 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Greedy Search Algorithms for Unsupervised Variable Selection: A Comparative Study
Mar 03, 2021
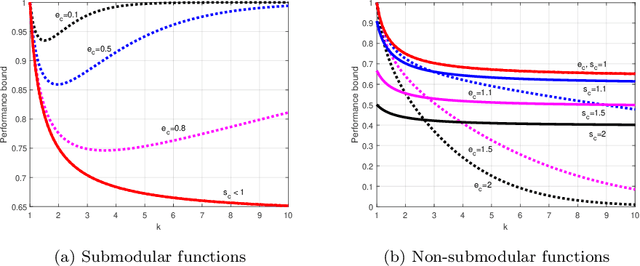
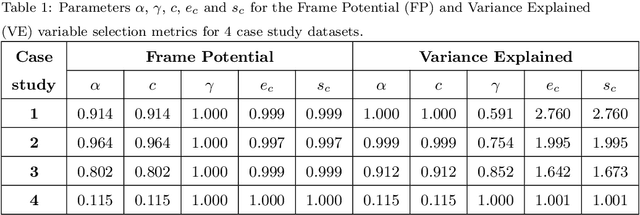
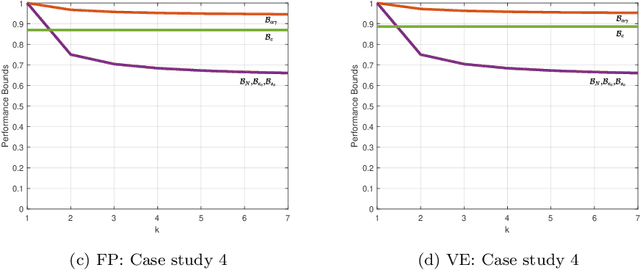

Dimensionality reduction is a important step in the development of scalable and interpretable data-driven models, especially when there are a large number of candidate variables. This paper focuses on unsupervised variable selection based dimensionality reduction, and in particular on unsupervised greedy selection methods, which have been proposed by various researchers as computationally tractable approximations to optimal subset selection. These methods are largely distinguished from each other by the selection criterion adopted, which include squared correlation, variance explained, mutual information and frame potential. Motivated by the absence in the literature of a systematic comparison of these different methods, we present a critical evaluation of seven unsupervised greedy variable selection algorithms considering both simulated and real world case studies. We also review the theoretical results that provide performance guarantees and enable efficient implementations for certain classes of greedy selection function, related to the concept of submodularity. Furthermore, we introduce and evaluate for the first time, a lazy implementation of the variance explained based forward selection component analysis (FSCA) algorithm. Our experimental results show that: (1) variance explained and mutual information based selection methods yield smaller approximation errors than frame potential; (2) the lazy FSCA implementation has similar performance to FSCA, while being an order of magnitude faster to compute, making it the algorithm of choice for unsupervised variable selection.
Speaker Attentive Speech Emotion Recognition
Apr 15, 2021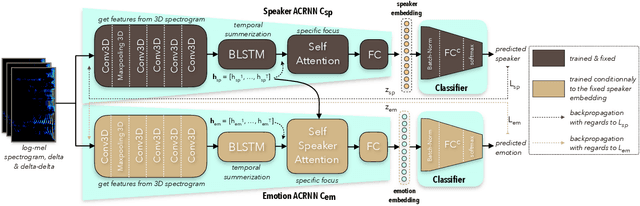
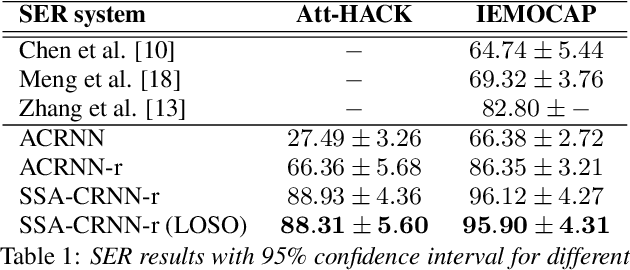
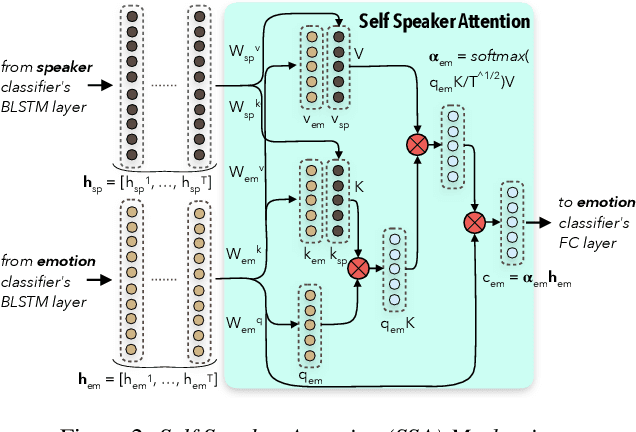
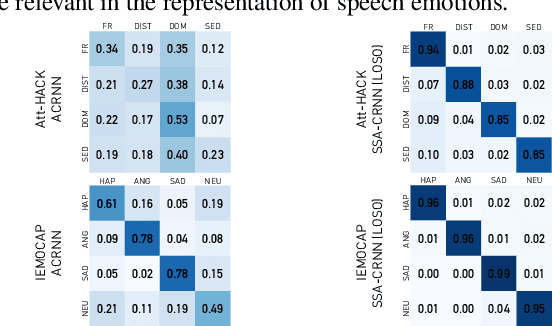
Speech Emotion Recognition (SER) task has known significant improvements over the last years with the advent of Deep Neural Networks (DNNs). However, even the most successful methods are still rather failing when adaptation to specific speakers and scenarios is needed, inevitably leading to poorer performances when compared to humans. In this paper, we present novel work based on the idea of teaching the emotion recognition network about speaker identity. Our system is a combination of two ACRNN classifiers respectively dedicated to speaker and emotion recognition. The first informs the latter through a Self Speaker Attention (SSA) mechanism that is shown to considerably help to focus on emotional information of the speech signal. Experiments on social attitudes database Att-HACK and IEMOCAP corpus demonstrate the effectiveness of the proposed method and achieve the state-of-the-art performance in terms of unweighted average recall.
A Two-stage Framework for Compound Figure Separation
Jan 25, 2021
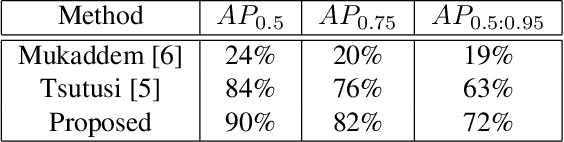
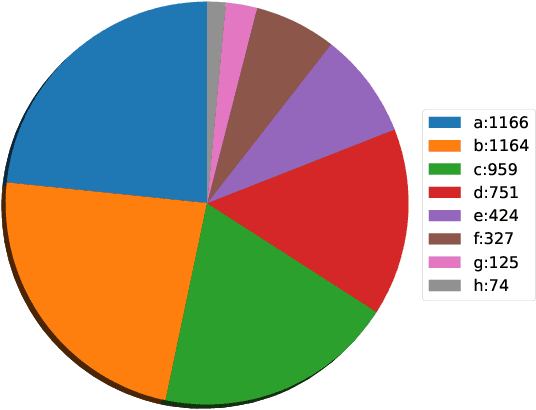
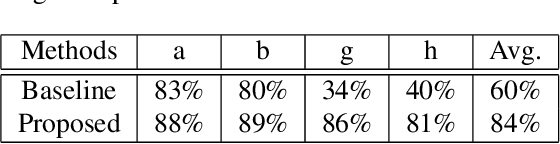
Scientific literature contains large volumes of complex, unstructured figures that are compound in nature (i.e. composed of multiple images, graphs, and drawings). Separation of these compound figures is critical for information retrieval from these figures. In this paper, we propose a new strategy for compound figure separation, which decomposes the compound figures into constituent subfigures while preserving the association between the subfigures and their respective caption components. We propose a two-stage framework to address the proposed compound figure separation problem. In particular, the subfigure label detection module detects all subfigure labels in the first stage. Then, in the subfigure detection module, the detected subfigure labels help to detect the subfigures by optimizing the feature selection process and providing the global layout information as extra features. Extensive experiments are conducted to validate the effectiveness and superiority of the proposed framework, which improves the detection precision by 9%.
Finding a Needle in a Haystack: Tiny Flying Object Detection in 4K Videos using a Joint Detection-and-Tracking Approach
May 18, 2021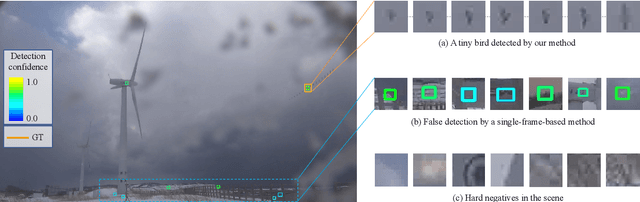

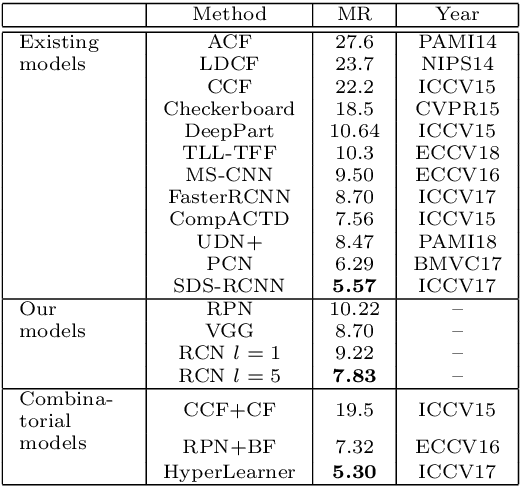
Detecting tiny objects in a high-resolution video is challenging because the visual information is little and unreliable. Specifically, the challenge includes very low resolution of the objects, MPEG artifacts due to compression and a large searching area with many hard negatives. Tracking is equally difficult because of the unreliable appearance, and the unreliable motion estimation. Luckily, we found that by combining this two challenging tasks together, there will be mutual benefits. Following the idea, in this paper, we present a neural network model called the Recurrent Correlational Network, where detection and tracking are jointly performed over a multi-frame representation learned through a single, trainable, and end-to-end network. The framework exploits a convolutional long short-term memory network for learning informative appearance changes for detection, while the learned representation is shared in tracking for enhancing its performance. In experiments with datasets containing images of scenes with small flying objects, such as birds and unmanned aerial vehicles, the proposed method yielded consistent improvements in detection performance over deep single-frame detectors and existing motion-based detectors. Furthermore, our network performs as well as state-of-the-art generic object trackers when it was evaluated as a tracker on a bird image dataset.
Causal version of Principle of Insufficient Reason and MaxEnt
Feb 07, 2021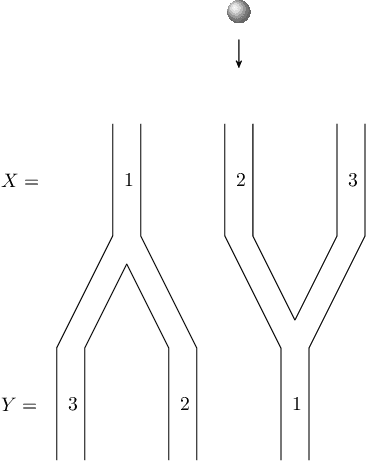
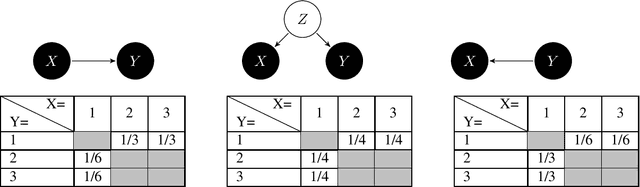
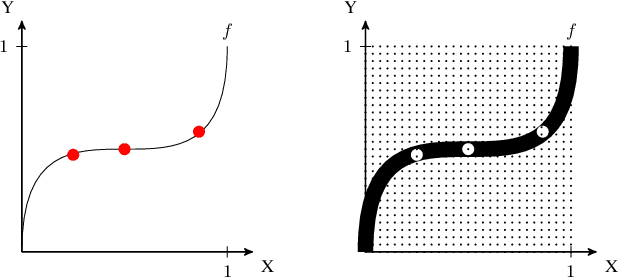
The Principle of insufficient Reason (PIR) assigns equal probabilities to each alternative of a random experiment whenever there is no reason to prefer one over the other. Maximum Entropy (MaxEnt) generalizes PIR to the case where statistical information like expectations are given. It is known that both principles result in paradox probability updates for joint distributions of cause and effect. This is because constraints on the conditional P(effect | cause) result in changes of P(cause) that assign higher probability to those values of the cause that offer more options for the effect, suggesting 'intentional behaviour'. Earlier work therefore suggested sequentially maximizing (conditional) entropy according to the causal order, but without further justification apart from plausibility for toy examples. We justify causal modifications of PIR and MaxEnt by separating constraints into restrictions for the cause and restrictions for the mechanism that generates the effect from the cause. We further sketch why Causal PIR also entails 'Information Geometric Causal Inference'. We briefly discuss problems of generalizing the causal version of MaxEnt to arbitrary causal DAGs.
Knodle: Modular Weakly Supervised Learning with PyTorch
May 10, 2021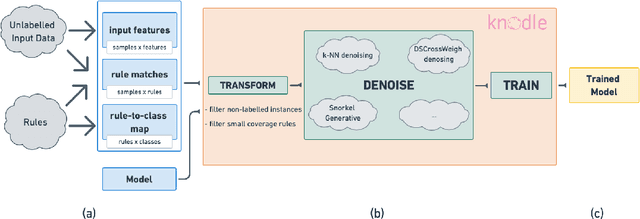

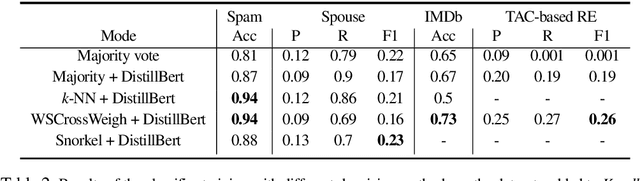
Strategies for improving the training and prediction quality of weakly supervised machine learning models vary in how much they are tailored to a specific task or integrated with a specific model architecture. In this work, we propose a software framework Knodle that treats weak data annotations, deep learning models, and methods for improving weakly supervised training as separate, modular components. The standardized interfaces between these independent parts account for data- and model-agnostic weak supervision method development, but still allow the training process to access fine-grained information such as data set characteristics, matches of heuristic rules, as well as elements of the deep learning model ultimately used for prediction. Hence, our framework can encompass a wide range of training methods for improving weak supervision, ranging from methods that only look at correlations of rules and output classes (independently of the machine learning model trained with the resulting labels), to those that harness the interplay of neural networks and weakly labeled data. We illustrate the benchmarking potential of the framework with a performance comparison of several reference implementations on a selection of datasets that are already available in Knodle.
PEMNET: A Transfer Learning-based Modeling Approach of High-Temperature Polymer Electrolyte Membrane Electrochemical Systems
May 24, 2021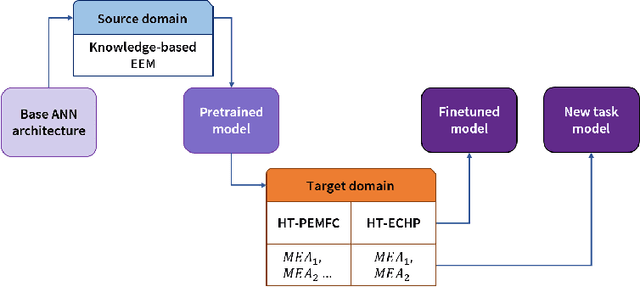
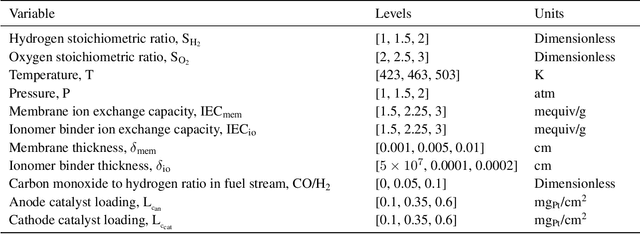
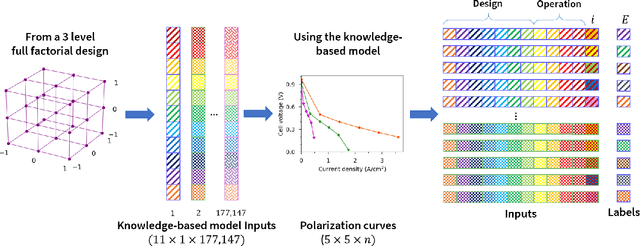
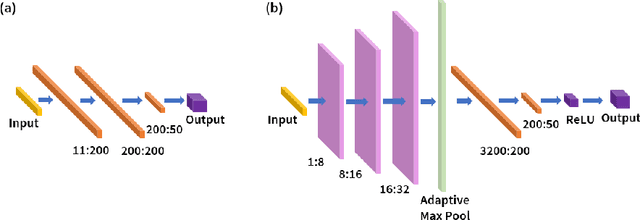
Widespread adoption of high-temperature polymer electrolyte membrane fuel cells (HT-PEMFCs) and HT-PEM electrochemical hydrogen pumps (HT-PEM ECHPs) requires models and computational tools that provide accurate scale-up and optimization. Knowledge-based modeling has limitations as it is time consuming and requires information about the system that is not always available (e.g., material properties and interfacial behavior between different materials). Data-driven modeling on the other hand, is easier to implement, but often necessitates large datasets that could be difficult to obtain. In this contribution, knowledge-based modeling and data-driven modeling are uniquely combined by implementing a Few-Shot Learning (FSL) approach. A knowledge-based model originally developed for a HT-PEMFC was used to generate simulated data (887,735 points) and used to pretrain a neural network source model. Furthermore, the source model developed for HT-PEMFCs was successfully applied to HT-PEM ECHPs - a different electrochemical system that utilizes similar materials to the fuel cell. Experimental datasets from both HT-PEMFCs and HT-PEM ECHPs with different materials and operating conditions (~50 points each) were used to train 8 target models via FSL. Models for the unseen data reached high accuracies in all cases (rRMSE between 1.04 and 3.73% for HT-PEMCs and between 6.38 and 8.46% for HT-PEM ECHPs).
NLHD: A Pixel-Level Non-Local Retinex Model for Low-Light Image Enhancement
Jun 15, 2021


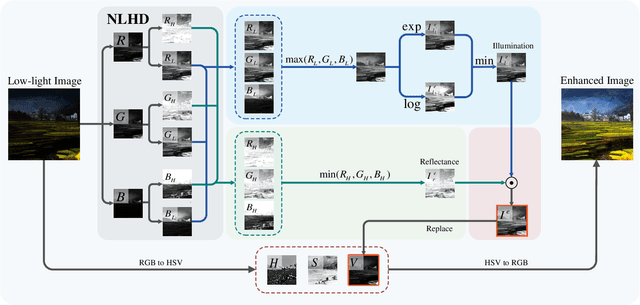
Retinex model has been applied to low-light image enhancement in many existing methods. More appropriate decomposition of a low-light image can help achieve better image enhancement. In this paper, we propose a new pixel-level non-local Haar transform based illumination and reflectance decomposition method (NLHD). The unique low-frequency coefficient of Haar transform on each similar pixel group is used to reconstruct the illumination component, and the rest of all high-frequency coefficients are employed to reconstruct the reflectance component. The complete similarity of pixels in a matched similar pixel group and the simple separable Haar transform help to obtain more appropriate image decomposition; thus, the image is hardly sharpened in the image brightness enhancement procedure. The exponential transform and logarithmic transform are respectively implemented on the illumination component. Then a minimum fusion strategy on the results of these two transforms is utilized to achieve more natural illumination component enhancement. It can alleviate the mosaic artifacts produced in the darker regions by the exponential transform with a gamma value less than 1 and reduce information loss caused by excessive enhancement of the brighter regions due to the logarithmic transform. Finally, the Retinex model is applied to the enhanced illumination and reflectance to achieve image enhancement. We also develop a local noise level estimation based noise suppression method and a non-local saturation reduction based color deviation correction method. These two methods can respectively attenuate noise or color deviation usually presented in the enhanced results of the extremely dark low-light images. Experiments on benchmark datasets show that the proposed method can achieve better low-light image enhancement results on subjective and objective evaluations than most existing methods.
Towards information-rich, logical text generation with knowledge-enhanced neural models
Mar 02, 2020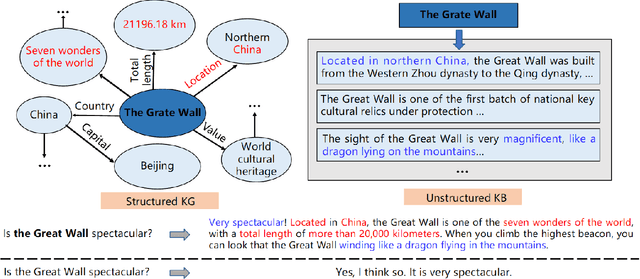

Text generation system has made massive promising progress contributed by deep learning techniques and has been widely applied in our life. However, existing end-to-end neural models suffer from the problem of tending to generate uninformative and generic text because they cannot ground input context with background knowledge. In order to solve this problem, many researchers begin to consider combining external knowledge in text generation systems, namely knowledge-enhanced text generation. The challenges of knowledge enhanced text generation including how to select the appropriate knowledge from large-scale knowledge bases, how to read and understand extracted knowledge, and how to integrate knowledge into generation process. This survey gives a comprehensive review of knowledge-enhanced text generation systems, summarizes research progress to solving these challenges and proposes some open issues and research directions.
Not All Relevance Scores are Equal: Efficient Uncertainty and Calibration Modeling for Deep Retrieval Models
May 10, 2021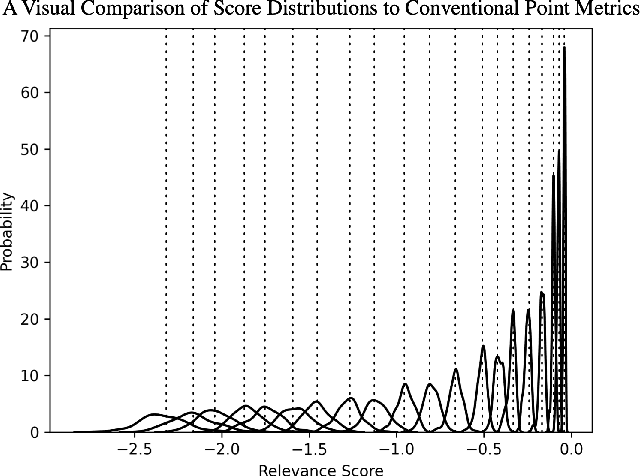
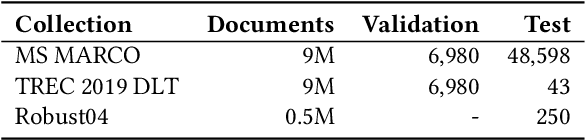
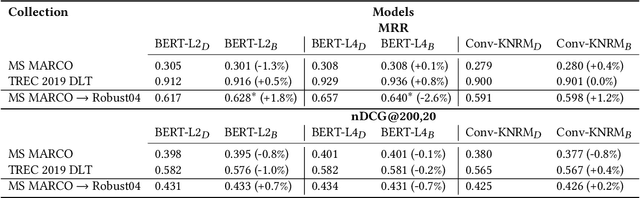
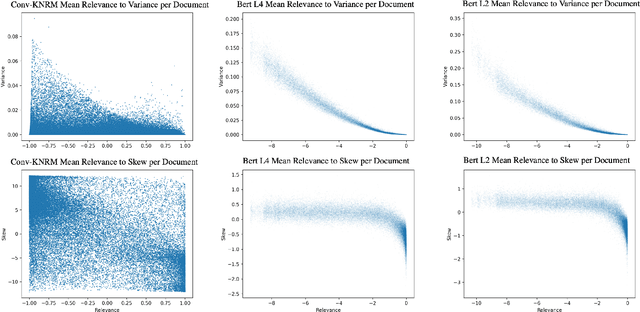
In any ranking system, the retrieval model outputs a single score for a document based on its belief on how relevant it is to a given search query. While retrieval models have continued to improve with the introduction of increasingly complex architectures, few works have investigated a retrieval model's belief in the score beyond the scope of a single value. We argue that capturing the model's uncertainty with respect to its own scoring of a document is a critical aspect of retrieval that allows for greater use of current models across new document distributions, collections, or even improving effectiveness for down-stream tasks. In this paper, we address this problem via an efficient Bayesian framework for retrieval models which captures the model's belief in the relevance score through a stochastic process while adding only negligible computational overhead. We evaluate this belief via a ranking based calibration metric showing that our approximate Bayesian framework significantly improves a retrieval model's ranking effectiveness through a risk aware reranking as well as its confidence calibration. Lastly, we demonstrate that this additional uncertainty information is actionable and reliable on down-stream tasks represented via cutoff prediction.