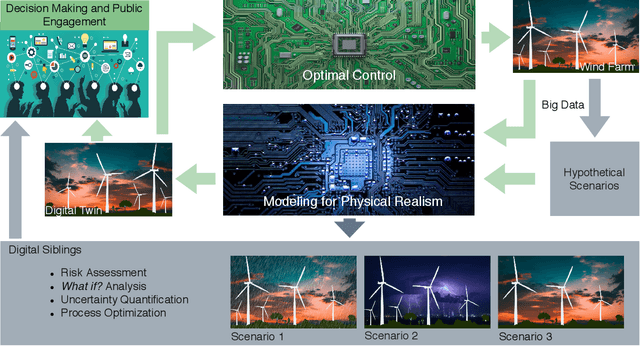
Most modeling approaches lie in either of the two categories: physics-based or data-driven. Recently, a third approach which is a combination of these deterministic and statistical models is emerging for scientific applications. To leverage these developments, our aim in this perspective paper is centered around exploring numerous principle concepts to address the challenges of (i) trustworthiness and generalizability in developing data-driven models to shed light on understanding the fundamental trade-offs in their accuracy and efficiency, and (ii) seamless integration of interface learning and multifidelity coupling approaches that transfer and represent information between different entities, particularly when different scales are governed by different physics, each operating on a different level of abstraction. Addressing these challenges could enable the revolution of digital twin technologies for scientific and engineering applications.
Societal Biases in Retrieved Contents: Measurement Framework and Adversarial Mitigation for BERT Rankers
May 11, 2021

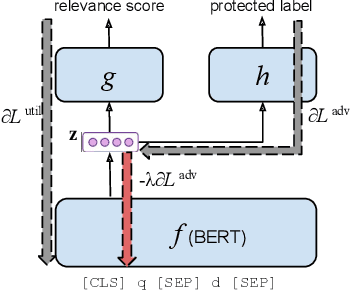
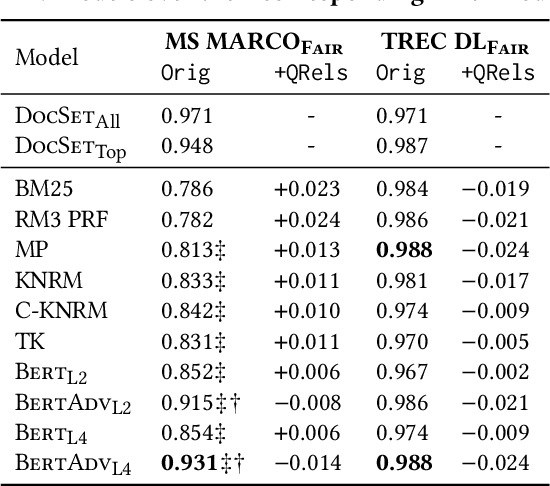
Societal biases resonate in the retrieved contents of information retrieval (IR) systems, resulting in reinforcing existing stereotypes. Approaching this issue requires established measures of fairness in respect to the representation of various social groups in retrieval results, as well as methods to mitigate such biases, particularly in the light of the advances in deep ranking models. In this work, we first provide a novel framework to measure the fairness in the retrieved text contents of ranking models. Introducing a ranker-agnostic measurement, the framework also enables the disentanglement of the effect on fairness of collection from that of rankers. To mitigate these biases, we propose AdvBert, a ranking model achieved by adapting adversarial bias mitigation for IR, which jointly learns to predict relevance and remove protected attributes. We conduct experiments on two passage retrieval collections (MSMARCO Passage Re-ranking and TREC Deep Learning 2019 Passage Re-ranking), which we extend by fairness annotations of a selected subset of queries regarding gender attributes. Our results on the MSMARCO benchmark show that, (1) all ranking models are less fair in comparison with ranker-agnostic baselines, and (2) the fairness of Bert rankers significantly improves when using the proposed AdvBert models. Lastly, we investigate the trade-off between fairness and utility, showing that we can maintain the significant improvements in fairness without any significant loss in utility.
Sentiment and Emotion Classification of Epidemic Related Bilingual data from Social Media
May 04, 2021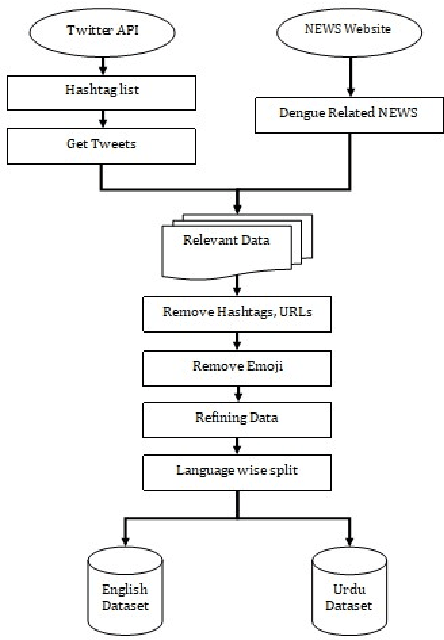
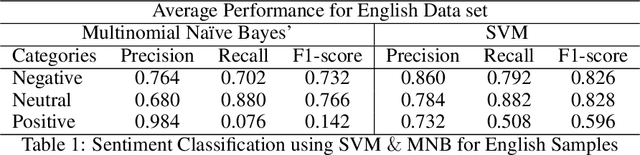
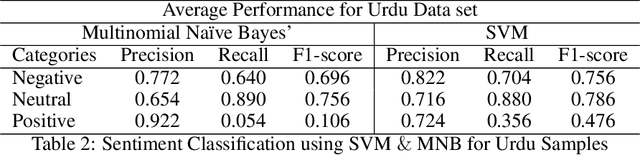
In recent years, sentiment analysis and emotion classification are two of the most abundantly used techniques in the field of Natural Language Processing (NLP). Although sentiment analysis and emotion classification are used commonly in applications such as analyzing customer reviews, the popularity of candidates contesting in elections, and comments about various sporting events; however, in this study, we have examined their application for epidemic outbreak detection. Early outbreak detection is the key to deal with epidemics effectively, however, the traditional ways of outbreak detection are time-consuming which inhibits prompt response from the respective departments. Social media platforms such as Twitter, Facebook, Instagram, etc. allow the users to express their thoughts related to different aspects of life, and therefore, serve as a substantial source of information in such situations. The proposed study exploits the bilingual (Urdu and English) data from Twitter and NEWS websites related to the dengue epidemic in Pakistan, and sentiment analysis and emotion classification are performed to acquire deep insights from the data set for gaining a fair idea related to an epidemic outbreak. Machine learning and deep learning algorithms have been used to train and implement the models for the execution of both tasks. The comparative performance of each model has been evaluated using accuracy, precision, recall, and f1-measure.
Cyclic Co-Learning of Sounding Object Visual Grounding and Sound Separation
Apr 05, 2021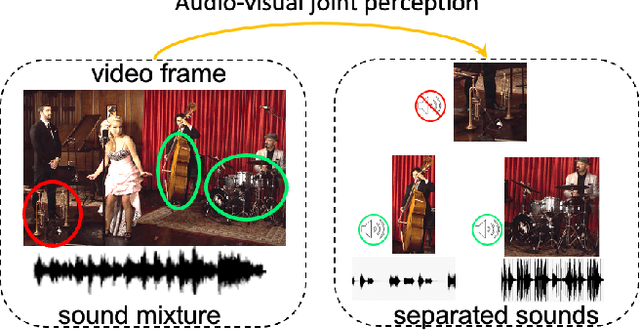
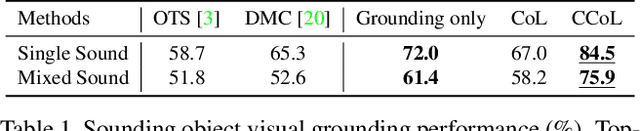
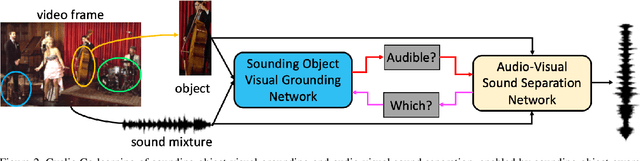
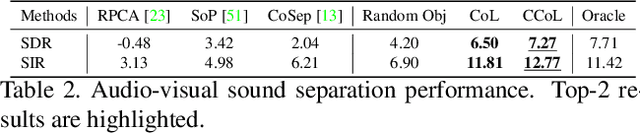
There are rich synchronized audio and visual events in our daily life. Inside the events, audio scenes are associated with the corresponding visual objects; meanwhile, sounding objects can indicate and help to separate their individual sounds in the audio track. Based on this observation, in this paper, we propose a cyclic co-learning (CCoL) paradigm that can jointly learn sounding object visual grounding and audio-visual sound separation in a unified framework. Concretely, we can leverage grounded object-sound relations to improve the results of sound separation. Meanwhile, benefiting from discriminative information from separated sounds, we improve training example sampling for sounding object grounding, which builds a co-learning cycle for the two tasks and makes them mutually beneficial. Extensive experiments show that the proposed framework outperforms the compared recent approaches on both tasks, and they can benefit from each other with our cyclic co-learning.
A Multiscale Graph Convolutional Network for Change Detection in Homogeneous and Heterogeneous Remote Sensing Images
Feb 16, 2021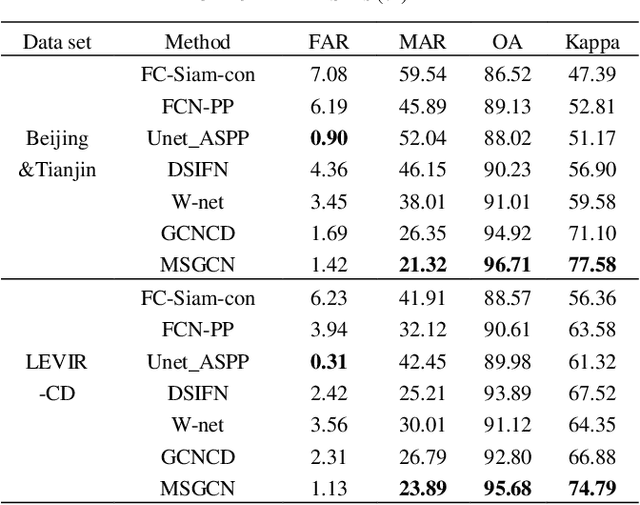
Change detection (CD) in remote sensing images has been an ever-expanding area of research. To date, although many methods have been proposed using various techniques, accurately identifying changes is still a great challenge, especially in the high resolution or heterogeneous situations, due to the difficulties in effectively modeling the features from ground objects with different patterns. In this paper, a novel CD method based on the graph convolutional network (GCN) and multiscale object-based technique is proposed for both homogeneous and heterogeneous images. First, the object-wise high level features are obtained through a pre-trained U-net and the multiscale segmentations. Treating each parcel as a node, the graph representations can be formed and then, fed into the proposed multiscale graph convolutional network with each channel corresponding to one scale. The multiscale GCN propagates the label information from a small number of labeled nodes to the other ones which are unlabeled. Further, to comprehensively incorporate the information from the output channels of multiscale GCN, a fusion strategy is designed using the father-child relationships between scales. Extensive Experiments on optical, SAR and heterogeneous optical/SAR data sets demonstrate that the proposed method outperforms some state-of the-art methods in both qualitative and quantitative evaluations. Besides, the Influences of some factors are also discussed.
Decentralized Inference with Graph Neural Networks in Wireless Communication Systems
Apr 19, 2021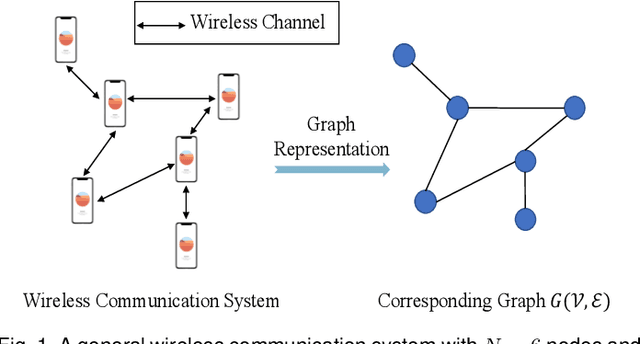
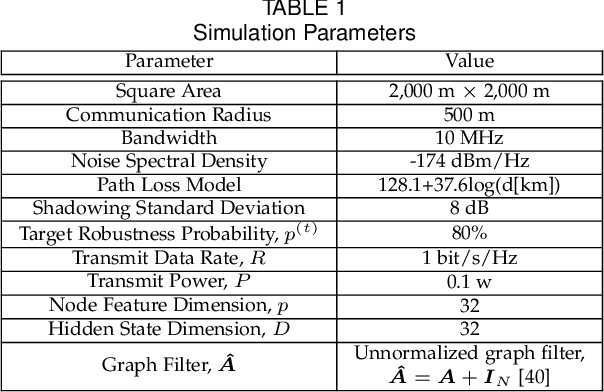
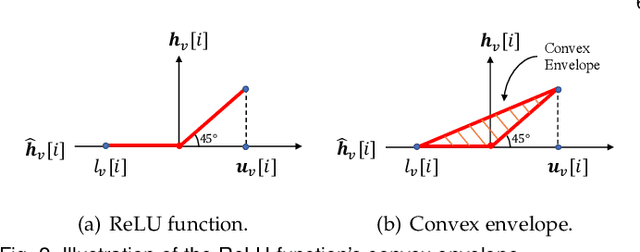

Graph neural network (GNN) is an efficient neural network model for graph data and is widely used in different fields, including wireless communications. Different from other neural network models, GNN can be implemented in a decentralized manner with information exchanges among neighbors, making it a potentially powerful tool for decentralized control in wireless communication systems. The main bottleneck, however, is wireless channel impairments that deteriorate the prediction robustness of GNN. To overcome this obstacle, we analyze and enhance the robustness of the decentralized GNN in different wireless communication systems in this paper. Specifically, using a GNN binary classifier as an example, we first develop a methodology to verify whether the predictions are robust. Then, we analyze the performance of the decentralized GNN binary classifier in both uncoded and coded wireless communication systems. To remedy imperfect wireless transmission and enhance the prediction robustness, we further propose novel retransmission mechanisms for the above two communication systems, respectively. Through simulations on the synthetic graph data, we validate our analysis, verify the effectiveness of the proposed retransmission mechanisms, and provide some insights for practical implementation.
Dr-Vectors: Decision Residual Networks and an Improved Loss for Speaker Recognition
Apr 05, 2021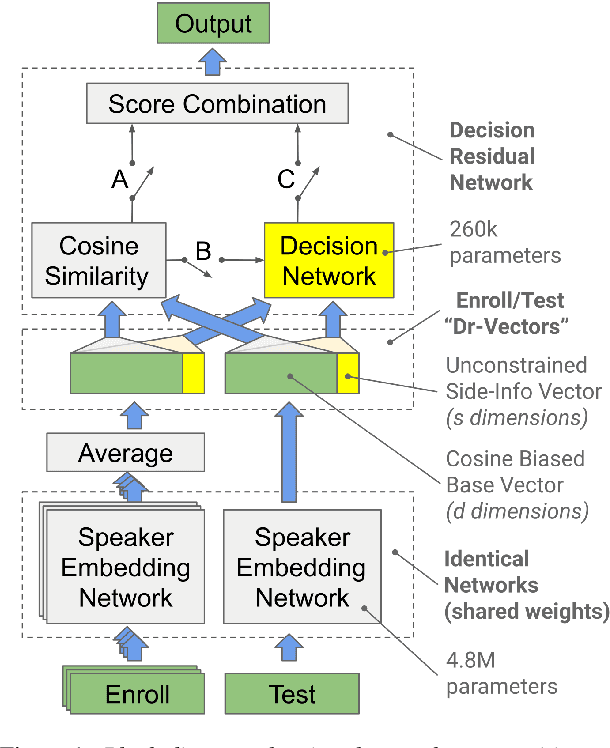
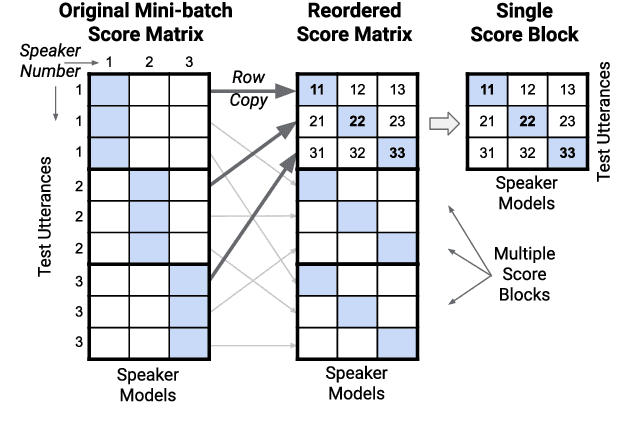
Many neural network speaker recognition systems model each speaker using a fixed-dimensional embedding vector. These embeddings are generally compared using either linear or 2nd-order scoring and, until recently, do not handle utterance-specific uncertainty. In this work we propose scoring these representations in a way that can capture uncertainty, enroll/test asymmetry and additional non-linear information. This is achieved by incorporating a 2nd-stage neural network (known as a decision network) as part of an end-to-end training regimen. In particular, we propose the concept of decision residual networks which involves the use of a compact decision network to leverage cosine scores and to model the residual signal that's needed. Additionally, we present a modification to the generalized end-to-end softmax loss function to better target the separation of same/different speaker scores. We observed significant performance gains for the two techniques.
An effective and friendly tool for seed image analysis
Mar 31, 2021
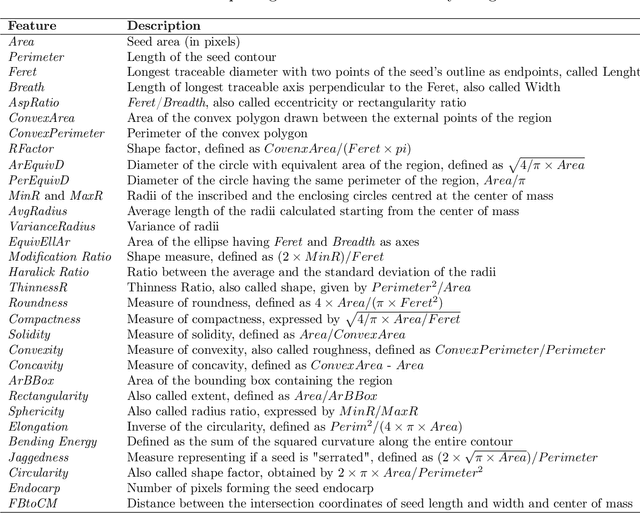


Image analysis is an essential field for several topics of life sciences, such as biology or botany. In particular, seeds analysis (e.g., fossil research) can provide significant information about their evolution, the history of agriculture, the domestication of plants, and the knowledge of diets in ancient times. This work aims to present a software that performs an image analysis by feature extraction and classification starting from images containing seeds through a brand new and unique framework. In detail, we propose two \emph{ImageJ} plugins, one capable of extracting morphological, textural, and colour characteristics from images of seeds, and another one to classify the seeds into categories by using the extracted features. The experimental results demonstrated the correctness and validity both of the extracted features and the classification predictions. The proposed tool is easily extendable to other fields of image analysis.
Traffic Scenario Clustering by Iterative Optimisation of Self-Supervised Networks Using a Random Forest Activation Pattern Similarity
May 17, 2021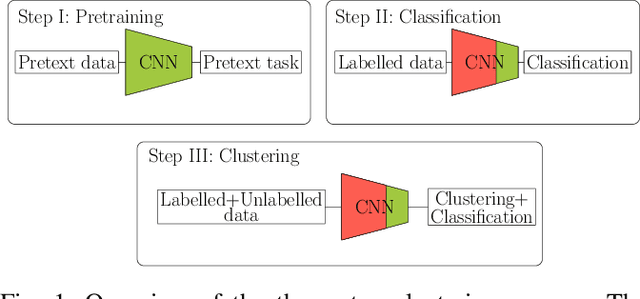
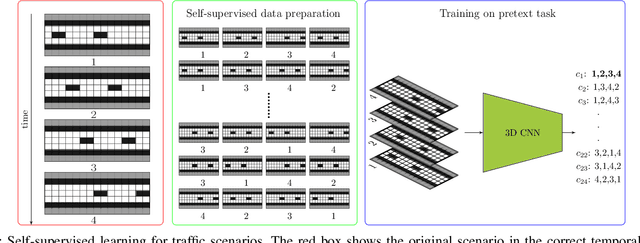
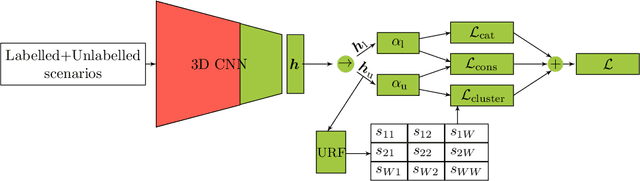
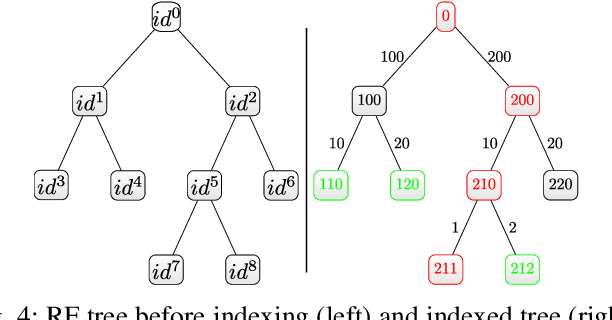
Traffic scenario categorisation is an essential component of automated driving, for e.\,g., in motion planning algorithms and their validation. Finding new relevant scenarios without handcrafted steps reduce the required resources for the development of autonomous driving dramatically. In this work, a method is proposed to address this challenge by introducing a clustering technique based on a novel data-adaptive similarity measure, called Random Forest Activation Pattern (RFAP) similarity. The RFAP similarity is generated using a tree encoding scheme in a Random Forest algorithm. The clustering method proposed in this work takes into account that there are labelled scenarios available and the information from the labelled scenarios can help to guide the clustering of unlabelled scenarios. It consists of three steps. First, a self-supervised Convolutional Neural Network~(CNN) is trained on all available traffic scenarios using a defined self-supervised objective. Second, the CNN is fine-tuned for classification of the labelled scenarios. Third, using the labelled and unlabelled scenarios an iterative optimisation procedure is performed for clustering. In the third step at each epoch of the iterative optimisation, the CNN is used as a feature generator for an unsupervised Random Forest. The trained forest, in turn, provides the RFAP similarity to adapt iteratively the feature generation process implemented by the CNN. Extensive experiments and ablation studies have been done on the highD dataset. The proposed method shows superior performance compared to baseline clustering techniques.